Syne Tune Versions Save
Large scale and asynchronous Hyperparameter and Architecture Optimization at your fingertips.
v0.13.0
3 months agoWhat's New
We are excited to announce the following updates in Syne Tune v0.13.0:
- Allow the acquisition function to be chosen in GPFIFOSearcher
- Allow to restrict GPUs to be used in LocalBackend to a subset of all available ones
- Obtain Pareto Set from results
Allow the acquisition function to be chosen in GPFIFOSearcher
When running Bayesian optimization or MOBSTER, you can now choose the acquisition function which is optimized in order to select the next configuration to be evaluated, using the acq_function and acq_function_kwargs arguments in search_options when creating the scheduler. Here are more details.
At present, we support the (negative) expected improvement ("ei"; default) and lower confidence bound ("lcb") acquisition functions. Your favorite acquisition function is missing? Why not implement it yourself (detailed hints are given here) and send us a pull request?
Allow to restrict GPUs to be used in LocalBackend to a subset of all available ones
By default, the local backend makes use of all GPUs available on the instance it runs on. Using the gpus_to_use argument of LocalBackend, you can now restrict the backend to use a subset of these only. This is useful if the remaining GPUs are needed for something else, or if you want to benchmark under restricted conditions.
Obtain Pareto Set from results
The new functions get_pareto_optimal and get_pareto_set filter results to obtain a Pareto optimal set. This is useful for visualizing the results from multi-objective hyperparameter optimization.
Changes
🌟 New Features
- feat: Allow to restrict GPUs to be used in LocalBackend to a subset of all available ones (#817) by @mseeger
- feat: Obtain Pareto Set from results (#798) by @aaronkl
- feat: Allow the acquisition function to be chosen in GPFIFOSearcher (#807) by @mseeger
📜 Documentation Updates
- docs: Add FAQ entry to clarify behaviour of training script for pause and resume scheduling (#809) by @mseeger
- docs: Links to Andreas Mueller's talk on Mothernet (#808) by @mseeger
🐛 Bug Fixes
- fix: Reject results if metric is NaN or infinite (#788) by @mseeger
🔧 Maintenance
- chore: Bump zgosalvez/github-actions-ensure-sha-pinned-actions from 2.1.4 to 3.0.3 (#797) by @dependabot
- chore: update Ray version in example (#814) by @wesk
- chore: Bump actions/setup-python from 4 to 5 (#793) by @dependabot
- chore: Bump release-drafter/release-drafter from 5.24.0 to 5.25.0 (#774) by @dependabot
- chore: Uncommented test which needs SageMaker. It is still commented out (#810) by @mseeger
- chore: change version of pymoo (#806) by @aaronkl
This release was made possible by the following contributors:
@aaronkl, @dependabot, @dependabot[bot], @mseeger and @wesk
v0.10.0
6 months agoWhat's New
We are excited to announce the following updates in Syne Tune v0.10.0:
- Integration with SMAC optimizer
- Documentation on how to resume a tuning with the same search space or a smaller search space
- Tune XGBoost example notebook
- Several quality of life improvements: 1) plot trial results directly from experiment results and 2) get best configurations directly from the tuner
SMAC Optimizer
Syne Tune now contains a wrapper allowing optimization with SMAC. We hope the integration will encourage more extensive benchmarking and allow users to leverage advanced features of SMAC.
- Example: examples/launch_smac_example.py
- Implementation: syne_tune/optimizer/baselines.py
Documentation on how to resume a tuning with the same search space or a smaller search space
Sometimes, one wants to resume a previous tuning, to tune a bit longer, perhaps rerun a failed tuning job, or rerun with restricted the search space. Given that this scenario is quite common, we added an example showing how to resume a previous tuning experiment and update the search space.
- Example: examples/launch_resume_tuning.py
Tune XGBoost example notebook
This is Syne Tune’s first example that is written as a Jupyter notebook. It shows how to tune XGBoost with Syne Tune.
- Example: https://github.com/awslabs/syne-tune/blob/main/examples/notebooks/tune_xgboost.ipynb
- Same example rendered in the docs: https://syne-tune.readthedocs.io/en/latest/notebooks/tune_xgboost.html
Several quality of life improvements: 1) plot trial results directly from experiment results and 2) get best configurations directly from the tuner
An efficient way to see how an experiment performed is to plot the results of trials over time. We added the following tool to make this easier:
from syne_tune.experiments import load_experiment
exp = load_experiment("PREVIOUS_EXPERIMENT_TAG")
exp.plot_trials_over_time()
Which generates plots that look like this:
Changes
🌟 New Features
- feat: Add example to resume tuning from previous experiment and update conf… (#780) by @geoalgo
- feat: Add method to get the best configuration directly from Tuner, add com… (#767) by @geoalgo
- feat: Add util to plot trials over time from ExperimentResult (#768) by @geoalgo
- feat: Add SMAC wrapper and examples (#765) by @geoalgo
- feat: Automatic streamlining of configuration space (#741) by @mseeger
📜 Documentation Updates
- docs: Adding links to API in tutorials (#787) by @mseeger
- ci: automatically test all notebooks under
examples/notebooksand render them in docs page (#756) by @wesk - fix: Fix malformatted table in docs (#757) by @mseeger
🐛 Bug Fixes
- fix: Fix sagemaker backend (#784) by @geoalgo
- fix: pin traitlets version to fix notebook conversion script (#782) by @wesk
- fix: Fix malformatted table in docs (#757) by @mseeger
- fix: pass arguments to scheduler (#755) by @aaronkl
- fix: RSBO (#748) by @aaronkl
- fix: Fix for issue #749 (#750) by @mseeger
🔧 Maintenance
- chore: release v0.10.0 (#783) by @wesk
- chore: Add smac to possible install tag, fix comment in example (#766) by @geoalgo
- chore: Update sphinx requirement from <7.0.0 to <8.0.0 (#745) by @dependabot
- chore: Update numpy requirement from <1.24.0,>=1.16.0 to >=1.16.0,<1.27.0 (#761) by @dependabot
- chore: Bump release-drafter/release-drafter from 5.23.0 to 5.24.0 (#735) by @dependabot
- chore: Bump aws-actions/configure-aws-credentials from 3 to 4 (#760) by @dependabot
- chore: Bump actions/checkout from 3 to 4 (#763) by @dependabot
- chore: Bump actions/setup-python from 2 to 4 (#762) by @dependabot
- chore: Bump actions/checkout from 3 to 4 (#759) by @dependabot
- chore: Bump actions/setup-python from 2 to 4 (#747) by @dependabot
- chore: Bump aws-actions/configure-aws-credentials from 2 to 3 (#752) by @dependabot
This release was made possible by the following contributors:
@aaronkl, @dependabot, @dependabot[bot], @geoalgo, @mseeger and @wesk
v0.9.1
9 months agoWhat's New
You can now install Syne Tune with the command pip install 'syne-tune[basic]'
This installs Syne Tune with a recommended set of dependencies.
You can still customize your installation and install Syne Tune using all the existing options, including:
-
pip install syne-tune, for the minimum dependencies -
pip install 'syne-tune[gpsearchers]', for built-in Gaussian process based optimizers -
pip install 'syne-tune[gpsearchers,aws]', for AWS SageMaker andgpsearchersdependencies -
pip install 'syne-tune[extra]', for all dependencies
Refer to the Syne Tune documentation for more information.
Changes
🌟 New Features
- feat: New group tag 'basic' for dependencies of reasonable size (#738) by @mseeger
📜 Documentation Updates
- docs: Small fix and update of README.md (#740) by @mseeger
🔧 Maintenance
- chore: next release (#744) by @wesk
- chore: Bump zgosalvez/github-actions-ensure-sha-pinned-actions from 2.1.3 to 2.1.4 (#742) by @dependabot
- chore: update README (#739) by @wesk
This release was made possible by the following contributors:
@dependabot, @dependabot[bot], @mseeger and @wesk
v0.9.0
10 months agoWhat's New
We are excited to announce the following updates in Syne Tune v0.9.0:
- Experimentation framework (aka benchmarking framework) can now be used without needing to install Syne Tune from source.
- Several multi-objective tuning methods are now available as baseline wrappers and via the experimentation framework.
- New advanced developer tutorial on how to implement or extend Bayesian optimization in Syne Tune
- Bug fix ensures that basic examples run with Syne Tune core dependencies
Experimentation Framework
Syne Tune's experimentation framework (aka benchmarking framework) is moved from benchmarking/commons to syne_tune/experiments, so it can be used without installing Syne Tune from source. This framework makes it very easy to compose launcher scripts, run studies with many experiments in parallel, explore the different trial execution backends, and plot results aggregated from many experiments. Learn more in this tutorial.
Multi-objective Tuning
Syne Tune contains a number of multi-objective tuning methods, which explore the Pareto frontier for a setup where multiple objectives matter. These are now easily available as MOASHA, MORandomScalarizationBayesOpt, NSGA2, MOREA, MOLinearScalarizationBayesOpt in syne_tune/optimizer/baselines.py.
Tutorial: How to Implement Bayesian Optimization
This extension of our developer tutorial shows how Bayesian optimization is implemented in Syne Tune. You learn how to implement a new surrogate model, a new acquisition function, or a new covariance function for Gaussian process models, or also how to combine existing GP code into a composite surrogate model.
Running Syne Tune with core Dependencies
In this release we fixed import bugs to make sure that many of our examples work with minimal dependencies, and also updated testing in our CI system.
There are several different ways you can install Syne Tune, including:
-
pip install syne-tune, with core dependencies only -
pip install 'syne-tune[aws]', for AWS dependencies -
pip install 'syne-tune[gpsearchers]', for Gaussian Process dependencies -
pip install 'syne-tune[moo]', for multi-objective dependencies -
pip install 'syne-tune[extra]', for all extra dependencies
The full list of extras is available here.
Syne Tune allows you to install just the dependencies that you want to use for your use-case.
If your use case does not need Bayesian optimization, multi-objective support, and AWS, for example, you may be able to run with just core dependencies (obtained with pip install syne-tune, as opposed to pip install syne-tune[extra] or a related command which installs extra dependencies).
Changes
📜 Documentation Updates
- docs: New tutorial on how to implement Bayesian optimization (#709) by @mseeger
- docs: Experimentation framework without Syne Tune installed from source (#733) by @mseeger
- docs: Updated documentation (#732) by @mseeger
- docs: Add CQR in list of method supported in readme (#736) by @geoalgo
🐛 Bug Fixes
- fix: Clean up imports so that code runs with core dependencies. Update test workflows (#734) by @mseeger
- fix: Make sure RemoteLauncher works with requirements.txt not ending on newline (#731) by @mseeger
- fix: ExperimentResult.best_config() always used max mode (#728) by @ystein
🏗️ Code Refactoring
- refactor: Move code from benchmarking/commons to syne_tune/experiments (#719) by @mseeger
- refactor: Wrappers for multi-objective methods (#727) by @mseeger
🔧 Maintenance
- chore: fix yahpo dependency version of configspace (#725) by @geoalgo
This release was made possible by the following contributors:
@geoalgo, @mseeger and @ystein
v0.8.0
10 months agoWhat's New
We are excited to announce the following new features in Syne Tune v0.8.0:
- New searcher which can use most SKLearn estimators as surrogates for BO, examples here
- Conformal Quantile Regression method from “Optimizing Hyperparameters with Conformal Quantile Regression" by Salinas et al.
- New Multi Surrogate Multi Objective Searcher with example usage here
- Implementation of the new method presented in "Obeying the Order: Introducing Ordered Transfer Hyperparameter Optimisation" paper by Hellan et al.
- Extension of BOTorch GP model to support transfer learning
- Improvements to plotting tools
⭐ Congratulations to @eddiebergman for making their first contribution to Syne Tune and @sighellan for their latest contribution!
SKlearn Searcher
Users of Syne Tune can now use any surrogate model that conforms with SKLearn interface in the new flexible Bayesian Optimization (BO) Searcher; take advantage of state of the art BO with custom models without boilerplate code. Simply define your Estimator (responsible for fitting the predictor) and Predictor (responsible for making predictions) and pass them to SKLearnSurrogateSearcher to take advantage of Bayesian Optimization (including acquisition functions, scheduling, etc.) in Syne Tune based on your custom models. Using models like BayesianRidge can be as simple as the example below (see launch_sklearn_surrogate_bo for details).
class BayesianRidgePredictor(SKLearnPredictor):
def __init__(self, ridge: BayesianRidge):
self.ridge = ridge
def predict(self, X: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:
return self.ridge.predict(X, return_std=True)
class BayesianRidgeEstimator(SKLearnEstimator):
def __init__(self, *args, **kwargs):
self.ridge = BayesianRidge(*args, **kwargs)
def fit(
self, X: np.ndarray, y: np.ndarray, update_params: bool
) -> SKLearnPredictor:
self.ridge.fit(X, y.ravel())
return BayesianRidgePredictor(ridge=copy.deepcopy(self.ridge))
searcher = SKLearnSurrogateSearcher(
config_space=config_space,
estimator=BayesianRidgeEstimator(),
)
scheduler = FIFOScheduler(
config_space,
metric=METRIC_ATTR,
mode=METRIC_MODE,
searcher=searcher,
)
Conformal Quantile Regression
Many state-of-the-art hyperparameter optimization (HPO) algorithms rely on model-based optimizers that learn surrogate models of the target function to guide the search. Gaussian processes are the de facto surrogate model due to their ability to capture uncertainty but they make strong assumptions about the observation noise, which might not be warranted in practice. In this work, we propose to leverage conformalized quantile regression which makes minimal assumptions about the observation noise and, as a result, models the target function in a more realistic and robust fashion which translates to quicker HPO convergence on empirical benchmarks. Read more about this work in Optimizing Hyperparameters with Conformal Quantile Regression and see example usage in launch_cqr_nasbench201.
Multi Surrogate Multi Objective Searcher
Combine multiple surrogate models in a single method in the new Multi Surrogate Searcher. Define custom models for every objective, for example Gaussian process regressor for some and a simple lookup table for others, and use them together to efficiently sample the pareto front of your MO problem. This is the latest release in our ongoing effort to expand Syne Tune’s coverage of multi-objective methods.
For the full list of multi-objective optimization methods that Syne Tune supports, refer to this table.
Obeying the Order: Introducing Ordered Transfer Hyperparameter Optimisation
We provide an implementation of OTHPO, a transfer learning method that takes the intrinsic order of tasks into account, such as, for example HPO where the dataset is increasing over time. Instead of modelling tasks as a set, OTHPO models them as a sequence to focus on more recent tasks. The code for this paper by Hellan et al is now available in Syne Tune and the experiments can be found in benchmarking/nursery.
Plotting improvements
Plotting tools now allow for custom transformation to be applied on the results dataframe before aggregation. This allows users to define and plot new derived metrics based on recorded ones such as hypervolume indicator.
Changes
🌟 New Features
- feat: Code for OTHPO paper (#710) by @sighellan
- feat: Multi Surrogate Multi Objective Searcher (#711) by @jgolebiowski
- feat: Allow to transform result dataframe before aggregation in plotting (#696) by @mseeger
- feat: Plotting for single seed results works as well (#706) by @mseeger
- feat: Add Conformal Quantile Regression method from ICML paper. (#689) by @geoalgo
- feat: Some extra plotting features (#694) by @mseeger
- feat: Allow base kernel to be selected (#698) by @mseeger
- feat: Adding new searcher that uses contributed surrogate models. (#684) by @jgolebiowski
- feat: Try again in remote launching when ResourceLimitExceeded is caught (#676) by @mseeger
📜 Documentation Updates
- docs(examples): Typo fix (#713) by @eddiebergman
- docs: Tutorial on experimentation (#705) by @mseeger
- docs: Tutorial for ODSC presentation (#703) by @mseeger
- feat: Allow base kernel to be selected (#698) by @mseeger
🐛 Bug Fixes
- fix: Avoid sphinx 7.0.0, since the readthedocs build fails with that (#720) by @mseeger
- fix: Removed the broken example from github actions (#718) by @jgolebiowski
- fix: Fix bug in RemoteLauncher with SageMakerBackend (#717) by @mseeger
- fix: Some fixes for multi-objective benchmarking (#708) by @mseeger
- fix: Command line arguments of benchmarking (#702) by @mseeger
- fix: Avoid MOO warning message (#700) by @wistuba
- fix: New benchmarks need **kwargs, so that defaults can be overwritte… (#693) by @mseeger
- fix: Remove (CITATION?). Currently, these results are not published a… (#692) by @mseeger
🏗️ Code Refactoring
- refactor: Remove tuple option for Type[AcquisitionFunction], as this … (#715) by @mseeger
- refactor: Simplification in scikit-learn based estimators (#704) by @mseeger
- refactor: Clean up transformer_wikitext2 code (#701) by @mseeger
- refactor: Refactoring of scikit-learn based surrogate models (#699) by @mseeger
🔧 Maintenance
- chore: Adding 0.8.0 version release notes (#724) by @jgolebiowski
- chore: update README (#723) by @wesk
- chore: Remove documentation link from README.md (#722) by @geoalgo
- chore: Update pytest-cov requirement from ~=4.0.0 to ~=4.1.0 (#697) by @dependabot
- chore: enable caching for unit tests, fix README typo (#695) by @wesk
This release was made possible by the following contributors:
@aaronkl, @eddiebergman, @geoalgo, @jgolebiowski, @mseeger, @sighellan, @wesk and @wistuba
v0.7.0
11 months agoWhat's New
We are excited to announce the following new features in Syne Tune v0.7.0:
- New visualization tools
- New backoff decorator for scheduling SageMaker training jobs
- New multi-objective algorithm: NSGA-2
As well as a variety of bug fixes and documentation improvements.
⭐ Congratulations to @ystein for making their first contribution to Syne Tune!
New Visualization Tools
Documentation: https://syne-tune.readthedocs.io/en/latest/tutorials/benchmarking/bm_plotting.html
Syne Tune now supports plotting tools which make it easy to visualize the results of comparative experiments.
For example, the below plots comparing model-based methods (MOBSTER and HYPERTUNE) against baseline methods (ASHA, SYNCHBOB, and BOHB) were generated using Syne Tune:
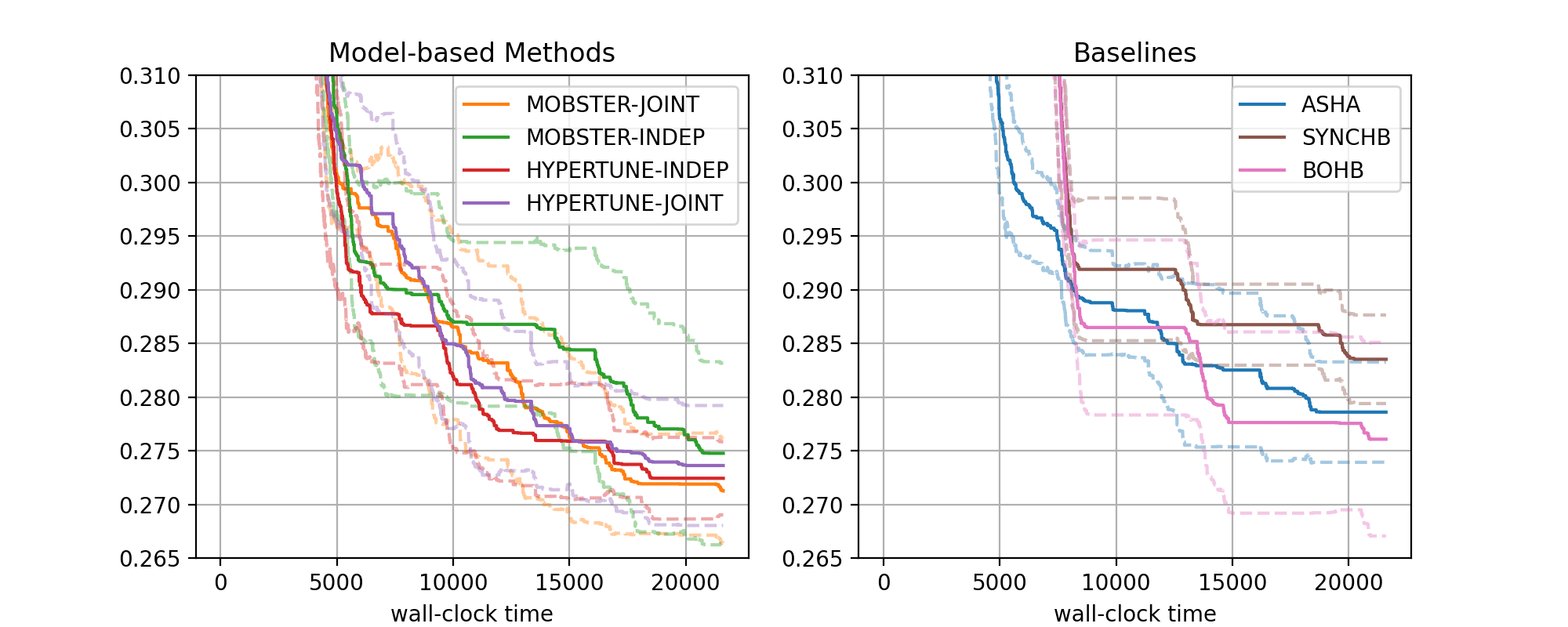
To learn how to use the plotting tools, refer to the tutorial.
Backoff Decorator for Scheduling SageMaker Training Jobs
The new backoff decorator makes it easier to avoid hitting SageMaker Training Job quota limits when running tuning jobs using the SageMaker backend. With this decorator, you can easily configure your code so that it automatically retries if you hit ResourceShareLimitExceededException or similar errors, making your trials more resilient.
New Multi-Objective Algorithm: NSGA-2
New in this release is support for NSGA-2, a popular genetic algorithm for multi-objective optimization that is frequently used in the literature. Our implementation is based on the pymoo library. This is the latest release in our ongoing effort to expand Syne Tune’s coverage of multi-objective methods.
For the full list of multi-objective optimization methods that Syne Tune supports, refer to this table.
Changes
🌟 New Features
- feat: Plotting code for fine_tuning_transformer_glue benchmark (#686) by @mseeger
- feat: Backoff decorator for jobs scheduling (#673) by @jgolebiowski
- feat: Plotting tools for result of comparative study (#652) by @mseeger
- feat: New surrogate models API (#669) by @jgolebiowski
- feat: implementation of NSGA-2 (#660) by @aaronkl
📜 Documentation Updates
- docs: Tutorial for plotting (#675) by @mseeger
- docs: Update README.md (#661) by @aaronkl
🐛 Bug Fixes
- fix: Missing image file in visualization tutorial (#691) by @mseeger
- fix: typos in "Getting started" code example (#687) by @ystein
- fix: Made scoring function compatible with acquisition function interface (#682) by @jgolebiowski
- fix: Sklearn estimator now fits the surrogate model without considering pending evaluations. (#681) by @jgolebiowski
- fix: Domain.len returns 0 for infinite domain (e.g., Float) (#672) by @mseeger
- fix: Fix bug in benchmarking where default values were int instead of… (#670) by @mseeger
- fix: Bugfix in benchmarking (#667) by @mseeger
- fix: Fix import bug, and also new workflow to install Syne Tune with … (#663) by @mseeger
🏗️ Code Refactoring
- refactor: Cleanup of training scripts (#668) by @mseeger
- refactor: Allow benchmark to be multi-objective (#666) by @mseeger
- refactor: Graduate some content in benchmarking/nursery and create ne… (#659) by @mseeger
- refactor: SurrogateModel -> Predictor; ModelFactory -> Estimator; Simplify bayesopt code (#651) by @mseeger
🔧 Maintenance
- chore: release v0.7.0 (#690) by @wesk
- chore: Bump codecov/codecov-action from 3.1.3 to 3.1.4 (#685) by @dependabot
- chore: fix unit test (#678) by @wesk
- chore: add initial multiobjective benchmarking logic (#674) by @wesk
- chore: re-introduce check-standalone-bayesian-optimization.yml (#664) by @wesk
- chore: Increase time limits on flakey tests (#658) by @mseeger
- chore: Bump zgosalvez/github-actions-ensure-sha-pinned-actions from 2.1.2 to 2.1.3 (#655) by @dependabot
This release was made possible by the following contributors:
@aaronkl, @dependabot, @dependabot[bot], @jgolebiowski, @mseeger, @wesk and @ystein
v0.6.0
1 year agoWhat's New
In this release we introduce 1) New example for tuning Hugging Face models on the SWAG benchmark, and 2) LocalBackend allows for more than 1 GPU per trial.
New example for tuning Hugging Face models on the SWAG benchmark (#641)
Demonstrates how to automate fine-tuning of a Hugging Face transformer model on the SWAG benchmark.
LocalBackend allows for more than 1 GPU per trial (#635)
You can specify num_gpus_per_trial with the local backend now, so that trials can use more than 1 GPU for training.
Changes
🌟 New Features
- feat: add example to optimize hyperparams of HF models on SWAG (#641) by @aaronkl
- feat: LocalBackend allows for >1 GPU per trial (#635) by @mseeger
📜 Documentation Updates
- docs: Link to D2L chapter in our docs (#653) by @mseeger
- docs: Alternative of 1-NN surrogate to restrict_configurations (#650) by @mseeger
🐛 Bug Fixes
- fix: Random seed range in benchmarking (#656) by @mseeger
- fix: Fixing limits for random seed (#645) by @mseeger
- fix: pin fastparquet version (#647) by @geoalgo
- fix: Fix
ListTrainingJobsthrottling for E2E tests (#634) by @wesk
🏗️ Code Refactoring
- refactor: Towards introduction of plotting code (#625) by @mseeger
- refactor: Simplified Bayesian optimization code (#640) by @mseeger
- refactor: Changes to benchmarking formalism (#637) by @mseeger
🔧 Maintenance
- chore: New release (0.6.0) (#657) by @mseeger
- chore: Bump gpy from 1.9.9 to 1.12.0 (#643) by @dependabot
- chore: Move long-running test (#654) by @mseeger
- chore: run two additional examples as tests (#648) by @wesk
- chore: only validate PR titles; specify list of valid prefixes (#646) by @wesk
- chore: Bump codecov/codecov-action from 3.1.2 to 3.1.3 (#639) by @dependabot
- chore: create workflow to draft CHANGELOG.md; auto-tag PRs on push (#631) by @wesk
This release was made possible by the following contributors:
@aaronkl, @dependabot, @dependabot[bot], @geoalgo, @mseeger and @wesk
v0.5.0
1 year agoWhat's New
In this release we introduce 1) Speculative early checkpoint removal, 2) Simple linear scalarization scheduler, 3) Plotting functions for multi-objective experiments, 4) Automatic termination criterion by Makarova et al., 5) support for custom results in results.csv.zip, and 6) Downsampling of observed data for Bayesian Optimization.
Speculative early checkpoint removal for async multi-fidelity (#628)
Retaining all checkpoints often exhausts all available disk space when training large models. With this optional feature, Syne Tune can now automatically remove checkpoints that are unlikely to be needed. Syne Tune now offers early checkpoint removal. For ASHA, MOBSTER, or HYPERTUNE, this involves dedicated logic to decide which checkpoints can safely be removed early.
Simple linear scalarization scheduler (#619)
We have expanded the offering of Multi-Objective Schedulers in Syne Tune by adding a simple scalarized optimizer. The method works by taking a multi-objective problem and turning it into a single-objective task by optimizing for a linear combination of all objectives. This wrapper works with all single-objective schedulers.
Plotting functions to analyse multi-objective experiments. (#611)
We have added experiment and plotting support for multi-objective benchmarks. You can now compute hypervolume indicator the points suggested by Tuner and plot the progress. Similarly with all individual objectives as well as their scalarization.
Automatic termination criterion (#605)
This implements the automatic termination criterion proposed by Makarova et al. Instead of defining a fix number of iterations or wall-clock time limit, we can set a threshold on how much worse do we allow the final solution to be compared to the global optima, such that we automatically stop the optimization process, once we found a solution meeting this criteria.
Allow for customized extra results to be written to results.csv.zip (#612)
It is now easy to add extra results to be written to the time-stamped dataframe, which by default stores all metric values recorded over time. This is useful, for example, to monitor the inner state of a scheduler.
Downsampling of observed data for single-fidelity Bayesian optimization (#607)
Bayesian optimization computations scale cubically with the number of observations. You can now bound the maximum number of observations used in BO, using a combination of retaining the best metric values and random sampling.
Changes
🌟 New Features
- feat: Speculative early checkpoint removal for async multi-fidelity (#628) by @mseeger
- feat: simple linear scalarization scheduler (#619) by @jgolebiowski
- feat: automatic termination criterion (#605) by @aaronkl
- feat: All schedulers have a is_multiobjective_scheduler function (#618) by @jgolebiowski
- feat: Allow for customized extra results to be written to results.csv.zip (#612) by @mseeger
- feat: Plotting functions to analyse multi-objective experiments. (#611) by @jgolebiowski
- feat: Downsampling of observed data for single-fidelity Bayesian optimization (#607) by @mseeger
📜 Documentation Updates
- docs: update instructions for how to install from source (#629) by @wesk
- docs: Update README.md (#615) by @mseeger
🐛 Bugfixes
- fix: CI failing with
ModuleNotFoundError: No module named 'examples'error (#626) by @wesk - fix: call init of class (#584) by @aaronkl
- fix: Make sure that checkpoints in PBT are removed once they are no longer needed (#600) by @mseeger
- fix: random seed initialisation limited to int32 (#608) by @sighellan
- fix: Move utils from benchmarking to syne_tune, and update docs (#606) by @mseeger
🏗️ Code Refactoring
- refactor: Move early checkpoint removal into mixin (#621) by @mseeger
- refactor: Keep rung levels sorted in HyperbandScheduler (#604) by @mseeger
🔧 Maintenance
- chore: Bump codecov/codecov-action from 3.1.1 to 3.1.2 (#623) by @dependabot
- chore: Bump zgosalvez/github-actions-ensure-sha-pinned-actions from 2.1.0 to 2.1.2 (#624) by @dependabot
- chore: add release drafter automation (#568) by @wesk
- chore: Moved scheduler metadata generation (#617) by @jgolebiowski
- chore: Bump tensorflow from 2.11.0 to 2.11.1 in /examples/training_scripts/rl_cartpole (#609) by @dependabot
This release was made possible by the following contributors:
@aaronkl, @dependabot, @dependabot[bot], @jgolebiowski, @mseeger, @sighellan and @wesk
v0.4.1
1 year ago[0.4.1] - 2023-03-16
We release version 0.4.1 which you can install with pip install syne-tune[extra].
Thanks to all contributors: @mseeger, @wesk, @sighellan, @aaronkl, @wistuba, @jgolebiowski, @610v4nn1, @geoalgo
Added
- New tutorial: Using Syne Tune for Transfer Learning
- Multi-objective regularized evolution (MO-REA)
- Gaussian-process based methods support Box-Cox target transform and input warping
- Configuration can be passed as JSON file to evaluation script
- Remote tuning: Metrics are published to CloudWatch console
Changed
- Refactoring and cleanup of
benchmarking - FIFOScheduler supports multi-objective schedulers
- Remote tuning with local backend: Checkpoints are not synced to S3
- Code in documentation is now tested automatically
- Benchmarking: Use longer descriptive names for result directories
Fixed
- Specific state converter for DyHPO (can work poorly with the state converter for MOBSTER or Hyper-Tune)
- Fix of BOHB and SyncBOHB
- _objective_function parsing for YAHPO blackbox
v0.4.0
1 year ago[0.4.0] - 2023-02-21
We release version 0.4.0 which you can install with pip install syne-tune[extra].
Thanks to all contributors! @mseeger, @ondrejbohdal, @sighellan, @wistuba, @wesk, @jgolebiowski, @geoalgo, and @aaronkl
Added
- New HPO algorithm: DyHPO
- New tutorial: Progressive ASHA
- Extended developer tutorial: Wrapping external scheduler code
- Schedulers can be restricted to set of configurations as subset of the
full configuration space (option
restrict_configurations) - Data filtering for model-based multi-fidelity schedulers to avoid slowdown
(option
max_size_data_for_model) - Input warping for Gaussian process covariance kernels
- Allow searchers to return the same configuration more than once (option
allow_duplicates). Unify duplicate filtering across all searchers - Support
OrdinalandOrdinalNearestNeighborinactive_config_spaceand warmstarting
Changed
- Major simplifications in
benchmarking - Examples and documentation are encouraging to use
max_resource_attrinstead ofmax_t - Major refactoring and extensions in testing and CI pipeline
-
RemoteLauncherdoes not require custom container anymore
Fixed
-
TensorboardCallback: Logging of hyperparameters made optional, and updated example - Refactoring of
BoTorchSearcher - Default value for DEHB baseline fixed
- Number of GPUs is now determined correctly