Spiceai Versions Save
A unified SQL query interface and portable runtime to locally materialize, accelerate, and query data tables sourced from any database, data warehouse, or data lake.
v0.10.1-alpha
3 weeks agoThe v0.10.1-alpha release focuses on stability, bug fixes, and usability by improving error messages when using SQLite data accelerators, improving the PostgreSQL support, and adding a basic Helm chart.
Highlights in v0.10.1-alpha
Improved PostgreSQL support for Data Connectors TLS is now supported with PostgreSQL Data Connectors and there is improved VARCHAR and BPCHAR conversions through Spice.
Improved Error messages Simplified error messages from Spice when propagating errors from Data Connectors and Accelerator Engines.
Spice Pods Command The spice pods command can give you quick statistics about models, dependencies, and datasets that are loaded by the Spice runtime.
Contributors
- @phillipleblanc
- @mitchdevenport
- @ewgenius
- @sgrebnov
- @lukekim
- @digadeesh
New in this release
- Adds Basic Helm Chart for spiceai (https://github.com/spiceai/spiceai/pull/1002)
-
Adds Support for
spice loginin environments with no browser. (https://github.com/spiceai/spiceai/pull/994) - Adds TLS support in Postgres connector. (https://github.com/spiceai/spiceai/pull/970)
- Fixes Improve Postgres VARCHAR and BPCHAR conversion. (https://github.com/spiceai/spiceai/pull/993)
-
Fixes
spice podsReturns incorrect counts. (https://github.com/spiceai/spiceai/pull/998) - Fixes Return friendly error messages for unsupported types in sqlite. (https://github.com/spiceai/spiceai/pull/982)
- Fixes Pass Tonic errors when receiving errors from dependencies. (https://github.com/spiceai/spiceai/pull/995)
v0.10.0-alpha
4 weeks agoAnnouncing the release of Spice.ai v0.10-alpha! 🎉
The Spice.ai v0.10-alpha release focused on additions and updates to improve stability, usability, and the overall Spice developer experience.
Highlights in v0.10-alpha
Public Bucket Support for S3 Data Connector: The S3 Data Connector now supports public buckets in addition to buckets requiring an access id and key.
JDBC-Client Connectivity: Improved connectivity for JDBC clients, like Tableau.
User Experience Improvements:
- Friendlier error messages across the board to make debugging and development better.
- Added a
spice login postgrescommand, streamlining the process for connecting to PostgreSQL databases. - Added PostgreSQL connection verification and connection string support, enhancing usability for PostgreSQL users.
Grafana Dashboard: Improving the ability to monitor Spice deployments, a standard Grafana dashboard is now available.
Contributors
- @phillipleblanc
- @mitchdevenport
- @Jeadie
- @ewgenius
- @sgrebnov
- @y-f-u
- @lukekim
- @digadeesh
New in this release
- Fixes Gracefully handle Arrow Flight DoExchange connection resets
- Adds Grafana Dashboard
- Adds Flight SQL CommandGetTableTypes Command support (improves JDBC-client connectivity)
- Adds Friendlier error messages
-
Adds
spice login postgrescommand - Adds PostgreSQL connection verification
- Adds PostgreSQL connection string support
- Adds Linux aarch64 build
-
Updates Improves
spice statuswith dataset metrics -
Updates CLI REPL improved
show tablesoutput - Updates CLI REPL limit output to 500 rows
- Updates Improved README.md with architecture diagram updates
- Updates Improved CI run time.
- Updates Use macOS hosted Actions runner
v0.9.1-alpha
4 weeks agoThe v0.9.1 release focused on stability, bug fixes, and usability by adding spice CLI commands for listing Spicepods (spice pods), Models (spice models), Datasets (spice datasets), and improved status (spice status) details. In addition, the Arrow Flight SQL (flightsql) data connector and SQLite (sqlite) data store were added.
Highlights in v0.9.1-alpha
FlightSQL data connector: Arrow Flight SQL can now be used as a connector for federated SQL query.
SQLite data backend: SQLite can now be used as a data store for acceleration.
Contributors
- @phillipleblanc
- @mitchdevenport
- @Jeadie
- @ewgenius
- @sgrebnov
- @y-f-u
- @lukekim
New in this release
-
Adds FlightSQL data connector (
flightsql). -
Adds SQLite data store, supports both in-memory and file based (
sqlite). - Adds support for date, varchar, bpchar, and primitive list types for the PostgreSQL data connector and data store.
-
Adds
spice pods,spice status,spice datasets, andspice modelsCLI commands. -
Adds
GET /v1/spicepodsAPI for listing loaded Spicepods. -
Adds
spicedDocker CI build and release. - Adds E2E tests for release installation and local acceleration.
- Adds E2E tests and instructions to run basic TPC-H benchmark tests.
-
Adds
linux/arm64binary build. -
Fixes
spice sqlREPL panics when query result is too large. (https://github.com/spiceai/spiceai/pull/875) -
Fixes
--access-secretinspice s3 login. (https://github.com/spiceai/spiceai/pull/894) - Fixes version check upgrade logic.
v0.9-alpha
1 month agoThe v0.9 release adds several data connectors including the Spice data connector for the ability to connect to other spiced instances. Improved observability for spiced has been added with the new /metrics endpoint for monitoring deployed instances.
Highlights in v0.9-alpha
Arrow Flight SQL endpoint: The Arrow Flight endpoint now supports Flight SQL, including JDBC, ODBC, and ADBC enabling database clients like DBeaver or BI applications like Tableau to connect to and query the Spice runtime.
Spice.ai data connector: Use other Spice runtime instances as data connectors for federated SQL query across Spice deployments and for chaining Spice runtimes.
Keyring secret store: Use the operating system native credential store, like macOS keychain for storing secrets used by spiced.
PostgreSQL data connector: PostgreSQL can now be used as both a data store for acceleration and as a connector for federated SQL query.
Databricks data connector: Databricks as a connector for federated SQL query across Delta Lake tables.
S3 data connector: S3 as a connector for federated SQL query across Parquet files stored in S3.
Metrics endpoint: Added new /metrics endpoint for spiced observability and monitoring with the following metrics:
- spiced_runtime_http_server_start counter
- spiced_runtime_flight_server_start counter
- datasets_count gauge
- load_dataset summary
- load_secrets summary
- datasets/load_error counter
- datasets/count counter
- models/load_error counter
- models/count counter
Contributors
- @phillipleblanc
- @mitchdevenport
- @Jeadie
- @ewgenius
- @sgrebnov
- @Sevenannn
- @y-f-u
- @digadeesh
- @lukekim
New in this release
-
Adds Keyring secret store (
keyring). -
Adds PostgreSQL data connector (
postgres). -
Adds Spice.ai data connector (
spiceai). - Adds Arrow Flight SQL (JDBC/ODBC/ADBC) support.
-
Adds Databricks data connector (
databricks) - Delta Lake support. -
Adds S3 data connector (
s3) - Parquet support. -
Adds
/v1/modelsAPI. -
Adds
/v1/statusAPI. -
Adds
/metricsAPI.
v0.8-alpha
1 month agoAnnouncing the release of Spice v0.8-alpha! 🏹
This is a minor release that builds on the new Rust-based runtime, adding stability and a preview of new features for the first major release.
Highlights in v0.8-alpha
Secrets management: Spice 0.8 runtime can now configure and retrieve secrets from local environment variables and in a Kubernetes cluster.
Data tables can be locally accelerated using PostgreSQL
New in this release
- Adds Secrets management in local environment variables and Kubernetes clusters.
- Adds (Preview) PostgreSQL as a data table acceleration engine.
v0.7-alpha
2 months agoAnnouncing the release of Spice v0.7-alpha! 🏹
Spice v0.7-alpha is an all new implementation of Spice written in Rust. The Spice v0.7 runtime provides developers with a unified SQL query interface to locally accelerate and query data tables sourced from any database, data warehouse, or data lake.
Learn more and get started in minutes with the updated Quickstart in the repository README!
Highlights in v0.7-alpha
DataFusion SQL Query Engine: Spice v0.7 leverages the Apache DataFusion query engine to provide very fast, high quality SQL query across one or more local or remote data sources.
Data tables can be locally accelerated using Apache Arrow in-memory or by DuckDB.
New in this release
- Adds runtime rewritten in Rust for high-performance.
- Adds Apache DataFusion SQL query engine.
- Adds The Spice.ai platform as a data source.
- Adds Dremio as a data source.
- Adds OpenTelemetry (OTEL) collector.
- Adds local data table acceleration.
- Adds DuckDB file or in-memory as a data table acceleration engine.
- Adds In-memory Apache Arrow as a data table acceleration engine.
- Removes the built-in AI training engine; now cloud-based and provided by the Spice.ai platform.
- Removes the built-in dashboard and web-interface; now cloud-based and provided by the Spice.ai platform.
v0.6.2-alpha
9 months agoAnnouncing the release of Spice.ai v0.6.2-alpha! 🐞
This release fixes a bug in the CLI that prevented users from adding Spicepods from spicerack.org
v0.6.1-alpha
2 years agoAnnouncing the release of Spice.ai v0.6.1-alpha! 🌶
Building upon the Apache Arrow support in v0.6-alpha, Spice.ai now includes new Apache Arrow data processor and Apache Arrow Flight data connector components! Together, these create a high-performance bulk-data transport directly into the Spice.ai ML engine. Coupled with big data systems from the Apache Arrow ecosystem like Hive, Drill, Spark, Snowflake, and BigQuery, it's now easier than ever to combine big data with Spice.ai.
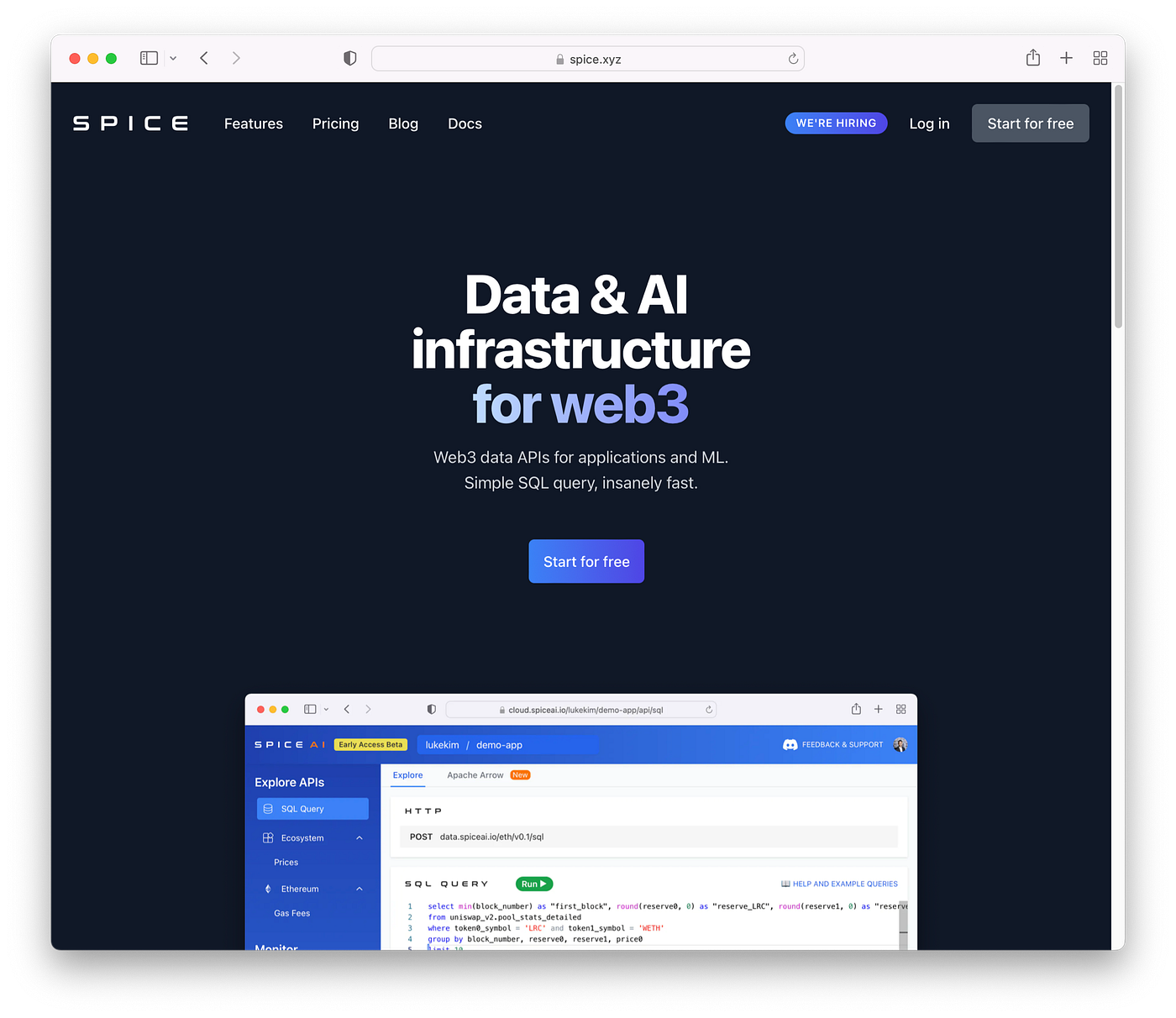
And we're also excited to announce the release of Spice.xyz! 🎉
Spice.xyz is data and AI infrastructure for web3. It’s web3 data made easy. Insanely fast and purpose designed for applications and ML.
Spice.xyz delivers data in Apache Arrow format, over high-performance Apache Arrow Flight APIs to your application, notebook, ML pipeline, and of course through these new data components, to the Spice.ai runtime.
Read the announcement post at blog.spice.ai.
New in this release
Now built with Go 1.18.
Dependency updates
- Updates to React 18
- Updates to CRA 5
- Updates to Glide DataGrid 4
- Updates to SWR 1.2
- Updates to TypeScript 4.6
v0.6-alpha
2 years agoAnnouncing the release of Spice.ai v0.6-alpha! 🏹
Spice.ai now scales to datasets 10-100 larger enabling new classes of uses cases and applications! 🚀 We've completely rebuilt Spice.ai's data processing and transport upon Apache Arrow, a high-performance platform that uses an in-memory columnar format. Spice.ai joins other major projects including Apache Spark, pandas, and InfluxDB in being powered by Apache Arrow. This also paves the way for high-performance data connections to the Spice.ai runtime using Apache Arrow Flight and import/export of data using Apache Parquet. We're incredibly excited about the potential this architecture has for building intelligent applications on top of a high-performance transport between application data sources the Spice.ai AI engine.

Highlights in v0.6-alpha
Massive improvement in data loading performance and dataset scale
From data connectors, to REST API, to AI engine, we've now rebuilt Spice.ai's data processing and transport on the Apache Arrow project. Specifically, using the Apache Arrow for Go implementation. Many thanks to Matt Topol for his contributions to the project and guidance on using it.
This release includes a change to the Spice.ai runtime to AI Engine transport from sending text CSV over gGPC to Apache Arrow Records over IPC (Unix sockets).
This is a breaking change to the Data Processor interface, as it now uses arrow.Record instead of Observation.
Benchmarking v0.6
Before v0.6, Spice.ai would not scale into the 100s of 1000s of rows.
| Format | Row Number | Data Size | Process Time | Load Time | Transport time | Memory Usage |
|---|---|---|---|---|---|---|
| csv | 2,000 | 163.15KiB | 3.0005s | 0.0000s | 0.0100s | 423.754MiB |
| csv | 20,000 | 1.61MiB | 2.9765s | 0.0000s | 0.0938s | 479.644MiB |
| csv | 200,000 | 16.31MiB | 0.2778s | 0.0000s | NA (error) | 0.000MiB |
| csv | 2,000,000 | 164.97MiB | 0.2573s | 0.0050s | NA (error) | 0.000MiB |
| json | 2,000 | 301.79KiB | 3.0261s | 0.0000s | 0.0282s | 422.135MiB |
| json | 20,000 | 2.97MiB | 2.9020s | 0.0000s | 0.2541s | 459.138MiB |
| json | 200,000 | 29.85MiB | 0.2782s | 0.0010s | NA (error) | 0.000MiB |
| json | 2,000,000 | 300.39MiB | 0.3353s | 0.0080s | NA (error) | 0.000MiB |
After building on Arrow, Spice.ai now easily scales beyond millions of rows.
| Format | Row Number | Data Size | Process Time | Load Time | Transport time | Memory Usage |
|---|---|---|---|---|---|---|
| csv | 2,000 | 163.14KiB | 2.8281s | 0.0000s | 0.0194s | 439.580MiB |
| csv | 20,000 | 1.61MiB | 2.7297s | 0.0000s | 0.0658s | 461.836MiB |
| csv | 200,000 | 16.30MiB | 2.8072s | 0.0020s | 0.4830s | 639.763MiB |
| csv | 2,000,000 | 164.97MiB | 2.8707s | 0.0400s | 4.2680s | 1897.738MiB |
| json | 2,000 | 301.80KiB | 2.7275s | 0.0000s | 0.0367s | 436.238MiB |
| json | 20,000 | 2.97MiB | 2.8284s | 0.0000s | 0.2334s | 473.550MiB |
| json | 200,000 | 29.85MiB | 2.8862s | 0.0100s | 1.7725s | 824.089MiB |
| json | 2,000,000 | 300.39MiB | 2.7437s | 0.0920s | 16.5743s | 4044.118MiB |
New in this release
- Adds Apache Arrow data processing and transport.
- Fixes TensorBoard logging and monitoring when using GitHub Codespaces and Docker.
- Adds Polling HTTP Data Connector
Dependency updates
- Updates to numpy 1.21.0
- Updates to marked 3.0.8
- Updates to follow-redirects 1.14.7
- Updates nanoid to 3.2.0
v0.5.1-alpha
2 years agoAnnouncing the release of Spice.ai v0.5.1-alpha! 📈
This minor release builds upon v0.5-alpha adding the ability to start training from the dashboard plus support for monitoring training runs with TensorBoard.
Highlights in v0.5.1-alpha
Start training from dashboard
A "Start Training" button has been added to the pod page on the dashboard so that you can easily start training runs from that context.
Training runs can now be started by:
- Modifications to the Spicepod YAML file.
- The spice train
command. - The "Start Training" dashboard button.
- POST API calls to
/api/v0.1/pods/{pod name}/train
Video: https://user-images.githubusercontent.com/80174/146122241-f8073266-ead6-4628-8563-93e98d74e9f0.mov
TensorBoard monitoring
TensorBoard monitoring is now supported when using DQL (default) or the new SACD learning algorithms that was announced in v0.5-alpha.
When enabled, TensorBoard logs will automatically be collected and a "Open TensorBoard" button will be shown on the pod page in the dashboard.
Logging can be enabled at the pod level with the training_loggers pod param or per training run with the CLI --training-loggers argument.
Video: https://user-images.githubusercontent.com/80174/146382503-2bb2570b-5111-4de0-9b80-a1dc4a5dcc35.mov
Support for VPG will be added in v0.6-alpha. The design allows for additional loggers to be added in the future. Let us know what you'd like to see!
New in this release
- Adds a start training button on the dashboard pod page.
- Adds TensorBoard logging and monitoring when using DQL and SACD learning algorithms.
Dependency updates
- Updates to Tailwind 3.0.6
- Updates to Glide Data Grid 3.2.1