Yolov5 Versions Save
YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite
v7.0
1 year ago
Our new YOLOv5 v7.0 instance segmentation models are the fastest and most accurate in the world, beating all current SOTA benchmarks. We've made them super simple to train, validate and deploy. See full details in our Release Notes and visit our YOLOv5 Segmentation Colab Notebook for quickstart tutorials.
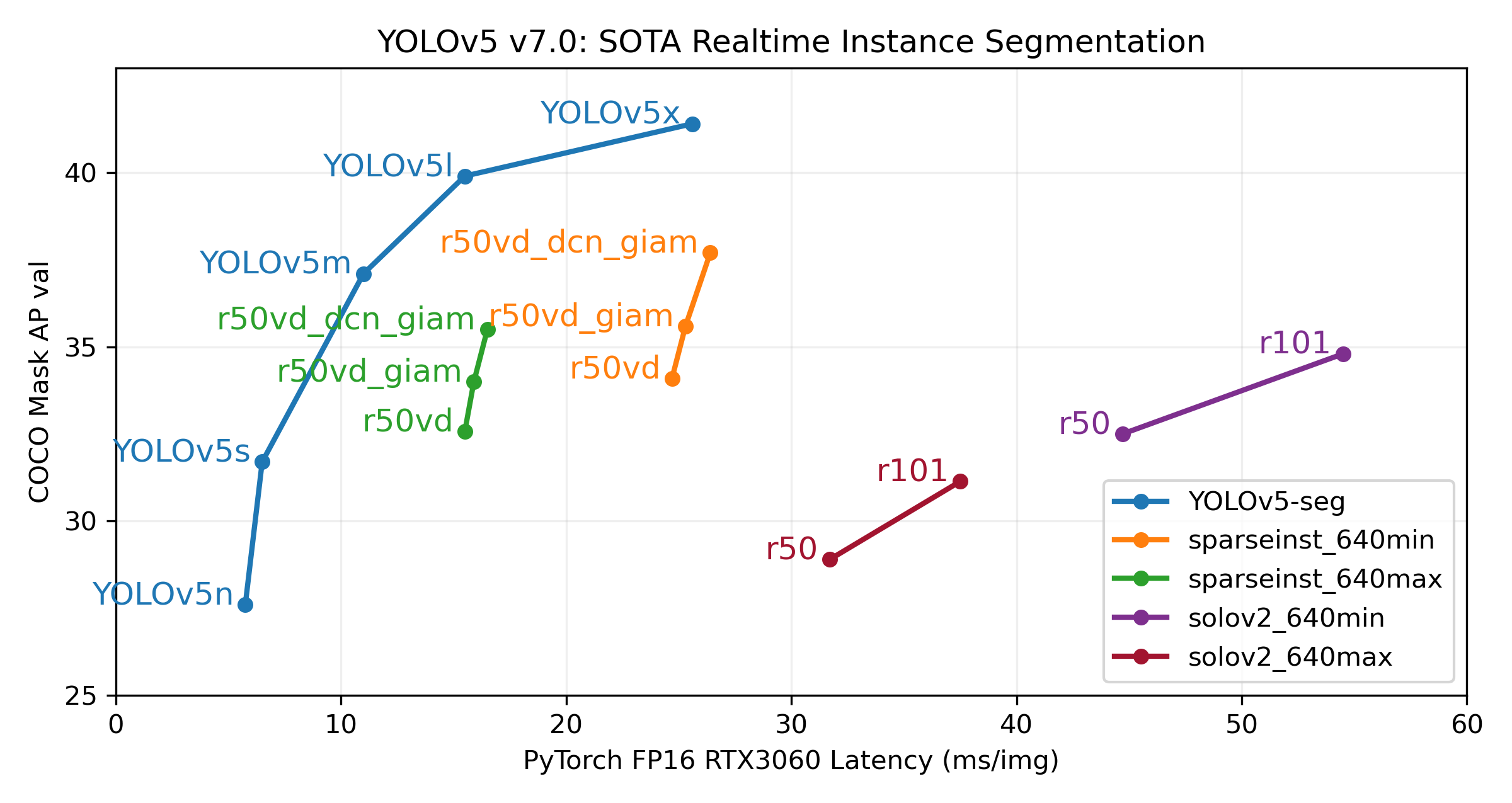
Our primary goal with this release is to introduce super simple YOLOv5 segmentation workflows just like our existing object detection models. The new v7.0 YOLOv5-seg models below are just a start, we will continue to improve these going forward together with our existing detection and classification models. We'd love your feedback and contributions on this effort!
This release incorporates 280 PRs from 41 contributors since our last release in August 2022.
Important Updates
- Segmentation Models ⭐ NEW: SOTA YOLOv5-seg COCO-pretrained segmentation models are now available for the first time (https://github.com/ultralytics/yolov5/pull/9052 by @glenn-jocher, @AyushExel and @Laughing-q)
- Paddle Paddle Export: Export any YOLOv5 model (cls, seg, det) to Paddle format with python export.py --include paddle (https://github.com/ultralytics/yolov5/pull/9459 by @glenn-jocher)
-
YOLOv5 AutoCache: Use
python train.py --cache ramwill now scan available memory and compare against predicted dataset RAM usage. This reduces risk in caching and should help improve adoption of the dataset caching feature, which can significantly speed up training. (https://github.com/ultralytics/yolov5/pull/10027 by @glenn-jocher) - Comet Logging and Visualization Integration: Free forever, Comet lets you save YOLOv5 models, resume training, and interactively visualise and debug predictions. (https://github.com/ultralytics/yolov5/pull/9232 by @DN6)
New Segmentation Checkpoints
We trained YOLOv5 segmentations models on COCO for 300 epochs at image size 640 using A100 GPUs. We exported all models to ONNX FP32 for CPU speed tests and to TensorRT FP16 for GPU speed tests. We ran all speed tests on Google Colab Pro notebooks for easy reproducibility.
| Model | size (pixels) |
mAPbox 50-95 |
mAPmask 50-95 |
Train time 300 epochs A100 (hours) |
Speed ONNX CPU (ms) |
Speed TRT A100 (ms) |
params (M) |
FLOPs @640 (B) |
|---|---|---|---|---|---|---|---|---|
| YOLOv5n-seg | 640 | 27.6 | 23.4 | 80:17 | 62.7 | 1.2 | 2.0 | 7.1 |
| YOLOv5s-seg | 640 | 37.6 | 31.7 | 88:16 | 173.3 | 1.4 | 7.6 | 26.4 |
| YOLOv5m-seg | 640 | 45.0 | 37.1 | 108:36 | 427.0 | 2.2 | 22.0 | 70.8 |
| YOLOv5l-seg | 640 | 49.0 | 39.9 | 66:43 (2x) | 857.4 | 2.9 | 47.9 | 147.7 |
| YOLOv5x-seg | 640 | 50.7 | 41.4 | 62:56 (3x) | 1579.2 | 4.5 | 88.8 | 265.7 |
- All checkpoints are trained to 300 epochs with SGD optimizer with
lr0=0.01andweight_decay=5e-5at image size 640 and all default settings.
Runs logged to https://wandb.ai/glenn-jocher/YOLOv5_v70_official -
Accuracy values are for single-model single-scale on COCO dataset.
Reproduce bypython segment/val.py --data coco.yaml --weights yolov5s-seg.pt -
Speed averaged over 100 inference images using a Colab Pro A100 High-RAM instance. Values indicate inference speed only (NMS adds about 1ms per image).
Reproduce bypython segment/val.py --data coco.yaml --weights yolov5s-seg.pt --batch 1 -
Export to ONNX at FP32 and TensorRT at FP16 done with
export.py.
Reproduce bypython export.py --weights yolov5s-seg.pt --include engine --device 0 --half
New Segmentation Usage Examples
Train
YOLOv5 segmentation training supports auto-download COCO128-seg segmentation dataset with --data coco128-seg.yaml argument and manual download of COCO-segments dataset with bash data/scripts/get_coco.sh --train --val --segments and then python train.py --data coco.yaml.
# Single-GPU
python segment/train.py --model yolov5s-seg.pt --data coco128-seg.yaml --epochs 5 --img 640
# Multi-GPU DDP
python -m torch.distributed.run --nproc_per_node 4 --master_port 1 segment/train.py --model yolov5s-seg.pt --data coco128-seg.yaml --epochs 5 --img 640 --device 0,1,2,3
Val
Validate YOLOv5m-seg accuracy on ImageNet-1k dataset:
bash data/scripts/get_coco.sh --val --segments # download COCO val segments split (780MB, 5000 images)
python segment/val.py --weights yolov5s-seg.pt --data coco.yaml --img 640 # validate
Predict
Use pretrained YOLOv5m-seg to predict bus.jpg:
python segment/predict.py --weights yolov5m-seg.pt --data data/images/bus.jpg
model = torch.hub.load('ultralytics/yolov5', 'custom', 'yolov5m-seg.pt') # load from PyTorch Hub (WARNING: inference not yet supported)
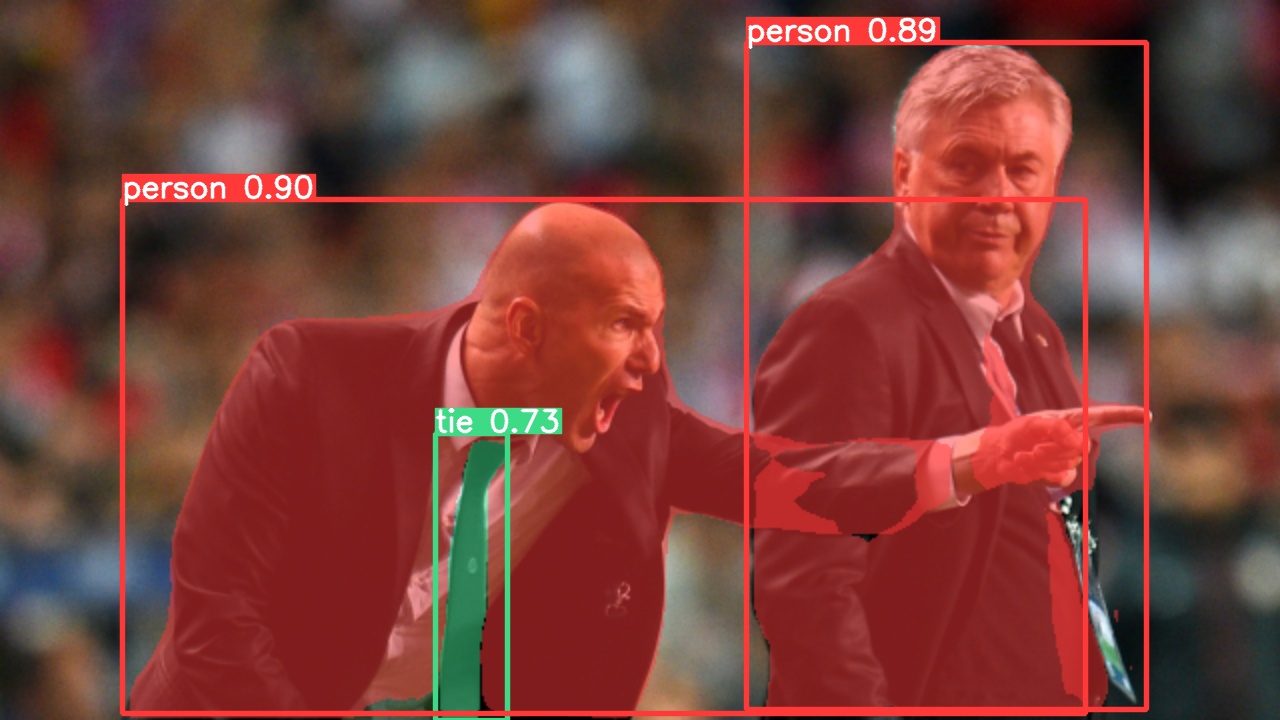 |
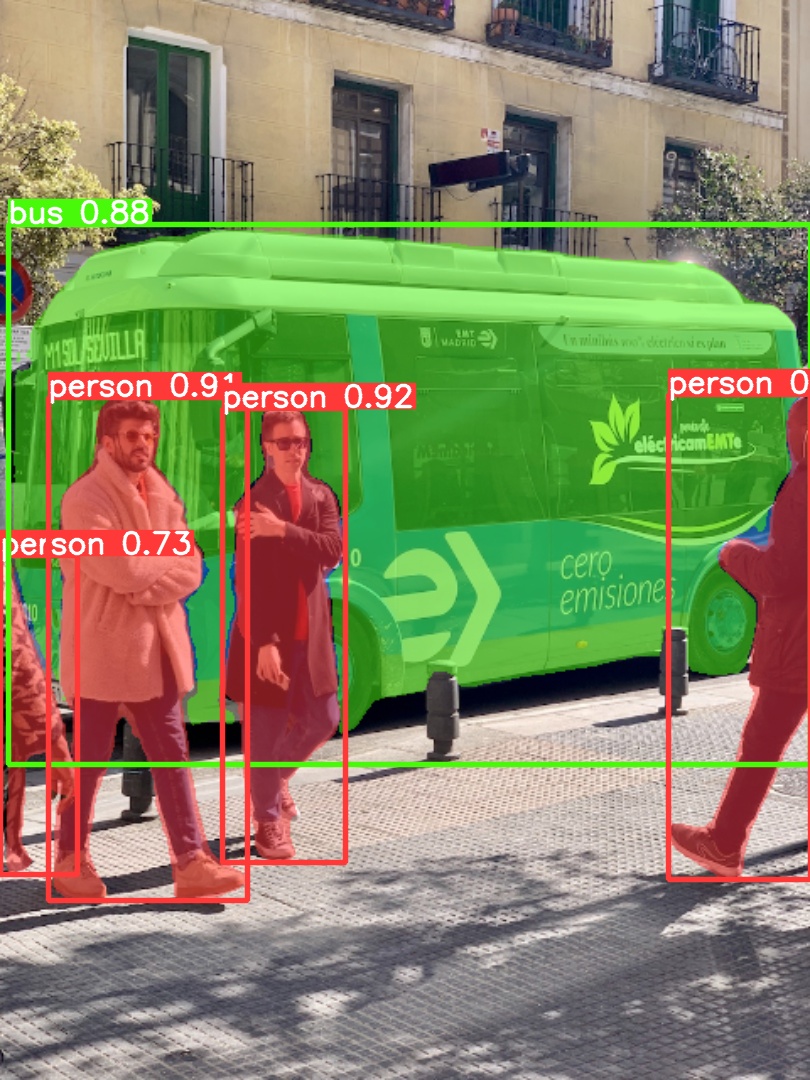 |
|---|
Export
Export YOLOv5s-seg model to ONNX and TensorRT:
python export.py --weights yolov5s-seg.pt --include onnx engine --img 640 --device 0
Changelog
- Changes between previous release and this release: https://github.com/ultralytics/yolov5/compare/v6.2...v7.0
- Changes since this release: https://github.com/ultralytics/yolov5/compare/v7.0...HEAD
🛠️ New Features and Bug Fixes (280)
* Improve classification comments by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/8997 * Update `attempt_download(release='v6.2')` by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/8998 * Update README_cn.md by @KieraMengru0907 in https://github.com/ultralytics/yolov5/pull/9001 * Update dataset `names` from array to dictionary by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9000 * [segment]: Allow inference on dirs and videos by @AyushExel in https://github.com/ultralytics/yolov5/pull/9003 * DockerHub tag update Usage example by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9005 * Add weight `decay` to argparser by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9006 * Add glob quotes to detect.py usage example by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9007 * Fix TorchScript JSON string key bug by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9015 * EMA FP32 assert classification bug fix by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9016 * Faster pre-processing for gray image input by @cher-liang in https://github.com/ultralytics/yolov5/pull/9009 * Improved `Profile()` inference timing by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9024 * `torch.empty()` for speed improvements by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9025 * Remove unused `time_sync` import by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9026 * Add PyTorch Hub classification CI checks by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9027 * Attach transforms to model by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9028 * Default --data `imagenette160` training (fastest) by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9033 * VOC `names` dictionary fix by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9034 * Update train.py `import val as validate` by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9037 * AutoBatch protect from negative batch sizes by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9048 * Temporarily remove `macos-latest` from CI by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9049 * Add `--save-hybrid` mAP warning by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9050 * Refactor for simplification by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9054 * Refactor for simplification 2 by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9055 * zero-mAP fix return `.detach()` to EMA by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9056 * zero-mAP fix 3 by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9058 * Daemon `plot_labels()` for faster start by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9057 * TensorBoard fix in tutorial.ipynb by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9064 * zero-mAP fix remove `torch.empty()` forward pass in `.train()` mode by @0zppd in https://github.com/ultralytics/yolov5/pull/9068 * Rename 'labels' to 'instances' by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9066 * Threaded TensorBoard graph logging by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9070 * De-thread TensorBoard graph logging by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9071 * Two dimensional `size=(h,w)` AutoShape support by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9072 * Remove unused Timeout import by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9073 * Improved Usage example docstrings by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9075 * Install `torch` latest stable by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9092 * New `@try_export` decorator by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9096 * Add optional `transforms` argument to LoadStreams() by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9105 * Streaming Classification support by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9106 * Fix numpy to torch cls streaming bug by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9112 * Infer Loggers project name by @AyushExel in https://github.com/ultralytics/yolov5/pull/9117 * Add CSV logging to GenericLogger by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9128 * New TryExcept decorator by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9154 * Fixed segment offsets by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9155 * New YOLOv5 v6.2 splash images by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9142 * Rename onnx_dynamic -> dynamic by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9168 * Inline `_make_grid()` meshgrid by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9170 * Comment EMA assert by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9173 * Fix confidence threshold for ClearML debug images by @HighMans in https://github.com/ultralytics/yolov5/pull/9174 * Update Dockerfile-cpu by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9184 * Update Dockerfile-cpu to libpython3-dev by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9185 * Update Dockerfile-arm64 to libpython3-dev by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9187 * Fix AutoAnchor MPS bug by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9188 * Skip AMP check on MPS by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9189 * ClearML's set_report_period's time is defined in minutes not seconds. by @HighMans in https://github.com/ultralytics/yolov5/pull/9186 * Add `check_git_status(..., branch='master')` argument by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9199 * `check_font()` on notebook init by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9200 * Comment `protobuf` in requirements.txt by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9207 * `check_font()` fstring update by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9208 * AutoBatch protect from extreme batch sizes by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9209 * Default AutoBatch 0.8 fraction by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9212 * Delete rebase.yml by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9202 * Duplicate segment verification fix by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9225 * New `LetterBox(size)` `CenterCrop(size)`, `ToTensor()` transforms (#9213) by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9213 * Add ClassificationModel TF export assert by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9226 * Remove usage of `pathlib.Path.unlink(missing_ok=...)` by @ymerkli in https://github.com/ultralytics/yolov5/pull/9227 * Add support for `*.pfm` images by @spacewalk01 in https://github.com/ultralytics/yolov5/pull/9230 * Python check warning emoji by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9238 * Add `url_getsize()` function by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9247 * Update dataloaders.py by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9250 * Refactor Loggers : Move code outside train.py by @AyushExel in https://github.com/ultralytics/yolov5/pull/9241 * Update general.py by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9252 * Add LoadImages._cv2_rotate() by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9249 * Move `cudnn.benchmarks(True)` to LoadStreams by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9258 * `cudnn.benchmark = True` on Seed 0 by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9259 * Update `TryExcept(msg='...')`` by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9261 * Make sure best.pt model file is preserved ClearML by @thepycoder in https://github.com/ultralytics/yolov5/pull/9265 * DetectMultiBackend improvements by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9269 * Update DetectMultiBackend for tuple outputs by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9274 * Update DetectMultiBackend for tuple outputs 2 by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9275 * Update benchmarks CI with `--hard-fail` min metric floor by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9276 * Add new `--vid-stride` inference parameter for videos by @VELCpro in https://github.com/ultralytics/yolov5/pull/9256 * [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ultralytics/yolov5/pull/9295 * Replace deprecated `np.int` with `int` by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9307 * Comet Logging and Visualization Integration by @DN6 in https://github.com/ultralytics/yolov5/pull/9232 * Comet changes by @DN6 in https://github.com/ultralytics/yolov5/pull/9328 * Train.py line 486 typo fix by @robinned in https://github.com/ultralytics/yolov5/pull/9330 * Add dilated conv support by @YellowAndGreen in https://github.com/ultralytics/yolov5/pull/9347 * Update `check_requirements()` single install by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9353 * Update `check_requirements(args, cmds='')` by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9355 * Update `check_requirements()` multiple string by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9356 * Add PaddlePaddle export and inference by @kisaragychihaya in https://github.com/ultralytics/yolov5/pull/9240 * PaddlePaddle Usage examples by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9358 * labels.jpg names fix by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9361 * Exclude `ipython` from hubconf.py `check_requirements()` by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9362 * `torch.jit.trace()` fix by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9363 * AMP Check fix by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9367 * Remove duplicate line in setup.cfg by @zldrobit in https://github.com/ultralytics/yolov5/pull/9380 * Remove `.train()` mode exports by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9429 * Continue on Docker arm64 failure by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9430 * Continue on Docker failure (all backends) by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9432 * Continue on Docker fail (all backends) fix by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9433 * YOLOv5 segmentation model support by @AyushExel in https://github.com/ultralytics/yolov5/pull/9052 * Fix val.py zero-TP bug by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9431 * New model.yaml `activation:` field by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9371 * Fix tick labels for background FN/FP by @hotohoto in https://github.com/ultralytics/yolov5/pull/9414 * Fix TensorRT exports to ONNX opset 12 by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9441 * AutoShape explicit arguments fix by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9443 * Update Detections() instance printing by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9445 * AutoUpdate TensorFlow in export.py by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9447 * AutoBatch `cudnn.benchmark=True` fix by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9448 * Do not move downloaded zips by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9455 * Update general.py by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9454 * `Detect()` and `Segment()` fixes for CoreML and Paddle by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9458 * Add Paddle exports to benchmarks by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9459 * Add `macos-latest` runner for CoreML benchmarks by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9453 * Fix cutout bug by @Oswells in https://github.com/ultralytics/yolov5/pull/9452 * Optimize imports by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9464 * TensorRT SegmentationModel fix by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9465 * `Conv()` dilation argument fix by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9466 * Update ClassificationModel default training `imgsz=224` by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9469 * Standardize warnings with `WARNING ⚠️ ...` by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9467 * TensorFlow macOS AutoUpdate by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9471 * `segment/predict --save-txt` fix by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9478 * TensorFlow SegmentationModel support by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9472 * AutoBatch report include reserved+allocated by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9491 * Update Detect() grid init `for` loop by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9494 * Accelerate video inference by @mucunwuxian in https://github.com/ultralytics/yolov5/pull/9487 * Comet Image Logging Fix by @DN6 in https://github.com/ultralytics/yolov5/pull/9498 * Fix visualization title bug by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9500 * Add paddle tips by @Zengyf-CVer in https://github.com/ultralytics/yolov5/pull/9502 * Segmentation `polygons2masks_overlap()` in `np.int32` by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9493 * Fix `random_perspective` param bug in segment by @FeiGeChuanShu in https://github.com/ultralytics/yolov5/pull/9512 * Remove `check_requirements('flatbuffers==1.12')` by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9514 * Fix TF Lite exports by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9517 * TFLite fix 2 by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9518 * FROM nvcr.io/nvidia/pytorch:22.08-py3 by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9520 * Remove scikit-learn constraint on coremltools 6.0 by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9530 * Update scikit-learn constraint per coremltools 6.0 by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9531 * Update `coremltools>=6.0` by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9532 * Update albumentations by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9503 * import re by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9535 * TF.js fix by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9536 * Refactor dataset batch-size by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9551 * Add `--source screen` for screenshot inference by @zombob in https://github.com/ultralytics/yolov5/pull/9542 * Update `is_url()` by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9566 * Detect.py supports running against a Triton container by @gaziqbal in https://github.com/ultralytics/yolov5/pull/9228 * New `scale_segments()` function by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9570 * generator seed fix for DDP mAP drop by @Forever518 in https://github.com/ultralytics/yolov5/pull/9545 * Update default GitHub assets by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9573 * Update requirements.txt comment https://pytorch.org/get-started/locally/ by @davidamacey in https://github.com/ultralytics/yolov5/pull/9576 * Add segment line predictions by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9571 * TensorRT detect.py inference fix by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9581 * Update Comet links by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9587 * Add global YOLOv5_DATASETS_DIR by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9586 * Add Paperspace Gradient badges by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9588 * #YOLOVISION22 announcement by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9590 * Bump actions/stale from 5 to 6 by @dependabot in https://github.com/ultralytics/yolov5/pull/9595 * #YOLOVISION22 update by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9598 * Apple MPS -> CPU NMS fallback strategy by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9600 * Updated Segmentation and Classification usage by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9607 * Update export.py Usage examples by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9609 * Fix `is_url('https://ultralytics.com')` by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9610 * Add `results.save(save_dir='path', exist_ok=False)` by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9617 * NMS MPS device wrapper by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9620 * Add SegmentationModel unsupported warning by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9632 * Disabled upload_dataset flag temporarily due to an artifact related bug by @soumik12345 in https://github.com/ultralytics/yolov5/pull/9652 * Add NVIDIA Jetson Nano Deployment tutorial by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9656 * Added cutout import from utils/augmentations.py to use Cutout Aug in … by @senhorinfinito in https://github.com/ultralytics/yolov5/pull/9668 * Simplify val.py benchmark mode with speed mode by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9674 * Allow list for Comet artifact class 'names' field by @KristenKehrer in https://github.com/ultralytics/yolov5/pull/9654 * [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ultralytics/yolov5/pull/9685 * TensorRT `--dynamic` fix by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9691 * FROM nvcr.io/nvidia/pytorch:22.09-py3 by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9711 * Error in utils/segment/general `masks2segments()` by @paulguerrie in https://github.com/ultralytics/yolov5/pull/9724 * Fix segment evolution keys by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9742 * Remove #YOLOVISION22 notice by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9751 * Update Loggers by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9760 * update mask2segments and saving results by @vladoossss in https://github.com/ultralytics/yolov5/pull/9785 * HUB VOC fix by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9792 * Update hubconf.py local repo Usage example by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9803 * Fix xView dataloaders import by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9807 * Argoverse HUB fix by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9809 * `smart_optimizer()` revert to weight with decay by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9817 * Allow PyTorch Hub results to display in notebooks by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9825 * Logger Cleanup by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9828 * Remove ipython from `check_requirements` exclude list by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9841 * Update HUBDatasetStats() usage examples by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9842 * Update ZipFile to context manager by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9843 * Update README.md by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9846 * Webcam show fix by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9847 * Fix OpenVINO Usage example by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9874 * ClearML Dockerfile fix by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9876 * Windows Python 3.7 .isfile() fix by @SSTato in https://github.com/ultralytics/yolov5/pull/9879 * Add TFLite Metadata to TFLite and Edge TPU models by @paradigmn in https://github.com/ultralytics/yolov5/pull/9903 * Add `gnupg` to Dockerfile-cpu by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9932 * Add ClearML minimum version requirement by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9933 * Update Comet Integrations table text by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9937 * Update README.md by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9957 * Update README.md by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9958 * Update README.md by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9961 * Switch from suffix checks to archive checks by @kalenmike in https://github.com/ultralytics/yolov5/pull/9963 * FROM nvcr.io/nvidia/pytorch:22.10-py3 by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9966 * Full-size proto code (optional) by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9980 * Update README.md by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9970 * Segmentation Tutorial by @paulguerrie in https://github.com/ultralytics/yolov5/pull/9521 * Fix `is_colab()` by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9994 * Check online twice on AutoUpdate by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9999 * Add `min_items` filter option by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9997 * Improved `check_online()` robustness by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/10000 * Fix `min_items` by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/10001 * Update default `--epochs 100` by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/10024 * YOLOv5 AutoCache Update by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/10027 * IoU `eps` adjustment by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/10051 * Update get_coco.sh by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/10057 * [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ultralytics/yolov5/pull/10068 * Use MNIST160 by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/10069 * Update Dockerfile keep default torch installation by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/10071 * Add `ultralytics` pip package by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/10103 * AutoShape integer image-size fix by @janus-zheng in https://github.com/ultralytics/yolov5/pull/10090 * YouTube Usage example comments by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/10106 * Mapped project and name to ClearML by @thepycoder in https://github.com/ultralytics/yolov5/pull/10100 * Update IoU functions by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/10123 * Add Ultralytics HUB to README by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/10070 * Fix benchmark.py usage comment by @rusamentiaga in https://github.com/ultralytics/yolov5/pull/10131 * Update HUB banner image by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/10134 * Copy-Paste zero value fix by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/10152 * Add Copy-Paste to `mosaic9()` by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/10165 * Add `join_threads()` by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/10086 * Fix dataloader filepath modification to perform replace only once and not for all occurences of string by @adumrewal in https://github.com/ultralytics/yolov5/pull/10163 * fix: prevent logging config clobbering by @rkechols in https://github.com/ultralytics/yolov5/pull/10133 * Filter PyTorch 1.13 UserWarnings by @triple-Mu in https://github.com/ultralytics/yolov5/pull/10166 * Revert "fix: prevent logging config clobbering" by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/10177 * Apply make_divisible for ONNX models in Autoshape by @janus-zheng in https://github.com/ultralytics/yolov5/pull/10172 * data.yaml `names.keys()` integer assert by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/10190 * fix: try 2 - prevent logging config clobbering by @rkechols in https://github.com/ultralytics/yolov5/pull/10192 * Segment prediction labels normalization fix by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/10205 * Simplify dataloader tqdm descriptions by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/10210 * New global `TQDM_BAR_FORMAT` by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/10211 * Feature/classification tutorial refactor by @paulguerrie in https://github.com/ultralytics/yolov5/pull/10039 * Remove Colab notebook High-Memory notices by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/10212 * Revert `--save-txt` to default False by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/10213 * Add `--source screen` Usage example by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/10215 * Add `git` info to training checkpoints by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/9655 * Add git info to cls, seg checkpoints by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/10217 * Update Comet preview image by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/10220 * Scope gitpyhon import in `check_git_info()` by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/10221 * Squeezenet reshape outputs fix by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/10222😃 New Contributors (30)
* @KieraMengru0907 made their first contribution in https://github.com/ultralytics/yolov5/pull/9001 * @cher-liang made their first contribution in https://github.com/ultralytics/yolov5/pull/9009 * @0zppd made their first contribution in https://github.com/ultralytics/yolov5/pull/9068 * @HighMans made their first contribution in https://github.com/ultralytics/yolov5/pull/9174 * @ymerkli made their first contribution in https://github.com/ultralytics/yolov5/pull/9227 * @spacewalk01 made their first contribution in https://github.com/ultralytics/yolov5/pull/9230 * @VELCpro made their first contribution in https://github.com/ultralytics/yolov5/pull/9256 * @DN6 made their first contribution in https://github.com/ultralytics/yolov5/pull/9232 * @robinned made their first contribution in https://github.com/ultralytics/yolov5/pull/9330 * @kisaragychihaya made their first contribution in https://github.com/ultralytics/yolov5/pull/9240 * @hotohoto made their first contribution in https://github.com/ultralytics/yolov5/pull/9414 * @Oswells made their first contribution in https://github.com/ultralytics/yolov5/pull/9452 * @mucunwuxian made their first contribution in https://github.com/ultralytics/yolov5/pull/9487 * @FeiGeChuanShu made their first contribution in https://github.com/ultralytics/yolov5/pull/9512 * @zombob made their first contribution in https://github.com/ultralytics/yolov5/pull/9542 * @gaziqbal made their first contribution in https://github.com/ultralytics/yolov5/pull/9228 * @Forever518 made their first contribution in https://github.com/ultralytics/yolov5/pull/9545 * @davidamacey made their first contribution in https://github.com/ultralytics/yolov5/pull/9576 * @soumik12345 made their first contribution in https://github.com/ultralytics/yolov5/pull/9652 * @senhorinfinito made their first contribution in https://github.com/ultralytics/yolov5/pull/9668 * @KristenKehrer made their first contribution in https://github.com/ultralytics/yolov5/pull/9654 * @paulguerrie made their first contribution in https://github.com/ultralytics/yolov5/pull/9724 * @vladoossss made their first contribution in https://github.com/ultralytics/yolov5/pull/9785 * @SSTato made their first contribution in https://github.com/ultralytics/yolov5/pull/9879 * @janus-zheng made their first contribution in https://github.com/ultralytics/yolov5/pull/10090 * @rusamentiaga made their first contribution in https://github.com/ultralytics/yolov5/pull/10131 * @adumrewal made their first contribution in https://github.com/ultralytics/yolov5/pull/10163 * @rkechols made their first contribution in https://github.com/ultralytics/yolov5/pull/10133 * @triple-Mu made their first contribution in https://github.com/ultralytics/yolov5/pull/10166v6.2
1 year agov6.1
2 years agoThis release incorporates many new features and bug fixes (271 PRs from 48 contributors) since our last release in October 2021. It adds TensorRT, Edge TPU and OpenVINO support, and provides retrained models at --batch-size 128 with new default one-cycle linear LR scheduler. YOLOv5 now officially supports 11 different formats, not just for export but for inference (both detect.py and PyTorch Hub), and validation to profile mAP and speed results after export.
| Format | export.py --include |
Model |
|---|---|---|
| PyTorch | - | yolov5s.pt |
| TorchScript | torchscript |
yolov5s.torchscript |
| ONNX | onnx |
yolov5s.onnx |
| OpenVINO | openvino |
yolov5s_openvino_model/ |
| TensorRT | engine |
yolov5s.engine |
| CoreML | coreml |
yolov5s.mlmodel |
| TensorFlow SavedModel | saved_model |
yolov5s_saved_model/ |
| TensorFlow GraphDef | pb |
yolov5s.pb |
| TensorFlow Lite | tflite |
yolov5s.tflite |
| TensorFlow Edge TPU | edgetpu |
yolov5s_edgetpu.tflite |
| TensorFlow.js | tfjs |
yolov5s_web_model/ |
Usage examples (ONNX shown):
Export: python export.py --weights yolov5s.pt --include onnx
Detect: python detect.py --weights yolov5s.onnx
PyTorch Hub: model = torch.hub.load('ultralytics/yolov5', 'custom', 'yolov5s.onnx')
Validate: python val.py --weights yolov5s.onnx
Visualize: https://netron.app
Important Updates
-
TensorRT support: TensorFlow, Keras, TFLite, TF.js model export now fully integrated using
python export.py --include saved_model pb tflite tfjs(https://github.com/ultralytics/yolov5/pull/5699 by @imyhxy) - Tensorflow Edge TPU support ⭐ NEW: New smaller YOLOv5n (1.9M params) model below YOLOv5s (7.5M params), exports to 2.1 MB INT8 size, ideal for ultralight mobile solutions. (https://github.com/ultralytics/yolov5/pull/3630 by @zldrobit)
- OpenVINO support: YOLOv5 ONNX models are now compatible with both OpenCV DNN and ONNX Runtime (https://github.com/ultralytics/yolov5/pull/6057 by @glenn-jocher).
-
Export Benchmarks: Benchmark (mAP and speed) all YOLOv5 export formats with
python utils/benchmarks.py --weights yolov5s.pt. Currently operates on CPU, future updates will implement GPU support. (https://github.com/ultralytics/yolov5/pull/6613 by @glenn-jocher). - Architecture: no changes
-
Hyperparameters: minor change
- hyp-scratch-large.yaml
lrfreduced from 0.2 to 0.1 (https://github.com/ultralytics/yolov5/pull/6525 by @glenn-jocher).
- hyp-scratch-large.yaml
-
Training: Default Learning Rate (LR) scheduler updated
- One-cycle with cosine replace with one-cycle linear for improved results (https://github.com/ultralytics/yolov5/pull/6729 by @glenn-jocher).
New Results
All model trainings logged to https://wandb.ai/glenn-jocher/YOLOv5_v61_official
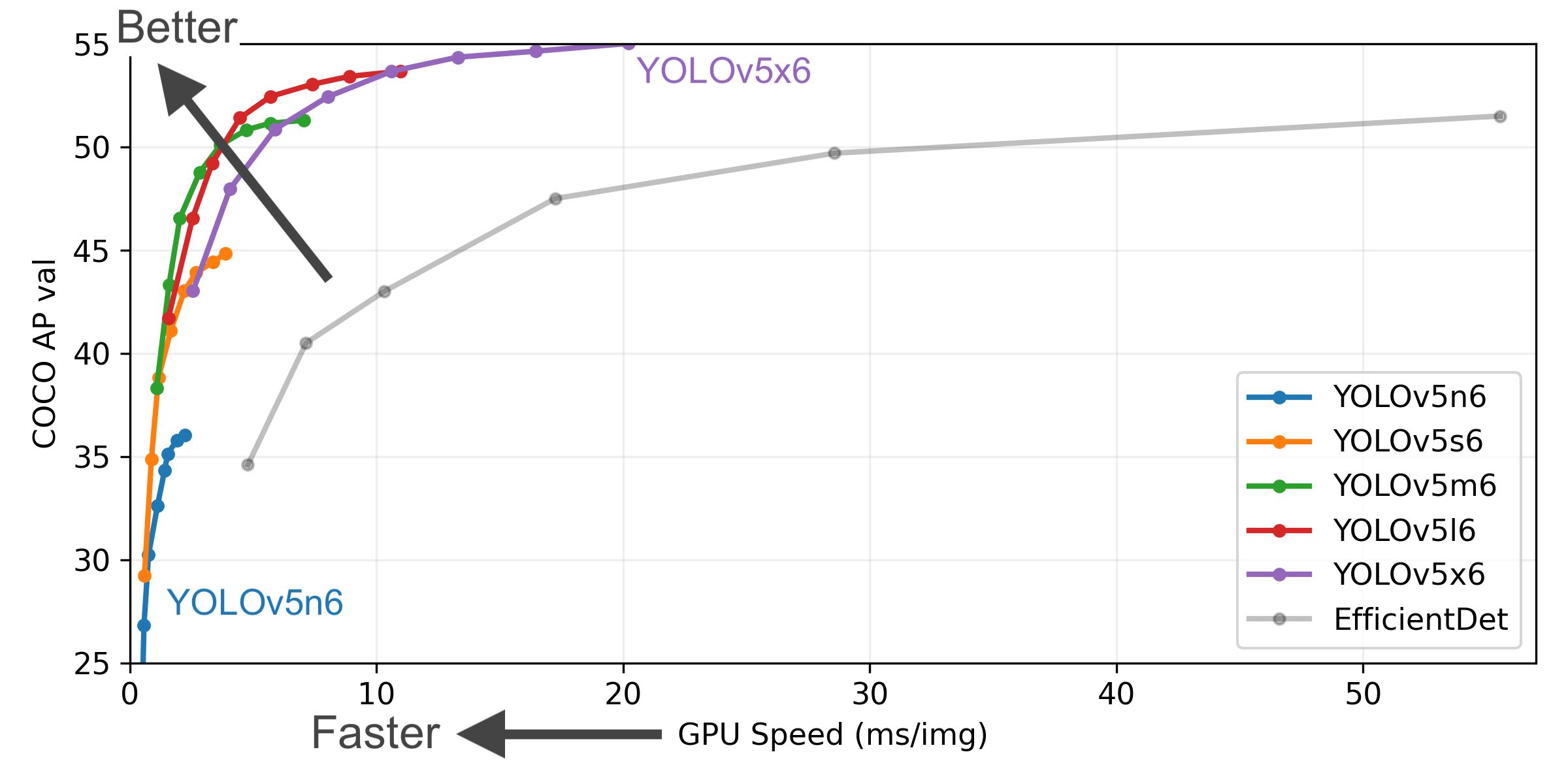
YOLOv5-P5 640 Figure (click to expand)
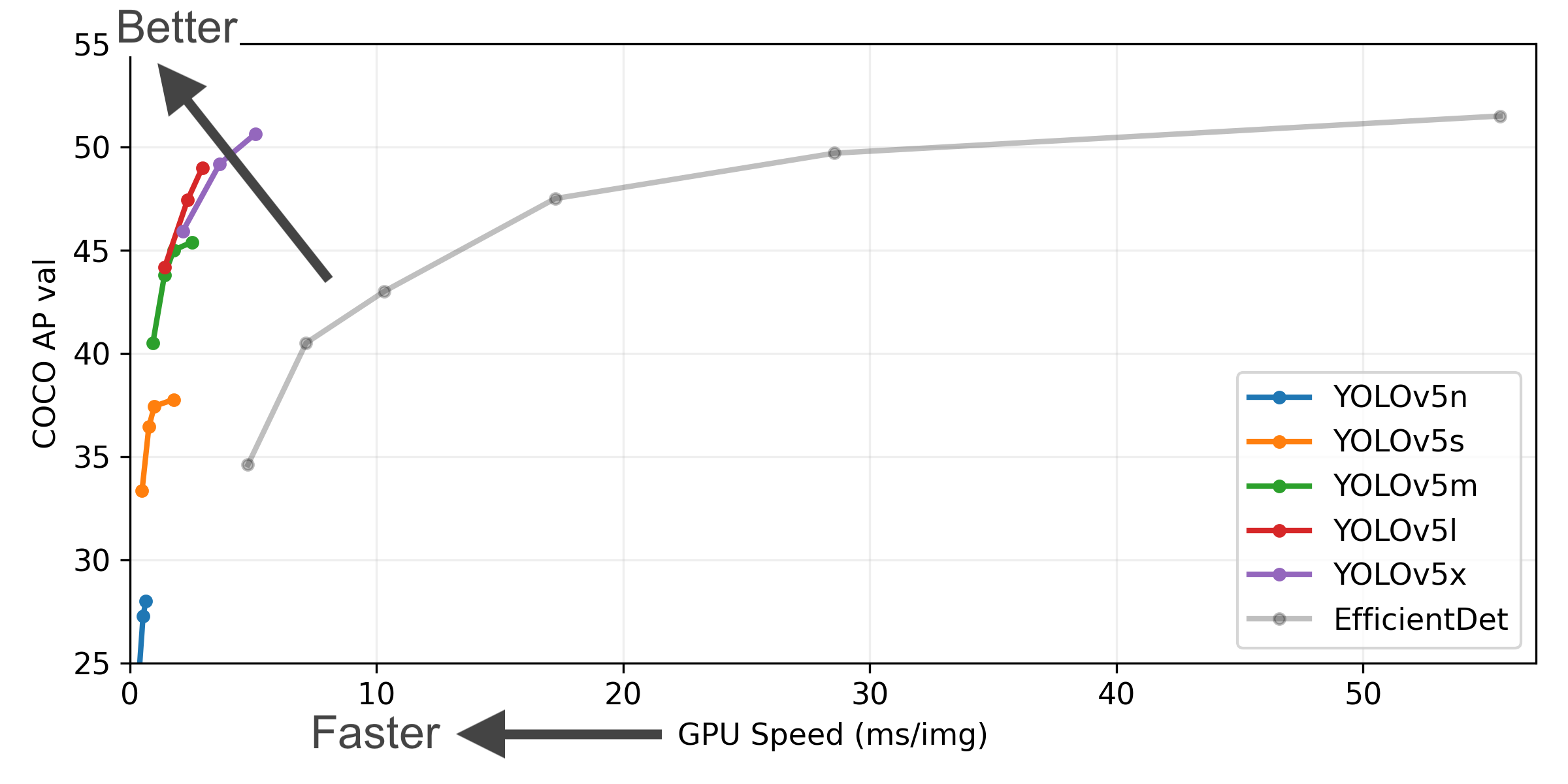
Figure Notes (click to expand)
- COCO AP val denotes [email protected]:0.95 metric measured on the 5000-image COCO val2017 dataset over various inference sizes from 256 to 1536.
- GPU Speed measures average inference time per image on COCO val2017 dataset using a AWS p3.2xlarge V100 instance at batch-size 32.
- EfficientDet data from google/automl at batch size 8.
-
Reproduce by
python val.py --task study --data coco.yaml --iou 0.7 --weights yolov5n6.pt yolov5s6.pt yolov5m6.pt yolov5l6.pt yolov5x6.pt
Example YOLOv5l before and after metrics:
| YOLOv5l Large |
size (pixels) |
mAPval 0.5:0.95 |
mAPval 0.5 |
Speed CPU b1 (ms) |
Speed V100 b1 (ms) |
Speed V100 b32 (ms) |
params (M) |
FLOPs @640 (B) |
|---|---|---|---|---|---|---|---|---|
| v5.0 | 640 | 48.2 | 66.9 | 457.9 | 11.6 | 2.8 | 47.0 | 115.4 |
| v6.0 (previous) | 640 | 48.8 | 67.2 | 424.5 | 10.9 | 2.7 | 46.5 | 109.1 |
| v6.1 (this release) | 640 | 49.0 | 67.3 | 430.0 | 10.1 | 2.7 | 46.5 | 109.1 |
Pretrained Checkpoints
| Model | size (pixels) |
mAPval 0.5:0.95 |
mAPval 0.5 |
Speed CPU b1 (ms) |
Speed V100 b1 (ms) |
Speed V100 b32 (ms) |
params (M) |
FLOPs @640 (B) |
|---|---|---|---|---|---|---|---|---|
| YOLOv5n | 640 | 28.0 | 45.7 | 45 | 6.3 | 0.6 | 1.9 | 4.5 |
| YOLOv5s | 640 | 37.4 | 56.8 | 98 | 6.4 | 0.9 | 7.2 | 16.5 |
| YOLOv5m | 640 | 45.4 | 64.1 | 224 | 8.2 | 1.7 | 21.2 | 49.0 |
| YOLOv5l | 640 | 49.0 | 67.3 | 430 | 10.1 | 2.7 | 46.5 | 109.1 |
| YOLOv5x | 640 | 50.7 | 68.9 | 766 | 12.1 | 4.8 | 86.7 | 205.7 |
| YOLOv5n6 | 1280 | 36.0 | 54.4 | 153 | 8.1 | 2.1 | 3.2 | 4.6 |
| YOLOv5s6 | 1280 | 44.8 | 63.7 | 385 | 8.2 | 3.6 | 12.6 | 16.8 |
| YOLOv5m6 | 1280 | 51.3 | 69.3 | 887 | 11.1 | 6.8 | 35.7 | 50.0 |
| YOLOv5l6 | 1280 | 53.7 | 71.3 | 1784 | 15.8 | 10.5 | 76.8 | 111.4 |
| YOLOv5x6 + TTA |
1280 1536 |
55.0 55.8 |
72.7 72.7 |
3136 - |
26.2 - |
19.4 - |
140.7 - |
209.8 - |
Table Notes (click to expand)
- All checkpoints are trained to 300 epochs with default settings. Nano and Small models use hyp.scratch-low.yaml hyps, all others use hyp.scratch-high.yaml.
-
mAPval values are for single-model single-scale on COCO val2017 dataset.
Reproduce bypython val.py --data coco.yaml --img 640 --conf 0.001 --iou 0.65 -
Speed averaged over COCO val images using a AWS p3.2xlarge instance. NMS times (~1 ms/img) not included.
Reproduce bypython val.py --data coco.yaml --img 640 --task speed --batch 1 -
TTA Test Time Augmentation includes reflection and scale augmentations.
Reproduce bypython val.py --data coco.yaml --img 1536 --iou 0.7 --augment
Changelog
Changes between previous release and this release: https://github.com/ultralytics/yolov5/compare/v6.0...v6.1 Changes since this release: https://github.com/ultralytics/yolov5/compare/v6.1...HEAD
New Features and Bug Fixes (271)
- fix
tfconversion in new v6 models by @YoniChechik in https://github.com/ultralytics/yolov5/pull/5153 - Use YOLOv5n for CI testing by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5154
- Update stale.yml by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5156
- Check
'onnxruntime-gpu' if torch.has_cudaby @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5087 - Add class filtering to
LoadImagesAndLabels()dataloader by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5172 - W&B: fix dpp with wandb disabled by @AyushExel in https://github.com/ultralytics/yolov5/pull/5163
- Update autodownload fallbacks to v6.0 assets by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5177
- W&B: DDP fix by @AyushExel in https://github.com/ultralytics/yolov5/pull/5176
- Adjust legend labels for classes without instances by @NauchtanRobotics in https://github.com/ultralytics/yolov5/pull/5174
- Improved check_suffix() robustness to
''and""by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5192 - Highlight contributors in README by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5173
- Add hyp.scratch-med.yaml by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5196
- Update Objects365.yaml to include the official validation set by @farleylai in https://github.com/ultralytics/yolov5/pull/5194
- Autofix duplicate label handling by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5210
- Update Objects365.yaml val count by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5212
- Update/inplace ops by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5233
- Add
on_fit_epoch_endcallback by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5232 - Update rebase.yml by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5245
- Add dependabot for GH actions by @zhiqwang in https://github.com/ultralytics/yolov5/pull/5250
- Bump cirrus-actions/rebase from 1.4 to 1.5 by @dependabot in https://github.com/ultralytics/yolov5/pull/5251
- Bump actions/cache from 1 to 2.1.6 by @dependabot in https://github.com/ultralytics/yolov5/pull/5252
- Bump actions/stale from 3 to 4 by @dependabot in https://github.com/ultralytics/yolov5/pull/5253
- Update rebase.yml with workflows permissions by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5255
- autosplit: take image files with uppercase extensions into account by @jdfr in https://github.com/ultralytics/yolov5/pull/5269
- take EXIF orientation tags into account when fixing corrupt images by @jdfr in https://github.com/ultralytics/yolov5/pull/5270
- More informative
EarlyStopping()message by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5303 - Uncomment OpenCV 4.5.4 requirement in detect.py by @SamFC10 in https://github.com/ultralytics/yolov5/pull/5305
- Weights download script minor improvements by @CristiFati in https://github.com/ultralytics/yolov5/pull/5213
- Small fixes to docstrings by @zhiqwang in https://github.com/ultralytics/yolov5/pull/5313
- W&B: Media panel fix by @AyushExel in https://github.com/ultralytics/yolov5/pull/5317
- Add
autobatchfeature for bestbatch-sizeestimation by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5092 - Update
AutoShape.forward()model.classes example by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5324 - DDP
nlfix by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5332 - Add pre-commit CI action by @Borda in https://github.com/ultralytics/yolov5/pull/4982
- W&B: Fix sweep by @AyushExel in https://github.com/ultralytics/yolov5/pull/5402
- Update GitHub issues templates by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5404
- Fix
MixConv2d()remove shortcut + apply depthwise by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5410 - Meshgrid
indexing='ij'for PyTorch 1.10 by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5309 - Update
get_loggers()by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/4854 - Update README.md by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5438
- Fixed a small typo in CONTRIBUTING.md by @pranathlcp in https://github.com/ultralytics/yolov5/pull/5445
- Update
check_git_status()to run underROOTworking directory by @MrinalJain17 in https://github.com/ultralytics/yolov5/pull/5441 - Fix tf.py
LoadImages()dataloader return values by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5455 - Remove
check_requirements(('tensorflow>=2.4.1',))by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5476 - Improve GPU name by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5478
- Update torch_utils.py import
LOGGERby @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5483 - Add tf.py verification printout by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5484
- Keras CI fix by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5486
- Delete code-format.yml by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5487
- Fix float zeros format by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5491
- Handle edgetpu model inference by @Namburger in https://github.com/ultralytics/yolov5/pull/5372
- precommit: isort by @Borda in https://github.com/ultralytics/yolov5/pull/5493
- Fix
increment_path()with multiple-suffix filenames by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5518 - Write date in checkpoint file by @developer0hye in https://github.com/ultralytics/yolov5/pull/5514
- Update plots.py feature_visualization path issues by @ys31jp in https://github.com/ultralytics/yolov5/pull/5519
- Update cls bias init by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5520
- Common
is_cocologic betwen train.py and val.py by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5521 - Fix
increment_path()explicit file vs dir handling by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5523 - Fix detect.py URL inference by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5525
- Update
check_file()avoid repeat URL downloads by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5526 - Update export.py by @nanmi in https://github.com/ultralytics/yolov5/pull/5471
- Update train.py by @wonbeomjang in https://github.com/ultralytics/yolov5/pull/5451
- Suppress ONNX export trace warning by @deepsworld in https://github.com/ultralytics/yolov5/pull/5437
- Update autobatch.py by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5536
- Update autobatch.py by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5538
- Update Issue Templates with 💡 ProTip! by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5539
- Update
models/hub/*.yamlfiles for v6.0n release by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5540 -
intersect_dicts()in hubconf.py fix by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5542 - Fix for *.yaml emojis on load by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5543
- Fix
save_one_box()by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5545 - Inside Ultralytics video https://youtu.be/Zgi9g1ksQHc by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5546
- Add
--conf-thres>> 0.001 warning by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5567 -
LOGGERconsolidation by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5569 - New
DetectMultiBackend()class by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5549 - FROM nvcr.io/nvidia/pytorch:21.10-py3 by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5592
- Add
notebook_init()to utils/init.py by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5488 - Fix
check_requirements()resource warning allocation open file by @ayman-saleh in https://github.com/ultralytics/yolov5/pull/5602 - Update train, val
tqdmto fixed width by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5367 - Update val.py
speedandstudytasks by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5608 -
np.unique()sort fix for segments by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5609 - Improve plots.py robustness by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5616
- HUB dataset previews to JPEG by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5627
- DDP
WORLD_SIZE-safe dataloader workers by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5631 - Default DataLoader
shuffle=Truefor training by @werner-duvaud in https://github.com/ultralytics/yolov5/pull/5623 - AutoAnchor and AutoBatch
LOGGERby @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5635 - W&B refactor, handle exceptions, CI example by @AyushExel in https://github.com/ultralytics/yolov5/pull/5618
- Replace 2
transpose()with 1permutein TransformerBlock()` by @dingyiwei in https://github.com/ultralytics/yolov5/pull/5645 - Bump pip from 19.2 to 21.1 in /utils/google_app_engine by @dependabot in https://github.com/ultralytics/yolov5/pull/5661
- Update ci-testing.yml to Python 3.9 by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5660
- TFDetect dynamic anchor count assignment fix by @nrupatunga in https://github.com/ultralytics/yolov5/pull/5668
- Update train.py comment to 'Model attributes' by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5670
- Update export.py docstring by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5689
-
NUM_THREADSleave at least 1 CPU free by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5706 - Prune unused imports by @Borda in https://github.com/ultralytics/yolov5/pull/5711
- Explicitly compute TP, FP in val.py by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5727
- Remove
.autoshape()method by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5694 - SECURITY.md by @IL2006 in https://github.com/ultralytics/yolov5/pull/5695
- Save *.npy features on detect.py
--visualizeby @Zengyf-CVer in https://github.com/ultralytics/yolov5/pull/5701 - Export, detect and validation with TensorRT engine file by @imyhxy in https://github.com/ultralytics/yolov5/pull/5699
- Do not save hyp.yaml and opt.yaml on evolve by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5775
- fix the path error in export.py by @miknyko in https://github.com/ultralytics/yolov5/pull/5778
- TorchScript
torch==1.7.0Path support by @miknyko in https://github.com/ultralytics/yolov5/pull/5781 - W&B: refactor W&B tables by @AyushExel in https://github.com/ultralytics/yolov5/pull/5737
- Scope TF imports in
DetectMultiBackend()by @phodgers in https://github.com/ultralytics/yolov5/pull/5792 - Remove NCOLS from tqdm by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5804
- Refactor new
model.warmup()method by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5810 - GCP VM from Image example by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5814
- Bump actions/cache from 2.1.6 to 2.1.7 by @dependabot in https://github.com/ultralytics/yolov5/pull/5816
- Update
dataset_stats()tocv2.INTER_AREAby @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5821 - Fix TensorRT potential unordered binding addresses by @imyhxy in https://github.com/ultralytics/yolov5/pull/5826
- Handle non-TTY
wandb.errors.UsageErrorby @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5839 - Avoid inplace modifying
imgsinLoadStreamsby @passerbythesun in https://github.com/ultralytics/yolov5/pull/5850 - Update
LoadImagesret_val=Falsehandling by @gmt710 in https://github.com/ultralytics/yolov5/pull/5852 - Update val.py by @pradeep-vishnu in https://github.com/ultralytics/yolov5/pull/5838
- Update TorchScript suffix to
*.torchscriptby @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5856 - Add
--workers 8argument to val.py by @iumyx2612 in https://github.com/ultralytics/yolov5/pull/5857 - Update
plot_lr_scheduler()by @daikankan in https://github.com/ultralytics/yolov5/pull/5864 - Update
nlaftercutout()by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5873 -
AutoShape()models asDetectMultiBackend()instances by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5845 - Single-command multiple-model export by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5882
-
Detections().tolist()explicit argument fix by @lizeng614 in https://github.com/ultralytics/yolov5/pull/5907 - W&B: Fix bug in upload dataset module by @AyushExel in https://github.com/ultralytics/yolov5/pull/5908
- Add *.engine (TensorRT extensions) to .gitignore by @greg2451 in https://github.com/ultralytics/yolov5/pull/5911
- Add ONNX inference providers by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5918
- Add hardware checks to
notebook_init()by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5919 - Revert "Update
plot_lr_scheduler()" by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5920 - Absolute '/content/sample_data' by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5922
- Default PyTorch Hub to
autocast(False)by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5926 - Fix ONNX opset inconsistency with parseargs and run args by @d57montes in https://github.com/ultralytics/yolov5/pull/5937
- Make
select_device()robust tobatch_size=-1by @youyuxiansen in https://github.com/ultralytics/yolov5/pull/5940 - fix .gitignore not tracking existing folders by @pasmai in https://github.com/ultralytics/yolov5/pull/5946
- Update
strip_optimizer()by @iumyx2612 in https://github.com/ultralytics/yolov5/pull/5949 - Add nms and agnostic nms to export.py by @d57montes in https://github.com/ultralytics/yolov5/pull/5938
- Refactor
NUM_THREADSby @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5954 - Fix Detections class
tolist()method by @yonomitt in https://github.com/ultralytics/yolov5/pull/5945 - Fix
imgszbug by @d57montes in https://github.com/ultralytics/yolov5/pull/5948 -
pretrained=Falsefix by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5966 - make parameter ignore epochs by @jinmc in https://github.com/ultralytics/yolov5/pull/5972
- YOLOv5s6 params and FLOPs fix by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5977
- Update callbacks.py with
__init__()by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5979 - Increase
ar_thrfrom 20 to 100 for better detection on slender (high aspect ratio) objects by @MrinalJain17 in https://github.com/ultralytics/yolov5/pull/5556 - Allow
--weights URLby @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5991 - Recommend
jar xf file.zipfor zips by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/5993 - *.torchscript inference
self.jitfix by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6007 - Check TensorRT>=8.0.0 version by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6021
- Multi-layer capable
--freezeargument by @youyuxiansen in https://github.com/ultralytics/yolov5/pull/6019 - train -> val comment fix by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6024
- Add dataset source citations by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6032
- Kaggle
LOGGERfix by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6041 - Simplify
set_logging()indexing by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6042 -
--freezefix by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6044 - OpenVINO Export by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6057
- Reduce G/D/CIoU logic operations by @jedi007 in https://github.com/ultralytics/yolov5/pull/6074
- Init tensor directly on device by @deepsworld in https://github.com/ultralytics/yolov5/pull/6068
- W&B: track batch size after autobatch by @AyushExel in https://github.com/ultralytics/yolov5/pull/6039
- W&B: Log best results after training ends by @AyushExel in https://github.com/ultralytics/yolov5/pull/6120
- Log best results by @awsaf49 in https://github.com/ultralytics/yolov5/pull/6085
- Refactor/reduce G/C/D/IoU
if: elsestatements by @cmoseses in https://github.com/ultralytics/yolov5/pull/6087 - Add EdgeTPU support by @zldrobit in https://github.com/ultralytics/yolov5/pull/3630
- Enable AdamW optimizer by @bilzard in https://github.com/ultralytics/yolov5/pull/6152
- Update export format docstrings by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6151
- Update greetings.yml by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6165
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ultralytics/yolov5/pull/6177
- Update NMS
max_wh=7680for 8k images by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6178 - Add OpenVINO inference by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6179
- Ignore
*_openvino_model/dir by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6180 - Global export format sort by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6182
- Fix TorchScript on mobile export by @yinrong in https://github.com/ultralytics/yolov5/pull/6183
- TensorRT 7
anchor_gridcompatibility fix by @imyhxy in https://github.com/ultralytics/yolov5/pull/6185 - Add
tensorrt>=7.0.0checks by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6193 - Add CoreML inference by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6195
- Fix
nan-robust stream FPS by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6198 - Edge TPU compiler comment by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6196
- TFLite
--int8'flatbuffers==1.12' fix by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6216 - TFLite
--int8'flatbuffers==1.12' fix 2 by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6217 - Add
edgetpu_compilerchecks by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6218 - Attempt
edgetpu-compilerautoinstall by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6223 - Update README speed reproduction command by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6228
- Update P2-P7
models/hubvariants by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6230 - TensorRT 7 export fix by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6235
- Fix
cmdstring ontfjsexport by @dart-bird in https://github.com/ultralytics/yolov5/pull/6243 - Enable ONNX
--halfFP16 inference by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6268 - Update export.py with Detect, Validate usages by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6280
- Add
is_kaggle()function by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6285 - Fix
devicecount check by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6290 - Fixing bug multi-gpu training by @hdnh2006 in https://github.com/ultralytics/yolov5/pull/6299
-
select_device()cleanup by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6302 - Fix
train.pyparameter groups desc error by @Otfot in https://github.com/ultralytics/yolov5/pull/6318 - Remove
dataset_stats()autodownload capability by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6303 - Console corrupted -> corrupt by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6338
- TensorRT
assert im.device.type != 'cpu'on export by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6340 -
export.pyreturn exported files/dirs by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6343 -
export.pyautomaticforward_exportby @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6352 - Add optional
VERBOSEenvironment variable by @johnk2hawaii in https://github.com/ultralytics/yolov5/pull/6353 - Reuse
de_parallel()rather thanis_parallel()by @imyhxy in https://github.com/ultralytics/yolov5/pull/6354 -
DEVICE_COUNTinstead ofWORLD_SIZEto calculatenwby @sitecao in https://github.com/ultralytics/yolov5/pull/6324 - Flush callbacks when on
--evolveby @AyushExel in https://github.com/ultralytics/yolov5/pull/6374 - FROM nvcr.io/nvidia/pytorch:21.12-py3 by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6377
- FROM nvcr.io/nvidia/pytorch:21.10-py3 by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6379
- Add
albumentationsto Dockerfile by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6392 - Add
stop_training=Falseflag to callbacks by @haimat in https://github.com/ultralytics/yolov5/pull/6365 - Add
detect.pyGIF video inference by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6410 - Update
greetings.yamlemail address by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6412 - Rename logger from 'utils.logger' to 'yolov5' by @JonathanSamelson in https://github.com/ultralytics/yolov5/pull/6421
- Prefer
tflite_runtimefor TFLite inference if installed by @motokimura in https://github.com/ultralytics/yolov5/pull/6406 - Update workflows by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6427
- Namespace
VERBOSEenv variable toYOLOv5_VERBOSEby @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6428 - Add
*.asfvideo support by @toschi23 in https://github.com/ultralytics/yolov5/pull/6436 - Revert "Remove
dataset_stats()autodownload capability" by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6442 - Fix
select_device()for Multi-GPU by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6434 - Fix2
select_device()for Multi-GPU by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6461 - Add Product Hunt social media icon by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6464
- Resolve dataset paths by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6489
- Simplify TF normalized to pixels by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6494
- Improved
export.pyusage examples by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6495 - CoreML inference fix
list()->sorted()by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6496 - Suppress
torch.jit.TracerWarningon export by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6498 - Suppress
export.run()TracerWarningby @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6499 - W&B: Remember
batch_sizeon resuming by @AyushExel in https://github.com/ultralytics/yolov5/pull/6512 - Update hyp.scratch-high.yaml
lrf: 0.1by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6525 - TODO issues exempt from stale action by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6530
- Update val_batch*.jpg for Chinese fonts by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6526
- Social icons after text by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6473
- Edge TPU compiler
sudofix by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6531 - Edge TPU export 'list index out of range' fix by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6533
- Edge TPU
tf.lite.experimental.load_delegatefix by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6536 - Fixing minor multi-streaming issues with TensoRT engine by @greg2451 in https://github.com/ultralytics/yolov5/pull/6504
- Load checkpoint on CPU instead of on GPU by @bilzard in https://github.com/ultralytics/yolov5/pull/6516
- flake8: code meanings by @Borda in https://github.com/ultralytics/yolov5/pull/6481
- Fix 6 Flake8 issues by @Borda in https://github.com/ultralytics/yolov5/pull/6541
- Edge TPU TF imports fix by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6542
- Move trainloader functions to class methods by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6559
- Improved AutoBatch DDP error message by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6568
- Fix zero-export handling with
if any(f):by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6569 - Fix
plot_labels()colored histogram bug by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6574 - Allow custom
--evolveproject names by @MattVAD in https://github.com/ultralytics/yolov5/pull/6567 - Add
DATASETS_DIRglobal in general.py by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6578 - return
optfromtrain.run()by @chf4850 in https://github.com/ultralytics/yolov5/pull/6581 - Fix YouTube dislike button bug in
pafypackage by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6603 - Fix
hyp_evolve.yamlindexing bug by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6604 - Fix
ROOT / datawhen running W&Blog_dataset()by @or-toledano in https://github.com/ultralytics/yolov5/pull/6606 - YouTube dependency fix
youtube_dl==2020.12.2by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6612 - Add YOLOv5n to Reproduce section by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6619
- W&B: Improve resume stability by @AyushExel in https://github.com/ultralytics/yolov5/pull/6611
- W&B: don't log media in evolve by @AyushExel in https://github.com/ultralytics/yolov5/pull/6617
- YOLOv5 Export Benchmarks by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6613
- Fix ConfusionMatrix scale
vmin=0.0by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6638 - Fixed wandb logger
KeyErrorby @imyhxy in https://github.com/ultralytics/yolov5/pull/6637 - Fix yolov3.yaml remove list by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6655
- Validate with 2x
--workersby @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6658 - Validate with 2x
--workerssingle-GPU/CPU fix by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6659 - Add
--cache valoption by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6663 - Robust
scipy.cluster.vq.kmeanstoo few points by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6668 - Update Dockerfile
torch==1.10.2+cu113by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6669 - FROM nvcr.io/nvidia/pytorch:22.01-py3 by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6670
- FROM nvcr.io/nvidia/pytorch:21.10-py3 by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6671
- Update Dockerfile reorder installs by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6672
- FROM nvcr.io/nvidia/pytorch:22.01-py3 by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6673
- FROM nvcr.io/nvidia/pytorch:21.10-py3 by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6677
- Fix TF exports >= 2GB by @zldrobit in https://github.com/ultralytics/yolov5/pull/6292
- Fix
--evolve --bucket gs://...by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6698 - Fix CoreML P6 inference by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6700
- Fix floating point in number of workers by @SamuelYvon in https://github.com/ultralytics/yolov5/pull/6701
- Edge TPU inference fix by @RaffaeleGalliera in https://github.com/ultralytics/yolov5/pull/6686
- Use
export_formats()in export.py by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6705 - Suppress
torchAMP-CPU warnings by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6706 - Update
nwtomax(nd, 1)by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6714 - GH: add PR template by @Borda in https://github.com/ultralytics/yolov5/pull/6482
- Switch default LR scheduler from cos to linear by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6729
- Updated VOC hyperparameters by @glenn-jocher in https://github.com/ultralytics/yolov5/pull/6732
New Contributors (48)
- @YoniChechik made their first contribution in https://github.com/ultralytics/yolov5/pull/5153
- @farleylai made their first contribution in https://github.com/ultralytics/yolov5/pull/5194
- @jdfr made their first contribution in https://github.com/ultralytics/yolov5/pull/5269
- @pranathlcp made their first contribution in https://github.com/ultralytics/yolov5/pull/5445
- @MrinalJain17 made their first contribution in https://github.com/ultralytics/yolov5/pull/5441
- @Namburger made their first contribution in https://github.com/ultralytics/yolov5/pull/5372
- @ys31jp made their first contribution in https://github.com/ultralytics/yolov5/pull/5519
- @nanmi made their first contribution in https://github.com/ultralytics/yolov5/pull/5471
- @wonbeomjang made their first contribution in https://github.com/ultralytics/yolov5/pull/5451
- @deepsworld made their first contribution in https://github.com/ultralytics/yolov5/pull/5437
- @ayman-saleh made their first contribution in https://github.com/ultralytics/yolov5/pull/5602
- @werner-duvaud made their first contribution in https://github.com/ultralytics/yolov5/pull/5623
- @nrupatunga made their first contribution in https://github.com/ultralytics/yolov5/pull/5668
- @IL2006 made their first contribution in https://github.com/ultralytics/yolov5/pull/5695
- @Zengyf-CVer made their first contribution in https://github.com/ultralytics/yolov5/pull/5701
- @miknyko made their first contribution in https://github.com/ultralytics/yolov5/pull/5778
- @phodgers made their first contribution in https://github.com/ultralytics/yolov5/pull/5792
- @passerbythesun made their first contribution in https://github.com/ultralytics/yolov5/pull/5850
- @gmt710 made their first contribution in https://github.com/ultralytics/yolov5/pull/5852
- @pradeep-vishnu made their first contribution in https://github.com/ultralytics/yolov5/pull/5838
- @iumyx2612 made their first contribution in https://github.com/ultralytics/yolov5/pull/5857
- @daikankan made their first contribution in https://github.com/ultralytics/yolov5/pull/5864
- @lizeng614 made their first contribution in https://github.com/ultralytics/yolov5/pull/5907
- @greg2451 made their first contribution in https://github.com/ultralytics/yolov5/pull/5911
- @youyuxiansen made their first contribution in https://github.com/ultralytics/yolov5/pull/5940
- @pasmai made their first contribution in https://github.com/ultralytics/yolov5/pull/5946
- @yonomitt made their first contribution in https://github.com/ultralytics/yolov5/pull/5945
- @jinmc made their first contribution in https://github.com/ultralytics/yolov5/pull/5972
- @jedi007 made their first contribution in https://github.com/ultralytics/yolov5/pull/6074
- @awsaf49 made their first contribution in https://github.com/ultralytics/yolov5/pull/6085
- @cmoseses made their first contribution in https://github.com/ultralytics/yolov5/pull/6087
- @bilzard made their first contribution in https://github.com/ultralytics/yolov5/pull/6152
- @pre-commit-ci made their first contribution in https://github.com/ultralytics/yolov5/pull/6177
- @yinrong made their first contribution in https://github.com/ultralytics/yolov5/pull/6183
- @dart-bird made their first contribution in https://github.com/ultralytics/yolov5/pull/6243
- @hdnh2006 made their first contribution in https://github.com/ultralytics/yolov5/pull/6299
- @Otfot made their first contribution in https://github.com/ultralytics/yolov5/pull/6318
- @johnk2hawaii made their first contribution in https://github.com/ultralytics/yolov5/pull/6353
- @sitecao made their first contribution in https://github.com/ultralytics/yolov5/pull/6324
- @haimat made their first contribution in https://github.com/ultralytics/yolov5/pull/6365
- @JonathanSamelson made their first contribution in https://github.com/ultralytics/yolov5/pull/6421
- @motokimura made their first contribution in https://github.com/ultralytics/yolov5/pull/6406
- @toschi23 made their first contribution in https://github.com/ultralytics/yolov5/pull/6436
- @MattVAD made their first contribution in https://github.com/ultralytics/yolov5/pull/6567
- @chf4850 made their first contribution in https://github.com/ultralytics/yolov5/pull/6581
- @or-toledano made their first contribution in https://github.com/ultralytics/yolov5/pull/6606
- @SamuelYvon made their first contribution in https://github.com/ultralytics/yolov5/pull/6701
- @RaffaeleGalliera made their first contribution in https://github.com/ultralytics/yolov5/pull/6686
Full Changelog: https://github.com/ultralytics/yolov5/compare/v6.0...v6.1
v6.0
2 years agov5.0
3 years agoThis release implements YOLOv5-P6 models and retrained YOLOv5-P5 models. All model sizes YOLOv5s/m/l/x are now available in both P5 and P6 architectures:
-
YOLOv5-P5 models (same architecture as v4.0 release): 3 output layers P3, P4, P5 at strides 8, 16, 32, trained at
--img 640
python detect.py --weights yolov5s.pt # P5 models
yolov5m.pt
yolov5l.pt
yolov5x.pt
-
YOLOv5-P6 models: 4 output layers P3, P4, P5, P6 at strides 8, 16, 32, 64 trained at
--img 1280
python detect.py --weights yolov5s6.pt # P6 models
yolov5m6.pt
yolov5l6.pt
yolov5x6.pt
Example usage:
# Command Line
python detect.py --weights yolov5m.pt --img 640 # P5 model at 640
python detect.py --weights yolov5m6.pt --img 640 # P6 model at 640
python detect.py --weights yolov5m6.pt --img 1280 # P6 model at 1280
# PyTorch Hub
model = torch.hub.load('ultralytics/yolov5', 'yolov5m6') # P6 model
results = model(imgs, size=1280) # inference at 1280
Notable Updates
-
YouTube Inference: Direct inference from YouTube videos, i.e.
python detect.py --source 'https://youtu.be/NUsoVlDFqZg'. Live streaming videos and normal videos supported. (https://github.com/ultralytics/yolov5/pull/2752) - AWS Integration: Amazon AWS integration and new AWS Quickstart Guide for simple EC2 instance YOLOv5 training and resuming of interrupted Spot instances. (https://github.com/ultralytics/yolov5/pull/2185)
- Supervise.ly Integration: New integration with the Supervisely Ecosystem for training and deploying YOLOv5 models with Supervise.ly (https://github.com/ultralytics/yolov5/issues/2518)
- Improved W&B Integration: Allows saving datasets and models directly to Weights & Biases. This allows for --resume directly from W&B (useful for temporary environments like Colab), as well as enhanced visualization tools. See this blog by @AyushExel for details. (https://github.com/ultralytics/yolov5/pull/2125)
Updated Results
P6 models include an extra P6/64 output layer for detection of larger objects, and benefit the most from training at higher resolution. For this reason we trained all P5 models at 640, and all P6 models at 1280.

YOLOv5-P5 640 Figure (click to expand)
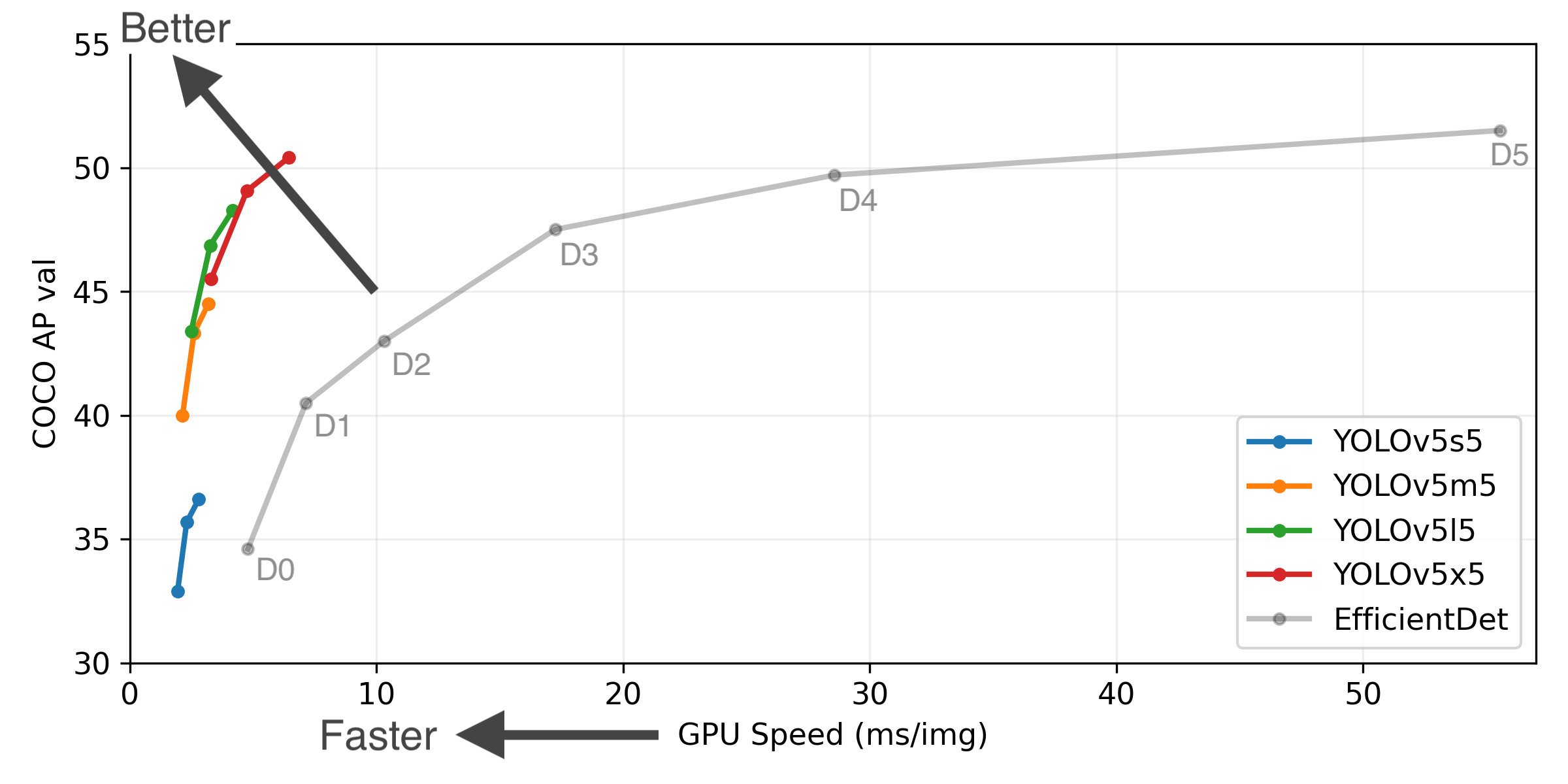
Figure Notes (click to expand)
- GPU Speed measures end-to-end time per image averaged over 5000 COCO val2017 images using a V100 GPU with batch size 32, and includes image preprocessing, PyTorch FP16 inference, postprocessing and NMS.
- EfficientDet data from google/automl at batch size 8.
-
Reproduce by
python test.py --task study --data coco.yaml --iou 0.7 --weights yolov5s6.pt yolov5m6.pt yolov5l6.pt yolov5x6.pt
- April 11, 2021: v5.0 release: YOLOv5-P6 1280 models, AWS, Supervise.ly and YouTube integrations.
- January 5, 2021: v4.0 release: nn.SiLU() activations, Weights & Biases logging, PyTorch Hub integration.
- August 13, 2020: v3.0 release: nn.Hardswish() activations, data autodownload, native AMP.
- July 23, 2020: v2.0 release: improved model definition, training and mAP.
Pretrained Checkpoints
| Model | size (pixels) |
mAPval 0.5:0.95 |
mAPtest 0.5:0.95 |
mAPval 0.5 |
Speed V100 (ms) |
params (M) |
FLOPS 640 (B) |
|
|---|---|---|---|---|---|---|---|---|
| YOLOv5s | 640 | 36.7 | 36.7 | 55.4 | 2.0 | 7.3 | 17.0 | |
| YOLOv5m | 640 | 44.5 | 44.5 | 63.1 | 2.7 | 21.4 | 51.3 | |
| YOLOv5l | 640 | 48.2 | 48.2 | 66.9 | 3.8 | 47.0 | 115.4 | |
| YOLOv5x | 640 | 50.4 | 50.4 | 68.8 | 6.1 | 87.7 | 218.8 | |
| YOLOv5s6 | 1280 | 43.3 | 43.3 | 61.9 | 4.3 | 12.7 | 17.4 | |
| YOLOv5m6 | 1280 | 50.5 | 50.5 | 68.7 | 8.4 | 35.9 | 52.4 | |
| YOLOv5l6 | 1280 | 53.4 | 53.4 | 71.1 | 12.3 | 77.2 | 117.7 | |
| YOLOv5x6 | 1280 | 54.4 | 54.4 | 72.0 | 22.4 | 141.8 | 222.9 | |
| YOLOv5x6 TTA | 1280 | 55.0 | 55.0 | 72.0 | 70.8 | - | - |
Table Notes (click to expand)
- APtest denotes COCO test-dev2017 server results, all other AP results denote val2017 accuracy.
- AP values are for single-model single-scale unless otherwise noted. Reproduce mAP by
python test.py --data coco.yaml --img 640 --conf 0.001 --iou 0.65 - SpeedGPU averaged over 5000 COCO val2017 images using a GCP n1-standard-16 V100 instance, and includes FP16 inference, postprocessing and NMS. Reproduce speed by
python test.py --data coco.yaml --img 640 --conf 0.25 --iou 0.45 - All checkpoints are trained to 300 epochs with default settings and hyperparameters (no autoaugmentation).
- Test Time Augmentation (TTA) includes reflection and scale augmentation. Reproduce TTA by
python test.py --data coco.yaml --img 1536 --iou 0.7 --augment
Changelog
Changes between previous release and this release: https://github.com/ultralytics/yolov5/compare/v4.0...v5.0 Changes since this release: https://github.com/ultralytics/yolov5/compare/v5.0...HEAD
Click a section below to expand details:
Implemented Enhancements (26)
- Return predictions as json #2703
- Single channel image training? #2609
- Images in MPO Format are considered corrupted #2446
- Improve Validation Visualization #2384
- Add ASFF (three fuse feature layers) int the Head for V5(s,m,l,x) #2348
- Dear author, can you provide a visualization scheme for YOLOV5 feature graphs during detect.py? Thank you! #2259
- Dataloader #2201
- Update Train Custom Data wiki page #2187
- Multi-class NMS #2162
- 💡Idea: Mosaic cropping using segmentation labels #2151
- Improving Confusion Matrix Interpretability: FP and FN vectors should be switched to align with Predicted and True axis #2071
- Interpreting model YoloV5 by Grad-cam #2065
- Output optimal confidence threshold based on PR curve #2048
- is it valuable that add --cache-images option to detect.py? #2004
- I want to change the anchor box to anchor circles, where do you think the change to be made ? #1987
- Support for imgaug #1954
- Any plan for Knowledge Distillation? #1762
- Is there a wasy to run detections on a video/webcam/rtrsp, etc EVERY x SECONDS? #1742
- Can yolov5 support rotated target detection? #1728
- Deploying yolov5 to TorchServe (GPU compatible) #1681
- Why diffrent colors of bboxs? #1638
- Yet another export yolov5 models to ONNX and inference with TensorRT #1597
- Rerange the blocks of Focus Layer into
row majorto be compatible with tensorflowSpaceToDepth#413 - YouTube Livestream Detection #2752 (ben-milanko)
- Add TransformerLayer, TransformerBlock, C3TR modules #2333 (dingyiwei)
- Improved W&B integration #2125 (AyushExel)
Fixed Bugs (73)
- it seems that check_wandb_resume don't support multiple input files of images. #2716
- ip camera or web camera. error: (-215:Assertion failed) !ss ize.empty() in function 'cv::resize' #2709
- Model predict with forward will fail if PIL image does not have filename attribute #2702
- ❔Question Whenever i try to run my model i run into this error AttributeError: 'NoneType' object has no attribute 'startswith' from wandbutils.py line 161 I wonder why ? Any workaround or fix #2697
- coremltools no longer included in docker container #2686
- 'LoadImages' path handling appears to be broken #2618
- CUDA memory leak #2586
- UnboundLocalError: local variable 'wandb_logger' referenced before assignment #2562
- RuntimeError: CUDA error: CUBLAS_STATUS_INTERNAL_ERROR when calling
cublasCreate\(handle\)#2417 - CUDNN Mapping Error #2415
- Can't train in DDP mode after recent update #2405
- a bug about function bbox_iou() #2376
- Training got stuck when I used DistributedDataParallel mode but dataParallel mode is useful #2375
- Something wrong with fixing ema #2343
- Conversion to CoreML fails when running with --batch 2 #2322
- The "fitness" function in train.py. #2303
- Error "Directory already existed" happen when training with multiple GPUs #2275
- self.balance = {3: [4.0, 1.0, 0.4], 4: [4.0, 1.0, 0.25, 0.06], 5: [4.0, 1.0, 0.25, 0.06, .02]}[det.nl] #2255
- Cannot run model with URL as argument #2246
- Yolov5 crashes with RTSP stream analysis #2226
- interruption during evolve #2218
- I am a student of Tsinghua University, doing research in Tencent. When I train with yolov5, the following problems appear,Sincerely hope to get help, #2203
- Frame Loss in video stream #2196
- wandb.ai not logging epochs vs metrics/losses instead uses step #2175
- Evolve is leaking files #2142
- Issue in torchscript model inference #2129
- RuntimeError: CUDA error: device-side assert triggered #2124
- In 'evolve' mode, If the original hyp is 0, It will never update #2122
- Caching image path #2121
- can't convert cuda:0 device type tensor to numpy. Use Tensor.cpu() to copy the tensor to host memory first #2106
- Error in creating model with Ghost modules #2081
- TypeError: int() can't convert non-string with explicit base #2066
- [Pytorch Hub] Hub CI is broken with latest master of yolo5 example. #2050
- Problems when downloading requirements #2047
- detect.py - images always saved #2029
- thop and pycocotools shouldn't be hard requirements to train a model #2014
- CoreML export failure #2007
- loss function like has a bug #1988
- CoreML export failure: unexpected number of inputs for node x.2 (_convolution): 13 #1945
- torch.nn.modules.module.ModuleAttributeError: 'Hardswish' object has no attribute 'inplace' #1939
- runs not logging separately in wandb.ai #1937
- wrong batch size after --resume on multiple GPUs #1936
- TypeError: int() can't convert non-string with explicit base #1927
- RuntimeError: DataLoader worker #1908
- Unable to export weights into onnx #1900
- CUDA Initialization Warning on Docker when not passing in gpu #1891
- Issue with github api rate limiting #1890
- wandb: ERROR Error while calling W&B API: Error 1062: Duplicate entry '189160-gbp6y2en' for key 'PRIMARY' (<Response [409]>) #1878
- Broken pipe #1859
- detection.py #1858
- Getting error on loading custom trained model #1856
- W&B id is always the same and continue with the old logging. #1851
- pytorch1.7 is not completely support.'inplace'! 'inplace'! 'inplace'! #1832
- Validation errors are NaN #1804
- Error Loading custom model weights with pytorch.hub.load #1788
- 'cap' object is not self. initialized #1781
- ValueError: API key must be 40 characters long, yours was 1 #1777
- scipy #1766
- error of missing key 'anchors' in hyp.scratch.yaml #1744
- mss grab color conversion problem using TorchHub #1735
- Video rotation when running detection. #1725
- RuntimeError: CUDA out of memory. Tried to allocate 294.00 MiB (GPU 0; 6.00 GiB total capacity; 118.62 MiB already allocated; 4.20 GiB free; 362.00 MiB reserved in total by PyTorch) #1698
- Errors on MAC #1690
- RuntimeError: DataLoader worker (pid(s) 296430) exited unexpectedly #1675
- Non-positive Stride #1671
- gbk error. How can I solve it? #1669
- CoreML export failure: unexpected number of inputs for node x.2 (_convolution): 13 #1667
- RuntimeError: Given groups=1, weight of size [32, 128, 1, 1], expected input[1, 64, 32, 32] to have 128 channels, but got 64 channels instead #1627
- segmentation fault #1620
- Getting different output sizes when using exported torchscript #1562
- some bugs when training #1547
- Evolve getting error #1319
- AssertionError: Image Not Found ../dataset/images/train/4501.jpeg #195
Closed Issues (42)
- Can feed tensor the model #2722
- hello, everyone, In order to modify the network more conveniently based on this rep., I restructure the network part, which is divided into backbone, neck, head #2710
- Differentiate between normal banner and LED banner #2647
- 👋 Hello @Wilson-inclaims, thank you for your interest in 🚀 YOLOv5! Please visit our ⭐️ [Tutorials](https://github.com/ultralytics/yolov5/wiki#tutorials) to get started, where you can find quickstart guides for simple tasks like [Custom Data Training](https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data) all the way to advanced concepts like [Hyperparameter Evolution](https://github.com/ultralytics/yolov5/issues/607). #2516
- I got a runtimerror when I run classifier.py to train my own dataset. #2438
- RuntimeError: a view of a leaf Variable that requires grad is being used in an in-place operation. #2403
- 🌟💡 YOLOv5 Study: batch size #2377
- export.py export onnx for gpu failed #2365
- in _ddp_init_helper expect_sparse_gradient) RuntimeError: Model replicas must have an equal number of parameters. #2311
- Custom dataset training using YOLOv5 #2296
- label format #2293
- MAP NOT PRINTING #2283
- Why didn't I get results in my video test? #2277
- Label Missing: for images and labels... 203 found, 50 missing, 0 empty, 0 corrupted: 100% #2268
- Pytorch Hub inference returns different results than detect.py #2224
- yolov5x train.py error #2181
- degrees is radians? #2160
- AssertionError: Image Not Found #2130
- How to load custom trained model to detect sample image? #2097
- YOLOv5 installed failed on Macbook M1 #2075
- How to set the number of seconds to detect once #2072
- Where the changes should be made to detect horizontal line and vertical lines? Can anyone discus elaborately? #2070
- Video inference stops after a certain number of frames #2064
- Can't YOLOV5 be detected with multithreading? #1979
- I want to make a images file what divided images in test.py #1931
- different image size w/ torchscript windows c++ #1920
- run detect the result ,the Image don't have box #1910
- resume problem #1884
- Detect source as .txt error #1877
- yolov5 v4.0 tensorrt deployment #1874
- Hyperparameter Evolution: load dataset every time #1864
- Caching images problem #1862
- About Release v4.0 #1841
- @glenn best practices for running trained YOLOv5 models in new python environments is to use PyTorch Hub. See PyTorch Hub Tutorial: #1789
- yolov5x.pt is not compatible with ./models/yolov5x.yam #1721
- Parameter '--device' doesn't work! #1706
- Thank you for your issue! #1687
- Convert the label format #1652
- Autorun not working #1599
- When model.model[-1]. export = False in export.py, coreml export failing. Please check. #1491
- Error 'AttributeError: 'str' object has no attribute 'get'' at running train.py #1479
- Docker image is not working,
torch.nn.modules.module.ModuleAttributeError: 'Hardswish' object has no attribute 'inplace' #1327
Merged Pull Requests (172)
- Tensorboard model visualization bug fix #2758 (glenn-jocher)
- utils/wandb_logging PEP8 reformat #2755 (glenn-jocher)
- torch.cuda.amp bug fix #2750 (glenn-jocher)
- autocast enable=torch.cuda.is_available() #2748 (glenn-jocher)
- Add Hub results.pandas() method #2725 (glenn-jocher)
- Update README with collapsable notes #2721 (glenn-jocher)
- Fix #2716: Add support for list-of-directory data format for wandb #2719 (AyushExel)
- Updated filename attributes for YOLOv5 Hub BytesIO #2718 (glenn-jocher)
- Updated filename attributes for YOLOv5 Hub results #2708 (glenn-jocher)
- pip install coremltools onnx #2690 (glenn-jocher)
- autoShape forward im = np.asarray(im) # to numpy #2689 (glenn-jocher)
- PyTorch Hub model.save() increment as runs/hub/exp #2684 (glenn-jocher)
- Fix: #2674 #2683 (AyushExel)
- Update README with Tips for Best Results tutorial #2682 (glenn-jocher)
- Disallow resume for dataset uploading #2657 (AyushExel)
- Speed profiling improvements #2648 (glenn-jocher)
- Add tqdm pbar.close() #2644 (zzttqu)
- PyTorch Hub amp.autocast() inference #2641 (glenn-jocher)
- PyTorch Hub custom model to CUDA device fix #2636 (glenn-jocher)
- Improve git_describe() fix 1 #2635 (glenn-jocher)
- Fix: evolve with wandb #2634 (AyushExel)
- Improve git_describe() #2633 (glenn-jocher)
- FROM nvcr.io/nvidia/pytorch:21.03-py3 #2623 (glenn-jocher)
- Remove conflicting nvidia-tensorboard package #2622 (glenn-jocher)
- Update Detections() self.n comment #2620 (glenn-jocher)
- Update detections() self.t = tuple() #2617 (glenn-jocher)
- Create date_modified() #2616 (glenn-jocher)
- Added '.mpo' to supported image formats #2615 (maxupp)
- Fix Indentation in test.py #2614 (AyushExel)
- Update git_describe() for remote dir usage #2606 (glenn-jocher)
- Remove Cython from requirements.txt #2604 (glenn-jocher)
- resume.py fix DDP typo #2603 (glenn-jocher)
- Update segment2box() comment #2600 (glenn-jocher)
- Save webcam results, add --nosave option #2598 (glenn-jocher)
- YOLOv5 PyTorch Hub models >> check_requirements() #2592 (glenn-jocher)
- YOLOv5 PyTorch Hub models >> check_requirements() #2591 (glenn-jocher)
- YOLOv5 PyTorch Hub models >> check_requirements() #2588 (glenn-jocher)
- W&B DDP fix 2 #2587 (glenn-jocher)
- W&B resume ddp from run link fix #2579 (AyushExel)
- YOLOv5 PyTorch Hub models >> check_requirements() #2577 (glenn-jocher)
- Update tensorboard>=2.4.1 #2576 (glenn-jocher)
- Enhanced check_requirements() with auto-install #2575 (glenn-jocher)
- W&B DDP fix #2574 (AyushExel)
- check_requirements() exclude pycocotools, thop #2571 (glenn-jocher)
- Update Detections() times=None #2570 (glenn-jocher)
- Add opencv-contrib-python to requirements.txt #2564 (youngjinshin)
- Supervisely Ecosystem #2519 (mkolomeychenko)
- add option to disable half precision when testing #2507 (bfineran)
- PyTorch Hub models default to CUDA:0 if available #2472 (glenn-jocher)
- Scipy kmeans-robust autoanchor update #2470 (glenn-jocher)
- Be able to create dataset from annotated images only #2466 (kinoute)
- autoShape() speed profiling update #2460 (glenn-jocher)
- Add autoShape() speed profiling #2459 (glenn-jocher)
- CVPR 2021 Argoverse-HD autodownload curl #2455 (glenn-jocher)
- labels.jpg class names #2454 (glenn-jocher)
- Update test.py --task train val study #2453 (glenn-jocher)
- Integer printout #2450 (glenn-jocher)
- DDP after autoanchor reorder #2421 (glenn-jocher)
- CVPR 2021 Argoverse-HD autodownload fix #2418 (glenn-jocher)
- CVPR 2021 Argoverse-HD dataset autodownload support #2400 (karthiksharma98)
- GCP sudo docker userdata.sh #2393 (glenn-jocher)
- AWS wait && echo "All tasks done." #2391 (glenn-jocher)
- bbox_iou() stability and speed improvements #2385 (glenn-jocher)
- image weights compatible faster random index generator v2 for mosaic … #2383 (developer0hye)
- ENV HOME=/usr/src/app #2382 (glenn-jocher)
- --no-cache notebook #2381 (glenn-jocher)
- Resume with custom anchors fix #2361 (glenn-jocher)
- Anchor override for training from scratch #2350 (glenn-jocher)
- faster random index generator for mosaic augmentation #2345 (developer0hye)
- Add --label-smoothing eps argument to train.py (default 0.0) #2344 (ptran1203)
- FROM nvcr.io/nvidia/pytorch:21.02-py3 #2341 (glenn-jocher)
- EMA bug fix 2 #2330 (glenn-jocher)
- remove TTA 1 pixel offset #2325 (glenn-jocher)
- Update Dockerfile install htop #2320 (glenn-jocher)
- Update test.py #2319 (glenn-jocher)
- final_epoch EMA bug fix #2317 (glenn-jocher)
- Fix labels being missed when image extension appears twice in filename #2300 (idenc)
- W&B entity support #2298 (toretak)
- GPU export options #2297 (toretak)
- Improved model+EMA checkpointing fix #2295 (glenn-jocher)
- Improved model+EMA checkpointing #2292 (glenn-jocher)
- Update train.py #2290 (glenn-jocher)
- Amazon AWS EC2 startup and re-startup scripts patch #2282 (glenn-jocher)
- FLOPS min stride 32 #2276 (xiaowo1996)
- Update Dockerfile with apt install zip #2274 (glenn-jocher)
- Update greetings.yml for auto-rebase on PR #2272 (glenn-jocher)
- Update minimum stride to 32 #2266 (glenn-jocher)
- Robust objectness loss balancing #2256 (glenn-jocher)
- Update inference default to multi_label=False #2252 (glenn-jocher)
- Improved hubconf.py CI tests #2251 (glenn-jocher)
- YOLOv5 Hub URL inference bug fix #2250 (glenn-jocher)
- Unified hub and detect.py box and labels plotting #2243 (kinoute)
- Add isdocker() #2232 (glenn-jocher)
- Add check_imshow() #2231 (glenn-jocher)
- Update CI badge #2230 (glenn-jocher)
- Update yolo.py channel array #2223 (glenn-jocher)
- LoadStreams() frame loss bug fix #2222 (glenn-jocher)
- TTA augument boxes one pixel shifted in de-flip ud and lr #2219 (VdLMV)
- Dynamic ONNX engine generation #2208 (aditya-dl)
- YOLOv5 PyTorch Hub results.save() method retains filenames #2194 (dan0nchik)
- YOLOv5 Segmentation Dataloader Updates #2188 (glenn-jocher)
- Amazon AWS EC2 startup and re-startup scripts #2185 (glenn-jocher)
- PyTorch Hub results.save('path/to/dir') #2179 (glenn-jocher)
- Changed socket port and added timeout #2176 (NanoCode012)
- Update utils/datasets.py to support .webp files #2174 (Transigent)
- Update requirements.txt #2173 (glenn-jocher)
- Update detect.py #2167 (ab-101)
- Update data-autodownload background tasks #2154 (glenn-jocher)
- Linear LR scheduler option #2150 (glenn-jocher)
- Update train.py batch_size * 2 #2149 (glenn-jocher)
- Update train.py test batch_size #2148 (glenn-jocher)
- LoadImages() pathlib update #2140 (glenn-jocher)
- Unique *.cache filenames fix #2134 (train255)
- Making inference thread-safe by avoiding mutable state in Detect class #2120 (olehb)
- Make normalized confusion matrix more interpretable #2114 (rbavery)
- Update plot_study() #2112 (glenn-jocher)
- Update test.py --task speed and study #2099 (glenn-jocher)
- Add variable-stride inference support #2091 (glenn-jocher)
- Add Kaggle badge #2090 (glenn-jocher)
- Add Amazon Deep Learning AMI environment #2085 (glenn-jocher)
- Add YOLOv5-P6 models #2083 (glenn-jocher)
- GhostConv update #2082 (glenn-jocher)
- W&B epoch logging update #2073 (glenn-jocher)
- Update to colors.TABLEAU_COLORS #2069 (glenn-jocher)
- Update run-once lines #2058 (glenn-jocher)
- Metric-Confidence plots feature addition #2057 (glenn-jocher)
- Add histogram equalization fcn #2049 (glenn-jocher)
- Confusion matrix native image-space fix #2046 (ramonhollands)
- Check im.format during dataset caching #2042 (glenn-jocher)
- Add exclude tuple to check_requirements() #2041 (glenn-jocher)
- data-autodownload background tasks #2034 (glenn-jocher)
- Docker pyYAML>=5.3.1 fix #2031 (glenn-jocher)
- PyYAML==5.4.1 #2030 (glenn-jocher)
- Update autoshape .print() and .save() #2022 (glenn-jocher)
- Update requirements.txt #2021 (glenn-jocher)
- Update general.py check_git_status() fix #2020 (glenn-jocher)
- Update inference multiple-counting #2019 (glenn-jocher)
- Update ci-testing.yml --img 128 #2018 (glenn-jocher)
- Update google_utils.py attempt_download() fix #2017 (glenn-jocher)
- Update Dockerfile #2016 (glenn-jocher)
- check_git_status() Windows fix #2015 (glenn-jocher)
- --verbose on final_epoch #1997 (glenn-jocher)
- Add xywhn2xyxy() #1983 (glenn-jocher)
- Update Dockerfile #1982 (glenn-jocher)
- check_git_status() asserts #1977 (glenn-jocher)
- Update train.py #1972 (Anon-Artist)
- Update autoanchor.py #1971 (Anon-Artist)
- Update yolo.py #1970 (Anon-Artist)
- Update test.py #1969 (Anon-Artist)
- Update plots.py #1968 (Anon-Artist)
- check_git_status() when not exist /workspace #1966 (glenn-jocher)
- Security Fix for Arbitrary Code Execution - huntr.dev #1962 (huntr-helper)
- prevent check_git_status() in docker images #1951 (glenn-jocher)
- Add ComputeLoss() class #1950 (glenn-jocher)
- W&B mosaic log bug fix #1949 (glenn-jocher)
- Start setting up the improved W&B integration #1948 (AyushExel)
- W&B log epoch #1946 (glenn-jocher)
- Daemon thread mosaic plots fix #1943 (glenn-jocher)
- Fix batch-size on resume for multi-gpu #1942 (NanoCode012)
- Add nn.SiLU inplace in attempt_load() #1940 (1991wangliang)
- GitHub API rate limit fallback #1930 (glenn-jocher)
- check_git_status() bug fix #1925 (glenn-jocher)
- check_git_status() improvements #1916 (glenn-jocher)
- Colorstr() updates #1909 (glenn-jocher)
- PyTorch Hub results.render() #1897 (glenn-jocher)
- Docker CUDA warning fix #1895 (glenn-jocher)
- GitHub API rate limit fix #1894 (glenn-jocher)
- Add colorstr() #1887 (glenn-jocher)
- auto-verbose if nc <= 20 #1869 (glenn-jocher)
- actions/stale@v3 #1868 (glenn-jocher)
- Add check_requirements() #1853 (glenn-jocher)
- W&B ID reset on training completion #1852 (TommyZihao)
v4.0
3 years agoThis release implements two architecture changes to YOLOv5, as well as various bug fixes and performance improvements.
Breaking Changes
- nn.SiLU() activations replace nn.LeakyReLU(0.1) and nn.Hardswish() activations used in previous versions. nn.SiLU() was introduced in PyTorch 1.7.0 (https://pytorch.org/docs/stable/generated/torch.nn.SiLU.html), and due to the recent timeframe certain export pipelines may be temporarily unavailable (CoreML possibly) without updates to the associated tools (i.e. coremltools).
Bug Fixes
- Multi-GPU --resume #1810
- leaf Variable inplace bug fix #1759
- Various additional bug fixes contained in PRs #1235 through #1837
Added Functionality
- Weights & Biases (W&B) Feature Addition #1235
- Utils reorganization #1392
- PyTorch Hub and autoShape update #1415
- W&B artifacts feature addition #1712
- Various additional feature additions contained in PRs #1235 through #1837
Updated Results
Latest models are all slightly smaller to due removal of one convolution within each bottleneck, which have been renamed as C3() modules now in light of the 3 I/O convolutions each one does vs the 4 in the standard CSP bottleneck. The previous manual concatenation and LeakyReLU(0.1) activations have both removed, simplifying the architecture, reducing parameter count, and better exploiting the .fuse() operation at inference time.
nn.SiLU() activations replace nn.LeakyReLU(0.1) and nn.Hardswish() activations throughout the model, simplifying the architecture as we now only have one single activation function used everywhere rather than the two types before.
In general the changes result in smaller models (89.0M params -> 87.7M YOLOv5x), faster inference times (6.9ms -> 6.0ms), and improved mAP (49.2 -> 50.1) for all models except YOLOv5s, which reduced mAP slightly (37.0 -> 36.8). In general the largest models benefit the most from this update. YOLOv5x in particular is now above 50.0 mAP at --img-size 640, which may be the first time this is possible at 640 resolution for any architecture I'm aware of (correct me if I'm wrong though).
 ** GPU Speed measures end-to-end time per image averaged over 5000 COCO val2017 images using a V100 GPU with batch size 32, and includes image preprocessing, PyTorch FP16 inference, postprocessing and NMS. EfficientDet data from google/automl at batch size 8.
** GPU Speed measures end-to-end time per image averaged over 5000 COCO val2017 images using a V100 GPU with batch size 32, and includes image preprocessing, PyTorch FP16 inference, postprocessing and NMS. EfficientDet data from google/automl at batch size 8.
Pretrained Checkpoints
| Model | size | APval | APtest | AP50 | SpeedV100 | FPSV100 | params | GFLOPS | |
|---|---|---|---|---|---|---|---|---|---|
| YOLOv5s | 640 | 36.8 | 36.8 | 55.6 | 2.2ms | 455 | 7.3M | 17.0 | |
| YOLOv5m | 640 | 44.5 | 44.5 | 63.1 | 2.9ms | 345 | 21.4M | 51.3 | |
| YOLOv5l | 640 | 48.1 | 48.1 | 66.4 | 3.8ms | 264 | 47.0M | 115.4 | |
| YOLOv5x | 640 | 50.1 | 50.1 | 68.7 | 6.0ms | 167 | 87.7M | 218.8 | |
| YOLOv5x + TTA | 832 | 51.9 | 51.9 | 69.6 | 24.9ms | 40 | 87.7M | 1005.3 |
v3.1
3 years agoThis release aggregates various minor bug fixes and performance improvements since the main v3.0 release and incorporates PyTorch 1.7.0 compatibility updates. v3.1 models share weights with v3.0 models but contain minor module updates (inplace fields for nn.Hardswish() activations) for native PyTorch 1.7.0 compatibility. For PyTorch 1.7.0 release updates see https://github.com/pytorch/pytorch/releases/tag/v1.7.0.
Breaking Changes
- 'giou' hyperparameter has been renamed to 'box' to better reflect a criteria-agnostic regression loss term (https://github.com/ultralytics/yolov5/pull/1120)
Bug Fixes
- PyTorch 1.7 compatibility update.
torch>=1.6.0required,torch>=1.7.0recommended (https://github.com/ultralytics/yolov5/pull/1233) - GhostConv module bug fix (https://github.com/ultralytics/yolov5/pull/1176)
- Rectangular padding min stride bug fix from 64 to 32 (https://github.com/ultralytics/yolov5/pull/1165)
- Mosaic4 bug fix (https://github.com/ultralytics/yolov5/pull/1021)
- Logging directory runs/exp bug fix (https://github.com/ultralytics/yolov5/pull/978)
- Various additional
Added Functionality
- PyTorch Hub functionality with YOLOv5 .autoshape() method added (https://github.com/ultralytics/yolov5/pull/1210)
- Autolabelling addition and standardization across detect.py and test.py (https://github.com/ultralytics/yolov5/pull/1182)
- Precision-Recall Curve automatic plotting when testing (https://github.com/ultralytics/yolov5/pull/1107)
- Self-host VOC dataset for more reliable access and faster downloading (https://github.com/ultralytics/yolov5/pull/1077)
- Adding option to output autolabel confidence with --save-conf in test.py and detect.py (https://github.com/ultralytics/yolov5/pull/994)
- Google App Engine deployment option (https://github.com/ultralytics/yolov5/pull/964)
- Infinite Dataloader for faster training (https://github.com/ultralytics/yolov5/pull/876)
- Various additional
v3.0
3 years agoThis releases includes nn.Hardswish() activation implementation on Conv() modules, which increases mAP for all models at the expense of about 10% in inference speed. Training speeds are not significantly affected, though CUDA memory requirements increase about 10%. Training from scratch as well as finetuning both benefit from this change. The smallest models benefit the most from the Hardswish() activations, with increases of +0.9/+0.8/+0.7/[email protected]:0.95 for YOLOv5s/m/l/x.
All mAP values in our README are now reported at --img-size 640 (v2.0 reported at 672, and v1.0 reported at 736), so we've succeeded in increasing mAP while reducing the required --img-size :)
We've also listed YOLOv5x Test Time Augmentation (TTA) mAP and speeds for v3.0 in our README table for the first time (and for v2.0 below). Best results are YOLOv5x with TTA at 50.8 [email protected]:0.95. We've also updated efficientdet results in our comparison plot to reflect recent improvements in the google/automl repo.
Breaking Changes
- This release does not contain breaking changes.
- This release is only backwards compatible with v2.0 models trained with torch>=1.6.
Bug Fixes
- Hyperparameter evolution fixed, tutorial added (https://github.com/ultralytics/yolov5/issues/607)
Added Functionality
-
PyTorch 1.6 compatible.
torch>=1.6required (43a616a9551cd53f031c05688884927ba0c13513) -
PyTorch 1.6 native Automatic Mixed Precision (AMP) replaces NVIDIA Apex AMP (https://github.com/ultralytics/yolov5/pull/573)
-
nn.Hardswish()activations replacenn.LeakyReLU(0.1)in base convolution modulemodels.Conv() -
Dataset Autodownload feature added (https://github.com/ultralytics/yolov5/pull/685)
-
Model Autodownload improved (https://github.com/ultralytics/yolov5/pull/711)
-
Layer freezing code added (https://github.com/ultralytics/yolov5/issues/679)
-
TensorRT export tutorial added (https://github.com/ultralytics/yolov5/pull/623)
 ** GPU Speed measures end-to-end time per image averaged over 5000 COCO val2017 images using a V100 GPU with batch size 32, and includes image preprocessing, PyTorch FP16 inference, postprocessing and NMS. EfficientDet data from google/automl at batch size 8.
** GPU Speed measures end-to-end time per image averaged over 5000 COCO val2017 images using a V100 GPU with batch size 32, and includes image preprocessing, PyTorch FP16 inference, postprocessing and NMS. EfficientDet data from google/automl at batch size 8.
-
August 13, 2020: v3.0 release: nn.Hardswish() activations, data autodownload, native AMP.
-
July 23, 2020: v2.0 release: improved model definition, training and mAP.
-
June 22, 2020: PANet updates: new heads, reduced parameters, improved speed and mAP 364fcfd.
-
June 19, 2020: FP16 as new default for smaller checkpoints and faster inference d4c6674.
-
June 9, 2020: CSP updates: improved speed, size, and accuracy (credit to @WongKinYiu for CSP).
-
May 27, 2020: Public release. YOLOv5 models are SOTA among all known YOLO implementations.
-
April 1, 2020: Start development of future compound-scaled YOLOv3/YOLOv4-based PyTorch models.
Pretrained Checkpoints
v3.0 with nn.Hardswish()
| Model | APval | APtest | AP50 | SpeedGPU | FPSGPU | params | FLOPS | |
|---|---|---|---|---|---|---|---|---|
| YOLOv5s | 37.0 | 37.0 | 56.2 | 2.4ms | 476 | 7.5M | 13.2B | |
| YOLOv5m | 44.3 | 44.3 | 63.2 | 3.4ms | 333 | 21.8M | 39.4B | |
| YOLOv5l | 47.7 | 47.7 | 66.5 | 4.4ms | 256 | 47.8M | 88.1B | |
| YOLOv5x | 49.2 | 49.2 | 67.7 | 6.9ms | 164 | 89.0M | 166.4B | |
| YOLOv5x + TTA | 50.8 | 50.8 | 68.9 | 25.5ms | 39 | 89.0M | 354.3B | |
| YOLOv3-SPP | 45.6 | 45.5 | 65.2 | 4.5ms | 222 | 63.0M | 118.0B |
** APtest denotes COCO test-dev2017 server results, all other AP results in the table denote val2017 accuracy.
** All AP numbers are for single-model single-scale without ensemble or test-time augmentation except for TTA. Reproduce by python test.py --data coco.yaml --img 640 --conf 0.001. Test Time Augmentation (TTA) runs at 3 image sizes. Reproduce TTA results by python test.py --data coco.yaml --img 832 --augment
** SpeedGPU measures end-to-end time per image averaged over 5000 COCO val2017 images using a GCP n1-standard-16 instance with one V100 GPU, and includes image preprocessing, PyTorch FP16 image inference at --batch-size 32 --img-size 640, postprocessing and NMS. Average NMS time included in this chart is 1-2ms/img. Reproduce by python test.py --data coco.yaml --img 640 --conf 0.1
** All checkpoints are trained to 300 epochs with default settings and hyperparameters (no autoaugmentation).
v2.0 with nn.LeakyReLU(0.1)
| Model | APval | APtest | AP50 | SpeedGPU | FPSGPU | params | FLOPS | |
|---|---|---|---|---|---|---|---|---|
| YOLOv5s | 36.1 | 36.1 | 55.3 | 2.2ms | 476 | 7.5M | 13.2B | |
| YOLOv5m | 43.5 | 43.5 | 62.5 | 3.2ms | 333 | 21.8M | 39.4B | |
| YOLOv5l | 47.0 | 47.1 | 65.6 | 4.1ms | 256 | 47.8M | 88.1B | |
| YOLOv5x | 49.0 | 49.0 | 67.4 | 6.4ms | 164 | 89.0M | 166.4B | |
| YOLOv5x + TTA | 50.4 | 50.4 | 68.5 | 23.4ms | 43 | 89.0M | 354.3B | |
| YOLOv3-SPP | 45.6 | 45.5 | 65.2 | 4.5ms | 222 | 63.0M | 118.0B |
** APtest denotes COCO test-dev2017 server results, all other AP results in the table denote val2017 accuracy.
** All AP numbers are for single-model single-scale without ensemble or test-time augmentation. Reproduce by python test.py --data coco.yaml --img 672 --conf 0.001
** SpeedGPU measures end-to-end time per image averaged over 5000 COCO val2017 images using a GCP n1-standard-16 instance with one V100 GPU, and includes image preprocessing, PyTorch FP16 image inference at --batch-size 32 --img-size 640, postprocessing and NMS. Average NMS time included in this chart is 1-2ms/img. Reproduce by python test.py --data coco.yaml --img 640 --conf 0.1
** All checkpoints are trained to 300 epochs with default settings and hyperparameters (no autoaugmentation).
v2.0
3 years agoBreaking Changes
IMPORTANT: v2.0 release contains breaking changes. Models trained with earlier versions will not operate correctly with v2.0. The last commit before v2.0 that operates correctly with all earlier pretrained models is: https://github.com/ultralytics/yolov5/tree/5e970d45c44fff11d1eb29bfc21bed9553abf986
To clone last commit prior to v2.0:
git clone https://github.com/ultralytics/yolov5 # clone repo
cd yolov5
git reset --hard 5e970d4 # last commit before v2.0
Bug Fixes
- Various
Added Functionality
- Various
 ** GPU Speed measures end-to-end time per image averaged over 5000 COCO val2017 images using a V100 GPU with batch size 8, and includes image preprocessing, PyTorch FP16 inference, postprocessing and NMS.
** GPU Speed measures end-to-end time per image averaged over 5000 COCO val2017 images using a V100 GPU with batch size 8, and includes image preprocessing, PyTorch FP16 inference, postprocessing and NMS.
- July 23, 2020: v2.0 release: improved model definition, training and mAP.
- June 22, 2020: PANet updates: new heads, reduced parameters, improved speed and mAP 364fcfd.
- June 19, 2020: FP16 as new default for smaller checkpoints and faster inference d4c6674.
- June 9, 2020: CSP updates: improved speed, size, and accuracy (credit to @WongKinYiu for CSP).
- May 27, 2020: Public release. YOLOv5 models are SOTA among all known YOLO implementations.
- April 1, 2020: Start development of future compound-scaled YOLOv3/YOLOv4-based PyTorch models.
Pretrained Checkpoints
| Model | APval | APtest | AP50 | SpeedGPU | FPSGPU | params | FLOPS | |
|---|---|---|---|---|---|---|---|---|
| YOLOv5s | 36.1 | 36.1 | 55.3 | 2.1ms | 476 | 7.5M | 13.2B | |
| YOLOv5m | 43.5 | 43.5 | 62.5 | 3.0ms | 333 | 21.8M | 39.4B | |
| YOLOv5l | 47.0 | 47.1 | 65.6 | 3.9ms | 256 | 47.8M | 88.1B | |
| YOLOv5x | 49.0 | 49.0 | 67.4 | 6.1ms | 164 | 89.0M | 166.4B | |
| YOLOv3-SPP | 45.6 | 45.5 | 65.2 | 4.5ms | 222 | 63.0M | 118.0B |
** APtest denotes COCO test-dev2017 server results, all other AP results in the table denote val2017 accuracy.
** All AP numbers are for single-model single-scale without ensemble or test-time augmentation. Reproduce by python test.py --data coco.yaml --img 672 --conf 0.001
** SpeedGPU measures end-to-end time per image averaged over 5000 COCO val2017 images using a GCP n1-standard-16 instance with one V100 GPU, and includes image preprocessing, PyTorch FP16 image inference at --batch-size 32 --img-size 640, postprocessing and NMS. Average NMS time included in this chart is 1-2ms/img. Reproduce by python test.py --data coco.yaml --img 640 --conf 0.1
** All checkpoints are trained to 300 epochs with default settings and hyperparameters (no autoaugmentation).
v1.0
3 years agoYOLOv5 1.0 Release Notes
- June 22, 2020: PANet updates: increased layers, reduced parameters, faster inference and improved mAP 364fcfd.
- June 19, 2020: FP16 as new default for smaller checkpoints and faster inference d4c6674.
- June 9, 2020: CSP updates: improved speed, size, and accuracy. Credit to @WongKinYiu for excellent CSP work.
- May 27, 2020: Public release of repo. YOLOv5 models are SOTA among all known YOLO implementations.
- April 1, 2020: Start development of future YOLOv3/YOLOv4-based PyTorch models in a range of compound-scaled sizes.
** GPU Speed measures end-to-end time per image averaged over 5000 COCO val2017 images using a V100 GPU with batch size 8, and includes image preprocessing, PyTorch FP16 inference, postprocessing and NMS.
Pretrained Checkpoints
| Model | APval | APtest | AP50 | SpeedGPU | FPSGPU | params | FLOPS | |
|---|---|---|---|---|---|---|---|---|
| YOLOv5s | 36.6 | 36.6 | 55.8 | 2.1ms | 476 | 7.5M | 13.2B | |
| YOLOv5m | 43.4 | 43.4 | 62.4 | 3.0ms | 333 | 21.8M | 39.4B | |
| YOLOv5l | 46.6 | 46.7 | 65.4 | 3.9ms | 256 | 47.8M | 88.1B | |
| YOLOv5x | 48.4 | 48.4 | 66.9 | 6.1ms | 164 | 89.0M | 166.4B | |
| YOLOv3-SPP | 45.6 | 45.5 | 65.2 | 4.5ms | 222 | 63.0M | 118.0B |
** APtest denotes COCO test-dev2017 server results, all other AP results in the table denote val2017 accuracy.
** All AP numbers are for single-model single-scale without ensemble or test-time augmentation. Reproduce by python test.py --img 736 --conf 0.001
** SpeedGPU measures end-to-end time per image averaged over 5000 COCO val2017 images using a GCP n1-standard-16 instance with one V100 GPU, and includes image preprocessing, PyTorch FP16 image inference at --batch-size 32 --img-size 640, postprocessing and NMS. Average NMS time included in this chart is 1-2ms/img. Reproduce by python test.py --img 640 --conf 0.1
** All checkpoints are trained to 300 epochs with default settings and hyperparameters (no autoaugmentation).