World Population Cartogram Save
This repository contains a set of data able to reproduce Max Roser's beautiful masterpiece for "Our World in Data" -- The World Population Cartogram.
🗺️ World Population Cartogram
This repository contains a set of data able to reproduce Max Roser's beautiful masterpiece for "Our World in Data" -- The World Population Cartogram.
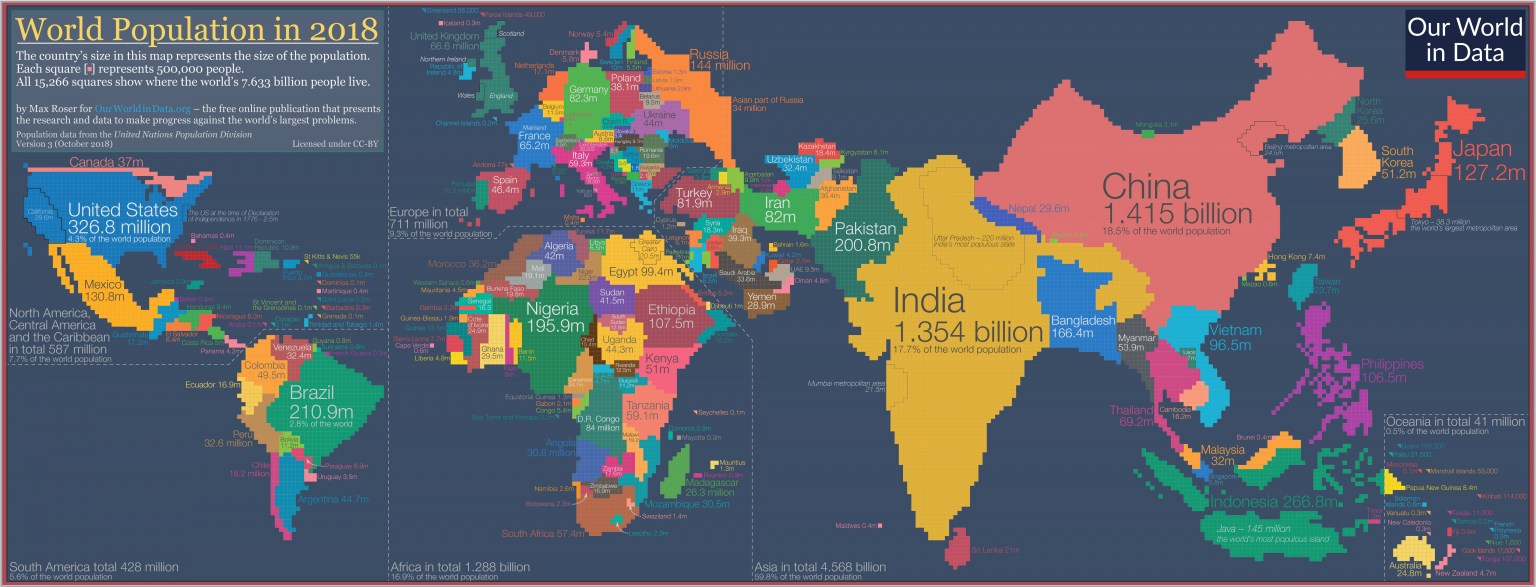
Table of Contents
🙌 Motivation
From Wikipedia:
A cartogram is a map in which some thematic mapping variable – such as travel time, population, or GNP – is substituted for land area or distance
Good cartograms are notoriously difficult to make, as they require a careful balance of distorting distance, area, & shape -- enough to match the target variable, but not too much causing the countries to become unrecognizable. For this reason, cartograms that are generated purely algorithmically are generally of low quality. Hence my motivation for this repo. Max Roser's map is fantastic and should be available for anyone and everyone to easily build upon. In fact, it's so good, it's the first image in the wikipedia entry for "cartogram".
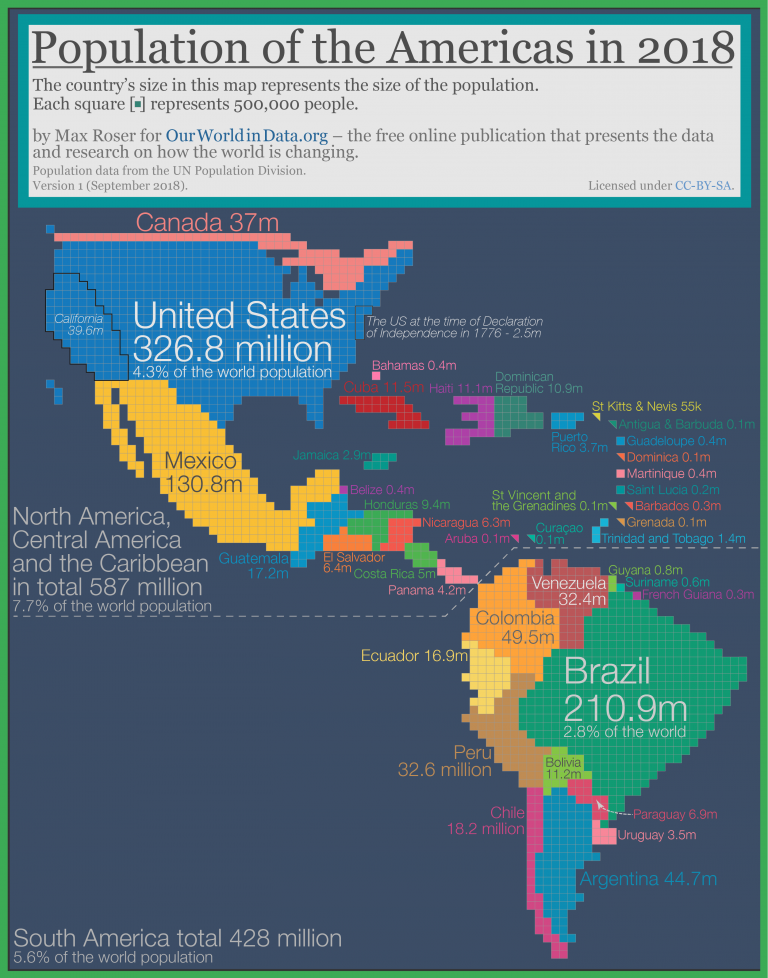
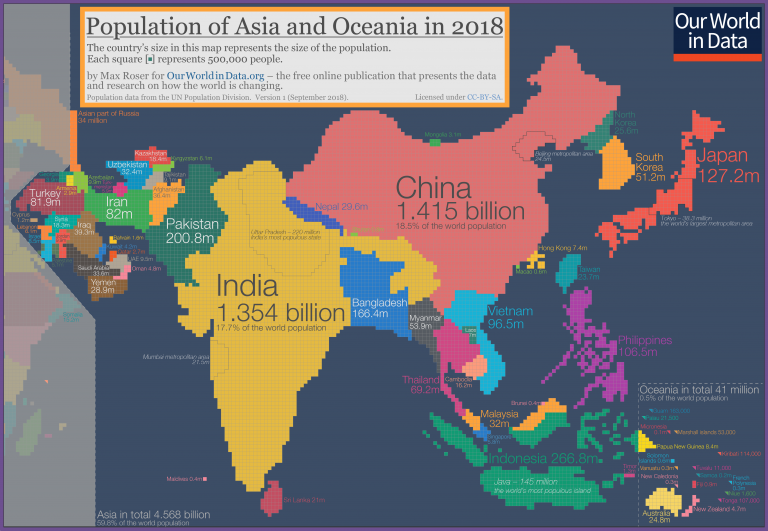
Here's a small gallery of graphics I made using this cartogram layout:

👩💻 Using The Data (Example Code)
R
library(ggplot2)
cellsDF <- read.csv('https://raw.githubusercontent.com/mattdzugan/World-Population-Cartogram/master/data/year_2018__cell_500k/squares_and_triangles/cells.csv')
bordersDF <- read.csv('https://raw.githubusercontent.com/mattdzugan/World-Population-Cartogram/master/data/year_2018__cell_500k/squares_and_triangles/borders.csv')
ggplot()+
theme_void()+
theme(legend.position = 'none')+
geom_tile(data=cellsDF, aes(x=X+.5, y=Y+.5, fill=as.factor(CountryCode)), color=NA)+
geom_path(data=bordersDF, aes(x=X, y=Y, group=PolygonID))+
coord_fixed()
Python
import numpy as np
import pandas as pd
from matplotlib.collections import PatchCollection
import matplotlib
import matplotlib.pyplot as plt
borders = pd.read_csv("https://raw.githubusercontent.com/mattdzugan/World-Population-Cartogram/master/data/year_2018__cell_500k/squares_and_triangles/borders.csv")
cells = pd.read_csv("https://raw.githubusercontent.com/mattdzugan/World-Population-Cartogram/master/data/year_2018__cell_500k/squares_and_triangles/cells.csv")
fig = plt.figure()
ax = fig.add_subplot(111, aspect='equal')
plt.xlim([0, max(cells["X"]+1)])
plt.ylim([0, max(cells["Y"]+1)])
n=cells.shape[0]
patches = []
for i in range(0,n):
patches.append(matplotlib.patches.Rectangle((cells.loc[i,"X"]+.5, cells.loc[i,"Y"]+.5),1,1))
ax.add_collection(PatchCollection(patches, color="#111111", alpha=0.1))
for p in np.unique(borders["PolygonID"]):
ax.plot(borders.loc[borders["PolygonID"]==p, "X"], borders.loc[borders["PolygonID"]==p, "Y"])
plt.show()
D3.js
world_pop_cartogram = d3.json(
"https://raw.githubusercontent.com/mattdzugan/World-Population-Cartogram/topojson/data/year_2018__cell_500k/squares/topo.json"
)
const svg = d3.create("svg").attr("viewBox", [0, 0, 1000, 500]);
const g = svg.append("g");
const path = d3.geoPath();
const color = d3.scaleOrdinal([
'#66C5CC', '#F6CF71', '#F89C74', '#DCB0F2', '#87C55F', '#9EB9F3', '#FE88B1', '#C9DB74', '#8BE0A4', '#B497E7', '#D3B484'
]);
const mycountries = topojson.feature(
world_pop_cartogram,
world_pop_cartogram.objects.countries
).features;
g.append("g")
.selectAll("path")
.data(mycountries)
.join("path")
.attr("stroke", "#555")
.attr("stroke-width", 1.3333)
.attr("fill", (d, i) => color(i))
.attr("d", path);
🔢 About the Data Artifacts and their Formats
The Square Grid
The cartogram is composed ~15,000 square* cells within a grid. Each cell represents a population of 500,000 (0.5M) people who reside in its corresponding country. This means that the only information necessary to represent the World Population Cartogram is a list of tuples: {X, Y, Country} describing which cells map to which countries. To avoid dealing with spelling mismatches and other localization glitches, this repo uses ISO 3166-1 country codes to identify countries.
cells.csv
For example, the following 11 rows represent the 4.7M people (9 cells) of New Zealand (ISO: 554) and the 0.9M people (2 cells) of Fiji (ISO: 242)
X, Y, CountryCode
337, 0, 554
338, 1, 554
338, 0, 554
339, 2, 554
339, 1, 554
340, 5, 554
340, 4, 554
340, 3, 554
341, 4, 554
340, 9, 242
340, 8, 242
...
borders.csv
For convenience, the aggregate polygons are also computed (using computeBoundaries.py) & written to a CSV file which looks like this:
X, Y, PolygonID, CountryCode, BorderType
...
163, 63, 295, 262, Exterior
163, 64, 295, 262, Exterior
164, 64, 295, 262, Exterior
164, 63, 295, 262, Exterior
166, 25, 296, 480, Exterior
166, 24, 296, 480, Exterior
165, 24, 296, 480, Exterior
...
Needing to describe a BorderType as either Exterior or Interior may come as a surprise to you. If so, please checkout South Africa & Lesotho. South Africa, therefore has two PolygonID associated with it. One Exterior border, and one Interior border.
It should be noted that the borders are not cells themselves. They do not "take up space". They are merely just zero-width representations of the perimeters of each country.
Cells & Borders Playing Together
cells.csv can be thought of as descriptions of the pixels that make up the cartogram. borders.csv describe the perimeters that lie around groups of pixels.
Using them together introduces one slight complication:
Each cell is technically a region itself, a 1x1 rectangle. The cells.csv however only represents it as a single {X,Y} point. The convention here is that a cell's {X,Y} coordinate is specifically referring to its lower-left (south-west) corner. For example, a single-cell Country at {X=100, Y=200} would have a border of [{X=100, Y=200}, {X=101, Y=200}, {X=101, Y=201}, {X=100, Y=201}]
countries.svg
countries.svg is a pre-computed vector file the cartogram. Styling is minimal so as not to presuppose any design decisions.

geo.json & topo.json
geo.json is JSON file that obeys the geojson specification for describing geographic data. It's essentially an array of Features where each Feature maps to a Country. Note that the properties.id describes the same ISO 3166-1 country code used in the other files.
{
"type": "FeatureCollection",
"features": [{
"type": "Feature",
"geometry": {
"type": "MultiPolygon",
"coordinates": [
[
[
[0.163, 0.084],
[0.163, 0.085], // ... <TRUNCATED FOR README>
[0.163, 0.084]
]
],
[
[
[0.153, 0.092],
[0.153, 0.091], // ... <TRUNCATED FOR README>
[0.153, 0.092]
]
]
]
},
"properties": {
"id": "792"
}
}, {
"type": "Feature",
"geometry": {
"type": "Polygon",
"coordinates": [
[
[0.157, 0.082],
[0.156, 0.082], // ... <TRUNCATED FOR README>
[0.157, 0.082]
]
]
},
"properties": {
"id": "196"
}
}, {
topo.json is a relative of the geo.json file which has several advantages like simplified polygons, reused borders, and an inferred topology. This file type is popular in the D3.js community, you can see it in action in this notebook.
Triangles...?
Because of the fact that there are a handful of (mostly island) nations with a population less than the 500,000 cell-size, these countries being represented by a full square cell can be a little misleading. Max Roser's Cartogram addresses this by carving out a special type of cell just for this, a half-filled cell in the shape of a triangle. Just look in the Carribean or the South-Pacific for a few examples of these triangles.
In my view, while the triangles are cute, I personally prefer the aesthetic that you get from all-squares.
Plus, the triangles don't really help all that much in making the area directly proportional to population.

Because it really just comes down to personal preference, two versions of the data are made available. One in data/*/squares/ and the other in data/*/squares_and_triangles/. That way, you can choose whichever you prefer!
The borders.csv file, the countries.svg file and any of the *.json files behave the same way in the data/*/squares_and_triangles/ directory as they do in the data/*/squares/ directory, explained above. There is a slight difference when handling cells.csv however...
Because a single square-cell can now contain two triangles, we need a way to identify that. Thus, boolean columns: LowerLeft and UpperRight are introduced.
X, Y, CountryCode, LowerLeft, UpperRight, IncludeInSquares
165, 24, 480, 1, 1, 1
166, 25, 480, 1, 1, 1
127, 36, 678, 0, 1, 1
133, 102, 380, 1, 0, 0
...
- a row where both
LowerLeft==1&UpperRight==1is a square - a row where only 1 of
LowerLeft==1orUpperRight==1is a triangle - a row where
IncludeInSquares==0is not included as a square in/squares/cells.csvfile- this is very rare, the only instances are the portions of
Italythat are replaced by squares forVatican CityandSan Marino
- this is very rare, the only instances are the portions of
Certainly these artifacts housed in the data/ folder are the main feature of this repository. There is however a small set of code in src/ that assists in creating some of these data artifacts, more details can be found in the CONTRIBUTING file.
⁉️ FAQ
Where is the code that processed the original Image to create this dataset?
Well... it doesn't exist. The dataset was created by manually examining & transcribing the image. I originally set out to automate most of this process, specifically, algorithmically determining the regional boundaries of each country (using the color of the source image) and mapping those to the lower-resolution grid. However once I noticed that the original image had some quirks (inconsistent size of grid-cells, inconsistent size of gridlines) - I determined it'd take me longer to write the code to handle all the corner-cases than it would take for me to just manually transcribe the map. Plus, there's no feasible way to automate the labeling (once the polygons are defined) of which polygon maps to which country, so that piece would always be manual.
How can make a version of this for a different year?
This is unfortunately not easy. Imagine for a moment we wanted a similar version of this map for the year 2000. There are a many countries where population has increased by more than 500,000 people from 2000 to 2018, this means that the 2000 map would need less cells. So which cells should we delete? It's not obvious that there's a sensible way to do this. Then once we delete a cell, we'll need to push the adjacent countries over to fill the new gap -- but how do we do that while maintaining the shape of the countries? It quickly becomes a logistical nightmare that would be difficult to solve (well) algorithmically.
If you come up with something you like, please create a Pull Request & I will consider adding it to this repo. More details are available in the CONTRIBUTING.md file.
How can make a version of this for a different cell-size (other than 500,000 persons/cell)?
This is maybe a little more straightforward than the above, but still challenging.
I suspect a simple resampling of the image would get 90% of the way there. Using something like scipy.ndimage.zoom with mode='nearest' will increase the change the resolution of the grid. Then some manual attention would likely be needed to handle the nuances of country boundaries.
If you come up with something you like, please create a Pull Request & I will consider adding it to this repo.
Where's Russia?
It's over there. To the left. Further... keep going... further. Yep, there it is.
Do the coordinates refer to Latitude & Longitude?
No! Despite the fact that the values may appear to be in the same range as Latiude and Longitude, this is purely a coincidence. The exact values of the coordinate-system are completely arbitrary. For this reason, I'd suggest always removing axis labels, tick marks, and any gridlines/graticule from visualization of this data.
This thing looks so weird, why would I ever use it?
Humans subconsiously find 'bigger things' more memorable and striking. So when seeing a graphic like this one of Countries by System of Government
 ... it is only natural to overlook the shade of orange representing
... it is only natural to overlook the shade of orange representing Parliamentary republic with a ceremonial presidency. There just simply aren't many orange pixels on this map.
A map like the World Population Cartogram which provides visual weight proportional to population, would solve this problem.
This thing is cool, why would I ever NOT use it?
Not everything makes sense when tied to population.
For example a map showing each country's year of founding or length of its wikipedia article may not benefit from a population-weighted view.
📒 Citations
Max Roser (2018) – "The map we need if we want to think about how global living conditions are changing". Published online at OurWorldInData.org. Retrieved from: ‘https://ourworldindata.org/world-population-cartogram’ [Online Resource]
Max's relevant citations:
This data I took from the UN Population Division and you can access that data and visualize it for other countries on our map here. https://ourworldindata.org/grapher/UN-population-projection-medium-variant?year=2018 The 2018 data is a future projection that the UN Population Division created last year. Other data – the US in 1776, the population of various metropolitan areas, and the population of some small countries – are mostly from Wikipedia.
License
Our World In Data copyrights their work under a CC-BY license, so be sure to provide attribution when using this Cartogram.
Any code ('.py', '.R') found in this repository, is available for use without restriction (MIT)

{kind=link}
{kind=link}
{kind=link}