Taier Versions Save
Taier is a big data development platform for submission, scheduling, operation and maintenance, and indicator information display
v1.4.0
1 year agoWhat's Changed
- [feat_1.3_issue#724][taier-data-develop] standalone bugfix by @ghm02708 in https://github.com/DTStack/Taier/pull/799
- [Improve][CI] Fix ci/cd by @FlechazoW in https://github.com/DTStack/Taier/pull/793
- [refactor/queue][taier-ui]move queueConfig from rightbar to create config by @mortalYoung in https://github.com/DTStack/Taier/pull/795
- [feat/website][website]develop website homepage by @mortalYoung in https://github.com/DTStack/Taier/pull/800
- [1.3_beta][taier-all] fix flink standalone component config by @vainhope in https://github.com/DTStack/Taier/pull/802
- [1.3_beta][taier-all] fix dirty table by @vainhope in https://github.com/DTStack/Taier/pull/804
- [fix/workflow][taier-ui]fix lost line in workflow by @mortalYoung in https://github.com/DTStack/Taier/pull/791
- [fix/flink][taier-ui]fix flink tab saving by @mortalYoung in https://github.com/DTStack/Taier/pull/803
- [fix/clickhouse][taier-ui]clickhouse and doris as task support syntax highlight by @mortalYoung in https://github.com/DTStack/Taier/pull/805
- [feat/sparkjar][taier-ui]support sparkjar task by @mortalYoung in https://github.com/DTStack/Taier/pull/806
- [fix/usePagination][taier-ui]fix pagination get incorrect by @mortalYoung in https://github.com/DTStack/Taier/pull/809
- [fix/validator][taier-ui]fix validator folder failed in resource by @mortalYoung in https://github.com/DTStack/Taier/pull/796
- [fix/default][taier-ui]remove default actions and barItems by @mortalYoung in https://github.com/DTStack/Taier/pull/807
- [fix/folderPicker][taier-ui]fix folderPicker with workflow by @mortalYoung in https://github.com/DTStack/Taier/pull/797
- [fix/workflow][taier-ui]fix workflow repeated name in validating by @mortalYoung in https://github.com/DTStack/Taier/pull/808
- feat: improve popup in create by @mortalYoung in https://github.com/DTStack/Taier/pull/810
- [test/services][taier-ui]improve test coverage by @mortalYoung in https://github.com/DTStack/Taier/pull/811
- [fix/splitKey][taier-ui]support to get splitKey in array by @mortalYoung in https://github.com/DTStack/Taier/pull/812
- [feat/taskInfo][taier-ui]support to show dataSource in task info tab by @mortalYoung in https://github.com/DTStack/Taier/pull/816
- [1.3_beta][taier-all] fix sql by @vainhope in https://github.com/DTStack/Taier/pull/818
- [fix/schema][taier-ui]remove Schema in contextMenu by @mortalYoung in https://github.com/DTStack/Taier/pull/819
- [fix/scheduleConf][taier-ui]fix selfReliance won't change by @mortalYoung in https://github.com/DTStack/Taier/pull/814
- [fix/cluster][taier-ui]improve cluster save by @mortalYoung in https://github.com/DTStack/Taier/pull/820
- [fix/flinkSource][taier-ui]fix flinkSource alias by @mortalYoung in https://github.com/DTStack/Taier/pull/817
- [refactor/preview][taier-ui]improve preview table by @mortalYoung in https://github.com/DTStack/Taier/pull/822
- 1.3 beta by @vainhope in https://github.com/DTStack/Taier/pull/823
- [issue#798][taier-data-develop] flink udf 回显不正确 by @ghm02708 in https://github.com/DTStack/Taier/pull/824
- [issue#826][taier-data-develop] replace task_template,init sql revisal by @ghm02708 in https://github.com/DTStack/Taier/pull/827
- [fix/componentVersion][taier-ui]improve componentVersion label by @mortalYoung in https://github.com/DTStack/Taier/pull/825
- [fix][taier-data-develop] remove common DataSourceType by @ghm02708 in https://github.com/DTStack/Taier/pull/828
- Bump molecule from 1.1.0 to 1.2.0 by @mortalYoung in https://github.com/DTStack/Taier/pull/831
- [refactor/completion][taier-ui]improve completion for editor by @mortalYoung in https://github.com/DTStack/Taier/pull/830
- 1.3 beta by @vainhope in https://github.com/DTStack/Taier/pull/832
- [fix/cluster][taier-ui]support more impressive error log by @mortalYoung in https://github.com/DTStack/Taier/pull/833
- [fix/execute][taier-ui]fix log output panel after executing by @mortalYoung in https://github.com/DTStack/Taier/pull/834
- [Improve][Common] Upgrade 'flink.version' to 1.12.7 by @FlechazoW in https://github.com/DTStack/Taier/pull/836
- [fix][taier-data-develop] com.dtstack.chunjun.util.FactoryHelper should be loaded by DtClassloader by @ghm02708 in https://github.com/DTStack/Taier/pull/837
- [fix][taier-data-develop] standalone log fix by @ghm02708 in https://github.com/DTStack/Taier/pull/838
- 1.3 beta by @vainhope in https://github.com/DTStack/Taier/pull/839
- [fix/stream][taier-ui]remove component version filters in stream by @mortalYoung in https://github.com/DTStack/Taier/pull/840
- [fix/flink][taier-ui]fix validation on flinksql by @mortalYoung in https://github.com/DTStack/Taier/pull/835
- [1.3_beta][迁移 listFile 方法到 datasource 中] by @poxiao8 in https://github.com/DTStack/Taier/pull/841
- [doc] [web-site] add task sql doc by @vainhope in https://github.com/DTStack/Taier/pull/853
- [Fix][sql] change sync datasource query interface by @vainhope in https://github.com/DTStack/Taier/pull/856
- [fix/dataSource][taier-ui]fix dataSource query failed by @mortalYoung in https://github.com/DTStack/Taier/pull/860
- [fea_doc][doc] add online web url by @vainhope in https://github.com/DTStack/Taier/pull/855
- build: reset ui build by @bnyte in https://github.com/DTStack/Taier/pull/854
- [hotfix][Taier-develop] 向导模式flinksql version 转化问题 by @ghm02708 in https://github.com/DTStack/Taier/pull/867
- [feat/website][taier-ui]replace case image by @mortalYoung in https://github.com/DTStack/Taier/pull/870
- [doc/readme][taier]translate README into English by @mortalYoung in https://github.com/DTStack/Taier/pull/873
- [feat_docker][taier-all] remove unused docker file by @vainhope in https://github.com/DTStack/Taier/pull/877
- [feat_863][taier-worker-plugin] spark sql proxy auto upload by @jiemotongxue in https://github.com/DTStack/Taier/pull/866
- [hotfix][taier-docs] taier源码包下载地址不对 by @jiemotongxue in https://github.com/DTStack/Taier/pull/865
- [feat_doc][taier-all] add precautions.md by @vainhope in https://github.com/DTStack/Taier/pull/881
- build: specify the node and yarn version of taier-ui(#878) by @bnyte in https://github.com/DTStack/Taier/pull/882
- [issue_875][taier-all] add upload file size config by @vainhope in https://github.com/DTStack/Taier/pull/884
- [hotfix_871][taier-worker-plugin] script-core build Dir is error by @jiemotongxue in https://github.com/DTStack/Taier/pull/872
- [feat/cluster][taier-ui]improve description label in cluster's uploader by @mortalYoung in https://github.com/DTStack/Taier/pull/886
- [hotfix_datasource][taier-data-develop] fix datasource update time by @vainhope in https://github.com/DTStack/Taier/pull/894
- [issue_903][sql] fix sync init sql by @vainhope in https://github.com/DTStack/Taier/pull/906
- [issue_876][sql] adjust spark network time by @vainhope in https://github.com/DTStack/Taier/pull/904
- [fix/schedule][taier-ui]support render deleted task in schedule by @mortalYoung in https://github.com/DTStack/Taier/pull/902
- fixed: the ui project cannot download yarn by @bnyte in https://github.com/DTStack/Taier/pull/901
- [issue_669][taier-data-develop]show schedule job name when task is deleted; scheduling job to autoCanceled rather than submitFaild if task is deleted by @yyl4ever in https://github.com/DTStack/Taier/pull/905
- [fix/envParams][taier-ui]fix cursor always in first time on envParams by @mortalYoung in https://github.com/DTStack/Taier/pull/909
- [feat_exception][taier-data-develop] adjust exception message by @vainhope in https://github.com/DTStack/Taier/pull/916
- [issue_669][taier-data-develop]scheduling job to submitFaild if task is deleted, logic accord with TaskStatusSubmitInterceptor, so we can rerun son jobs. by @yyl4ever in https://github.com/DTStack/Taier/pull/918
- [fix/testConn][taier-ui]fix message.error in twice by @mortalYoung in https://github.com/DTStack/Taier/pull/917
- [Bug][taier-datasource、taier-worker-plugin] 对datasource plugin和 worker plugin的spi文件增加 License by @jiemotongxue in https://github.com/DTStack/Taier/pull/922
- [Feature] Add Oracle Datasource Plugin by @jiemotongxue in https://github.com/DTStack/Taier/pull/913
- [issue_923][taier-data-develop]cache tip after application start-up, remove left join SQ by @yyl4ever in https://github.com/DTStack/Taier/pull/926
- Feature: support mysql task by @chyueyi in https://github.com/DTStack/Taier/pull/925
- feature: supported ftp source reader and target by @bnyte in https://github.com/DTStack/Taier/pull/915
- [feat/ftp][taier-ui]support ftp in reader and writer by @mortalYoung in https://github.com/DTStack/Taier/pull/911
- fixed: 1.3.1 increment sql merged(#936) by @bnyte in https://github.com/DTStack/Taier/pull/937
- [issue_934][taier-schedule] fix hour schedule task fill data only one… by @vainhope in https://github.com/DTStack/Taier/pull/935
- [issue_939][taier-data-develop] fix new task lost task param fix #939 by @vainhope in https://github.com/DTStack/Taier/pull/940
- [issue_883][taier-data-develop] fix doris sql query lost column name … by @vainhope in https://github.com/DTStack/Taier/pull/933
- [issue_920][taier-schedule] fix cluster config standalone deploy get … by @vainhope in https://github.com/DTStack/Taier/pull/928
- Feat npe by @vainhope in https://github.com/DTStack/Taier/pull/942
- fixed: ftp target index #938 no initial value given by @bnyte in https://github.com/DTStack/Taier/pull/943
- fix: table render in FTP target by @mortalYoung in https://github.com/DTStack/Taier/pull/941
- [fix/dependence][taier-ui]fix tenantName render incorrect by @mortalYoung in https://github.com/DTStack/Taier/pull/945
- [refactor][taier-ui]parse task variables by editor's value in default by @mortalYoung in https://github.com/DTStack/Taier/pull/950
- [style/utils][taier-ui]remove unused functions by @mortalYoung in https://github.com/DTStack/Taier/pull/949
- [fix/create][taier-ui]fix create folder failed by @mortalYoung in https://github.com/DTStack/Taier/pull/953
- [feat/icon][taier-ui]add several icons by @mortalYoung in https://github.com/DTStack/Taier/pull/955
- [issue_944][taier-data-develop] add taskTask update fix #944 by @vainhope in https://github.com/DTStack/Taier/pull/954
- [refactor/upstream][taier-ui]improve the upstream default options by @mortalYoung in https://github.com/DTStack/Taier/pull/956
- build: bump molecule's version to 1.3.0 by @mortalYoung in https://github.com/DTStack/Taier/pull/958
- [feat/selection][taier-ui]support run sql in selection by @mortalYoung in https://github.com/DTStack/Taier/pull/957
- [issue_932][taier-schedule] remove prometheus information delay time … by @vainhope in https://github.com/DTStack/Taier/pull/946
- [Improve][DataSource] Use automatic resource management to replace 'try - finally' code block. by @FlechazoW in https://github.com/DTStack/Taier/pull/960
- Issue 932 by @vainhope in https://github.com/DTStack/Taier/pull/959
- chore(version): bump @dtinsight/molecule to 1.3.0 by @mortalYoung in https://github.com/DTStack/Taier/pull/962
- [Issue_767][taier-data-develop] Support datasync target datasource with Hive3 by @jiemotongxue in https://github.com/DTStack/Taier/pull/961
- [feat/close][taier-ui] improve close tab related event handler by @mortalYoung in https://github.com/DTStack/Taier/pull/965
- fix: fix result render failed by @mortalYoung in https://github.com/DTStack/Taier/pull/963
- [improve/test][taier-ui] improve test coverage by @mortalYoung in https://github.com/DTStack/Taier/pull/969
- Feat doc by @vainhope in https://github.com/DTStack/Taier/pull/970
- [tests/components][taier-ui]update tests for components by @mortalYoung in https://github.com/DTStack/Taier/pull/971
- [test/pages][taier-ui]update tests for pages by @mortalYoung in https://github.com/DTStack/Taier/pull/972
- [refactor/warning][taier-ui] remove warning message in devtool console by @mortalYoung in https://github.com/DTStack/Taier/pull/968
- [style/ci][taier-ui]improve code style by @mortalYoung in https://github.com/DTStack/Taier/pull/973
- [fix][data-develop]fix sync job channel(#974) by @QAQ-Jun in https://github.com/DTStack/Taier/pull/975
- [fix][Taier-data-develop] task dependency loop check by @wjschsg88 in https://github.com/DTStack/Taier/pull/976
- [fix] Fixed deployment document for docker compose by @JinsYin in https://github.com/DTStack/Taier/pull/978
- [fix][taier-all] fix MaxCompute sql run error by @vainhope in https://github.com/DTStack/Taier/pull/977
- Feat support mr by @jiemotongxue in https://github.com/DTStack/Taier/pull/983
- Feat ns1 by @vainhope in https://github.com/DTStack/Taier/pull/979
- [issue_951][taier-scheduler] fix create hive partition bug #951 by @QAQ-Jun in https://github.com/DTStack/Taier/pull/989
- [feature][taier-all] delete select temp table after expire time fix #889 by @vainhope in https://github.com/DTStack/Taier/pull/990
- [doc][website] update doc by @vainhope in https://github.com/DTStack/Taier/pull/993
- [hotfix_][taier-data-develop] fix select sql query null by @vainhope in https://github.com/DTStack/Taier/pull/995
- [hotfix_master_cycle_sacnning_day][schedule][ fix scanner job ] by @zhaozhenzhi in https://github.com/DTStack/Taier/pull/994
- [doc][website] fix doc sidebar by @vainhope in https://github.com/DTStack/Taier/pull/996
- [script][taier-script] fix start script not check dir by @vainhope in https://github.com/DTStack/Taier/pull/998
- [issue_997][taier-all] support hive properties set fix #997 by @vainhope in https://github.com/DTStack/Taier/pull/1001
- 升级fastjson版本到1.2.83,1.2.83版本之前存在代码执行漏洞风险,CVE-2022-25845 by @BIngDiAn-s in https://github.com/DTStack/Taier/pull/1011
- [feat/hadoopMR][taier-ui]support hadoopMR icon by @mortalYoung in https://github.com/DTStack/Taier/pull/1022
- [fix/execute][taier-ui]fix get same jobId when execute sql repeat by @mortalYoung in https://github.com/DTStack/Taier/pull/1021
- [fix/envParams][taier-ui]fix envParams not changed when task changed by @mortalYoung in https://github.com/DTStack/Taier/pull/1015
- [feat/console][taier-ui]improve multiple version render by @mortalYoung in https://github.com/DTStack/Taier/pull/1033
- Feat table by @vainhope in https://github.com/DTStack/Taier/pull/1029
- Conflict datax into master by @peishengsheng in https://github.com/DTStack/Taier/pull/1034
- fixed: 系统兼容性(#964)不同系统数据文件分割符问题 by @bnyte in https://github.com/DTStack/Taier/pull/1035
- [issue_1005][taier-schedule] fix jobKey contains my self fix #1005 by @vainhope in https://github.com/DTStack/Taier/pull/1039
- [issue_1019][taier-script] add project type field by @vainhope in https://github.com/DTStack/Taier/pull/1037
- [feat_mapper][taier_dao] fix "getByVersionName" sql by @numbernumberone in https://github.com/DTStack/Taier/pull/1042
- [improve/keywords][taier-ui]prevent duplicated fetch for keywords by @mortalYoung in https://github.com/DTStack/Taier/pull/1047
- [fix/dep][taier-ui]fix dep render undefined by @mortalYoung in https://github.com/DTStack/Taier/pull/1044
- [feat_table_desc][sql] add table comment by @vainhope in https://github.com/DTStack/Taier/pull/1043
- [feat_script_doc][website] add script standalone doc by @QAQ-Jun in https://github.com/DTStack/Taier/pull/1048
- Conflict bug by @QAQ-Jun in https://github.com/DTStack/Taier/pull/1051
- [issue_1045][taier-schedule] self-dependence day tasks fill data lose… by @vainhope in https://github.com/DTStack/Taier/pull/1046
New Contributors
- @poxiao8 made their first contribution in https://github.com/DTStack/Taier/pull/841
- @chyueyi made their first contribution in https://github.com/DTStack/Taier/pull/925
- @wjschsg88 made their first contribution in https://github.com/DTStack/Taier/pull/976
- @JinsYin made their first contribution in https://github.com/DTStack/Taier/pull/978
- @zhaozhenzhi made their first contribution in https://github.com/DTStack/Taier/pull/994
- @BIngDiAn-s made their first contribution in https://github.com/DTStack/Taier/pull/1011
- @numbernumberone made their first contribution in https://github.com/DTStack/Taier/pull/1042
Full Changelog: https://github.com/DTStack/Taier/commits/v1.4.0
v1.3.0
1 year agoWhat's Changed
- [feat_1.3_issue#724][taier-data-develop] standalone bugfix by @ghm02708 in https://github.com/DTStack/Taier/pull/799
- [Improve][CI] Fix ci/cd by @FlechazoW in https://github.com/DTStack/Taier/pull/793
- [refactor/queue][taier-ui]move queueConfig from rightbar to create config by @mortalYoung in https://github.com/DTStack/Taier/pull/795
- [feat/website][website]develop website homepage by @mortalYoung in https://github.com/DTStack/Taier/pull/800
- [1.3_beta][taier-all] fix flink standalone component config by @vainhope in https://github.com/DTStack/Taier/pull/802
- [1.3_beta][taier-all] fix dirty table by @vainhope in https://github.com/DTStack/Taier/pull/804
- [fix/workflow][taier-ui]fix lost line in workflow by @mortalYoung in https://github.com/DTStack/Taier/pull/791
- [fix/flink][taier-ui]fix flink tab saving by @mortalYoung in https://github.com/DTStack/Taier/pull/803
- [fix/clickhouse][taier-ui]clickhouse and doris as task support syntax highlight by @mortalYoung in https://github.com/DTStack/Taier/pull/805
- [feat/sparkjar][taier-ui]support sparkjar task by @mortalYoung in https://github.com/DTStack/Taier/pull/806
- [fix/usePagination][taier-ui]fix pagination get incorrect by @mortalYoung in https://github.com/DTStack/Taier/pull/809
- [fix/validator][taier-ui]fix validator folder failed in resource by @mortalYoung in https://github.com/DTStack/Taier/pull/796
- [fix/default][taier-ui]remove default actions and barItems by @mortalYoung in https://github.com/DTStack/Taier/pull/807
- [fix/folderPicker][taier-ui]fix folderPicker with workflow by @mortalYoung in https://github.com/DTStack/Taier/pull/797
- [fix/workflow][taier-ui]fix workflow repeated name in validating by @mortalYoung in https://github.com/DTStack/Taier/pull/808
- feat: improve popup in create by @mortalYoung in https://github.com/DTStack/Taier/pull/810
- [test/services][taier-ui]improve test coverage by @mortalYoung in https://github.com/DTStack/Taier/pull/811
- [fix/splitKey][taier-ui]support to get splitKey in array by @mortalYoung in https://github.com/DTStack/Taier/pull/812
- [feat/taskInfo][taier-ui]support to show dataSource in task info tab by @mortalYoung in https://github.com/DTStack/Taier/pull/816
- [1.3_beta][taier-all] fix sql by @vainhope in https://github.com/DTStack/Taier/pull/818
- [fix/schema][taier-ui]remove Schema in contextMenu by @mortalYoung in https://github.com/DTStack/Taier/pull/819
- [fix/scheduleConf][taier-ui]fix selfReliance won't change by @mortalYoung in https://github.com/DTStack/Taier/pull/814
- [fix/cluster][taier-ui]improve cluster save by @mortalYoung in https://github.com/DTStack/Taier/pull/820
- [fix/flinkSource][taier-ui]fix flinkSource alias by @mortalYoung in https://github.com/DTStack/Taier/pull/817
- [refactor/preview][taier-ui]improve preview table by @mortalYoung in https://github.com/DTStack/Taier/pull/822
- 1.3 beta by @vainhope in https://github.com/DTStack/Taier/pull/823
- [issue#798][taier-data-develop] flink udf 回显不正确 by @ghm02708 in https://github.com/DTStack/Taier/pull/824
- [issue#826][taier-data-develop] replace task_template,init sql revisal by @ghm02708 in https://github.com/DTStack/Taier/pull/827
- [fix/componentVersion][taier-ui]improve componentVersion label by @mortalYoung in https://github.com/DTStack/Taier/pull/825
- [fix][taier-data-develop] remove common DataSourceType by @ghm02708 in https://github.com/DTStack/Taier/pull/828
- Bump molecule from 1.1.0 to 1.2.0 by @mortalYoung in https://github.com/DTStack/Taier/pull/831
- [refactor/completion][taier-ui]improve completion for editor by @mortalYoung in https://github.com/DTStack/Taier/pull/830
- 1.3 beta by @vainhope in https://github.com/DTStack/Taier/pull/832
- [fix/cluster][taier-ui]support more impressive error log by @mortalYoung in https://github.com/DTStack/Taier/pull/833
- [fix/execute][taier-ui]fix log output panel after executing by @mortalYoung in https://github.com/DTStack/Taier/pull/834
- [Improve][Common] Upgrade 'flink.version' to 1.12.7 by @FlechazoW in https://github.com/DTStack/Taier/pull/836
- [fix][taier-data-develop] com.dtstack.chunjun.util.FactoryHelper should be loaded by DtClassloader by @ghm02708 in https://github.com/DTStack/Taier/pull/837
- [fix][taier-data-develop] standalone log fix by @ghm02708 in https://github.com/DTStack/Taier/pull/838
- 1.3 beta by @vainhope in https://github.com/DTStack/Taier/pull/839
- [fix/stream][taier-ui]remove component version filters in stream by @mortalYoung in https://github.com/DTStack/Taier/pull/840
- [fix/flink][taier-ui]fix validation on flinksql by @mortalYoung in https://github.com/DTStack/Taier/pull/835
- [1.3_beta][迁移 listFile 方法到 datasource 中] by @poxiao8 in https://github.com/DTStack/Taier/pull/841
- 1.3 beta by @vainhope in https://github.com/DTStack/Taier/pull/845
New Contributors
- @poxiao8 made their first contribution in https://github.com/DTStack/Taier/pull/841
Full Changelog: https://github.com/DTStack/Taier/commits/v1.3.0
v1.2.0
1 year agoTaier1.2版本做了以下更新:
1. 新增工作流
通过可视化的拖动任务节点到画板中,手动连接上下游任务组成依赖关系,形成一个DAG的工作流。 支持任意类型的任务通过工作流拖拽的方式,直接实现配置化编排业务
2. 新增OceanBase SQL
新增OceanBaseSQL 任务,支持OceanBaseSQL的任务调度和运维展示
3. 新增Flink jar任务
支持上传自定义开发的flink jar任务,通过taier提交运行和监控,
4. 数据同步、实时采集支持脏数据管理
数据同步、实时采集支持脏数据管理,可以配置脏数据数量限制和保存方式,可保存至数据库实时查看
5. Hive UDF
Hive SQL 支持udf函数开发配置
6. 控制台
控制台交互和页面全新升级,通过树形结构展示组件配置信息。支持扩展自定义组件进行配置
7. 租户绑定简化
集群和租户绑定简化,移除租户对接集群schema的强制绑定关系,不同类型计算组件无强制依赖, 优化任务开发流程逻辑,支持自定义扩展任务类型,新增了任务和schema绑定关系
感谢所有向 Taier 1.2贡献的朋友
| 参与者 |
|---|
| bnyte |
| ghm02708 |
| kongshan-zhuyu |
| LousenJay |
| mortalYoung |
| QAQ-Jun |
| Saltingfish |
| vainhope |
v1.1.0
2 years ago本次上线的Taier1.1版本做了以下更新:
1. Flink 版本升级到1.12
Taier作为一个分布式可视化的DAG任务调度系统,采用Chunjun作为分布式数据同步工具。 1.1版本将Flink版本升级到1.12 ,支持Chunjun 1.12版本中新增的transformer算子,用户在脚本中定义好数据类型以及SQL转换逻辑。 支持Flink 1.12的原生语法及Function
2. 数据同步支持脚本模式、增量同步
数据同步任务除向导模式外,1.1版本新增数据同步脚本模式。 脚本模式通过json的方式配置,无需依赖datasourcex的支持的数据源,直接通过json配置的方式提交任务, 脚本模式的json格式无缝兼容Chunjun的数据格式,用户可以通过脚本模式调试各类数据源的数据同步

3. 新增Hive SQL
新增Hive SQL类型任务,Apache Hive是一个构建于Hadoop顶层的数据仓库,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。
Taier1.1版本新增Hive SQL ,支持对接Hive的不同版本

4. 新增Flink SQL、实时采集等实时类型任务
新增实时采集任务,支持将MySQL、Oracle的数据同步至Kafka
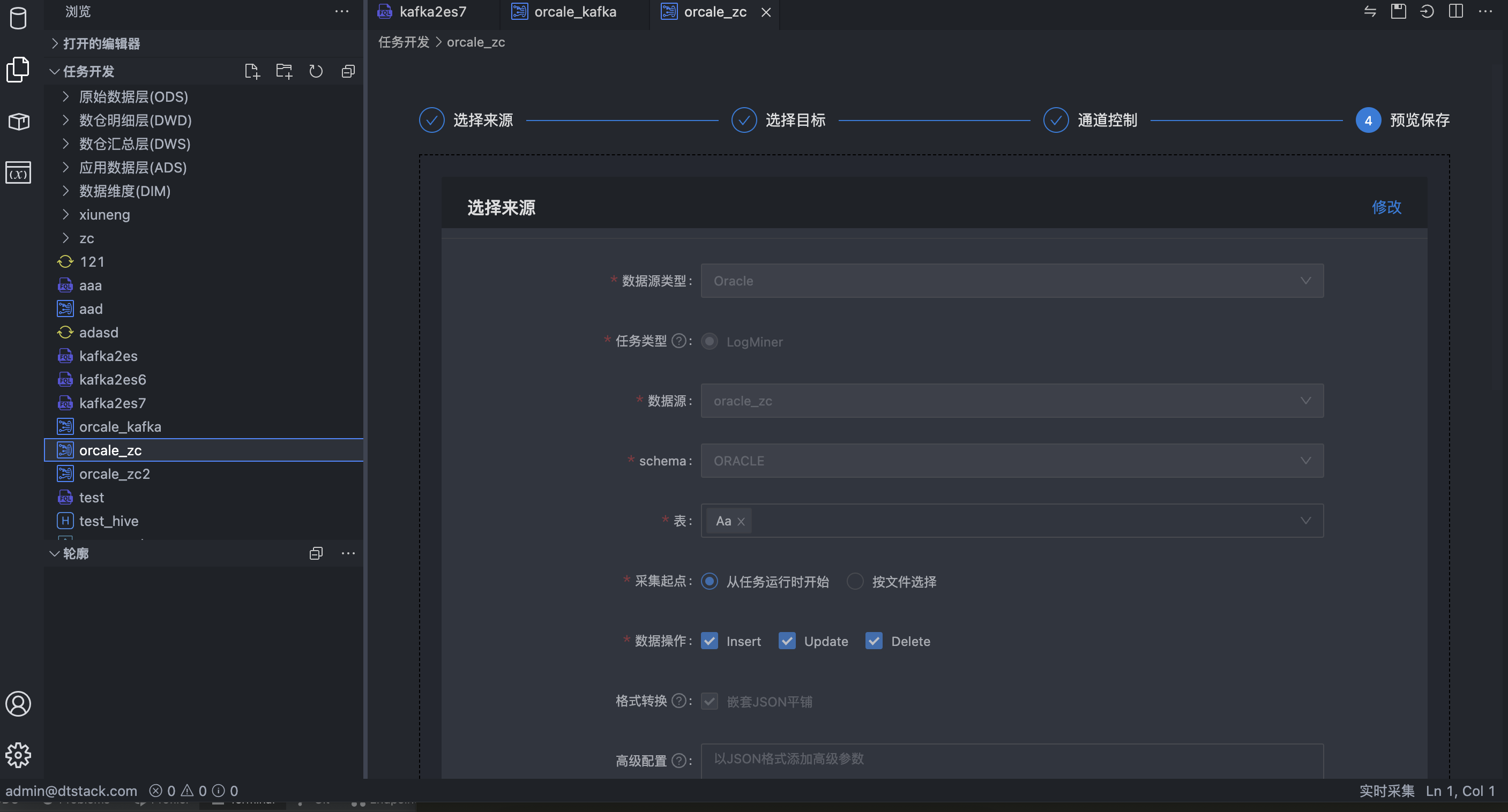 新增Flink SQL任务,通过标准SQL语义的开发帮助快速完成数据任务的配置工作
新增Flink SQL任务,通过标准SQL语义的开发帮助快速完成数据任务的配置工作

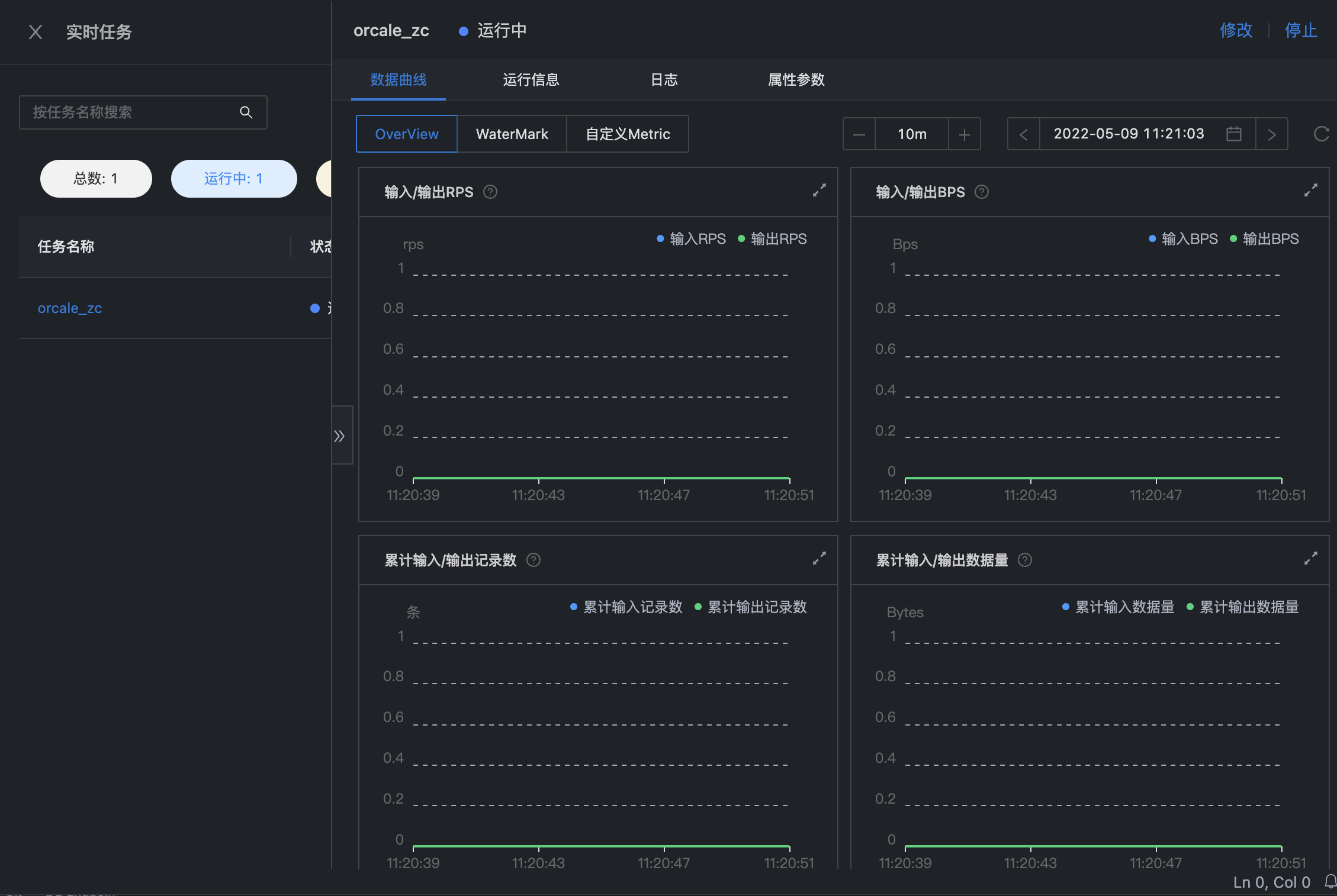
5. 新增实时任务运维
通过实时运维中心查看实时任务的相关指标信息以及任务的详细日志信息
6. 支持Flink UDF、Spark UDF
用户自定义函数(User Defined Function,简称 UDF),是用户除了使用系统函数外,自行创建的函数,用于满足个性化的计算需求。自定义函数在使用上与普通的系统函数类似。
目前Taier1.1版本 Spark SQL 和 Flink SQL 任务均支持自定义函数
7. 暗黑主题
Taier开发界面暗黑主题上线,提供多种主题切换,用户可自行选择
感谢所有向 Taier 1.1贡献的朋友
| 参与者 |
|---|
| bnyte |
| dtdazhi |
| ghm02708 |
| jiemotongxue |
| kongshan-zhuyu |
| LousenJay |
| mortalYoung |
| QAQ-Jun |
| Saltingfish |
| vainhope |
v1.0.0
2 years ago支持 chunjun1.10 支持 Spark SQL 2.1版本 支持 对接kerberos认证 支持 docker部署 支持 hadoop2、hadoop3版本