Snakers4 Mnasnet Pytorch Save Abandoned
A PyTorch implementation of MNASNET
Training your own MNASNET

Motivation
We tried implementing the MNASNET network from this paper from scratch - and failed to achieve the claimed accuracy with the methods we used. Hm, probably this is the reason why in Cadene's repository the NASNET-mobile is just ported from TF? Well, it is good to know that training networks on ImageNet is not as easy as it sounds).
Even though we failed to achieve the claimed 75-76% top1 accuracy on MNASNET, we believe that most likely is is with the way it is supposed (?) to be trained. In our experience with various training regimes, the networks just seemed to have peaked at around 35-40% top accuracy. Also maybe we should have waited longer than 15-30 ImageNET epochs to confirm that the training stalled, but who knows.
The thing is, Google in its paper claims to have used:
- RMSPROP as optimizer;
- Very peculiar settings for Batch-normalization layers;
- Some warmup schedule with high initial LR;
- The paper is a bit vague on a number of subjects:
- The initial version of the paper did not mention the use of activation layers (like RELU). Authors clarified that this was an error / omission;
- The exact design of FC + Pooling. The authors clarified that they just used average pooling;
- The network as depicted on the image above will not work - you will have to add some downsampling layers;
But I have never seen people, who used RMSPROP with success. Also talking to a friend, who successfully trained MobileNet 1 and 2, he mostly said that:
- ADAM and SGD both work with some form of decay;
- They both converge. but ADAM performs a few p.p. worse than SGD, though converging much faster;
- Typically it takes ~150-200 epochs on ImageNet to converge;
- They used large (1000-2000) batch-sizes on 6 GPUs;
See his training log for yourself:
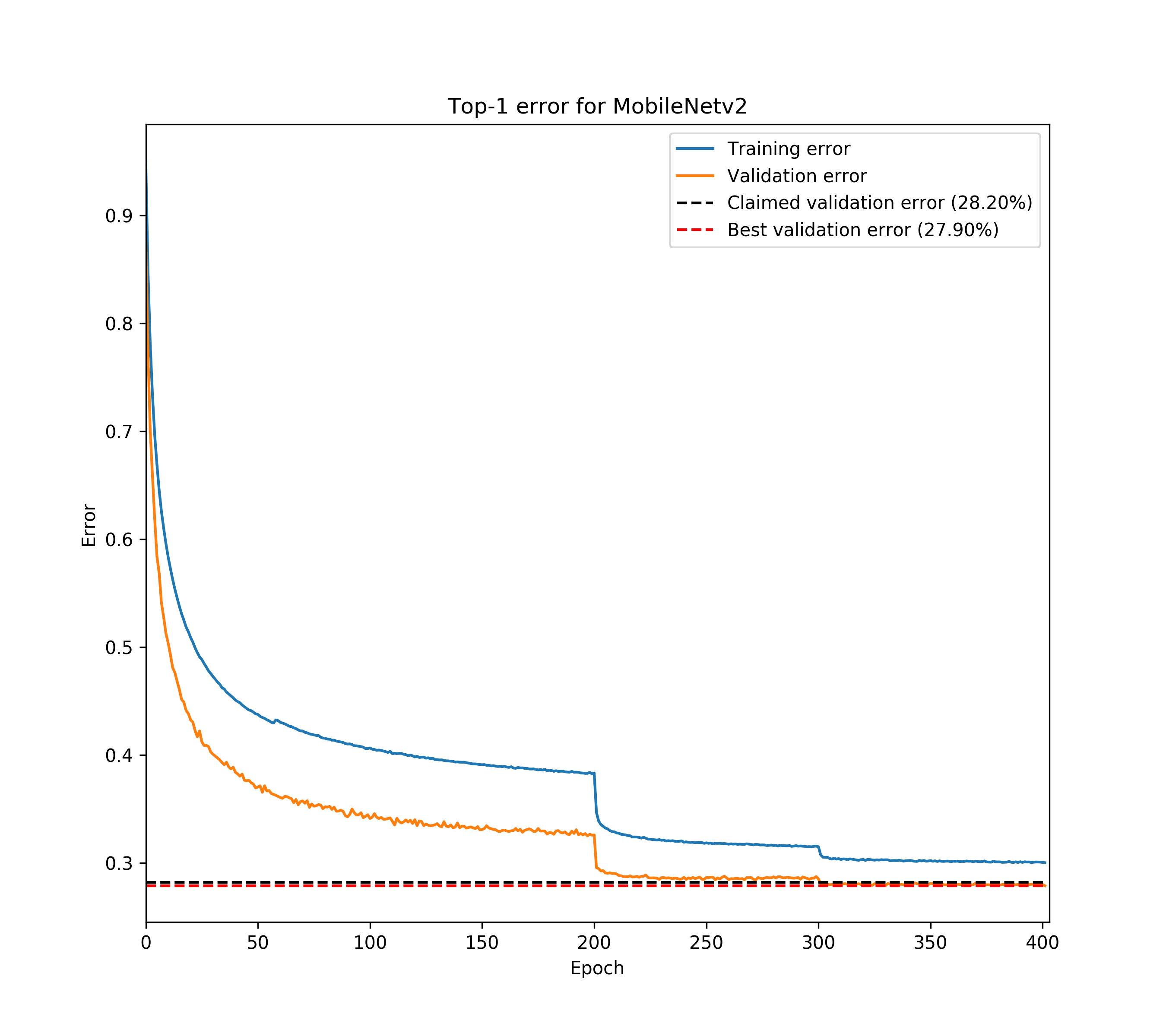
What we tried and learned
What we learned:
- Training heavily optimized networks on ImageNet from scratch is trickier than it sounds;
- Adam and SGD both work, ADAM converges much faster. But it our case we could not achieve 75-76%, so all of this is kind of relative;
- Training with progressively growing image-size worked a bit better than just training with standard image size from scratch;
- Training with RandomResized crops works otherwise the network overfits heavily;
- Just using Pooling + one FC layer in our case resulted in heavy overfitting;
- Training on larger size images from scratch does not work (looks like the network is heavily optimized for 224x224);
- Removing the bottle-neck (at first we used
320->512->256->1000) in the FC layers did no help; - I was able to get ~35-40% accuracy tops on validation with various runs;
Some of our best runs
Note that in this case 1 epoch = 0.2 epochs on fill ImageNET.

What to watch out for
The paper was a bit vague on:
- Using activations;
- Down-sizing your activation maps - exactly when - either at the beginning of the module or at the end;
- Batch-size;
- Google's training regime is peculiar;
- Using their batch-norm settings probably has something to do with RMSPROP;
Reuse our code!
This code may shorten you path if you would like to train this network from scratch. You may reuse two main things:
- The network itself;
- The dataset class;
- Also you may find our training loop useful;
If you would like to use the dataset, then you would need a pre-processed dataframe with the following columns:
-
class- imagenet class label; -
label_name- human readable label name; -
cluster- I divided the dataset onto 3 clusters mostly by quantizing the image resolution, see below; -
filename- just the filename of the image;
Clusters I used:
self.cluster_dict = {
0: (384,512),
1: (512, 512),
2: (512, 384)
}
Clusters can be used to train using rectangular crops instead of squares. Also obviously, you would need the ImageNET dataset.
If you need our imnet_cluster_df_short.feather - you can just use this file.
Typical launch code
I will not go into detail about building your own environment (please reach out if you need the details or follow this link), but mostly we used:
- PyTorch 0.4;
- CUDA 9.0;
- Standard scientific libraries (
pandas numpy scikit-imageetc);
Typically I launch my networks with code like this:
CUDA_VISIBLE_DEVICES=0,2 python3 train.py \
--epochs 1000 --epoch_fraction 0.2 \
--batch-size 200 --workers 6 \
--dataset imagenet \
--size_ratio 0.5 --preprocessing_type 5 \
--fold 0 --arch mnasnet --multi_class False \
--num_classes 1000 --classifier_config 512 \
--lr 1e-3 --optimizer adam --lr_regime auto_decay \
--epochs_grow_size 0 \
--lognumber mnasnet_standard_adam_1e3_512_cut_last_nosampler \
--tensorboard True --tensorboard_images True --print-freq 5 \
Final remarks
Probably choosing a highly optimized network designed using some form of RL was not the best idea for a small side project, but it is valuable experience.
Nevertheless, if I was picking this repo as a starter for MNASNET, I would:
- Review the code at first;
- Test the network thoroughly;
- Play with various LR warmup regimes;
