Naver AI Hackathon Speech Save Abandoned
2019 Clova AI Hackathon : Speech - Rank 12 / Team Kai.Lib
Project README
Naver AI Hackathon Speech - Team Kai.Lib
![]()
네이버 AI 해커톤 2019 - Speech Team Kai.Lib
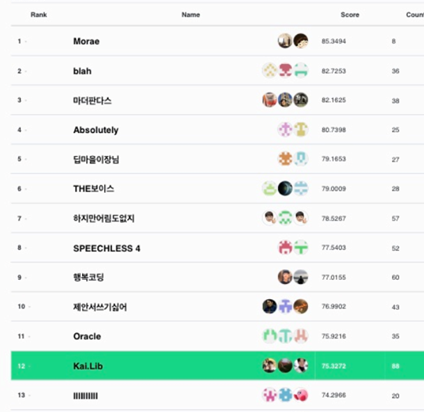
Team : Kai.Lib
Rank : 12
CRR : 75.33%
Korean-Speech-Recognition Using Pytorch.
Naver 2019 Hackathon - Speech Team Kai.Lib
Demonstration Application
Our Further Works is in progress here
Team Member


Model
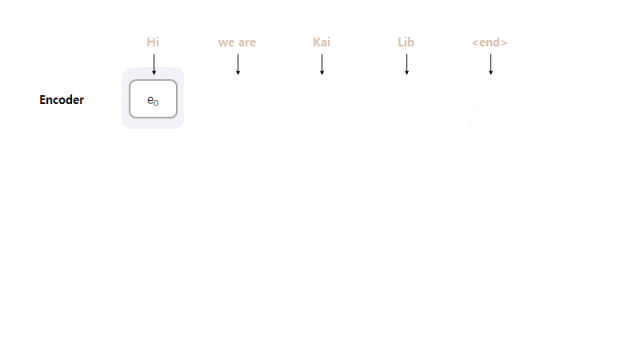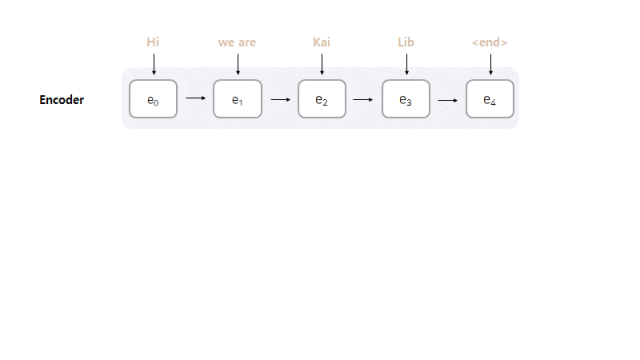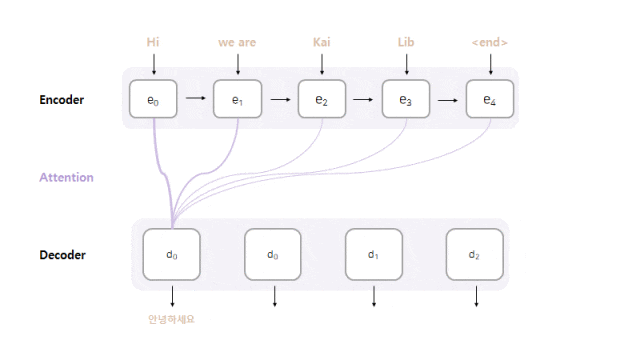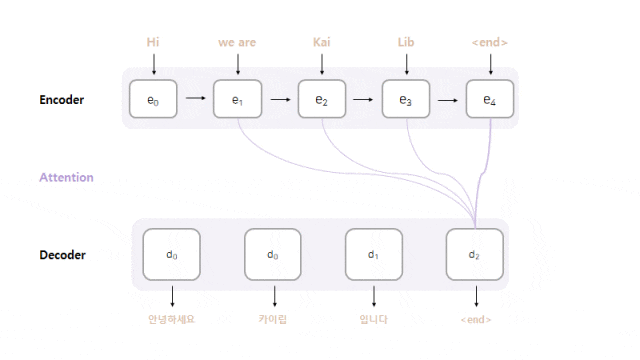
- Model Architecture : Seq2seq with Attention
Seq2seq(
(encoder): EncoderRNN(
(input_dropout): Dropout(p=0.5, inplace=False)
(conv): Sequential(
(0): Conv2d(1, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Hardtanh(min_val=0, max_val=20, inplace=True)
(3): Conv2d(16, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): Hardtanh(min_val=0, max_val=20, inplace=True)
(6): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(7): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): Hardtanh(min_val=0, max_val=20, inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(11): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(12): Hardtanh(min_val=0, max_val=20, inplace=True)
(13): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(14): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(rnn): GRU(2560, 256, num_layers=4, batch_first=True, dropout=0.5, bidirectional=True)
)
(decoder): DecoderRNN(
(input_dropout): Dropout(p=0.5, inplace=False)
(rnn): GRU(512, 512, num_layers=4, batch_first=True, dropout=0.5)
(embedding): Embedding(820, 512)
(attention): Attention(
(linear_out): Linear(in_features=1024, out_features=512, bias=True)
)
(out): Linear(in_features=512, out_features=820, bias=True)
)
)
- Model based on IBM Pytorch-Seq2seq
Test Validation
[2019-10-26 16:49:10,857 main.py:220 - evaluate()] target : 오픈마감시간이 어떻게 되나요?
[2019-10-26 16:49:10,858 main.py:221 - evaluate()] predict : 오픈마감시간이 어떻게 되나요?
[2019-10-26 16:49:10,858 main.py:220 - evaluate()] target : 방문포장 하려고 하는데요
[2019-10-26 16:49:10,859 main.py:221 - evaluate()] predict : 방문 포장하려고 하는데요
[2019-10-26 16:49:10,860 main.py:220 - evaluate()] target : 디저트에 아이스크림 류도 파나요?
[2019-10-26 16:49:10,861 main.py:221 - evaluate()] predict : 저녁에 아이스크림 오픈하나요?
[2019-10-26 16:49:10,862 main.py:220 - evaluate()] target : 봉청중앙시장쪽인데 설입쪽으로 진진하나요?
[2019-10-26 16:49:10,863 main.py:221 - evaluate()] predict : 봉천 중앙시간 쪽인데 서비쪽도 직진하나요?
[2019-10-26 16:49:10,864 main.py:220 - evaluate()] target : 월요일 8시에 예약 할 수 있어요?
[2019-10-26 16:49:10,864 main.py:221 - evaluate()] predict : 오늘 8시에 예약 할수 있어요?
[2019-10-26 16:49:10,865 main.py:220 - evaluate()] target : 얼마 이상 먹으면 주차비 무료 되나요?
[2019-10-26 16:49:10,866 main.py:221 - evaluate()] predict : 얼마 이상 먹으면 주차비 무료 되나요?
[2019-10-26 16:49:11,323 main.py:220 - evaluate()] target : 스테이크 중 런치 세트 메뉴는 얼마나 더 저렴할까요?
[2019-10-26 16:49:11,325 main.py:221 - evaluate()] predict : 스테이크 중 런치 세트 메뉴 얼마나 걸릴까요?
[2019-10-26 16:49:11,326 main.py:220 - evaluate()] predict : 테이크 아웃 하고 싶은데요
[2019-10-26 16:49:11,327 main.py:221 - evaluate()] predict : 테이크 아웃 하고 싶은데요
[2019-10-26 16:49:11,327 main.py:220 - evaluate()] predict : 단체 예약도 가능한가요?
[2019-10-26 16:49:11,328 main.py:221 - evaluate()] predict : 단체 예약도 가능한가요?
Hyper Parameter
| Hyper Parameter | Use |
|---|---|
| use_attention | True |
| layer_size | 4 |
| hidden_size | 256 |
| batch_size | 32 |
| dropout | 0.5 -> 0.3 |
| teacher_forcing | 0.80 -> 0.99 |
| lr | 1e-4 |
| max_epochs | 30 |
- dropout : (init) 0.5 (after epoch 25) 0.3
- teacher_forcing : (init) 0.80 (after epoch 25) 0.99
- lr : (init) 1e-4 (after epoch 25) 5e-5
Hyper Parameter Tuning
60시간 데이터로 실험

CRR : Character Recognition Rate
Data
네이버에서 제공한 100시간 데이터 사용
Data format
- 음성 데이터 : 16bit, mono 16k sampling PCM, WAV audio
- 정답 스크립트 : 코드와 함께 제공되는 Character level dictionary를 통해서 인덱스로 변환된 정답
"네 괜찮습니다." => "715 662 127 76 396 337 669 662"
Dataset folder structure
* DATASET-ROOT-FOLDER
|--train
|--train_data
+--data_list.csv
+--a.wav, b.wav, c.wav ...
+--train_label
|--test
|--test_submit
- data_list.csv
<wav-filename>,<script-filename>
wav_001.wav,wav_001.label
wav_002.wav,wav_002.label
wav_003.wav,wav_003.label
wav_004.wav,wav_004.label
wav_005.wav,wav_005.label
- train_label
<filename>,<script labels>
wav_001,574 268 662 675 785 661 662
wav_002,715 662 545 566 441 337 669 662
wav_003,628 9 625 662 408 690 2 125 71 662 220 630 610 749 62 661 123 662
wav_004,384 638 610 533 784 662 130 602 662 179 192 661 123 662
...
Score
CRR = (1.0 - CER) * 100.0
- CRR : Character Recognition Rate
- CER : Character Error Rate based on Edit Distance

Feature
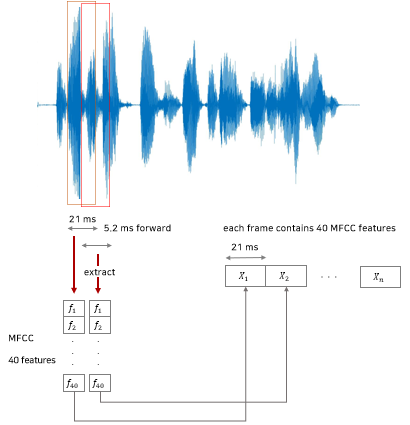
- MFCC (Mel-Frequency Cepstral Coefficient)
- frame length : 21ms
- overlap : 15.8ms (75%)
- stride : 5.2ms
- MFCC
Reference
[1] IBM pytorch-seq2seq
[2] Further Works
[3] Dataset-Part1
[4] Dataset-Part2
License
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
데이터등은 비상업적인(NON-COMMERCIAL)인 AI 연구, 학습에서만 사용할 수 있으며, 상업적인 이용은 엄격히 금지됨.
데이터등은 제공된 그대로만 사용하여야 하며, 이를 수정, 변경 등 재가공하는 것음 엄격히 금지됨.
데이터등은 자신만 이용하여야 하며, 이를 제3자에게 임의로 제공하는 것은 엄격히 금지됨.
데이터등을 연구 등에서 비상업적으로 이용하는 경우에도 데이터의 출처를 [NAVER Corp]로 표시하여야 함.
네이버는 제공되는 데이터등의 완전성이나 무결성, 정합성, 정확성, 적절성 등을 보증하지 않으며, 따라서 그에 대한 책임을 부담하지 않음.
※ 제공되는 데이터등은 음성제공자가 제공하면서 동의한 범위 내에서만 사용되어야 하므로, 상업적 이용 등 그를 넘어 이용할 경우 음성제공자 사이와의 관계에서도 법적인 책임을 부담할 수 있으므로, 반드시 위 제한사항을 준수하여 사용하시기 바랍니다.
Open Source Agenda is not affiliated with "Naver AI Hackathon Speech" Project. README Source: sooftware/Naver-AI-Hackathon-Speech
Stars
25
Open Issues
0
Last Commit
3 years ago
License
