OpenPrompt Save Abandoned
An Open-Source Framework for Prompt-Learning.

An Open-Source Framework for Prompt-learning.
Overview • Installation • How To Use • Docs • Paper • Citation • Performance •
What's New?
- ❗️ April 2023: $\color{red}{\normalsize{\textbf{Want to build your Chat AI?}}}$ We are releasing UltraChat, use OpenPrompt and UltraChat to conduct supervised instruction tuning, see
./tutorial/9_UltraChat.py. - Aug 2022: Thanks to contributor zhiyongLiu1114, OpenPrompt now supports ERNIE 1.0 in PaddlePaddle.
- July 2022: OpenPrompt supports OPT now.
- June 2022: OpenPrompt wins ACL 2022 Best Demo Paper Award.
- Mar 2022: We add a tutorial as the response to issue 124, which uses a customized tokenizer_wrapper to perform tasks that are not in the default configuration of OpenPrompt (e.g., Bert tokenizer+T5 model).
- Feb 2022: Check out our sister repo OpenDelta!
- Dec 2021:
pip install openprompt - Dec 2021: SuperGLUE performance are added
- Dec 2021: We support generation paradigm for all tasks by adding a new verbalizer:GenerationVerbalizer and a tutorial: 4.1_all_tasks_are_generation.py
- Nov 2021: Now we have released a paper OpenPrompt: An Open-source Framework for Prompt-learning.
- Nov 2021 PrefixTuning supports t5 now.
- Nov 2021: We made some major changes from the last version, where a flexible template language is newly introduced! Part of the docs is outdated and we will fix it soon.
Overview
Prompt-learning is the latest paradigm to adapt pre-trained language models (PLMs) to downstream NLP tasks, which modifies the input text with a textual template and directly uses PLMs to conduct pre-trained tasks. This library provides a standard, flexible and extensible framework to deploy the prompt-learning pipeline. OpenPrompt supports loading PLMs directly from huggingface transformers. In the future, we will also support PLMs implemented by other libraries. For more resources about prompt-learning, please check our paper list.
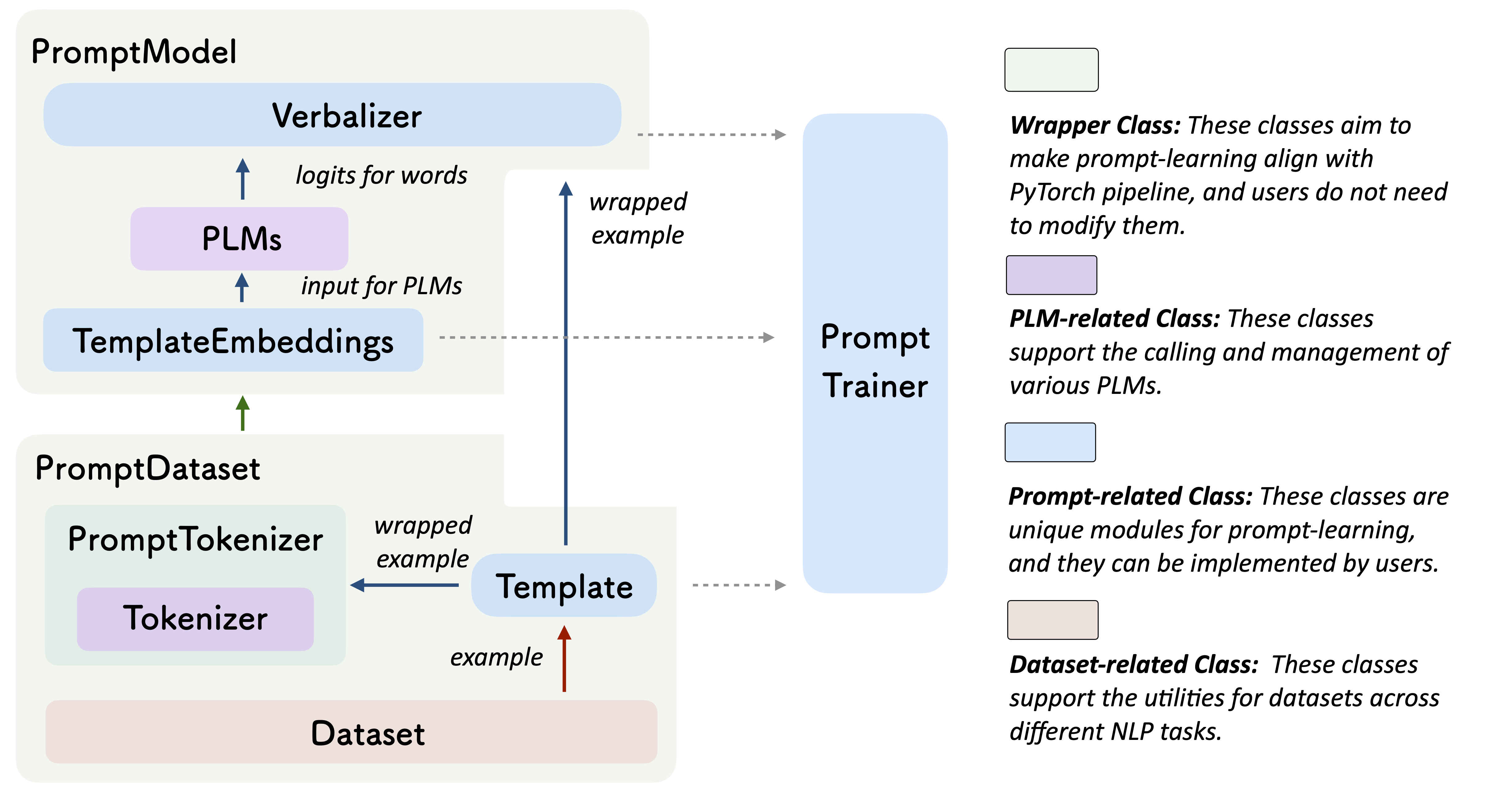
What Can You Do via OpenPrompt?

- Use the implementations of current prompt-learning approaches.* We have implemented various of prompting methods, including templating, verbalizing and optimization strategies under a unified standard. You can easily call and understand these methods.
- Design your own prompt-learning work. With the extensibility of OpenPrompt, you can quickly practice your prompt-learning ideas.
Installation
Note: Please use Python 3.8+ for OpenPrompt
Using Pip
Our repo is tested on Python 3.8+ and PyTorch 1.8.1+, install OpenPrompt using pip as follows:
pip install openprompt
To play with the latest features, you can also install OpenPrompt from the source.
Using Git
Clone the repository from github:
git clone https://github.com/thunlp/OpenPrompt.git
cd OpenPrompt
pip install -r requirements.txt
python setup.py install
Modify the code
python setup.py develop
Use OpenPrompt
Base Concepts
A PromptModel object contains a PLM, a (or multiple) Template and a (or multiple) Verbalizer, where the Template class is defined to wrap the original input with templates, and the Verbalizer class is to construct a projection between labels and target words in the current vocabulary. And a PromptModel object practically participates in training and inference.
Introduction by a Simple Example
With the modularity and flexibility of OpenPrompt, you can easily develop a prompt-learning pipeline.
Step 1: Define a task
The first step is to determine the current NLP task, think about what’s your data looks like and what do you want from the data! That is, the essence of this step is to determine the classes and the InputExample of the task. For simplicity, we use Sentiment Analysis as an example. tutorial_task.
from openprompt.data_utils import InputExample
classes = [ # There are two classes in Sentiment Analysis, one for negative and one for positive
"negative",
"positive"
]
dataset = [ # For simplicity, there's only two examples
# text_a is the input text of the data, some other datasets may have multiple input sentences in one example.
InputExample(
guid = 0,
text_a = "Albert Einstein was one of the greatest intellects of his time.",
),
InputExample(
guid = 1,
text_a = "The film was badly made.",
),
]
Step 2: Define a Pre-trained Language Models (PLMs) as backbone.
Choose a PLM to support your task. Different models have different attributes, we encourge you to use OpenPrompt to explore the potential of various PLMs. OpenPrompt is compatible with models on huggingface.
from openprompt.plms import load_plm
plm, tokenizer, model_config, WrapperClass = load_plm("bert", "bert-base-cased")
Step 3: Define a Template.
A Template is a modifier of the original input text, which is also one of the most important modules in prompt-learning.
We have defined text_a in Step 1.
from openprompt.prompts import ManualTemplate
promptTemplate = ManualTemplate(
text = '{"placeholder":"text_a"} It was {"mask"}',
tokenizer = tokenizer,
)
Step 4: Define a Verbalizer
A Verbalizer is another important (but not necessary) in prompt-learning,which projects the original labels (we have defined them as classes, remember?) to a set of label words. Here is an example that we project the negative class to the word bad, and project the positive class to the words good, wonderful, great.
from openprompt.prompts import ManualVerbalizer
promptVerbalizer = ManualVerbalizer(
classes = classes,
label_words = {
"negative": ["bad"],
"positive": ["good", "wonderful", "great"],
},
tokenizer = tokenizer,
)
Step 5: Combine them into a PromptModel
Given the task, now we have a PLM, a Template and a Verbalizer, we combine them into a PromptModel. Note that although the example naively combine the three modules, you can actually define some complicated interactions among them.
from openprompt import PromptForClassification
promptModel = PromptForClassification(
template = promptTemplate,
plm = plm,
verbalizer = promptVerbalizer,
)
Step 6: Define a DataLoader
A PromptDataLoader is basically a prompt version of pytorch Dataloader, which also includes a Tokenizer, a Template and a TokenizerWrapper.
from openprompt import PromptDataLoader
data_loader = PromptDataLoader(
dataset = dataset,
tokenizer = tokenizer,
template = promptTemplate,
tokenizer_wrapper_class=WrapperClass,
)
Step 7: Train and inference
Done! We can conduct training and inference the same as other processes in Pytorch.
import torch
# making zero-shot inference using pretrained MLM with prompt
promptModel.eval()
with torch.no_grad():
for batch in data_loader:
logits = promptModel(batch)
preds = torch.argmax(logits, dim = -1)
print(classes[preds])
# predictions would be 1, 0 for classes 'positive', 'negative'
Please refer to our tutorial scripts, and documentation for more details.
Datasets
We provide a series of download scripts in the dataset/ folder, feel free to use them to download benchmarks.
Performance Report
There are too many possible combinations powered by OpenPrompt. We are trying our best to test the performance of different methods as soon as possible. The performance will be constantly updated into the Tables. We also encourage the users to find the best hyper-parameters for their own tasks and report the results by making pull request.
Known Issues
Major improvement/enhancement in future.
- We made some major changes from the last version, so part of the docs is outdated. We will fix it soon.
Citation
Please cite our paper if you use OpenPrompt in your work
@article{ding2021openprompt,
title={OpenPrompt: An Open-source Framework for Prompt-learning},
author={Ding, Ning and Hu, Shengding and Zhao, Weilin and Chen, Yulin and Liu, Zhiyuan and Zheng, Hai-Tao and Sun, Maosong},
journal={arXiv preprint arXiv:2111.01998},
year={2021}
}
Contributors
We thank all the contributors to this project, more contributors are welcome!
