Transformers Versions Save
🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX.
v4.40.1
3 weeks agoKudos to @pcuenca for the prompt fix in:
- Make EosTokenCriteria compatible with mps #30376
To support EosTokenCriteria on MPS while pytorch adds this functionality.
v4.40.0
4 weeks agoNew model additions
Llama 3
Llama 3 is supported in this release through the Llama 2 architecture and some fixes in the tokenizers library.
Idefics2

The Idefics2 model was created by the Hugging Face M4 team and authored by Léo Tronchon, Hugo Laurencon, Victor Sanh. The accompanying blog post can be found here.
Idefics2 is an open multimodal model that accepts arbitrary sequences of image and text inputs and produces text outputs. The model can answer questions about images, describe visual content, create stories grounded on multiple images, or simply behave as a pure language model without visual inputs. It improves upon IDEFICS-1, notably on document understanding, OCR, or visual reasoning. Idefics2 is lightweight (8 billion parameters) and treats images in their native aspect ratio and resolution, which allows for varying inference efficiency.
- Add Idefics2 by @amyeroberts in #30253
Recurrent Gemma
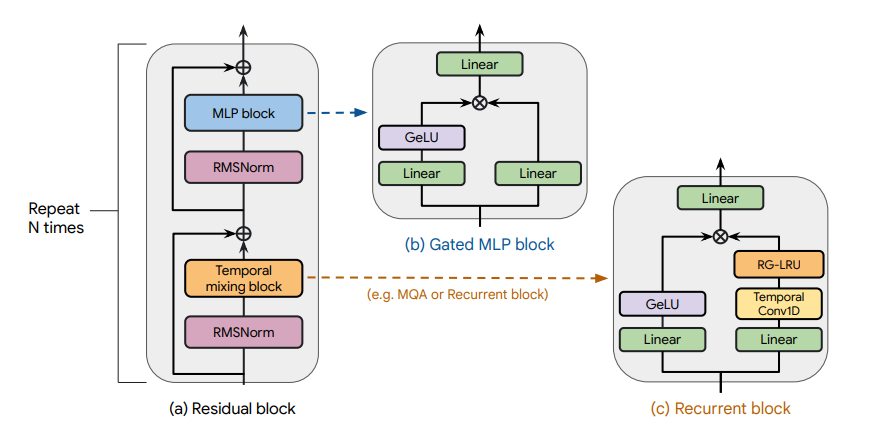
Recurrent Gemma architecture. Taken from the original paper.
The Recurrent Gemma model was proposed in RecurrentGemma: Moving Past Transformers for Efficient Open Language Models by the Griffin, RLHF and Gemma Teams of Google.
The abstract from the paper is the following:
We introduce RecurrentGemma, an open language model which uses Google’s novel Griffin architecture. Griffin combines linear recurrences with local attention to achieve excellent performance on language. It has a fixed-sized state, which reduces memory use and enables efficient inference on long sequences. We provide a pre-trained model with 2B non-embedding parameters, and an instruction tuned variant. Both models achieve comparable performance to Gemma-2B despite being trained on fewer tokens.
- Add recurrent gemma by @ArthurZucker in #30143
Jamba
Jamba is a pretrained, mixture-of-experts (MoE) generative text model, with 12B active parameters and an overall of 52B parameters across all experts. It supports a 256K context length, and can fit up to 140K tokens on a single 80GB GPU.
As depicted in the diagram below, Jamba’s architecture features a blocks-and-layers approach that allows Jamba to successfully integrate Transformer and Mamba architectures altogether. Each Jamba block contains either an attention or a Mamba layer, followed by a multi-layer perceptron (MLP), producing an overall ratio of one Transformer layer out of every eight total layers.
Jamba introduces the first HybridCache object that allows it to natively support assisted generation, contrastive search, speculative decoding, beam search and all of the awesome features from the generate API!
- Add jamba by @tomeras91 in #29943
DBRX
DBRX is a transformer-based decoder-only large language model (LLM) that was trained using next-token prediction. It uses a fine-grained mixture-of-experts (MoE) architecture with 132B total parameters of which 36B parameters are active on any input.
It was pre-trained on 12T tokens of text and code data. Compared to other open MoE models like Mixtral-8x7B and Grok-1, DBRX is fine-grained, meaning it uses a larger number of smaller experts. DBRX has 16 experts and chooses 4, while Mixtral-8x7B and Grok-1 have 8 experts and choose 2.
This provides 65x more possible combinations of experts and the authors found that this improves model quality. DBRX uses rotary position encodings (RoPE), gated linear units (GLU), and grouped query attention (GQA).
- Add DBRX Model by @abhi-mosaic in #29921
OLMo
The OLMo model was proposed in OLMo: Accelerating the Science of Language Models by Dirk Groeneveld, Iz Beltagy, Pete Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Harsh Jha, Hamish Ivison, Ian Magnusson, Yizhong Wang, Shane Arora, David Atkinson, Russell Authur, Khyathi Raghavi Chandu, Arman Cohan, Jennifer Dumas, Yanai Elazar, Yuling Gu, Jack Hessel, Tushar Khot, William Merrill, Jacob Morrison, Niklas Muennighoff, Aakanksha Naik, Crystal Nam, Matthew E. Peters, Valentina Pyatkin, Abhilasha Ravichander, Dustin Schwenk, Saurabh Shah, Will Smith, Emma Strubell, Nishant Subramani, Mitchell Wortsman, Pradeep Dasigi, Nathan Lambert, Kyle Richardson, Luke Zettlemoyer, Jesse Dodge, Kyle Lo, Luca Soldaini, Noah A. Smith, Hannaneh Hajishirzi.
OLMo is a series of Open Language Models designed to enable the science of language models. The OLMo models are trained on the Dolma dataset. We release all code, checkpoints, logs (coming soon), and details involved in training these models.
- Add OLMo model family by @2015aroras in #29890
Qwen2MoE
Qwen2MoE is the new model series of large language models from the Qwen team. Previously, we released the Qwen series, including Qwen-72B, Qwen-1.8B, Qwen-VL, Qwen-Audio, etc.
Model Details Qwen2MoE is a language model series including decoder language models of different model sizes. For each size, we release the base language model and the aligned chat model. Qwen2MoE has the following architectural choices:
Qwen2MoE is based on the Transformer architecture with SwiGLU activation, attention QKV bias, group query attention, mixture of sliding window attention and full attention, etc. Additionally, we have an improved tokenizer adaptive to multiple natural languages and codes. Qwen2MoE employs Mixture of Experts (MoE) architecture, where the models are upcycled from dense language models. For instance, Qwen1.5-MoE-A2.7B is upcycled from Qwen-1.8B. It has 14.3B parameters in total and 2.7B activated parameters during runtime, while it achieves comparable performance with Qwen1.5-7B, with only 25% of the training resources.
- Add Qwen2MoE by @bozheng-hit in #29377
Grounding Dino
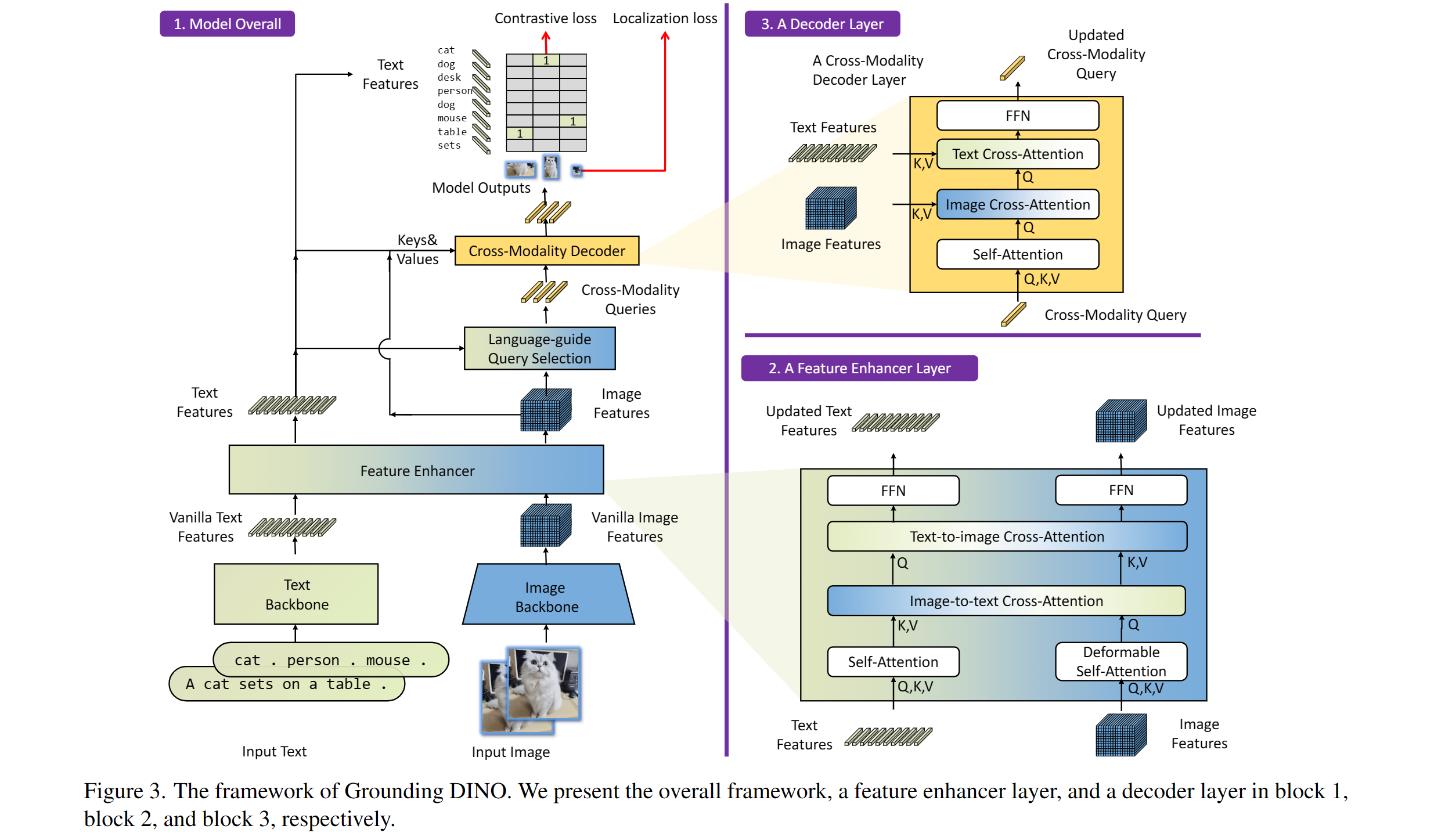
Taken from the original paper.
The Grounding DINO model was proposed in Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection by Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang. Grounding DINO extends a closed-set object detection model with a text encoder, enabling open-set object detection. The model achieves remarkable results, such as 52.5 AP on COCO zero-shot.
- Adding grounding dino by @EduardoPach in #26087
Static pretrained maps
Static pretrained maps have been removed from the library's internals and are currently deprecated. These used to reflect all the available checkpoints for a given architecture on the Hugging Face Hub, but their presence does not make sense in light of the huge growth of checkpoint shared by the community.
With the objective of lowering the bar of model contributions and reviewing, we first start by removing legacy objects such as this one which do not serve a purpose.
- Remove static pretrained maps from the library's internals by @LysandreJik in #29112
Notable improvements
Processors improvements
Processors are ungoing changes in order to uniformize them and make them clearer to use.
- Separate out kwargs in processor by @amyeroberts in #30193
- [Processor classes] Update docs by @NielsRogge in #29698
SDPA
- re-introduced the fast path for sdpa by @fxmarty in #30070
Push to Hub for pipelines
Pipelines can now be pushed to Hub using a convenient push_to_hub method.
- add
push_to_hubto pipeline by @not-lain in #29172
Flash Attention 2 for more models (M2M100, NLLB, GPT2, MusicGen) !
Thanks to the community contribution, Flash Attention 2 has been integrated for more architectures
- Adding Flash Attention 2 Support for GPT2 by @EduardoPach in #29226
- Add Flash Attention 2 support to Musicgen and Musicgen Melody by @ylacombe in #29939
- Add Flash Attention 2 to M2M100 model by @visheratin in #30256
Improvements and bugfixes
- [docs] Remove redundant
-andthefrom custom_tools.md by @windsonsea in #29767 - Fixed typo in quantization_config.py by @kurokiasahi222 in #29766
- OWL-ViT box_predictor inefficiency issue by @RVV-karma in #29712
- Allow
-OOmode fordocstring_decoratorby @matthid in #29689 - fix issue with logit processor during beam search in Flax by @giganttheo in #29636
- Fix docker image build for
Latest PyTorch + TensorFlow [dev]by @ydshieh in #29764 - [
LlavaNext] Fix llava next unsafe imports by @ArthurZucker in #29773 - Cast bfloat16 to float32 for Numpy conversions by @Rocketknight1 in #29755
- Silence deprecations and use the DataLoaderConfig by @muellerzr in #29779
- Add deterministic config to
set_seedby @muellerzr in #29778 - Add support for
torch_dtypein the run_mlm example by @jla524 in #29776 - Generate: remove legacy generation mixin imports by @gante in #29782
- Llama: always convert the causal mask in the SDPA code path by @gante in #29663
- Prepend
bos tokento Blip generations by @zucchini-nlp in #29642 - Change in-place operations to out-of-place in LogitsProcessors by @zucchini-nlp in #29680
- [
quality] update quality check to make sure we check imports 😈 by @ArthurZucker in #29771 - Fix type hint for train_dataset param of Trainer.init() to allow IterableDataset. Issue 29678 by @stevemadere in #29738
- Enable AMD docker build CI by @IlyasMoutawwakil in #29803
- Correct llava mask & fix missing setter for
vocab_sizeby @fxmarty in #29389 - rm input dtype change in CPU by @jiqing-feng in #28631
- Generate: remove unused attributes in
AssistedCandidateGeneratorby @gante in #29787 - replaced concatenation to f-strings to improve readability and unify … by @igeni in #29785
- [
cleanup] vestiges of causal mask by @ArthurZucker in #29806 - Complete security policy with mentions of remote code by @LysandreJik in #29707
- [
SuperPoint] Fix doc example by @amyeroberts in #29816 - [DOCS] Fix typo for llava next docs by @aliencaocao in #29829
- model_summary.md - Restore link to Harvard's Annotated Transformer. by @gamepad-coder in #29702
- Fix the behavior of collecting 'num_input_tokens_seen' by @YouliangHUANG in #29099
- Populate torch_dtype from model to pipeline by @B-Step62 in #28940
- remove quotes in code example by @johko in #29812
- Add warnings if training args differ from checkpoint trainer state by @jonflynng in #29255
- Replace 'decord' with 'av' in VideoClassificationPipeline by @Tyx-main in #29747
- Fix header in IFE task guide by @merveenoyan in #29859
- [docs] Indent ordered list in add_new_model.md by @windsonsea in #29796
- Allow
bos_token_id is Noneduring the generation withinputs_embedsby @LZHgrla in #29772 - Add
cosine_with_min_lrscheduler in Trainer by @liuyanyi in #29341 - Disable AMD memory benchmarks by @IlyasMoutawwakil in #29871
- Set custom_container in build docs workflows by @Wauplin in #29855
- Support
num_attention_heads!=num_key_value_headsin Flax Llama Implementation by @bminixhofer in #29557 - Mamba
slow_forwardgradient fix by @vasqu in #29563 - Fix 29807, sinusoidal positional encodings overwritten by post_init() by @hovnatan in #29813
- Reimplement "Automatic safetensors conversion when lacking these files" by @LysandreJik in #29846
- fix fuyu device_map compatibility by @SunMarc in #29880
- Move
eos_token_idto stopping criteria by @zucchini-nlp in #29459 - add Cambricon MLUs support by @huismiling in #29627
- MixtralSparseMoeBlock: add gate jitter by @lorenzoverardo in #29865
- Fix typo in T5Block error message by @Mingosnake in #29881
- [
make fix-copies] update and help by @ArthurZucker in #29924 - [
GptNeox] don't gather on pkv when using the trainer by @ArthurZucker in #29892 - [
pipeline]. Zero shot add doc warning by @ArthurZucker in #29845 - [doc] fix some typos and add
xputo the testing documentation by @faaany in #29894 - Tests: replace
torch.testing.assert_allclosebytorch.testing.assert_closeby @gante in #29915 - Add beam search visualizer to the doc by @aymeric-roucher in #29876
- Safe import of LRScheduler by @amyeroberts in #29919
- add functions to inspect model and optimizer status to trainer.py by @CKeibel in #29838
- RoPE models: add numerical sanity-check test for RoPE scaling by @gante in #29808
- [
Mamba] from pretrained issue withself.embeddingsby @ArthurZucker in #29851 - [
TokenizationLlama] fix the way we convert tokens to strings to keep leading spaces 🚨 breaking fix by @ArthurZucker in #29453 - Allow GradientAccumulationPlugin to be configured from AcceleratorConfig by @fabianlim in #29589
- [
BC] Fix BC for other libraries by @ArthurZucker in #29934 - Fix doc issue #29758 in DebertaV2Config class by @vinayakkgarg in #29842
- [
LlamaSlowConverter] Slow to Fast better support by @ArthurZucker in #29797 - Update installs in image classification doc by @MariaHei in #29947
- [
StableLm] Add QK normalization and Parallel Residual Support by @jon-tow in #29745 - Mark
test_eager_matches_sdpa_generateflaky for some models by @ydshieh in #29479 - Super tiny fix 12 typos about "with with" by @fzyzcjy in #29926
- Fix rope theta for OpenLlama by @jla524 in #29893
- Add warning message for
run_qa.pyby @jla524 in #29867 - fix: get mlflow version from mlflow-skinny by @clumsy in #29918
- Reset alarm signal when the function is ended by @coldnight in #29706
- Update model card and link of blog post. by @bozheng-hit in #29928
- [
BC] Fix BC for AWQ quant by @TechxGenus in #29965 - Rework tests to compare trainer checkpoint args by @muellerzr in #29883
- Fix FA2 tests by @ylacombe in #29909
- Fix copies main ci by @ArthurZucker in #29979
- [tests] fix the wrong output in
ImageToTextPipelineTests.test_conditional_generation_llavaby @faaany in #29975 - Generate: move misplaced test by @gante in #29902
- [docs] Big model loading by @stevhliu in #29920
- [
generate] fix breaking change for patch by @ArthurZucker in #29976 - Fix 29807 sinusoidal positional encodings in Flaubert, Informer and XLM by @hovnatan in #29904
- [bnb] Fix bug in
_replace_with_bnb_linearby @SunMarc in #29958 - Adding FlaxNoRepeatNGramLogitsProcessor by @giganttheo in #29677
- [Docs] Make an ordered list prettier in add_tensorflow_model.md by @windsonsea in #29949
- Fix
skip_special_tokensforWav2Vec2CTCTokenizer._decodeby @msublee in #29311 - Hard error when ignoring tensors. by @Narsil in #27484)
- Generate: fix logits processors doctests by @gante in #29718
- Fix
remove_columnsintext-classificationexample by @mariosasko in #29351 - Update
tests/utils/tiny_model_summary.jsonby @ydshieh in #29941 - Make EncodecModel.decode ONNX exportable by @fxmarty in #29913
- Fix Swinv2ForImageClassification NaN output by @miguelm-almeida in #29981
- Fix Qwen2Tokenizer by @jklj077 in #29929
- Fix
kwargshandling ingenerate_with_fallbackby @cifkao in #29225 - Fix probability computation in
WhisperNoSpeechDetectionwhen recomputing scores by @cifkao in #29248 - Fix vipllava for generation by @zucchini-nlp in #29874
- [docs] Fix audio file by @stevhliu in #30006
- Superpoint imports fix by @zucchini-nlp in #29898
- [
Main CIs] Fix the red cis by @ArthurZucker in #30022 - Make clearer about zero_init requirements by @muellerzr in #29879
- Enable multi-device for efficientnet by @jla524 in #29989
- Add a converter from mamba_ssm -> huggingface mamba by @byi8220 in #29705
- [
ProcessingIdefics] Attention mask bug with padding by @byi8220 in #29449 - Add
whispertoIMPORTANT_MODELSby @ydshieh in #30046 - skip
test_encode_decode_fast_slow_all_tokensfor now by @ydshieh in #30044 - if output is tuple like facebook/hf-seamless-m4t-medium, waveform is … by @sywangyi in #29722
- Fix mixtral ONNX Exporter Issue. by @AdamLouly in #29858
- [Trainer] Allow passing image processor by @NielsRogge in #29896
- [bnb] Fix offload test by @SunMarc in #30039
- Update quantizer_bnb_4bit.py: In the ValueError string there should be "....you need to set
llm_int8_enable_fp32_cpu_offload=True...." instead of "load_in_8bit_fp32_cpu_offload=True". by @miRx923 in #30013 - [test fetcher] Always include the directly related test files by @ydshieh in #30050
- Fix
torch.fxsymbolic tracing for LLama by @michaelbenayoun in #30047 - Refactor daily CI workflow by @ydshieh in #30012
- Add docstrings and types for MambaCache by @koayon in #30023
- Fix auto tests by @ydshieh in #30067
- Fix whisper kwargs and generation config by @zucchini-nlp in #30018
- doc: Correct spelling mistake by @caiyili in #30107
- [Whisper] Computing features on GPU in batch mode for whisper feature extractor. by @vaibhavagg303 in #29900
- Change log level to warning for num_train_epochs override by @xu-song in #30014
- Make MLFlow version detection more robust and handles mlflow-skinny by @helloworld1 in #29957
- updated examples/pytorch/language-modeling scripts and requirements.txt to require datasets>=2.14.0 by @Patchwork53 in #30120
- [tests] add
require_bitsandbytesmarker by @faaany in #30116 - fixing issue 30034 - adding data format for run_ner.py by @JINO-ROHIT in #30088
- Patch fix - don't use safetensors for TF models by @amyeroberts in #30118
- [#29174] ImportError Fix: Trainer with PyTorch requires accelerate>=0.20.1 Fix by @UtkarshaGupte in #29888
- Accept token in trainer.push_to_hub() by @mapmeld in #30093
- fix learning rate display in trainer when using galore optimizer by @vasqu in #30085
- Fix falcon with SDPA, alibi but no passed mask by @fxmarty in #30123
- Trainer / Core : Do not change init signature order by @younesbelkada in #30126
- Make vitdet jit trace complient by @fxmarty in #30065
- Fix typo at ImportError by @DrAnaximandre in #30090
- Adding
mpsas device forPipelineclass by @fnhirwa in #30080 - Fix failing DeepSpeed model zoo tests by @pacman100 in #30112
- Add datasets.Dataset to Trainer's train_dataset and eval_dataset type hints by @ringohoffman in #30077
- Fix docs Pop2Piano by @zucchini-nlp in #30140
- Revert workaround for TF safetensors loading by @Rocketknight1 in #30128
- [Trainer] Fix default data collator by @NielsRogge in #30142
- [Trainer] Undo #29896 by @NielsRogge in #30129
- Fix slow tests for important models to be compatible with A10 runners by @ydshieh in #29905
- Send headers when converting safetensors by @ydshieh in #30144
- Fix quantization tests by @SunMarc in #29914
- [docs] Fix image segmentation guide by @stevhliu in #30132
- [CI] Fix setup by @SunMarc in #30147
- Fix length related warnings in speculative decoding by @zucchini-nlp in #29585
- Fix and simplify semantic-segmentation example by @qubvel in #30145
- [CI] Quantization workflow fix by @SunMarc in #30158
- [tests] make 2 tests device-agnostic by @faaany in #30008
- Add str to TrainingArguments report_to type hint by @ringohoffman in #30078
- [UDOP] Fix tests by @NielsRogge in #29573
- [UDOP] Improve docs, add resources by @NielsRogge in #29571
- Fix accelerate kwargs for versions <0.28.0 by @vasqu in #30086
- Fix typing annotation in hf_argparser by @xu-song in #30156
- Fixing a bug when MlFlow try to log a torch.tensor by @etiennebonnafoux in #29932
- Fix natten install in docker by @ydshieh in #30161
- FIX / bnb: fix torch compatiblity issue with
itemizeby @younesbelkada in #30162 - Update config class check in auto factory by @Rocketknight1 in #29854
- Fixed typo in comments/documentation for Pipelines documentation by @DamonGuzman in #30170
- Fix Llava chat template examples by @lewtun in #30130
- Guard XLA version imports by @muellerzr in #30167
- chore: remove repetitive words by @hugehope in #30174
- fix: Fixed
ruffconfiguration to avoid deprecated configuration warning by @Sai-Suraj-27 in #30179 - Refactor Cohere Model by @saurabhdash2512 in #30027
- Update output of SuperPointForKeypointDetection by @NielsRogge in #29809
- Falcon: make activation, ffn_hidden_size configurable by @sshleifer in #30134
- Docs PR template by @stevhliu in #30171
- ENH: [
CI] Add new workflow to run slow tests of important models on push main if they are modified by @younesbelkada in #29235 - Fix pipeline logger.warning_once bug by @amyeroberts in #30195
- fix: Replaced deprecated
logger.warnwithlogger.warningby @Sai-Suraj-27 in #30197 - fix typo by @mdeff in #30220
- fix fuyu doctest by @molbap in #30215
- Fix
RecurrentGemmaIntegrationTest.test_2b_sampleby @ydshieh in #30222 - Update modeling_bark.py by @bes-dev in #30221
- Fix/Update for doctest by @ydshieh in #30216
- Fixed config.json download to go to user-supplied cache directory by @ulatekh in #30189
- Add test for parse_json_file and change typing to os.PathLike by @xu-song in #30183
- fix: Replace deprecated
assertEqualswithassertEqualby @Sai-Suraj-27 in #30241 - Set pad_token in run_glue_no_trainer.py #28534 by @JINO-ROHIT in #30234
- fix: Replaced deprecated
typing.Textwithstrby @Sai-Suraj-27 in #30230 - Refactor doctest by @ydshieh in #30210
- fix: Fixed
type annotationfor compatability with python 3.8 by @Sai-Suraj-27 in #30243 - Fix doctest more (for
docs/source/en) by @ydshieh in #30247 - round epoch only in console by @xdedss in #30237
- update github actions packages' version to suppress warnings by @ydshieh in #30249
- [tests] add the missing
require_torch_multi_gpuflag by @faaany in #30250 - [Docs] Update recurrent_gemma.md for some minor nits by @sayakpaul in #30238
- Remove incorrect arg in codellama doctest by @Rocketknight1 in #30257
- Update
ko/_toctree.ymlby @jungnerd in #30062 - More fixes for doctest by @ydshieh in #30265
- FIX: Fix corner-case issue with the important models workflow by @younesbelkada in #30212
- FIX: Fix 8-bit serialization tests by @younesbelkada in #30051
- Allow for str versions of dicts based on typing by @muellerzr in #30227
- Workflow: Update tailscale to release version by @younesbelkada in #30268
- Raise relevent err when wrong type is passed in as the accelerator_config by @muellerzr in #29997
- BLIP - fix pt-tf equivalence test by @amyeroberts in #30258
- fix: Fixed a
raisestatement by @Sai-Suraj-27 in #30275 - Fix test fetcher (doctest) +
Idefics2's doc example by @ydshieh in #30274 - Fix SDPA sliding window compatibility by @fxmarty in #30127
- Fix SpeechT5 forward docstrings by @ylacombe in #30287
- FIX / AWQ: Fix failing exllama test by @younesbelkada in #30288
- Configuring Translation Pipelines documents update #27753 by @UtkarshaGupte in #29986
- Enable fx tracing for Mistral by @zucchini-nlp in #30209
- Fix test
ExamplesTests::test_run_translationby @ydshieh in #30281 - Fix
Fatal Python error: Bus errorinZeroShotAudioClassificationPipelineTestsby @ydshieh in #30283 - FIX: Fix push important models CI by @younesbelkada in #30291
- Add token type ids to CodeGenTokenizer by @st81 in #29265
- Add strategy to store results in evaluation loop by @qubvel in #30267
- Upgrading to tokenizers 0.19.0 by @Narsil in #30289
- Re-enable SDPA's FA2 path by @fxmarty in #30070
- Fix quality Olmo + SDPA by @fxmarty in #30302
- Fix donut token2json multiline by @qubvel in #30300
- Fix all torch pipeline failures except one by @ydshieh in #30290
- Add atol for sliding window test by @fxmarty in #30303
- Fix RecurrentGemma device_map by @SunMarc in #30273
- Revert "Re-enable SDPA's FA2 path by @ArthurZucker in #30070)"
- Do not drop mask with SDPA for more cases by @fxmarty in #30311
- FIX: Fixes unexpected behaviour for Llava / LLama & AWQ Fused modules + revert #30070 at the same time by @younesbelkada in #30317
Significant community contributions
The following contributors have made significant changes to the library over the last release:
- @bozheng-hit
- Add Qwen2MoE (#29377)
- Update model card and link of blog post. (#29928)
- @EduardoPach
- Adding Flash Attention 2 Support for GPT2 (#29226)
- Adding grounding dino (#26087)
- @2015aroras
- Add OLMo model family (#29890)
- @tomeras91
- Add jamba (#29943)
- @abhi-mosaic
- Add DBRX Model (#29921)
v4.39.3
1 month agoThe AWQ issue persisted, and there was a regression reported with beam search and input embeddings.
Changes
- Fix BC for AWQ quant #29965
- generate fix breaking change for patch #29976
v4.39.2
1 month agoSeries of fixes for backwards compatibility (AutoAWQ and other quantization libraries, imports from trainer_pt_utils) and functionality (LLaMA tokenizer conversion)
- Safe import of LRScheduler #29919
- [
BC] Fix BC for other libraries #29934 - [
LlamaSlowConverter] Slow to Fast better support #29797
v4.39.1
1 month agoPatch release to fix some breaking changes to LLaVA model, fixes/cleanup for Cohere & Gemma and broken doctest
- Correct llava mask & fix missing setter for
vocab_size#29389 - [
cleanup] vestiges of causal mask #29806 - [
SuperPoint] Fix doc example (https://github.com/huggingface/transformers/pull/29816)
v4.39.0
1 month agov4.39.0
🚨 VRAM consumption 🚨
The Llama, Cohere and the Gemma model both no longer cache the triangular causal mask unless static cache is used. This was reverted by #29753, which fixes the BC issues w.r.t speed , and memory consumption, while still supporting compile and static cache. Small note, fx is not supported for both models, a patch will be brought very soon!
New model addition
Cohere open-source model
Command-R is a generative model optimized for long context tasks such as retrieval augmented generation (RAG) and using external APIs and tools. It is designed to work in concert with Cohere's industry-leading Embed and Rerank models to provide best-in-class integration for RAG applications and excel at enterprise use cases. As a model built for companies to implement at scale, Command-R boasts:
- Strong accuracy on RAG and Tool Use
- Low latency, and high throughput
- Longer 128k context and lower pricing
- Strong capabilities across 10 key languages
- Model weights available on HuggingFace for research and evaluation
- Cohere Model Release by @saurabhdash2512 in #29622
LLaVA-NeXT (llava v1.6)
Llava next is the next version of Llava, which includes better support for non padded images, improved reasoning, OCR, and world knowledge. LLaVA-NeXT even exceeds Gemini Pro on several benchmarks.
Compared with LLaVA-1.5, LLaVA-NeXT has several improvements:
- Increasing the input image resolution to 4x more pixels. This allows it to grasp more visual details. It supports three aspect ratios, up to 672x672, 336x1344, 1344x336 resolution.
- Better visual reasoning and OCR capability with an improved visual instruction tuning data mixture.
- Better visual conversation for more scenarios, covering different applications.
- Better world knowledge and logical reasoning.
- Along with performance improvements, LLaVA-NeXT maintains the minimalist design and data efficiency of LLaVA-1.5. It re-uses the pretrained connector of LLaVA-1.5, and still uses less than 1M visual instruction tuning samples. The largest 34B variant finishes training in ~1 day with 32 A100s.*
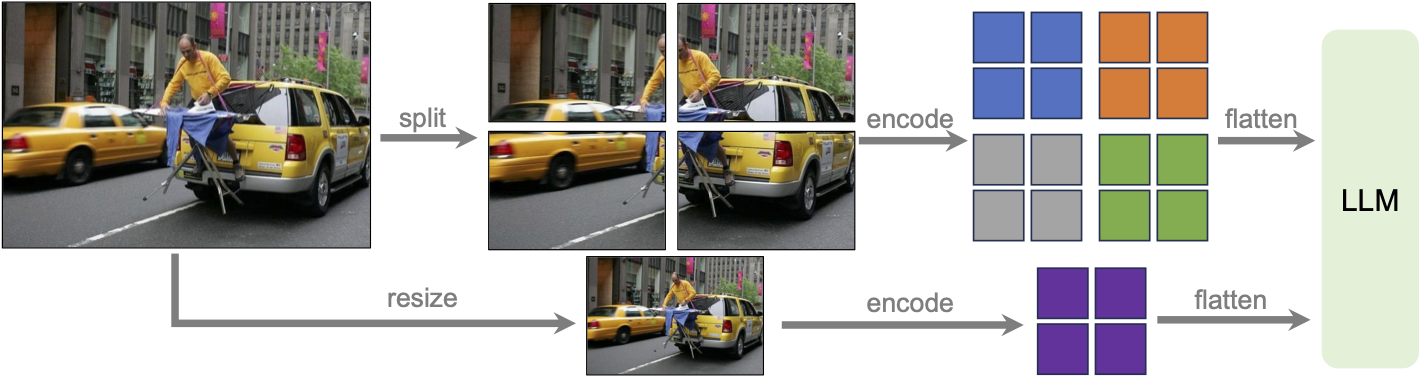
LLaVa-NeXT incorporates a higher input resolution by encoding various patches of the input image. Taken from the original paper.
MusicGen Melody
The MusicGen Melody model was proposed in Simple and Controllable Music Generation by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
MusicGen Melody is a single stage auto-regressive Transformer model capable of generating high-quality music samples conditioned on text descriptions or audio prompts. The text descriptions are passed through a frozen text encoder model to obtain a sequence of hidden-state representations. MusicGen is then trained to predict discrete audio tokens, or audio codes, conditioned on these hidden-states. These audio tokens are then decoded using an audio compression model, such as EnCodec, to recover the audio waveform.
Through an efficient token interleaving pattern, MusicGen does not require a self-supervised semantic representation of the text/audio prompts, thus eliminating the need to cascade multiple models to predict a set of codebooks (e.g. hierarchically or upsampling). Instead, it is able to generate all the codebooks in a single forward pass.
- Add MusicGen Melody by @ylacombe in #28819
PvT-v2
The PVTv2 model was proposed in PVT v2: Improved Baselines with Pyramid Vision Transformer by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, and Ling Shao. As an improved variant of PVT, it eschews position embeddings, relying instead on positional information encoded through zero-padding and overlapping patch embeddings. This lack of reliance on position embeddings simplifies the architecture, and enables running inference at any resolution without needing to interpolate them.
- Add PvT-v2 Model by @FoamoftheSea in #26812
UDOP
The UDOP model was proposed in Unifying Vision, Text, and Layout for Universal Document Processing by Zineng Tang, Ziyi Yang, Guoxin Wang, Yuwei Fang, Yang Liu, Chenguang Zhu, Michael Zeng, Cha Zhang, Mohit Bansal. UDOP adopts an encoder-decoder Transformer architecture based on T5 for document AI tasks like document image classification, document parsing and document visual question answering.
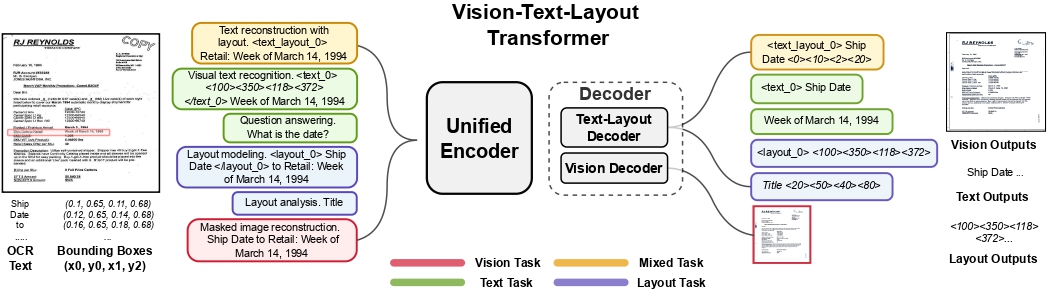
UDOP architecture. Taken from the original paper.
- Add UDOP by @NielsRogge in #22940
Mamba
This model is a new paradigm architecture based on state-space-models, rather than attention like transformer models. The checkpoints are compatible with the original ones
- [
Add Mamba] Adds support for theMambamodels by @ArthurZucker in #28094
StarCoder2
StarCoder2 is a family of open LLMs for code and comes in 3 different sizes with 3B, 7B and 15B parameters. The flagship StarCoder2-15B model is trained on over 4 trillion tokens and 600+ programming languages from The Stack v2. All models use Grouped Query Attention, a context window of 16,384 tokens with a sliding window attention of 4,096 tokens, and were trained using the Fill-in-the-Middle objective.
- Starcoder2 model - bis by @RaymondLi0 in #29215
SegGPT
The SegGPT model was proposed in SegGPT: Segmenting Everything In Context by Xinlong Wang, Xiaosong Zhang, Yue Cao, Wen Wang, Chunhua Shen, Tiejun Huang. SegGPT employs a decoder-only Transformer that can generate a segmentation mask given an input image, a prompt image and its corresponding prompt mask. The model achieves remarkable one-shot results with 56.1 mIoU on COCO-20 and 85.6 mIoU on FSS-1000.
- Adding SegGPT by @EduardoPach in #27735
Galore optimizer

With Galore, you can pre-train large models on consumer-type hardwares, making LLM pre-training much more accessible to anyone from the community.
Our approach reduces memory usage by up to 65.5% in optimizer states while maintaining both efficiency and performance for pre-training on LLaMA 1B and 7B architectures with C4 dataset with up to 19.7B tokens, and on fine-tuning RoBERTa on GLUE tasks. Our 8-bit GaLore further reduces optimizer memory by up to 82.5% and total training memory by 63.3%, compared to a BF16 baseline. Notably, we demonstrate, for the first time, the feasibility of pre-training a 7B model on consumer GPUs with 24GB memory (e.g., NVIDIA RTX 4090) without model parallel, checkpointing, or offloading strategies.
Galore is based on low rank approximation of the gradients and can be used out of the box for any model.
Below is a simple snippet that demonstrates how to pre-train mistralai/Mistral-7B-v0.1 on imdb:
import torch
import datasets
from transformers import TrainingArguments, AutoConfig, AutoTokenizer, AutoModelForCausalLM
import trl
train_dataset = datasets.load_dataset('imdb', split='train')
args = TrainingArguments(
output_dir="./test-galore",
max_steps=100,
per_device_train_batch_size=2,
optim="galore_adamw",
optim_target_modules=["attn", "mlp"]
)
model_id = "mistralai/Mistral-7B-v0.1"
config = AutoConfig.from_pretrained(model_id)
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_config(config).to(0)
trainer = trl.SFTTrainer(
model=model,
args=args,
train_dataset=train_dataset,
dataset_text_field='text',
max_seq_length=512,
)
trainer.train()
Quantization
Quanto integration
Quanto has been integrated with transformers ! You can apply simple quantization algorithms with few lines of code with tiny changes. Quanto is also compatible with torch.compile
Check out the announcement blogpost for more details
- [Quantization] Quanto quantizer by @SunMarc in #29023
Exllama 🤝 AWQ
Exllama and AWQ combined together for faster AWQ inference - check out the relevant documentation section for more details on how to use Exllama + AWQ.
- Exllama kernels support for AWQ models by @IlyasMoutawwakil in #28634
MLX Support
Allow models saved or fine-tuned with Apple’s MLX framework to be loaded in transformers (as long as the model parameters use the same names), and improve tensor interoperability. This leverages MLX's adoption of safetensors as their checkpoint format.
- Add mlx support to BatchEncoding.convert_to_tensors by @Y4hL in #29406
- Add support for metadata format MLX by @alexweberk in #29335
- Typo in mlx tensor support by @pcuenca in #29509
- Experimental loading of MLX files by @pcuenca in #29511
Highligted improvements
Notable memory reduction in Gemma/LLaMa by changing the causal mask buffer type from int64 to boolean.
- Use
torch.boolinstead oftorch.int64for non-persistant causal mask buffer by @fxmarty in #29241
Remote code improvements
- Allow remote code repo names to contain "." by @Rocketknight1 in #29175
- simplify get_class_in_module and fix for paths containing a dot by @cebtenzzre in #29262
Breaking changes
The PRs below introduced slightly breaking changes that we believed was necessary for the repository; if these seem to impact your usage of transformers, we recommend checking out the PR description to get more insights in how to leverage the new behavior.
- 🚨🚨[Whisper Tok] Update integration test by @sanchit-gandhi in #29368
- 🚨 Fully revert atomic checkpointing 🚨 by @muellerzr in #29370
- [BC 4.37 -> 4.38] for Llama family, memory and speed #29753 (causal mask is no longer a registered buffer)
Fixes and improvements
- FIX [
Gemma] Fix bad rebase with transformers main by @younesbelkada in #29170 - Add training version check for AQLM quantizer. by @BlackSamorez in #29142
- [Gemma] Fix eager attention by @sanchit-gandhi in #29187
- [Mistral, Mixtral] Improve docs by @NielsRogge in #29084
- Fix
torch.compilewithfullgraph=Truewhenattention_maskinput is used by @fxmarty in #29211 - fix(mlflow): check mlflow version to use the synchronous flag by @cchen-dialpad in #29195
- Fix missing translation in README_ru by @strikoder in #29054
- Improve _update_causal_mask performance by @alessandropalla in #29210
- [
Doc] update model doc qwen2 by @ArthurZucker in #29238 - Use torch 2.2 for daily CI (model tests) by @ydshieh in #29208
- Cache
is_vision_availableresult by @bmuskalla in #29280 - Use
DS_DISABLE_NINJA=1by @ydshieh in #29290 - Add
non_device_testpytest mark to filter out non-device tests by @fxmarty in #29213 - Add feature extraction mapping for automatic metadata update by @merveenoyan in #28944
- Generate: v4.38 removals and related updates by @gante in #29171
- Track each row separately for stopping criteria by @zucchini-nlp in #29116
- [docs] Spanish translation of tasks_explained.md by @aaronjimv in #29224
- [i18n-zh] Translated torchscript.md into Chinese by @windsonsea in #29234
- 🌐 [i18n-ZH] Translate chat_templating.md into Chinese by @shibing624 in #28790
- [i18n-vi] Translate README.md to Vietnamese by @hoangsvit in #29229
- [i18n-zh] Translated task/asr.md into Chinese by @windsonsea in #29233
- Fixed Deformable Detr typo when loading cuda kernels for MSDA by @EduardoPach in #29294
- GenerationConfig validate both constraints and force_words_ids by @FredericOdermatt in #29163
- Add generate kwargs to VQA pipeline by @regisss in #29134
- Cleaner Cache
dtypeanddeviceextraction for CUDA graph generation for quantizers compatibility by @BlackSamorez in #29079 - Image Feature Extraction docs by @merveenoyan in #28973
- Fix
attn_implementationdocumentation by @fxmarty in #29295 - [tests] enable benchmark unit tests on XPU by @faaany in #29284
- Use torch 2.2 for deepspeed CI by @ydshieh in #29246
- Add compatibility with skip_memory_metrics for mps device by @SunMarc in #29264
- Token level timestamps for long-form generation in Whisper by @zucchini-nlp in #29148
- Fix a few typos in
GenerationMixin's docstring by @sadra-barikbin in #29277 - [i18n-zh] Translate fsdp.md into Chinese by @windsonsea in #29305
- FIX [
Gemma/CI] Make sure our runners have access to the model by @younesbelkada in #29242 - Remove numpy usage from owlvit by @fxmarty in #29326
- [
require_read_token] fix typo by @ArthurZucker in #29345 - [
T5 and Llama Tokenizer] remove warning by @ArthurZucker in #29346 - [
Llama ROPE] Fix torch export but also slow downs in forward by @ArthurZucker in #29198 - Disable Mixtral
output_router_logitsduring inference by @LeonardoEmili in #29249 - Idefics: generate fix by @gante in #29320
- RoPE loses precision for Llama / Gemma + Gemma logits.float() by @danielhanchen in #29285
- check if position_ids exists before using it by @jiqing-feng in #29306
- [CI] Quantization workflow by @SunMarc in #29046
- Better SDPA unmasking implementation by @fxmarty in #29318
- [i18n-zh] Sync source/zh/index.md by @windsonsea in #29331
- FIX [
CI/starcoder2] Change starcoder2 path to correct one for slow tests by @younesbelkada in #29359 - FIX [
CI]: Fix failing tests for peft integration by @younesbelkada in #29330 - FIX [
CI]require_read_tokenin the llama FA2 test by @younesbelkada in #29361 - Avoid using uncessary
get_values(MODEL_MAPPING)by @ydshieh in #29362 - Patch YOLOS and others by @NielsRogge in #29353
- Fix @require_read_token in tests by @Wauplin in #29367
- Expose
offload_buffersparameter ofacceleratetoPreTrainedModel.from_pretrainedmethod by @notsyncing in #28755 - Fix Base Model Name of LlamaForQuestionAnswering by @lenglaender in #29258
- FIX [
quantization/ESM] Fix ESM 8bit / 4bit with bitsandbytes by @younesbelkada in #29329 - [
Llama + AWQ] fixprepare_inputs_for_generation🫠 by @ArthurZucker in #29381 - [
YOLOS] Fix - return padded annotations by @amyeroberts in #29300 - Support subfolder with
AutoProcessorby @JingyaHuang in #29169 - Fix llama + gemma accelete tests by @SunMarc in #29380
- Fix deprecated arg issue by @muellerzr in #29372
- Correct zero division error in inverse sqrt scheduler by @DavidAfonsoValente in #28982
- [tests] enable automatic speech recognition pipeline tests on XPU by @faaany in #29308
- update path to hub files in the error message by @poedator in #29369
- [Mixtral] Fixes attention masking in the loss by @DesmonDay in #29363
- Workaround for #27758 to avoid ZeroDivisionError by @tleyden in #28756
- Convert SlimSAM checkpoints by @NielsRogge in #28379
- Fix: Fixed the previous tracking URI setting logic to prevent clashes with original MLflow code. by @seanswyi in #29096
- Fix OneFormer
post_process_instance_segmentationfor panoptic tasks by @nickthegroot in #29304 - Fix grad_norm unserializable tensor log failure by @svenschultze in #29212
- Avoid edge case in audio utils by @ylacombe in #28836
- DeformableDETR support bfloat16 by @DonggeunYu in #29232
- [Docs] Spanish Translation -Torchscript md & Trainer md by @njackman-2344 in #29310
- FIX [
Generation] Fix some issues when running the MaxLength criteria on CPU by @younesbelkada in #29317 - Fix max length for BLIP generation by @zucchini-nlp in #29296
- [docs] Update starcoder2 paper link by @xenova in #29418
- [tests] enable test_pipeline_accelerate_top_p on XPU by @faaany in #29309
- [
UdopTokenizer] Fix post merge imports by @ArthurZucker in #29451 - more fix by @ArthurZucker (direct commit on main)
- Revert-commit 0d52f9f582efb82a12e8d9162b43a01b1aa0200f by @ArthurZucker in #29455
- [
Udop imports] Processor tests were not run. by @ArthurZucker in #29456 - Generate: inner decoding methods are no longer public by @gante in #29437
- Fix bug with passing capture_* args to neptune callback by @AleksanderWWW in #29041
- Update pytest
import_pathlocation by @loadams in #29154 - Automatic safetensors conversion when lacking these files by @LysandreJik in #29390
- [i18n-zh] Translate add_new_pipeline.md into Chinese by @windsonsea in #29432
- 🌐 [i18n-KO] Translated generation_strategies.md to Korean by @AI4Harmony in #29086
- [FIX]
offload_weight()takes from 3 to 4 positional arguments but 5 were given by @faaany in #29457 - [
Docs/Awq] Add docs on exllamav2 + AWQ by @younesbelkada in #29474 - [
docs] Add starcoder2 docs by @younesbelkada in #29454 - Fix TrainingArguments regression with torch <2.0.0 for dataloader_prefetch_factor by @ringohoffman in #29447
- Generate: add tests for caches with
pad_to_multiple_ofby @gante in #29462 - Generate: get generation mode from the generation config instance 🧼 by @gante in #29441
- Avoid dummy token in PLD to optimize performance by @ofirzaf in #29445
- Fix test failure on DeepSpeed by @muellerzr in #29444
- Generate: torch.compile-ready generation config preparation by @gante in #29443
- added the max_matching_ngram_size to GenerationConfig by @mosheber in #29131
- Fix
TextGenerationPipeline.__call__docstring by @alvarobartt in #29491 - Substantially reduce memory usage in _update_causal_mask for large batches by using .expand instead of .repeat [needs tests+sanity check] by @nqgl in #29413
- Fix: Disable torch.autocast in RotaryEmbedding of Gemma and LLaMa for MPS device by @currybab in #29439
- Enable BLIP for auto VQA by @regisss in #29499
- v4.39 deprecations 🧼 by @gante in #29492
- Revert "Automatic safetensors conversion when lacking these files by @LysandreJik in #2…
- fix: Avoid error when fsdp_config is missing xla_fsdp_v2 by @ashokponkumar in #29480
- Flava multimodal add attention mask by @zucchini-nlp in #29446
- test_generation_config_is_loaded_with_model - fall back to pytorch model for now by @amyeroberts in #29521
- Set
inputsas kwarg inTextClassificationPipelineby @alvarobartt in #29495 - Fix
VisionEncoderDecoderPositional Arg by @nickthegroot in #29497 - Generate: left-padding test, revisited by @gante in #29515
- [tests] add the missing
require_sacremosesdecorator by @faaany in #29504 - fix image-to-text batch incorrect output issue by @sywangyi in #29342
- Typo fix in error message by @clefourrier in #29535
- [tests] use
torch_deviceinstead ofautofor model testing by @faaany in #29531 - StableLM: Fix dropout argument type error by @liangjs in #29236
- Make sliding window size inclusive in eager attention by @jonatanklosko in #29519
- fix typos in FSDP config parsing logic in
TrainingArgumentsby @yundai424 in #29189 - Fix WhisperNoSpeechDetection when input is full silence by @ylacombe in #29065
- [tests] use the correct
n_gpuinTrainerIntegrationTest::test_train_and_eval_dataloadersfor XPU by @faaany in #29307 - Fix eval thread fork bomb by @muellerzr in #29538
- feat: use
warning_advicefor tensorflow warning by @winstxnhdw in #29540 - [
Mamba doc] Post merge updates by @ArthurZucker in #29472 - [
Docs] fixed minor typo by @j-gc in #29555 - Add Fill-in-the-middle training objective example - PyTorch by @tanaymeh in #27464
- Bark model Flash Attention 2 Enabling to pass on check_device_map parameter to super() by @damithsenanayake in #29357
- Make torch xla available on GPU by @yitongh in #29334
- [Docs] Fix FastSpeech2Conformer model doc links by @khipp in #29574
- Don't use a subset in test fetcher if on
mainbranch by @ydshieh in #28816 - fix error: TypeError: Object of type Tensor is not JSON serializable … by @yuanzhoulvpi2017 in #29568
- Add missing localized READMEs to the copies check by @khipp in #29575
- Fixed broken link by @amritgupta98 in #29558
- Tiny improvement for doc by @fzyzcjy in #29581
- Fix Fuyu doc typos by @zucchini-nlp in #29601
- Fix minor typo: softare => software by @DriesVerachtert in #29602
- Stop passing None to compile() in TF examples by @Rocketknight1 in #29597
- Fix typo (determine) by @koayon in #29606
- Implemented add_pooling_layer arg to TFBertModel by @tomigee in #29603
- Update legacy Repository usage in various example files by @Hvanderwilk in #29085
- Set env var to hold Keras at Keras 2 by @Rocketknight1 in #29598
- Update flava tests by @ydshieh in #29611
- Fix typo ; Update quantization.md by @furkanakkurt1335 in #29615
- Add tests for batching support by @zucchini-nlp in #29297
- Fix: handle logging of scalars in Weights & Biases summary by @parambharat in #29612
- Examples: check
max_position_embeddingsin the translation example by @gante in #29600 - [
Gemma] Supports converting directly in half-precision by @younesbelkada in #29529 - [Flash Attention 2] Add flash attention 2 for GPT-J by @bytebarde in #28295
- Core: Fix copies on main by @younesbelkada in #29624
- [Whisper] Deprecate forced ids for v4.39 by @sanchit-gandhi in #29485
- Warn about tool use by @LysandreJik in #29628
- Adds pretrained IDs directly in the tests by @LysandreJik in #29534
- [generate] deprecate forced ids processor by @sanchit-gandhi in #29487
- Fix minor typo: infenrece => inference by @DriesVerachtert in #29621
- [
MaskFormer,Mask2Former] Use einsum where possible by @amyeroberts in #29544 - Llama: allow custom 4d masks by @gante in #29618
- [PyTorch/XLA] Fix extra TPU compilations introduced by recent changes by @alanwaketan in #29158
- [docs] Spanish translate chat_templating.md & yml addition by @njackman-2344 in #29559
- Add support for FSDP+QLoRA and DeepSpeed ZeRO3+QLoRA by @pacman100 in #29587
- [
Mask2Former] Move normalization for numerical stability by @amyeroberts in #29542 - [tests] make
test_trainer_log_level_replicato run on accelerators with more than 2 devices by @faaany in #29609 - Refactor TFP call to just sigmoid() by @Rocketknight1 in #29641
- Fix batching tests for new models (Mamba and SegGPT) by @zucchini-nlp in #29633
- Fix
multi_gpu_data_parallel_forwardforMusicgenTestby @ydshieh in #29632 - [docs] Remove broken ChatML format link from chat_templating.md by @aaronjimv in #29643
- Add newly added PVTv2 model to all README files. by @robinverduijn in #29647
- [
PEFT] Fixsave_pretrainedto make sure adapters weights are also saved on TPU by @shub-kris in #29388 - Fix TPU checkpointing inside Trainer by @shub-kris in #29657
- Add
dataset_revisionargument toRagConfigby @ydshieh in #29610 - Fix PVT v2 tests by @ydshieh in #29660
- Generate: handle
cache_positionupdate ingenerateby @gante in #29467 - Allow apply_chat_template to pass kwargs to the template and support a dict of templates by @Rocketknight1 in #29658
- Inaccurate code example within inline code-documentation by @MysteryManav in #29661
- Extend import utils to cover "editable" torch versions by @bhack in #29000
- Trainer: fail early in the presence of an unsavable
generation_configby @gante in #29675 - Pipeline: use tokenizer pad token at generation time if the model pad token is unset. by @gante in #29614
- [tests] remove deprecated tests for model loading by @faaany in #29450
- Fix AutoformerForPrediction example code by @m-torhan in #29639
- [tests] ensure device-required software is available in the testing environment before testing by @faaany in #29477
- Fix wrong condition used in
filter_modelsby @ydshieh in #29673 - fix: typos by @testwill in #29653
- Rename
gluetonyu-mll/glueby @lhoestq in #29679 - Generate: replace breaks by a loop condition by @gante in #29662
- [FIX] Fix speech2test modeling tests by @ylacombe in #29672
- Revert "Fix wrong condition used in
filter_models" by @ydshieh in #29682 - [docs] Spanish translation of attention.md by @aaronjimv in #29681
- CI / generate: batch size computation compatible with all models by @gante in #29671
- Fix
filter_modelsby @ydshieh in #29710 - FIX [
bnb] Makeunexpected_keysoptional by @younesbelkada in #29420 - Update the pipeline tutorial to include
gradio.Interface.from_pipelineby @abidlabs in #29684 - Use logging.warning instead of warnings.warn in pipeline.call by @tokestermw in #29717
Significant community contributions
The following contributors have made significant changes to the library over the last release:
- @windsonsea
- [i18n-zh] Translated torchscript.md into Chinese (#29234)
- [i18n-zh] Translated task/asr.md into Chinese (#29233)
- [i18n-zh] Translate fsdp.md into Chinese (#29305)
- [i18n-zh] Sync source/zh/index.md (#29331)
- [i18n-zh] Translate add_new_pipeline.md into Chinese (#29432)
- @hoangsvit
- [i18n-vi] Translate README.md to Vietnamese (#29229)
- @EduardoPach
- Fixed Deformable Detr typo when loading cuda kernels for MSDA (#29294)
- Adding SegGPT (#27735)
- @RaymondLi0
- Starcoder2 model - bis (#29215)
- @njackman-2344
- [Docs] Spanish Translation -Torchscript md & Trainer md (#29310)
- [docs] Spanish translate chat_templating.md & yml addition (#29559)
- @tanaymeh
- Add Fill-in-the-middle training objective example - PyTorch (#27464)
- @Hvanderwilk
- Update legacy Repository usage in various example files (#29085)
- @FoamoftheSea
- Add PvT-v2 Model (#26812)
- @saurabhdash2512
- Cohere Model Release (#29622)
v4.38.2
2 months agoFix backward compatibility issues with Llama and Gemma:
We mostly made sure that performances are not affected by the new change of paradigm with ROPE. Fixed the ROPE computation (should always be in float32) and the causal_mask dtype was set to bool to take less RAM.
YOLOS had a regression, and Llama / T5Tokenizer had a warning popping for random reasons
- FIX [Gemma] Fix bad rebase with transformers main (#29170)
- Improve _update_causal_mask performance (#29210)
- [T5 and Llama Tokenizer] remove warning (#29346)
- [Llama ROPE] Fix torch export but also slow downs in forward (#29198)
- RoPE loses precision for Llama / Gemma + Gemma logits.float() (#29285)
- Patch YOLOS and others (#29353)
- Use torch.bool instead of torch.int64 for non-persistant causal mask buffer (#29241)
v4.38.1
2 months agoFix eager attention in Gemma!
- [Gemma] Fix eager attention #29187 by @sanchit-gandhi
TLDR:
- attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+ attn_output = attn_output.view(bsz, q_len, -1)
v4.38.0
2 months agoNew model additions
💎 Gemma 💎
Gemma is a new opensource Language Model series from Google AI that comes with a 2B and 7B variant. The release comes with the pre-trained and instruction fine-tuned versions and you can use them via AutoModelForCausalLM, GemmaForCausalLM or pipeline interface!
Read more about it in the Gemma release blogpost: https://hf.co/blog/gemma
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b")
model = AutoModelForCausalLM.from_pretrained("google/gemma-2b", device_map="auto", torch_dtype=torch.float16)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
You can use the model with Flash Attention, SDPA, Static cache and quantization API for further optimizations !
- Flash Attention 2
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b")
model = AutoModelForCausalLM.from_pretrained(
"google/gemma-2b", device_map="auto", torch_dtype=torch.float16, attn_implementation="flash_attention_2"
)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
- bitsandbytes-4bit
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b")
model = AutoModelForCausalLM.from_pretrained(
"google/gemma-2b", device_map="auto", load_in_4bit=True
)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
- Static Cache
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b")
model = AutoModelForCausalLM.from_pretrained(
"google/gemma-2b", device_map="auto"
)
model.generation_config.cache_implementation = "static"
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
Depth Anything Model
The Depth Anything model was proposed in Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data by Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao. Depth Anything is based on the DPT architecture, trained on ~62 million images, obtaining state-of-the-art results for both relative and absolute depth estimation.
- Add Depth Anything by @NielsRogge in #28654
Stable LM
StableLM 3B 4E1T was proposed in StableLM 3B 4E1T: Technical Report by Stability AI and is the first model in a series of multi-epoch pre-trained language models.
StableLM 3B 4E1T is a decoder-only base language model pre-trained on 1 trillion tokens of diverse English and code datasets for four epochs. The model architecture is transformer-based with partial Rotary Position Embeddings, SwiGLU activation, LayerNorm, etc.
The team also provides StableLM Zephyr 3B, an instruction fine-tuned version of the model that can be used for chat-based applications.
- Add
StableLMby @jon-tow in #28810
⚡️ Static cache was introduced in the following PRs ⚡️
Static past key value cache allows LlamaForCausalLM' s forward pass to be compiled using torch.compile !
This means that (cuda) graphs can be used for inference, which speeds up the decoding step by 4x!
A forward pass of Llama2 7B takes around 10.5 ms to run with this on an A100! Equivalent to TGI performances! ⚡️
- [
Core generation] Adds support for static KV cache by @ArthurZucker in #27931 - [
CLeanup] Revert SDPA attention changes that got in the static kv cache PR by @ArthurZucker in #29027 - Fix static generation when compiling! by @ArthurZucker in #28937
- Static Cache: load models with MQA or GQA by @gante in #28975
- Fix symbolic_trace with kv cache by @fxmarty in #28724
⚠️ Support for generate is not included yet. This feature is experimental and subject to changes in subsequent releases.
from transformers import AutoTokenizer, AutoModelForCausalLM, StaticCache
import torch
import os
# compilation triggers multiprocessing
os.environ["TOKENIZERS_PARALLELISM"] = "true"
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf")
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-2-7b-hf",
device_map="auto",
torch_dtype=torch.float16
)
# set up the static cache in advance of using the model
model._setup_cache(StaticCache, max_batch_size=1, max_cache_len=128)
# trigger compilation!
compiled_model = torch.compile(model, mode="reduce-overhead", fullgraph=True)
# run the model as usual
input_text = "A few facts about the universe: "
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda").input_ids
model_outputs = compiled_model(input_ids)
Quantization
🧼 HF Quantizer 🧼
HfQuantizer makes it easy for quantization method researchers and developers to add inference and / or quantization support in 🤗 transformers. If you are interested in adding the support for new methods, please refer to this documentation page: https://huggingface.co/docs/transformers/main/en/hf_quantizer
-
HfQuantizerclass for quantization-related stuff inmodeling_utils.pyby @poedator in #26610 - [
HfQuantizer] Move it to "Developper guides" by @younesbelkada in #28768 - [
HFQuantizer] Removecheck_packages_compatibilitylogic by @younesbelkada in #28789 - [docs] HfQuantizer by @stevhliu in #28820
⚡️AQLM ⚡️
AQLM is a new quantization method that enables no-performance degradation in 2-bit precision. Check out this demo about how to run Mixtral in 2-bit on a free-tier Google Colab instance: https://huggingface.co/posts/ybelkada/434200761252287
- AQLM quantizer support by @BlackSamorez in #28928
- Removed obsolete attribute setting for AQLM quantization. by @BlackSamorez in #29034
🧼 Moving canonical repositories 🧼
The canonical repositories on the hugging face hub (models that did not have an organization, like bert-base-cased), have been moved under organizations.
You can find the entire list of models moved here: https://huggingface.co/collections/julien-c/canonical-models-65ae66e29d5b422218567567
Redirection has been set up so that your code continues working even if you continue calling the previous paths. We, however, still encourage you to update your code to use the new links so that it is entirely future proof.
- canonical repos moves by @julien-c in #28795
- Update all references to canonical models by @LysandreJik in #29001
Flax Improvements 🚀
The Mistral model was added to the library in Flax.
- Flax mistral by @kiansierra in #26943
TensorFlow Improvements 🚀
With Keras 3 becoming the standard version of Keras in TensorFlow 2.16, we've made some internal changes to maintain compatibility. We now have full compatibility with TF 2.16 as long as the tf-keras compatibility package is installed. We've also taken the opportunity to do some cleanup - in particular, the objects like BatchEncoding that are returned by our tokenizers and processors can now be directly passed to Keras methods like model.fit(), which should simplify a lot of code and eliminate a long-standing source of annoyances.
- Add tf_keras imports to prepare for Keras 3 by @Rocketknight1 in #28588
- Wrap Keras methods to support BatchEncoding by @Rocketknight1 in #28734
- Fix Keras scheduler import so it works for older versions of Keras by @Rocketknight1 in #28895
Pre-Trained backbone weights 🚀
Enable loading in pretrained backbones in a new model, where all other weights are randomly initialized. Note: validation checks are still in place when creating a config. Passing in use_pretrained_backbone will raise an error. You can override by setting
config.use_pretrained_backbone = True after creating a config. However, it is not yet guaranteed to be fully backwards compatible.
from transformers import MaskFormerConfig, MaskFormerModel
config = MaskFormerConfig(
use_pretrained_backbone=False,
backbone="microsoft/resnet-18"
)
config.use_pretrained_backbone = True
# Both models have resnet-18 backbone weights and all other weights randomly
# initialized
model_1 = MaskFormerModel(config)
model_2 = MaskFormerModel(config)
- Enable instantiating model with pretrained backbone weights by @amyeroberts in #28214
Introduce a helper function load_backbone to load a backbone from a backbone's model config e.g. ResNetConfig, or from a model config which contains backbone information. This enables cleaner modeling files and crossloading between timm and transformers backbones.
from transformers import ResNetConfig, MaskFormerConfig
from transformers.utils.backbone_utils import load_backbone
# Resnet defines the backbone model to load
config = ResNetConfig()
backbone = load_backbone(config)
# Maskformer config defines a model which uses a resnet backbone
config = MaskFormerConfig(use_timm_backbone=True, backbone="resnet18")
backbone = load_backbone(config)
config = MaskFormerConfig(backbone_config=ResNetConfig())
backbone = load_backbone(config)
- [
Backbone] Useload_backboneinstead ofAutoBackbone.from_configby @amyeroberts in #28661 - Backbone kwargs in config by @amyeroberts in #28784
Add in API references, list supported backbones, updated examples, clarification and moving information to better reflect usage and docs
- [docs] Backbone by @stevhliu in #28739
- Improve Backbone API docs by @merveenoyan in #28666
Image Processor work 🚀
- Raise unused kwargs image processor by @molbap in #29063
- Abstract image processor arg checks by @molbap in #28843
Bugfixes and improvements 🚀
- Fix id2label assignment in run_classification.py by @jheitmann in #28590
- Add missing key to TFLayoutLM signature by @Rocketknight1 in #28640
- Avoid root logger's level being changed by @ydshieh in #28638
- Add config tip to custom model docs by @Rocketknight1 in #28601
- Fix lr_scheduler in no_trainer training scripts by @bofenghuang in #27872
- [
Llava] Update convert_llava_weights_to_hf.py script by @isaac-vidas in #28617 - [
GPTNeoX] Fix GPTNeoX + Flash Attention 2 issue by @younesbelkada in #28645 - Update image_processing_deformable_detr.py by @sounakdey in #28561
- [
SigLIP] Only import tokenizer if sentencepiece available by @amyeroberts in #28636 - Fix phi model doc checkpoint by @amyeroberts in #28581
- get default device through
PartialState().default_deviceas it has been officially released by @statelesshz in #27256 - integrations: fix DVCLiveCallback model logging by @dberenbaum in #28653
- Enable safetensors conversion from PyTorch to other frameworks without the torch requirement by @LysandreJik in #27599
-
tensor_size- fix copy/paste error msg typo by @scruel in #28660 - Fix windows err with checkpoint race conditions by @muellerzr in #28637
- add dataloader prefetch factor in training args and trainer by @qmeeus in #28498
- Support single token decode for
CodeGenTokenizerby @cmathw in #28628 - Remove deprecated eager_serving fn by @Rocketknight1 in #28665
- fix a hidden bug of
GenerationConfig, now thegeneration_config.jsoncan be loaded successfully by @ParadoxZW in #28604 - Update README_es.md by @vladydev3 in #28612
- Exclude the load balancing loss of padding tokens in Mixtral-8x7B by @khaimt in #28517
- Use save_safetensor to disable safe serialization for XLA by @jeffhataws in #28669
- Add back in generation types by @amyeroberts in #28681
- [docs] DeepSpeed by @stevhliu in #28542
- Improved type hinting for all attention parameters by @nakranivaibhav in #28479
- improve efficient training on CPU documentation by @faaany in #28646
- [docs] Fix doc format by @stevhliu in #28684
- [
chore] Add missing space in warning by @tomaarsen in #28695 - Update question_answering.md by @yusyel in #28694
- [
Vilt] align input and model dtype in the ViltPatchEmbeddings forward pass by @faaany in #28633 - [
docs] Improve visualization for vertical parallelism by @petergtz in #28583 - Don't fail when
LocalEntryNotFoundErrorduringprocessor_config.jsonloading by @ydshieh in #28709 - Fix duplicate & unnecessary flash attention warnings by @fxmarty in #28557
- support PeftMixedModel signature inspect by @Facico in #28321
- fix: corrected misleading log message in save_pretrained function by @mturetskii in #28699
- [
docs] Update preprocessing.md by @velaia in #28719 - Initialize _tqdm_active with hf_hub_utils.are_progress_bars_disabled(… by @ShukantPal in #28717
- Fix
weights_onlyby @ydshieh in #28725 - Stop confusing the TF compiler with ModelOutput objects by @Rocketknight1 in #28712
- fix: suppress
GatedRepoErrorto use cache file (fix #28558). by @scruel in #28566 - Unpin pydantic by @ydshieh in #28728
- [docs] Fix datasets in guides by @stevhliu in #28715
- [Flax] Update no init test for Flax v0.7.1 by @sanchit-gandhi in #28735
- Falcon: removed unused function by @gante in #28605
- Generate: deprecate old src imports by @gante in #28607
- [
Siglip] protect from imports if sentencepiece not installed by @amyeroberts in #28737 - Add serialization logic to pytree types by @angelayi in #27871
- Fix
DepthEstimationPipeline's docstring by @ydshieh in #28733 - Fix input data file extension in examples by @khipp in #28741
- [Docs] Fix Typo in English & Japanese CLIP Model Documentation (TMBD -> TMDB) by @Vinyzu in #28751
- PatchtTST and PatchTSMixer fixes by @wgifford in #28083
- Enable Gradient Checkpointing in Deformable DETR by @FoamoftheSea in #28686
- small doc update for CamemBERT by @julien-c in #28644
- Pin pytest version <8.0.0 by @amyeroberts in #28758
- Mark test_constrained_beam_search_generate as flaky by @amyeroberts in #28757
- Fix typo of
Block. by @xkszltl in #28727 - [Whisper] Make tokenizer normalization public by @sanchit-gandhi in #28136
- Support saving only PEFT adapter in checkpoints when using PEFT + FSDP by @AjayP13 in #28297
- Add French translation: french README.md by @ThibaultLengagne in #28696
- Don't allow passing
load_in_8bitandload_in_4bitat the same time by @osanseviero in #28266 - Move CLIP _no_split_modules to CLIPPreTrainedModel by @lz1oceani in #27841
- Use Conv1d for TDNN by @gau-nernst in #25728
- Fix transformers.utils.fx compatibility with torch<2.0 by @fxmarty in #28774
- Further pin pytest version (in a temporary way) by @ydshieh in #28780
- Task-specific pipeline init args by @amyeroberts in #28439
- Pin Torch to <2.2.0 by @Rocketknight1 in #28785
- [
bnb] Fix bnb slow tests by @younesbelkada in #28788 - Prevent MLflow exception from disrupting training by @codiceSpaghetti in #28779
- don't initialize the output embeddings if we're going to tie them to input embeddings by @tom-p-reichel in #28192
- [Whisper] Refactor forced_decoder_ids & prompt ids by @patrickvonplaten in #28687
- Resolve DeepSpeed cannot resume training with PeftModel by @lh0x00 in #28746
- Wrap Keras methods to support BatchEncoding by @Rocketknight1 in #28734
- DeepSpeed: hardcode
torch.arangedtype onfloatusage to avoid incorrect initialization by @gante in #28760 - Add artifact name in job step to maintain job / artifact correspondence by @ydshieh in #28682
- Split daily CI using 2 level matrix by @ydshieh in #28773
- [docs] Correct the statement in the docstirng of compute_transition_scores in generation/utils.py by @Ki-Seki in #28786
- Adding [T5/MT5/UMT5]ForTokenClassification by @hackyon in #28443
- Make
is_torch_bf16_available_on_devicemore strict by @ydshieh in #28796 - Add tip on setting tokenizer attributes by @Rocketknight1 in #28764
- enable graident checkpointing in DetaObjectDetection and add tests in Swin/Donut_Swin by @SangbumChoi in #28615
- [docs] fix some bugs about parameter description by @zspo in #28806
- Add models from deit by @rajveer43 in #28302
- [Docs] Fix spelling and grammar mistakes by @khipp in #28825
- Explicitly check if token ID's are None in TFBertTokenizer constructor by @skumar951 in #28824
- Add missing None check for hf_quantizer by @jganitkevitch in #28804
- Fix issues caused by natten by @ydshieh in #28834
- fix / skip (for now) some tests before switch to torch 2.2 by @ydshieh in #28838
- Use
-vforpyteston CircleCI by @ydshieh in #28840 - Reduce GPU memory usage when using FSDP+PEFT by @pacman100 in #28830
- Mark
test_encoder_decoder_model_generateforvision_encoder_deocderas flaky by @amyeroberts in #28842 - Support custom scheduler in deepspeed training by @VeryLazyBoy in #26831
- [Docs] Fix bad doc: replace save with logging by @chenzizhao in #28855
- Ability to override clean_code_for_run by @w4ffl35 in #28783
- [WIP] Hard error when ignoring tensors. by @Narsil in #27484
- [
Doc] update contribution guidelines by @ArthurZucker in #28858 - Correct wav2vec2-bert inputs_to_logits_ratio by @ylacombe in #28821
- Image Feature Extraction pipeline by @amyeroberts in #28216
- ClearMLCallback enhancements: support multiple runs and handle logging better by @eugen-ajechiloae-clearml in #28559
- Do not use mtime for checkpoint rotation. by @xkszltl in #28862
- Adds LlamaForQuestionAnswering class in modeling_llama.py along with AutoModel Support by @nakranivaibhav in #28777
- [Docs] Update project names and links in awesome-transformers by @khipp in #28878
- Fix LongT5ForConditionalGeneration initialization of lm_head by @eranhirs in #28873
- Raise error when using
save_only_modelwithload_best_model_at_endfor DeepSpeed/FSDP by @pacman100 in #28866 - Fix
FastSpeech2ConformerModelTestand skip it on CPU by @ydshieh in #28888 - Revert "[WIP] Hard error when ignoring tensors." by @ydshieh in #28898
- unpin torch by @ydshieh in #28892
- Explicit server error on gated model by @Wauplin in #28894
- [Docs] Fix backticks in inline code and documentation links by @khipp in #28875
- Hotfix - make
torchaudioget the correct version intorch_and_flax_jobby @ydshieh in #28899 - [Docs] Add missing language options and fix broken links by @khipp in #28852
- fix: Fixed the documentation for
logging_first_stepby removing "evaluate" by @Sai-Suraj-27 in #28884 - fix Starcoder FA2 implementation by @pacman100 in #28891
- Fix Keras scheduler import so it works for older versions of Keras by @Rocketknight1 in #28895
- ⚠️ Raise
Exceptionwhen trying to generate 0 tokens ⚠️ by @danielkorat in #28621 - Update the cache number by @ydshieh in #28905
- Add npu device for pipeline by @statelesshz in #28885
- [Docs] Fix placement of tilde character by @khipp in #28913
- [Docs] Revert translation of '@slow' decorator by @khipp in #28912
- Fix utf-8 yaml load for marian conversion to pytorch in Windows by @SystemPanic in #28618
- Remove dead TF loading code by @Rocketknight1 in #28926
- fix: torch.int32 instead of torch.torch.int32 by @vodkaslime in #28883
- pass kwargs in stopping criteria list by @zucchini-nlp in #28927
- Support batched input for decoder start ids by @zucchini-nlp in #28887
- [Docs] Fix broken links and syntax issues by @khipp in #28918
- Fix max_position_embeddings default value for llama2 to 4096 #28241 by @karl-hajjar in #28754
- Fix a wrong link to CONTRIBUTING.md section in PR template by @B-Step62 in #28941
- Fix type annotations on neftune_noise_alpha and fsdp_config TrainingArguments parameters by @peblair in #28942
- [i18n-de] Translate README.md to German by @khipp in #28933
- [Nougat] Fix pipeline by @NielsRogge in #28242
- [Docs] Update README and default pipelines by @NielsRogge in #28864
- Convert
torch_dtypeasstrto actual torch data type (i.e. "float16" …totorch.float16) by @KossaiSbai in #28208 - [
pipelines] updated docstring with vqa alias by @cmahmut in #28951 - Tests: tag
test_save_load_fast_init_from_baseas flaky by @gante in #28930 - Updated requirements for image-classification samples: datasets>=2.14.0 by @alekseyfa in #28974
- Always initialize tied output_embeddings if it has a bias term by @hackyon in #28947
- Clean up staging tmp checkpoint directory by @woshiyyya in #28848
- [Docs] Add language identifiers to fenced code blocks by @khipp in #28955
- [Docs] Add video section by @NielsRogge in #28958
- [i18n-de] Translate CONTRIBUTING.md to German by @khipp in #28954
- [
NllbTokenizer] refactor with added tokens decoder by @ArthurZucker in #27717 - Add sudachi_projection option to BertJapaneseTokenizer by @hiroshi-matsuda-rit in #28503
- Update configuration_llama.py: fixed broken link by @AdityaKane2001 in #28946
- [
DETR] Update the processing to adapt masks & bboxes to reflect padding by @amyeroberts in #28363 - ENH: Do not pass warning message in case
quantization_configis in config but not passed as an arg by @younesbelkada in #28988 - ENH [
AutoQuantizer]: enhance trainer + not supported quant methods by @younesbelkada in #28991 - Add SiglipForImageClassification and CLIPForImageClassification by @NielsRogge in #28952
- [
Doc] Fix docbuilder - makeBackboneMixinandBackboneConfigMixinimportable fromutils. by @amyeroberts in #29002 - Set the dataset format used by
test_trainerto float32 by @statelesshz in #28920 - Introduce AcceleratorConfig dataclass by @muellerzr in #28664
- Fix flaky test vision encoder-decoder generate by @zucchini-nlp in #28923
- Mask Generation Task Guide by @merveenoyan in #28897
- Add tie_weights() to LM heads and set bias in set_output_embeddings() by @hackyon in #28948
- [TPU] Support PyTorch/XLA FSDP via SPMD by @alanwaketan in #28949
- FIX [
Trainer/ tags]: Fix trainer + tags when users do not pass"tags"totrainer.push_to_hub()by @younesbelkada in #29009 - Add cuda_custom_kernel in DETA by @SangbumChoi in #28989
- DeformableDetrModel support fp16 by @DonggeunYu in #29013
- Fix copies between DETR and DETA by @amyeroberts in #29037
- FIX: Fix error with
logger.warning+ inline with recent refactor by @younesbelkada in #29039 - Patch to skip failing
test_save_load_low_cpu_mem_usagetests by @amyeroberts in #29043 - Fix a tiny typo in
generation/utils.py::GenerateEncoderDecoderOutput's docstring by @sadra-barikbin in #29044 - add test marker to run all tests with @require_bitsandbytes by @Titus-von-Koeller in #28278
- Update important model list by @LysandreJik in #29019
- Fix max_length criteria when using inputs_embeds by @zucchini-nlp in #28994
- Support : Leverage Accelerate for object detection/segmentation models by @Tanmaypatil123 in #28312
- fix num_assistant_tokens with heuristic schedule by @jmamou in #28759
- fix failing trainer ds tests by @pacman100 in #29057
-
auto_find_batch_sizeisn't yet supported with DeepSpeed/FSDP. Raise error accrodingly. by @pacman100 in #29058 - Honor trust_remote_code for custom tokenizers by @rl337 in #28854
- Feature: Option to set the tracking URI for MLflowCallback. by @seanswyi in #29032
- Fix trainer test wrt DeepSpeed + auto_find_bs by @muellerzr in #29061
- Add chat support to text generation pipeline by @Rocketknight1 in #28945
- [Docs] Spanish translation of task_summary.md by @aaronjimv in #28844
- [
Awq] Add peft support for AWQ by @younesbelkada in #28987 - FIX [
bnb/tests]: Fix currently failing bnb tests by @younesbelkada in #29092 - fix the post-processing link by @davies-w in #29091
- Fix the
bert-base-casedtokenizer configuration test by @LysandreJik in #29105 - Fix a typo in
examples/pytorch/text-classification/run_classification.pyby @Ja1Zhou in #29072 - change version by @ArthurZucker in #29097
- [Docs] Add resources by @NielsRogge in #28705
- ENH: added new output_logits option to generate function by @mbaak in #28667
- Bnb test fix for different hardwares by @Titus-von-Koeller in #29066
- Fix two tiny typos in
pipelines/base.py::Pipeline::_sanitize_parameters()'s docstring by @sadra-barikbin in #29102 - storing & logging gradient norm in trainer by @shijie-wu in #27326
- Fixed nll with label_smoothing to just nll by @nileshkokane01 in #28708
- [
gradient_checkpointing] default to use it for torch 2.3 by @ArthurZucker in #28538 - Move misplaced line by @kno10 in #29117
- FEAT [
Trainer/bnb]: Add RMSProp frombitsandbytesto HFTrainerby @younesbelkada in #29082 - Abstract image processor arg checks. by @molbap in #28843
- FIX [
bnb/tests] Propagate the changes from #29092 to 4-bit tests by @younesbelkada in #29122 - Llama: fix batched generation by @gante in #29109
- Generate: unset GenerationConfig parameters do not raise warning by @gante in #29119
- [
cuda kernels] only compile them when initializing by @ArthurZucker in #29133 - FIX [
PEFT/Trainer] Handle better peft + quantized compiled models by @younesbelkada in #29055 - [
Core tokenization]add_dummy_prefix_spaceoption to help with latest issues by @ArthurZucker in #28010 - Revert low cpu mem tie weights by @amyeroberts in #29135
- Add support for fine-tuning CLIP-like models using contrastive-image-text example by @tjs-intel in #29070
- Save (circleci) cache at the end of a job by @ydshieh in #29141
- [Phi] Add support for sdpa by @hackyon in #29108
- Generate: missing generation config eos token setting in encoder-decoder tests by @gante in #29146
- Added image_captioning version in es and included in toctree file by @gisturiz in #29104
- Fix drop path being ignored in DINOv2 by @fepegar in #29147
- [
pipeline] Add pool option to image feature extraction pipeline by @amyeroberts in #28985
Significant community contributions
The following contributors have made significant changes to the library over the last release:
- @nakranivaibhav
- Improved type hinting for all attention parameters (#28479)
- Adds LlamaForQuestionAnswering class in modeling_llama.py along with AutoModel Support (#28777)
- @khipp
- Fix input data file extension in examples (#28741)
- [Docs] Fix spelling and grammar mistakes (#28825)
- [Docs] Update project names and links in awesome-transformers (#28878)
- [Docs] Fix backticks in inline code and documentation links (#28875)
- [Docs] Add missing language options and fix broken links (#28852)
- [Docs] Fix placement of tilde character (#28913)
- [Docs] Revert translation of '@slow' decorator (#28912)
- [Docs] Fix broken links and syntax issues (#28918)
- [i18n-de] Translate README.md to German (#28933)
- [Docs] Add language identifiers to fenced code blocks (#28955)
- [i18n-de] Translate CONTRIBUTING.md to German (#28954)
- @ThibaultLengagne
- Add French translation: french README.md (#28696)
- @poedator
-
HfQuantizerclass for quantization-related stuff inmodeling_utils.py(#26610)
-
- @kiansierra
- Flax mistral (#26943)
- @hackyon
- Adding [T5/MT5/UMT5]ForTokenClassification (#28443)
- Always initialize tied output_embeddings if it has a bias term (#28947)
- Add tie_weights() to LM heads and set bias in set_output_embeddings() (#28948)
- [Phi] Add support for sdpa (#29108)
- @SangbumChoi
- enable graident checkpointing in DetaObjectDetection and add tests in Swin/Donut_Swin (#28615)
- Add cuda_custom_kernel in DETA (#28989)
- @rajveer43
- Add models from deit (#28302)
- @jon-tow
- Add
StableLM(#28810)
- Add
v4.37.2
3 months agoSelection of fixes
- Protecting the imports for SigLIP's tokenizer if sentencepiece isn't installed
- Fix permissions issue on windows machines when using trainer in multi-node setup
- Allow disabling safe serialization when using Trainer. Needed for Neuron SDK
- Fix error when loading processor from cache
- torch < 1.13 compatible
torch.load
Commits
- [Siglip] protect from imports if sentencepiece not installed (#28737)
- Fix weights_only (#28725)
- Enable safetensors conversion from PyTorch to other frameworks without the torch requirement (#27599)
- Don't fail when LocalEntryNotFoundError during processor_config.json loading (#28709)
- Use save_safetensor to disable safe serialization for XLA (#28669)
- Fix windows err with checkpoint race conditions (#28637)
- [SigLIP] Only import tokenizer if sentencepiece available (#28636)