NoiseFace Save
Noise-Tolerant Paradigm for Training Face Recognition CNNs [Official, CVPR 2019]
Noise-Tolerant Paradigm for Training Face Recognition CNNs
Paper link: https://arxiv.org/abs/1903.10357
Presented at CVPR 2019
This is the code for the paper
Contents
Requirements
Dataset
Training dataset:
Testing dataset:
Both the training data and testing data are aligned by the method described in util.py
How-to-use
Firstly, you can train the network in noisy dataset as following steps:
step 1: add noise_tolerant_fr and relevant layers(at ./layers directory) to caffe project and recompile it.
step 2: download training dataset to ./data directory, and corrupt training dataset in different noise ratio which you can refer to ./code/gen_noise.py, then generate the lmdb file through caffe tool.
step 3: configure prototxt file in ./deploy directory.
step 4: run caffe command to train the network by using noisy dataset.
After training, you can evaluate the model on testing dataset by using evaluate.py.
Diagram
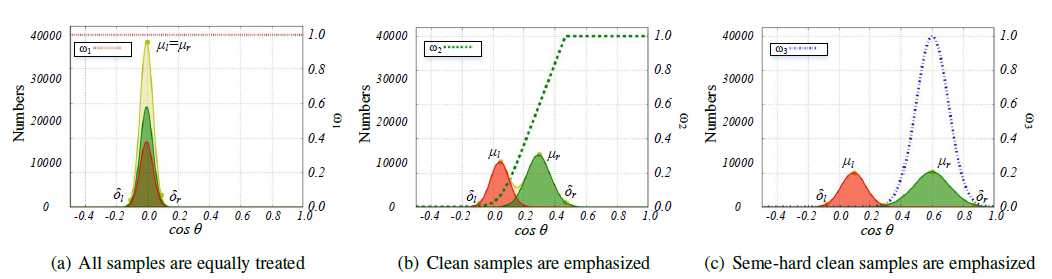
The figure shows three strategies in different purposes. At the beginning of the training process, we focus on all samples; then we focus on easy/clean samples; at last we focus on semi-hard clean samples.
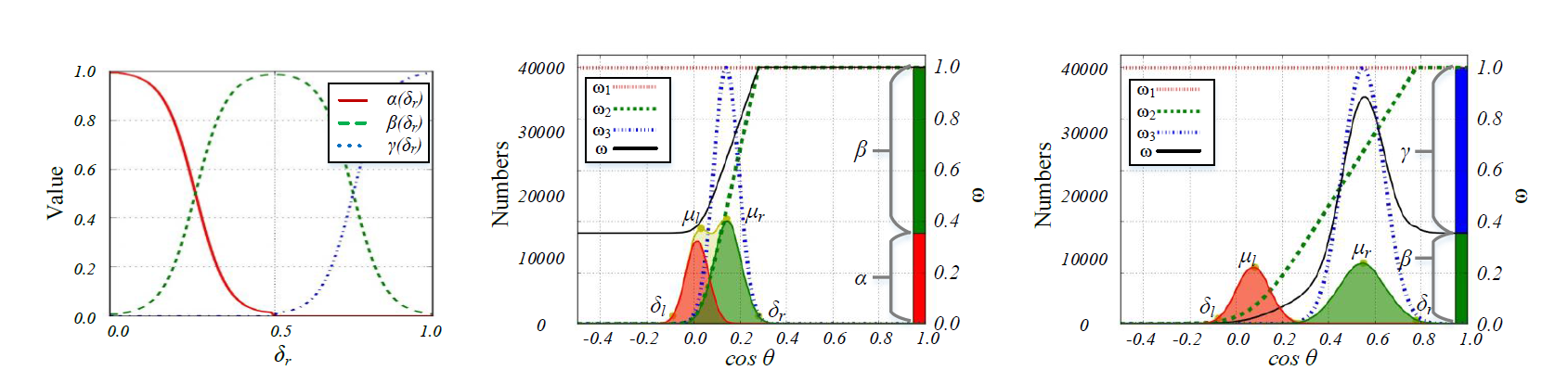
The figure explains the fusion function of three strategies. The left part demonstrates three functions: α(δr), β(δr), and γ(δr). The right part shows two fusion examples. According to the ω, we can see that the easy/clean samples are emphasized in the first example(δr < 0.5), and the semi-hard clean samples are emphasized in the second example(δr > 0.5).
For more detail, please click here to play demo video.
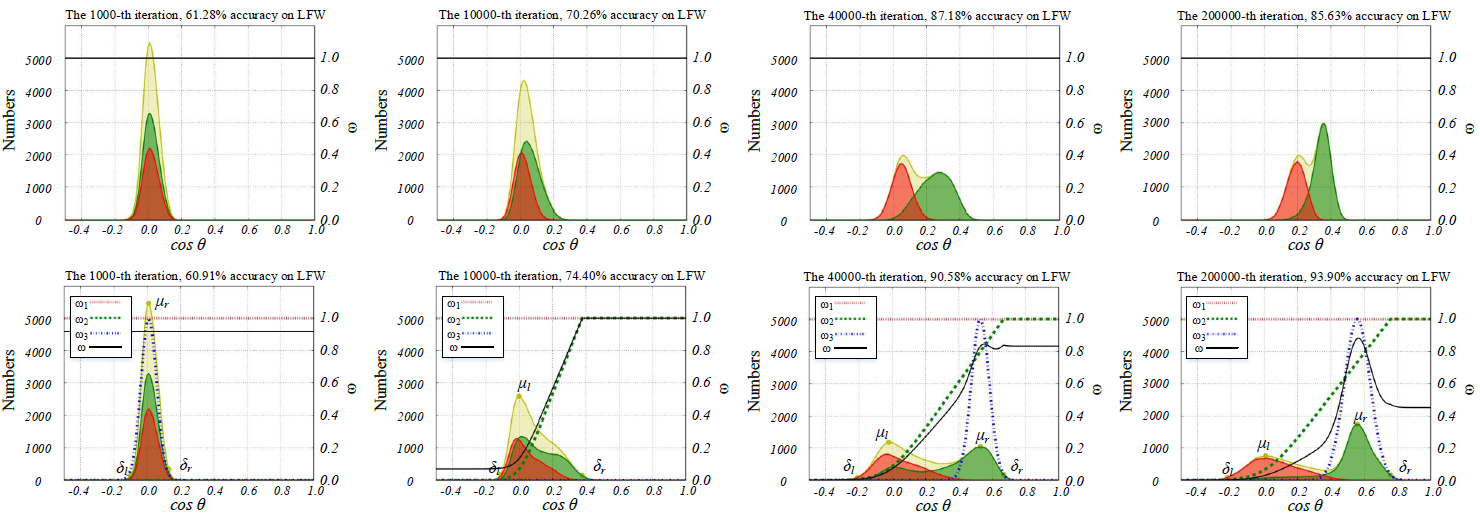
The figure shows the 2D Histall of CNNcommon (up) and CNNm2 (down) under 40% noise rate.
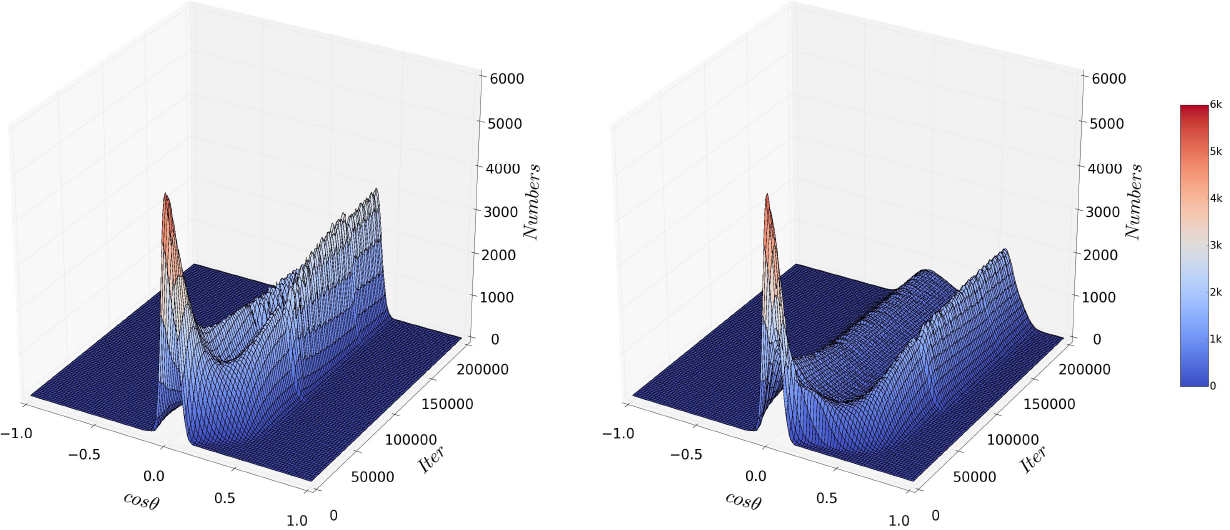
The figure shows the 3D Histall of CNNcommon (left) and CNNm2 (right) under 40% noise rate.
Performance
The table shows comparison of accuracies(%) on LFW, ResNet-20 models are used. CNNclean is trained with clean data WebFace-Clean-Sub by using the traditional method. CNNcommon is trained with noisy dataset WebFace-All by using the traditional method. CNNct is trained with noisy dataset WebFace-All by using our implemented Co-teaching(with pre-given noise rates). CNNm1 and CNNm2 are all trained with noisy dataset WebFace-All but through the proposed approach, and they respectively use the 1st and 2nd method to compute loss. Note: The WebFace-Clean-Sub is the clean part of the WebFace-All, the WebFace-All contains noise data with different rate as describe below.
| Loss | Actual Noise Rate | CNNclean | CNNcommon | CNNct | CNNm1 | CNNm2 | Estimated Noise Rate |
|---|---|---|---|---|---|---|---|
| L2softmax | 0% | 94.65 | 94.65 | - | 95.00 | 96.28 | 2% |
| L2softmax | 20% | 94.18 | 89.05 | 92.12 | 92.95 | 95.26 | 18% |
| L2softmax | 40% | 92.71 | 85.63 | 87.10 | 89.91 | 93.90 | 42% |
| L2softmax | 60% | 91.15 | 76.61 | 83.66 | 86.11 | 87.61 | 56% |
| Arcface | 0% | 97.95 | 97.95 | - | 97.11 | 98.11 | 2% |
| Arcface | 20% | 97.80 | 96.48 | 96.53 | 96.83 | 97.76 | 18% |
| Arcface | 40% | 96.53 | 92.33 | 94.25 | 95.88 | 97.23 | 36% |
| Arcface | 60% | 94.56 | 84.05 | 90.36 | 93.66 | 95.15 | 54% |
Contact
Citation
If you find this work useful in your research, please cite
@inproceedings{Hu2019NoiseFace,
title = {Noise-Tolerant Paradigm for Training Face Recognition CNNs},
author = {Hu, Wei and Huang, Yangyu and Zhang, Fan and Li, Ruirui},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition},
month = {June},
year = {2019},
address = {Long Beach, CA}
}
License
The project is released under the MIT License
