Spiceai Versions Save
A unified SQL query interface and portable runtime to locally materialize, accelerate, and query datasets from any database, data warehouse, or data lake.
v0.6.1-alpha
2 years agoAnnouncing the release of Spice.ai v0.6.1-alpha! 🌶
Building upon the Apache Arrow support in v0.6-alpha, Spice.ai now includes new Apache Arrow data processor and Apache Arrow Flight data connector components! Together, these create a high-performance bulk-data transport directly into the Spice.ai ML engine. Coupled with big data systems from the Apache Arrow ecosystem like Hive, Drill, Spark, Snowflake, and BigQuery, it's now easier than ever to combine big data with Spice.ai.
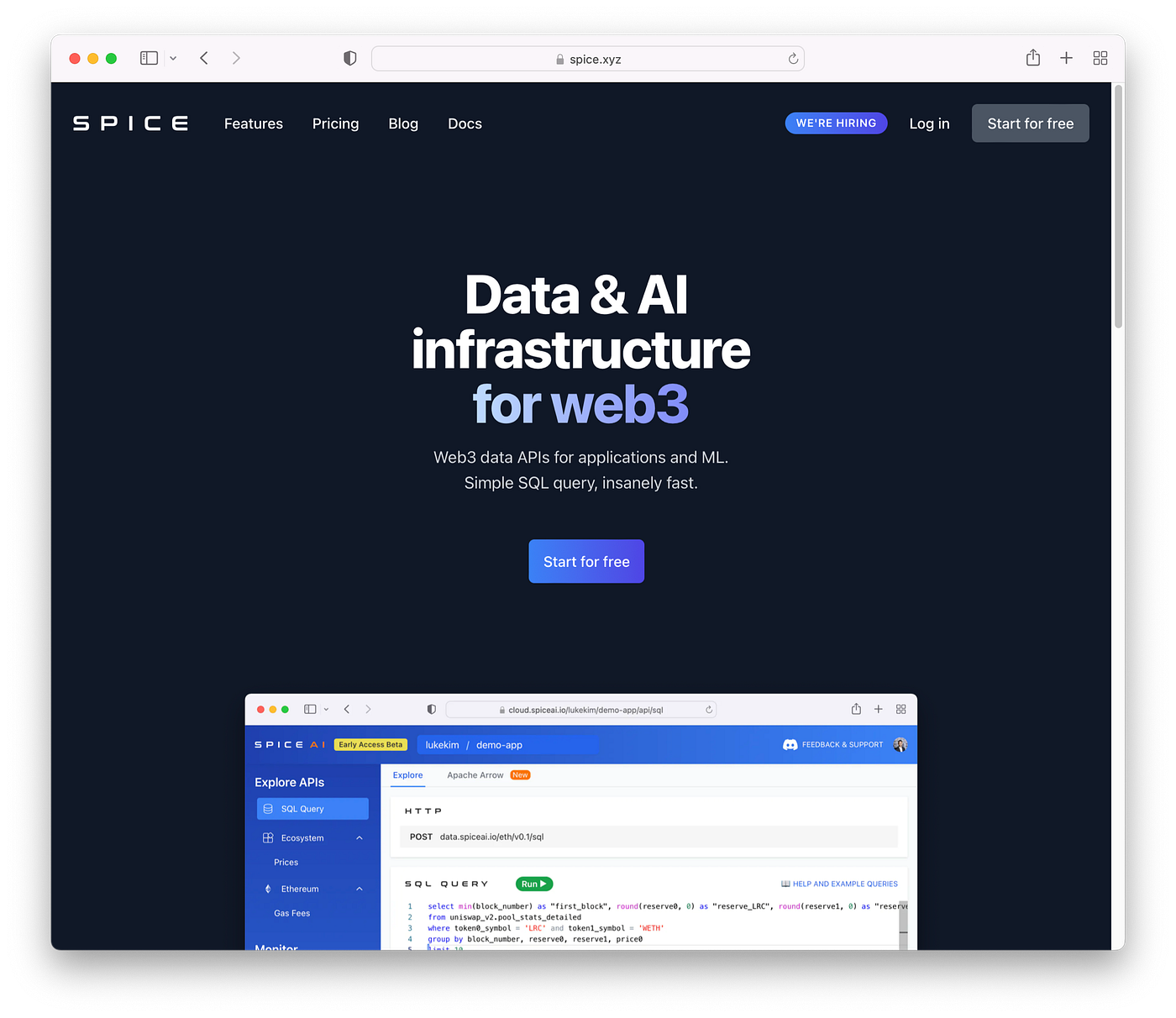
And we're also excited to announce the release of Spice.xyz! 🎉
Spice.xyz is data and AI infrastructure for web3. It’s web3 data made easy. Insanely fast and purpose designed for applications and ML.
Spice.xyz delivers data in Apache Arrow format, over high-performance Apache Arrow Flight APIs to your application, notebook, ML pipeline, and of course through these new data components, to the Spice.ai runtime.
Read the announcement post at blog.spice.ai.
New in this release
Now built with Go 1.18.
Dependency updates
- Updates to React 18
- Updates to CRA 5
- Updates to Glide DataGrid 4
- Updates to SWR 1.2
- Updates to TypeScript 4.6
v0.6-alpha
2 years agoAnnouncing the release of Spice.ai v0.6-alpha! 🏹
Spice.ai now scales to datasets 10-100 larger enabling new classes of uses cases and applications! 🚀 We've completely rebuilt Spice.ai's data processing and transport upon Apache Arrow, a high-performance platform that uses an in-memory columnar format. Spice.ai joins other major projects including Apache Spark, pandas, and InfluxDB in being powered by Apache Arrow. This also paves the way for high-performance data connections to the Spice.ai runtime using Apache Arrow Flight and import/export of data using Apache Parquet. We're incredibly excited about the potential this architecture has for building intelligent applications on top of a high-performance transport between application data sources the Spice.ai AI engine.

Highlights in v0.6-alpha
Massive improvement in data loading performance and dataset scale
From data connectors, to REST API, to AI engine, we've now rebuilt Spice.ai's data processing and transport on the Apache Arrow project. Specifically, using the Apache Arrow for Go implementation. Many thanks to Matt Topol for his contributions to the project and guidance on using it.
This release includes a change to the Spice.ai runtime to AI Engine transport from sending text CSV over gGPC to Apache Arrow Records over IPC (Unix sockets).
This is a breaking change to the Data Processor interface, as it now uses arrow.Record instead of Observation.
Benchmarking v0.6
Before v0.6, Spice.ai would not scale into the 100s of 1000s of rows.
| Format | Row Number | Data Size | Process Time | Load Time | Transport time | Memory Usage |
|---|---|---|---|---|---|---|
| csv | 2,000 | 163.15KiB | 3.0005s | 0.0000s | 0.0100s | 423.754MiB |
| csv | 20,000 | 1.61MiB | 2.9765s | 0.0000s | 0.0938s | 479.644MiB |
| csv | 200,000 | 16.31MiB | 0.2778s | 0.0000s | NA (error) | 0.000MiB |
| csv | 2,000,000 | 164.97MiB | 0.2573s | 0.0050s | NA (error) | 0.000MiB |
| json | 2,000 | 301.79KiB | 3.0261s | 0.0000s | 0.0282s | 422.135MiB |
| json | 20,000 | 2.97MiB | 2.9020s | 0.0000s | 0.2541s | 459.138MiB |
| json | 200,000 | 29.85MiB | 0.2782s | 0.0010s | NA (error) | 0.000MiB |
| json | 2,000,000 | 300.39MiB | 0.3353s | 0.0080s | NA (error) | 0.000MiB |
After building on Arrow, Spice.ai now easily scales beyond millions of rows.
| Format | Row Number | Data Size | Process Time | Load Time | Transport time | Memory Usage |
|---|---|---|---|---|---|---|
| csv | 2,000 | 163.14KiB | 2.8281s | 0.0000s | 0.0194s | 439.580MiB |
| csv | 20,000 | 1.61MiB | 2.7297s | 0.0000s | 0.0658s | 461.836MiB |
| csv | 200,000 | 16.30MiB | 2.8072s | 0.0020s | 0.4830s | 639.763MiB |
| csv | 2,000,000 | 164.97MiB | 2.8707s | 0.0400s | 4.2680s | 1897.738MiB |
| json | 2,000 | 301.80KiB | 2.7275s | 0.0000s | 0.0367s | 436.238MiB |
| json | 20,000 | 2.97MiB | 2.8284s | 0.0000s | 0.2334s | 473.550MiB |
| json | 200,000 | 29.85MiB | 2.8862s | 0.0100s | 1.7725s | 824.089MiB |
| json | 2,000,000 | 300.39MiB | 2.7437s | 0.0920s | 16.5743s | 4044.118MiB |
New in this release
- Adds Apache Arrow data processing and transport.
- Fixes TensorBoard logging and monitoring when using GitHub Codespaces and Docker.
- Adds Polling HTTP Data Connector
Dependency updates
- Updates to numpy 1.21.0
- Updates to marked 3.0.8
- Updates to follow-redirects 1.14.7
- Updates nanoid to 3.2.0
v0.5.1-alpha
2 years agoAnnouncing the release of Spice.ai v0.5.1-alpha! 📈
This minor release builds upon v0.5-alpha adding the ability to start training from the dashboard plus support for monitoring training runs with TensorBoard.
Highlights in v0.5.1-alpha
Start training from dashboard
A "Start Training" button has been added to the pod page on the dashboard so that you can easily start training runs from that context.
Training runs can now be started by:
- Modifications to the Spicepod YAML file.
- The spice train
command. - The "Start Training" dashboard button.
- POST API calls to
/api/v0.1/pods/{pod name}/train
Video: https://user-images.githubusercontent.com/80174/146122241-f8073266-ead6-4628-8563-93e98d74e9f0.mov
TensorBoard monitoring
TensorBoard monitoring is now supported when using DQL (default) or the new SACD learning algorithms that was announced in v0.5-alpha.
When enabled, TensorBoard logs will automatically be collected and a "Open TensorBoard" button will be shown on the pod page in the dashboard.
Logging can be enabled at the pod level with the training_loggers pod param or per training run with the CLI --training-loggers argument.
Video: https://user-images.githubusercontent.com/80174/146382503-2bb2570b-5111-4de0-9b80-a1dc4a5dcc35.mov
Support for VPG will be added in v0.6-alpha. The design allows for additional loggers to be added in the future. Let us know what you'd like to see!
New in this release
- Adds a start training button on the dashboard pod page.
- Adds TensorBoard logging and monitoring when using DQL and SACD learning algorithms.
Dependency updates
- Updates to Tailwind 3.0.6
- Updates to Glide Data Grid 3.2.1
v0.5-alpha
2 years agoWe are excited to announce the release of Spice.ai v0.5-alpha! 🥇
Highlights include a new learning algorithm called "Soft Actor-Critic" (SAC), fixes to the behavior of spice upgrade, and a more consistent authoring experience for reward functions.
If you are new to Spice.ai, check out the getting started guide and star spiceai/spiceai on GitHub.
Highlights in v0.5-alpha
Soft Actor-Critic (Discrete) (SAC) Learning Algorithm
The addition of the Soft Actor-Critic (Discrete) (SAC) learning algorithm is a significant improvement to the power of the AI engine. It is not set as the default algorithm yet, so to start using it pass the --learning-algorithm sacd parameter to spice train. We'd love to get your feedback on how its working!
Consistent reward authoring experience
With the addition of the reward function files that allow you to edit your reward function in a Python file, the behavior of starting a new training session by editing the reward function code was lost. With this release, that behavior is restored.
In addition, there is a breaking change to the variables used to access the observation state and interpretations. This change was made to better reflect the purpose of the variables and make them easier to work with in Python
| Previous (Type) | New (Type) |
|---|---|
prev_state (SimpleNamespace) |
current_state (dict) |
prev_state.interpretations (list) |
current_state_interpretations (list) |
new_state (SimpleNamespace) |
next_state (dict) |
new_state.interpretations (list) |
next_state_interpretations (list) |
Improved spice upgrade behavior
The Spice.ai CLI will no longer recommend "upgrading" to an older version. An issue was also fixed where trying to upgrade the Spice.ai CLI using spice upgrade on Linux would return an error.
New in this release
- Adds a new learning algorithm called "Soft-Actor Critic (Discrete)" (SAC).
-
Updates the reward function parameters for the YAML code blocks from
prev_stateandnew_statetocurrent_stateandnext_stateto be consistent with the reward function files. - Fixes an issue where editing a reward functions file would not automatically trigger training.
- Fixes the normalization of values for the Deep-Q Learning algorithm to handle larger values.
-
Fixes an issue where the Spice.ai CLI would not upgrade on Linux with the
spice upgradecommand. - Fixes an issue where the Spice.ai CLI would recommend an "upgrade" to an older version.
v0.4.1-alpha
2 years agoAnnouncing the release of Spice.ai v0.4.1-alpha! ✅
This point release focuses on fixes and improvements to v0.4-alpha. Highlights include AI engine performance improvements, updates to the dashboard observations data grid, notification of new CLI versions, and several bug fixes.
A special acknowledgment to @Adm28, who added the CLI upgrade detection and prompt, which notifies users of new CLI versions and prompts to upgrade.

Highlights in v0.4.1-alpha
AI engine performance improvements
Overall training performance has been improved up to 13% by removing a lock in the AI engine.
In versions before v0.4.1-alpha, performance was especially impacted when streaming new data during a training run.
Dashboard Observations Datagrid
The dashboard observations datagrid now automatically resizes to the window width, and headers are easier to read, with automatic grouping into dataspaces. In addition, column widths are also resizable.
CLI version detection and upgrade prompt
When it is run, the Spice.ai CLI will now automatically check for new CLI versions once a day maximum.
If it detects a new version, it will print a notification to the console on spice version, spice run or spice add commands prompting the user to upgrade using the new spice upgrade command.
New in this release
- Adds automatic resizing of the observations datagrid.
- Adds header group by dataspace to the observations datagrid.
- Adds CLI version detection and prompt for upgrade on version, run, and add commands.
-
Adds Support for parsing hex-encoded times and measurements. Use the
time_formatofhexor prefix with0x. - Updates AI engine with improved training performance.
- Updates Go and NPM dependencies.
-
Fixes detection of Spicepods in the
Spicepodsdirectory, and a resulting error when loading a non-Spicepod file. - Fixes a potential "zip slip" security issue.
- Fixes an issue where the AI engine may not gracefully shutdown.
v0.4-alpha
2 years agoWe are excited to announce the release of Spice.ai v0.4-alpha! 🏄♂️
Highlights include support for authoring reward functions in a code file, the ability to specify the time of recommendation, and ingestion support for transaction/correlation ids. Authoring reward functions in a code file is a significant improvement to the developer experience than specifying functions inline in the YAML manifest, and we are looking forward to your feedback on it!
If you are new to Spice.ai, check out the getting started guide and star spiceai/spiceai on GitHub.
Highlights in v0.4-alpha
Upgrade using spice upgrade
The spice upgrade command was added in the v0.3.1-alpha release, so you can now upgrade from v0.3.1 to v0.4 by simply running spice upgrade in your terminal. Special thanks to community member @Adm28 for contributing this feature!
Reward Function Files
In addition to defining reward code inline, it is now possible to author reward code in functions in a separate Python file.
The reward function file path is defined by the reward_funcs property.
A function defined in the code file is mapped to an action by authoring its name in the with property of the relevant reward.
Example:
training:
reward_funcs: my_reward.py
rewards:
- reward: buy
with: buy_reward
- reward: sell
with: sell_reward
- reward: hold
with: hold_reward
Learn more in the documentation: docs.spiceai.org/concepts/rewards/external
Time Categories
Spice.ai can now learn from cyclical patterns, such as daily, weekly, or monthly cycles.
To enable automatic cyclical field generation from the observation time, specify one or more time categories in the pod manifest, such as a month or weekday in the time section.
For example, by specifying month the Spice.ai engine automatically creates a field in the AI engine data stream called time_month_{month} with the value calculated from the month of which that timestamp relates.
Example:
time:
categories:
- month
- dayofweek
Supported category values are:
month dayofmonth dayofweek hour
Learn more in the documentation: docs.spiceai.org/reference/pod/#time
Get recommendation for a specific time
It is now possible to specify the time of recommendations fetched from the /recommendation API.
Valid times are from pod epoch_time to epoch_time + period.
Previously the API only supported recommendations based on the time of the last ingested observation.
Requests are made in the following format: GET http://localhost:8000/api/v0.1/pods/{pod}/recommendation?time={unix_timestamp}`
An example for quickstarts/trader
GET http://localhost:8000/api/v0.1/pods/trader/recommendation?time=1605729600
Specifying {unix_timestamp} as 0 will return a recommendation based on the latest data. An invalid {unix_timestamp} will return a result that has the valid time range in the error message:
{
"response": {
"result": "invalid_recommendation_time",
"message": "The time specified (1610060201) is outside of the allowed range: (1610057600, 1610060200)",
"error": true
}
}
New in this release
- Adds time categories configuration to the pod manifest to enable learning from cyclical patterns in data - e.g. hour, day of week, day of month, and month
- Adds support for defining reward functions in a rewards functions code file.
- Adds the ability to specify recommendation time making it possible to now see which action Spice.ai recommends at any time during the pod period.
-
Adds support for ingestion of transaction/correlation identifiers (e.g.
order_id,trace_id) in the pod manifest. - Adds validation for invalid dataspace names in the pod manifest.
- Adds the ability to resize columns to the dashboard observation data grid.
- Updates to TensorFlow 2.7 and Keras 2.7
- Fixes a bug where data processors were using data connector params
- Fixes a dashboard issue in the pod observations data grid where a column might not be shown.
-
Fixes a crash on pod load if the
trainingsection is not included in the manifest. - Fixes an issue where data manager stats errors were incorrectly being printed to console.
- Fixes an issue where selectors may not match due to surrounding whitespace.
v0.3.1-alpha
2 years agoWe are excited to announce the release of Spice.ai v0.3.1-alpha! 🎃
This point release focuses on fixes and improvements to v0.3-alpha. Highlights include the ability to specify both seed and runtime data, to select custom named fields for time and tags, a new spice upgrade command and several bug fixes.
A special acknowledgment to @Adm28, who added the new spice upgrade command, which enables the CLI to self-update, which in turn will auto-update the runtime.
Highlights in v0.3.1-alpha
Upgrade command
The CLI can now be updated using the new spice upgrade command. This command will check for, download, and install the latest Spice.ai CLI release, which will become active on it's next run.
When run, the CLI will check for the matching version of the Spice.ai runtime, and will automatically download and install it as necessary.
The version of both the Spice.ai CLI and runtime can be checked with the spice version CLI command.
Seed data
When working with streaming data sources, like market prices, it's often also useful to seed the dataspace with historical data. Spice.ai enables this with the new seed_data node in the dataspace configuration. The syntax is exactly the same as the data syntax. For example:
dataspaces:
- from: coinbase
name: btcusd
seed_data:
connector: file
params:
path: path/to/seed/data.csv
processor:
name: csv
data:
connector: coinbase
params:
product_ids: BTC-USD
processor:
name: json
The seed data will be fetched first, before the runtime data is initialized. Both sets of connectors and processors use the dataspace scoped measurements, categories and tags for processing, and both data sources are merged in pod-scoped observation timeline.
Time field selectors
Before v0.3.1-alpha, data was required to include a specific time field. In v0.3.1-alpha, the JSON and CSV data processors now support the ability to select a specific field to populate the time field. An example selector to use the created_at column for time is:
data:
processor:
name: csv
params:
time_selector: created_at
Tag field selectors
Before v0.3.1-alpha, tags were required to be placed in a _tags field. In v0.3.1-alpha, any field can now be selected to populate tags. Tags are pod-unique string values, and the union of all selected fields will make up the resulting tag list. For example:
dataspace:
from: twitter
name: tweets
tags:
selectors:
- tags
- author_id
values:
- spiceaihq
- spicy
New in this release
-
Adds a new
spice upgradecommand for self-upgrade of the Spice.ai CLI. -
Adds a new
seed_datanode to the dataspace configuration, enabling the dataspace to be seeded with an alternative source of data. -
Adds the ability to select a custom time field in JSON and CSV data processors with the
time_selectorparameter. -
Adds the ability to select custom tag fields in the dataspace configuration with
selectorslist. - Adds error reporting for AI engine crashes, where previously it would fail silently.
- Fixes the dashboard pods list from "jumping" around due to being unsorted.
- Fixes rare cases where categorical data might be sent to the AI engine in the wrong format.
v0.3-alpha
2 years agoSpice.ai v0.3-alpha
We are excited to announce the release of Spice.ai v0.3-alpha! 🎉
This release adds support for ingestion, automatic encoding, and training of categorical data, enabling more use-cases and datasets beyond just numerical measurements. For example, perhaps you want to learn from data that includes a category of t-shirt sizes, with discrete values, such as small, medium, and large. The v0.3 engine now supports this and automatically encodes the categorical string values into numerical values that the AI engine can use. Also included is a preview of data visualizations in the dashboard, which is helpful for developers as they author Spicepods and dataspaces.
A special acknowledgment to @sboorlagadda, who submitted the first Spice.ai feature contribution from the community ever! He added the ability to list pods from the CLI with the new spice pods list command. Thank you, @sboorlagadda!!!
If you are new to Spice.ai, check out the getting started guide and star spiceai/spiceai on GitHub.
Highlights in v0.3-alpha
Categorical data
In v0.1, the runtime and AI engine only supported ingesting numerical data. In v0.2, tagged data was accepted and automatically encoded into fields available for learning. In this release, v0.3, categorical data can now also be ingested and automatically encoded into fields available for learning. This is a breaking change with the format of the manifest changing separating numerical measurements and categorical data.
Pre-v0.3, the manifest author specified numerical data using the fields node.
In v0.3, numerical data is now specified under measurements and categorical data under categories. E.g.
dataspaces:
- from: event
name: stream
measurements:
- name: duration
selector: length_of_time
fill: none
- name: guest_count
selector: num_guests
fill: none
categories:
- name: event_type
values:
- dinner
- party
- name: target_audience
values:
- employees
- investors
tags:
- tagA
- tagB
Data visualizations preview
A top piece of community feedback was the ability to visualize data. After first running Spice.ai, we'd often hear from developers, "how do I see the data?". A preview of data visualizations is now included in the dashboard on the pod page.
Listing pods
Once the Spice.ai runtime has started, you can view the loaded pods on the dashboard and fetch them via API call localhost:8000/api/v0.1/pods. To make it even easier, we've added the ability to list them via the CLI with the new spice pods list command, which shows the list of pods and their manifest paths.
Coinbase data connector
A new Coinbase data connector is included in v0.3, enabling the streaming of live market ticker prices from Coinbase Pro. Enable it by specifying the coinbase data connector and providing a list of Coinbase Pro product ids. E.g. "BTC-USD". A new sample which demonstrates is also available with its associated Spicepod available from the spicerack.org registry. Get it with spice add samples/trader.
Tweet Recommendation Quickstart
A new Tweet Recommendation Quickstart has been added. Given past tweet activity and metrics of a given account, this app can recommend when to tweet, comment, or retweet to maximize for like count, interaction rates, and outreach of said given Twitter account.
Trader Sample
A new Trader Sample has been added in addition to the Trader Quickstart. The sample uses the new Coinbase data connector to stream live Coinbase Pro ticker data for learning.
New in this release
- Adds support for ingesting, encoding, and training on categorical data. v0.3 uses one-hot-encoding.
- Changes Spicepod manifest fields node to measurements and add the categories node.
- Adds the ability to select a field from the source data and map it to a different field name in the dataspace. See an example for measurements in docs.
-
Adds support for JSON content type when fetching from the
/observationsAPI. Previously, only CSV was supported. - Adds a preview version of data visualizations to the dashboard. The grid has several limitations, one of which is it currently cannot be resized.
- Adds the ability to select which learning algorithm to use via the CLI, the API, and specified in the Spicepod manifest. Possible choices are currently "vpg", Vanilla Policy Gradient and "dql", Deep Q-Learning. Shout out to @corentin-pro, who added this feature on his second day on the team!
- Adds the ability to list loaded pods with the CLI command spice pods list.
- Adds a new coinbase data connector for Coinbase Pro market prices.
- Adds a new Tweet Recommendation Quickstart.
- Adds a new Trader Sample.
-
Fixes bug where the
/observationsendpoint was not providing fully qualified field names. - Fixes issue where debugging messages were printed when using spice add.
v0.3-alpha-rc
2 years agoThis is the release candidate 0.3-alpha-rc
v0.2.1-alpha
2 years agoSpice.ai v0.2.1-alpha
Announcing the release of Spice.ai v0.2.1-alpha! 🚚
This point release focuses on fixes and improvements to v0.2-alpha. Highlights include the ability to specify how missing data should be treated and a new production mode for spiced.
This release supports the ability to specify how the runtime should treat missing data. Previous releases filled missing data with the last value (or initial value) in the series. While this makes sense for some data, i.e., market prices of a stock or cryptocurrency, it does not make sense for discrete data, i.e., ratings. In v0.2.1, developers can now add the fill parameter on a dataspace field to specify the behavior. This release supports fill types previous and none. The default is previous.
Example in a manifest:
dataspaces:
- from: twitter
name: tweets
fields:
- name: likes
fill: none # The new fill parameter
spiced now defaults to a new production mode when run standalone (not via the CLI), with development mode now explicitly set with the --development flag. Production mode does not activate development time features, such as the Spicepod file watcher. The CLI always runs spiced in development mode as it is not expected to be used in production deployments.
New in this release
-
Adds a
fillparameter to dataspace fields to specify how missing values should be treated. - Adds the ability to specify the fill behavior of empty values in a dataspace.
-
Simplifies releases with a single
spiceairelease instead of separatespiceandspicedreleases. -
Adds an explicit development mode to
spiced. Production mode does not activate the file watcher. -
Fixes a bug when the pod parameter
epoch_timewas not set which would cause data not to be sent to the AI engine. - Fixes a bug where the User-Agent was not set correctly from CLI calls to api.spicerack.org