Multiview2Novelview Save
An official TensorFlow implementation of "Multi-view to Novel view: Synthesizing novel views with Self-Learned Confidence" (ECCV 2018) by Shao-Hua Sun, Minyoung Huh, Yuan-Hong Liao, Ning Zhang, and Joseph J. Lim
![]()
![]()
![]()
![]()
Multi-view to Novel view:
Synthesizing Novel Views with Self-Learned Confidence
Descriptions
This project is a TensorFlow implementation of Multi-view to Novel view: Synthesizing Novel Views with Self-Learned Confidence, which is published in ECCV 2018. We provide codes, datasets, and checkpoints.
In this work, we address the task of multi-view novel view synthesis, where we are interested in synthesizing a target image with an arbitrary camera pose from given source images. An illustration of the task is as follows.

We propose an end-to-end trainable framework that learns to exploit multiple viewpoints to synthesize a novel view without any 3D supervision. Specifically, our model consists of a flow prediction module (flow predictor) and a pixel generation module (recurrent pixel generator) to directly leverage information presented in source views as well as hallucinate missing pixels from statistical priors. To merge the predictions produced by the two modules given multi-view source images, we introduce a self-learned confidence aggregation mechanism. An illustration of the proposed framework is as follows.
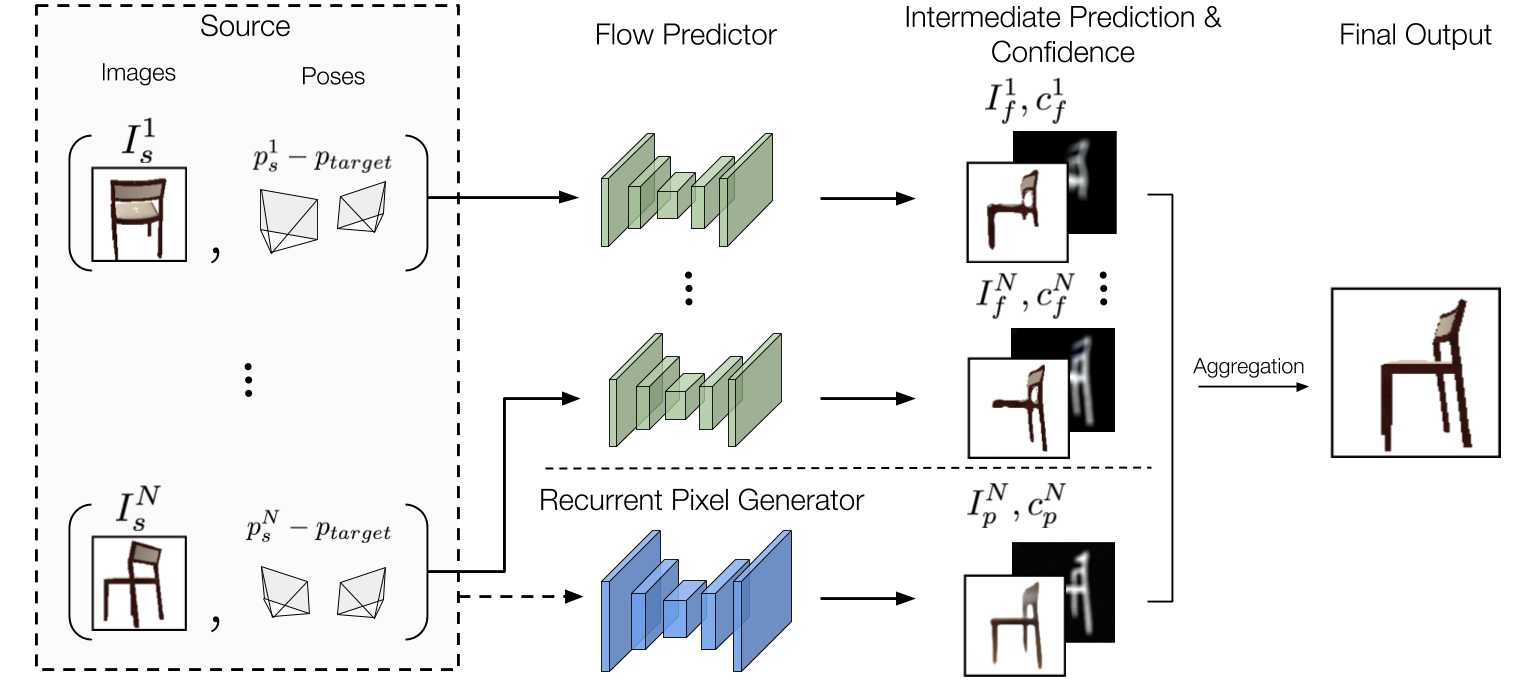
We evaluate our model on images rendered from 3D object models (ShapeNet) as well as real and synthesized scenes (KITTI and Synthia). We demonstrate that our model is able to achieve state-of-the-art results as well as progressively improve its predictions when more source images are available.
A simpler novel view synthesis codebase can be found at Novel View Synthesis in TensorFlow, where all the data loaders, as well as training/testing scripts, are well-configured, and you can just play with models.
Prerequisites
Datasets
All datasets are stored as HDF5 files, and the links are as follows. Each data point (HDF5 group) contains an image and its camera pose.
ShapeNet

KITTI

- Download from here (4.3GB)
- Put the file to this directory
./datasets/kitti.
Synthia

- Download from here (3.3GB)
- Put the file to this directory
./datasets/synthia.
Usage
After downloading the datasets, we can start to train models with the following command:
Train
$ python trainer.py --batch_size 8 --dataset car --num_input 4
- Selected arguments (see the
trainer.pyfor more details)- --prefix: a nickname for the training
- --dataset: choose among
car,chair,kitti, andsynthia. You can also add your own datasets. - Checkpoints: specify the path to a pre-trained checkpoint
- --checkpoint: load all the parameters including the flow and pixel modules and the discriminator.
- Logging
- --log_setp: the frequency of outputing log info (
[train step 681] Loss: 0.51319 (1.896 sec/batch, 16.878 instances/sec)) - --ckpt_save_step: the frequency of saving a checkpoint
- --test_sample_step: the frequency of performing testing inference during training (default 100)
- --write_summary_step: the frequency of writing TensorBoard summaries (default 100)
- --log_setp: the frequency of outputing log info (
- Hyperparameters
- --num_input: the number of source images
- --batch_size: the mini-batch size (default 8)
- --max_steps: the max training iterations
- GAN
- --gan_type: the type of GAN losses such as LS-GAN, WGAN, etc
Interpret TensorBoard
Launch Tensorboard and go to the specified port, you can see differernt losses in the scalars tab and plotted images in the images tab. The plotted images could be interpreted as follows.

Test
We can also evaluate trained models or the checkpoints provided by the authors with the following command:
$ python evaler.py --dataset car --data_id_list ./testing_tuple_lists/id_car_random_elevation.txt [--train_dir /path/to/the/training/dir/ OR --checkpoint /path/to/the/trained/model] --loss True --write_summary True --summary_file log_car.txt --plot_image True --output_dir img_car
- Selected arguments (see the
evaler.pyfor more details)- Id list
- --data_id_list: specify a list of data point that you want to evaluate
- Task
- --loss: report the loss
- --write_summary: write the summary of this evaluation as a text file
- --plot_image: render synthesized images
- Output
- --quiet: only display the final report
- --summary_file: the path to the summary file
- --output_dir: the output dir of plotted images
- Id list
Result
ShapeNet Cars

More results for ShapeNet cars (1k randomly samlped results from all 10k testing data)
ShapeNet Chairs
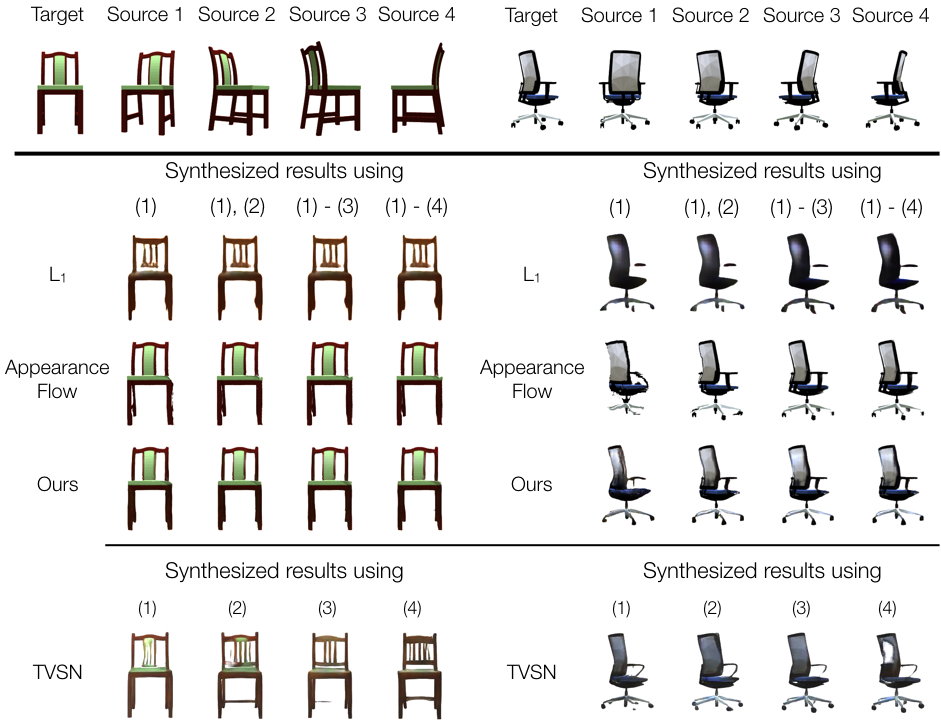
More results for ShapeNet cars (1k randomly samlped results from all 10k testing data)
Scenes: KITTI and Synthia

Checkpoints
We provide checkpoints and evaluation report files of our models for all eooxperiments.
Related work
- [L_1] Multi-view 3D Models from Single Images with a Convolutional Network in CVPR 2016
- [Appearance Flow]View Synthesis by Appearance Flow in ECCV 2016
- [TVSN] Transformation-Grounded Image Generation Network for Novel 3D View Synthesis in CVPR 2017
- Neural scene representation and rendering in Science 2018
- Weakly-supervised Disentangling with Recurrent Transformations for 3D View Synthesis in NIPS 2015
- DeepStereo: Learning to Predict New Views From the World's Imagery in CVPR 2016
- Learning-Based View Synthesis for Light Field Cameras in SIGGRAPH Asia 2016
Cite the paper
If you find this useful, please cite
@inproceedings{sun2018multiview,
title={Multi-view to Novel View: Synthesizing Novel Views with Self-Learned Confidence},
author={Sun, Shao-Hua and Huh, Minyoung and Liao, Yuan-Hong and Zhang, Ning and Lim, Joseph J},
booktitle={European Conference on Computer Vision},
year={2018},
}
Authors
Shao-Hua Sun, Minyoung Huh, Yuan-Hong Liao, Ning Zhang, and Joseph J. Lim
