Recommender System Tutorial Save
A step-by-step tutorial on developing a practical recommendation system (retrieval and ranking) using TensorFlow Recommenders and Keras.
Build a recommendation system with TensorFlow and Keras
It is a step-by-step tutorial on developing a practical recommendation system (retrieval and ranking tasks) using TensorFlow Recommenders and Keras and deploy it using TensorFlow Serving.
Here, you can find an introduction to the information retrieval and the recommendation systems, then you can explore the Jupyter notebook and run it in Google Colab in order to study the code.
![]()
In the notebook, we load MovieLens dataset using TesorFlow Datasets, preprocess its features using Keras preprocessing layers, build the retrieval and ranking tasks using TensorFlow Recommenders and index and search for similar items using Spotify Annoy.
This tutorial is recommended to both academic and industry enthusiasts.
Introduction
What is a recommendation system?!
Online services usually provides thousands, millions or even billions of items like products, video clips, movies, musics, news, articles, blog posts, advertisements, etc. For example, the Google Play Store provides millions of apps and YouTube provides billions of videos. [1]
However, users prefer to see a handful shortlist of likely items instead of struggling with the full corpora. They usually can search or filter the list to find the best handful items, but sometimes they even don't know what they really want (e.g. a birthday gift). In a physical store an expert seller would help in this case by useful recommendations. So, why not in an online store?!
A recommedation system can retrieve, filter and recommend best personalized results for the user - results which the user is likely to buy. So it is one of the major requirements of modern businesses in order to increase their conversion rate. On September 21, 2009, Netflix gave a grand prize of $1,000,000 to a team which bested Netflix's own algorithm for predicting ratings by 10.06%. [2]

A recommendation system ia a system that gives a query (context) which is what we know about the liking list, and filter the corpus (full catalog of items) to a shortlist of candidates (items, documents). A query (context) can be a user id, user's geographical location or user's history of previous purchases and the resulting candidates can be some new items that we guess are interesting for the user.
The query can also be an item id, its image or its textual description and the candidates can be some similar or related items from the corpus.

Recommendation stages (tasks)
In practice, dealing with a large corpus and filter it to a shortlist is an intractable and inefficient task. So practical recommender systems has two (or three) filterng phases:
- Retrieval (Candidate Generation)
- Ranking (Scoring)
- Re-ranking or optimazation or ...
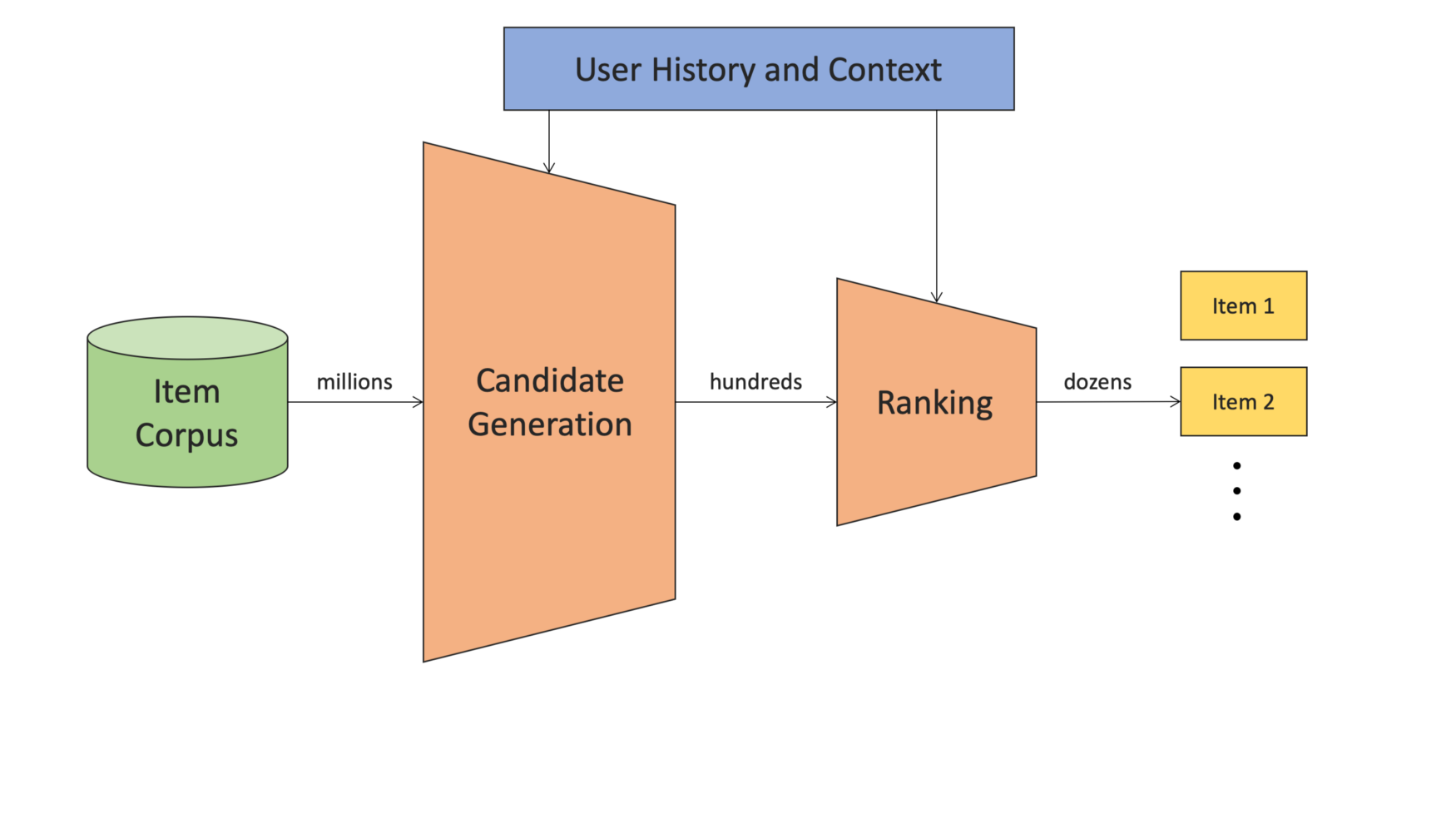
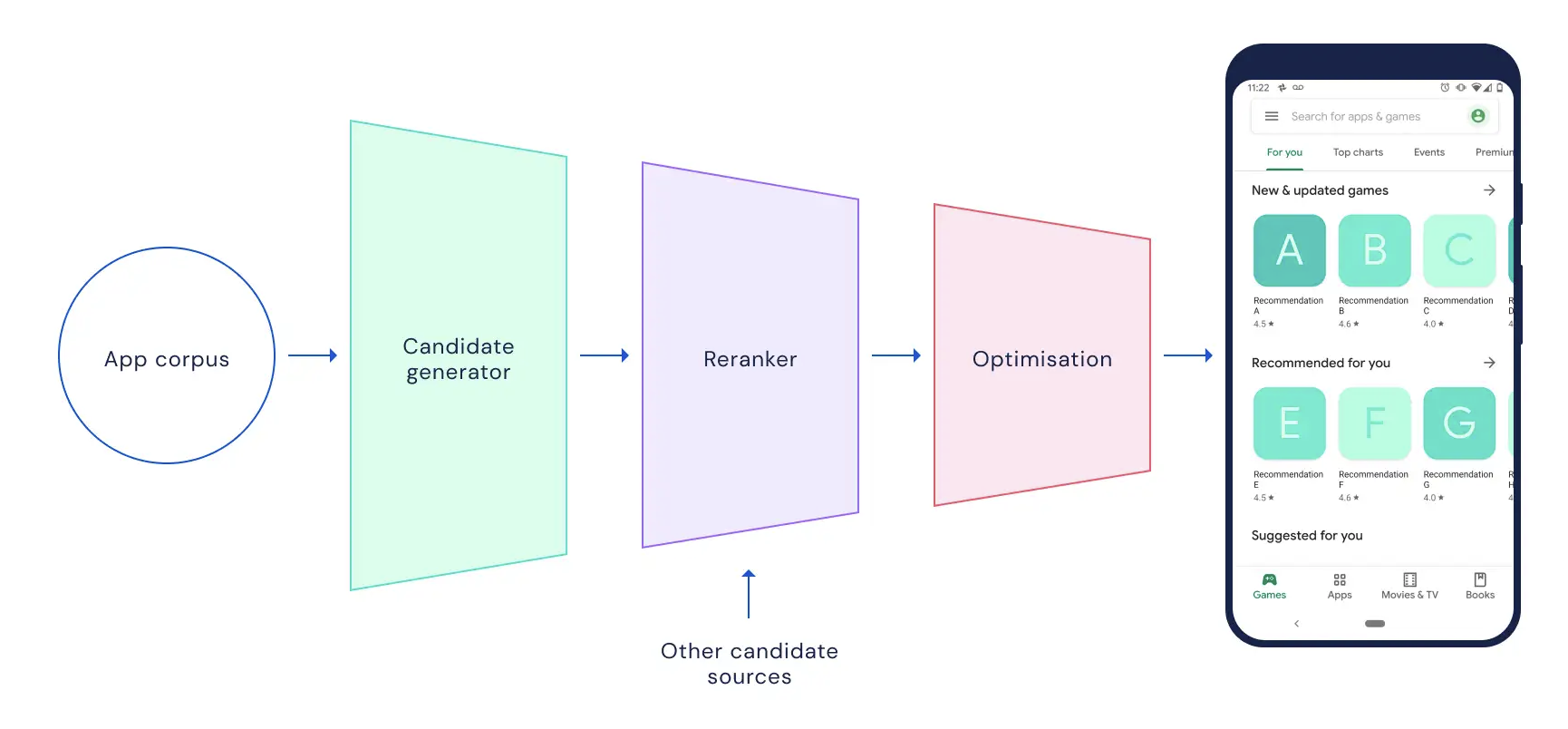
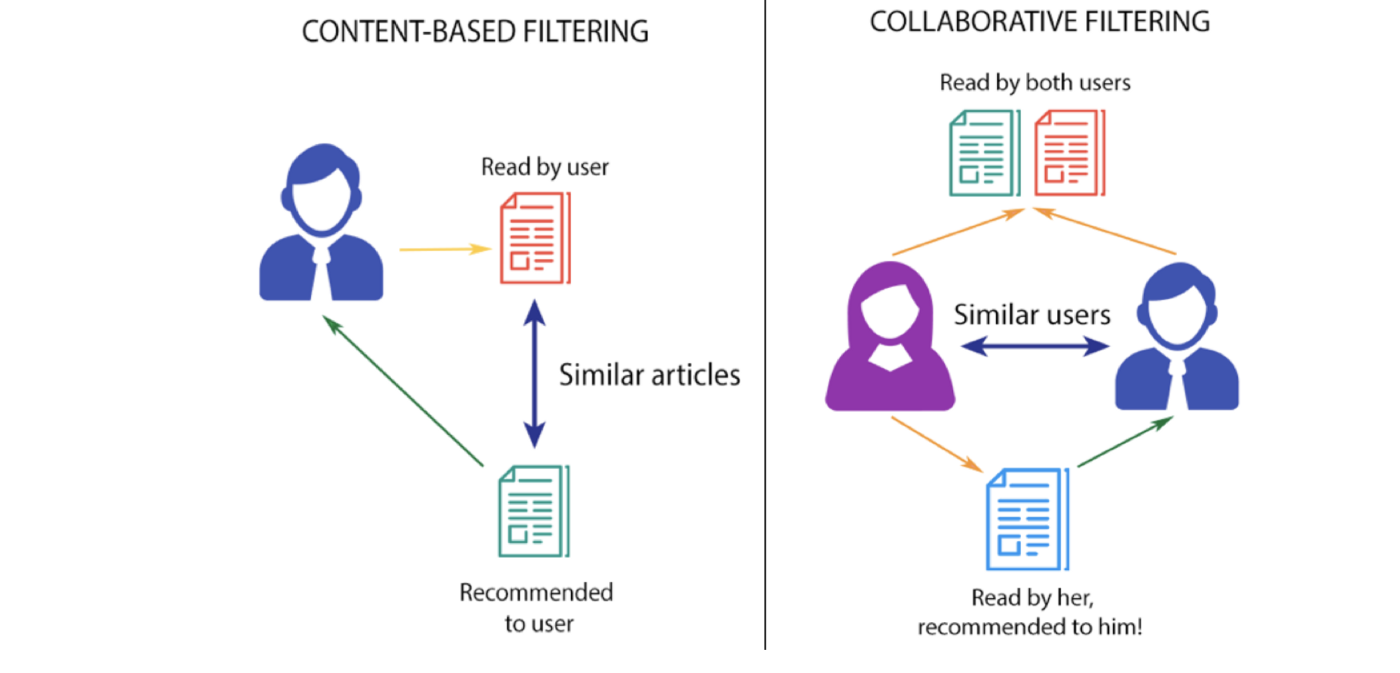
Content-based Filtering vs Collaborative Filtering
Filtering items is based on similarities. we can filter the list based on similar candidates (content-based filtering) or based on the similarity between queries and candidates (collaborative filtering). Collaborative filtering algorithms usually perform better than content-based methods.
Representation of a query or a candidate
A query or a candidate has lots of different features. For example a query can be constructed by these features:
- user_id
- user_previous_history
- user_job
- etc.
And a candidate can have features like:
- item_description
- item_image
- item_price
- posted_time
- etc.
These obviouse features can be numerical variables, categorical variables, bitmaps or raw texts. However, these low-level features are not enough and we should extract some more abstract latent features from these obvious features to represent the query or the candidate as a numerical high-dimensional vector - known as Embedding Vector.
Matrix Factorization (MF) is a classic collaborative filtering method to learn some latent factors (latent features) from user_id, item_id and rating features and represent users and items by latent (embedding) vectors.
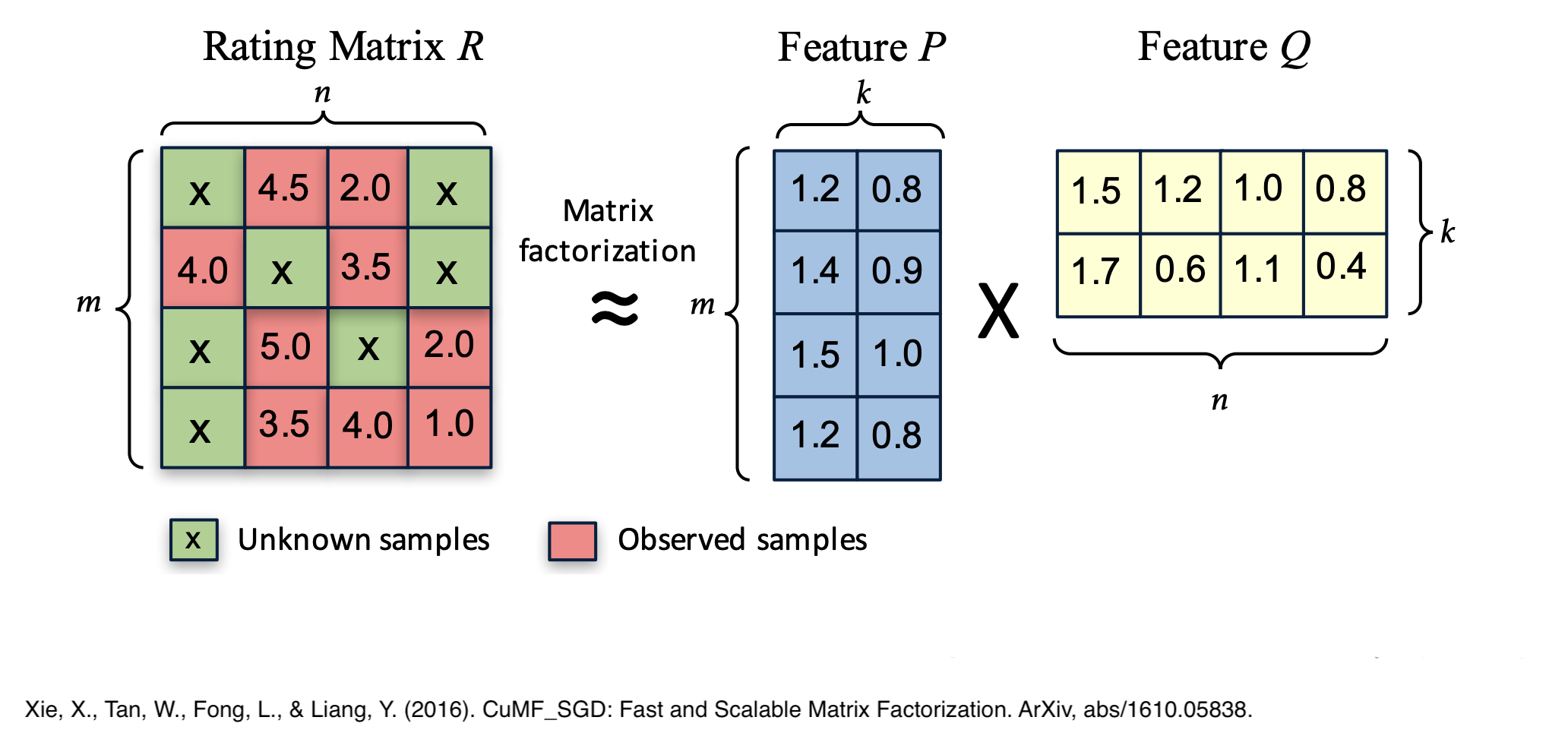
Matrix Factorization method only uses user_id and candidate_id features collaboratively to learn the latent features. In fact it doesn't care about other side-features like candidate_description, price, user_comment, etc.
To involve side-features as well as ids while learning latent features (embeddings), we can use deep neural network (DNN) architectures like softmax or two-tower neural models.

YouTube two-tower neural model uses side-features to represent queries and candidates in an abstract high-dimentional embedding vector.
Movielens dataset
The Movielens dataset is a benchmark dataset in the field of recommender system research containing a set of ratings given to movies by a set of users, collected from the MovieLens website - a movie recommendation service.
There are 5 different versions of Movielens available for different purposes: "25m", "latest-small", "100k", "1m" and "20m". In this tutorial we are going to work with "100k" version. For more information about different versions visit the official website.
movielens/100k-ratings
The oldest version of the MovieLens dataset containing 100,000 ratings from 943 users on 1,682 movies. Each user has rated at least 20 movies. Ratings are in whole-star increments. This dataset contains demographic data of users in addition to data on movies and ratings.
movielens/100k-movies
This dataset contains data of 1,682 movies rated in the movielens/100k-ratings dataset.
Explore the Jupyter notebook
 View the code on GitHub View the code on GitHub
|
|
Donation
Give a ⭐ if this project helped you!
