Transformers Versions Save
🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX.
v4.37.1
3 months agoA patch release to resolve import errors from removed custom types in generation utils
- Add back in generation types #28681
v4.37.0
3 months agoModel releases
Qwen2
Qwen2 is the new model series of large language models from the Qwen team. Previously, the Qwen series was released, including Qwen-72B, Qwen-1.8B, Qwen-VL, Qwen-Audio, etc.
Qwen2 is a language model series including decoder language models of different model sizes. For each size, we release the base language model and the aligned chat model. It is based on the Transformer architecture with SwiGLU activation, attention QKV bias, group query attention, mixture of sliding window attention and full attention, etc. Additionally, we have an improved tokenizer adaptive to multiple natural languages and codes.
- Add qwen2 by @JustinLin610 in #28436
Phi-2
Phi-2 is a transformer language model trained by Microsoft with exceptionally strong performance for its small size of 2.7 billion parameters. It was previously available as a custom code model, but has now been fully integrated into transformers.
- [Phi2] Add support for phi2 models by @susnato in #28211
- [Phi] Extend implementation to use GQA/MQA. by @gugarosa in #28163
- update docs to add the
phi-2example by @susnato in #28392 - Fixes default value of
softmax_scaleinPhiFlashAttention2. by @gugarosa in #28537
SigLIP
The SigLIP model was proposed in Sigmoid Loss for Language Image Pre-Training by Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer. SigLIP proposes to replace the loss function used in CLIP by a simple pairwise sigmoid loss. This results in better performance in terms of zero-shot classification accuracy on ImageNet.
- Add SigLIP by @NielsRogge in #26522
- [SigLIP] Don't pad by default by @NielsRogge in #28578
ViP-LLaVA
The VipLlava model was proposed in Making Large Multimodal Models Understand Arbitrary Visual Prompts by Mu Cai, Haotian Liu, Siva Karthik Mustikovela, Gregory P. Meyer, Yuning Chai, Dennis Park, Yong Jae Lee.
VipLlava enhances the training protocol of Llava by marking images and interact with the model using natural cues like a “red bounding box” or “pointed arrow” during training.
- Adds VIP-llava to transformers by @younesbelkada in #27932
- Fix Vip-llava docs by @younesbelkada in #28085
FastSpeech2Conformer
The FastSpeech2Conformer model was proposed with the paper Recent Developments On Espnet Toolkit Boosted By Conformer by Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang, and Yuekai Zhang.
FastSpeech 2 is a non-autoregressive model for text-to-speech (TTS) synthesis, which develops upon FastSpeech, showing improvements in training speed, inference speed and voice quality. It consists of a variance adapter; duration, energy and pitch predictor and waveform and mel-spectrogram decoder.
- Add FastSpeech2Conformer by @connor-henderson in #23439
Wav2Vec2-BERT
The Wav2Vec2-BERT model was proposed in Seamless: Multilingual Expressive and Streaming Speech Translation by the Seamless Communication team from Meta AI.
This model was pre-trained on 4.5M hours of unlabeled audio data covering more than 143 languages. It requires finetuning to be used for downstream tasks such as Automatic Speech Recognition (ASR), or Audio Classification.
- Add new meta w2v2-conformer BERT-like model by @ylacombe in #28165
- Add w2v2bert to pipeline by @ylacombe in #28585
4-bit serialization
Enables saving and loading transformers models in 4bit formats - you can now push bitsandbytes 4-bit weights on Hugging Face Hub. To save 4-bit models and push them on the hub, simply install the latest bitsandbytes package from pypi pip install -U bitsandbytes, load your model in 4-bit precision and call save_pretrained / push_to_hub. An example repo here
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "facebook/opt-125m"
model = AutoModelForCausalLM.from_pretrained(model_id, load_in_4bit=True)
model.push_to_hub("ybelkada/opt-125m-bnb-4bit")
- [bnb] Let's make serialization of 4bit models possible by @poedator in #26037
- [
Docs] Add 4-bit serialization docs by @younesbelkada in #28182
4D Attention mask
Enable passing in 4D attention masks to models that support it. This is useful for reducing memory footprint of certain generation tasks.
- 4D
attention_masksupport by @poedator in #27539
Improved quantization support
Ability to customise which modules are quantized and which are not.
- [
Awq] Enable the possibility to skip quantization for some target modules by @younesbelkada in #27950 - add
modules_in_block_to_quantizearg in GPTQconfig by @SunMarc in #27956
Added fused modules support
- [docs] Fused AWQ modules by @stevhliu in #27896
- [
Awq] Add llava fused modules support by @younesbelkada in #28239 - [
Mixtral/Awq] Add mixtral fused modules for Awq by @younesbelkada in #28240
SDPA Support for LLaVa, Mixtral, Mistral
- Fix SDPA correctness following torch==2.1.2 regression by @fxmarty in #27973
- [
Llava/Vip-Llava] Add SDPA into llava by @younesbelkada in #28107 - [
Mixtral&Mistral] Add support for sdpa by @ArthurZucker in #28133 - [SDPA] Make sure attn mask creation is always done on CPU by @patrickvonplaten in #28400
- Fix SDPA tests by @fxmarty in #28552
Whisper: Batched state-of-the-art long-form transcription
All decoding strategies (temperature fallback, compression/log-prob/no-speech threshold, ...) of OpenAI's long-form transcription (see: https://github.com/openai/whisper or section 4.5 in paper) have been added. Contrary to https://github.com/openai/whisper, Transformers long-form transcription is fully compatible with pure FP16 and Batching!
For more information see: https://github.com/huggingface/transformers/pull/27658.
- [Whisper] Finalize batched SOTA long-form generation by @patrickvonplaten in #27658
Generation: assisted generation upgrades, speculative decoding, and ngram speculation
Assisted generation was reworked to accept arbitrary sources of candidate sequences. This enabled us to smoothly integrate ngram speculation, and opens the door for new candidate generation methods. Additionally, we've added the speculative decoding strategy on top of assisted generation: when you call assisted generation with an assistant model and do_sample=True, you'll benefit from the faster speculative decoding sampling 🏎️💨
- Generate:
assisted_decodingnow accepts arbitrary candidate generators by @gante in #27751 - Generate: assisted decoding now uses
generatefor the assistant by @gante in #28031 - Generate: speculative decoding by @gante in #27979
- Generate: fix speculative decoding by @gante in #28166
- Adding Prompt lookup decoding by @apoorvumang in #27775
- Fix _speculative_sampling implementation by @ofirzaf in #28508
torch.load pickle protection
Adding pickle protection via weights_only=True in the torch.load calls.
- make torch.load a bit safer by @julien-c in #27282
Build methods for TensorFlow Models
Unlike PyTorch, TensorFlow models build their weights "lazily" after model initialization, using the shape of their inputs to figure out what their weight shapes should be. We previously needed a full forward pass through TF models to ensure that all layers received an input they could use to build their weights, but with this change we now have proper build() methods that can correctly infer shapes and build model weights. This avoids a whole range of potential issues, as well as significantly accelerating model load times.
- Proper build() methods for TF by @Rocketknight1 in #27794
- Replace build() with build_in_name_scope() for some TF tests by @Rocketknight1 in #28046
- More TF fixes by @Rocketknight1 in #28081
- Even more TF test fixes by @Rocketknight1 in #28146
Remove support for torch 1.10
The last version to support PyTorch 1.10 was 4.36.x. As it has been more than 2 years, and we're looking forward to using features available in PyTorch 1.11 and up, we do not support PyTorch 1.10 for v4.37 (i.e. we don't run the tests against torch 1.10).
- Byebye torch 1.10 by @ydshieh in #28207
Model tagging
You can now add custom tags into your model before pushing it on the Hub! This enables you to filter models that contain that tag on the Hub with a simple URL filter. For example if you want to filter models that have trl tag you can search: https://huggingface.co/models?other=trl&sort=created
- [
core/ FEAT] Add the possibility to push custom tags usingPreTrainedModelitself by @younesbelkada in #28405 - e.g.
from transformers import AutoModelForCausalLM
model_name = "HuggingFaceM4/tiny-random-LlamaForCausalLM"
model = AutoModelForCausalLM.from_pretrained(model_name)
model.add_model_tags(["tag-test"])
model.push_to_hub("llama-tagged")
Bugfixes and improvements
- Fix PatchTSMixer Docstrings by @vijaye12 in #27943
- use logger.warning_once to avoid massive outputs by @ranchlai in #27428
- Docs for AutoBackbone & Backbone by @merveenoyan in #27456
- Fix test for auto_find_batch_size on multi-GPU by @muellerzr in #27947
- Update import message by @NielsRogge in #27946
- Fix parameter count in readme for mixtral 45b by @CyberTimon in #27945
- In PreTrainedTokenizerBase add missing word in error message by @petergtz in #27949
- Fix AMD scheduled CI not triggered by @ydshieh in #27951
- Add deepspeed test to amd scheduled CI by @echarlaix in #27633
- Fix a couple of typos and add an illustrative test by @rjenc29 in #26941
- fix bug in mask2former: cost matrix is infeasible by @xuchenhao001 in #27897
- Fix for stochastic depth decay rule in the TimeSformer implementation by @atawari in #27875
- fix no sequence length models error by @AdamLouly in #27522
- [
Mixtral] Change mistral op order by @younesbelkada in #27955 - Update bounding box format everywhere by @NielsRogge in #27944
- Support PeftModel signature inspect by @dancingpipi in #27865
- fixed typos (issue 27919) by @asusevski in #27920
- Hot-fix-mixstral-loss by @ArthurZucker in #27948
- Fix link in README.md of Image Captioning by @saswatmeher in #27969
- Better key error for AutoConfig by @Rocketknight1 in #27976
- [doc] fix typo by @stas00 in #27981
- fix typo in dvclive callback by @dberenbaum in #27983
- [
Tokenizer Serialization] Fix the broken serialisation by @ArthurZucker in #27099 - [
Whisper] raise better errors by @ArthurZucker in #27971 - Fix PatchTSMixer slow tests by @ajati in #27997
- [
CI slow] Fix expected values by @ArthurZucker in #27999 - Fix bug with rotating checkpoints by @muellerzr in #28009
- [Doc] Spanish translation of glossary.md by @aaronjimv in #27958
- Add model_docs from cpmant.md to derformable_detr.md by @rajveer43 in #27884
- well well well by @ArthurZucker in #28011
- [
SeamlessM4TTokenizer] Safe import by @ArthurZucker in #28026 - [
core/modeling] Fix training bug with PEFT + GC by @younesbelkada in #28031 - Fix AMD push CI not triggered by @ydshieh in #28029
- SeamlessM4T:
test_retain_grad_hidden_states_attentionsis flaky by @gante in #28035 - Fix languages covered by M4Tv2 by @ylacombe in #28019
- Fixed spelling error in T5 tokenizer warning message (s/thouroughly/t… by @jeddobson in #28014
- Generate: Mistral/Mixtral FA2 cache fix when going beyond the context window by @gante in #28037
- [Seamless] Fix links in docs by @sanchit-gandhi in #27905
- Remove warning when Annotion enum is created by @amyeroberts in #28048
- [
FA-2] Fix fa-2 issue when passingconfigtofrom_pretrainedby @younesbelkada in #28043 - [
Modeling/Mixtral] Fix GC + PEFT issues with Mixtral by @younesbelkada in #28061 - [Flax BERT] Update deprecated 'split' method by @sanchit-gandhi in #28012
- [Flax LLaMA] Fix attn dropout by @sanchit-gandhi in #28059
- Remove SpeechT5 deprecated argument by @ylacombe in #28062
- doc: Correct spelling mistake by @caiyili in #28064
- [
Mixtral] update conversion script to reflect new changes by @younesbelkada in #28068 - Skip M4T
test_retain_grad_hidden_states_attentionsby @ylacombe in #28060 - [LLaVa] Add past_key_values to _skip_keys_device_placement to fix multi-GPU dispatch by @aismlv in #28051
- Make GPT2 traceable in meta state by @kwen2501 in #28054
- Fix bug for checkpoint saving on multi node training setting by @dumpmemory in #28078
- Update fixtures-image-utils by @lhoestq in #28080
- Fix
low_cpu_mem_usageFlag Conflict with DeepSpeed Zero 3 infrom_pretrainedfor Models withkeep_in_fp32_modules" by @kotarotanahashi in #27762 - Fix wrong examples in llava usage. by @Lyken17 in #28020
- [docs] Trainer by @stevhliu in #27986
- [docs] MPS by @stevhliu in #28016
- fix resuming from ckpt when using FSDP with FULL_STATE_DICT by @pacman100 in #27891
- Fix the deprecation warning of _torch_pytree._register_pytree_node by @cyyever in #27803
- Spelling correction by @saeneas in #28110
- in peft finetune, only the trainable parameters need to be saved by @sywangyi in #27825
- fix ConversationalPipeline docstring by @not-lain in #28091
- Disable jitter noise during evaluation in SwitchTransformers by @DaizeDong in #28077
- Remove warning if
DISABLE_TELEMETRYis used by @Wauplin in #28113 - Fix indentation error - semantic_segmentation.md by @rajveer43 in #28117
- [docs] General doc fixes by @stevhliu in #28087
- Fix a typo in tokenizer documentation by @mssalvatore in #28118
- [Doc] Fix token link in What 🤗 Transformers can do by @aaronjimv in #28123
- When save a model on TPU, make a copy to be moved to CPU by @qihqi in #27993
- Update split string in doctest to reflect #28087 by @amyeroberts in #28135
- [
Mixtral] Fix loss + nits by @ArthurZucker in #28115 - Update modeling_utils.py by @mzelling in #28127
- [docs] Fix mistral link in mixtral.md by @aaronjimv in #28143
- Remove deprecated CPU dockerfiles by @ashahba in #28149
- Fix FA2 integration by @pacman100 in #28142
- [gpt-neox] Add attention_bias config to support model trained without attention biases by @dalgarak in #28126
- move code to Trainer.evaluate to enable use of that function with multiple datasets by @peter-sk in #27844
- Fix weights not properly initialized due to shape mismatch by @ydshieh in #28122
- Avoid unnecessary warnings when loading
CLIPConfigby @ydshieh in #28108 - Update FA2 exception msg to point to hub discussions by @amyeroberts in #28161
- Align backbone stage selection with out_indices & out_features by @amyeroberts in #27606
- [docs] Trainer docs by @stevhliu in #28145
- Fix yolos resizing by @amyeroberts in #27663
- disable test_retain_grad_hidden_states_attentions on SeamlessM4TModelWithTextInputTest by @dwyatte in #28169
- Fix
input_embedsdocstring in encoder-decoder architectures by @gante in #28168 - [Whisper] Use torch for stft if available by @sanchit-gandhi in #26119
- Fix slow backbone tests - out_indices must match stage name ordering by @amyeroberts in #28186
- Update YOLOS slow test values by @amyeroberts in #28187
- Update
docs/source/en/perf_infer_gpu_one.mdby @ydshieh in #28198 - Fix ONNX export for causal LM sequence classifiers by removing reverse indexing by @dwyatte in #28144
- Add Swinv2 backbone by @NielsRogge in #27742
- Fix: [SeamlessM4T - S2TT] Bug in batch loading of audio in torch.Tensor format in the SeamlessM4TFeatureExtractor class by @nicholasneo78 in #27914
- Bug:
training_args.pyfix missing import with accelerate with versionaccelerate==0.20.1by @michaelfeil in #28171 - Fix the check of models supporting FA/SDPA not run by @ydshieh in #28202
- Drop
feature_extractor_typewhen loading an image processor file by @ydshieh in #28195 - [Whisper] Fix word-level timestamps with bs>1 or num_beams>1 by @ylacombe in #28114
- Fixing visualization code for object detection to support both types of bounding box. by @Anindyadeep in #27842
- update the logger message with accordant weights_file_name by @izyForever in #28181
- [
Llava] Fix llava index errors by @younesbelkada in #28032 - fix FA2 when using quantization by @pacman100 in #28203
- small typo by @stas00 in #28229
- Update docs around mixing hf scheduler with deepspeed optimizer by @dwyatte in #28223
- Fix trainer saving safetensors: metadata is None by @hiyouga in #28219
- fix bug:divide by zero in _maybe_log_save_evaluate() by @frankenliu in #28251
- [Whisper] Fix errors with MPS backend introduced by new code on word-level timestamps computation by @ercaronte in #28288
- Remove fast tokenization warning in Data Collators by @dbuos in #28213
- fix documentation for zero_shot_object_detection by @not-lain in #28267
- Remove token_type_ids from model_input_names (like #24788) by @Apsod in #28325
- Translate contributing.md into Chinese by @Mayfsz in #28243
- [docs] Sort es/toctree.yml | Translate performance.md by @aaronjimv in #28262
- Fix error in M4T feature extractor by @ylacombe in #28340
- README: install transformers from conda-forge channel by @kevherro in #28313
- Don't check the device when device_map=auto by @yuanwu2017 in #28351
- Fix pos_mask application and update tests accordingly by @ferjorosa in #27892
- fix FA2 when using quantization for remaining models by @susnato in #28341
- Update VITS modeling to enable ONNX export by @echarlaix in #28141
- chore: Fix typo s/exclusivelly/exclusively/ by @hugo-syn in #28361
- Enhancing Code Readability and Maintainability with Simplified Activation Function Selection. by @hi-sushanta in #28349
- Fix building alibi tensor when num_heads is not a power of 2 by @abuelnasr0 in #28380
- remove two deprecated function by @statelesshz in #28220
- Bugfix / ffmpeg input device (mic) not working on Windows by @Teapack1 in #27051
- [AttentionMaskConverter] fix sdpa unmask unattended by @zspo in #28369
- Remove shell=True from subprocess.Popen to Mitigate Security Risk by @avimanyu786 in #28299
- Add segmentation map processing to SAM Image Processor by @rwood-97 in #27463
- update warning for image processor loading by @ydshieh in #28209
- Fix initialization for missing parameters in
from_pretrainedunder ZeRO-3 by @XuehaiPan in #28245 - Fix
_merge_input_ids_with_image_featuresfor llava model by @VictorSanh in #28333 - Use mmap option to load_state_dict by @weimingzha0 in #28331
- [BUG] BarkEosPrioritizerLogitsProcessor eos_token_id use list, tensor size mismatch by @inkinworld in #28201
- Skip now failing test in the Trainer tests by @muellerzr in #28421
- Support
DeepSpeedwhen using auto find batch size by @muellerzr in #28088 - Fix number of models in README.md by @prasatee in #28430
- CI: limit natten version by @gante in #28432
- Fix for checkpoint rename race condition by @tblattner in #28364
- Fix load correct tokenizer in Mixtral model documentation by @JuanFKurucz in #28437
- [docstring] Fix docstring for ErnieConfig, ErnieMConfig by @Sparty in #27029
- [Whisper] Fix slow test by @patrickvonplaten in #28407
- Assitant model may on a different device by @jiqing-feng in #27995
- Enable multi-label image classification in pipeline by @amyeroberts in #28433
- Optimize the speed of the truncate_sequences function. by @ikkvix in #28263
- Use python 3.10 for docbuild by @ydshieh in #28399
- Fix docker file by @ydshieh in #28452
- Set
cache_dirforevaluate.load()in example scripts by @aphedges in #28422 - Optionally preprocess segmentation maps for MobileViT by @harisankar95 in #28420
- Correctly resolve trust_remote_code=None for AutoTokenizer by @Rocketknight1 in #28419
- Fix load balancing loss func for mixtral by @liangxuZhang in #28256
- Doc by @jiqing-feng in #28431
- Fix docstring checker issues with PIL enums by @Rocketknight1 in #28450
- Fix broken link on page by @keenranger in #28451
- Mark two logger tests as flaky by @amyeroberts in #28458
- Update metadata loading for oneformer by @amyeroberts in #28398
- Fix torch.ones usage in xlnet by @sungho-ham in #28471
- Generate: deprecate old public functions by @gante in #28478
- Docs: add model paths by @gante in #28475
- Generate: refuse to save bad generation config files by @gante in #28477
- TF: purge
TFTrainerby @gante in #28483 - Fix docstrings and update docstring checker error message by @Rocketknight1 in #28460
- Change progress logging to once across all nodes by @siddartha-RE in #28373
- Generate: fix candidate device placement by @gante in #28493
- Fix paths to AI Sweden Models reference and model loading by @JuanFKurucz in #28423
- [
chore] Update warning text, a word was missing by @tomaarsen in #28017 - Don't set
finetuned_fromif it is a local path by @ydshieh in #28482 - Add the XPU device check for pipeline mode by @yuanwu2017 in #28326
- Tokenizer kwargs in textgeneration pipe by @thedamnedrhino in #28362
- [GPTQ] Fix test by @SunMarc in #28018
- Fixed minor typos by @rishit5 in #28489
- Add a use_safetensors arg to TFPreTrainedModel.from_pretrained() by @Rocketknight1 in #28511
- Generate: consolidate output classes by @gante in #28494
- fix: sampling in flax keeps EOS by @borisdayma in #28378
- improve dev setup comments and hints by @4imothy in #28495
- SiLU activation wrapper for safe importing by @amyeroberts in #28509
- Remove
taskarg inload_datasetin image-classification example by @regisss in #28408 - Improving Training Performance and Scalability Documentation by @HamzaFB in #28497
- Fix mismatching loading in from_pretrained with/without accelerate by @fxmarty in #28414
- Fix/speecht5 bug by @NimaYaqmuri in #28481
- [
TokenizationUtils] Fixadd_special_tokenswhen the token is already there by @ArthurZucker in #28520 - [
TokenizationRoformerFast] Fix the save and loading by @ArthurZucker in #28527 - [
SpeechT5Tokenization] Add copied from and fix theconvert_tokens_to_stringto match the fast decoding scheme by @ArthurZucker in #28522 - Clearer error for SDPA when explicitely requested by @fxmarty in #28006
- Add is_model_supported for fx by @inisis in #28521
- Config: warning when saving generation kwargs in the model config by @gante in #28514
- [Makefile] Exclude research projects from format by @patrickvonplaten in #28551
- symbolic_trace: add past_key_values, llama, sdpa support by @fxmarty in #28447
- Allow to train dinov2 with different dtypes like bf16 by @StarCycle in #28504
- Fix Switch Transformers When sparse_step = 1 by @agemagician in #28564
- Save
Processorby @ydshieh in #27761 - Use
weights_onlyonly if torch >= 1.13 by @ydshieh in #28506 - [
Core Tokenization] Support a fix for spm fast models by @ArthurZucker in #26678 - Use
LoggingLevelcontext manager in 3 tests by @ydshieh in #28575 - Fix the documentation checkpoint for xlm-roberta-xl by @jeremyfowers in #28567
- [ASR Pipe] Update init to set model type and subsequently call parent init method by @sanchit-gandhi in #28486
- [Whisper Tok] Move token ids to CPU when computing offsets by @sanchit-gandhi in #28485
- [Whisper] Fix audio classification with weighted layer sum by @sanchit-gandhi in #28563
- Making CTC training example more general by @ylacombe in #28582
- Don't save
processor_config.jsonif a processor has no extra attribute by @ydshieh in #28584 - Fix wrong xpu device in DistributedType.MULTI_XPU mode by @faaany in #28386
- [GPTNeoX] Fix BC issue with 4.36 by @ArthurZucker in #28602
Significant community contributions
The following contributors have made significant changes to the library over the last release:
- @aaronjimv
- [Doc] Spanish translation of glossary.md (#27958)
- [Doc] Fix token link in What 🤗 Transformers can do (#28123)
- [docs] Fix mistral link in mixtral.md (#28143)
- [docs] Sort es/toctree.yml | Translate performance.md (#28262)
- @rajveer43
- Add model_docs from cpmant.md to derformable_detr.md (#27884)
- Fix indentation error - semantic_segmentation.md (#28117)
- @poedator
- 4D
attention_masksupport (#27539) - [bnb] Let's make serialization of 4bit models possible (#26037)
- 4D
- @connor-henderson
- Add FastSpeech2Conformer (#23439)
- @JustinLin610
- Add qwen2 (#28436)
- @SangbumChoi
- enable training mask2former and maskformer for transformers trainer by @SangbumChoi in #28277
- [DETA] Improvement and Sync from DETA especially for training by @SangbumChoi in #27990
- fix auxiliary loss training in DetrSegmentation by @SangbumChoi in #28354
v4.36.2
4 months agoPatch release to resolve some critical issues relating to the recent cache refactor, flash attention refactor and training in the multi-gpu and multi-node settings:
- Resolve training bug with PEFT + GC #28031
- Resolve cache issue when going beyond context window for Mistral/Mixtral FA2 #28037
- Re-enable passing
configtofrom_pretrainedwith FA #28043 - Fix resuming from checkpoint when using FDSP with FULL_STATE_DICT #27891
- Resolve bug when saving a checkpoint in the multi-node setting #28078
v4.36.1
4 months agoA patch release for critical torch issues mostly:
- Fix SDPA correctness following torch==2.1.2 regression #27973
- [Tokenizer Serialization] Fix the broken serialisation #27099
- Fix bug with rotating checkpoints #28009
- Hot-fix-mixstral-loss (#27948)
🔥
v4.36.0
4 months agoNew model additions
Mixtral
Mixtral is the new open-source model from Mistral AI announced by the blogpost Mixtral of Experts. The model has been proven to have comparable capabilities to Chat-GPT according to the benchmark results shared on the release blogpost.
The architecture is a sparse Mixture of Experts with Top-2 routing strategy, similar as NllbMoe architecture in transformers. You can use it through AutoModelForCausalLM interface:
>>> import torch
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mixtral-8x7B", torch_dtype=torch.float16, device_map="auto")
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-8x7B")
>>> prompt = "My favourite condiment is"
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(device)
>>> model.to(device)
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=100, do_sample=True)
>>> tokenizer.batch_decode(generated_ids)[0]
The model is compatible with existing optimisation tools such Flash Attention 2, bitsandbytes and PEFT library. The checkpoints are release under mistralai organisation on the Hugging Face Hub.
Llava / BakLlava
Llava is an open-source chatbot trained by fine-tuning LlamA/Vicuna on GPT-generated multimodal instruction-following data. It is an auto-regressive language model, based on the transformer architecture. In other words, it is an multi-modal version of LLMs fine-tuned for chat / instructions.

The Llava model was proposed in Improved Baselines with Visual Instruction Tuning by Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee.
- [
Llava] Add Llava to transformers by @younesbelkada in #27662 - [LLaVa] Some improvements by @NielsRogge in #27895
The integration also includes BakLlava which is a Llava model trained with Mistral backbone.
The mode is compatible with "image-to-text" pipeline:
from transformers import pipeline
from PIL import Image
import requests
model_id = "llava-hf/llava-1.5-7b-hf"
pipe = pipeline("image-to-text", model=model_id)
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/ai2d-demo.jpg"
image = Image.open(requests.get(url, stream=True).raw)
prompt = "USER: <image>\nWhat does the label 15 represent? (1) lava (2) core (3) tunnel (4) ash cloud\nASSISTANT:"
outputs = pipe(image, prompt=prompt, generate_kwargs={"max_new_tokens": 200})
print(outputs)
And you can find all Llava weights under llava-hf organisation on the Hub.
SeamlessM4T v2
SeamlessM4T-v2 is a collection of models designed to provide high quality translation, allowing people from different linguistic communities to communicate effortlessly through speech and text. It is an improvement on the previous version and was proposed in Seamless: Multilingual Expressive and Streaming Speech Translation by the Seamless Communication team from Meta AI.
For more details on the differences between v1 and v2, refer to section Difference with SeamlessM4T-v1.
SeamlessM4T enables multiple tasks without relying on separate models:
- Speech-to-speech translation (S2ST)
- Speech-to-text translation (S2TT)
- Text-to-speech translation (T2ST)
- Text-to-text translation (T2TT)
- Automatic speech recognition (ASR)
- Add SeamlessM4T v2 by @ylacombe in #27779
PatchTST
The PatchTST model was proposed in A Time Series is Worth 64 Words: Long-term Forecasting with Transformers by Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong and Jayant Kalagnanam.
At a high level, the model vectorizes time series into patches of a given size and encodes the resulting sequence of vectors via a Transformer that then outputs the prediction length forecast via an appropriate head. The model is illustrated in the following figure:
- [Time series] Add PatchTST by @psinthong in #25927
- [Time series] Add PatchTST by @kashif in #27581
PatchTSMixer
The PatchTSMixer model was proposed in TSMixer: Lightweight MLP-Mixer Model for Multivariate Time Series Forecasting by Vijay Ekambaram, Arindam Jati, Nam Nguyen, Phanwadee Sinthong and Jayant Kalagnanam.
PatchTSMixer is a lightweight time-series modeling approach based on the MLP-Mixer architecture. In this HuggingFace implementation, we provide PatchTSMixer’s capabilities to effortlessly facilitate lightweight mixing across patches, channels, and hidden features for effective multivariate time-series modeling. It also supports various attention mechanisms starting from simple gated attention to more complex self-attention blocks that can be customized accordingly. The model can be pretrained and subsequently used for various downstream tasks such as forecasting, classification and regression.
- [Time series] Add PatchTSMixer by @ajati in #26247
CLVP
The CLVP (Contrastive Language-Voice Pretrained Transformer) model was proposed in Better speech synthesis through scaling by James Betker.
- Add CLVP by @susnato in #24745
Phi-1/1.5
The Phi-1 model was proposed in Textbooks Are All You Need by Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, Adil Salim, Shital Shah, Harkirat Singh Behl, Xin Wang, Sébastien Bubeck, Ronen Eldan, Adam Tauman Kalai, Yin Tat Lee and Yuanzhi Li.
The Phi-1.5 model was proposed in Textbooks Are All You Need II: phi-1.5 technical report by Yuanzhi Li, Sébastien Bubeck, Ronen Eldan, Allie Del Giorno, Suriya Gunasekar and Yin Tat Lee.
- Add Phi-1 and Phi-1_5 by @susnato in #26170
TVP
The text-visual prompting (TVP) framework was proposed in the paper Text-Visual Prompting for Efficient 2D Temporal Video Grounding by Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding.
This research addresses temporal video grounding (TVG), which is the process of pinpointing the start and end times of specific events in a long video, as described by a text sentence. Text-visual prompting (TVP), is proposed to enhance TVG. TVP involves integrating specially designed patterns, known as ‘prompts’, into both the visual (image-based) and textual (word-based) input components of a TVG model. These prompts provide additional spatial-temporal context, improving the model’s ability to accurately determine event timings in the video. The approach employs 2D visual inputs in place of 3D ones. Although 3D inputs offer more spatial-temporal detail, they are also more time-consuming to process. The use of 2D inputs with the prompting method aims to provide similar levels of context and accuracy more efficiently.
- TVP model by @jiqing-feng in #25856
DINOv2 depth estimation
Depth estimation is added to the DINO v2 implementation.
- Add DINOv2 depth estimation by @NielsRogge in #26092
ROCm support for AMD GPUs
AMD's ROCm GPU architecture is now supported across the board and fully tested in our CI with MI210/MI250 GPUs. We further enable specific hardware acceleration for ROCm in Transformers, such as Flash Attention 2, GPTQ quantization and DeepSpeed.
- Add RoCm scheduled CI & upgrade RoCm CI to PyTorch 2.1 by @fxmarty in #26940
- Flash Attention 2 support for RoCm by @fxmarty in #27611
- Reflect RoCm support in the documentation by @fxmarty in #27636
- restructure AMD scheduled CI by @ydshieh in #27743
PyTorch scaled_dot_product_attention native support
PyTorch's torch.nn.functional.scaled_dot_product_attention operator is now supported in the most-used Transformers models and used by default when using torch>=2.1.1, allowing to dispatch on memory-efficient attention and Flash Attention backend implementations with no other package than torch required. This should significantly speed up attention computation on hardware that that supports these fastpath.
While Transformers automatically handles the dispatch to use SDPA when available, it is possible to force the usage of a given attention implementation ("eager" being the manual implementation, where each operation is implemented step by step):
# or `attn_implementation="sdpa", or `attn_implementation="flash_attention_2"`
model = AutoModelForSpeechSeq2Seq.from_pretrained("openai/whisper-tiny", attn_implementation="eager")
Training benchmark, run on A100-SXM4-80GB.
| Model | Batch size | Sequence length | Time per batch ("eager", s) |
Time per batch ("sdpa", s) |
Speedup | Peak memory ("eager", MB) |
Peak memory ("sdpa", MB) |
Memory savings |
|---|---|---|---|---|---|---|---|---|
| llama2 7b | 4 | 1024 | 1.065 | 0.90 | 19.4% | 73878.28 | 45977.81 | 60.7% |
| llama2 7b | 4 | 2048 | OOM | 1.87 | / | OOM | 78394.58 | SDPA does not OOM |
| llama2 7b | 1 | 2048 | 0.64 | 0.48 | 32.0% | 55557.01 | 29795.63 | 86.4% |
| llama2 7b | 1 | 3072 | OOM | 0.75 | / | OOM | 37916.08 | SDPA does not OOM |
| llama2 7b | 1 | 4096 | OOM | 1.03 | / | OOM | 46028.14 | SDPA does not OOM |
| llama2 7b | 2 | 4096 | OOM | 2.05 | / | OOM | 78428.14 | SDPA does not OOM |
Inference benchmark, run on A100-SXM4-80GB.
| Model | Batch size | Prompt length | Num new tokens | Per token latency "eager" (ms) |
Per token latency "sdpa" (ms) |
Speedup |
|---|---|---|---|---|---|---|
| llama2 13b | 1 | 1024 | 1 (prefill) | 178.66 | 159.36 | 12.11% |
| llama2 13b | 1 | 100 | 100 | 40.35 | 37.62 | 7.28% |
| llama2 13b | 8 | 100 | 100 | 40.55 | 38.06 | 6.53% |
| Whisper v3 large | 1 | / | 62 | 20.05 | 18.90 | 6.10% |
| Whisper v3 large | 8 | / | 77 | 25.42 | 24.77 | 2.59% |
| Whisper v3 large | 16 | / | 77 | 28.51 | 26.32 | 8.34% |
- F.scaled_dot_product_attention support by @fxmarty in #26572
New Cache abstraction & Attention Sinks support
We are rolling out a new abstraction for the past_key_values cache, which enables the use of different types of caches. For now, only llama and llama-inspired architectures (mistral, persimmon, phi) support it, with other architectures scheduled to have support in the next release. By default, a growing cache (DynamicCache) is used, which preserves the existing behavior.
This release also includes a new SinkCache cache, which implements the Attention Sinks paper. With SinkCache, the model is able to continue generating high-quality text well beyond its training sequence length! Note that it does not expand the context window, so it can’t digest very long inputs — it is suited for streaming applications such as multi-round dialogues. Check this colab for an example.
- Generate: New
Cacheabstraction and Attention Sinks support by @tomaarsen in #26681 - Generate: SinkCache can handle iterative prompts by @gante in #27907
Safetensors as a default
We continue toggling features enabling safetensors as a default across the board, in PyTorch, Flax, and TensorFlow.
When using PyTorch model and forcing the load of safetensors file with use_safetensors=True, if the repository does not contain the safetensors files, they will now be converted on-the-fly server-side.
- Default to msgpack for safetensors by @LysandreJik in #27460
- Fix
from_ptflag when loading withsafetensorsby @LysandreJik in #27394 - Make using safetensors files automated. by @Narsil in #27571
Breaking changes
pickle files
We now disallow the use of pickle.load internally for security purposes. To circumvent this, you can use the TRUST_REMOTE_CODE=True command to indicate that you would still like to load it.
- 🚨🚨🚨 Disallow
pickle.loadunlessTRUST_REMOTE_CODE=Trueby @ydshieh in #27776
Beam score calculation for decoder-only models
In the previous implementation of beam search, when length_penalty is active, the beam score for decoder-only models was penalized by the total length of both prompt and generated sequence. However, the length of prompt should not be included in the penalization step -- this release fixes it.
- 🚨🚨 Fix beam score calculation issue for decoder-only models by @VsonicV in #27351
- Fix remaining issues in beam score calculation by @VsonicV in #27808
- Fix beam score calculation issue for Tensorflow version by @VsonicV in #27814
- Fix beam score calculation issue for JAX version by @VsonicV in #27816
Slight API changes/corrections
- ⚠️ [VitDet] Fix test by @NielsRogge in #27832
- [⚠️ removed a default argument] Make
AttentionMaskConvertercompatible withtorch.compile(..., fullgraph=True)by @fxmarty in #27868
Bugfixes and improvements
- Enrich TTS pipeline parameters naming by @ylacombe in #26473
- translate peft.md to chinese by @jiaqiw09 in #27215
- Removed the redundant SiLUActivation class. by @hi-sushanta in #27136
- Fixed base model class name extraction from PeftModels by @kkteru in #27162
- Fuyu protection by @LysandreJik in #27248
- Refactor: Use Llama RoPE implementation for Falcon by @tomaarsen in #26933
- [
PEFT/Tests] Fix peft integration failing tests by @younesbelkada in #27258 - Avoid many failing tests in doctesting by @ydshieh in #27262
- [docs] Custom model doc update by @MKhalusova in #27213
- Update the ConversationalPipeline docstring for chat templates by @Rocketknight1 in #27250
- Fix switch transformer mixed precision issue by @timlee0212 in #27220
- [
Docs/SAM] Reflect correct changes to run inference without OOM by @younesbelkada in #27268 - [Docs] Model_doc structure/clarity improvements by @MKhalusova in #26876
- [
FA2] Add flash attention for forDistilBertby @susnato in #26489 - translate autoclass_tutorial to chinese by @jiaqiw09 in #27269
- translate run_scripts.md to chinese by @jiaqiw09 in #27246
- Fix tokenizer export for LLamaTokenizerFast by @mayank31398 in #27222
- Fix daily CI image build by @ydshieh in #27307
- Update doctest workflow file by @ydshieh in #27306
- Remove an unexpected argument for FlaxResNetBasicLayerCollection by @pingzhili in #27272
- enable memory tracker metrics for npu by @statelesshz in #27280
- [
PretrainedTokenizer] add some of the most important functions to the doc by @ArthurZucker in #27313 - Update sequence_classification.md by @akshayvkt in #27281
- Fix VideoMAEforPretrained dtype error by @ikergarcia1996 in #27296
- Fix
Kosmos2Processorbatch mode by @ydshieh in #27323 - [docs] fixed links with 404 by @MKhalusova in #27327
- [Whisper] Block language/task args for English-only by @sanchit-gandhi in #27322
- Fix autoawq docker image by @younesbelkada in #27339
- Generate: skip tests on unsupported models instead of passing by @gante in #27265
- Fix Whisper Conversion Script: Correct decoder_attention_heads and _download function by @zuazo in #26834
- [
FA2] Add flash attention forGPT-Neoby @susnato in #26486 - [
Whisper] Add conversion script for the tokenizer by @ArthurZucker in #27338 - Remove a redundant variable. by @hi-sushanta in #27288
- Resolve AttributeError by utilizing device calculation at the start of the forward function by @folbaeni in #27347
- Remove padding_masks from
gpt_bigcode. by @susnato in #27348 - [
Whisper] Nit converting the tokenizer by @ArthurZucker in #27349 - FIx Bark batching feature by @ylacombe in #27271
- Allow scheduler parameters by @Plemeur in #26480
- translate the en tokenizer_summary.md to Chinese by @ZouJiu1 in #27291
- translate model_sharing.md and llm_tutorial.md to chinese by @jiaqiw09 in #27283
- Add numpy alternative to FE using torchaudio by @ylacombe in #26339
- moving example of benchmarking to legacy dir by @statelesshz in #27337
- Fix example tests from failing by @muellerzr in #27353
- Fix
Kosmos-2device issue by @ydshieh in #27346 - MusicGen Update by @sanchit-gandhi in #27084
- Translate index.md to Turkish by @mertyyanik in #27093
- Remove unused param from example script tests by @muellerzr in #27354
- [Flax Whisper] large-v3 compatibility by @sanchit-gandhi in #27360
- Fix tiny model script: not using
from_pt=Trueby @ydshieh in #27372 - translate big_models.md and performance.md to chinese by @jiaqiw09 in #27334
- Add Flash Attention 2 support to Bark by @ylacombe in #27364
- Update deprecated
torch.rangeintest_modeling_ibert.pyby @kit1980 in #27355 - translate debugging.md to chinese by @jiaqiw09 in #27374
- Smangrul/fix failing ds ci tests by @pacman100 in #27358
- [
CodeLlamaTokenizer] Nit, update init to make sure the AddedTokens are not normalized because they are special by @ArthurZucker in #27359 - Change thresh in test by @muellerzr in #27378
- Put doctest options back to
pyproject.tomlby @ydshieh in #27366 - Skip failing cache call tests by @amyeroberts in #27393
- device-agnostic deepspeed testing by @statelesshz in #27342
- Adds dvclive callback by @dberenbaum in #27352
- use
pytest.markdirectly by @ydshieh in #27390 - Fix fuyu checkpoint repo in
FuyuConfigby @ydshieh in #27399 - Use editable install for git deps by @muellerzr in #27404
- Final fix of the accelerate installation issue by @ydshieh in #27408
- Fix RequestCounter to make it more future-proof by @Wauplin in #27406
- remove failing tests and clean FE files by @ylacombe in #27414
- Fix
Owlv2checkpoint name and a default value inOwlv2VisionConfigby @ydshieh in #27402 - Run all tests if
circleci/create_circleci_config.pyis modified by @ydshieh in #27413 - add attention_mask and position_ids in assisted model by @jiqing-feng in #26892
- [
Quantization] Add str to enum conversion for AWQ by @younesbelkada in #27320 - update Bark FA2 docs by @ylacombe in #27400
- [
AttentionMaskConverter] ]Fix-mask-inf by @ArthurZucker in #27114 - At most 2 GPUs for CI by @ydshieh in #27435
- Normalize floating point cast by @amyeroberts in #27249
- Make
examples_torch_jobfaster by @ydshieh in #27437 - Fix line ending in
utils/not_doctested.txtby @ydshieh in #27459 - Fix some Wav2Vec2 related models' doctest by @ydshieh in #27462
- Fixed typo in error message by @cmcmaster1 in #27461
- Remove-auth-token by @ArthurZucker in #27060
- [
Llama + Mistral] Add attention dropout by @ArthurZucker in #27315 - OWLv2: bug fix in post_process_object_detection() when using cuda device by @assafbot in #27468
- Fix docstring for
gradient_checkpointing_kwargsby @tomaszcichy98 in #27470 - Install
python-Levenshteinfornougatin CI image by @ydshieh in #27465 - Add version check for Jinja by @Rocketknight1 in #27403
- Fix Falcon tokenizer loading in pipeline by @Rocketknight1 in #27316
- [
AWQ] Addresses TODO for awq tests by @younesbelkada in #27467 - Perf torch compile by @jiaqiw09 in #27422
- Fixed typo in pipelines.md documentation by @adismort14 in #27455
- Fix FA2 import + deprecation cycle by @SunMarc in #27330
- [
Peft]modules_to_savesupport for peft integration by @younesbelkada in #27466 - [
CI-test_torch] skiptest_tf_from_pt_safetensorsfor 4 models by @ArthurZucker in #27481 - Fix M4T weights tying by @ylacombe in #27395
- Add speecht5 batch generation and fix wrong attention mask when padding by @Spycsh in #25943
- Clap processor: remove wasteful np.stack operations by @m-bain in #27454
- [Whisper] Fix pipeline test by @sanchit-gandhi in #27442
- Revert "[time series] Add PatchTST by @amyeroberts in #25927)"
- translate hpo_train.md and perf_hardware.md to chinese by @jiaqiw09 in #27431
- Generate: fix
ExponentialDecayLengthPenaltydoctest by @gante in #27485 - Update and reorder docs for chat templates by @Rocketknight1 in #27443
- Generate:
GenerationConfig.from_pretrainedcan return unused kwargs by @gante in #27488 - Minor type annotation fix by @vwxyzjn in #27276
- Have seq2seq just use gather by @muellerzr in #27025
- Update processor mapping for hub snippets by @amyeroberts in #27477
- Track the number of tokens seen to metrics by @muellerzr in #27274
- [
CI-test_torch] skip test_tf_from_pt_safetensors andtest_assisted_decoding_sampleby @ArthurZucker in #27508 - [Fuyu] Add tests by @NielsRogge in #27001
- [Table Transformer] Add Transformers-native checkpoints by @NielsRogge in #26928
- Update spelling mistake by @LimJing7 in #27506
- [
CircleCI] skip test_assisted_decoding_sample for everyone by @ArthurZucker in #27511 - Make some jobs run on the GitHub Actions runners by @ydshieh in #27512
- [
tokenizers] updatetokenizersversion pin by @ArthurZucker in #27494 - [
PretrainedConfig] Improve messaging by @ArthurZucker in #27438 - Fix wav2vec2 params by @muellerzr in #27515
- Translating
en/model_docdocs to Japanese. by @Yuki-Imajuku in #27401 - Fixing the failure of models without max_position_embeddings attribute. by @AdamLouly in #27499
- Incorrect setting for num_beams in translation and summarization examples by @Rocketknight1 in #27519
- Fix bug for T5x to PyTorch convert script with varying encoder and decoder layers by @JamesJiang97 in #27448
- Fix offload disk for loading derivated model checkpoint into base model by @SunMarc in #27253
- translate model.md to chinese by @statelesshz in #27518
- Support ONNX export for causal LM sequence classifiers by @dwyatte in #27450
- [
pytest] Avoid flash attn test marker warning by @ArthurZucker in #27509 - docs: add docs for map, and add num procs to load_dataset by @pphuc25 in #27520
- Update the TF pin for 2.15 by @Rocketknight1 in #27375
- Revert "add attention_mask and position_ids in assisted model" by @patrickvonplaten in #27523
- Set
usedforsecurity=Falsein hashlib methods (FIPS compliance) by @Wauplin in #27483 - Raise error when quantizing a quantized model by @SunMarc in #27500
- Disable docker image build job
latest-pytorch-amdfor now by @ydshieh in #27541 - [
Styling] stylify using ruff by @ArthurZucker in #27144 - Generate: improve assisted generation tests by @gante in #27540
- Updated albert.md doc for ALBERT model by @ENate in #27223
- translate Trainer.md to chinese by @jiaqiw09 in #27527
- Skip some fuyu tests by @ydshieh in #27553
- Fix AMD CI not showing GPU by @ydshieh in #27555
- Generate: fix flaky tests by @gante in #27543
- Generate: update compute transition scores doctest by @gante in #27558
- fixed broken link by @VpkPrasanna in #27560
- Broken links fixed related to datasets docs by @VpkPrasanna in #27569
- translate deepspeed.md to chinese by @jiaqiw09 in #27495
- Fix broken distilbert url by @osanseviero in #27579
- Adding leaky relu in dict ACT2CLS by @rafaelpadilla in #27574
- Fix idx2sym not loaded from pretrained vocab file in Transformer XL by @jtang98 in #27589
- Add
convert_hf_to_openai.pyscript to Whisper documentation resources by @zuazo in #27590 - docs: fix 404 link by @panpan0000 in #27529
- [ examples] fix loading jsonl with load dataset in run translation example by @mathiasesn in #26924
- [
FA-2] Add fa2 support forfrom_configby @younesbelkada in #26914 - timm to pytorch conversion for vit model fix by @staghado in #26908
- [Whisper] Add
large-v3version support by @flyingleafe in #27336 - Update Korean tutorial for using LLMs, and refactor the nested conditional statements in hr_argparser.py by @YeonwooSung in #27489
- Fix torch.fx import issue for torch 1.12 by @amyeroberts in #27570
- dvclive callback: warn instead of fail when logging non-scalars by @dberenbaum in #27608
- [
core/gradient_checkpointing] add support for old GC method by @younesbelkada in #27610 - [ConvNext] Improve backbone by @NielsRogge in #27621
- Generate: Update docs regarding reusing
past_key_valuesingenerateby @gante in #27612 - Idefics: Fix information leak with cross attention gate in modeling by @leot13 in #26839
- Fix flash attention bugs with Mistral and Falcon by @fxmarty in #27625
- Fix tracing dinov2 by @amyeroberts in #27561
- remove the deprecated method
init_git_repoby @statelesshz in #27617 - Explicitely specify
use_cache=Truein Flash Attention tests by @fxmarty in #27635 - Harmonize HF environment variables + other cleaning by @Wauplin in #27564
- Fix
resize_token_embeddingsby @czy-orange in #26861) - [
dependency] update pillow pins by @ArthurZucker in #27409 - Simplify the implementation of jitter noise in moe models by @jiangwangyi in #27643
- Fix
max_stepsdocumentation regarding the end-of-training condition by @qgallouedec in #27624 - [Whisper] Add sequential longform decoding by @patrickvonplaten in #27492
- Add UnivNet Vocoder Model for Tortoise TTS Diffusers Integration by @dg845 in #24799
- update Openai API call method by @Strive-for-excellence in #27628
- update d_kv'annotation in mt5'configuration by @callanwu in #27585
- [
FA2] Add flash attention for opt by @susnato in #26414 - Extended semantic segmentation to image segmentation by @merveenoyan in #27039
- Update TVP arxiv link by @amyeroberts in #27672
- [DPT, Dinov2] Add resources by @NielsRogge in #27655
- Update tiny model summary file by @ydshieh in #27388
- Refactoring Trainer, adds
save_only_modelarg and simplifying FSDP integration by @pacman100 in #27652 - Skip pipeline tests for 2 models for now by @ydshieh in #27687
- Deprecate
TransfoXLby @ydshieh in #27607 - Fix typo in warning message by @liuxueyang in #27055
- Docs/Add conversion code to the musicgen docs by @yoinked-h in #27665
- Fix semantic error in evaluation section by @anihm136 in #27675
- [
DocString] Support a revision in the docstringadd_code_sample_docstringsto facilitate integrations by @ArthurZucker in #27645 - Successfully Resolved The ZeroDivisionError Exception. by @hi-sushanta in #27524
- Fix
TVPModelTestby @ydshieh in #27695 - Fix sliding_window hasattr in Mistral by @IlyaGusev in #27041
- Fix Past CI by @ydshieh in #27696
- fix warning by @ArthurZucker in #27689
- Reorder the code on the Hub to explicit that sharing on the Hub isn't a requirement by @LysandreJik in #27691
- Fix mistral generate for long prompt / response by @lorabit110 in #27548
- Fix oneformer instance segmentation RuntimeError by @yhshin11 in #27725
- fix assisted decoding assistant model inputs by @jiqing-feng in #27503
- Update forward signature test for vision models by @NielsRogge in #27681
- Modify group_sub_entities in TokenClassification Pipeline to support label with "-" by @eshoyuan in #27325
- Fix owlv2 code snippet by @NielsRogge in #27698
- docs: replace torch.distributed.run by torchrun by @panpan0000 in #27528
- Update chat template warnings/guides by @Rocketknight1 in #27634
- translation main-class files to chinese by @jiaqiw09 in #27588
- Translate
en/model_docto JP by @rajveer43 in #27264 - Fixed passing scheduler-specific kwargs via TrainingArguments lr_scheduler_kwargs by @CharbelAD in #27595
- Fix AMD Push CI not triggered by @ydshieh in #27732
- Add BeitBackbone by @NielsRogge in #25952
- Update tiny model creation script by @ydshieh in #27674
- Log a warning in
TransfoXLTokenizer.__init__by @ydshieh in #27721 - Add madlad-400 MT models by @jbochi in #27471
- Enforce pin memory disabling when using cpu only by @qgallouedec in #27745
- Trigger corresponding pipeline tests if
tests/utils/tiny_model_summary.jsonis modified by @ydshieh in #27693 - CLVP Fixes by @susnato in #27547
- Docs: Fix broken cross-references, i.e.
~transformer.->~transformers.by @tomaarsen in #27740 - [docs] Quantization by @stevhliu in #27641
- Fix precision errors from casting rotary parameters to FP16 with AMP by @kevinhu in #27700
- Remove
check_runner_status.ymlby @ydshieh in #27767 - uses dvclive_test mode in examples/pytorch/test_accelerate_examples.py by @dberenbaum in #27763
- Generate:
GenerationConfigthrows an exception whengenerateargs are passed by @gante in #27757 - Fix unsupported setting of self._n_gpu in training_args on XPU devices by @Liangliang-Ma in #27716
- [SeamlessM4Tv2] Fix links in README by @xenova in #27782
- [i18n-fr] Translate installation to French by @NoB0 in #27657
- Fixes for PatchTST Config by @wgifford in #27777
- Better error message for bitsandbytes import by @SunMarc in #27764
- [MusicGen] Fix audio channel attribute by @sanchit-gandhi in #27440
- [JAX] Replace uses of jax.devices("cpu") with jax.local_devices(backend="cpu") by @hvaara in #27593
- Improve forward signature test by @NielsRogge in #27729
- Fix typo in max_length deprecation warnings by @siegeln in #27788
- Add
persistent_workersparameter toTrainingArgumentsby @Sorrow321 in #27189 - [
ModelOnTheFlyConversionTester] Mark as slow for now by @ArthurZucker in #27823 - Fix
TvpModelIntegrationTestsby @ydshieh in #27792 - Fix
Owlv2ModelIntegrationTest::test_inference_object_detectionby @ydshieh in #27793 - Keypoints 0.0 are confusing ../transformers/models/detr/image_processing_detr.py which are fixed by @hackpk in #26250
- [Seamless v1] Link to v2 docs by @sanchit-gandhi in #27827
- [Whisper] Fix doctest in timestamp logits processor by @sanchit-gandhi in #27795
- Added test cases for rembert refering to albert and reformer test_tok… by @nileshkokane01 in #27637
- [Hot-Fix][XLA] Re-enable broken _tpu_save for XLATensors by @yeounoh in #27799
- single word should be set to False by @ArthurZucker in #27738
- [Seamless v2] Add FE to auto mapping by @sanchit-gandhi in #27829
- translate internal folder files to chinese by @jiaqiw09 in #27638
- Translate
en/tasksfolder docs to Japanese 🇯🇵 by @rajveer43 in #27098 - pin
ruff==0.1.5by @ydshieh in #27849 - Make image processors more general by @NielsRogge in #27690
- Faster generation using AWQ + Fused modules by @younesbelkada in #27411
- Generate: Update VisionEncoderDecoder test value by @gante in #27850
- [
ClipVision]acceleratesupport for clip-vision by @younesbelkada in #27851 - Add Llama Flax Implementation by @vvvm23 in #24587
- Move tensors to same device to enable IDEFICS naive MP training by @willemsenbram in #27746
- Update
VitDetModelTester.get_configto usepretrain_image_sizeby @ydshieh in #27831 - fix(whisper): mutable generation config by @badayvedat in #27833
- Documentation: Spanish translation of perplexity.mdx by @aaronjimv in #27807
- [
Docs] Update broken image on fused modules by @younesbelkada in #27856 - Update CUDA versions for DeepSpeed by @muellerzr in #27853
- removed the delete doc workflows by @MKhalusova in #27852
- Avoid class attribute
_keep_in_fp32_modulesbeing modified by @ydshieh in #27867 - [
Flash Attention 2] Add flash attention 2 for GPT-Neo-X by @younesbelkada in #26463 - Translating en/model_doc folder docs to Japanese(from
bliptoclap) 🇯🇵 by @rajveer43 in #27673 - Fix bug of _prepare_4d_attention_mask by @jiqing-feng in #27847
- [i18n-fr] Translate autoclass tutorial to French by @NoB0 in #27659
- [
FA-2] Add Flash Attention toPhiby @susnato in #27661 - fix: fix gradient accumulate step for learning rate by @pphuc25 in #27667
- Allow
# Ignore copyby @ydshieh in #27328 - update
create_model_cardto properly save peft details when using Trainer with PEFT by @pacman100 in #27754 - update version of warning notification for
get_default_deviceto v4.38 by @statelesshz in #27848 - Fix device of masks in tests by @fxmarty in #27887
- Show new failing tests in a more clear way in slack report by @ydshieh in #27881
- Fix TF loading PT safetensors when weights are tied by @Rocketknight1 in #27490
- Generate: All logits processors are documented and have examples by @gante in #27796
- [docs] Custom semantic segmentation dataset by @stevhliu in #27859
- Updates the distributed CPU training documentation to add instructions for running on a Kubernetes cluster by @dmsuehir in #27780
- Translate
model_docfiles fromcliptocpmto JP by @rajveer43 in #27774 - Fix: Raise informative exception when
prefix_allowed_tokens_fnreturn empty set of tokens by @Saibo-creator in #27797 - Added passing parameters to "reduce_lr_on_plateau" scheduler by @CharbelAD in #27860
- fix: non-atomic checkpoint save by @thundergolfer in #27820
- Fix CLAP converting script by @ylacombe in #27153
- mark
test_initializationas flaky in 2 model tests by @ydshieh in #27906 - Fix
notification_service.pyby @ydshieh in #27903 - Fix 2 tests in
FillMaskPipelineTestsby @ydshieh in #27889 - Llama conversion script: adjustments for Llama Guard by @pcuenca in #27910
- fix llava by @ArthurZucker in #27909
- Allow
resume_from_checkpointto handleauto_find_batch_sizeby @muellerzr in #27568 - [Doc] Spanish translation of pad_truncation.md by @aaronjimv in #27890
- fix typo in image_processing_blip.py Wwhether -> Whether by @zhc7 in #27899
- [CLAP] Replace hard-coded batch size to enable dynamic ONNX export by @xenova in #27790
- [integration] Update Ray Tune integration for Ray 2.7 by @justinvyu in #26499
- Fix typo by @f4hy in #27918
- [DETA] fix backbone freeze/unfreeze function by @SangbumChoi in #27843
Significant community contributions
The following contributors have made significant changes to the library over the last release:
- @jiaqiw09
- translate peft.md to chinese (#27215)
- translate autoclass_tutorial to chinese (#27269)
- translate run_scripts.md to chinese (#27246)
- translate model_sharing.md and llm_tutorial.md to chinese (#27283)
- translate big_models.md and performance.md to chinese (#27334)
- translate debugging.md to chinese (#27374)
- Perf torch compile (#27422)
- translate hpo_train.md and perf_hardware.md to chinese (#27431)
- translate Trainer.md to chinese (#27527)
- translate deepspeed.md to chinese (#27495)
- translation main-class files to chinese (#27588)
- translate internal folder files to chinese (#27638)
- @susnato
- [
FA2] Add flash attention for forDistilBert(#26489) - [
FA2] Add flash attention forGPT-Neo(#26486) - Remove padding_masks from
gpt_bigcode. (#27348) - Add CLVP (#24745)
- Add Phi-1 and Phi-1_5 (#26170)
- [
FA2] Add flash attention for opt (#26414) - CLVP Fixes (#27547)
- [
FA-2] Add Flash Attention toPhi(#27661)
- [
- @jiqing-feng
- add attention_mask and position_ids in assisted model (#26892)
- TVP model (#25856)
- fix assisted decoding assistant model inputs (#27503)
- Fix bug of _prepare_4d_attention_mask (#27847)
- @psinthong
- [time series] Add PatchTST (#25927)
- @Yuki-Imajuku
- Translating
en/model_docdocs to Japanese. (#27401)
- Translating
- @dg845
- Add UnivNet Vocoder Model for Tortoise TTS Diffusers Integration (#24799)
- @rajveer43
- Translate
en/model_docto JP (#27264) - Translate
en/tasksfolder docs to Japanese 🇯🇵 (#27098) - Translating en/model_doc folder docs to Japanese(from
bliptoclap) 🇯🇵 (#27673) - Translate
model_docfiles fromcliptocpmto JP (#27774)
- Translate
- @NoB0
- [i18n-fr] Translate installation to French (#27657)
- [i18n-fr] Translate autoclass tutorial to French (#27659)
- @ajati
- [Time series] Add PatchTSMixer (#26247)
- @vvvm23
- Add Llama Flax Implementation (#24587)
v4.35.2
5 months agoA patch release was made for the following commit:
- [
tokenizers] update tokenizers version pin #27494
to fix all the issues with versioning regarding tokenizers and huggingface_hub
v4.35.1
5 months agoA patch release was made for the following three commits:
- Fix FA2 import + deprecation cycle (#27330)
- Fix from_pt flag when loading with safetensors (#27394)
- Default to msgpack for safetensors (#27460)
v4.35.0
6 months agoNew models
Distil-Whisper
Distil-Whisper is a distilled version of Whisper that is 6 times faster, 49% smaller, and performs within 1% word error rate (WER) on out-of-distribution data. It was proposed in the paper Robust Knowledge Distillation via Large-Scale Pseudo Labelling.
Distil-Whisper copies the entire encoder from Whisper, meaning it retains Whisper's robustness to different audio conditions. It only copies 2 decoder layers, which significantly reduces the time taken to auto-regressively generate text tokens:

Distil-Whisper is MIT licensed and directly available in the Transformers library with chunked long-form inference, Flash Attention 2 support, and Speculative Decoding. For details on using the model, refer to the following instructions.
Joint work from @sanchit-gandhi, @patrickvonplaten and @srush.
- [Assistant Generation] Improve Encoder Decoder by @patrickvonplaten in #26701
- [WhisperForCausalLM] Add WhisperForCausalLM for speculative decoding by @patrickvonplaten in #27195
- [Whisper, Bart, MBart] Add Flash Attention 2 by @patrickvonplaten in #27203
Fuyu
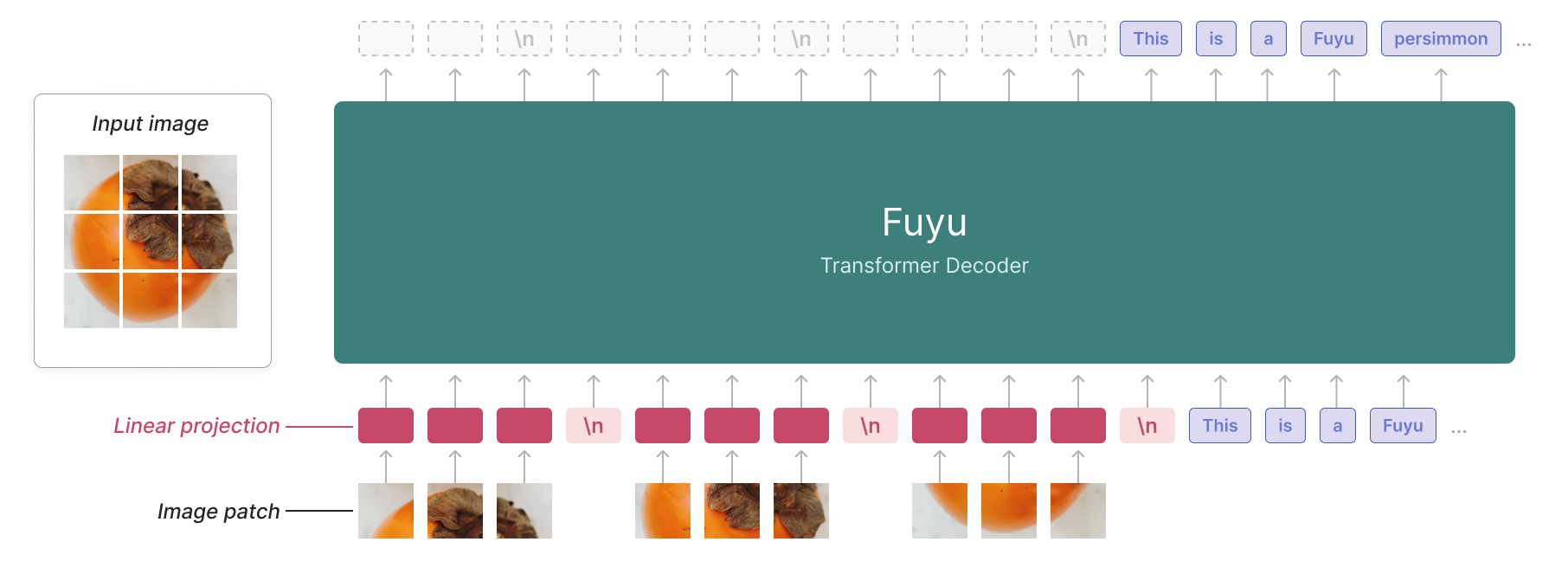
The Fuyu model was created by ADEPT, and authored by Rohan Bavishi, Erich Elsen, Curtis Hawthorne, Maxwell Nye, Augustus Odena, Arushi Somani, Sağnak Taşırlar.
The authors introduced Fuyu-8B, a decoder-only multimodal model based on the classic transformers architecture, with query and key normalization. A linear encoder is added to create multimodal embeddings from image inputs.
By treating image tokens like text tokens and using a special image-newline character, the model knows when an image line ends. Image positional embeddings are removed. This avoids the need for different training phases for various image resolutions. With 8 billion parameters and licensed under CC-BY-NC, Fuyu-8B is notable for its ability to handle both text and images, its impressive context size of 16K, and its overall performance.
Joint work from @molbap, @pcuenca, @amyeroberts, @ArthurZucker
- Add fuyu model by @molbap in #26911
- Fuyu: improve image processing by @molbap in #27007
SeamlessM4T

The SeamlessM4T model was proposed in SeamlessM4T — Massively Multilingual & Multimodal Machine Translation by the Seamless Communication team from Meta AI.
SeamlessM4T is a collection of models designed to provide high quality translation, allowing people from different linguistic communities to communicate effortlessly through speech and text.
SeamlessM4T enables multiple tasks without relying on separate models:
- Speech-to-speech translation (S2ST)
- Speech-to-text translation (S2TT)
- Text-to-speech translation (T2ST)
- Text-to-text translation (T2TT)
- Automatic speech recognition (ASR)
SeamlessM4TModel can perform all the above tasks, but each task also has its own dedicated sub-model.
- Add Seamless M4T model by @ylacombe in #25693
Kosmos-2
The KOSMOS-2 model was proposed in Kosmos-2: Grounding Multimodal Large Language Models to the World by Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Furu Wei.

KOSMOS-2 is a Transformer-based causal language model and is trained using the next-word prediction task on a web-scale dataset of grounded image-text pairs GRIT. The spatial coordinates of the bounding boxes in the dataset are converted to a sequence of location tokens, which are appended to their respective entity text spans (for example, a snowman followed by <patch_index_0044><patch_index_0863>). The data format is similar to “hyperlinks” that connect the object regions in an image to their text span in the corresponding caption.
- Add
Kosmos-2model by @ydshieh in #24709
Owl-v2
OWLv2 was proposed in Scaling Open-Vocabulary Object Detection by Matthias Minderer, Alexey Gritsenko, Neil Houlsby. OWLv2 scales up OWL-ViT using self-training, which uses an existing detector to generate pseudo-box annotations on image-text pairs. This results in large gains over the previous state-of-the-art for zero-shot object detection.
- Add OWLv2, bis by @NielsRogge in #26668
🚨🚨🚨 Safetensors by default for torch serialization 🚨🚨🚨
Version v4.35.0 now puts safetensors serialization by default. This is a significant change targeted at making users of the Hugging Face Hub, transformers, and any downstream library leveraging it safer.
The safetensors library is a safe serialization framework for machine learning tensors. It has been audited and will become the default serialization framework for several organizations (Hugging Face, EleutherAI, Stability AI).
It was already the default loading mechanism since v4.30.0 and would therefore already default to loading model.safetensors files instead of pytorch_model.bin if these were present in the repository.
With v4.35.0, any call to save_pretrained for torch models will now save a safetensors file. This safetensors file is in the PyTorch format, but can be loaded in TensorFlow and Flax models alike.
⚠️ If you run into any issues with this, please let us know ASAP in the issues so that we may help you. Namely, the following errors may indicate something is up:
- Loading a
safetensorsfile and having a warning mentioning missing weights unexpectedly - Obtaining completely wrong/random results at inference after loading a pretrained model that you have saved in
safetensors
If you wish to continue saving files in the .bin format, you can do so by specifying safe_serialization=False in all your save_pretrained calls.
- Safetensors serialization by default by @LysandreJik in #27064
Chat templates
Chat templates have been expanded with the addition of the add_generation_prompt argument to apply_chat_template(). This has also enabled us to rework the ConversationalPipeline class to use chat templates. Any model with a chat template is now automatically usable through ConversationalPipeline.
- Add add_generation_prompt argument to apply_chat_template by @Rocketknight1 in #26573
- Conversation pipeline fixes by @Rocketknight1 in #26795
Guides
Two new guides on LLMs were added the library:
- [docs] LLM prompting guide by @MKhalusova in #26274
- [docs] Optimizing LLMs by @patrickvonplaten in #26058
Quantization
Exllama-v2 integration
Exllama-v2 provides better GPTQ kernel for higher throughput and lower latency for GPTQ models. The original code can be found here.
- add exllamav2 arg by @SunMarc in #26437
- Add exllamav2 better by @SunMarc in #27111
You will need the latest versions of optimum and auto-gptq. Read more about the integration here.
AWQ integration
AWQ is a new and popular quantization scheme, already used in various libraries such as TGI, vllm, etc. and known to be faster than GPTQ models according to some benchmarks. The original code can be found here and here you can read more about the original paper.
We support AWQ inference with original kernels as well as kernels provided through autoawq package that you can simply install with pip install autoawq.
- [
core/Quantization] AWQ integration by @younesbelkada in #27045
We also provide an example script on how to push quantized weights on the hub on the original repository.
Read more about the benchmarks and the integration here
GPTQ on CPU !
You can now run GPTQ models on CPU using the latest version of auto-gptq thanks to @vivekkhandelwal1 !
- Add support for loading GPTQ models on CPU by @vivekkhandelwal1 in #26719
Attention mask refactor
We refactored the attention mask logic for major models in transformers. For instance, we removed padding_mask argument which was ambiguous for some users
- Remove ambiguous
padding_maskand instead use a 2D->4D Attn Mask Mapper by @patrickvonplaten in #26792 - [Attention Mask] Refactor all encoder-decoder attention mask by @patrickvonplaten in #27086
Flash Attention 2 for more models + quantization fine-tuning bug fix
Gpt-bigcode (starcoder), whisper, Bart and MBart now supports FA-2 ! Use it by simply passing use_flash_attention_2=True to from_pretrained. Some bugfixes with respect to mixed precision training with FA2 have been also addressed.
- Add flash attention for
gpt_bigcodeby @susnato in #26479 - [
FA2] Fix flash attention 2 fine-tuning with Falcon by @younesbelkada in #26852 - [Whisper, Bart, MBart] Add Flash Attention 2 by @patrickvonplaten in #27203
A bugfix with respect to fine-tuning with FA-2 in bfloat16 was addressed. You should now smoothly fine-tune FA-2 models in bfloat16 using quantized base models.
- 🚨🚨🚨 [
Quantization] Store the original dtype in the config as a private attribute 🚨🚨🚨 by @younesbelkada in #26761 - [
FA-2] Final fix for FA2 dtype by @younesbelkada in #26846
Neftune
NEFTune is a new technique to boost Supervised Fine-tuning performance by adding random noise on the embedding vector. Read more about it on the original paper here

We propose a very simple API for users to benefit from this technique, simply pass a valid neftune_noise_alpha parameter to TrainingArguments
Read more about the API here
- [FEAT] Add Neftune into transformers Trainer by @younesbelkada in #27141
Gradient checkpointing refactor
We have refactored the gradient checkpointing API so that users can pass keyword arguments supported by torch.utils.checkpoint.checkpoint directly through gradient_checkpointing_kwargs when calling gradient_checkpointing_enable(), e.g.
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("facebook/opt-125m")
model.gradient_checkpointing_enable(gradient_checkpointing_kwargs={"use_reentrant": False})
gradient_checkpointing_kwargs is also supported with Trainer through TrainingArguments.
- [
Trainer/GC] Addgradient_checkpointing_kwargsin trainer and training arguments by @younesbelkada in #27068 - [
core] Refactor ofgradient_checkpointingby @younesbelkada in #27020 - [
core/GC/tests] Stronger GC tests by @younesbelkada in #27124 - Fix import of torch.utils.checkpoint by @NielsRogge in #27155
The refactor should be totally backward compatible with previous behaviour. For superusers, you can still use the attribute gradient_checkpointing on model's submodules to control the activation / deactivation of gradient_checkpointing.
Breaking changes
- 🚨🚨🚨 [
Quantization] Store the original dtype in the config as a private attribute 🚨🚨🚨 by @younesbelkada in #26761 - 🚨🚨 Generate: change order of ops in beam sample to avoid nans by @gante in #26843
- 🚨🚨 Raise error when no speaker embeddings in speecht5._generate_speech by @ylacombe in #26418
Bugfixes and improvements
- [
Nougat] from transformers import * by @ArthurZucker in #26562 - [Whisper] Allow basic text normalization by @sanchit-gandhi in #26149
- 🌐 [i18n-KO] Translated
semantic_segmentation.mdto Korean by @jungnerd in #26515 - [Tokenizers] Skip tests temporarily by @LysandreJik in #26574
- docs: feat: add clip notebook resources from OSSCA community by @junejae in #26505
- Extend Trainer to enable Ascend NPU to use the fused Adamw optimizer when training by @statelesshz in #26194
- feat: add trainer label to wandb run upon initialization by @parambharat in #26466
- Docstring check by @sgugger in #26052
- refactor: change default block_size by @pphuc25 in #26229
- [Mistral] Update config docstring by @sanchit-gandhi in #26593
- Add # Copied from statements to audio feature extractors that use the floats_list function by @dg845 in #26581
- Fix embarrassing typo in the doc chat template! by @Rocketknight1 in #26596
- Fix encoder->decoder typo bug in convert_t5x_checkpoint_to_pytorch.py by @soyoung97 in #26587
- skip flaky hub tests by @ArthurZucker in #26594
- Update mistral.md to update 404 link by @Galland in #26590
- [Wav2Vec2] Fix tokenizer set lang by @sanchit-gandhi in #26349
- add zh translation for installation by @yyLeaves in #26084
- [
NougatProcessor] Fix the default channel by @ArthurZucker in #26608 - [
GPTNeoX] Faster rotary embedding for GPTNeoX (based on llama changes) by @ArthurZucker in #25830 - [Falcon] Set
use_cache=Falsebefore creatingpresentswhich relies onuse_cacheby @yundai424 in #26328 - Fix failing tests on
maindue to torch 2.1 by @ydshieh in #26607 - Make
ModelOutputserializable by @cbensimon in #26493 - [
core] fix silent bugkeep_in_fp32modules by @younesbelkada in #26589 - #26566 swin2 sr allow in out channels by @marvingabler in #26568
- Don't close ClearML task if it was created externally by @eugen-ajechiloae-clearml in #26614
- Fix
transformers-pytorch-gpudocker build by @ydshieh in #26615 - [docs] Update to scripts building index.md by @MKhalusova in #26546
- Don't install
pytorch-quantizationin Doc Builder docker file by @ydshieh in #26622 - Remove unnecessary
views ofposition_idsby @ramiro050 in #26059 - Fixed inconsistency in several fast tokenizers by @Towdo in #26561
- Update tokenization_code_llama_fast.py by @andyl98 in #26576
- Remove unnecessary unsqueeze - squeeze in rotary positional embedding by @fxmarty in #26162
- Update chat template docs with more tips on writing a template by @Rocketknight1 in #26625
- fix RoPE t range issue for fp16 by @rui-ren in #26602
- Fix failing
MusicgenTest .test_pipeline_text_to_audioby @ydshieh in #26586 - remove SharedDDP as it is deprecated by @statelesshz in #25702
- [
LlamaTokenizerFast] Adds edge cases for the template processor by @ArthurZucker in #26606 - [docstring] Fix docstring for
AlbertConfigby @ydshieh in #26636 - docs(zh): review and punctuation & space fix by @wfjsw in #26627
- [DINOv2] Convert more checkpoints by @NielsRogge in #26177
- Fixed malapropism error by @Zhreyu in #26660
- fix links in README.md for the GPT, GPT-2, and Llama2 Models by @dcarpintero in #26640
- Avoid CI OOM by @ydshieh in #26639
- fix typos in idefics.md by @dribnet in #26648
- [docstring] Fix docstring CLIP configs by @isaac-chung in #26677
- [docstring] Fix docstring for
CLIPImageProcessorby @isaac-chung in #26676 - [docstring] Fix docstring for DonutImageProcessor by @abzdel in #26641
- Fix stale bot by @LysandreJik in #26692
- [docstring] Fix docstrings for
CLIPby @isaac-chung in #26691 - Control first downsample stride in ResNet by @jiqing-feng in #26374
- Fix Typo: table in deepspeed.md by @Pairshoe in #26705
- [docstring] Fix docstring for
LlamaConfigby @pavaris-pm in #26685 - fix a typo in flax T5 attention - attention_mask variable is misnamed by @giganttheo in #26663
- Fix source_prefix default value by @jheitmann in #26654
- [JAX] Replace uses of
jnp.arrayin types withjnp.ndarray. by @hvaara in #26703 - Make Whisper Encoder's sinusoidal PE non-trainable by default by @gau-nernst in #26032
- In assisted decoding, pass model_kwargs to model's forward call (fix prepare_input_for_generation in all models) by @sinking-point in #25242
- Update docs to explain disabling callbacks using report_to by @nebrelbug in #26155
-
Copied fromfor test files by @ydshieh in #26713 - [docstring]
SwinModeldocstring fix by @shivanandmn in #26679 - fix the model card issue as
use_cuda_ampis no more available by @pacman100 in #26731 - Fix stale bot for locked issues by @LysandreJik in #26711
- Fix checkpoint path in
no_trainerscripts by @muellerzr in #26733 - Update docker files to use
torch==2.1.0by @ydshieh in #26735 - Revert #20715 by @ydshieh in #26734
- [docstring] Fix docstring for
LlamaTokenizerandLlamaTokenizerFastby @minhoryang in #26669 - [docstring] Fix docstring for
CodeLlamaTokenizerby @Bojun-Feng in #26709 - add japanese documentation by @rajveer43 in #26138
- Translated the accelerate.md file of the documentation to Chinese by @liteli1987gmail in #26161
- Fix doctest for
Blip2ForConditionalGenerationby @ydshieh in #26737 - Add many missing spaces in adjacent strings by @tomaarsen in #26751
- Warnings controlled by logger level by @LysandreJik in #26527
- Fix
PersimmonIntegrationTestOOM by @ydshieh in #26750 - Fix
MistralIntegrationTestOOM by @ydshieh in #26754 - Fix backward compatibility of Conversation by @wdhorton in #26741
- [docstring] Fix
UniSpeech,UniSpeechSat,Wav2Vec2ForCTCby @gizemt in #26664 - [docstring] Update
GPT2andWhisperby @McDonnellJoseph in #26642 - [docstring] Fix docstring for 'BertGenerationConfig' by @AdwaitSalankar in #26661
- Fix
PerceiverModelIntegrationTest::test_inference_masked_lmby @ydshieh in #26760 - chore: fix typos by @afuetterer in #26756
- [
core] Fix fa-2 import by @younesbelkada in #26785 - Skip
TrainerIntegrationFSDP::test_basic_run_with_cpu_offloadiftorch < 2.1by @ydshieh in #26764 - 🌐 [i18n-KO] Translated
big_models.mdto Korean by @wonhyeongseo in #26245 - Update expect outputs of
IdeficsProcessorTest.test_tokenizer_paddingby @ydshieh in #26779 - [docstring] Fix docstring for
RwkvConfigby @Bojun-Feng in #26782 - Fix num. of minimal calls to the Hub with peft for pipeline by @ydshieh in #26385
- [docstring] fix docstring
DPRConfigby @AVAniketh0905 in #26674 - Disable default system prompt for LLaMA by @Rocketknight1 in #26765
- Fix Falcon generation test by @Rocketknight1 in #26770
- Fixed KeyError for Mistral by @MatteoRaso in #26682
- [
Flava] Fix flava doc by @younesbelkada in #26789 - Add CLIP resources by @eenzeenee in #26534
- translation brazilian portuguese by @alvarorichard in #26769
- Fixed typos by @Zhreyu in #26810
- [docstring] Fix docstring for
CanineConfigby @Sparty in #26771 - Add Japanese translation by @shinshin86 in #26799
- [docstring] Fix docstring for
CodeLlamaTokenizerFastby @Bojun-Feng in #26666 - Image-to-Image Task Guide by @merveenoyan in #26595
- Make fsdp ram efficient loading optional by @pacman100 in #26631
- fix resume_from_checkpoint bug by @Jintao-Huang in #26739
- [OWL-ViT, OWLv2] Add resources by @NielsRogge in #26822
- Llama tokenizer: remove space in template comment by @pcuenca in #26788
- Better way to run AMD CI with different flavors by @ydshieh in #26634
- [docstring] Fix bert generation tokenizer by @przemL in #26820
- Conversation pipeline fixes by @Rocketknight1 in #26795
- Fix Mistral OOM again by @ydshieh in #26847
- Chore: Typo fixed in multiple files of docs/source/en/model_doc by @SusheelThapa in #26833
- fix: when window_size is passes as array by @dotneet in #26800
- Update logits_process.py docstrings to clarify penalty and reward cases (attempt #2) by @larekrow in #26784
- [docstring] Fix docstring for LukeConfig by @louietouie in #26858
- Fixed a typo in mistral.md by @DTennant in #26879*
- Translating
en/internalfolder docs to Japanese 🇯🇵 by @rajveer43 in #26747 - Fix TensorFlow pakage check by @jayfurmanek in #26842
- Generate: improve docstrings for custom stopping criteria by @gante in #26863
- Knowledge distillation for vision guide by @merveenoyan in #25619
- Fix Seq2seqTrainer decoder attention mask by @Rocketknight1 in #26841
- [
Tokenizer] Fix slow and fast serialization by @ArthurZucker in #26570 - Emergency PR to skip conversational tests to fix CI by @Rocketknight1 in #26906
- Add default template warning by @Rocketknight1 in #26637
- Refactor code part in documentation translated to japanese by @rajveer43 in #26900
- [i18n-ZH] Translated fast_tokenizers.md to Chinese by @yyLeaves in #26910
- [
FA-2] Revert suggestion that broke FA2 fine-tuning with quantized models by @younesbelkada in #26916 - [docstring] Fix docstring for
ChineseCLIPby @Sparty in #26880 - [Docs] Make sure important decode and generate method are nicely displayed in Whisper docs by @patrickvonplaten in #26927
- Fix and re-enable ConversationalPipeline tests by @Rocketknight1 in #26907
- [docstring] Fix docstrings for
CodeGenby @daniilgaltsev in #26821 - Fix license by @MedAymenF in #26931
- Pin Keras for now by @Rocketknight1 in #26904
- [
FA-2/Mistral] Supprot fa-2 + right padding + forward by @younesbelkada in #26912 - Generate: update basic llm tutorial by @gante in #26937
- Corrected modalities description in README_ru.md by @letohx in #26913
- [docstring] Fix docstring for speech-to-text config by @R055A in #26883
- fix set_transform link docs by @diegulio in #26856
- Fix Fuyu image scaling bug by @pcuenca in #26918
- Update README_hd.md by @biswabaibhab007 in #26872
- Added Telugu [te] translations by @hakunamatata1997 in #26828
- fix logit-to-multi-hot conversion in example by @ranchlai in #26936
- Limit to inferior fsspec version by @LysandreJik in #27010
- python falcon doc-string example typo by @SoyGema in #26995
- skip two tests by @ArthurZucker in #27013
- Nits in Llama2 docstring by @osanseviero in #26996
- Change default
max_shard_sizeto smaller value by @younesbelkada in #26942 - [
NLLB-MoE] Fix NLLB MoE 4bit inference by @younesbelkada in #27012 - [
SeamlessM4T] fix copies with NLLB MoE int8 by @ArthurZucker in #27018 - small typos found by @rafaelpadilla in #26988
- Remove token_type_ids from default TF GPT-2 signature by @Rocketknight1 in #26962
- Translate
pipeline_tutorial.mdto chinese by @jiaqiw09 in #26954 - 🌐 [i18n-ZH] Translate multilingual into Chinese by @yyLeaves in #26935
- translate
preprocessing.mdto Chinese by @jiaqiw09 in #26955 - Bugfix device map detr model by @pedrogengo in #26849
- Fix little typo by @mertyyanik in #27028
- 🌐 [i18n-ZH] Translate create_a_model.md into Chinese by @yyLeaves in #27026
- Fix key dtype in GPTJ and CodeGen by @fxmarty in #26836
- Register ModelOutput as supported torch pytree nodes by @XuehaiPan in #26618
- Add
default_to_square_for_sizetoCLIPImageProcessorby @ydshieh in #26965 - Add descriptive docstring to WhisperTimeStampLogitsProcessor by @jprivera44 in #25642
- Normalize only if needed by @mjamroz in #26049
- [
TFxxxxForSequenceClassifciation] Fix the eager mode after #25085 by @ArthurZucker in #25751 - Safe import of rgb_to_id from FE modules by @amyeroberts in #27037
- add info on TRL docs by @lvwerra in #27024
- Add fuyu device map by @SunMarc in #26949
- Device agnostic testing by @vvvm23 in #25870
- Fix config silent copy in from_pretrained by @patrickvonplaten in #27043
- [docs] Performance docs refactor p.2 by @MKhalusova in #26791
- Add a default decoder_attention_mask for EncoderDecoderModel during training by @hackyon in #26752
- Fix RoPE config validation for FalconConfig + various config typos by @tomaarsen in #26929
- Skip-test by @ArthurZucker in #27062
- Fix TypicalLogitsWarper tensor OOB indexing edge case by @njhill in #26579
- [docstring] fix incorrect llama docstring: encoder -> decoder by @ztjhz in #27071
- [DOCS] minor fixes in README.md by @Akash190104 in #27048
- [
docs] AddMaskGenerationPipelinein docs by @younesbelkada in #27063 - 🌐 [i18n-ZH] Translate custom_models.md into Chinese by @yyLeaves in #27065
- Hindi translation of pipeline_tutorial.md by @AaryaBalwadkar in #26837
- Handle unsharded Llama2 model types in conversion script by @coreyhu in #27069
- Bring back
set_epochfor Accelerate-based dataloaders by @muellerzr in #26850 - Bump
flash_attnversion to2.1by @younesbelkada in #27079 - Remove unneeded prints in modeling_gpt_neox.py by @younesbelkada in #27080
- Add-support for commit description by @ArthurZucker in #26704
- [Llama FA2] Re-add _expand_attention_mask and clean a couple things by @patrickvonplaten in #27074
- Correct docstrings and a typo in comments by @lewis-yeung in #27047
- Save TB logs as part of push_to_hub by @muellerzr in #27022
- Added huggingface emoji instead of the markdown format by @shettyvarshaa in #27091
- [
T5Tokenizer] Fix fast and extra tokens by @ArthurZucker in #27085 - Revert "add exllamav2 arg" by @ArthurZucker in #27102
- Add early stopping for Bark generation via logits processor by @isaac-chung in #26675
- Provide alternative when warning on use_auth_token by @Wauplin in #27105
- Fix no split modules underlying modules by @SunMarc in #27090
- [
core/gradient_checkpointing] Refactor GC - part 2 by @younesbelkada in #27073 - fix detr device map by @SunMarc in #27089
- Added Telugu [te] translation for README.md in main by @hakunamatata1997 in #27077
- translate transformers_agents.md to Chinese by @jiaqiw09 in #27046
- Fix docstring and type hint for resize by @daniilgaltsev in #27104
- [Typo fix] flag config in WANDB by @SoyGema in #27130
- Fix slack report failing for doctest by @ydshieh in #27042
- [
FA2/Mistral] Revert previous behavior with right padding + forward by @younesbelkada in #27125 - Fix data2vec-audio note about attention mask by @gau-nernst in #27116
- remove the obsolete code related to fairscale FSDP by @statelesshz in #26651
- Fix some tests using
"common_voice"by @ydshieh in #27147 - [
tests/Quantization] Fix bnb test by @younesbelkada in #27145 - make tests of pytorch_example device agnostic by @statelesshz in #27081
- Remove some Kosmos-2
copied fromby @ydshieh in #27149 - 🌐 [i18n-ZH] Translate serialization.md into Chinese by @yyLeaves in #27076
- Translating
en/main_classesfolder docs to Japanese 🇯🇵 by @rajveer43 in #26894 - Device agnostic trainer testing by @statelesshz in #27131
- Fix: typos in README.md by @THEFZNKHAN in #27154
- [KOSMOS-2] Update docs by @NielsRogge in #27157
- deprecate function
get_default_deviceintools/base.pyby @statelesshz in #26774 - Remove broken links to s-JoL/Open-Llama by @CSRessel in #27164
- [docstring] Fix docstring for AltCLIPTextConfig, AltCLIPVisionConfig and AltCLIPConfig by @AksharGoyal in #27128
- [doctring] Fix docstring for BlipTextConfig, BlipVisionConfig by @Hangsiin in #27173
- Disable CI runner check by @ydshieh in #27170
- fix: Fix typical_p behaviour broken in recent change by @njhill in #27165
- Trigger CI if
tiny_model_summary.jsonis modified by @ydshieh in #27175 - Shorten the conversation tests for speed + fixing position overflows by @Rocketknight1 in #26960
- device agnostic pipelines testing by @statelesshz in #27129
- Backward compatibility fix for the Conversation class by @Rocketknight1 in #27176
- [
Quantization/tests] Fix bnb MPT test by @younesbelkada in #27178 - Fix dropout in
StarCoderby @susnato in #27182 - translate traning.md to chinese by @jiaqiw09 in #27122
- [docs] Update CPU/GPU inference docs by @stevhliu in #26881
- device agnostic models testing by @statelesshz in #27146
- Unify warning styles for better readability by @oneonlee in #27184
- 🌐 [i18n-ZH] Translate tflite.md into Chinese by @yyLeaves in #27134
- device agnostic fsdp testing by @statelesshz in #27120
- Fix docstring get maskformer resize output image size by @wesleylp in #27196
- Fix the typos and grammar mistakes in CONTRIBUTING.md. by @THEFZNKHAN in #27193
- Fixing docstring in get_resize_output_image_size function by @wesleylp in #27191
- added unsqueeze_dim to apply_rotary_pos_emb by @ShashankMosaicML in #27117
- Added cache_block_outputs option to enable GPTQ for non-regular models by @AlexKoff88 in #27032
- Add TensorFlow implementation of ConvNeXTv2 by @neggles in #25558
- Fix docstring in get_oneformer_resize_output_image_size func by @wesleylp in #27207
- improving TimmBackbone to support FrozenBatchNorm2d by @rafaelpadilla in #27160
- Translate task summary to chinese by @jiaqiw09 in #27180
- Fix CPU offload + disk offload tests by @LysandreJik in #27204
- Enable split_batches through TrainingArguments by @muellerzr in #26798
- support bf16 by @etemadiamd in #25879
- Reproducible checkpoint for npu by @statelesshz in #27208
- [
core/Quantization] Fix for 8bit serialization tests by @younesbelkada in #27234
Significant community contributions
The following contributors have made significant changes to the library over the last release:
- @jungnerd
- 🌐 [i18n-KO] Translated
semantic_segmentation.mdto Korean (#26515)
- 🌐 [i18n-KO] Translated
- @statelesshz
- Extend Trainer to enable Ascend NPU to use the fused Adamw optimizer when training (#26194)
- remove SharedDDP as it is deprecated (#25702)
- remove the obsolete code related to fairscale FSDP (#26651)
- make tests of pytorch_example device agnostic (#27081)
- Device agnostic trainer testing (#27131)
- deprecate function
get_default_deviceintools/base.py(#26774) - device agnostic pipelines testing (#27129)
- device agnostic models testing (#27146)
- device agnostic fsdp testing (#27120)
- Reproducible checkpoint for npu (#27208)
- @sgugger
- Docstring check (#26052)
- @yyLeaves
- add zh translation for installation (#26084)
- [i18n-ZH] Translated fast_tokenizers.md to Chinese (#26910)
- 🌐 [i18n-ZH] Translate multilingual into Chinese (#26935)
- 🌐 [i18n-ZH] Translate create_a_model.md into Chinese (#27026)
- 🌐 [i18n-ZH] Translate custom_models.md into Chinese (#27065)
- 🌐 [i18n-ZH] Translate serialization.md into Chinese (#27076)
- 🌐 [i18n-ZH] Translate tflite.md into Chinese (#27134)
- @sinking-point
- In assisted decoding, pass model_kwargs to model's forward call (fix prepare_input_for_generation in all models) (#25242)
- @rajveer43
- add japanese documentation (#26138)
- Translating
en/internalfolder docs to Japanese 🇯🇵 (#26747) - Refactor code part in documentation translated to japanese (#26900)
- Translating
en/main_classesfolder docs to Japanese 🇯🇵 (#26894)
- @alvarorichard
- translation brazilian portuguese (#26769)
- @hakunamatata1997
- Added Telugu [te] translations (#26828)
- Added Telugu [te] translation for README.md in main (#27077)
- @jiaqiw09
- Translate
pipeline_tutorial.mdto chinese (#26954) - translate
preprocessing.mdto Chinese (#26955) - translate transformers_agents.md to Chinese (#27046)
- translate traning.md to chinese (#27122)
- Translate task summary to chinese (#27180)
- Translate
- @neggles
- Add TensorFlow implementation of ConvNeXTv2 (#25558)
v4.34.1
6 months agoA patch release was made for the following three commits:
- Add add_generation_prompt argument to apply_chat_template (https://github.com/huggingface/transformers/pull/26573)
- Fix backward compatibility of Conversation (https://github.com/huggingface/transformers/pull/26741)
- [Tokenizer] Fix slow and fast serialization (https://github.com/huggingface/transformers/pull/26570)
v4.34.0
6 months agoNew models
Mistral
Mistral-7B-v0.1 is a decoder-based LM with the following architectural choices:
- Sliding Window Attention - Trained with 8k context length and fixed cache size, with a theoretical attention span of 128K tokens
- GQA (Grouped Query Attention) - allowing faster inference and lower cache size.
- Byte-fallback BPE tokenizer - ensures that characters are never mapped to out-of-vocabulary tokens.
- [Mistral] Mistral-7B-v0.1 support by @Bam4d in #26447
Persimmon
The authors introduced Persimmon-8B, a decoder model based on the classic transformers architecture, with query and key normalization. Persimmon-8B is a fully permissively licensed model with approximately 8 billion parameters, released under the Apache license. Some of the key attributes of Persimmon-8B are long context size (16K), performance, and capabilities for multimodal extensions.
- [
Persimmon] Add support for persimmon by @ArthurZucker in #26042
BROS
BROS stands for BERT Relying On Spatiality. It is an encoder-only Transformer model that takes a sequence of tokens and their bounding boxes as inputs and outputs a sequence of hidden states. BROS encode relative spatial information instead of using absolute spatial information.
- Add BROS by @jinhopark8345 in #23190
ViTMatte
ViTMatte leverages plain Vision Transformers for the task of image matting, which is the process of accurately estimating the foreground object in images and videos.
- Add ViTMatte by @NielsRogge in #25843
Nougat
Nougat uses the same architecture as Donut, meaning an image Transformer encoder and an autoregressive text Transformer decoder to translate scientific PDFs to markdown, enabling easier access to them.
- Add Nougat by @NielsRogge and @molbap in #25942
Prompt templating
We've added a new template feature for chat models. This allows the formatting that a chat model was trained with to be saved with the model, ensuring that users can exactly reproduce that formatting when they want to fine-tune the model or use it for inference. For more information, see our template documentation.
- Overhaul Conversation class and prompt templating by @Rocketknight1 in #25323
🚨🚨 Tokenizer refactor
- [
Tokenizer] attemp to fix add_token issues by @ArthurZucker in #23909 - Nit-added-tokens by @ArthurZucker in #26538 adds some fix to #23909 .
🚨Workflow Changes 🚨:
These are not breaking changes per se but rather bugfixes. However, we understand that this may result in some workflow changes so we highlight them below.
- unique_no_split_tokens attribute removed and not used in the internal logic
- sanitize_special_tokens() follows a deprecation cycle and does nothing
- All attributes in SPECIAL_TOKENS_ATTRIBUTES are stored as AddedTokens and no strings.
- loading a slow from a fast or a fast from a slow will no longer raise and error if the tokens added don't have the correct index. This is because they will always be added following the order of the added_tokens but will correct mistakes in the saved vocabulary if there are any. (And there are a lot in old format tokenizers)
- the length of a tokenizer is now max(set(self.get_vocab().keys())) accounting for holes in the vocab. The vocab_size no longer takes into account the added vocab for most of the tokenizers (as it should not). Mostly breaking for T5
- Adding a token using tokenizer.add_tokens([AddedToken("hey", rstrip=False, normalized=True)]) now takes into account rstrip, lstrip, normalized information.
- added_tokens_decoder holds AddedToken, not strings.
- add_tokens() for both fast and slow will always be updated if the token is already part of the vocab, allowing for custom stripping.
- initializing a tokenizer form scratch will now add missing special tokens to the vocab.
- stripping is not always done for special tokens! 🚨 Only if the AddedToken has lstrip=True and rstrip=True
- fairseq_ids_to_tokens attribute removed for Barthez (was not used)
➕ Most visible features:
- printing a tokenizer now shows
tokenizer.added_tokens_decoderfor both fast and slow tokenizers. Moreover, additional tokens that were already part of the initial vocab are also found there. - faster
from_pretrained, fasteradd_tokensbecause special and non special can be mixed together and the trie is not always rebuilt. - faster encode/decode with caching mechanism for
added_tokens_decoder/encoder. - information is fully saved in the
tokenizer_config.json
For any issues relating to this, make sure to open a new issue and ping @ArthurZucker.
Flash Attention 2
FA2 support added to transformers for most popular architectures (llama, mistral, falcon) architectures actively being contributed in this issue (https://github.com/huggingface/transformers/issues/26350). Simply pass use_flash_attention_2=True when calling from_pretrained
In the future, PyTorch will support Flash Attention 2 through torch.scaled_dot_product_attention, users would be able to benefit from both (transformers core & transformers + SDPA) implementations of Flash Attention-2 with simple changes (model.to_bettertransformer() and force-dispatch the SDPA kernel to FA-2 in the case of SDPA)
- [
core] Integrate Flash attention 2 in most used models by @younesbelkada in #25598
For our future plans regarding integrating F.sdpa from PyTorch in core transformers, see here: https://github.com/huggingface/transformers/issues/26557
Lazy import structure
Support for lazy loading integration libraries has been added. This will drastically speed up importing transformers and related object from the library.
Example before this change:
2023-09-11 11:07:52.010179: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
python3 -c "from transformers import CLIPTextModel" 3.31s user 3.06s system 220% cpu 2.893 total
After this change:
python3 -c "from transformers import CLIPTextModel" 1.70s user 1.49s system 220% cpu 1.447 total
- [Core] Add lazy import structure to imports by @patrickvonplaten in #26090
Bugfixes and improvements
- Fix typo by @susnato in #25966
- Fix Detr CI by @ydshieh in #25972
- Fix
test_load_img_url_timeoutby @ydshieh in #25976 - nn.Identity is not required to be compatible with PyTorch < 1.1.0 as the minimum PyTorch version we currently support is 1.10.0 by @statelesshz in #25974
- Add
Pop2Pianospace demo. by @susnato in #25975 - fix typo by @kai01ai in #25981
- Use main in conversion script by @ydshieh in #25973
- [doc] Always call it Agents for consistency by @julien-c in #25958
- Update RAG README.md with correct path to examples/seq2seq by @tleyden in #25953
- Update training_args.py to remove the runtime error by @sahel-sh in #25920
- Trainer: delegate default generation values to
generation_configby @gante in #25987 - Show failed tests on CircleCI layout in a better way by @ydshieh in #25895
- Patch with accelerate xpu by @abhilash1910 in #25714
- PegasusX add _no_split_modules by @andreeahedes in #25933
- Add TFDebertaV2ForMultipleChoice by @raghavanone in #25932
- deepspeed resume from ckpt fixes and adding support for deepspeed optimizer and HF scheduler by @pacman100 in #25863
- [Wav2Vec2 Conformer] Fix inference float16 by @sanchit-gandhi in #25985
- Add LLaMA resources by @eenzeenee in #25859
- [
CI] Fix red CI and ERROR failed should show by @ArthurZucker in #25995 - [
VITS] tokenizer integration test: fix revision did not exist by @ArthurZucker in #25996 - Fix Mega chunking error when using decoder-only model by @tanaymeh in #25765
- save space when converting hf model to megatron model. by @flower-with-safe in #25950
- Update README.md by @NinoRisteski in #26003
- Falcon: fix revision propagation by @LysandreJik in #26006
- TF-OPT attention mask fixes by @Rocketknight1 in #25238
- Fix small typo README.md by @zspo in #25934
- 🌐[i18n-KO] Translated
llm_tutorial.mdto Korean by @harheem in #25791 - Remove Falcon from undocumented list by @Rocketknight1 in #26008
- modify context length for GPTQ + version bump by @SunMarc in #25899
- Fix err with FSDP by @muellerzr in #25991
- fix _resize_token_embeddings will set lm head size to 0 when enabled deepspeed zero3 by @kai01ai in #26024
- Fix CircleCI config by @ydshieh in #26023
- Add
tgsspeed metrics by @CokeDong in #25858 - [VITS] Fix nightly tests by @sanchit-gandhi in #25986
- Added HerBERT to README.md by @Muskan011 in #26020
- Fix vilt config docstring parameter to match value in init by @raghavanone in #26017
- Punctuation fix by @kwonmha in #26025
- Try to fix training Loss inconsistent after resume from old checkpoint by @dumpmemory in #25872
- Fix Dropout Implementation in Graphormer by @alexanderkrauck in #24817
- Update missing docs on
activation_dropoutand fix DropOut docs for SEW-D by @gau-nernst in #26031 - Skip warning if tracing with dynamo by @angelayi in #25581
- 🌐 [i18n-KO] Translated
llama.mdto Korean by @harheem in #26044 - [
CodeLlamaTokenizerFast] Fix fixset_infilling_processorto properly reset by @ArthurZucker in #26041 - [
CITests] skip failing tests until #26054 is merged by @ArthurZucker in #26063 - only main process should call _save on deepspeed zero3 by @zjjMaiMai in #25959
- docs: update link huggingface map by @pphuc25 in #26077
- docs: add space to docs by @pphuc25 in #26067
- [
core] Import tensorflow inside relevant methods intrainer_utilsby @younesbelkada in #26106 - Generate: legacy mode is only triggered when
generation_configis untouched by @gante in #25962 - Update logits_process.py docstrings by @larekrow in #25971
- Fix ExponentialDecayLengthPenalty negative logits issue by @pokjay in #25594
- 🌐 [i18n-KO] Translated
llama2.mdto Korean by @mjk0618 in #26047 - [docs] Updates to TTS task guide with regards to the new TTS pipeline by @MKhalusova in #26095
- 🌐 [i18n-KO] Translated
contributing.mdto Korean by @mjk0618 in #25877 - enable optuna multi-objectives feature by @sywangyi in #25969
- chore: correct update_step and correct gradient_accumulation_steps by @pphuc25 in #26068
- Text2text pipeline: don't parameterize from the config by @gante in #26118
- Fix
MarianTokenizerto remove metaspace character indecodeby @tanaymeh in #26091 - safeguard torch distributed check by @pacman100 in #26056
- fix the deepspeed tests by @pacman100 in #26021
- Fix AutoTokenizer docstring typo by @amyeroberts in #26117
- [
core] fix 4bitnum_parametersby @younesbelkada in #26132 - Add missing space in generation/utils.py by @jbochi in #26121
- Update spectrogram and waveform model mapping for TTS/A pipeline by @Vaibhavs10 in #26114
- [
RWKV] Final fix RWMV 4bit by @younesbelkada in #26134 - docs: feat: add llama2 notebook resources from OSSCA community by @junejae in #26076
- Generate: ignore warning when
generation_config.max_lengthis set toNoneby @gante in #26147 - Fix
test_finetune_bert2bertby @ydshieh in #25984 - Falcon: batched generation by @gante in #26137
- Fix
beam_scoresshape when token scores shape changes afterlogits_processorby @BakerBunker in #25980 - Update training_args.py - addition of self.distributed_state when using XPU by @Serizao in #25999
- [docs] last hidden state vs hidden_states[-1] by @MKhalusova in #26142
- Flex xpu bug fix by @abhilash1910 in #26135
- Add missing Maskformer dataclass decorator, add dataclass check in ModelOutput for subclasses by @rachthree in #25638
- Fix eval accumulation when
accelerate> 0.20.3 by @sam-scale in #26060 - [Whisper Tokenizer] Encode timestamps by @sanchit-gandhi in #26054
- [
PEFT] Fix PEFT + gradient checkpointing by @younesbelkada in #25846 - [MusicGen] Add streamer to generate by @sanchit-gandhi in #25320
- Fix beam search when using model parallel by @pfldy2850 in #24969
- [MusicGen] Add sampling rate to config by @sanchit-gandhi in #26136
- [Whisper] Fix word-level timestamps for audio < 30 seconds by @xenova in #25607
- [BLIP-2] Improve conversion script by @NielsRogge in #24854
- IDEFICS: allow interpolation of vision's pos embeddings by @leot13 in #26029
- [TTA Pipeline] Test MusicGen and VITS by @sanchit-gandhi in #26146
- Tweaks to Chat Templates docs by @Rocketknight1 in #26168
- [Whisper] Check length of prompt + max new tokens by @sanchit-gandhi in #26164
- Update notebook.py to support multi eval datasets by @matrix1001 in #25796
- Fix pad to multiple of by @ArthurZucker in #25732
- [docs] IDEFICS guide and task guides restructure by @MKhalusova in #26035
- [PEFT] Allow PEFT model dict to be loaded by @patrickvonplaten in #25721
- No doctest for
convert_bros_to_pytorch.pyby @ydshieh in #26212 - Remove
utils/documentation_tests.txtby @ydshieh in #26213 - moved
ctrltoSalesforce/ctrlby @julien-c in #26183 - Fix ConversationalPipeline tests by @Rocketknight1 in #26217
- [FSMT] Fix non-shared weights by @LysandreJik in #26187
- refactor decay_parameters production into its own function by @shijie-wu in #26152
- refactor: change default block_size in block size > max position embeddings by @pphuc25 in #26069
- [Wav2Vec2-Conf / LLaMA] Style fix by @sanchit-gandhi in #26188
- [Permisson] Style fix by @sanchit-gandhi in #26228
- [Check] Fix config docstring by @sanchit-gandhi in #26222
- 🌐 [i18n-KO] Translated
whisper.mdto Korean by @nuatmochoi in #26002 - Create the return value on device to avoid unnecessary copying from CPU by @mksit in #26151
- [AutoBackbone] Add test by @NielsRogge in #26094
- Update README.md by @NinoRisteski in #26198
- Update add_new_pipeline.md by @NinoRisteski in #26197
- [docs] Fix model reference in zero shot image classification example by @Aleksandar1932 in #26206
- Fix the gitlab user mention in issue templates to the correct user by @muellerz in #26237
- Fix some docstring in image processors by @ydshieh in #26235
- Fix gated repo tests by @Wauplin in #26257
- Fix
Errornot captured in PR doctesting by @ydshieh in #26215 - DeepSpeed ZeRO-3 handling when resizing embedding layers by @pacman100 in #26259
- [FIX] resize_token_embeddings by @passaglia in #26102
- FSDP tests and checkpointing fixes by @pacman100 in #26180
- fix name error when accelerate is not available by @pacman100 in #26278
- Update bros checkpoint by @jinhopark8345 in #26277
- Integrate AMD GPU in CI/CD environment by @mfuntowicz in #26007
- Rewrite for custom code warning messages by @Rocketknight1 in #26291
- fix deepspeed available detection by @fxmarty in #26252
- add bbox input validation by @jinhopark8345 in #26294
- include changes from llama by @ArthurZucker in #26260
- [
Trainer] Refactor trainer + bnb logic by @younesbelkada in #26248 - add custom RMSNorm to
ALL_LAYERNORM_LAYERSby @shijie-wu in #26227 - Keep relevant weights in fp32 when
model._keep_in_fp32_modulesis set even whenaccelerateis not installed by @fxmarty in #26225 - Fix FSMT weight sharing by @LysandreJik in #26292
- update hf hub dependency to be compatible with the new tokenizers by @ArthurZucker in #26301
- Porting the torchaudio kaldi fbank implementation to audio_utils by @ylacombe in #26182
- More error message fixup, plus some linebreaks! by @Rocketknight1 in #26296
- [QUICK FIX LINK] Update trainer.py by @SoyGema in #26293
- Use CircleCI
store_test_resultsby @ydshieh in #26223 - Fix doctest CI by @ydshieh in #26324
- [doc] fixed indices in obj detection example by @MKhalusova in #26343
- [TTA Pipeline] Fix MusicGen test by @sanchit-gandhi in #26348
- Add image to image pipeline by @LeviVasconcelos in #25393
- feat: adding num_proc to load_dataset by @pphuc25 in #26326
- Fixed unclosed p tags by @HanSeokhyeon in #26240
- Update add_new_model.md by @NinoRisteski in #26365
- Fix MusicGen logging error by @osanseviero in #26370
- [docs] removed MaskFormerSwin and TimmBackbone from the table on index.md by @MKhalusova in #26347
- Update tiny model information and pipeline tests by @ydshieh in #26285
- Add Russian localization for README by @qweme32 in #26208
- 🌐 [i18n-KO] Translated
audio_classification.mdxto Korean by @gabrielwithappy in #26200 - [ViTMatte] Add resources by @NielsRogge in #26317
- Deleted duplicate sentence by @titi-devv in #26394
- added support for gradient checkpointing in ESM models by @sanjeevk-os in #26386
- Fix DeepSpeed issue with Idefics by @HugoLaurencon in #26393
- Add torch
RMSPropoptimizer by @natolambert in #26425 - Fix padding for IDEFICS by @shauray8 in #26396
- Update semantic_segmentation.md by @zekaouinoureddine in #26419
- Fixing tokenizer when
transformersis installed withouttokenizersby @urialon in #26236 - [
FA/tests] Add use_cache tests for FA models by @younesbelkada in #26415 - add bf16 mixed precision support for NPU by @statelesshz in #26163
- [
PEFT] Fix PEFT multi adapters support by @younesbelkada in #26407 - Fix failing doctest by @LysandreJik in #26450
- Update
runs-onin workflow files by @ydshieh in #26435 - [i18n-DE] Complete first toc chapter by @flozi00 in #26311
- 🌐 [i18n-KO] Translated
debugging.mdto Korean by @wonhyeongseo in #26246 - 🌐 [i18n-KO] Translated
perf_train_gpu_many.mdto Korean by @wonhyeongseo in #26244 - optimize VRAM for calculating pos_bias in LayoutLM v2, v3 by @NormXU in #26139
- Fix
cos_sindevice issue in Falcon model by @ydshieh in #26448 - docs: change assert to raise and some small docs by @pphuc25 in #26232
- change mention of decoder_input_ids to input_ids and same with decode_inputs_embeds by @tmabraham in #26406
- [VITS] Fix speaker_embed device mismatch by @fakhirali in #26115
- [
PEFT] introducingadapter_kwargsfor loading adapters from different Hub location (subfolder,revision) than the base model by @younesbelkada in #26270 - Do not warn about unexpected decoder weights when loading T5EncoderModel and LongT5EncoderModel by @fleonce in #26211
- fix_mbart_tied_weights by @SunMarc in #26422
- Esm checkpointing by @Amelie-Schreiber in #26454
- [Whisper Tokenizer] Make decoding faster after adding timestamps by @sanchit-gandhi in #26299
- [docs] Update offline mode docs by @stevhliu in #26478
- [docs] navigation improvement between text gen pipelines and text gen params by @MKhalusova in #26477
- Skip 2 failing persimmon pipeline tests for now by @ydshieh in #26485
- Avoid all-zeor attnetion mask used in testing by @ydshieh in #26469
- [Flax Examples] Seq2Seq ASR Fine-Tuning Script by @sanchit-gandhi in #21764
- [ASR Pipe] Improve docs and error messages by @sanchit-gandhi in #26476
- Revert falcon exception by @LysandreJik in #26472
- Fix num_heads in _upad_input by @fs4r in #26490
- Fix requests connection error during modelcard creation by @jphme in #26518
- Fix issue of canine forward requiring input_ids anyway by @marcmk6 in #26290
- Fix broken link to video classification task by @HelgeS in #26487
- [
PEFT] Pass token when callingfind_adapter_configby @younesbelkada in #26488 - [
core/auto] Fix bnb test with code revision + bug with code revision by @younesbelkada in #26431 - Fix model integration ci by @ArthurZucker in #26322
- [
PEFT] Protectadapter_kwargscheck by @younesbelkada in #26537 - Remove-warns by @ArthurZucker in #26483
- [Doctest] Add configuration_roformer.py by @Adithya4720 in #26530
- Code-llama-nit by @ArthurZucker in #26300
- add build_inputs_with_special_tokens to LlamaFast by @ArthurZucker in #26297
- 🌐 [i18n-KO] Translated
tokenizer_summary.mdto Korean by @wonhyeongseo in #26243 - [i18n-DE] contribute chapter by @flozi00 in #26481
- [RFC, Logging] Change warning to info by @patrickvonplaten in #26545
- Add tokenizer kwargs to fill mask pipeline. by @nmcahill in #26234
- [Wav2Vec2 and Co] Update init tests for PT 2.1 by @sanchit-gandhi in #26494
- [AMD] Add initial version for run_tests_multi_gpu by @mfuntowicz in #26346
- [Doctest] Add
configuration_encoder_decoder.pyby @SrijanSahaySrivastava in #26519 - [InternLM] Add support for InternLM by @Rocketknight1 in #26302
Significant community contributions
The following contributors have made significant changes to the library over the last release:
- @jinhopark8345
- Add BROS (#23190)
- Update bros checkpoint (#26277)
- add bbox input validation (#26294)
- @qweme32
- Add Russian localization for README (#26208)
- @Bam4d
- [Mistral] Mistral-7B-v0.1 support (#26447)
- @flozi00
- [i18n-DE] Complete first toc chapter (#26311)
- [i18n-DE] contribute chapter (#26481)
- @wonhyeongseo
- 🌐 [i18n-KO] Translated
debugging.mdto Korean (#26246) - 🌐 [i18n-KO] Translated
perf_train_gpu_many.mdto Korean (#26244) - 🌐 [i18n-KO] Translated
tokenizer_summary.mdto Korean (#26243)
- 🌐 [i18n-KO] Translated