Pytorch Geometric Versions Save
Graph Neural Network Library for PyTorch
2.5.3
3 weeks agoPyG 2.5.3 includes a variety of bug fixes related to the MessagePassing refactoring.
Bug Fixes
- Ensure backward compatibility in
MessagePassingviatorch.load(#9105) - Prevent model compilation on custom
propagatefunctions (#9079) - Flush template file before closing it (#9151)
- Do not set
propagatemethod twice inMessagePassingfordecomposed_layers > 1(#9198)
Full Changelog: https://github.com/pyg-team/pytorch_geometric/compare/2.5.2...2.5.3
2.5.2
1 month agoPyG 2.5.2 includes a bug fix for implementing MessagePassing layers in Google Colab.
Bug Fixes
- Raise error in case
inspect.get_sourceis not supported (#9068)
Full Changelog: https://github.com/pyg-team/pytorch_geometric/compare/2.5.1...2.5.2
2.5.1
2 months agoPyG 2.5.1 includes a variety of bugfixes.
Bug Fixes
- Ignore
self.propagateappearances in comments when parsingMessagePassingimplementation (#9044) - Fixed
OSErroron read-only file systems withinMessagePassing(#9032) - Made
MessagePassinginterface thread-safe (#9001) - Fixed metaclass conflict in
Dataset(#8999) - Fixed import errors on
MessagePassingmodules with nested inheritance (#8973) - Fix
OSErrorwhen downloading datasets withsimplecache(#8932)
Full Changelog: https://github.com/pyg-team/pytorch_geometric/compare/2.5.0...2.5.1
2.5.0
3 months agoWe are excited to announce the release of PyG 2.5 🎉🎉🎉
PyG 2.5 is the culmination of work from 38 contributors who have worked on features and bug-fixes for a total of over 360 commits since torch-geometric==2.4.0.
Highlights
torch_geometric.distributed
We are thrilled to announce the first in-house distributed training solution for PyG via the torch_geometric.distributed sub-package. Developers and researchers can now take full advantage of distributed training on large-scale datasets which cannot be fully loaded in memory of one machine at the same time. This implementation doesn't require any additional packages to be installed on top of the default PyG stack.
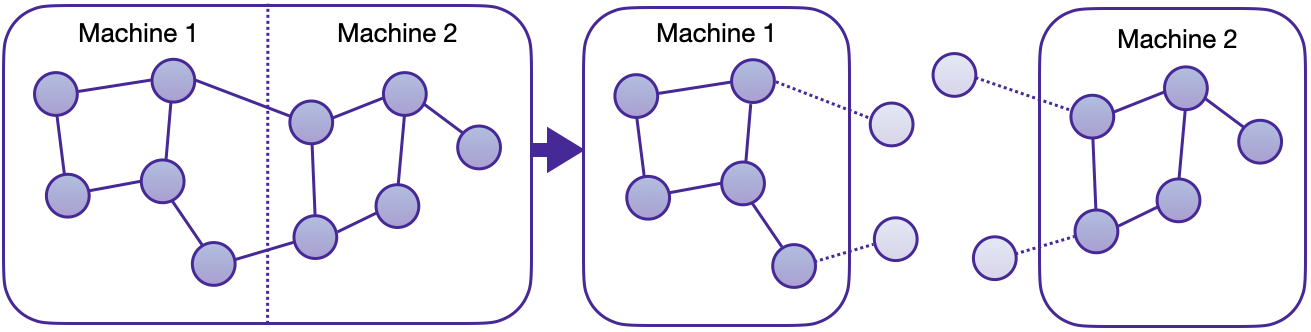
Key Advantages
- Balanced graph partitioning via METIS ensures minimal communication overhead when sampling subgraphs across compute nodes.
- Utilizing DDP for model training in conjunction with RPC for remote sampling and feature fetching routines (with TCP/IP protocol and gloo communication backend) allows for data parallelism with distinct data partitions at each node.
- The implementation via custom
GraphStoreandFeatureStoreAPIs provides a flexible and tailored interface for distributing large graph structure information and feature storage. - Distributed neighbor sampling is capable of sampling in both local and remote partitions through RPC communication channels. All advanced functionality of single-node sampling are also applicable for distributed training, e.g., heterogeneous sampling, link-level sampling, temporal sampling, etc.
- Distributed data loaders offer a high-level abstraction for managing sampler processes, ensuring simplicity and seamless integration with standard PyG data loaders.
See here for the accompanying tutorial. In addition, we provide two distributed examples in examples/distributed/pyg to get started:
-
Distributed node-level classification on
ogbn-products -
Distributed temporal link prediction on
MovieLens
EdgeIndex Tensor Representation
torch-geometric==2.5.0 introduces the EdgeIndex class.
EdgeIndex is a torch.Tensor, that holds an edge_index representation of shape [2, num_edges]. Edges are given as pairwise source and destination node indices in sparse COO format. While EdgeIndex sub-classes a general torch.Tensor, it can hold additional (meta)data, i.e.:
-
sparse_size: The underlying sparse matrix size -
sort_order: The sort order (if present), either by row or column -
is_undirected: Whether edges are bidirectional.
Additionally, EdgeIndex caches data for fast CSR or CSC conversion in case its representation is sorted (i.e. its rowptr or colptr). Caches are filled based on demand (e.g., when calling EdgeIndex.sort_by()), or when explicitly requested via EdgeIndex.fill_cache_(), and are maintained and adjusted over its lifespan (e.g., when calling EdgeIndex.flip()).
from torch_geometric import EdgeIndex
edge_index = EdgeIndex(
[[0, 1, 1, 2],
[1, 0, 2, 1]]
sparse_size=(3, 3),
sort_order='row',
is_undirected=True,
device='cpu',
)
>>> EdgeIndex([[0, 1, 1, 2],
... [1, 0, 2, 1]])
assert edge_index.is_sorted_by_row
assert edge_index.is_undirected
# Flipping order:
edge_index = edge_index.flip(0)
>>> EdgeIndex([[1, 0, 2, 1],
... [0, 1, 1, 2]])
assert edge_index.is_sorted_by_col
assert edge_index.is_undirected
# Filtering:
mask = torch.tensor([True, True, True, False])
edge_index = edge_index[:, mask]
>>> EdgeIndex([[1, 0, 2],
... [0, 1, 1]])
assert edge_index.is_sorted_by_col
assert not edge_index.is_undirected
# Sparse-Dense Matrix Multiplication:
out = edge_index.flip(0) @ torch.randn(3, 16)
assert out.size() == (3, 16)
EdgeIndex is implemented through extending torch.Tensor via the __torch_function__ interface (see here for the highly recommended tutorial).
EdgeIndex ensures for optimal computation in GNN message passing schemes, while preserving the ease-of-use of regular COO-based PyG workflows. EdgeIndex will fully deprecate the usage of SparseTensor from torch-sparse in later releases, leaving us with just a single source of truth for representing graph structure information in PyG.
RecSys Support
Previously, all/most of our link prediction models were trained and evaluated using binary classification metrics. However, this usually requires that we have a set of candidates in advance, from which we can then infer the existence of links. This is not necessarily practical, since in most cases, we want to find the top-k most likely links from the full set of O(N^2) pairs.
torch-geometric==2.5.0 brings full support for using GNNs as a recommender system (#8452), including support for
-
Maximum Inner Product Search (MIPS) via
MIPSKNNIndex -
Retrieval metrics such as
f1@k,map@k,precision@k,recall@kandndcg@k, including mini-batch support
mips = MIPSKNNIndex(dst_emb)
for src_batch in src_loader:
src_emb = model(src_batch.x_dict, src_batch.edge_index_dict)
_, pred_index_mat = mips.search(src_emb, k)
for metric in retrieval_metrics:
metric.update(pred_index_mat, edge_label_index)
for metric in retrieval_metrics:
metric.compute()
See here for the accompanying example.
PyTorch 2.2 Support
PyG 2.5 is fully compatible with PyTorch 2.2 (#8857), and supports the following combinations:
| PyTorch 2.2 | cpu |
cu118 |
cu121 |
|---|---|---|---|
| Linux | ✅ | ✅ | ✅ |
| macOS | ✅ | ||
| Windows | ✅ | ✅ | ✅ |
You can still install PyG 2.5 with an older PyTorch release up to PyTorch 1.12 in case you are not eager to update your PyTorch version.
Native torch.compile(...) and TorchScript Support
torch-geometric==2.5.0 introduces a full re-implementation of the MessagePassing interface, which makes it natively applicable to both torch.compile and TorchScript. As such, torch_geometric.compile is now fully deprecated in favor of torch.compile
- model = torch_geometric.compile(model)
+ model = torch.compile(model)
and MessagePassing.jittable() is now a no-op:
- conv = torch.jit.script(conv.jittable())
+ model = torch.jit.script(conv)
In addition, torch.compile usage has been fixed to not require disabling of extension packages such as torch-scatter or torch-sparse.
New Tutorials, Examples, Models and Improvements
-
Tutorials
- Multi-Node Training using SLURM (#8071)
- Point Cloud Processing (#8015)
-
Examples
- Distributed training via
torch_geometric.distributed(examples/distributed/pyg/) (#8713) - Edge-level temporal sampling on a heterogeneous graph (
examples/hetero/temporal_link_pred.py) (#8383) - Edge-level temporal sampling on a heterogeneous graph with distributed training (
examples/distributed/pyg/temporal_link_movielens_cpu.py) (#8820) - Distributed training on XPU device (
examples/multi_gpu/distributed_sampling_xpu.py) (#8032) - Multi-node multi-GPU training on
ogbn-papers100M(examples/multi_gpu/papers100m_gcn_multinode.py) (#8070) - Naive model parallelism on multiple GPUs (
examples/multi_gpu/model_parallel.py) (#8309)
- Distributed training via
-
Models
- Added the equivariant
ViSNetfrom "ViSNet: an equivariant geometry-enhanced graph neural network with vector-scalar interactive message passing for molecules" (#8287)
- Added the equivariant
-
Improvements
- Enabled multi-GPU evaluation in distributed sampling example (
examples/multi_gpu/distributed_sampling.py) (#8880)
- Enabled multi-GPU evaluation in distributed sampling example (
Breaking Changes
-
GATConvnow initializes modules differently depending on whether their input is bipartite or non-bipartite (#8397). This will lead to issues when loading model state forGATConvlayers trained on earlier PyG versions.
Deprecations
- Deprecated
torch_geometric.compilein favor oftorch.compile(#8780) - Deprecated
torch_geometric.nn.DataParallelin favor oftorch.nn.parallel.DistributedDataParallel(#8250) - Deprecated
MessagePassing.jittable(#8781, #8731) - Deprecated
torch_geometric.data.makedirsin favor ofos.makedirs(#8421)
Features
Package-wide Improvements
- Added support for type checking via
mypy(#8254) - Added
fsspecas file system backend (#8379, #8426, #8434, #8474) - Added fallback code path for segment-based reductions in case
torch-scatteris not installed (#8852)
Temporal Graph Support
- Added support for edge-level temporal sampling in
NeighborLoaderandLinkNeighborLoader(#8372, #8428) - Added
Data.{sort_by_time,is_sorted_by_time,snapshot,up_to}for temporal graph use-cases (#8454) - Added support for graph partitioning for temporal data in
torch_geometric.distributed(#8718, #8815)
torch_geometric.datasets
- Added the Risk Commodity Detection Dataset (
RCDD) from "Datasets and Interfaces for Benchmarking Heterogeneous Graph Neural Networks" (#8196) - Added the
StochasticBlockModelDataset(num_graphs: int)argument (#8648) - Added support for floating-point average degree numbers in
FakeDatasetandFakeHeteroDataset(#8404) - Added
InMemoryDataset.to(device)(#8402) - Added the
force_reload: bool = Falseargument toDatasetandInMemoryDatasetin order to enforce re-processing of datasets (#8352, #8357, #8436) - Added the
TreeGraphandGridMotifgenerators (#8736)
torch_geometric.nn
- Added
KNNIndexexclusion logic (#8573) - Added support for MRR computation in
KGEModel.test()(#8298) - Added support for
nn.to_hetero_with_baseson static graphs (#8247) - Addressed graph breaks in
ModuleDict,ParameterDict,MultiAggregationandHeteroConvfor better support fortorch.compile(#8363, #8345, #8344)
torch_geometric.metrics
- Added support for
f1@k,map@k,precision@k,recall@kandndcg@kmetrics for link-prediction retrieval tasks (#8499, #8326, #8566, #8647)
torch_geometric.explain
- Enabled skipping explanations of certain message passing layers via
conv.explain = False(#8216) - Added support for visualizing explanations with node labels via
visualize_graph(node_labels: list[str] | None)argument (#8816)
torch_geometric.transforms
- Added a faster dense computation code path in
AddRandomWalkPE(#8431)
Other Improvements
- Added support for returning multi graphs in
utils.to_networkx(#8575) - Added noise scheduler utilities
utils.noise_scheduler.{get_smld_sigma_schedule,get_diffusion_beta_schedule}for diffusion-based graph generative models (#8347) - Added a relabel node functionality to
utils.dropout_nodeviarelabel_nodes: boolargument (#8524) - Added support for weighted
utils.cross_entropy.sparse_cross_entropy(#8340) - Added support for profiling on XPU device via
profile.profileit("xpu")(#8532) - Added METIS partitioning with CSC/CSR format selection in
ClusterData(#8438)
Bugfixes
- Fixed dummy value creation of boolean tensors in
HeteroData.to_homogeneous()(#8858) - Fixed Google Drive download issues (#8804)
- Fixed
InMemoryDatasetto reconstruct the correct data class when apre_transformhas modified it (#8692) - Fixed a bug in which transforms were not applied for
OnDiskDataset(#8663) - Fixed mini-batch computation in
DMoNPooingloss function (#8285) - Fixed
NaNhandling inSQLDatabase(#8479) - Fixed
CaptumExplainerin case noindexis passed (#8440) - Fixed
edge_indexconstruction in theUPFDdataset (#8413) - Fixed TorchScript support in
AttentionalAggregationandDeepSetsAggregation(#8406) - Fixed
GraphMaskExplainerfor GNNs with more than two layers (#8401) - Fixed
input_idcomputation inNeighborLoaderin case amaskis given (#8312) - Respect current device when deep-copying
Linearlayers (#8311) - Fixed
Data.subgraph()/HeteroData.subgraph()in caseedge_indexis not defined (#8277) - Fixed empty edge handling in
MetaPath2Vec(#8248) - Fixed
AttentionExplainerusage withinAttentiveFP(#8244) - Fixed
load_from_state_dictin lazyLinearmodules (#8242) - Fixed pre-trained
DimeNet++performance onQM9(#8239) - Fixed
GNNExplainerusage withinAttentiveFP(#8216) - Fixed
to_networkx(to_undirected=True)in case the input graph is not undirected (#8204) - Fixed sparse-sparse matrix multiplication support on Windows in
TwoHopandAddRandomWalkPEtransformations (#8197, #8225) - Fixed mini-batching of
HeteroDataobjects converted viaToSparseTensor()whentorch-sparseis not installed (#8356)
Changes
- Disallow the usage of
add_self_loops=TrueinGCNConv(normalize=False)(#8210) - Changed the default inference mode for
use_segment_matmulbased on benchmarking results (from a heuristic-based version) (#8615) - Sparse node features in
NELLandAttributedGraphDatasetare now represented astorch.sparse_csr_tensorinstead oftorch_sparse.SparseTensor(#8679) - Accelerated mini-batching of
torch.sparsetensors (#8670) -
ExplainerDatasetwill now contain node labels for any motif generator (#8519) - Made
utils.softmaxfaster via the in-housepyg_lib.ops.softmax_csrkernel (#8399) - Made
utils.mask.mask_selectfaster (#8369) - Added a warning when calling
Dataset.num_classeson regression datasets (#8550)
New Contributors
- @stadlmax made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/8207
- @joaquincabezas made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/8215
- @SZiesche made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/8201
- @666even666 made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/8268
- @irustandi made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/8274
- @joao-alex-cunha made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/8223
- @chaous made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/8309
- @songsong0425 made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/8298
- @rachitk made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/8356
- @pmpalang made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/8372
- @flxmr made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/8353
- @GuyAglionby made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/8401
- @plutonium-239 made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/8404
- @asherbondy made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/8379
- @wwang-chcn made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/8285
- @SimonPop made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/8326
- @brovatten made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/8566
- @XJTUNR made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/8287
- @kativenOG made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/8648
- @ilsenatorov made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/8663
- @dependabot made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/8706
- @Sutongtong233 made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/8736
- @m-atalla made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/8755
- @A-LOST-WAPITI made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/8818
- @AtomicVar made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/8825
- @vahanhov made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/8816
- @rraadd88 made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/8842
- @mashaan14 made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/8884
Full Changelog: https://github.com/pyg-team/pytorch_geometric/compare/2.4.0...2.5.0
2.4.0
7 months agoWe are excited to announce the release of PyG 2.4 🎉🎉🎉
PyG 2.4 is the culmination of work from 62 contributors who have worked on features and bug-fixes for a total of over 500 commits since torch-geometric==2.3.1.
Highlights
PyTorch 2.1 and torch.compile(dynamic=True) support
The long wait has an end! With the release of PyTorch 2.1, PyG 2.4 now brings full support for torch.compile to graphs of varying size via the dynamic=True option, which is especially useful for use-cases that involve the usage of DataLoader or NeighborLoader. Examples and tutorials have been updated to reflect this support accordingly (#8134), and models and layers in torch_geometric.nn have been tested to produce zero graph breaks:
import torch_geometric
model = torch_geometric.compile(model, dynamic=True)
When enabling the dynamic=True option, PyTorch will up-front attempt to generate a kernel that is as dynamic as possible to avoid recompilations when sizes change across mini-batches changes. As such, you should only ever not specify dynamic=True when graph sizes are guaranteed to never change. Note that dynamic=True requires PyTorch >= 2.1.0 to be installed.
PyG 2.4 is fully compatible with PyTorch 2.1, and supports the following combinations:
| PyTorch 2.1 | cpu |
cu118 |
cu121 |
|---|---|---|---|
| Linux | ✅ | ✅ | ✅ |
| macOS | ✅ | ||
| Windows | ✅ | ✅ | ✅ |
You can still install PyG 2.4 on older PyTorch releases up to PyTorch 1.11 in case you are not eager to update your PyTorch version.
OnDiskDataset Interface
We added the OnDiskDataset base class for creating large graph datasets (e.g., molecular databases with billions of graphs), which do not easily fit into CPU memory at once (#8028, #8044, #8046, #8051, #8052, #8054, #8057, #8058, #8066, #8088, #8092, #8106). OnDiskDataset leverages our newly introduced Database backend (sqlite3 by default) for on-disk storage and access of graphs, supports DataLoader out-of-the-box, and is optimized for maximum performance.
OnDiskDataset utilizes a user-specified schema to store data as efficient as possible (instead of Python pickling). The schema can take int, float str, object or a dictionary with dtype and size keys (for specifying tensor data) as input, and can be nested as a dictionary. For example,
dataset = OnDiskDataset(root, schema={
'x': dict(dtype=torch.float, size=(-1, 16)),
'edge_index': dict(dtype=torch.long, size=(2, -1)),
'y': float,
})
creates a database with three columns, where x and edge_index are stored as binary data, and y is stored as a float.
Afterwards, you can append data to the OnDiskDataset and retrieve data from it via dataset.append()/dataset.extend(), and dataset.get()/dataset.multi_get(), respectively. We added a fully working example on how to set up your own OnDiskDataset here (#8102). You can also convert in-memory dataset instances to an OnDiskDataset instance by running InMemoryDataset.to_on_disk_dataset() (#8116).
Neighbor Sampling Improvements
Hierarchical Sampling
One drawback of NeighborLoader is that it computes a representations for all sampled nodes at all depths of the network. However, nodes sampled in later hops no longer contribute to the node representations of seed nodes in later GNN layers, thus performing useless computation. NeighborLoader will be marginally slower since we are computing node embeddings for nodes we no longer need. This is a trade-off we have made to obtain a clean, modular and experimental-friendly GNN design, which does not tie the definition of the model to its utilized data loader routine.
With PyG 2.4, we introduced the option to eliminate this overhead and speed-up training and inference in mini-batch GNNs further, which we call "Hierarchical Neighborhood Sampling" (see here for the full tutorial) (#6661, #7089, #7244, #7425, #7594, #7942). Its main idea is to progressively trim the adjacency matrix of the returned subgraph before inputting it to each GNN layer, and works seamlessly across several models, both in the homogeneous and heterogeneous graph setting. To support this trimming and implement it effectively, the NeighborLoader implementation in PyG and in pyg-lib additionally return the number of nodes and edges sampled in each hop, which are then used on a per-layer basis to trim the adjacency matrix and the various feature matrices to only maintain the required amount (see the trim_to_layer method):
class GNN(torch.nn.Module):
def __init__(self, in_channels: int, out_channels: int, num_layers: int):
super().__init__()
self.convs = ModuleList([SAGEConv(in_channels, 64)])
for _ in range(num_layers - 1):
self.convs.append(SAGEConv(hidden_channels, hidden_channels))
self.lin = Linear(hidden_channels, out_channels)
def forward(
self,
x: Tensor,
edge_index: Tensor,
num_sampled_nodes_per_hop: List[int],
num_sampled_edges_per_hop: List[int],
) -> Tensor:
for i, conv in enumerate(self.convs):
# Trim edge and node information to the current layer `i`.
x, edge_index, _ = trim_to_layer(
i, num_sampled_nodes_per_hop, num_sampled_edges_per_hop,
x, edge_index)
x = conv(x, edge_index).relu()
return self.lin(x)
Corresponding examples can be found here and here.
Biased Sampling
Additionally, we added support for weighted/biased sampling in NeighborLoader/LinkNeighborLoader scenarios. For this, simply specify your edge_weight attribute during NeighborLoader initialization, and PyG will pick up these weights to perform weighted/biased sampling (#8038):
data = Data(num_nodes=5, edge_index=edge_index, edge_weight=edge_weight)
loader = NeighborLoader(
data,
num_neighbors=[10, 10],
weight_attr='edge_weight',
)
batch = next(iter(loader))
New models, datasets, examples & tutorials
As part of our algorithm and documentation sprints (#7892), we have added:
-
Model components:
-
MixHopConv: “MixHop: Higher-Order Graph Convolutional Architecturesvia Sparsified Neighborhood Mixing” (examples/mixhop.py) (#8025) -
LCMAggregation: “Learnable Commutative Monoids for Graph Neural Networks” (examples/lcm_aggr_2nd_min.py) (#7976, #8020, #8023, #8026, #8075) -
DirGNNConv: “Edge Directionality Improves Learning on Heterophilic Graphs” (examples/dir_gnn.py) (#7458) - Support for
PerformerinGPSConv: “Recipe for a General, Powerful, Scalable Graph Transformer” (examples/graph_gps.py) (#7465) -
PMLP: “Graph Neural Networks are Inherently Good Generalizers: Insights by Bridging GNNs and MLPs” (examples/pmlp.py) (#7470, #7543) -
RotateE: “RotatE: Knowledge Graph Embedding by Relational Rotation in Complex Space” (examples/kge_fb15k_237.py) (#7026) -
NeuralFingerprint: “Convolutional Networks on Graphs for Learning Molecular Fingerprints” (#7919)
-
-
Datasets:
HM(#7515),BrcaTcga(#7994),MyketDataset(#7959),Wikidata5M(#7864),OSE_GVCS(#7811),MovieLens1M(#7479),AmazonBook(#7483),GDELTLite(#7442),IGMCDataset(#7441),MovieLens100K(#7398),EllipticBitcoinTemporalDataset(#7011),NeuroGraphDataset(#8112),PCQM4Mv2(#8102) - Tutorials:
-
Examples:
- Heterogeneous link-level GNN explanations via
CaptumExplainer(examples/captum_explainer_hetero_link.py) (#7096) - Training
LightGCNonAmazonBookfor recommendation (examples/lightgcn.py) (#7603) - Using the Kùzu remote backend as
FeatureStore(examples/kuzu) (#7298) - Multi-GPU training on
ogbn-papers100M(examples/papers100m_multigpu.py) (#7921) - The
OGCmodel onCora(examples/ogc.py) (#8168) - Distributed training via
graphlearn-for-pytorch(examples/distributed/graphlearn_for_pytorch) (#7402)
- Heterogeneous link-level GNN explanations via
Join our Slack here if you're interested in joining community sprints in the future!
Breaking Changes
-
Data.keys()is now a method instead of a property (#7629):2.4 data = Data(x=x, edge_index=edge_index) print(data.keys) # ['x', 'edge_index']data = Data(x=x, edge_index=edge_index) print(data.keys()) # ['x', 'edge_index'] - Dropped Python 3.7 support (#7939)
- Removed
FastHGTConvin favor ofHGTConv(#7117) - Removed the
layer_typeargument fromGraphMaskExplainer(#7445) - Renamed
destargument todstinutils.geodesic_distance(#7708)
Deprecations
- Deprecated
contrib.explain.GraphMaskExplainerin favor ofexplain.algorithm.GraphMaskExplainer(#7779)
Features
Data and HeteroData improvements
- Added a warning for isolated/non-existing node types in
HeteroData.validate()(#7995) - Added
HeteroDatasupport into_networkx(#7713) - Added
Data.sort()andHeteroData.sort()(#7649) - Added padding capabilities to
HeteroData.to_homogeneous()in case feature dimensionalities do not match (#7374) - Added
torch.nested_tensorsupport inDataandBatch(#7643, #7647) - Added
keep_inter_cluster_edgesoption toClusterDatato support inter-subgraph edge connections when doing graph partitioning (#7326)
Data-loading improvements
- Added support for floating-point slicing in
Dataset, e.g.,dataset[:0.9](#7915) - Added
saveandloadmethods toInMemoryDataset(#7250, #7413) - Beta: Added
IBMBNodeLoaderandIBMBBatchLoaderdata loaders (#6230) - Beta: Added
HyperGraphDatato support hypergraphs (#7611) - Added
CachedLoader(#7896, #7897) - Allowed GPU tensors as input to
NodeLoaderandLinkLoader(#7572) - Added
PrefetchLoadercapabilities (#7376, #7378, #7383) - Added manual sampling interface to
NodeLoaderandLinkLoader(#7197)
Better support for sparse tensors
- Added
SparseTensorsupport toWLConvContinuous,GeneralConv,PDNConvandARMAConv(#8013) - Change
torch_sparse.SparseTensorlogic to utilizetorch.sparse_csrinstead (#7041) - Added support for
torch.sparse.TensorinDataLoader(#7252) - Added support for
torch.jit.scriptwithinMessagePassinglayers withouttorch_sparsebeing installed (#7061, #7062) - Added unbatching logic for
torch.sparse.Tensor(#7037) - Added support for
Data.num_edgesfor nativetorch.sparse.Tensoradjacency matrices (#7104) - Accelerated sparse tensor conversion routines (#7042, #7043)
- Added a sparse
cross_entropyimplementation (#7447, #7466)
Integration with 3rd-party libraries
torch_geometric.transforms
- All transforms are now immutable, i.e. they perform a shallow-copy of the data and therefore do not longer modify data in-place (#7429)
- Added the
HalfHopgraph upsampling augmentation (#7827) - Added interval argument to
Cartesian,LocalCartesianandDistancetransformations (#7533, #7614, #7700) - Added an optional
add_pad_maskargument to thePadtransform (#7339) - Added
NodePropertySplittransformation for creating node-level splits using structural node properties (#6894) - Added a
AddRemainingSelfLoopstransformation (#7192)
Bugfixes
- Fixed
HeteroConvfor layers that have a non-default argument order, e.g.,GCN2Conv(#8166) - Handle reserved keywords as keys in
ModuleDictandParameterDict(#8163) - Fixed
DynamicBatchSampler.__len__to raise an error in casenum_stepsis undefined (#8137) - Enabled pickling of
DimeNetmodels (#8019) - Fixed a bug in which
batch.e_idwas not correctly computed on unsorted graph inputs (#7953) - Fixed
from_networkxconversion fromnx.stochastic_block_modelgraphs (#7941) - Fixed the usage of
bias_initializerinHeteroLinear(#7923) - Fixed broken URLs in
HGBDataset(#7907) - Fixed an issue where
SetTransformerAggregationproduced NaN values for isolates nodes (#7902) - Fixed
summaryon modules with uninitialized parameters (#7884) - Fixed tracing of
add_self_loopsfor a dynamic number of nodes (#7330) - Fixed device issue in
PNAConv.get_degree_histogram(#7830) - Fixed the shape of
edge_label_timewhen using temporal sampling on homogeneous graphs (#7807) - Fixed
edge_label_indexcomputation inLinkNeighborLoaderfor the homogeneous+disjoint mode (#7791) - Fixed
CaptumExplainerfor binary classification tasks (#7787) - Raise error when collecting non-existing attributes in
HeteroData(#7714) - Fixed
get_mesh_laplacianfornormalization="sym"(#7544) - Use
dim_sizeto initialize output size of theEquilibriumAggregationlayer (#7530) - Fixed empty edge indices handling in
SparseTensor(#7519) - Move the
scalertensor inGeneralConvto the correct device (#7484) - Fixed
HeteroLinearbug when used via mixed precision (#7473) - Fixed gradient computation of edge weights in
utils.spmm(#7428) - Fixed an index-out-of-range bug in
QuantileAggregationwhendim_sizeis passed (#7407) - Fixed a bug in
LightGCN.recommendation_loss()to only use the embeddings of the nodes involved in the current mini-batch (#7384) - Fixed a bug in which inputs where modified in-place in
to_hetero_with_bases(#7363) - Do not load
node_defaultandedge_defaultattributes infrom_networkx(#7348) - Fixed
HGTConvutility function_construct_src_node_feat(#7194) - Fixed
subgraphon unordered inputs (#7187) - Allow missing node types in
HeteroDictLinear(#7185) - Fix
numpyincompatiblity when reading files forPlanetoiddatasets (#7141) - Fixed crash of heterogeneous data loaders if node or edge types are missing (#7060, #7087)
- Allowed
CaptumExplainerto be called multiple times in a row (#7391)
Changes
- Enabled dense eigenvalue computation in
AddLaplacianEigenvectorPEfor small-scale graphs (#8143) - Accelerated and simplified
top_kcomputation inTopKPooling(#7737) - Updated
GINimplementation in benchmarks to apply sequential batch normalization (#7955) - Updated
QM9data pre-processing to include the SMILES string (#7867) - Warn user when using the
trainingflag into_heteromodules (#7772) - Changed
add_random_edgeto only add true negative edges (#7654) - Allowed the usage of
BasicGNNmodels inDeepGraphInfomax(#7648) - Added a
num_edgesparameter to the forward method ofHypergraphConv(#7560) - Added a
max_num_elementsparameter to the forward method ofGraphMultisetTransformer,GRUAggregation,LSTMAggregation,SetTransformerAggregationandSortAggregation(#7529, #7367) - Re-factored
ClusterLoaderto integratepyg-libMETIS routine (#7416) - The
filter_per_workeroption will not get automatically inferred by default based on the device of the underlying data (#7399) - Added the option to pass
fill_valueas atorch.tensortoutils.to_dense_batch(#7367) - Updated examples to use
NeighborLoaderinstead ofNeighborSampler(#7152) - Extend dataset summary to create stats for each node/edge type (#7203)
- Added an optional
batch_sizeargument toavg_pool_xandmax_pool_x(#7216) - Optimized
from_networkxmemory footprint by reducing unnecessary copies (#7119) - Added an optional
batch_sizeargument toLayerNorm,GraphNorm,InstanceNorm,GraphSizeNormandPairNorm(#7135) - Accelerated attention-based
MultiAggregation(#7077) - Edges in
HeterophilousGraphDatasetare now undirected by default (#7065) - Added an optional
batch_sizeandmax_num_nodesarguments toMemPoolinglayer (#7239)
Full Changelog
Full Changelog: https://github.com/pyg-team/pytorch_geometric/compare/2.3.0...2.4.0
New Contributors
- @zoryzhang made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7027
- @DomInvivo made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7037
- @OlegPlatonov made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7065
- @hbenedek made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7053
- @rishiagarwal2000 made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7011
- @sisaman made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7104
- @amorehead made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7110
- @EulerPascal404 made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7093
- @Looong01 made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7143
- @kamil-andrzejewski made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7135
- @andreazanetti made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7089
- @akihironitta made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7195
- @kjkozlowski made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7216
- @vstenby made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7221
- @piotrchmiel made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7239
- @vedal made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7272
- @gvbazhenov made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/6894
- @Saydemr made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7313
- @HaoyuLu1022 made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7325
- @Vuenc made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7330
- @mewim made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7298
- @volltin made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7355
- @kasper-piskorski made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7377
- @happykygo made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7384
- @ThomasKLY made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7398
- @sky-2002 made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7421
- @denadai2 made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7456
- @chrisgo-gc made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7484
- @furkanakkurt1335 made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7507
- @mzamini92 made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7497
- @n-patricia made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7543
- @SalvishGoomanee made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7573
- @emalgorithm made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7458
- @marshka made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7595
- @djm93dev made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7598
- @NripeshN made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7770
- @ATheCoder made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7774
- @ebrahimpichka made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7775
- @kaidic made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7814
- @Wesxdz made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7811
- @daviddavo made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7888
- @frinkleko made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7907
- @chendiqian made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7917
- @rajveer43 made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7885
- @erfanloghmani made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7959
- @xnuohz made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7937
- @Favourj-bit made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7905
- @apfelsinecode made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7996
- @ArchieGertsman made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7976
- @bkmi made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/8019
- @harshit5674 made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7919
- @erikhuck made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/8024
- @jay-bhambhani made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/8028
- @Barcavin made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/8049
- @royvelich made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/8048
- @CodeTal made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/7611
- @filipekstrm made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/8117
- @Anwar-Said made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/8122
- @xYix made their first contribution in https://github.com/pyg-team/pytorch_geometric/pull/8168
2.3.1
1 year agoPyG 2.3.1 includes a variety of bugfixes.
Bug Fixes
- Fixed
cugraphGNN layer support forpylibcugraphops==23.04(#7023) - Removed
DeprecationWarningofTypedStorageusage inDataLoader(#7034) - Fixed a bug in
FastHGTConvthat computed values via parameters used to compute the keys (#7050) - Fixed
numpyincompatiblity when reading files inPlanetoiddatasets (#7141) - Fixed
utils.subgraphon unordered inputs (#7187) - Fixed support for
Data.num_edgesfor nativetorch.sparse.Tensoradjacency matrices (#7104)
Full Changelog: https://github.com/pyg-team/pytorch_geometric/compare/2.3.0...2.3.1
2.3.0
1 year ago2.2.0
1 year ago2.1.0
1 year ago2.0.4
2 years agoPyG 2.0.4 🎉
A new minor PyG version release, bringing PyTorch 1.11 support to PyG. It further includes a variety of new features and bugfixes:
Features
- Added Quiver examples for multi-GU training using
GraphSAGE(#4103), thanks to @eedalong and @luomai -
nn.model.to_captum: Full integration of explainability methods provided by the Captum library (#3990, #4076), thanks to @RBendias -
nn.conv.RGATConv: The relational graph attentional operator (#4031, #4110), thanks to @fork123aniket -
nn.pool.DMoNPooling: The spectral modularity pooling operator (#4166, #4242), thanks to @fork123aniket -
nn.*: Support for shape information in the documentation (#3739, #3889, #3893, #3946, #3981, #4009, #4120, #4158), thanks to @saiden89 and @arunppsg and @konstantinosKokos -
loader.TemporalDataLoader: A dataloader to load aTemporalDataobject in mini-batches (#3985, #3988), thanks to @otaviocx -
loader.ImbalancedSampler: A weighted random sampler that randomly samples elements according to class distribution (#4198) -
transforms.VirtualNode: A transform that adds a virtual node to a graph (#4163) -
transforms.LargestConnectedComponents: Selects the subgraph that corresponds to the largest connected components in the graph (#3949), thanks to @abojchevski -
utils.homophily: Support for class-insensitive edge homophily (#3977, #4152), thanks to @hash-ir and @jinjh0123 -
utils.get_mesh_laplacian: Mesh Laplacian computation (#4187), thanks to @daniel-unyi-42
Datasets
- Added a dataset cheatsheet to the documentation that collects import graph statistics across a variety of datasets supported in PyG (#3807, #3817) (please consider helping us filling its remaining content)
-
datasets.EllipticBitcoinDataset: A dataset of Bitcoin transactions (#3815), thanks to @shravankumar147
Minor Changes
-
nn.models.MLP: MLPs can now either be initialized via a list ofchannelsor by specifyinghidden_channelsandnum_layers(#3957) -
nn.models.BasicGNN: FinalLineartransformations are now always applied (except forjk=None) (#4042) -
nn.conv.MessagePassing: Message passing modules that make use ofedge_updaterare now jittable (#3765), thanks to @Padarn -
nn.conv.MessagePassing: (Official) support forminandmulaggregations (#4219) -
nn.LightGCN: Initialize embeddings viaxavier_uniformfor better model performance (#4083), thanks to @nishithshowri006 -
nn.conv.ChebConv: Automatic eigenvalue approximation (#4106), thanks to @daniel-unyi-42 -
nn.conv.APPNP: Added support for optionaledge_weight, (690a01d), thanks to @YueeXiang -
nn.conv.GravNetConv: Support fortorch.jit.script(#3885), thanks to @RobMcH -
nn.pool.global_*_pool: Thebatchvector is now optional (#4161) -
nn.to_hetero: Added a warning in caseto_heterois used onHeteroDatametadata with unused destination node types (#3775) -
nn.to_hetero: Support for nested modules (ea135bf) -
nn.Sequential: Support for indexing (#3790) -
nn.Sequential: Support forOrderedDictas input (#4075) -
datasets.ZINC: Added an in-depth description of the task (#3832), thanks to @gasteigerjo -
datasets.FakeDataset: Support for different feature distributions across different labels (#4065), thanks to @arunppsg -
datasets.FakeDataset: Support for custom global attributes (#4074), thanks to @arunppsg -
transforms.NormalizeFeatures: Features will no longer be transformed in-place (ada5b9a) -
transforms.NormalizeFeatures: Support for negative feature values (6008e30) -
utils.is_undirected: Improved efficiency (#3789) -
utils.dropout_adj: Improved efficiency (#4059) -
utils.contains_isolated_nodes: Improved efficiency (970de13) -
utils.to_networkx: Support forto_undirectedoptions (upper triangle vs. lower triangle) (#3901, #3948), thanks to @RemyLau -
graphgym: Support for custom metrics and loggers (#3494), thanks to @RemyLau -
graphgym.register: Register operations can now be used as class decorators (#3779, #3782) - Documentation: Added a few exercises at the end of documentation tutorials (#3780), thanks to @PabloAMC
- Documentation: Added better installation instructions to
CONTRIBUTUNG.md(#3803, #3991, #3995), thanks to @Cho-Geonwoo and @RBendias and @RodrigoVillatoro - Refactor: Clean-up dependencies (#3908, #4133, #4172), thanks to @adelizer
- CI: Improved test runtimes (#4241)
- CI: Additional linting check via
yamllint(#3886) - CI: Additional linting check via
isort(66b1780), thanks to @mananshah99 -
torch.package: Model packaging viatorch.package(#3997)
Bugfixes
-
data.HeteroData: Fixed a bug indata.{attr_name}_dictin casedata.{attr_name}does not exist (#3897) -
data.Data: Fixeddata.is_edge_attrin casedata.num_edges == 1(#3880) -
data.Batch: Fixed a device mismatch bug in case abatchobject was indexed that was created from GPU tensors (e6aa4c9, c549b3b) -
data.InMemoryDataset: Fixed a bug in whichcopydid not respect the underlying slice (d478dcb, #4223) -
nn.conv.MessagePassing: Fixed message passing with zero nodes/edges (#4222) -
nn.conv.MessagePassing: Fixed bipartite message passing withflow="target_to_source"(#3907) -
nn.conv.GeneralConv: Fixed an issue in caseskip_linear=Falseandin_channels=out_channels(#3751), thanks to @danielegrattarola -
nn.to_hetero: Fixed model transformation in case node type names or edge type names contain whitespaces or dashes (#3882, b63a660) -
nn.dense.Linear: Fixed a bug in lazy initialization for PyTorch < 1.8.0 (973d17d, #4086) -
nn.norm.LayerNorm: Fixed a bug in the shape of weights and biases (#4030), thanks to @marshka -
nn.pool: Fixedtorch.jit.scriptsupport fortorch-clusterfunctions (#4047) -
datasets.TOSCA: Fixed a bug in which indices of faces started at1rather than0(8c282a0), thanks to @JRowbottomGit -
datasets.WikiCS: FixedWikiCSto be undirected by default (#3796), thanks to @pmernyei - Resolved inconsistency between
utils.contains_isolated_nodesanddata.has_isolated_nodes(#4138) -
graphgym: Fixed the loss function regarding multi-label classification (#4206), thanks to @RemyLau - Documentation: Fixed typos, grammar and bugs (#3840, #3874, #3875, #4149), thanks to @itamblyn and @chrisyeh96 and @finquick