Pytorch Optimizer Save
torch-optimizer -- collection of optimizers for Pytorch
torch-optimizer
.. image:: https://github.com/jettify/pytorch-optimizer/workflows/CI/badge.svg :target: https://github.com/jettify/pytorch-optimizer/actions?query=workflow%3ACI :alt: GitHub Actions status for master branch .. image:: https://codecov.io/gh/jettify/pytorch-optimizer/branch/master/graph/badge.svg :target: https://codecov.io/gh/jettify/pytorch-optimizer .. image:: https://img.shields.io/pypi/pyversions/torch-optimizer.svg :target: https://pypi.org/project/torch-optimizer .. image:: https://readthedocs.org/projects/pytorch-optimizer/badge/?version=latest :target: https://pytorch-optimizer.readthedocs.io/en/latest/?badge=latest :alt: Documentation Status .. image:: https://img.shields.io/pypi/v/torch-optimizer.svg :target: https://pypi.python.org/pypi/torch-optimizer .. image:: https://static.deepsource.io/deepsource-badge-light-mini.svg :target: https://deepsource.io/gh/jettify/pytorch-optimizer/?ref=repository-badge
torch-optimizer -- collection of optimizers for PyTorch_ compatible with optim_ module.
Simple example
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.DiffGrad(model.parameters(), lr=0.001)
optimizer.step()
Installation
Installation process is simple, just::
$ pip install torch_optimizer
Documentation
https://pytorch-optimizer.rtfd.io
Citation
Please cite the original authors of the optimization algorithms. If you like this package::
@software{Novik_torchoptimizers,
title = {{torch-optimizer -- collection of optimization algorithms for PyTorch.}},
author = {Novik, Mykola},
year = 2020,
month = 1,
version = {1.0.1}
}
Or use the github feature: "cite this repository" button.
Supported Optimizers
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| A2GradExp_ | https://arxiv.org/abs/1810.00553 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| A2GradInc_ | https://arxiv.org/abs/1810.00553 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| A2GradUni_ | https://arxiv.org/abs/1810.00553 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| AccSGD_ | https://arxiv.org/abs/1803.05591 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| AdaBelief_ | https://arxiv.org/abs/2010.07468 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| AdaBound_ | https://arxiv.org/abs/1902.09843 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| AdaMod_ | https://arxiv.org/abs/1910.12249 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| Adafactor_ | https://arxiv.org/abs/1804.04235 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| Adahessian_ | https://arxiv.org/abs/2006.00719 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| AdamP_ | https://arxiv.org/abs/2006.08217 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| AggMo_ | https://arxiv.org/abs/1804.00325 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| Apollo_ | https://arxiv.org/abs/2009.13586 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| DiffGrad_ | https://arxiv.org/abs/1909.11015 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| Lamb_ | https://arxiv.org/abs/1904.00962 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| Lookahead_ | https://arxiv.org/abs/1907.08610 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| MADGRAD_ | https://arxiv.org/abs/2101.11075 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| NovoGrad_ | https://arxiv.org/abs/1905.11286 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| PID_ | https://www4.comp.polyu.edu.hk/~cslzhang/paper/CVPR18_PID.pdf |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| QHAdam_ | https://arxiv.org/abs/1810.06801 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| QHM_ | https://arxiv.org/abs/1810.06801 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| RAdam_ | https://arxiv.org/abs/1908.03265 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| Ranger_ | https://medium.com/@lessw/new-deep-learning-optimizer-ranger-synergistic-combination-of-radam-lookahead-for-the-best-of-2dc83f79a48d |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| RangerQH_ | https://arxiv.org/abs/1810.06801 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| RangerVA_ | https://arxiv.org/abs/1908.00700v2 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| SGDP_ | https://arxiv.org/abs/2006.08217 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| SGDW_ | https://arxiv.org/abs/1608.03983 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| SWATS_ | https://arxiv.org/abs/1712.07628 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| Shampoo_ | https://arxiv.org/abs/1802.09568 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| Yogi_ | https://papers.nips.cc/paper/8186-adaptive-methods-for-nonconvex-optimization |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
Visualizations
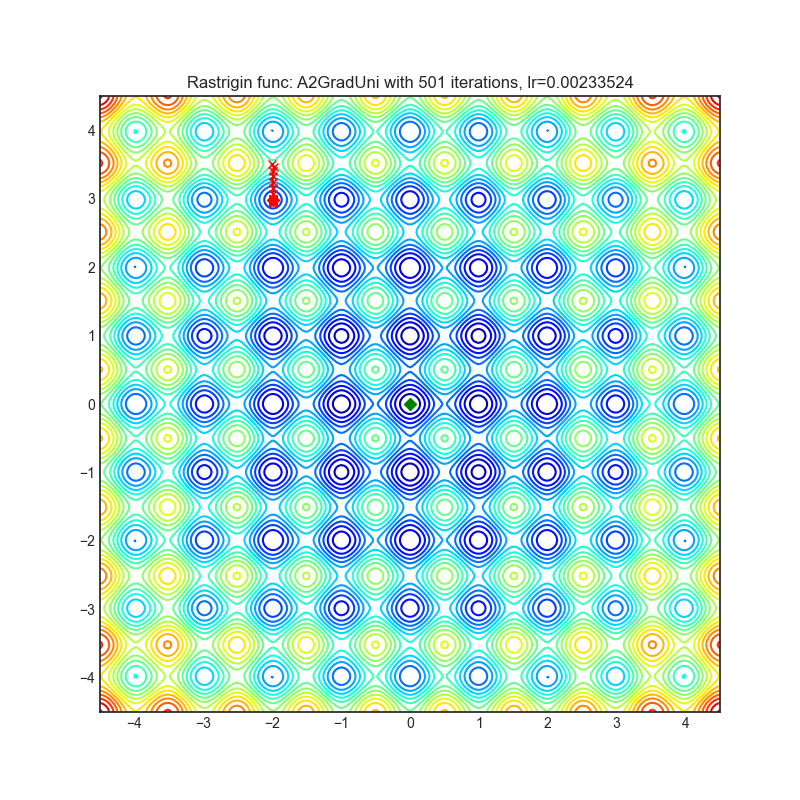
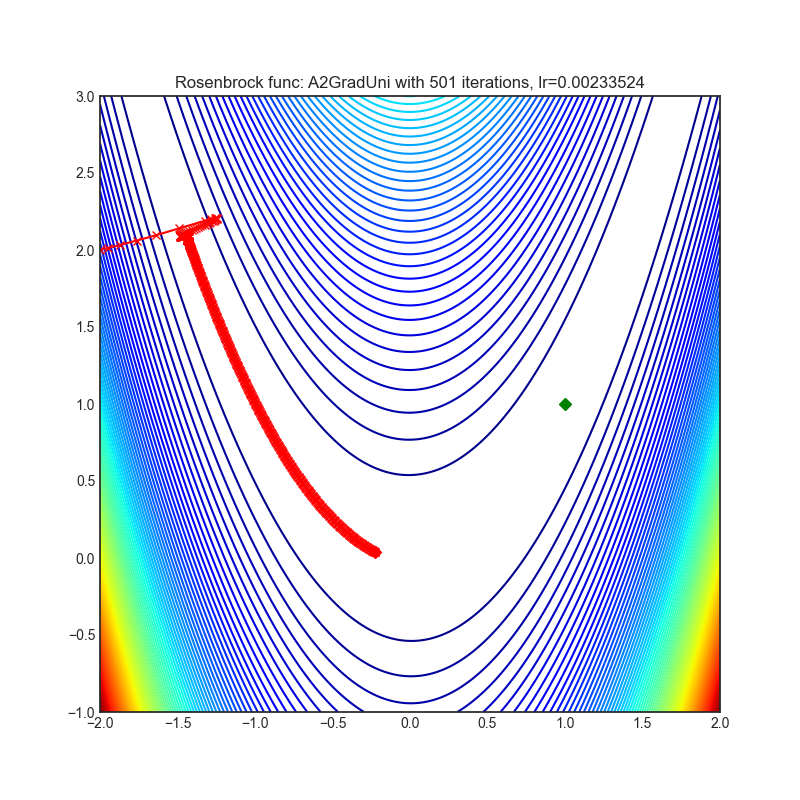
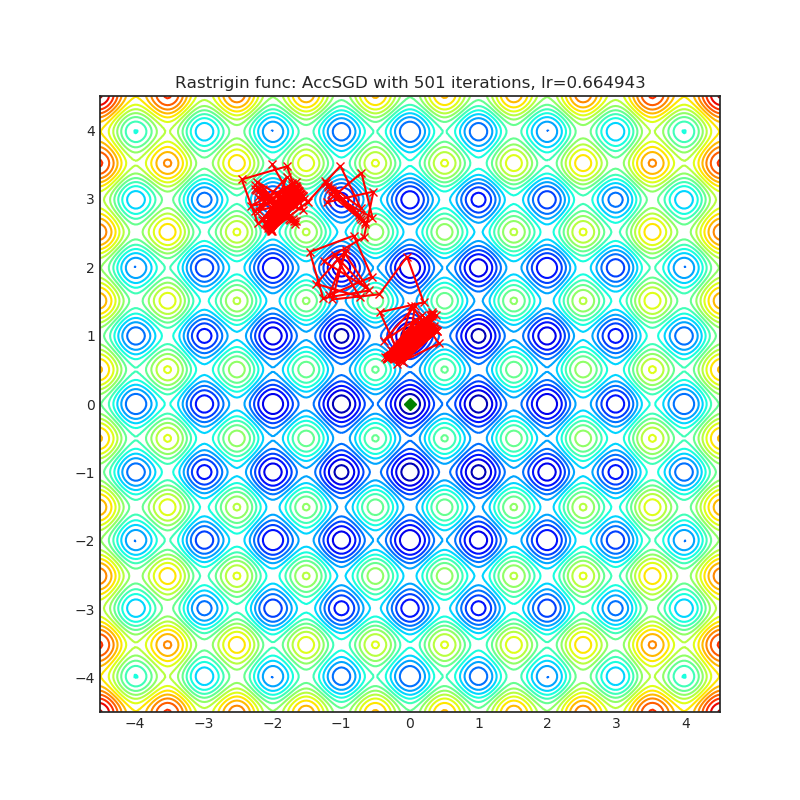
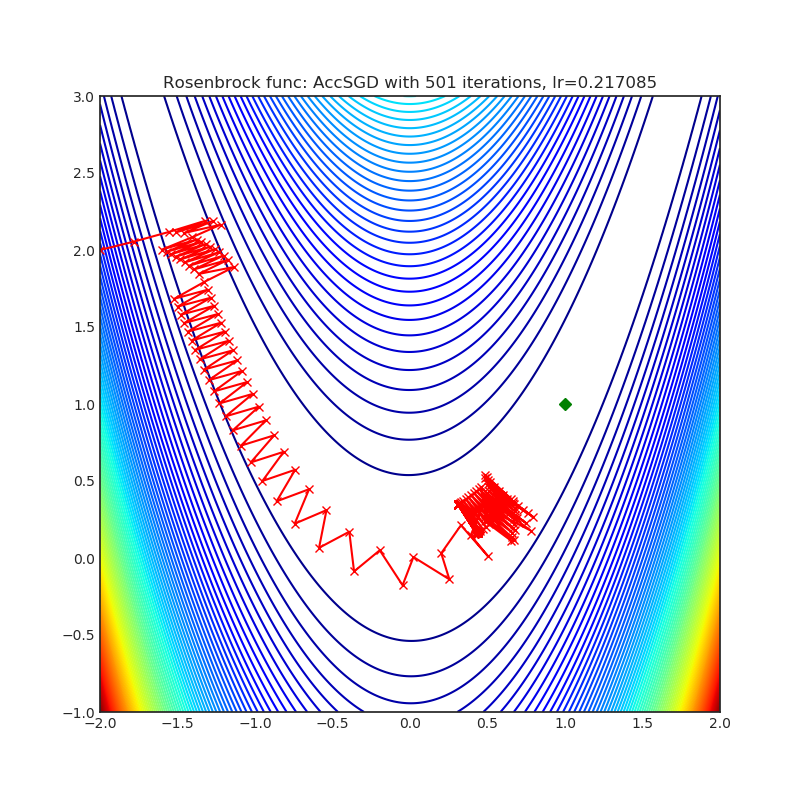
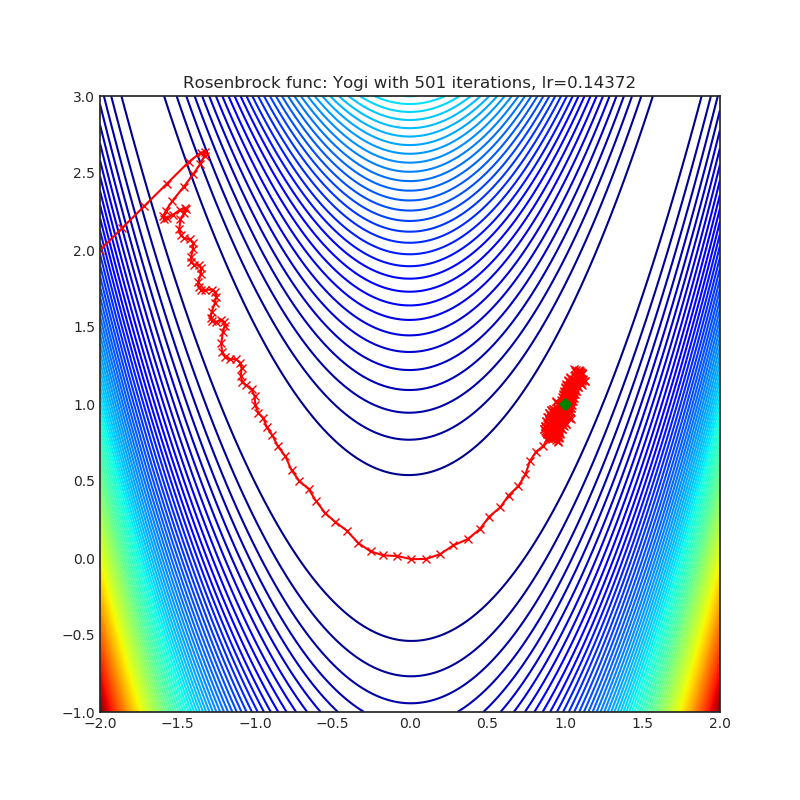
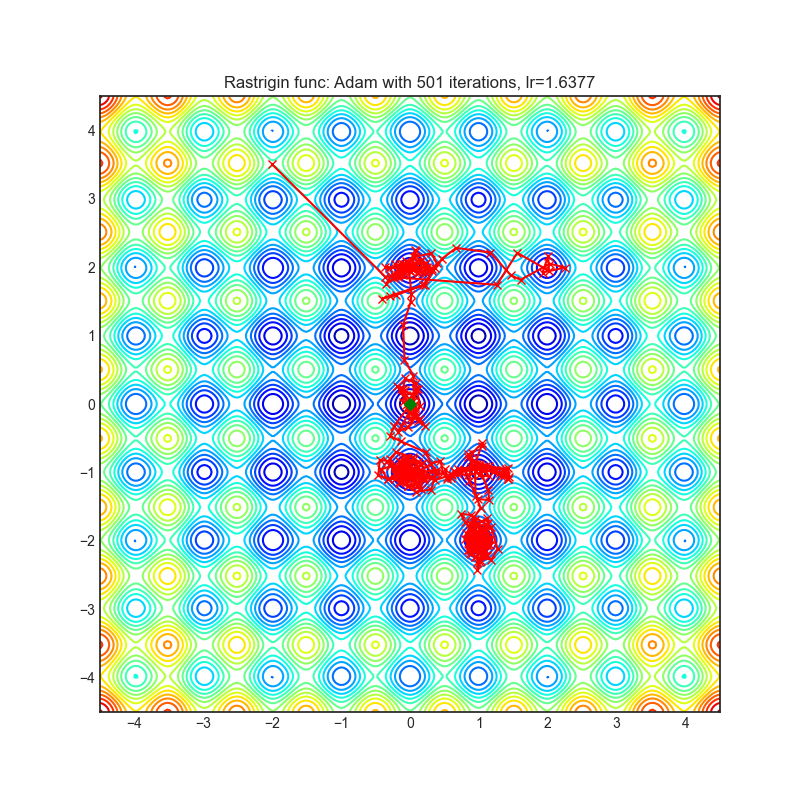
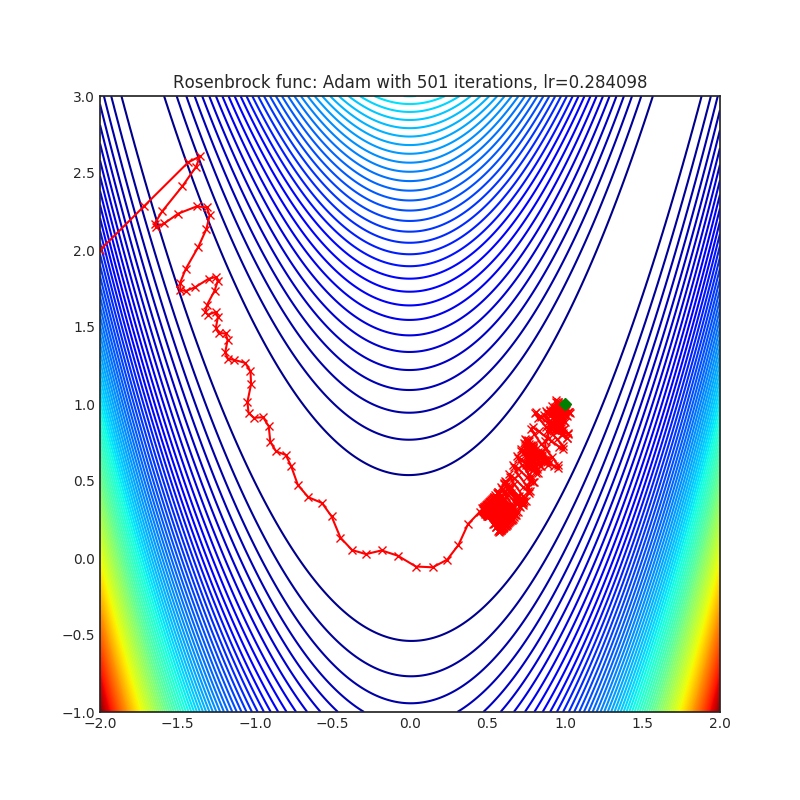
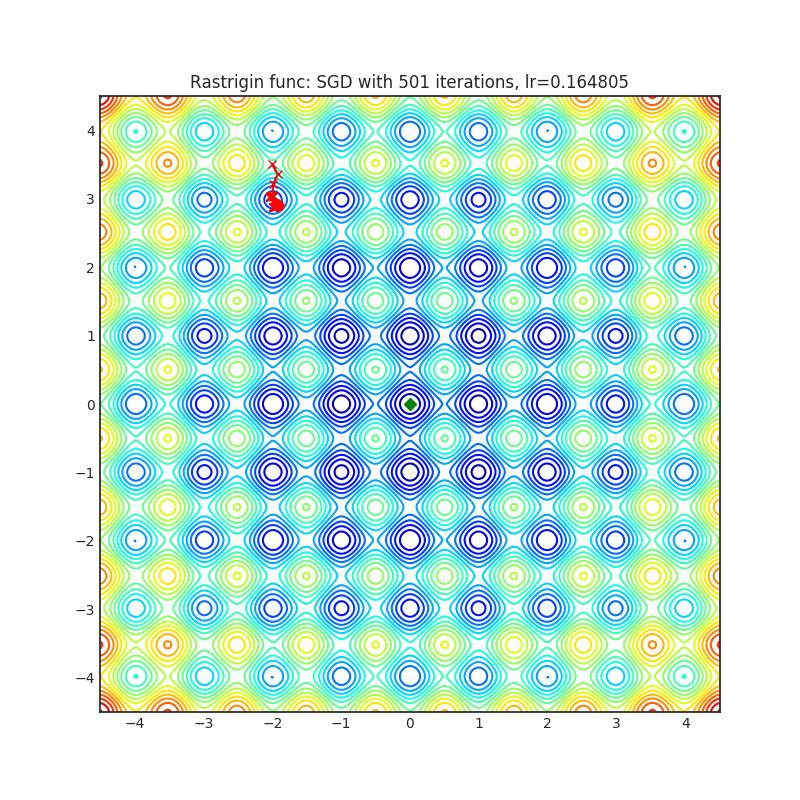
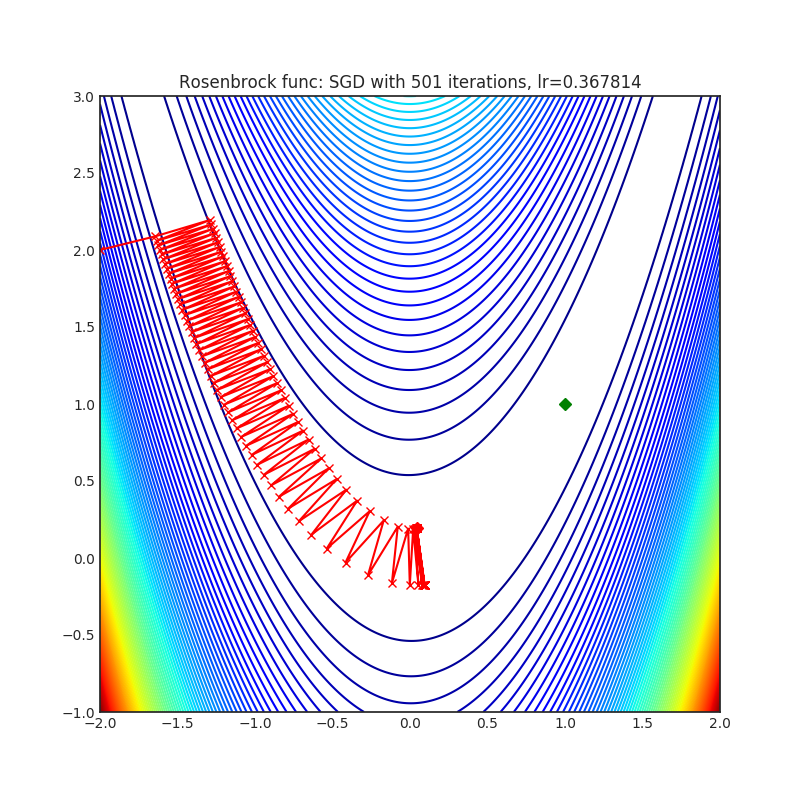
Visualizations help us see how different algorithms deal with simple situations like: saddle points, local minima, valleys etc, and may provide interesting insights into the inner workings of an algorithm. Rosenbrock_ and Rastrigin_ benchmark_ functions were selected because:
- Rosenbrock_ (also known as banana function), is non-convex function that has
one global minimum
(1.0. 1.0). The global minimum is inside a long, narrow, parabolic shaped flat valley. Finding the valley is trivial. Converging to the global minimum, however, is difficult. Optimization algorithms might pay a lot of attention to one coordinate, and struggle following the valley which is relatively flat.
.. image:: https://upload.wikimedia.org/wikipedia/commons/3/32/Rosenbrock_function.svg
-
Rastrigin_ is a non-convex function and has one global minimum in
(0.0, 0.0). Finding the minimum of this function is a fairly difficult problem due to its large search space and its large number of local minima... image:: https://upload.wikimedia.org/wikipedia/commons/8/8b/Rastrigin_function.png
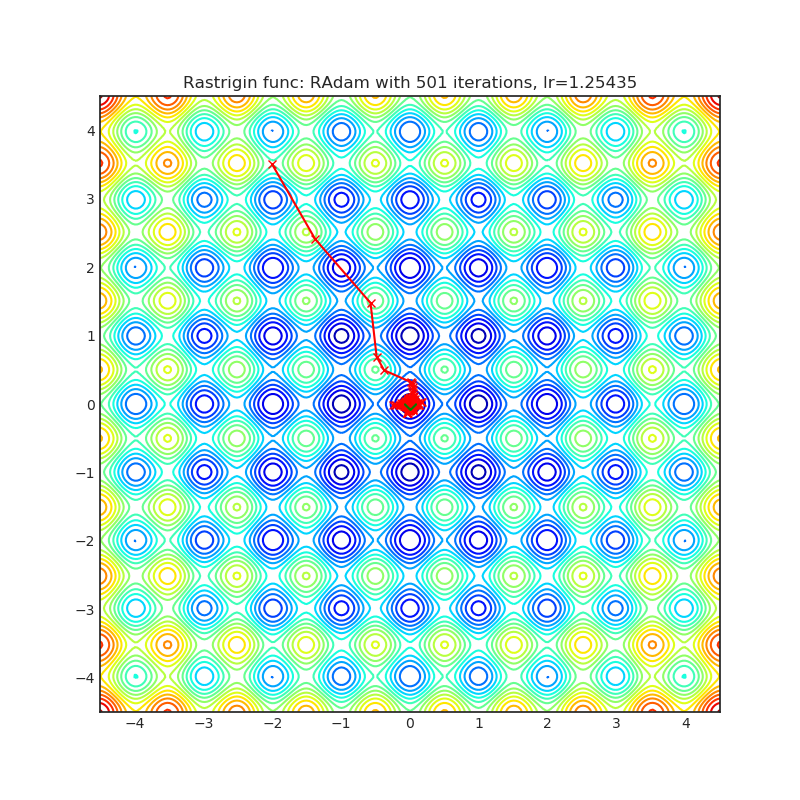
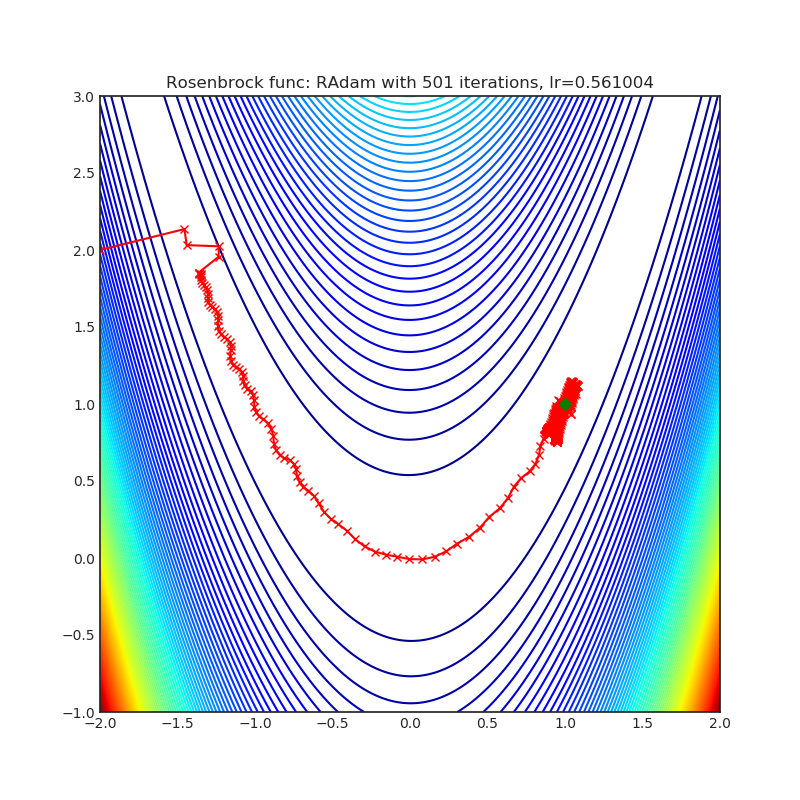
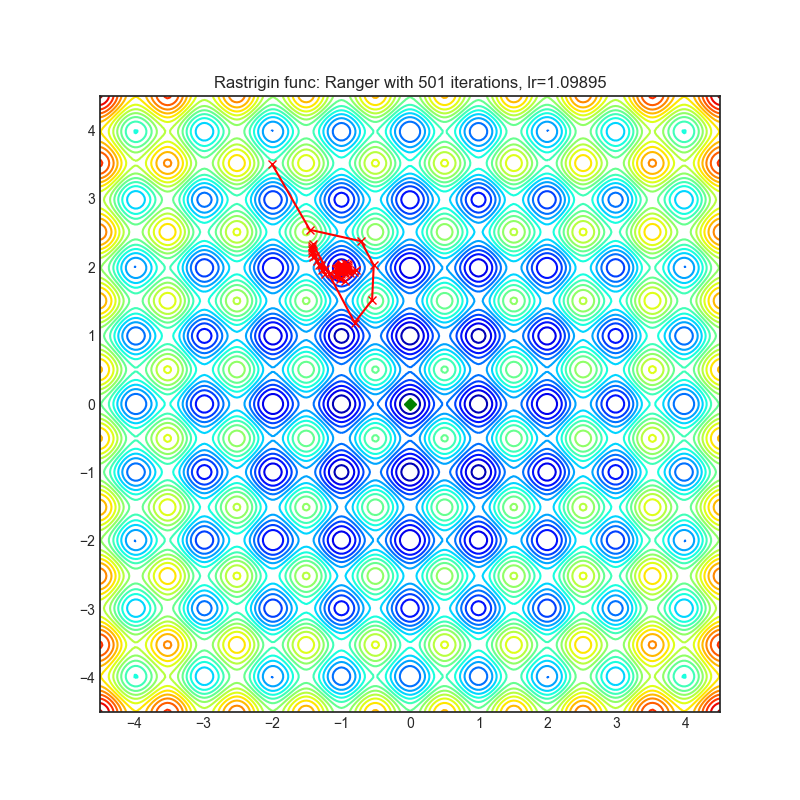
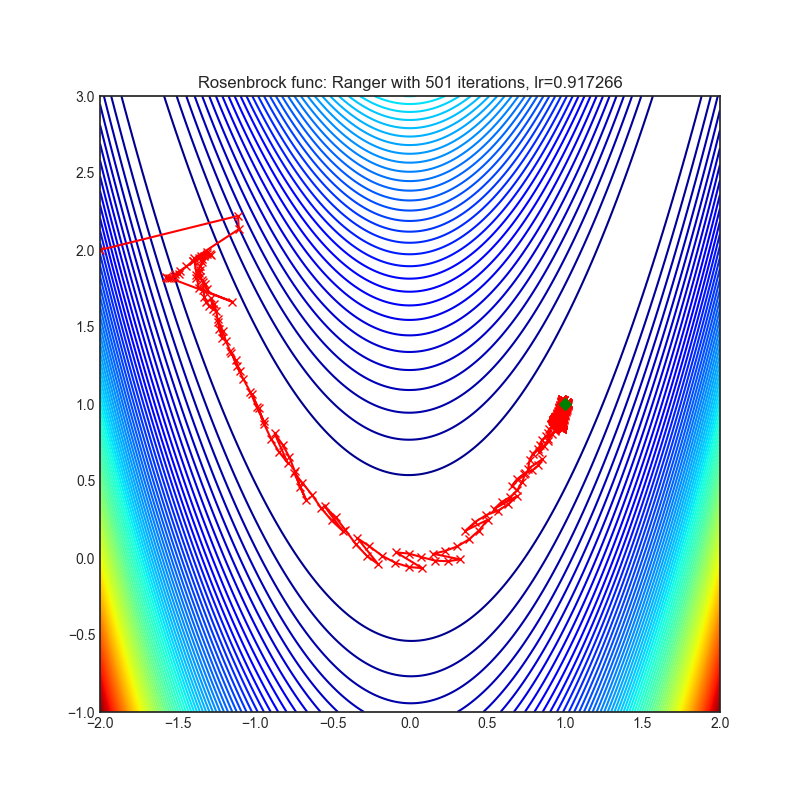
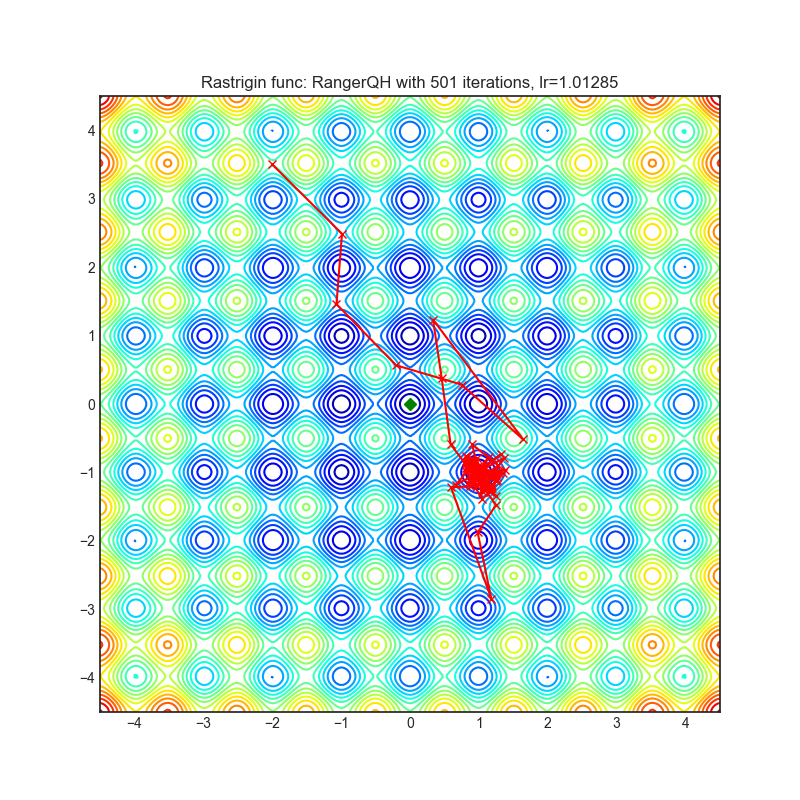
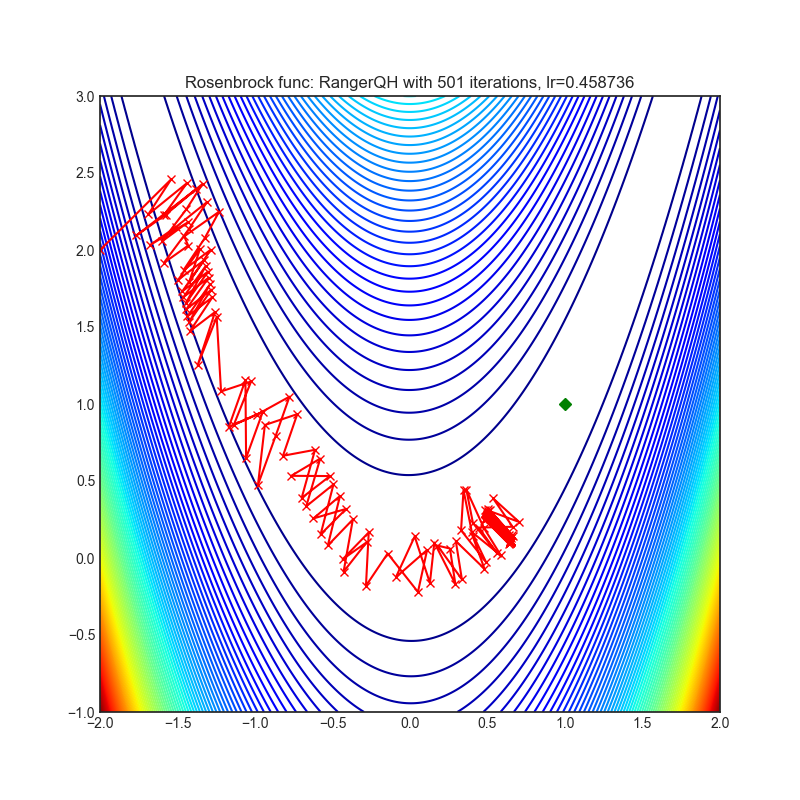
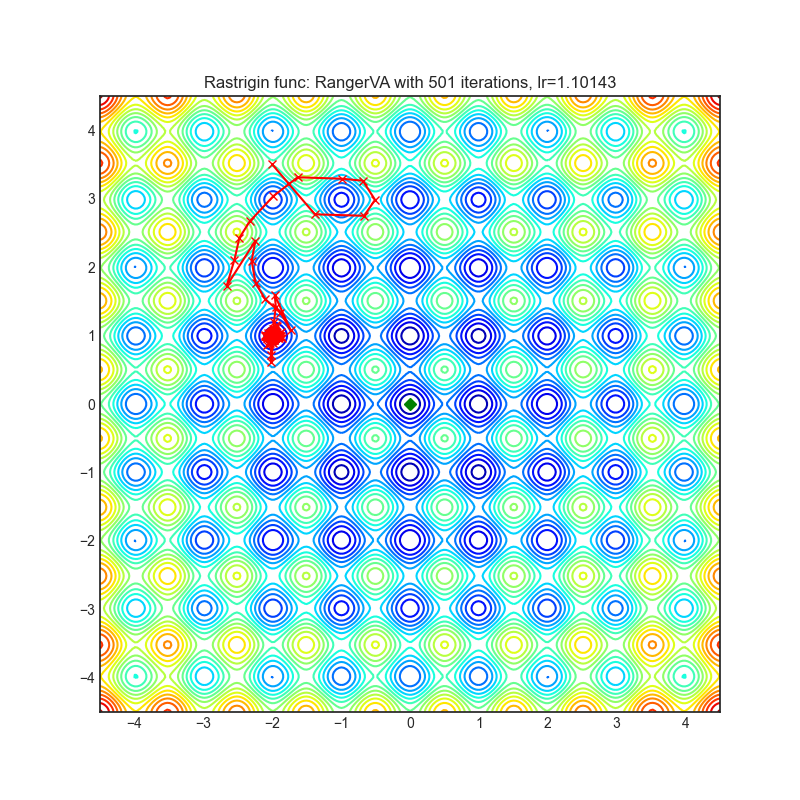
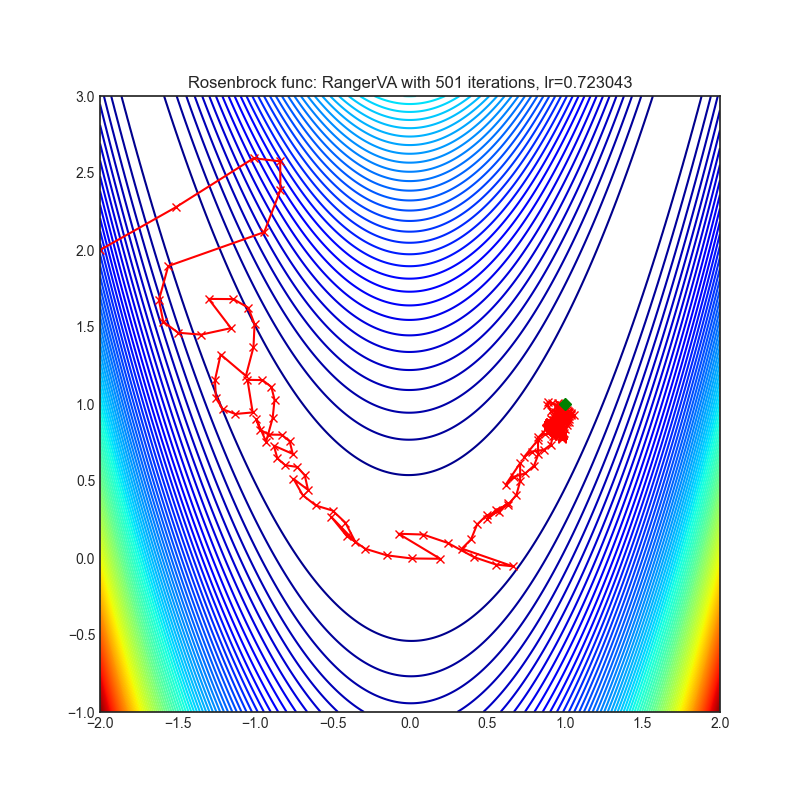
Each optimizer performs 501 optimization steps. Learning rate is the best one found
by a hyper parameter search algorithm, the rest of the tuning parameters are default. It
is very easy to extend the script and tune other optimizer parameters.
.. code::
python examples/viz_optimizers.py
Warning
Do not pick an optimizer based on visualizations, optimization approaches have unique properties and may be tailored for different purposes or may require explicit learning rate schedule etc. The best way to find out is to try one on your particular problem and see if it improves scores.
If you do not know which optimizer to use, start with the built in SGD/Adam. Once the training logic is ready and baseline scores are established, swap the optimizer and see if there is any improvement.
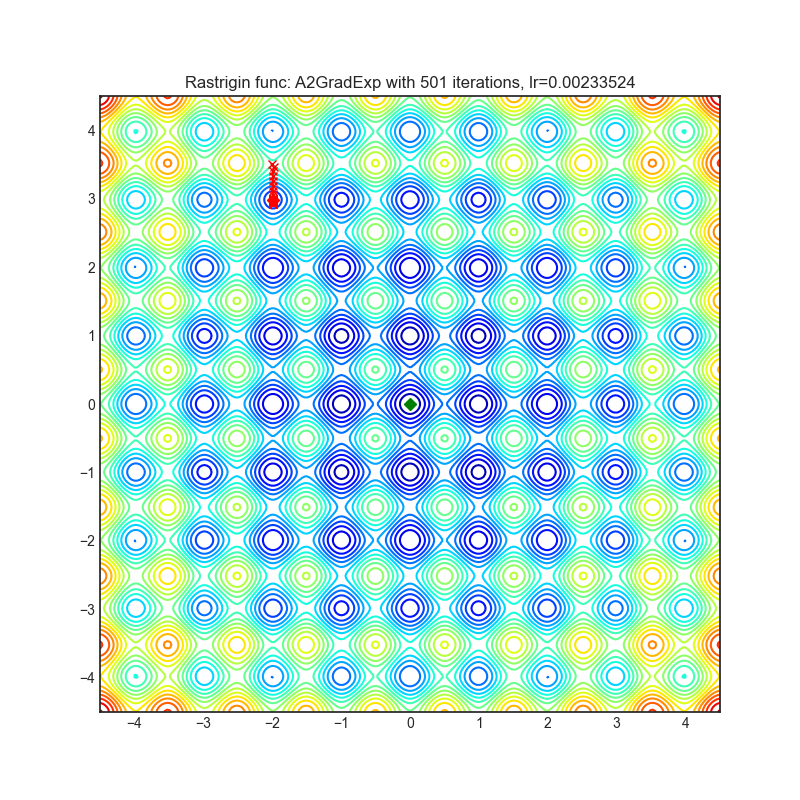
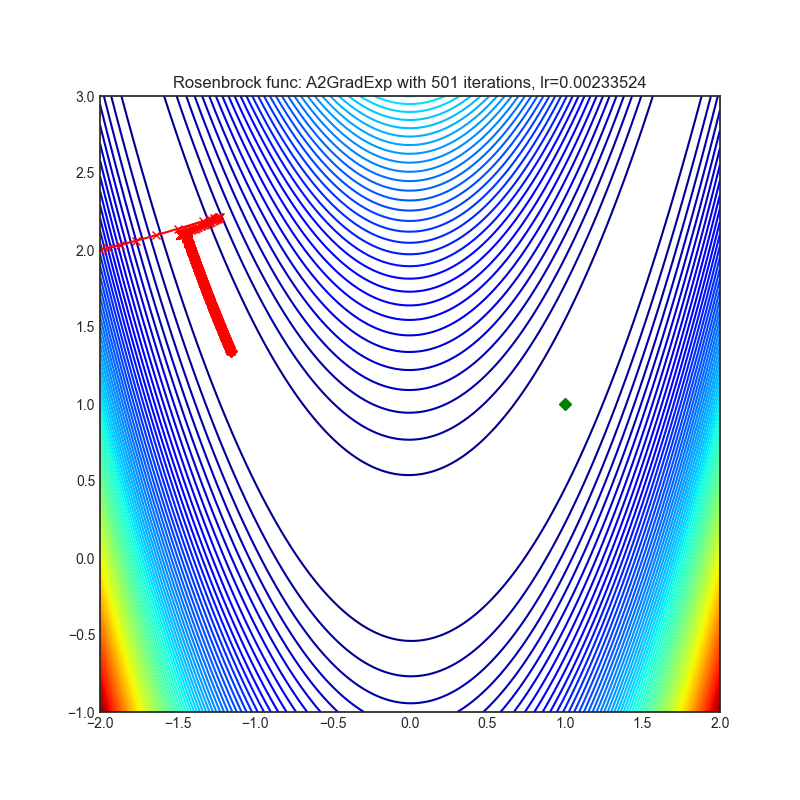
A2GradExp
+--------------------------------------------------------------------------------------------------------------+---------------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_A2GradExp.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_A2GradExp.png | +--------------------------------------------------------------------------------------------------------------+---------------------------------------------------------------------------------------------------------------+
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.A2GradExp(
model.parameters(),
kappa=1000.0,
beta=10.0,
lips=10.0,
rho=0.5,
)
optimizer.step()
Paper: Optimal Adaptive and Accelerated Stochastic Gradient Descent (2018) [https://arxiv.org/abs/1810.00553]
Reference Code: https://github.com/severilov/A2Grad_optimizer
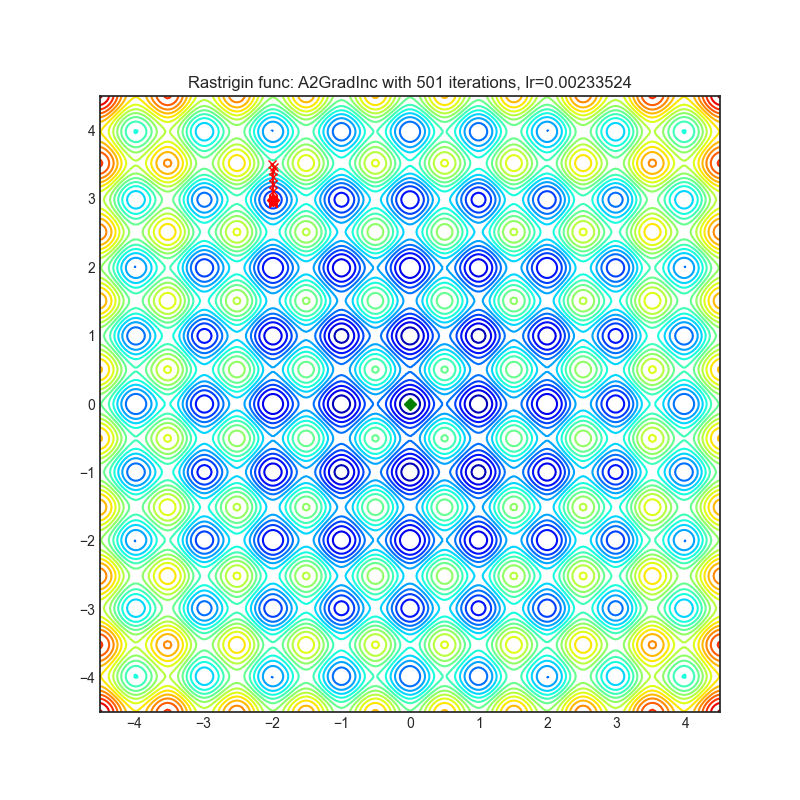
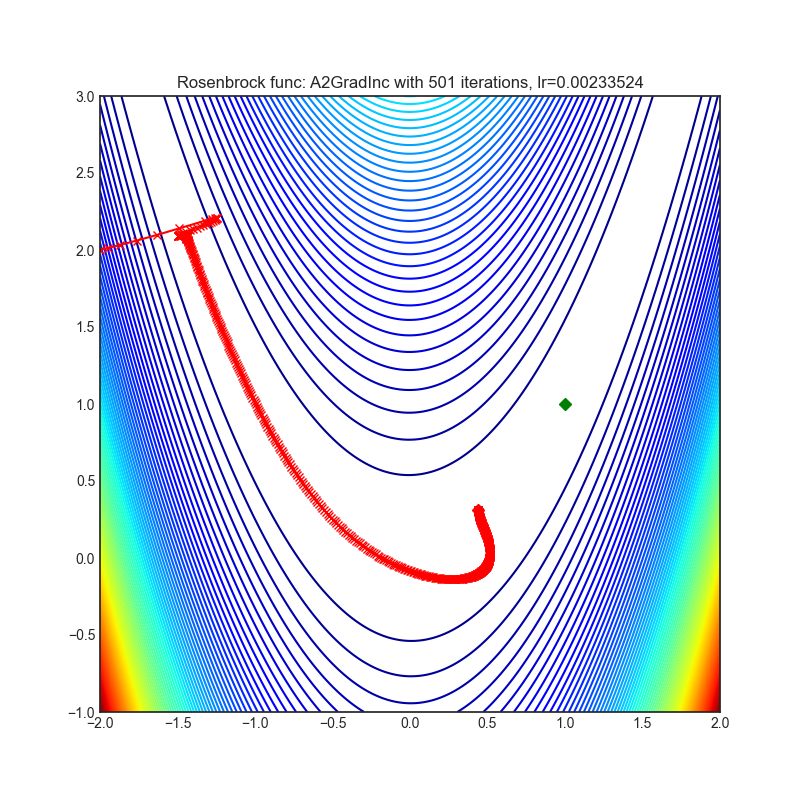
A2GradInc
+--------------------------------------------------------------------------------------------------------------+---------------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_A2GradInc.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_A2GradInc.png | +--------------------------------------------------------------------------------------------------------------+---------------------------------------------------------------------------------------------------------------+
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.A2GradInc(
model.parameters(),
kappa=1000.0,
beta=10.0,
lips=10.0,
)
optimizer.step()
Paper: Optimal Adaptive and Accelerated Stochastic Gradient Descent (2018) [https://arxiv.org/abs/1810.00553]
Reference Code: https://github.com/severilov/A2Grad_optimizer
A2GradUni
+--------------------------------------------------------------------------------------------------------------+---------------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_A2GradUni.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_A2GradUni.png | +--------------------------------------------------------------------------------------------------------------+---------------------------------------------------------------------------------------------------------------+
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.A2GradUni(
model.parameters(),
kappa=1000.0,
beta=10.0,
lips=10.0,
)
optimizer.step()
Paper: Optimal Adaptive and Accelerated Stochastic Gradient Descent (2018) [https://arxiv.org/abs/1810.00553]
Reference Code: https://github.com/severilov/A2Grad_optimizer
AccSGD
+-----------------------------------------------------------------------------------------------------------+------------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_AccSGD.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_AccSGD.png | +-----------------------------------------------------------------------------------------------------------+------------------------------------------------------------------------------------------------------------+
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.AccSGD(
model.parameters(),
lr=1e-3,
kappa=1000.0,
xi=10.0,
small_const=0.7,
weight_decay=0
)
optimizer.step()
Paper: On the insufficiency of existing momentum schemes for Stochastic Optimization (2019) [https://arxiv.org/abs/1803.05591]
Reference Code: https://github.com/rahulkidambi/AccSGD
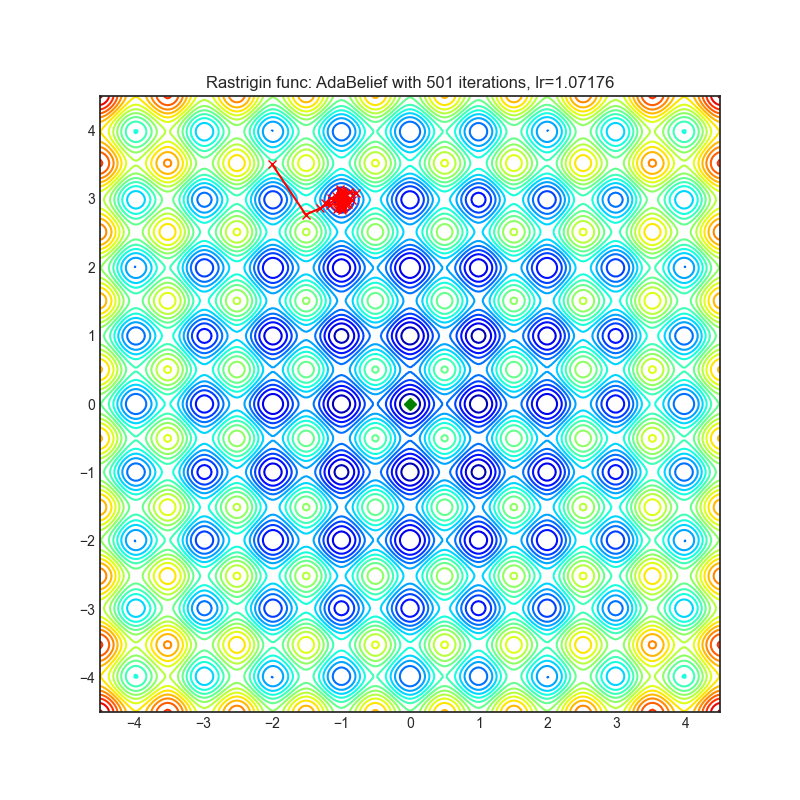
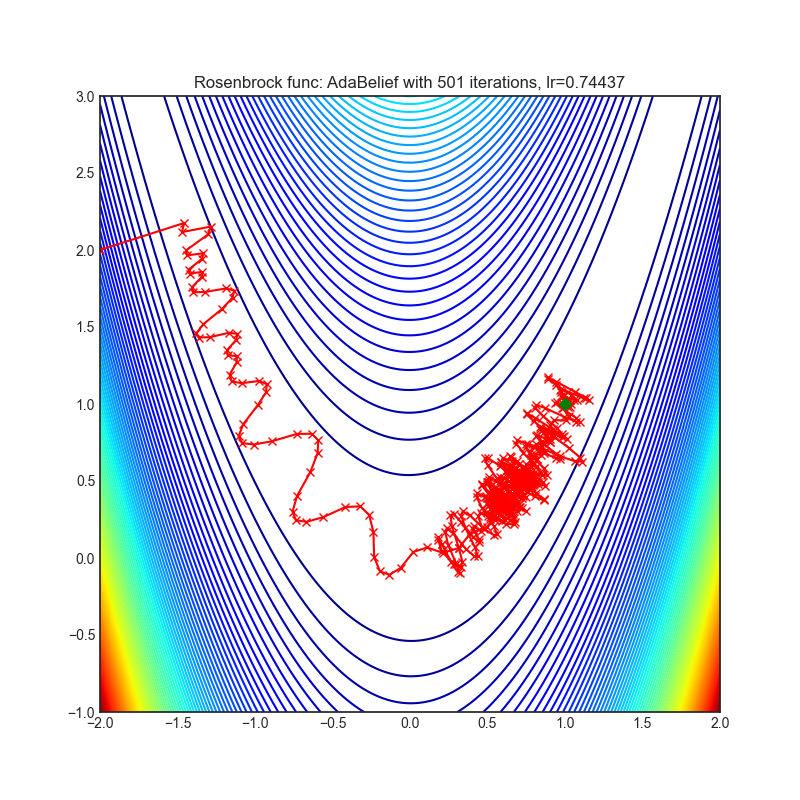
AdaBelief
+-------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_AdaBelief.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_AdaBelief.png | +-------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------+
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.AdaBelief(
m.parameters(),
lr= 1e-3,
betas=(0.9, 0.999),
eps=1e-3,
weight_decay=0,
amsgrad=False,
weight_decouple=False,
fixed_decay=False,
rectify=False,
)
optimizer.step()
Paper: AdaBelief Optimizer, adapting stepsizes by the belief in observed gradients (2020) [https://arxiv.org/abs/2010.07468]
Reference Code: https://github.com/juntang-zhuang/Adabelief-Optimizer
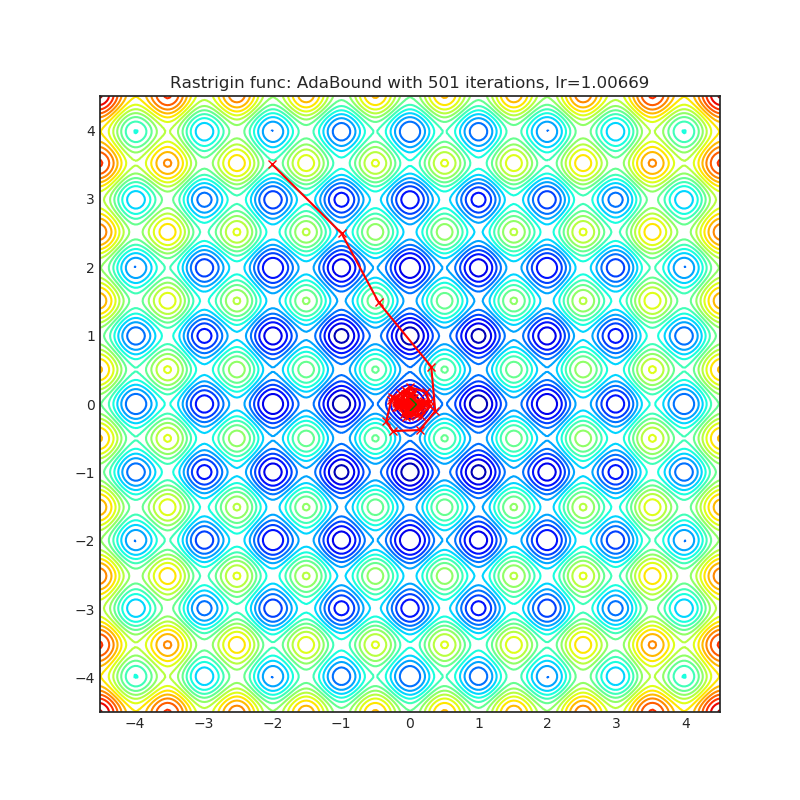
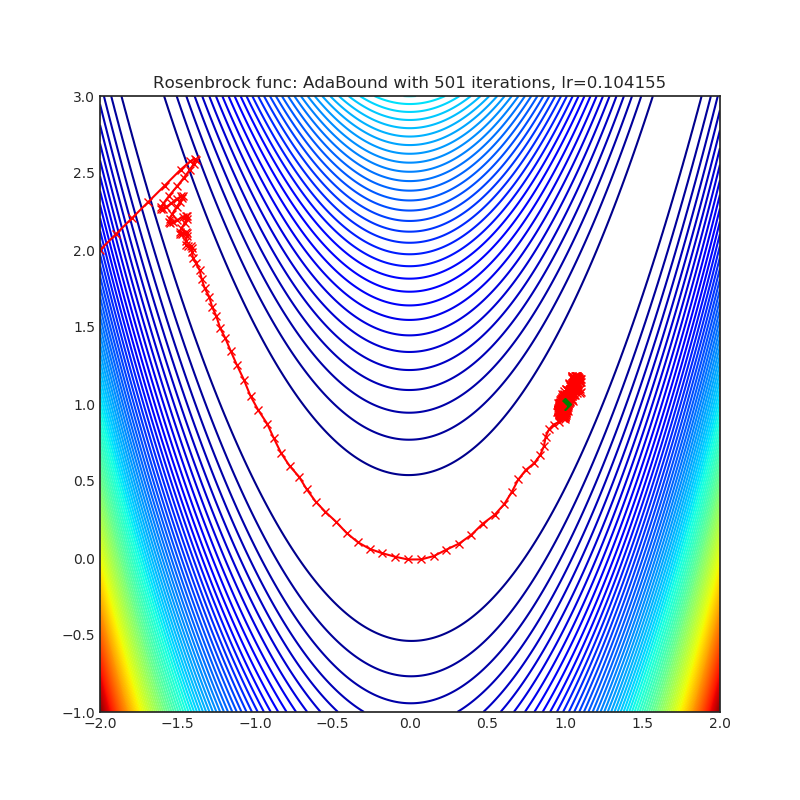
AdaBound
+------------------------------------------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_AdaBound.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_AdaBound.png | +------------------------------------------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------+
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.AdaBound(
m.parameters(),
lr= 1e-3,
betas= (0.9, 0.999),
final_lr = 0.1,
gamma=1e-3,
eps= 1e-8,
weight_decay=0,
amsbound=False,
)
optimizer.step()
Paper: Adaptive Gradient Methods with Dynamic Bound of Learning Rate (2019) [https://arxiv.org/abs/1902.09843]
Reference Code: https://github.com/Luolc/AdaBound
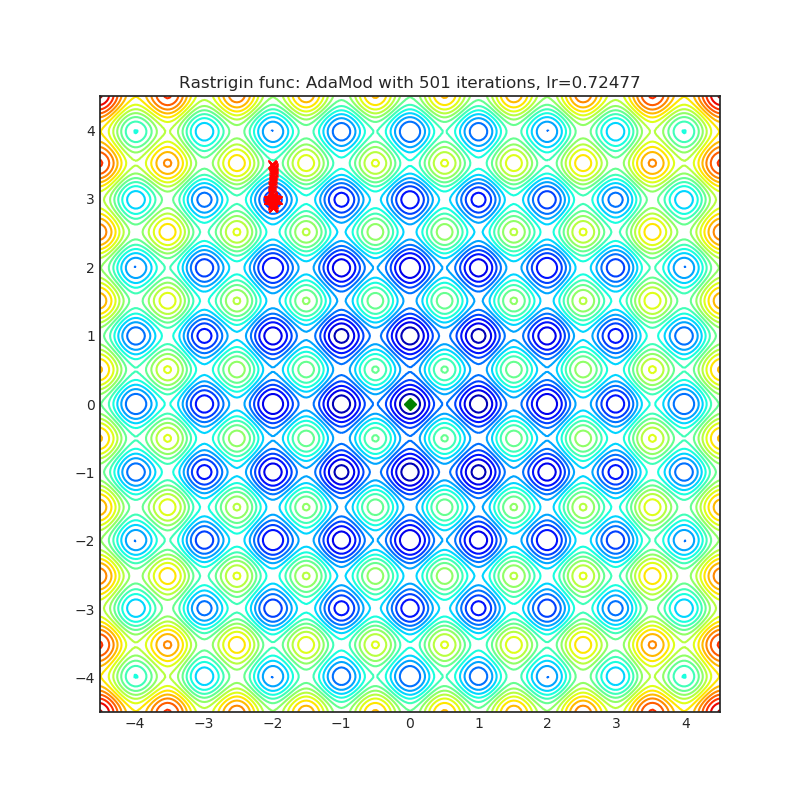
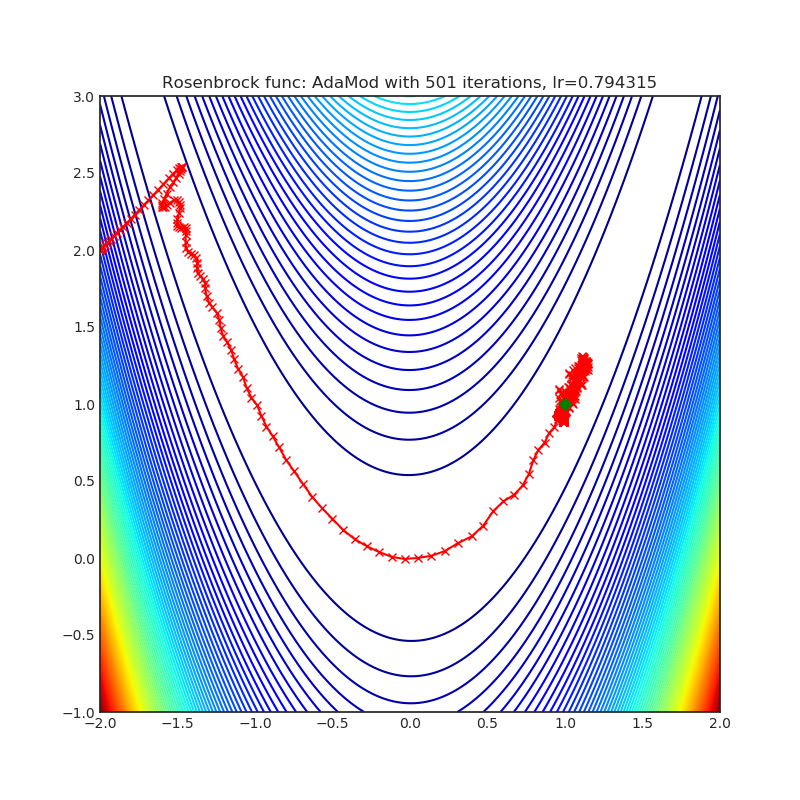
AdaMod
The AdaMod method restricts the adaptive learning rates with adaptive and momental upper bounds. The dynamic learning rate bounds are based on the exponential moving averages of the adaptive learning rates themselves, which smooth out unexpected large learning rates and stabilize the training of deep neural networks.
+------------------------------------------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_AdaMod.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_AdaMod.png | +------------------------------------------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------+
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.AdaMod(
m.parameters(),
lr= 1e-3,
betas=(0.9, 0.999),
beta3=0.999,
eps=1e-8,
weight_decay=0,
)
optimizer.step()
Paper: An Adaptive and Momental Bound Method for Stochastic Learning. (2019) [https://arxiv.org/abs/1910.12249]
Reference Code: https://github.com/lancopku/AdaMod
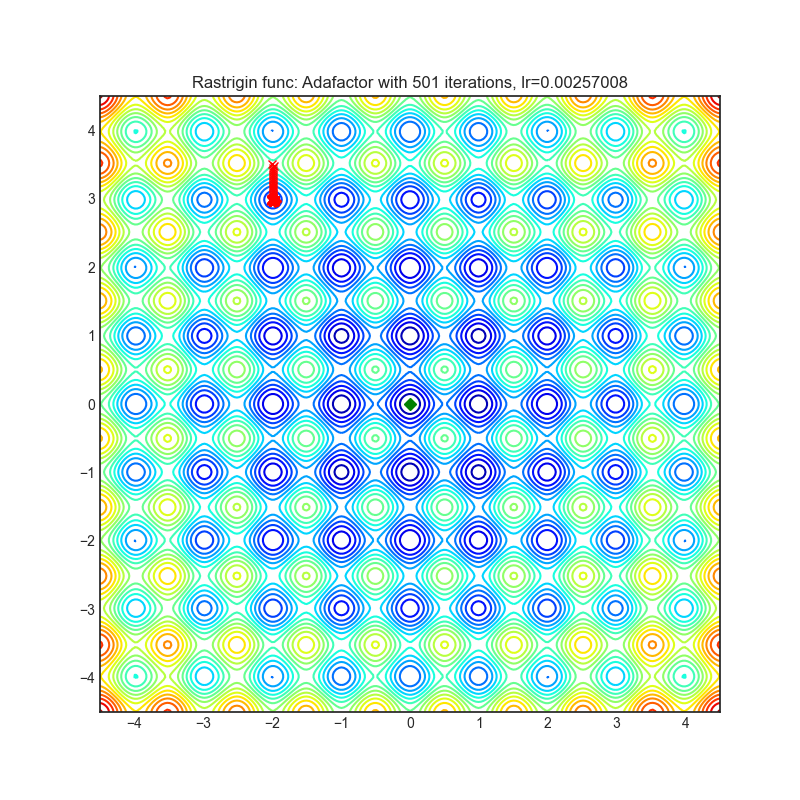
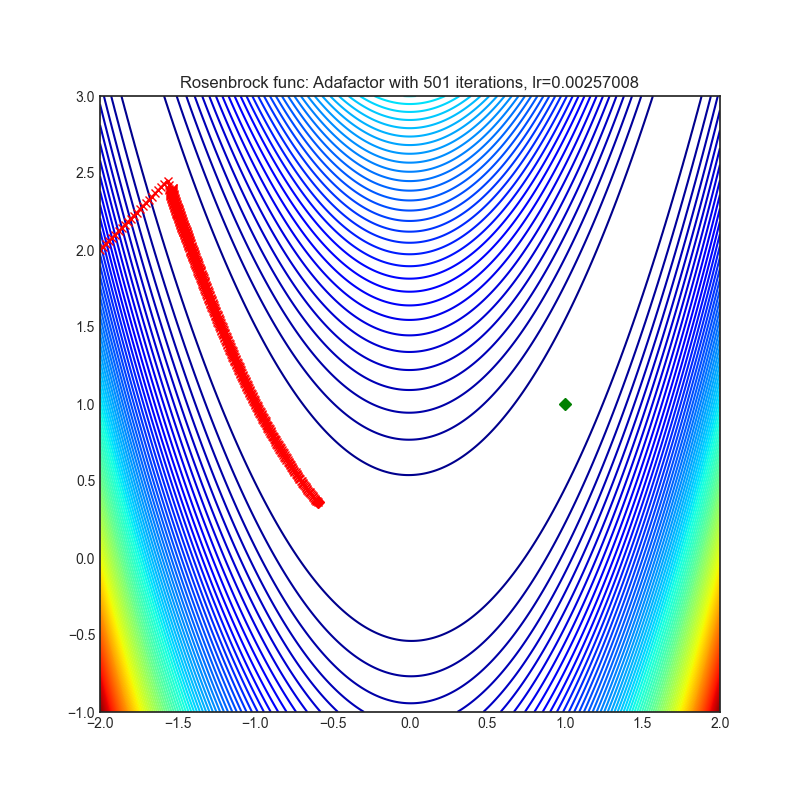
Adafactor
+------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_Adafactor.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_Adafactor.png | +------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------+
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.Adafactor(
m.parameters(),
lr= 1e-3,
eps2= (1e-30, 1e-3),
clip_threshold=1.0,
decay_rate=-0.8,
beta1=None,
weight_decay=0.0,
scale_parameter=True,
relative_step=True,
warmup_init=False,
)
optimizer.step()
Paper: Adafactor: Adaptive Learning Rates with Sublinear Memory Cost. (2018) [https://arxiv.org/abs/1804.04235]
Reference Code: https://github.com/pytorch/fairseq/blob/master/fairseq/optim/adafactor.py
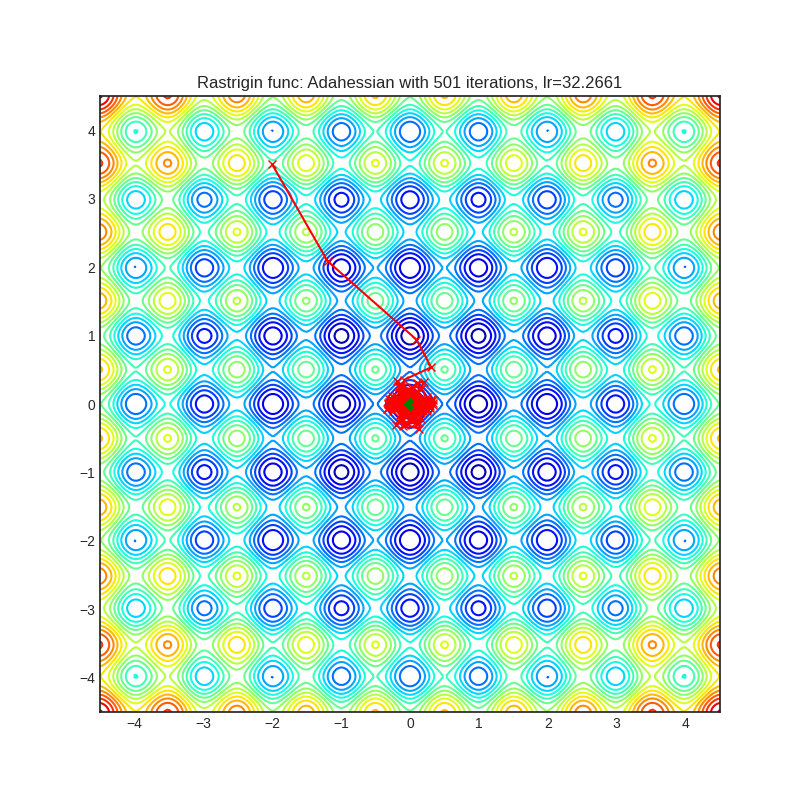
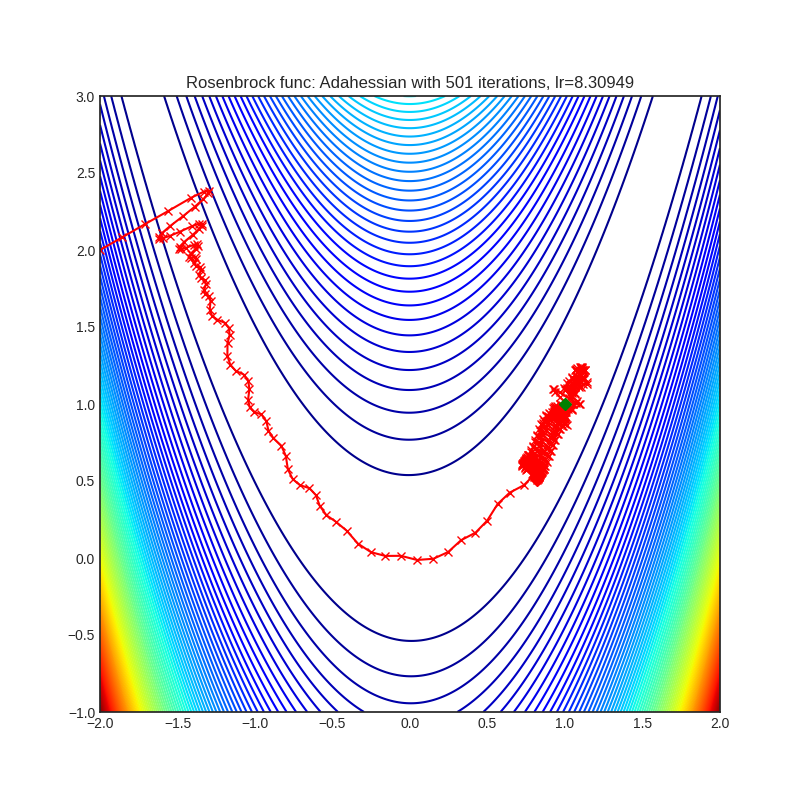
Adahessian
+-------------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_Adahessian.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_Adahessian.png | +-------------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------------+
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.Adahessian(
m.parameters(),
lr= 1.0,
betas= (0.9, 0.999),
eps= 1e-4,
weight_decay=0.0,
hessian_power=1.0,
)
loss_fn(m(input), target).backward(create_graph = True) # create_graph=True is necessary for Hessian calculation
optimizer.step()
Paper: ADAHESSIAN: An Adaptive Second Order Optimizer for Machine Learning (2020) [https://arxiv.org/abs/2006.00719]
Reference Code: https://github.com/amirgholami/adahessian
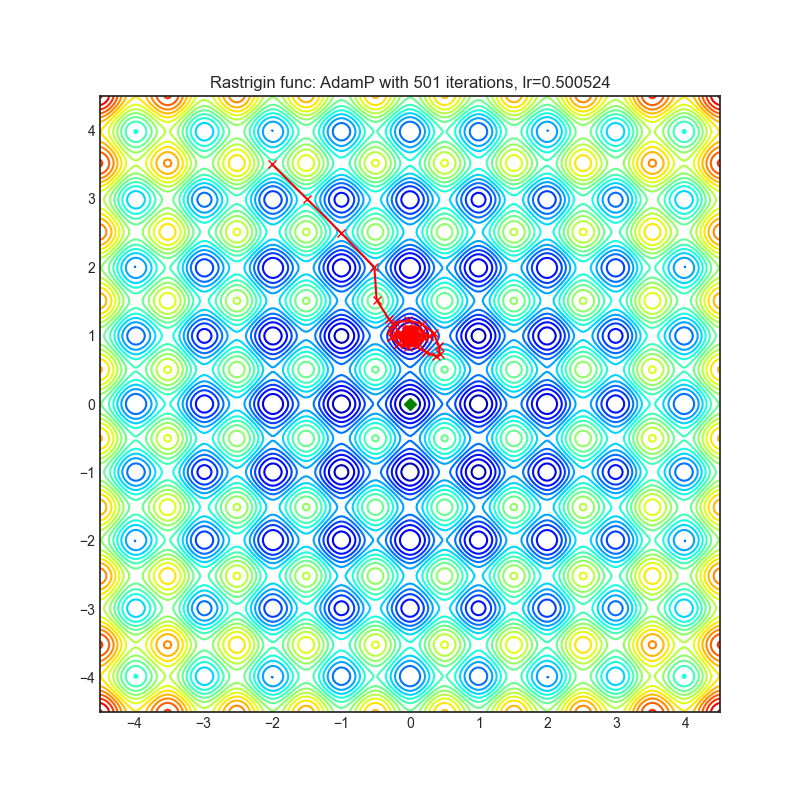
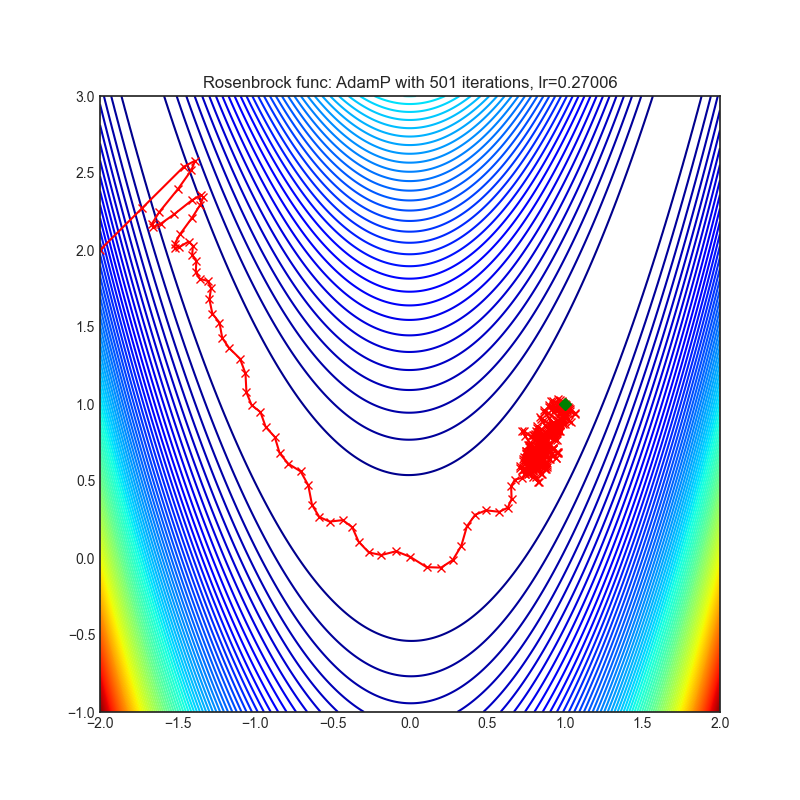
AdamP
AdamP propose a simple and effective solution: at each iteration of the Adam optimizer applied on scale-invariant weights (e.g., Conv weights preceding a BN layer), AdamP removes the radial component (i.e., parallel to the weight vector) from the update vector. Intuitively, this operation prevents the unnecessary update along the radial direction that only increases the weight norm without contributing to the loss minimization.
+------------------------------------------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_AdamP.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_AdamP.png | +------------------------------------------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------+
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.AdamP(
m.parameters(),
lr= 1e-3,
betas=(0.9, 0.999),
eps=1e-8,
weight_decay=0,
delta = 0.1,
wd_ratio = 0.1
)
optimizer.step()
Paper: Slowing Down the Weight Norm Increase in Momentum-based Optimizers. (2020) [https://arxiv.org/abs/2006.08217]
Reference Code: https://github.com/clovaai/AdamP
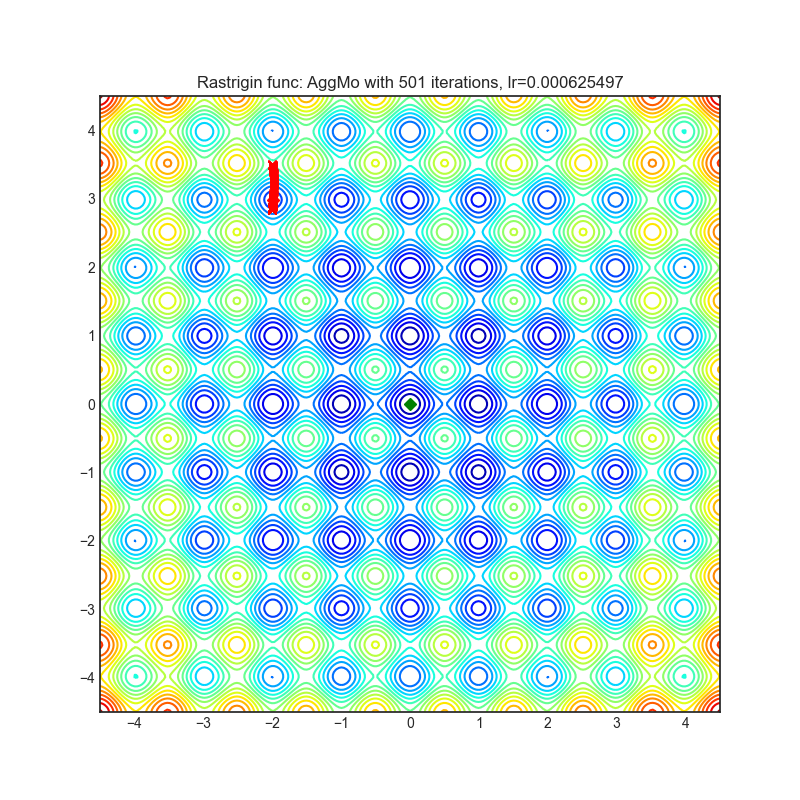
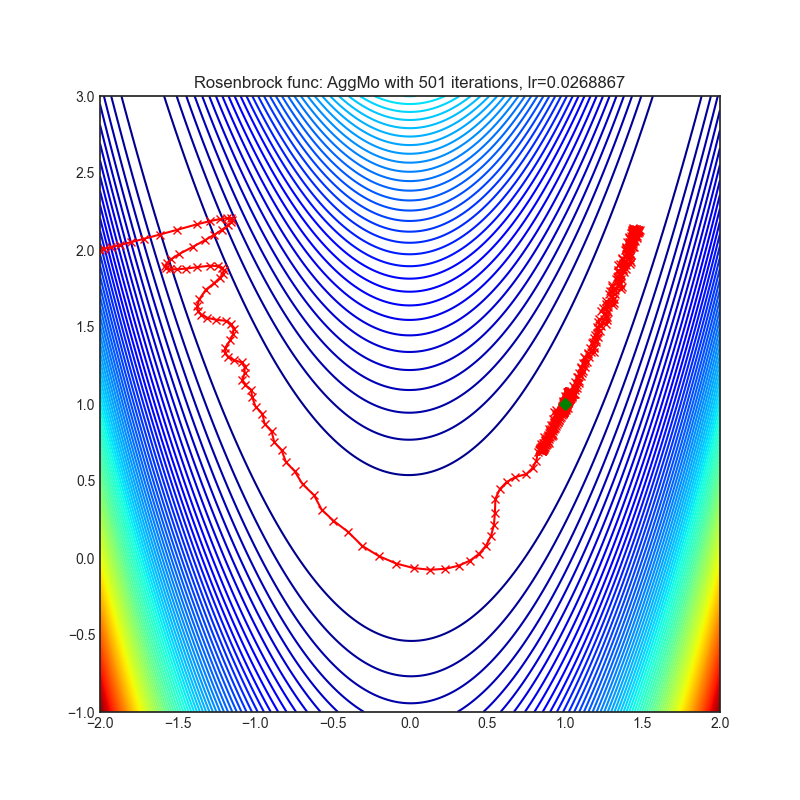
AggMo
+------------------------------------------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_AggMo.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_AggMo.png | +------------------------------------------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------+
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.AggMo(
m.parameters(),
lr= 1e-3,
betas=(0.0, 0.9, 0.99),
weight_decay=0,
)
optimizer.step()
Paper: Aggregated Momentum: Stability Through Passive Damping. (2019) [https://arxiv.org/abs/1804.00325]
Reference Code: https://github.com/AtheMathmo/AggMo
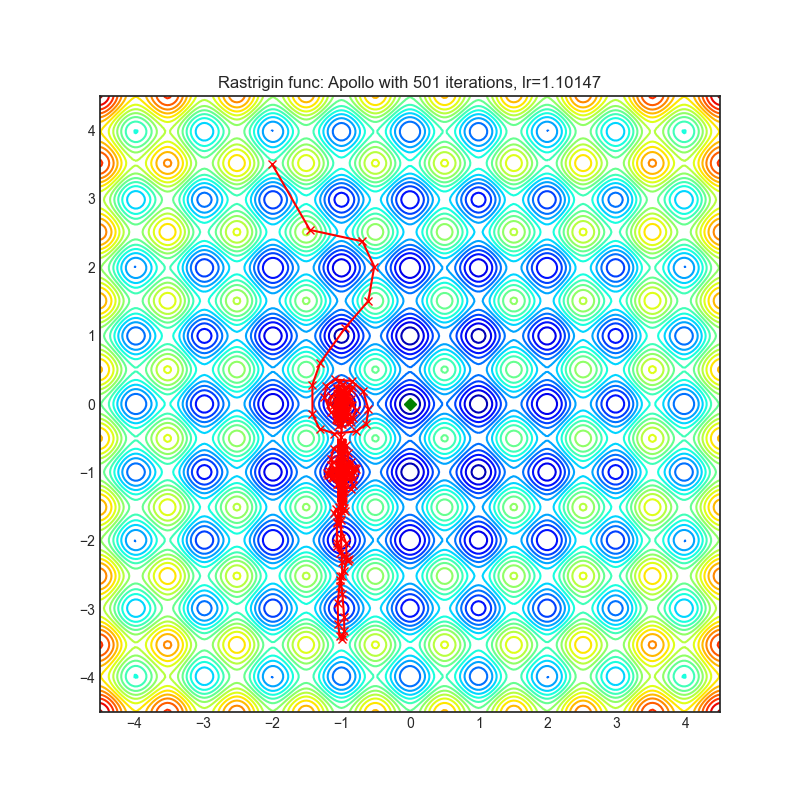
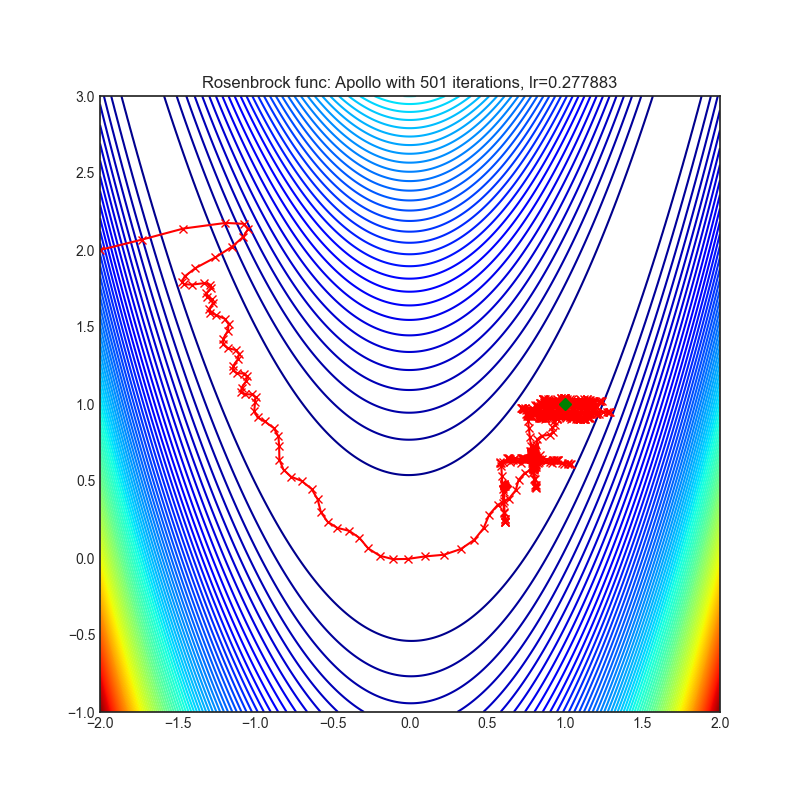
Apollo
+------------------------------------------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_Apollo.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_Apollo.png | +------------------------------------------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------+
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.Apollo(
m.parameters(),
lr= 1e-2,
beta=0.9,
eps=1e-4,
warmup=0,
init_lr=0.01,
weight_decay=0,
)
optimizer.step()
Paper: Apollo: An Adaptive Parameter-wise Diagonal Quasi-Newton Method for Nonconvex Stochastic Optimization. (2020) [https://arxiv.org/abs/2009.13586]
Reference Code: https://github.com/XuezheMax/apollo
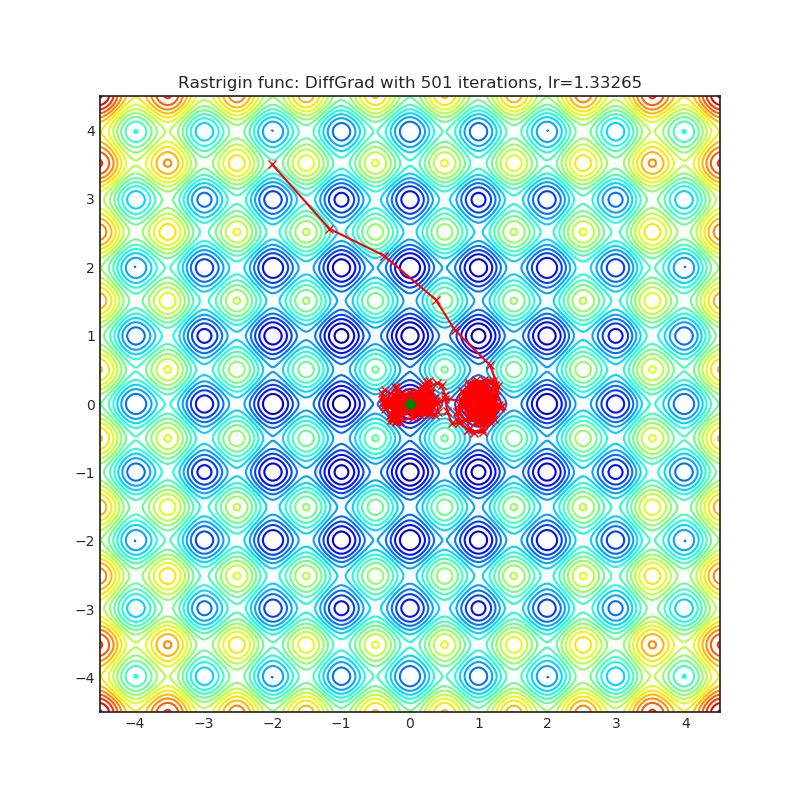
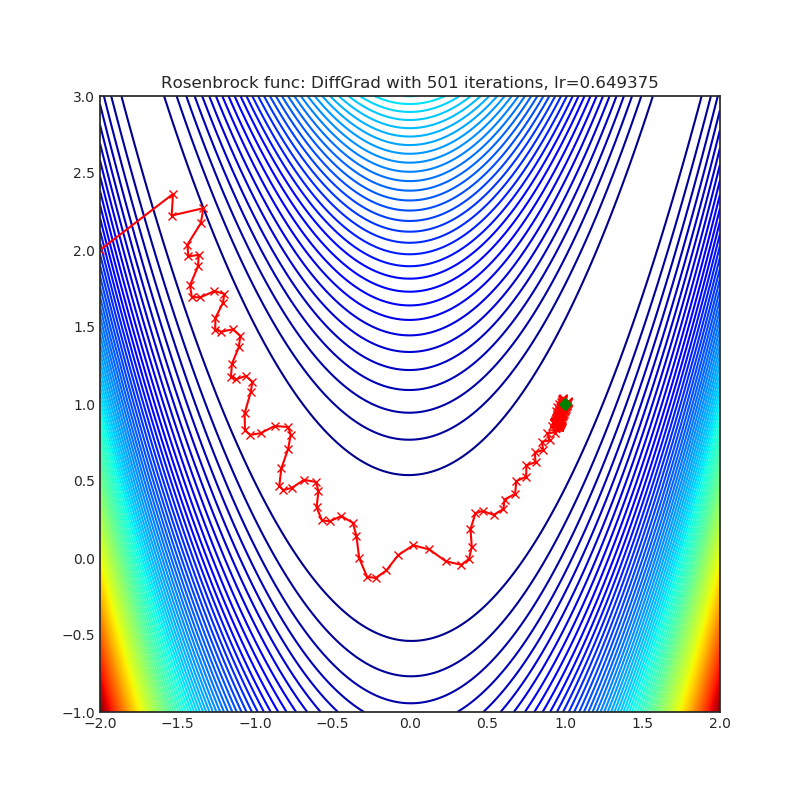
DiffGrad
Optimizer based on the difference between the present and the immediate past gradient, the step size is adjusted for each parameter in such a way that it should have a larger step size for faster gradient changing parameters and a lower step size for lower gradient changing parameters.
+------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_DiffGrad.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_DiffGrad.png | +------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------+
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.DiffGrad(
m.parameters(),
lr= 1e-3,
betas=(0.9, 0.999),
eps=1e-8,
weight_decay=0,
)
optimizer.step()
Paper: diffGrad: An Optimization Method for Convolutional Neural Networks. (2019) [https://arxiv.org/abs/1909.11015]
Reference Code: https://github.com/shivram1987/diffGrad
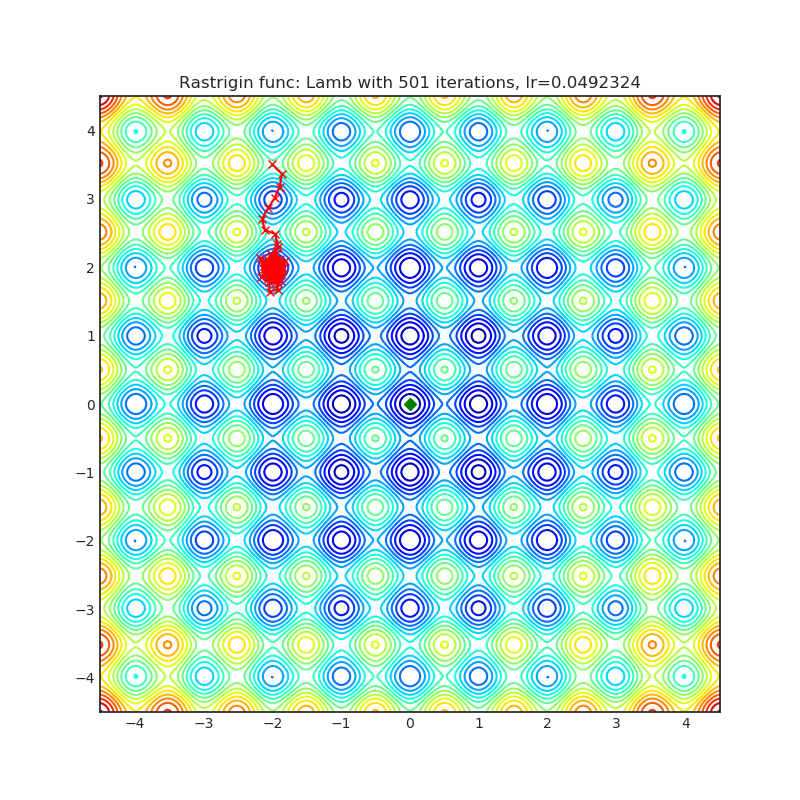
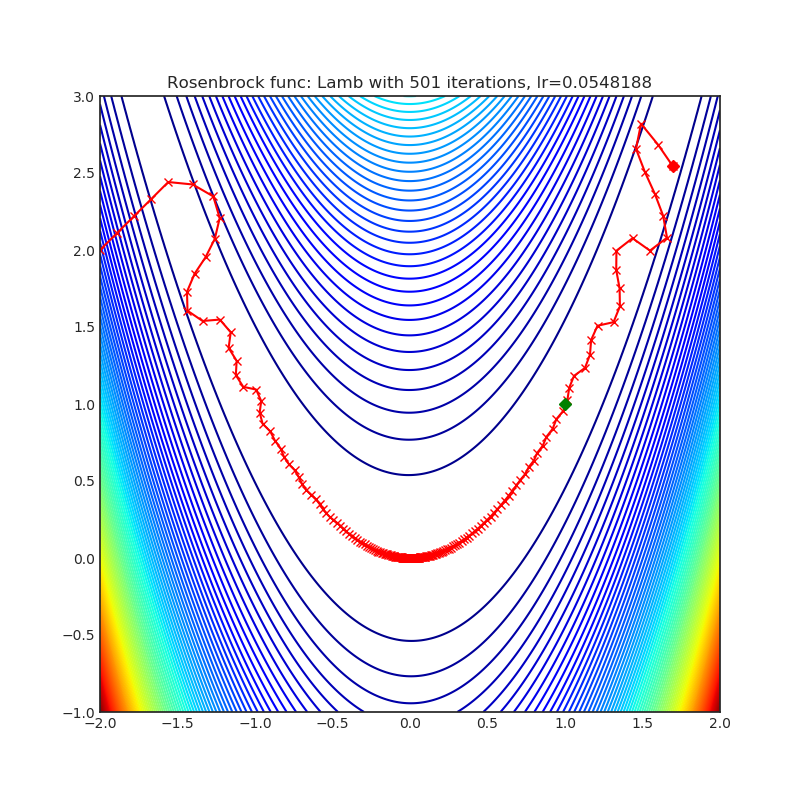
Lamb
+--------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_Lamb.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_Lamb.png | +--------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------+
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.Lamb(
m.parameters(),
lr= 1e-3,
betas=(0.9, 0.999),
eps=1e-8,
weight_decay=0,
)
optimizer.step()
Paper: Large Batch Optimization for Deep Learning: Training BERT in 76 minutes (2019) [https://arxiv.org/abs/1904.00962]
Reference Code: https://github.com/cybertronai/pytorch-lamb
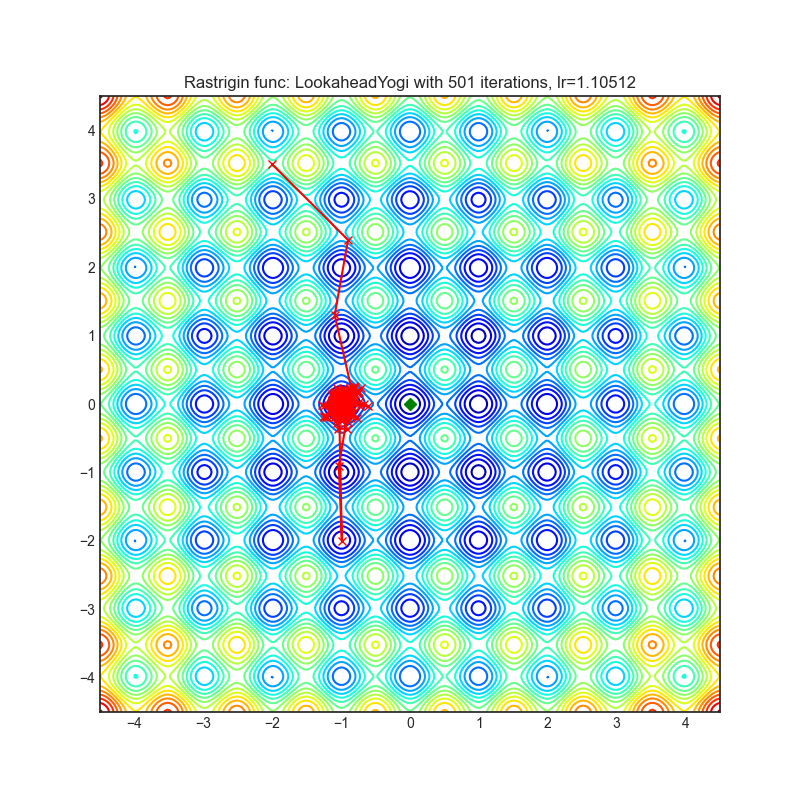
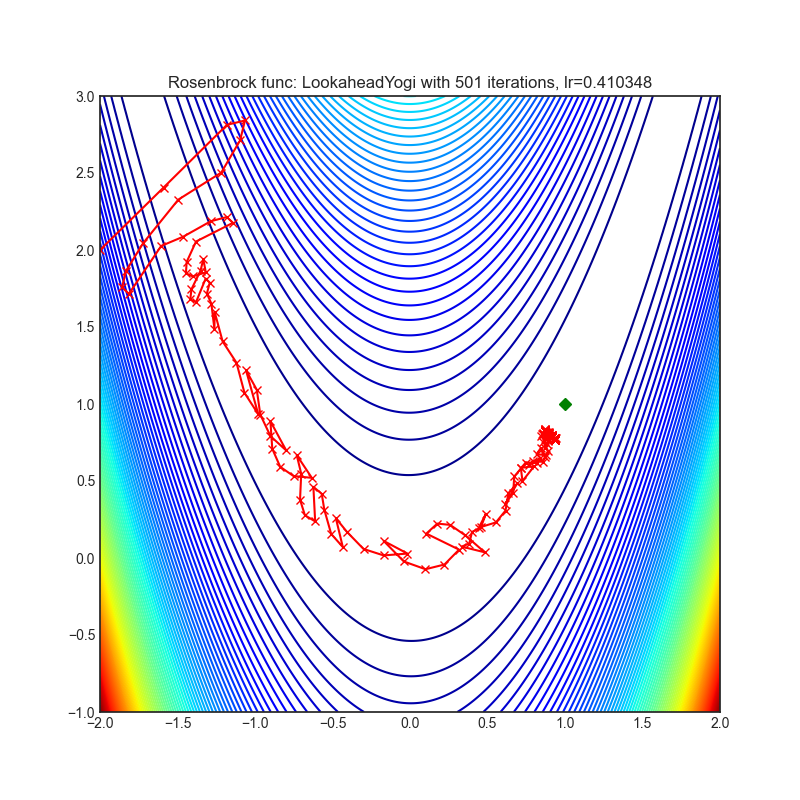
Lookahead
+-----------------------------------------------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_LookaheadYogi.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_LookaheadYogi.png | +-----------------------------------------------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------------+
.. code:: python
import torch_optimizer as optim
# model = ...
# base optimizer, any other optimizer can be used like Adam or DiffGrad
yogi = optim.Yogi(
m.parameters(),
lr= 1e-2,
betas=(0.9, 0.999),
eps=1e-3,
initial_accumulator=1e-6,
weight_decay=0,
)
optimizer = optim.Lookahead(yogi, k=5, alpha=0.5)
optimizer.step()
Paper: Lookahead Optimizer: k steps forward, 1 step back (2019) [https://arxiv.org/abs/1907.08610]
Reference Code: https://github.com/alphadl/lookahead.pytorch
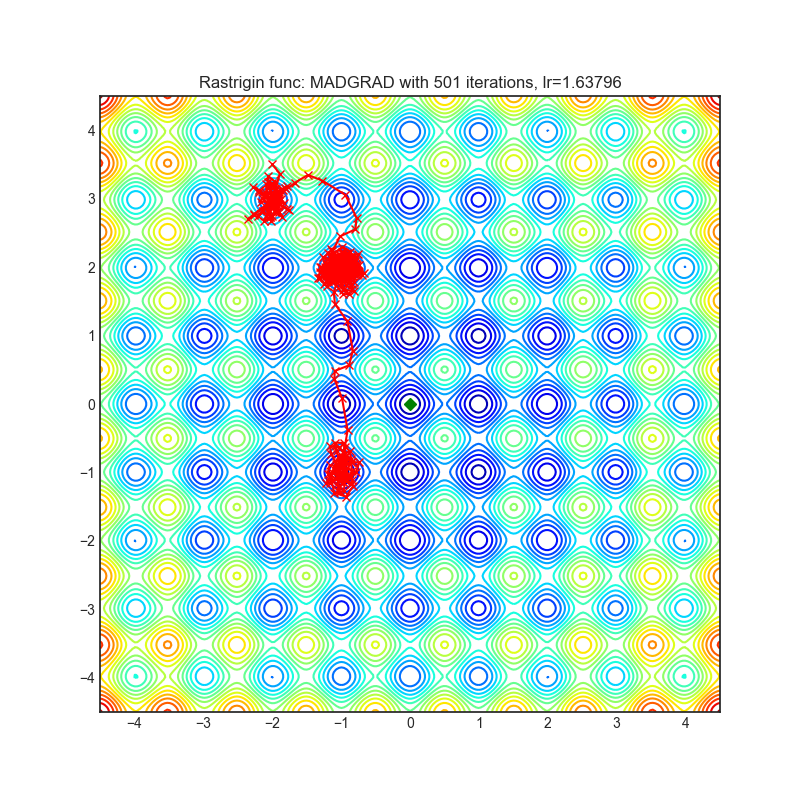
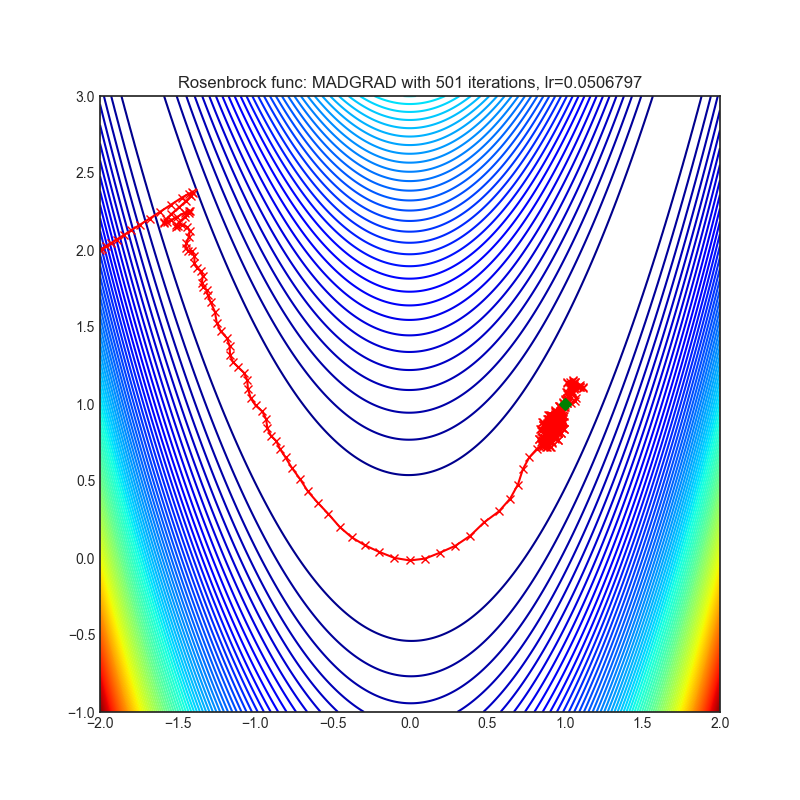
MADGRAD
+-----------------------------------------------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_MADGRAD.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_MADGRAD.png | +-----------------------------------------------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------------+
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.MADGRAD(
m.parameters(),
lr=1e-2,
momentum=0.9,
weight_decay=0,
eps=1e-6,
)
optimizer.step()
Paper: Adaptivity without Compromise: A Momentumized, Adaptive, Dual Averaged Gradient Method for Stochastic Optimization (2021) [https://arxiv.org/abs/2101.11075]
Reference Code: https://github.com/facebookresearch/madgrad
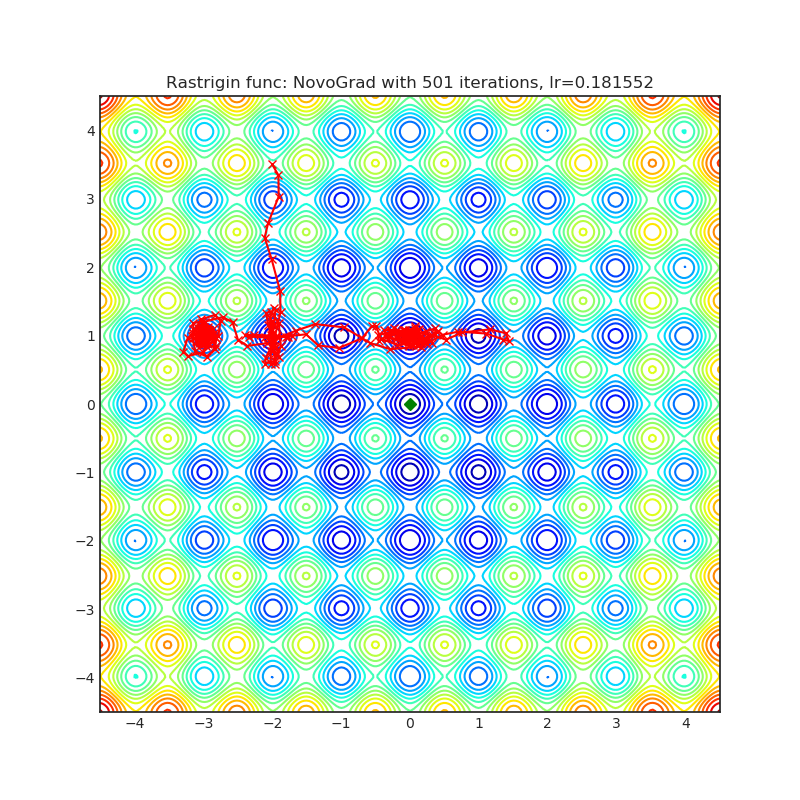
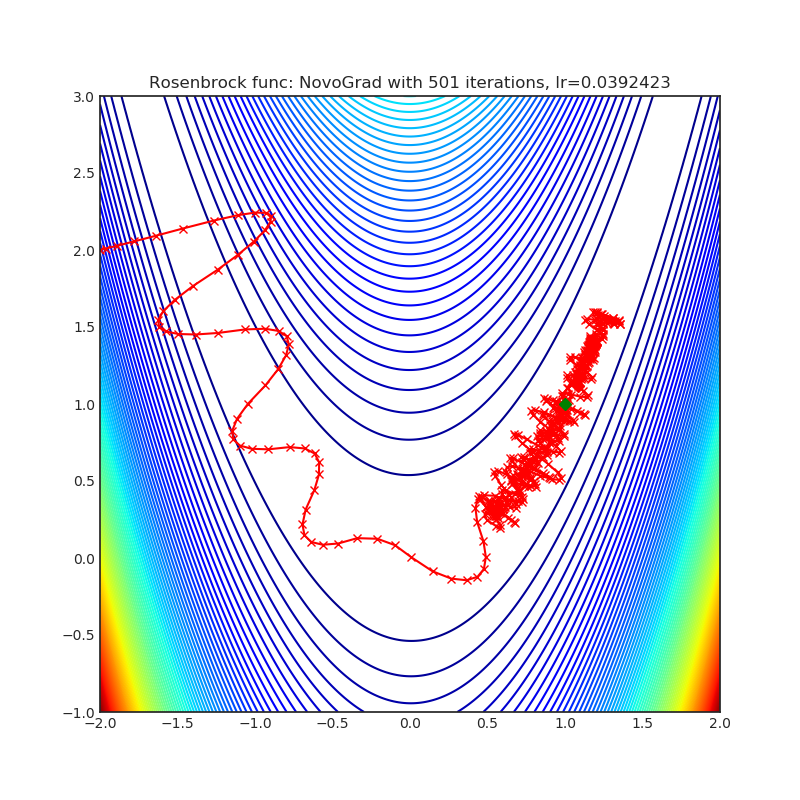
NovoGrad
+------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_NovoGrad.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_NovoGrad.png | +------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------+
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.NovoGrad(
m.parameters(),
lr= 1e-3,
betas=(0.9, 0.999),
eps=1e-8,
weight_decay=0,
grad_averaging=False,
amsgrad=False,
)
optimizer.step()
Paper: Stochastic Gradient Methods with Layer-wise Adaptive Moments for Training of Deep Networks (2019) [https://arxiv.org/abs/1905.11286]
Reference Code: https://github.com/NVIDIA/DeepLearningExamples/
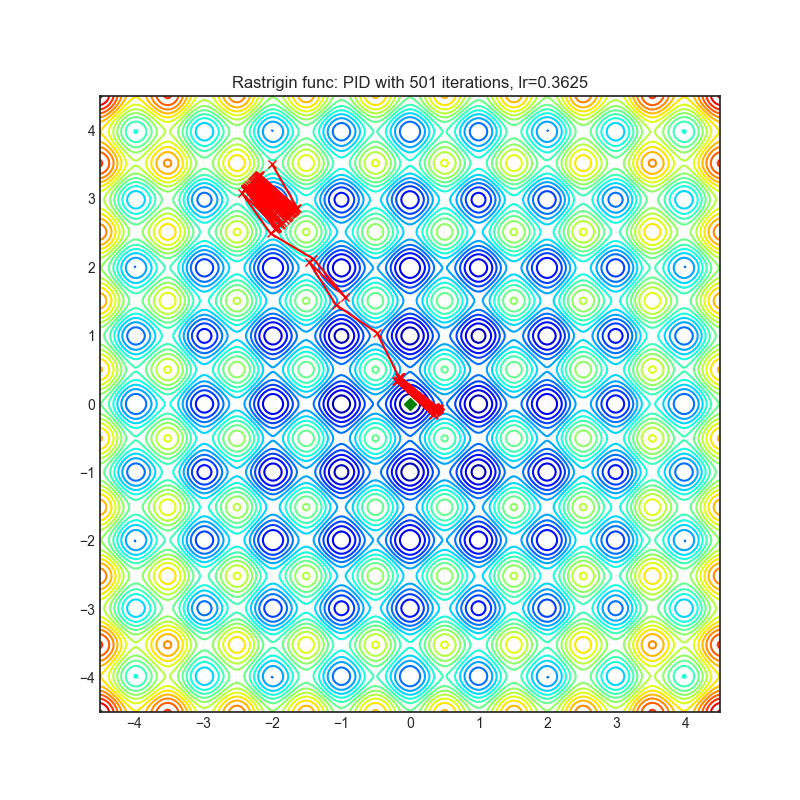
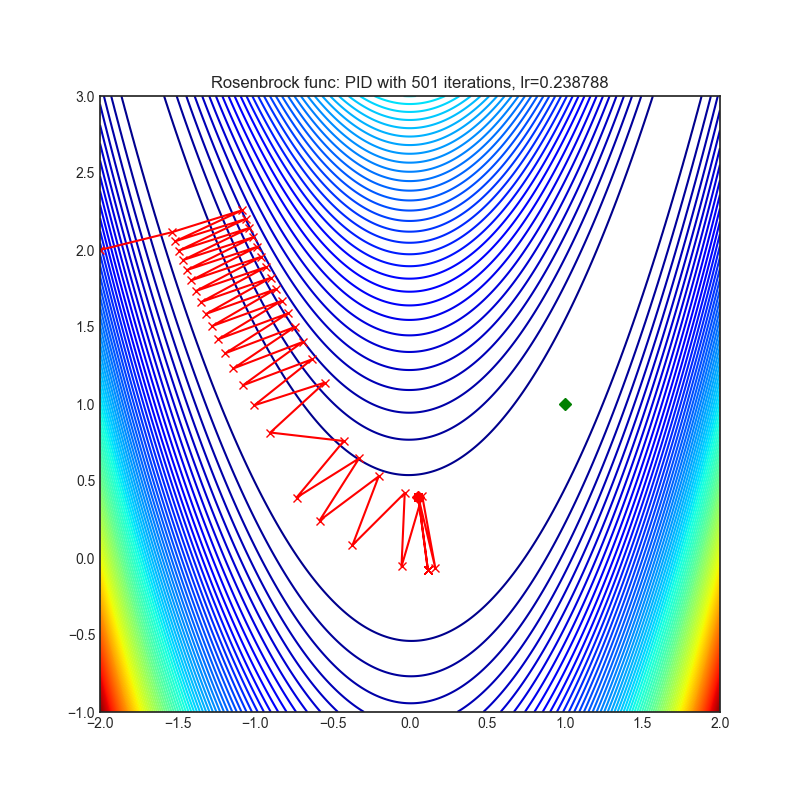
PID
+-------------------------------------------------------------------------------------------------------+---------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_PID.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_PID.png | +-------------------------------------------------------------------------------------------------------+---------------------------------------------------------------------------------------------------------+
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.PID(
m.parameters(),
lr=1e-3,
momentum=0,
dampening=0,
weight_decay=1e-2,
integral=5.0,
derivative=10.0,
)
optimizer.step()
Paper: A PID Controller Approach for Stochastic Optimization of Deep Networks (2018) [http://www4.comp.polyu.edu.hk/~cslzhang/paper/CVPR18_PID.pdf]
Reference Code: https://github.com/tensorboy/PIDOptimizer
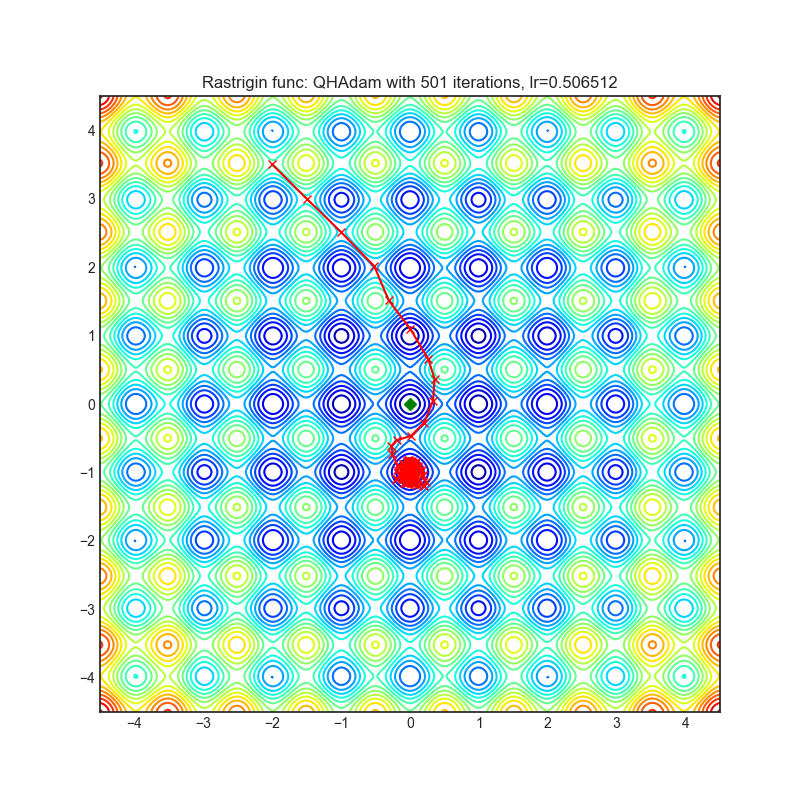
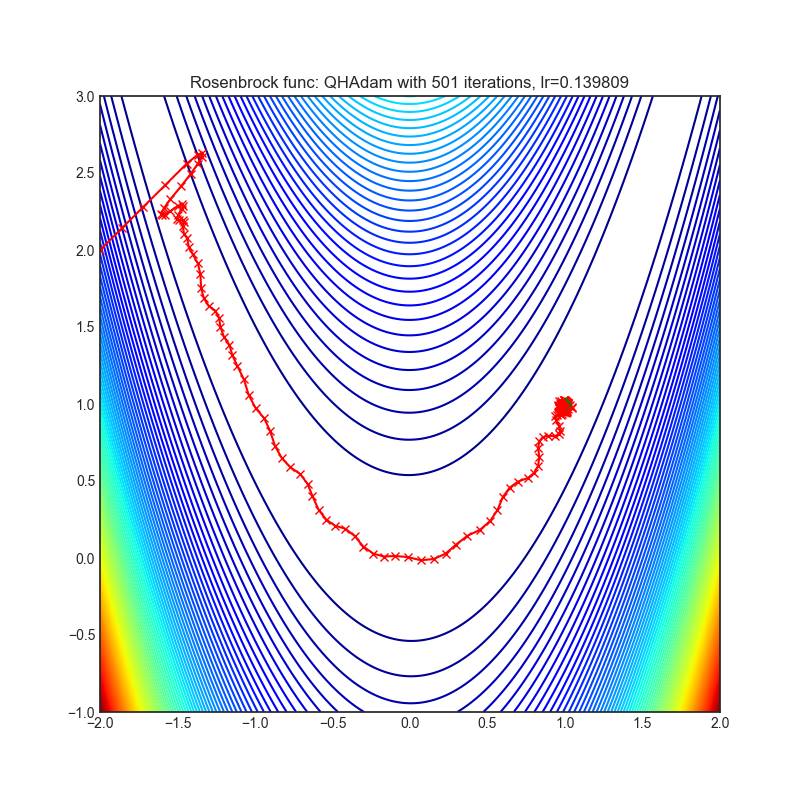
QHAdam
+----------------------------------------------------------------------------------------------------------+------------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_QHAdam.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_QHAdam.png | +----------------------------------------------------------------------------------------------------------+------------------------------------------------------------------------------------------------------------+
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.QHAdam(
m.parameters(),
lr= 1e-3,
betas=(0.9, 0.999),
nus=(1.0, 1.0),
weight_decay=0,
decouple_weight_decay=False,
eps=1e-8,
)
optimizer.step()
Paper: Quasi-hyperbolic momentum and Adam for deep learning (2019) [https://arxiv.org/abs/1810.06801]
Reference Code: https://github.com/facebookresearch/qhoptim
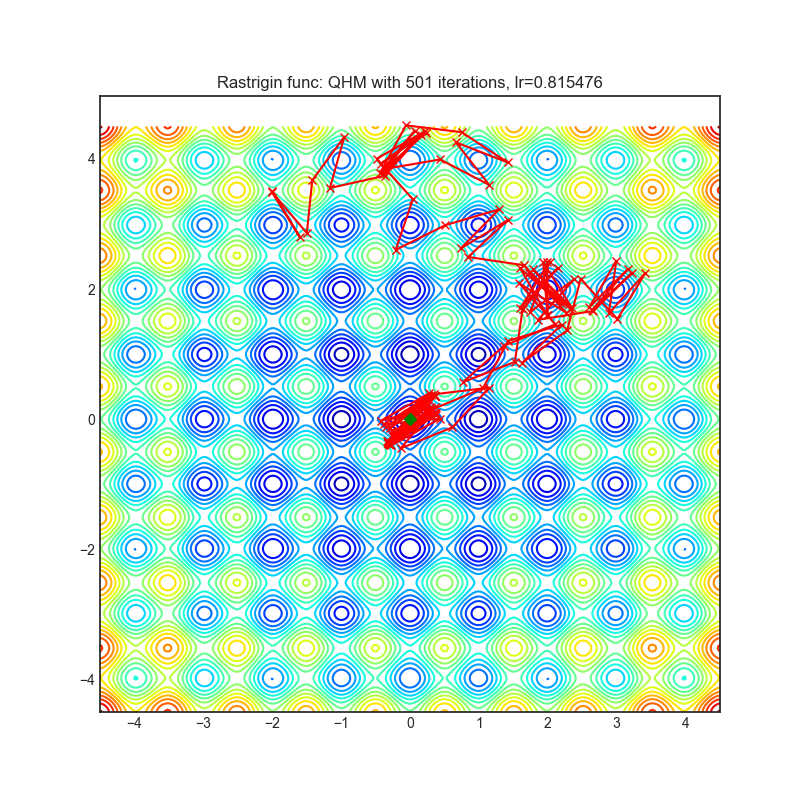
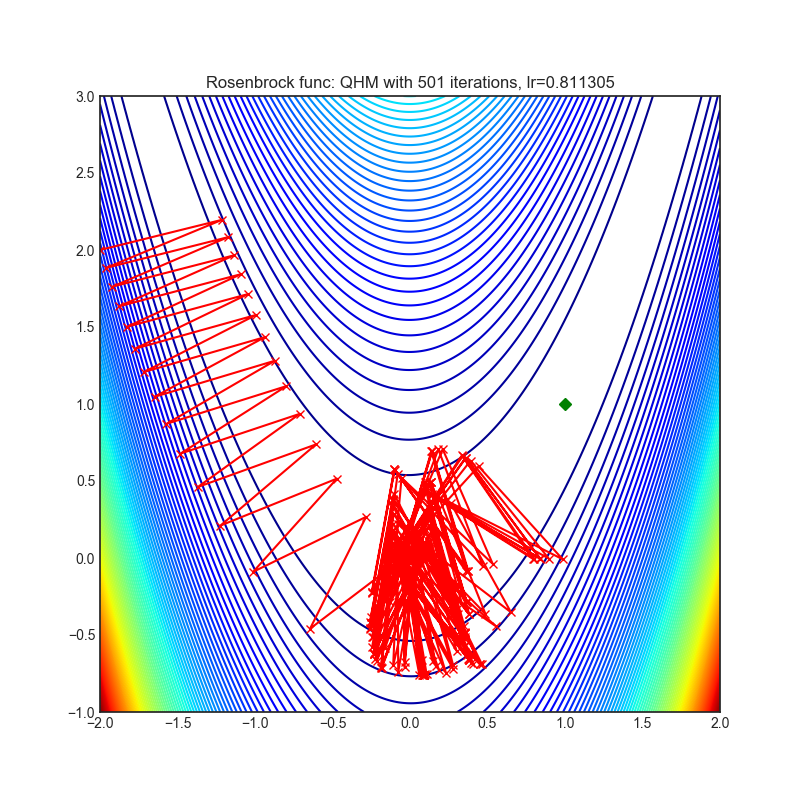
QHM
+-------------------------------------------------------------------------------------------------------+---------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_QHM.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_QHM.png | +-------------------------------------------------------------------------------------------------------+---------------------------------------------------------------------------------------------------------+
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.QHM(
m.parameters(),
lr=1e-3,
momentum=0,
nu=0.7,
weight_decay=1e-2,
weight_decay_type='grad',
)
optimizer.step()
Paper: Quasi-hyperbolic momentum and Adam for deep learning (2019) [https://arxiv.org/abs/1810.06801]
Reference Code: https://github.com/facebookresearch/qhoptim
RAdam
+---------------------------------------------------------------------------------------------------------+-----------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_RAdam.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_RAdam.png | +---------------------------------------------------------------------------------------------------------+-----------------------------------------------------------------------------------------------------------+
Deprecated, please use version provided by PyTorch_.
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.RAdam(
m.parameters(),
lr= 1e-3,
betas=(0.9, 0.999),
eps=1e-8,
weight_decay=0,
)
optimizer.step()
Paper: On the Variance of the Adaptive Learning Rate and Beyond (2019) [https://arxiv.org/abs/1908.03265]
Reference Code: https://github.com/LiyuanLucasLiu/RAdam
Ranger
+----------------------------------------------------------------------------------------------------------+------------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_Ranger.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_Ranger.png | +----------------------------------------------------------------------------------------------------------+------------------------------------------------------------------------------------------------------------+
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.Ranger(
m.parameters(),
lr=1e-3,
alpha=0.5,
k=6,
N_sma_threshhold=5,
betas=(.95, 0.999),
eps=1e-5,
weight_decay=0
)
optimizer.step()
Paper: New Deep Learning Optimizer, Ranger: Synergistic combination of RAdam + LookAhead for the best of both (2019) [https://medium.com/@lessw/new-deep-learning-optimizer-ranger-synergistic-combination-of-radam-lookahead-for-the-best-of-2dc83f79a48d]
Reference Code: https://github.com/lessw2020/Ranger-Deep-Learning-Optimizer
RangerQH
+------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_RangerQH.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_RangerQH.png | +------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------+
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.RangerQH(
m.parameters(),
lr=1e-3,
betas=(0.9, 0.999),
nus=(.7, 1.0),
weight_decay=0.0,
k=6,
alpha=.5,
decouple_weight_decay=False,
eps=1e-8,
)
optimizer.step()
Paper: Quasi-hyperbolic momentum and Adam for deep learning (2018) [https://arxiv.org/abs/1810.06801]
Reference Code: https://github.com/lessw2020/Ranger-Deep-Learning-Optimizer
RangerVA
+------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_RangerVA.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_RangerVA.png | +------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------+
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.RangerVA(
m.parameters(),
lr=1e-3,
alpha=0.5,
k=6,
n_sma_threshhold=5,
betas=(.95, 0.999),
eps=1e-5,
weight_decay=0,
amsgrad=True,
transformer='softplus',
smooth=50,
grad_transformer='square'
)
optimizer.step()
Paper: Calibrating the Adaptive Learning Rate to Improve Convergence of ADAM (2019) [https://arxiv.org/abs/1908.00700v2]
Reference Code: https://github.com/lessw2020/Ranger-Deep-Learning-Optimizer
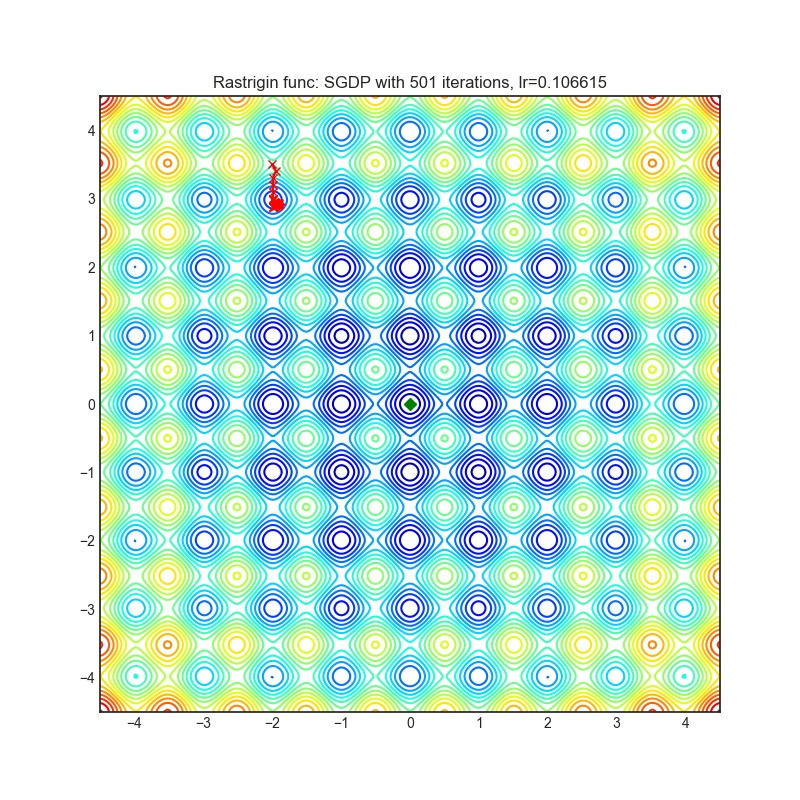
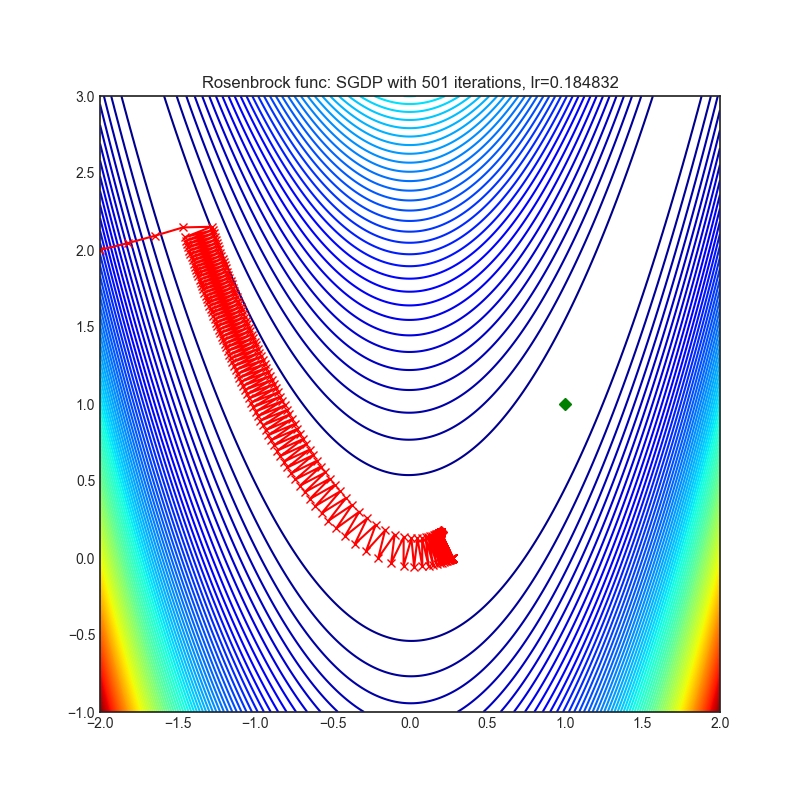
SGDP
+--------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_SGDP.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_SGDP.png | +--------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------+
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.SGDP(
m.parameters(),
lr= 1e-3,
momentum=0,
dampening=0,
weight_decay=1e-2,
nesterov=False,
delta = 0.1,
wd_ratio = 0.1
)
optimizer.step()
Paper: Slowing Down the Weight Norm Increase in Momentum-based Optimizers. (2020) [https://arxiv.org/abs/2006.08217]
Reference Code: https://github.com/clovaai/AdamP
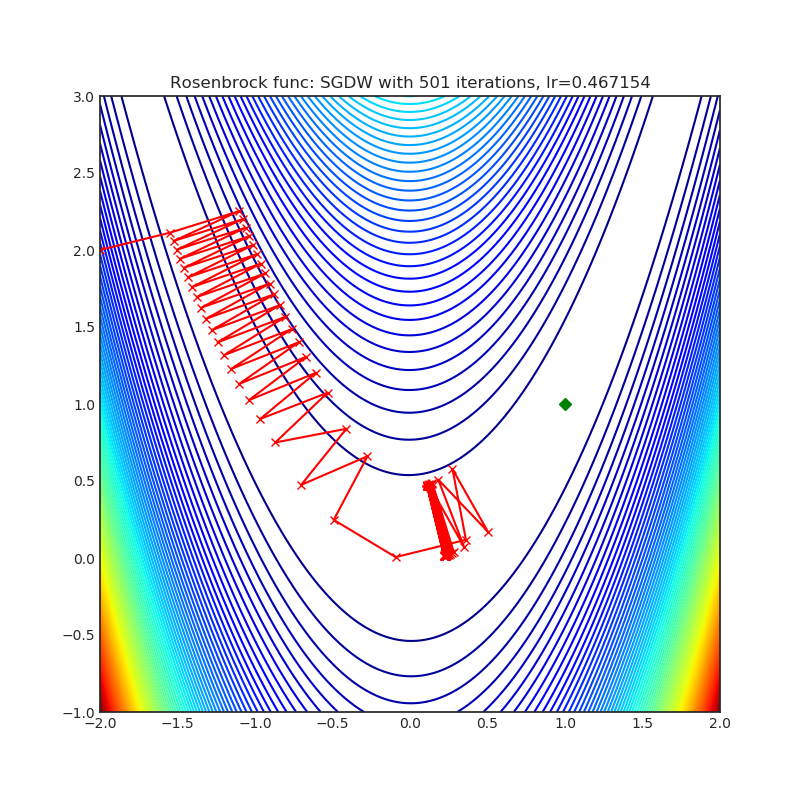
SGDW
+--------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_SGDW.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_SGDW.png | +--------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------+
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.SGDW(
m.parameters(),
lr= 1e-3,
momentum=0,
dampening=0,
weight_decay=1e-2,
nesterov=False,
)
optimizer.step()
Paper: SGDR: Stochastic Gradient Descent with Warm Restarts (2017) [https://arxiv.org/abs/1608.03983]
Reference Code: https://github.com/pytorch/pytorch/pull/22466
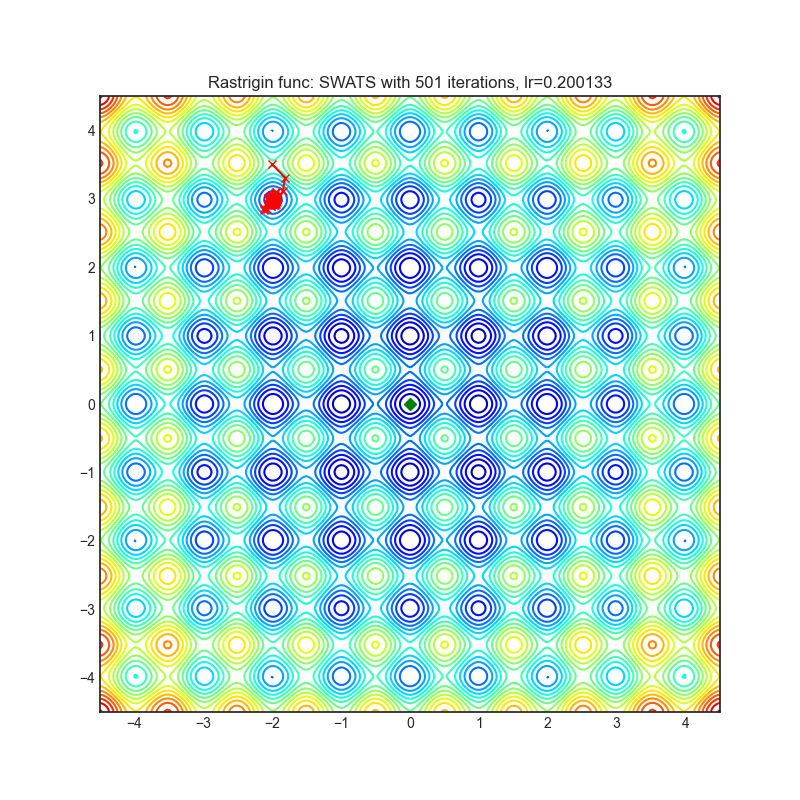
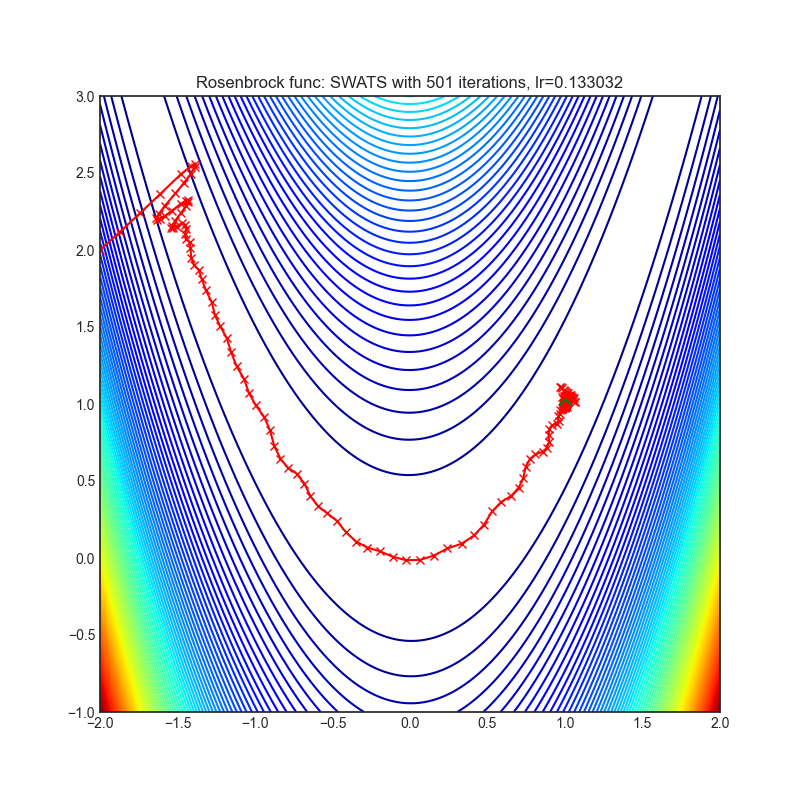
SWATS
+---------------------------------------------------------------------------------------------------------+-----------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_SWATS.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_SWATS.png | +---------------------------------------------------------------------------------------------------------+-----------------------------------------------------------------------------------------------------------+
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.SWATS(
model.parameters(),
lr=1e-1,
betas=(0.9, 0.999),
eps=1e-3,
weight_decay= 0.0,
amsgrad=False,
nesterov=False,
)
optimizer.step()
Paper: Improving Generalization Performance by Switching from Adam to SGD (2017) [https://arxiv.org/abs/1712.07628]
Reference Code: https://github.com/Mrpatekful/swats
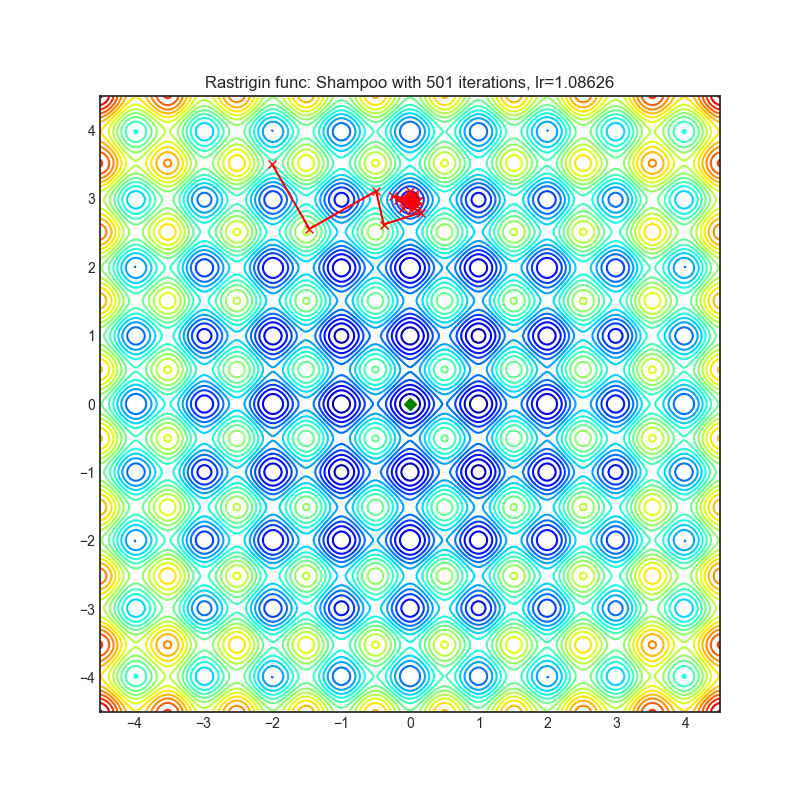
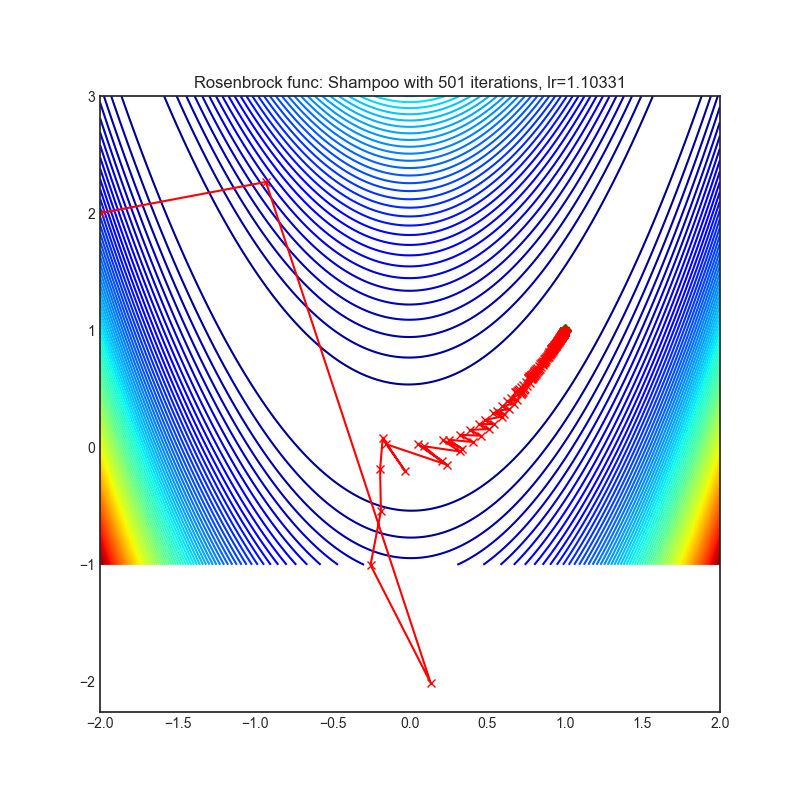
Shampoo
+-----------------------------------------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_Shampoo.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_Shampoo.png | +-----------------------------------------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------+
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.Shampoo(
m.parameters(),
lr=1e-1,
momentum=0.0,
weight_decay=0.0,
epsilon=1e-4,
update_freq=1,
)
optimizer.step()
Paper: Shampoo: Preconditioned Stochastic Tensor Optimization (2018) [https://arxiv.org/abs/1802.09568]
Reference Code: https://github.com/moskomule/shampoo.pytorch
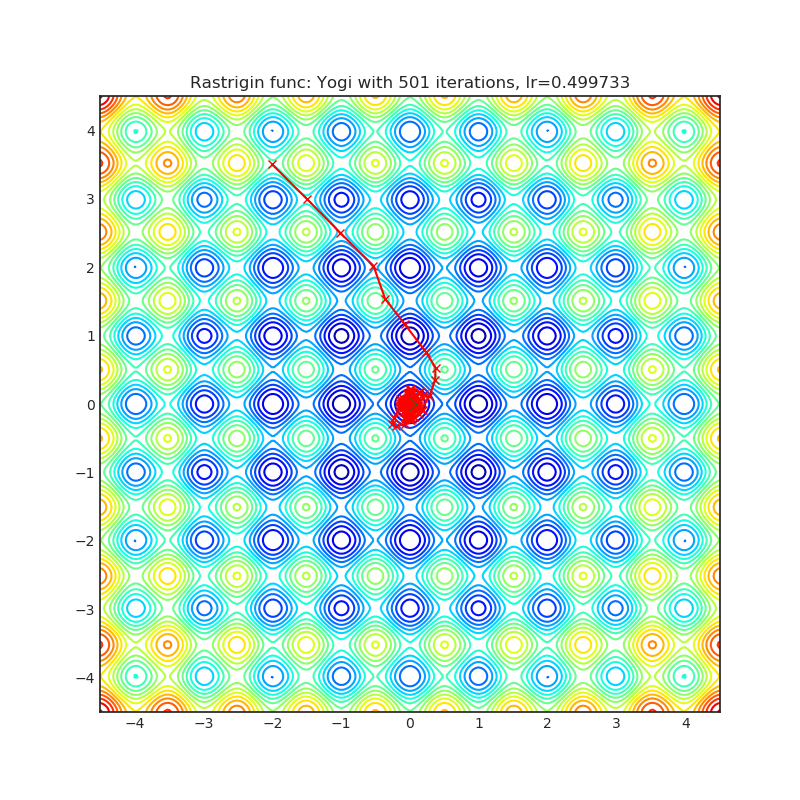
Yogi
Yogi is optimization algorithm based on ADAM with more fine grained effective learning rate control, and has similar theoretical guarantees on convergence as ADAM.
+--------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_Yogi.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_Yogi.png | +--------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------+
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.Yogi(
m.parameters(),
lr= 1e-2,
betas=(0.9, 0.999),
eps=1e-3,
initial_accumulator=1e-6,
weight_decay=0,
)
optimizer.step()
Paper: Adaptive Methods for Nonconvex Optimization (2018) [https://papers.nips.cc/paper/8186-adaptive-methods-for-nonconvex-optimization]
Reference Code: https://github.com/4rtemi5/Yogi-Optimizer_Keras
Adam (PyTorch built-in)
+---------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_Adam.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_Adam.png | +---------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------+
SGD (PyTorch built-in)
+--------------------------------------------------------------------------------------------------------+---------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_SGD.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_SGD.png | +--------------------------------------------------------------------------------------------------------+---------------------------------------------------------------------------------------------------------+
.. _Python: https://www.python.org .. _PyTorch: https://github.com/pytorch/pytorch .. _Rastrigin: https://en.wikipedia.org/wiki/Rastrigin_function .. _Rosenbrock: https://en.wikipedia.org/wiki/Rosenbrock_function .. _benchmark: https://en.wikipedia.org/wiki/Test_functions_for_optimization .. _optim: https://pytorch.org/docs/stable/optim.html

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}