Multi Label Text Classification For Chinese Save
pytorch implementation of multi-label text classification, includes kinds of models and pretrained. Especially for Chinese preprocessing.
README
This is a repo focused on Multi-Label Text Classification, the main structure was forked from lonePatient/Bert-Multi-Label-Text-Classification. We did several improvements:
- Add a pipeline to automatically configure the whole thing
- Add a preprocessor for Chinese
- Add an engineering part
- Add a basic tokenizer
Environment
# create a venv and install the dependencies
python3 -m venv env
source env/bin/activate
pip install -r requirements.txt
Usage
-
Prepare dataset
-
Read Dataset below.
-
Add
train.csvandtest.csvtodataset/ -
Each line of the
train.csvhas two fields (fact and meta). Each line of thetest.csvhas only one field:fact, the output is underoutputs/result -
If you want to evaluate your test score, please modify
main.pyline 181:is_train=Falsetois_train=True, make sure your test dataset has two fields like the train dataset. -
Paths and filenames can be defined in
configs/basic_config.py
-
-
Prepare pretrained model
- Add pretrained files to
pretrain/bert/base-uncased/, here we used a domain model - Paths and filenames can be defined in
configs/basic_config.py - For example bert filenames should be:
config.json,pytorch_model.binandbert_vocab.txt
- Add pretrained files to
-
Define a pipeline
- Edit
pipeline.yml - We have already added several pipelines in the file
- When the pipeline has been changed, it's better to clean the cached dataset
- Edit
-
Run
./run.sh- Also could run by hand
python main.py --do_data python main.py --do_train --save_best python main.py --do_test- Or set the train, test data number
python main.py --do_data --train_data_num 100 python main.py --do_train --save_best python main.py --do_test --test_data_num 10
中文处理
Dataset
thunlp/CAIL: Chinese AI & Law Challenge Task 1
类别信息是 meta 中的 accusation,共 202 种类别,每个 fact 可能有多个类别。
Preprocess
预处理主要做了以下工作:
- 剔除文本中的链接、图片等
- 剔除标点符号
- 剔除停用词
- 统一处理日期、时间
- 替换为 X,如 X年X月X日X时X分
- 中文数字数字化
- 金额
- 重量
- 浓度
- 统一处理金额
- 按大小区间分类
- 统一处理重量
- 按大小区间分类
- 统一处理浓度
- 按大小区间分类
- 统一处理地点、人名等实体
- 统一替换为特定的 Token
Features
尝试做了一些特征工程,不过并未实际运用在模型当中。主要包括几个方面:
- 基于长度的特征
- 文本长度
- 基于词的特征
- 总词数
- 标点符号占总词数比例
- 数字占总词数比例
- hapax_legomena1:出现一次的词占总词数的比例
- hapax_legomena2:出现两次的词占总词数的比例
- 一字词比例
- 二字词比例
- 三字词比例
- 四字词比例
- TTR:词 token 数/总词数
- 基于句子的特征
- 短句数
- 整句数
- 基于内容的特征
- 被告数量
- 被告中男性比例
- 被告中法定代表人比例
- 担保数
- 关键词
- 基于 TextRank 和 TF-IDF
Models
模型可选择的非常多,不过总体来看可以分为使用预训练模型和不使用预训练模型两种。一般情况下,使用预训练模型的效果要好于不使用。预训练模型可以使用词向量,也可以使用 Bert 和基于 Bert 的不同变形。
这里我们首先选择基本的、不使用预训练模型的 TextCNN 作为 Baseline,该模型如下图所示:
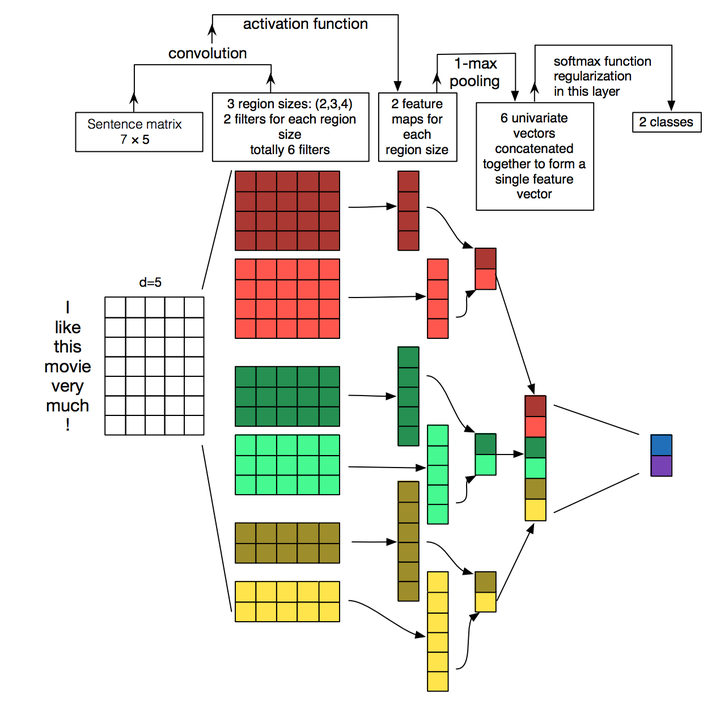
TextCNN 类似于 Ngram 滑动窗口提取特征,MaxPooling 获取重要特征,多个通道获取不同类型的特征。最大的问题是 MaxPooling 丢失了内部结构信息。
然后选择 Bert 作为预训练模型,我们选择了领域 Bert 模型,分别尝试了直接使用 Bert 的 classification 信息,TextRCNN 和 TextDPCNN。之所以选择这两个模型,是因为它们在之前的测评中显示的结果较好。
TextRCNN 相当于 RNN + CNN,其基本结构如下图所示:
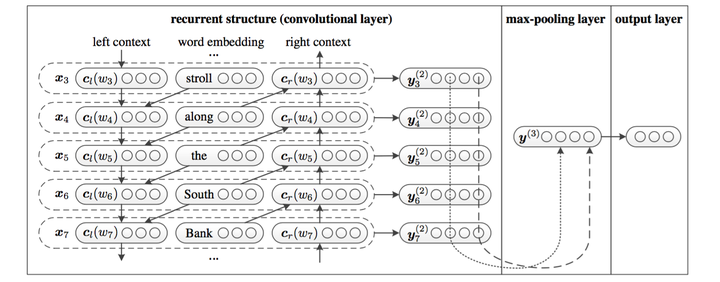
RNN 我们采用双向 LSTM,结果与 embedding 拼接后再接一个 Maxpooling 获取重要特征。
DPCNN 可以看作是多个叠加的 CNN,结果如下图所示:

先做了两次宽度为 3,filter 数量为 250 个的卷积,然后开始做两两相邻的 MaxPooling(丢失很少的信息,提取更抽象的特征)。每个 block 中,池化后的结果与卷积后的结果相加。
除了上面介绍的几种模型外,还有其他一些比较常见的模型:
- TextRNN:就是 TextRCNN 去掉 MaxPooling 后的部分。
- TextRNN + Attention:在 TextRNN 后面加了一个 Attention。这个模型还有个版本(HAN)是分层的,也就是先获取 word-level 的表示,在此基础上再获得 sentence-level 的表示,不同的层级分别对应有 Attention。
- FastText:Word + Bigram + Trigram,拼接后取序列平均。
- Transformer:完全的基于 Attention。
此外,一般也会做模型融合:
- 机器学习 + 深度学习
- 多个模型结果拼接后再用分类器分类
- 使用差异大的模型:模型差异越大,融合效果越好
- 重新划分训练集、验证集和测试集:相当于改变模型输入制造模型差异
因为 GPU 太贵了,就没有一一尝试了。一般比较好的结果应该是:
- 合理的数据集
- 精细的预处理
- 适当的特征工程
- 不同模型融合
Others
-
数据不平衡问题
-
补充数据,或用相关数据增强数据
-
对数目小的类别进行过采样
-
调整 loss 中样本权重
-
-
标签相似问题
References
- lonePatient/Bert-Multi-Label-Text-Classification: This repo contains a PyTorch implementation of a pretrained BERT model for multi-label text classification.
- 649453932/Bert-Chinese-Text-Classification-Pytorch: 使用Bert,ERNIE,进行中文文本分类
- Tencent/NeuralNLP-NeuralClassifier: An Open-source Neural Hierarchical Multi-label Text Classification Toolkit
- 中文文本分类 pytorch实现 - 知乎
- PyTorch 官方教程中文版 - PyTorch 官方教程中文版
- GuidoPaul/CAIL2019: 中国法研杯司法人工智能挑战赛之相似案例匹配第一名解决方案
- jingyihiter/mycail: 中国法研杯 - 司法人工智能挑战赛
- 中文文本分类 pytorch实现 - 知乎
- 如何到 top5%?NLP 文本分类和情感分析竞赛总结
- 用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践 - 知乎
- “达观杯”文本分类挑战赛Top10经验分享 - 知乎
- 中国法研杯---司法人工智能挑战赛 - 知乎
- 达观数据曾彦能:如何用深度学习做好长文本分类与法律文书智能化处理 - 云 + 社区 - 腾讯云
- 深度学习网络调参技巧 - 知乎
Changelog
-
191130 add 中文处理
-
191127 updated usage details
-
191126 created
