Yolov3 Versions Save
YOLOv3 in PyTorch > ONNX > CoreML > TFLite
v9.6.0
2 years agov9.5.0
3 years agov9.1
3 years agoThis release is a minor update implementing numerous bug fixes, feature additions and performance improvements from https://github.com/ultralytics/yolov5 to this repo. Models remain unchanged from v9.0 release.
Branch Notice
The ultralytics/yolov3 repository is now divided into two branches:
- Master branch: Forward-compatible with all YOLOv5 models and methods (recommended).
$ git clone https://github.com/ultralytics/yolov3 # master branch (default)
- Archive branch: Backwards-compatible with original darknet *.cfg models (⚠️ no longer maintained).
$ git clone -b archive https://github.com/ultralytics/yolov3 # archive branch
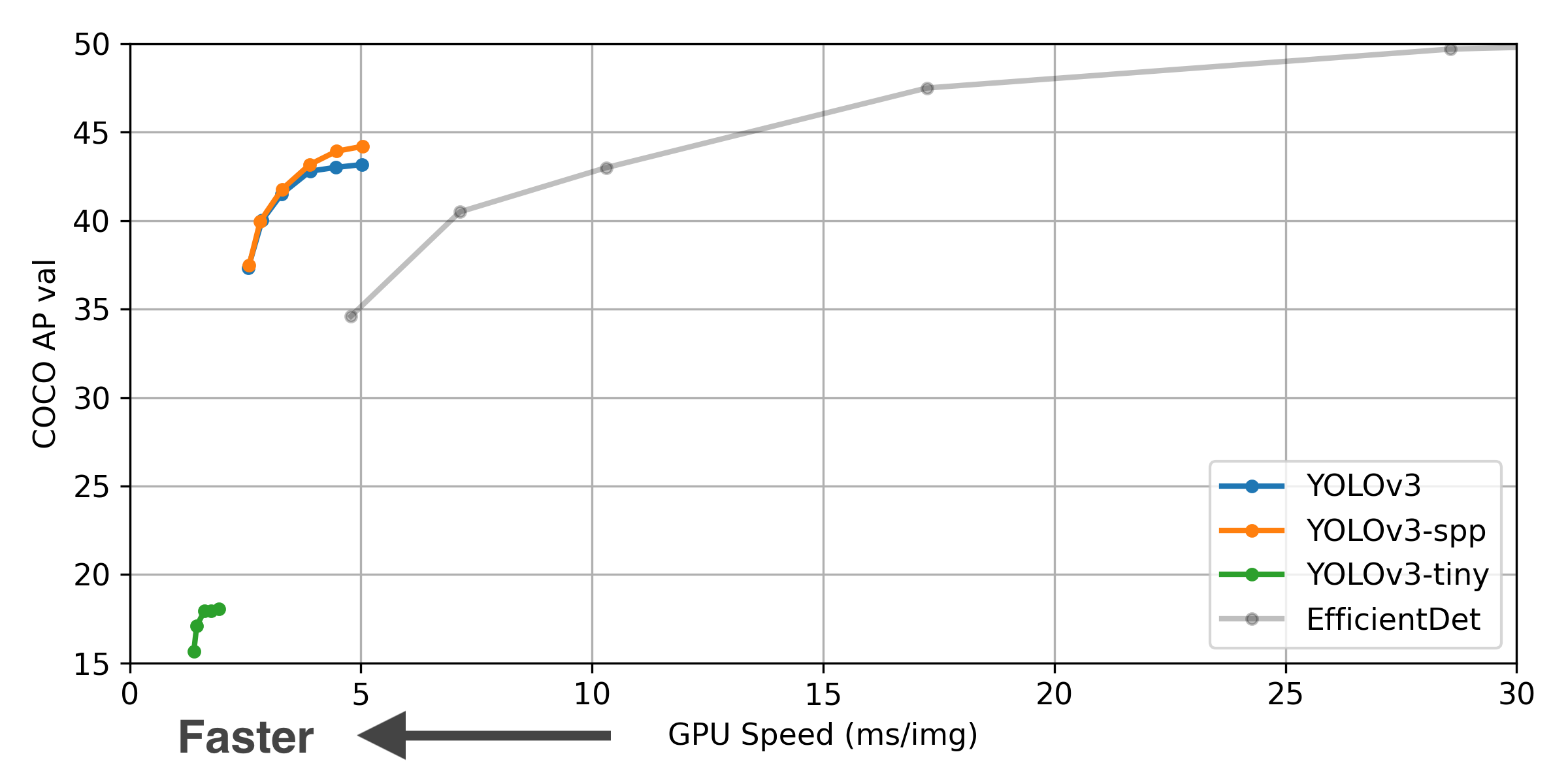
** GPU Speed measures end-to-end time per image averaged over 5000 COCO val2017 images using a V100 GPU with batch size 32, and includes image preprocessing, PyTorch FP16 inference, postprocessing and NMS. EfficientDet data from google/automl at batch size 8.
Pretrained Checkpoints
| Model | APval | APtest | AP50 | SpeedGPU | FPSGPU | params | FLOPS | |
|---|---|---|---|---|---|---|---|---|
| YOLOv3 | 43.3 | 43.3 | 63.0 | 4.8ms | 208 | 61.9M | 156.4B | |
| YOLOv3-SPP | 44.3 | 44.3 | 64.6 | 4.9ms | 204 | 63.0M | 157.0B | |
| YOLOv3-tiny | 17.6 | 34.9 | 34.9 | 1.7ms | 588 | 8.9M | 13.3B |
** APtest denotes COCO test-dev2017 server results, all other AP results denote val2017 accuracy.
** All AP numbers are for single-model single-scale without ensemble or TTA. Reproduce mAP by python test.py --data coco.yaml --img 640 --conf 0.001 --iou 0.65
** SpeedGPU averaged over 5000 COCO val2017 images using a GCP n1-standard-16 V100 instance, and includes image preprocessing, FP16 inference, postprocessing and NMS. NMS is 1-2ms/img. Reproduce speed by python test.py --data coco.yaml --img 640 --conf 0.25 --iou 0.45
** All checkpoints are trained to 300 epochs with default settings and hyperparameters (no autoaugmentation).
** Test Time Augmentation (TTA) runs at 3 image sizes. Reproduce TTA by python test.py --data coco.yaml --img 832 --iou 0.65 --augment
Requirements
Python 3.8 or later with all requirements.txt dependencies installed, including torch>=1.7. To install run:
$ pip install -r requirements.txt
v9.0
3 years agoThis release is a major update to the https://github.com/ultralytics/yolov3 repository that brings forward-compatibility with YOLOv5, and incorporates numerous bug fixes, feature additions and performance improvements from https://github.com/ultralytics/yolov5 to this repo.
Branch Notice
The ultralytics/yolov3 repository is now divided into two branches:
- Master branch: Forward-compatible with all YOLOv5 models and methods (recommended).
$ git clone https://github.com/ultralytics/yolov3 # master branch (default)
- Archive branch: Backwards-compatible with original darknet *.cfg models (⚠️ no longer maintained).
$ git clone -b archive https://github.com/ultralytics/yolov3 # archive branch
** GPU Speed measures end-to-end time per image averaged over 5000 COCO val2017 images using a V100 GPU with batch size 32, and includes image preprocessing, PyTorch FP16 inference, postprocessing and NMS. EfficientDet data from google/automl at batch size 8.
Pretrained Checkpoints
| Model | APval | APtest | AP50 | SpeedGPU | FPSGPU | params | FLOPS | |
|---|---|---|---|---|---|---|---|---|
| YOLOv3 | 43.3 | 43.3 | 63.0 | 4.8ms | 208 | 61.9M | 156.4B | |
| YOLOv3-SPP | 44.3 | 44.3 | 64.6 | 4.9ms | 204 | 63.0M | 157.0B | |
| YOLOv3-tiny | 17.6 | 34.9 | 34.9 | 1.7ms | 588 | 8.9M | 13.3B |
** APtest denotes COCO test-dev2017 server results, all other AP results denote val2017 accuracy.
** All AP numbers are for single-model single-scale without ensemble or TTA. Reproduce mAP by python test.py --data coco.yaml --img 640 --conf 0.001 --iou 0.65
** SpeedGPU averaged over 5000 COCO val2017 images using a GCP n1-standard-16 V100 instance, and includes image preprocessing, FP16 inference, postprocessing and NMS. NMS is 1-2ms/img. Reproduce speed by python test.py --data coco.yaml --img 640 --conf 0.25 --iou 0.45
** All checkpoints are trained to 300 epochs with default settings and hyperparameters (no autoaugmentation).
** Test Time Augmentation (TTA) runs at 3 image sizes. Reproduce TTA by python test.py --data coco.yaml --img 832 --iou 0.65 --augment
Requirements
Python 3.8 or later with all requirements.txt dependencies installed, including torch>=1.7. To install run:
$ pip install -r requirements.txt
v8
3 years agoThis is the final release of the darknet-compatible version of the https://github.com/ultralytics/yolov3 repository. This release is backwards-compatible with darknet *.cfg files for model configuration.
All pytorch (*.pt) and darknet (*.weights) models/backbones available are attached to this release in the Assets section below.
Breaking Changes
There are no breaking changes in this release.
Bug Fixes
- Various
Added Functionality
- Various
Speed
https://cloud.google.com/deep-learning-vm/
Machine type: preemptible n1-standard-8 (8 vCPUs, 30 GB memory)
CPU platform: Intel Skylake
GPUs: K80 ($0.14/hr), T4 ($0.11/hr), V100 ($0.74/hr) CUDA with Nvidia Apex FP16/32
HDD: 300 GB SSD
Dataset: COCO train 2014 (117,263 images)
Model: yolov3-spp.cfg
Command: python3 train.py --data coco2017.data --img 416 --batch 32
| GPU | n | --batch-size |
img/s | epoch time |
epoch cost |
|---|---|---|---|---|---|
| K80 | 1 | 32 x 2 | 11 | 175 min | $0.41 |
| T4 | 1 2 |
32 x 2 64 x 1 |
41 61 |
48 min 32 min |
$0.09 $0.11 |
| V100 | 1 2 |
32 x 2 64 x 1 |
122 178 |
16 min 11 min |
$0.21 $0.28 |
| 2080Ti | 1 2 |
32 x 2 64 x 1 |
81 140 |
24 min 14 min |
- - |
mAP
| Size | COCO mAP @0.5...0.95 |
COCO mAP @0.5 |
|
|---|---|---|---|
| YOLOv3-tiny YOLOv3 YOLOv3-SPP YOLOv3-SPP-ultralytics |
320 | 14.0 28.7 30.5 37.7 |
29.1 51.8 52.3 56.8 |
| YOLOv3-tiny YOLOv3 YOLOv3-SPP YOLOv3-SPP-ultralytics |
416 | 16.0 31.2 33.9 41.2 |
33.0 55.4 56.9 60.6 |
| YOLOv3-tiny YOLOv3 YOLOv3-SPP YOLOv3-SPP-ultralytics |
512 | 16.6 32.7 35.6 42.6 |
34.9 57.7 59.5 62.4 |
| YOLOv3-tiny YOLOv3 YOLOv3-SPP YOLOv3-SPP-ultralytics |
608 | 16.6 33.1 37.0 43.1 |
35.4 58.2 60.7 62.8 |
TODO
- NA
v7
3 years agoThis release requires PyTorch >= v1.4 to function properly. Please install the latest version from https://github.com/pytorch/pytorch/releases
Breaking Changes
There are no breaking changes in this release.
Bug Fixes
- Various
Added Functionality
- Improved training and test ground truth and prediction plotting. https://github.com/ultralytics/yolov3/pull/1114
- Increased augmentation speed. https://github.com/ultralytics/yolov3/pull/1110
- Improved Tensorboard integration.
- Auto class hyperparameter update based on dataset class count.
- Inference time augmentation option added now with
--augmentargument in test.py and detect.py. - Rectangular training with
--rectargument in train.py
Speed
https://cloud.google.com/deep-learning-vm/
Machine type: preemptible n1-standard-8 (8 vCPUs, 30 GB memory)
CPU platform: Intel Skylake
GPUs: K80 ($0.14/hr), T4 ($0.11/hr), V100 ($0.74/hr) CUDA with Nvidia Apex FP16/32
HDD: 300 GB SSD
Dataset: COCO train 2014 (117,263 images)
Model: yolov3-spp.cfg
Command: python3 train.py --data coco2017.data --img 416 --batch 32
| GPU | n | --batch-size |
img/s | epoch time |
epoch cost |
|---|---|---|---|---|---|
| K80 | 1 | 32 x 2 | 11 | 175 min | $0.41 |
| T4 | 1 2 |
32 x 2 64 x 1 |
41 61 |
48 min 32 min |
$0.09 $0.11 |
| V100 | 1 2 |
32 x 2 64 x 1 |
122 178 |
16 min 11 min |
$0.21 $0.28 |
| 2080Ti | 1 2 |
32 x 2 64 x 1 |
81 140 |
24 min 14 min |
- - |
mAP
| Size | COCO mAP @0.5...0.95 |
COCO mAP @0.5 |
|
|---|---|---|---|
| YOLOv3-tiny YOLOv3 YOLOv3-SPP YOLOv3-SPP-ultralytics |
320 | 14.0 28.7 30.5 37.7 |
29.1 51.8 52.3 56.8 |
| YOLOv3-tiny YOLOv3 YOLOv3-SPP YOLOv3-SPP-ultralytics |
416 | 16.0 31.2 33.9 41.2 |
33.0 55.4 56.9 60.6 |
| YOLOv3-tiny YOLOv3 YOLOv3-SPP YOLOv3-SPP-ultralytics |
512 | 16.6 32.7 35.6 42.6 |
34.9 57.7 59.5 62.4 |
| YOLOv3-tiny YOLOv3 YOLOv3-SPP YOLOv3-SPP-ultralytics |
608 | 16.6 33.1 37.0 43.1 |
35.4 58.2 60.7 62.8 |
TODO (help and PR's welcome!)
- Add iOS App inference to photos and videos in Camera Roll, as well as 'Flexible', or at least rectangular inference. https://github.com/ultralytics/yolov3/issues/224
v6
5 years agoThis release requires PyTorch >= v1.0.0 to function properly. Please install the latest version from https://github.com/pytorch/pytorch/releases
Breaking Changes
There are no breaking changes in this release.
Bug Fixes
- NMS now screens out nan and inf values which caused it to hang during some edge cases.
Added Functionality
- Rectangular Inference. detect.py now automatically processes images, videos and webcam feeds using rectangular inference, letterboxing to the minimum viable 32-multiple. This speeds up inference by up to 40% on HD video: https://github.com/ultralytics/yolov3/issues/232
- Conv2d + Batchnorm2d Layer Fusion: detect.py now automatically fuses the Conv2d and Batchnorm2d layers in the model before running inference. This speeds up inference by about 5-10%. https://github.com/ultralytics/yolov3/issues/224
- Hyperparameters all parameterized and grouped togethor in train.py now. Genetic Hyperparameter Evolution code added to train.py.
Performance
https://cloud.google.com/deep-learning-vm/
Machine type: n1-standard-8 (8 vCPUs, 30 GB memory)
CPU platform: Intel Skylake
GPUs: K80 ($0.198/hr), P4 ($0.279/hr), T4 ($0.353/hr), P100 ($0.493/hr), V100 ($0.803/hr)
HDD: 100 GB SSD
Dataset: COCO train 2014
| GPUs | batch_size |
batch time | epoch time | epoch cost |
|---|---|---|---|---|
| (images) | (s/batch) | |||
| 1 K80 | 16 | 1.43s | 175min | $0.58 |
| 1 P4 | 8 | 0.51s | 125min | $0.58 |
| 1 T4 | 16 | 0.78s | 94min | $0.55 |
| 1 P100 | 16 | 0.39s | 48min | $0.39 |
| 2 P100 | 32 | 0.48s | 29min | $0.47 |
| 4 P100 | 64 | 0.65s | 20min | $0.65 |
| 1 V100 | 16 | 0.25s | 31min | $0.41 |
| 2 V100 | 32 | 0.29s | 18min | $0.48 |
| 4 V100 | 64 | 0.41s | 13min | $0.70 |
| 8 V100 | 128 | 0.49s | 7min | $0.80 |
TODO (help and PR's welcome!)
- Add iOS App inference to photos and videos in Camera Roll, as well as 'Flexible', or at least rectangular inference. https://github.com/ultralytics/yolov3/issues/224
- Add parameter to switch between 'darknet' and 'power' wh methods. https://github.com/ultralytics/yolov3/issues/168
- YAPF linting (including possible wrap to PEP8 79 character-line standard) https://github.com/ultralytics/yolov3/issues/88.
- Resolve mAP bug: https://github.com/ultralytics/yolov3/issues/222
- Rectangular training. https://github.com/ultralytics/yolov3/issues/232
- Genetic Hyperparameter Evolution. HELP NEEDED HERE. If you have available hardware please contact us, as we need help expanding our hyperparameter search, for the benefit of everyone!
v5
5 years agoThis release requires PyTorch >= v1.0.0 to function properly. Please install the latest version from https://github.com/pytorch/pytorch/releases
Breaking Changes
There are no breaking changes in this release.
Bug Fixes
- None
Added Functionality
- Video Inference. detect.py now automatically processes both images and videos. Image and video results are saved in their respective formats now (video inference saves new videos).
- Transfer learning now operates automatically regardless of yolo layer size https://github.com/ultralytics/yolov3/issues/152.
Performance
https://cloud.google.com/deep-learning-vm/
Machine type: n1-standard-8 (8 vCPUs, 30 GB memory)
CPU platform: Intel Skylake
GPUs: K80 ($0.198/hr), P4 ($0.279/hr), T4 ($0.353/hr), P100 ($0.493/hr), V100 ($0.803/hr)
HDD: 100 GB SSD
Dataset: COCO train 2014
| GPUs | batch_size |
batch time | epoch time | epoch cost |
|---|---|---|---|---|
| (images) | (s/batch) | |||
| 1 K80 | 16 | 1.43s | 175min | $0.58 |
| 1 P4 | 8 | 0.51s | 125min | $0.58 |
| 1 T4 | 16 | 0.78s | 94min | $0.55 |
| 1 P100 | 16 | 0.39s | 48min | $0.39 |
| 2 P100 | 32 | 0.48s | 29min | $0.47 |
| 4 P100 | 64 | 0.65s | 20min | $0.65 |
| 1 V100 | 16 | 0.25s | 31min | $0.41 |
| 2 V100 | 32 | 0.29s | 18min | $0.48 |
| 4 V100 | 64 | 0.41s | 13min | $0.70 |
| 8 V100 | 128 | 0.49s | 7min | $0.80 |
TODO (help and PR's welcome!)
- Add iOS App inference to photos and videos in Camera Roll.
- Add parameter to switch between 'darknet' and 'power' wh methods. https://github.com/ultralytics/yolov3/issues/168
- YAPF linting (including possible wrap to PEP8 79 character-line standard) https://github.com/ultralytics/yolov3/issues/88.
- Hyperparameter search for loss function constants.
v4
5 years agoThis release requires PyTorch >= v1.0.0 to function properly. Please install the latest version from https://github.com/pytorch/pytorch/releases
Breaking Changes
There are no breaking changes in this release.
Bug Fixes
- Multi GPU support is now working correctly https://github.com/ultralytics/yolov3/issues/21.
-
test.pynow natively outputs the same results as pycocotools to within 1% under most circumstances https://github.com/ultralytics/yolov3/issues/2
Added Functionality
- Dataloader is now multithread. https://github.com/ultralytics/yolov3/issues/141
- mAP improved by smarter NMS. mAP now exceeds darknet mAP by a small amount in all image sizes 320-608.
ultralytics/yolov3 with pycocotools |
darknet/yolov3 | |
|---|---|---|
| YOLOv3-320 | 51.8 | 51.5 |
| YOLOv3-416 | 55.4 | 55.3 |
| YOLOv3-608 | 58.2 | 57.9 |
sudo rm -rf yolov3 && git clone https://github.com/ultralytics/yolov3
# bash yolov3/data/get_coco_dataset.sh
sudo rm -rf cocoapi && git clone https://github.com/cocodataset/cocoapi && cd cocoapi/PythonAPI && make && cd ../.. && cp -r cocoapi/PythonAPI/pycocotools yolov3
cd yolov3
python3 test.py --save-json --conf-thres 0.001 --img-size 416
Namespace(batch_size=32, cfg='cfg/yolov3.cfg', conf_thres=0.001, data_cfg='cfg/coco.data', img_size=416, iou_thres=0.5, nms_thres=0.5, save_json=True, weights='weights/yolov3.weights')
Using cuda _CudaDeviceProperties(name='Tesla V100-SXM2-16GB', major=7, minor=0, total_memory=16130MB, multi_processor_count=80)
Image Total P R mAP
Calculating mAP: 100%|█████████████████████████████████| 157/157 [08:34<00:00, 2.53s/it]
5000 5000 0.0896 0.756 0.555
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.312
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.554
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.317
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.145
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.343
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.452
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.268
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.411
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.435
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.244
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.477
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.587
python3 test.py --save-json --conf-thres 0.001 --img-size 608 --batch-size 16
Namespace(batch_size=16, cfg='cfg/yolov3.cfg', conf_thres=0.001, data_cfg='cfg/coco.data', img_size=608, iou_thres=0.5, nms_thres=0.5, save_json=True, weights='weights/yolov3.weights')
Using cuda _CudaDeviceProperties(name='Tesla V100-SXM2-16GB', major=7, minor=0, total_memory=16130MB, multi_processor_count=80)
Image Total P R mAP
Calculating mAP: 100%|█████████████████████████████████| 313/313 [08:54<00:00, 1.55s/it]
5000 5000 0.0966 0.786 0.579
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.331
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.582
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.344
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.198
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.362
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.427
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.281
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.437
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.463
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.309
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.494
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.577
Performance
- mAP computation is much slower now than before using default settings, as
--conf-thres 0.001captures many boxes that all must be passed through NMS. On a V100 test.py runs in about 8 minutes - Training speed is improved substantially compared to v3.0 due to the addition of the multithreaded PyTorch dataloader.
https://cloud.google.com/deep-learning-vm/
Machine type: n1-standard-8 (8 vCPUs, 30 GB memory)
CPU platform: Intel Skylake
GPUs: K80 ($0.198/hr), P4 ($0.279/hr), T4 ($0.353/hr), P100 ($0.493/hr), V100 ($0.803/hr)
HDD: 100 GB SSD
Dataset: COCO train 2014
| GPUs | batch_size |
batch time | epoch time | epoch cost |
|---|---|---|---|---|
| (images) | (s/batch) | |||
| 1 K80 | 16 | 1.43s | 175min | $0.58 |
| 1 P4 | 8 | 0.51s | 125min | $0.58 |
| 1 T4 | 16 | 0.78s | 94min | $0.55 |
| 1 P100 | 16 | 0.39s | 48min | $0.39 |
| 2 P100 | 32 | 0.48s | 29min | $0.47 |
| 4 P100 | 64 | 0.65s | 20min | $0.65 |
| 1 V100 | 16 | 0.25s | 31min | $0.41 |
| 2 V100 | 32 | 0.29s | 18min | $0.48 |
| 4 V100 | 64 | 0.41s | 13min | $0.70 |
| 8 V100 | 128 | 0.49s | 7min | $0.80 |
TODO (help and PR's welcome!)
- Video Inference. Pass a video file to detect.py.
- YAPF linting (including possible wrap to PEP8 79 character-line standard) https://github.com/ultralytics/yolov3/issues/88.
- Add iOS App inference to photos and videos in Camera Roll.
- Add parameter to switch between 'darknet' and 'power' wh methods. https://github.com/ultralytics/yolov3/issues/168
- Hyperparameter search for loss function constants.
v3.0
5 years agoThis release requires PyTorch >= v1.0.0 to function properly. Please install the latest version from https://github.com/pytorch/pytorch/releases
Breaking Changes
There are no breaking changes in this release.
Bug Fixes
- Multi GPU support https://github.com/ultralytics/yolov3/issues/21.
Added Functionality
- Tutorial created: https://github.com/ultralytics/yolov3/wiki/Example:-Transfer-Learning
- Tutorial created: https://github.com/ultralytics/yolov3/wiki/Example:-Train-Single-Image
- Tutorial created: https://github.com/ultralytics/yolov3/wiki/Example:-Train-Single-Class
- Tutorial created: https://github.com/ultralytics/yolov3/wiki/Train-Custom-Data
-
test.pyoptionally outputs pycocotools compatible json files now with the--save-jsonflag, and computes official COCO mAP using pycocotools. Output is verified against official darknet results from https://arxiv.org/abs/1804.02767. https://github.com/ultralytics/yolov3/issues/2#issuecomment-434751531.
| ultralytics/yolov3 mAP | darknet mAP | |
|---|---|---|
| YOLOv3-320 | 51.3 | 51.5 |
| YOLOv3-416 | 54.9 | 55.3 |
| YOLOv3-608 | 57.9 | 57.9 |
Performance
- 10% improvement in training speed via code optimization. Performance should be further improved by multithreading the dataloader (on the TODO list).
https://cloud.google.com/deep-learning-vm/
Machine type: n1-highmem-4 (4 vCPUs, 26 GB memory)
CPU platform: Intel Skylake
GPUs: 1-4 x NVIDIA Tesla P100
HDD: 100 GB SSD
| GPUs | batch_size |
speed | COCO epoch |
|---|---|---|---|
| (P100) | (images) | (s/batch) | (min/epoch) |
| 1 | 16 | 0.54s | 66min |
| 2 | 32 | 0.99s | 61min |
| 4 | 64 | 1.61s | 49min |
TODO (help and PR's welcome!)
- Dataloader should enable multithread. Single thread loading takes about 230 ms per batch currently, out of total batch time of 550 ms (40%). Low GPU utilization reported. https://github.com/ultralytics/yolov3/issues/141
- test.py should natively output the same results as pycocotools https://github.com/ultralytics/yolov3/issues/2
- Video Inference. Pass a video file to detect.py.
- YAPF linting (including possible wrap to PEP8 79 character-line standard) https://github.com/ultralytics/yolov3/issues/88.
- Add iOS App inference to photos and videos in Camera Roll.
- Add parameter to switch between 'darknet' and 'power' wh methods.