Metaworld Save
Collections of robotics environments geared towards benchmarking multi-task and meta reinforcement learning
Meta-World
![]()
![]()
The current version of Meta-World is a work in progress. If you find any bugs/errors please open an issue.
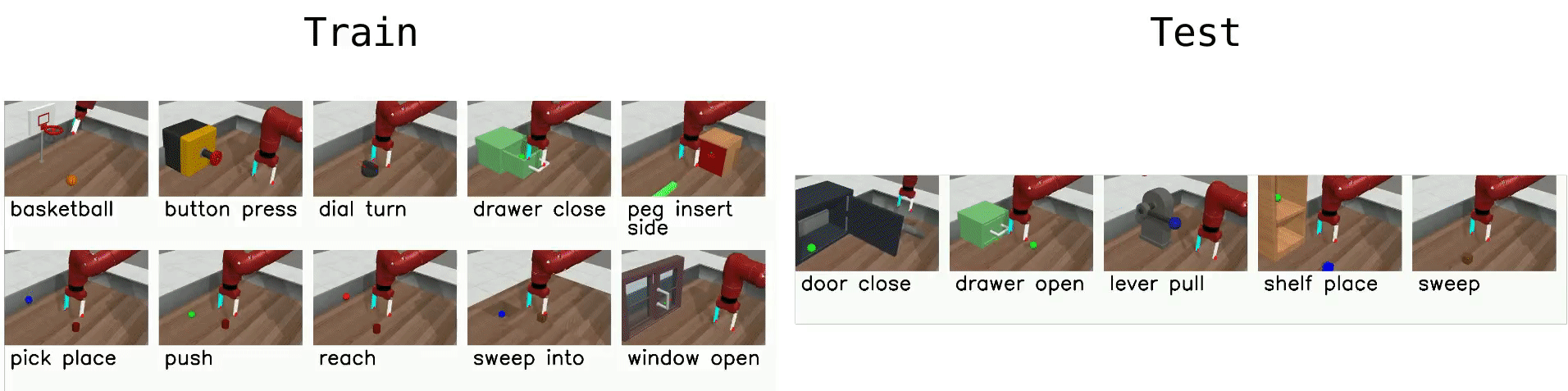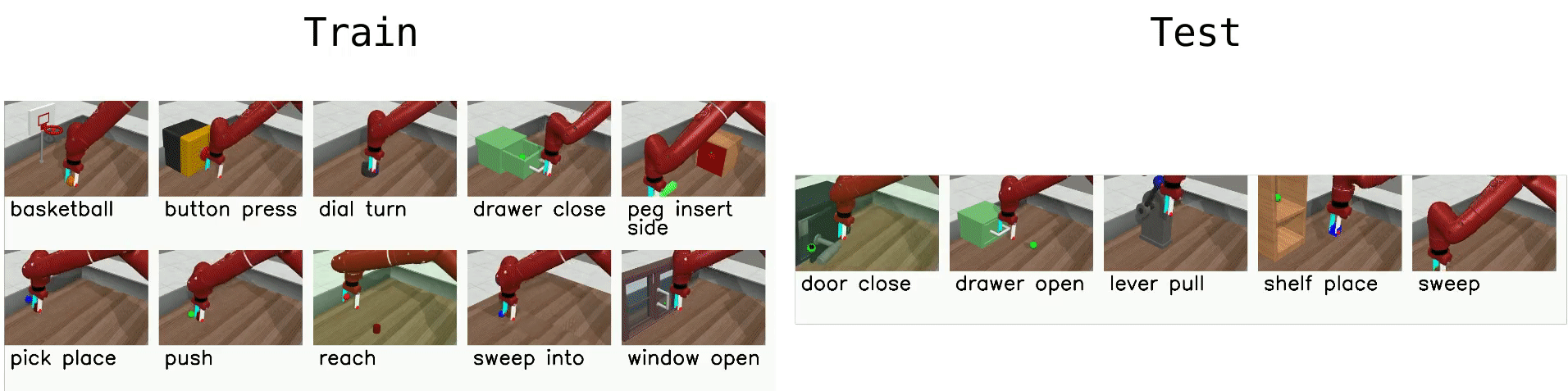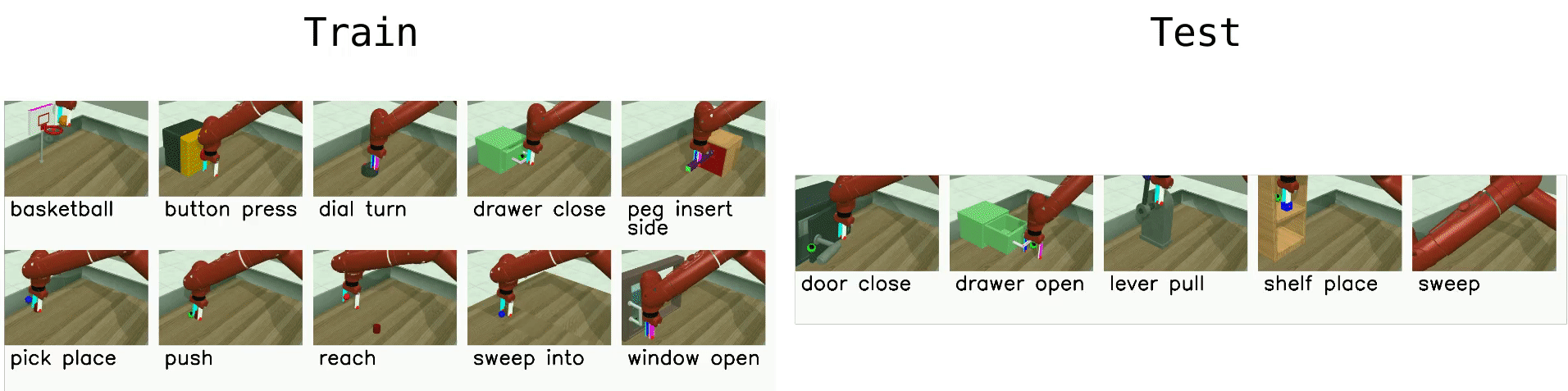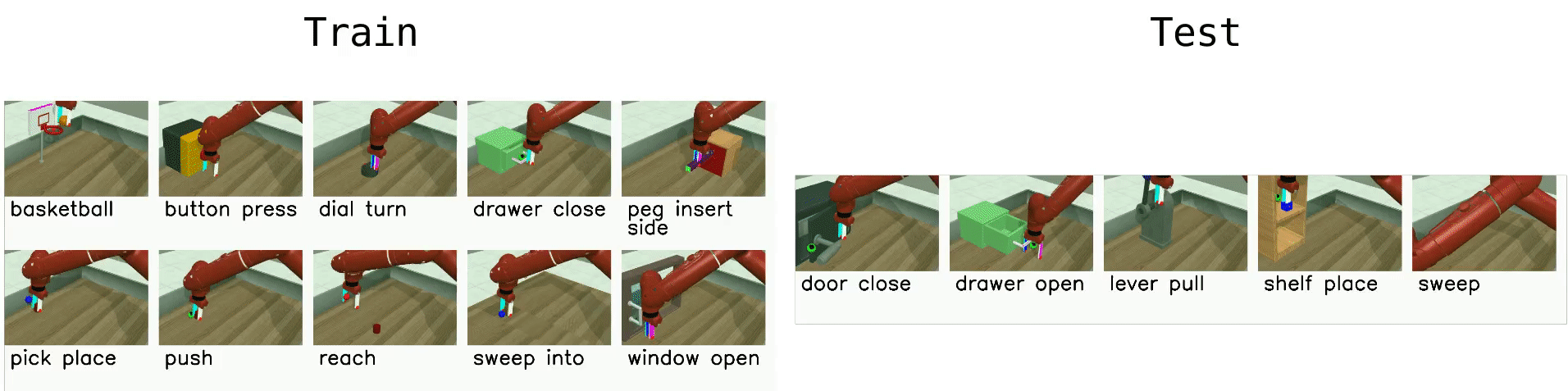
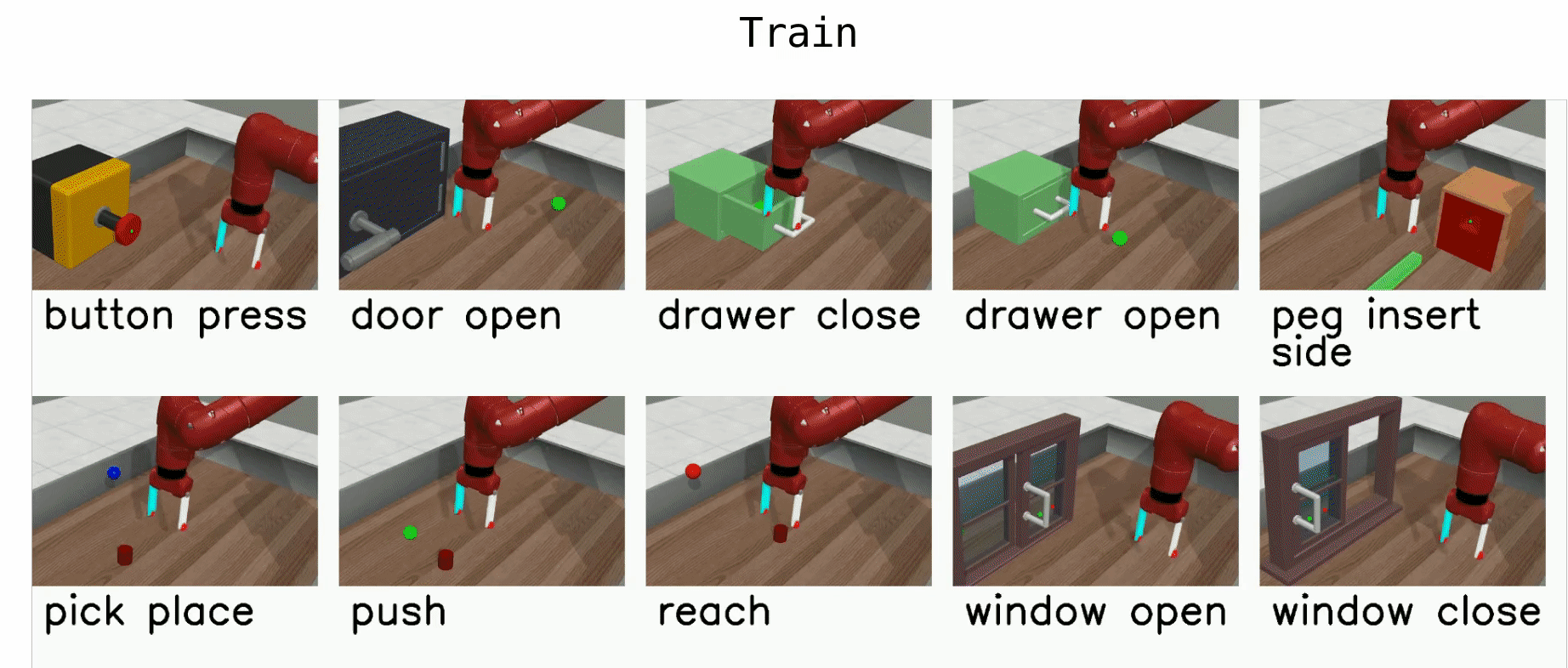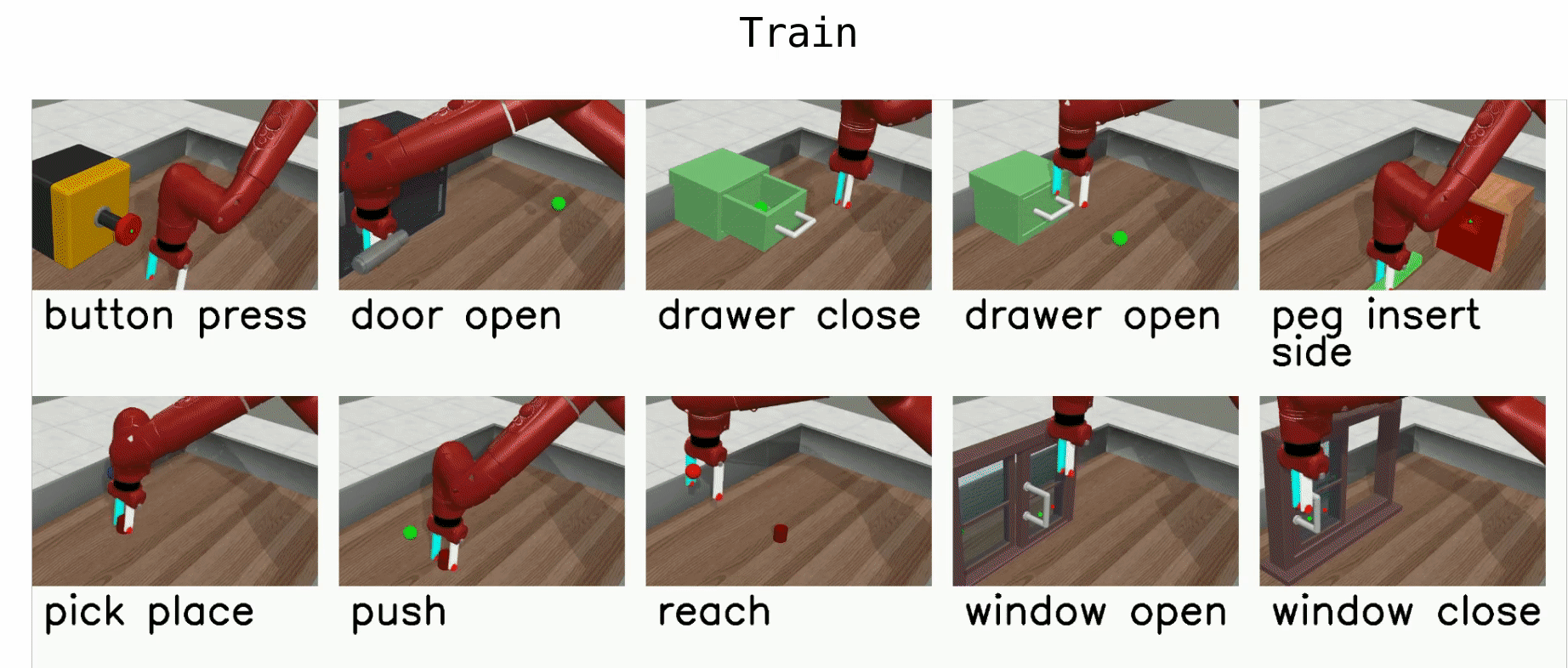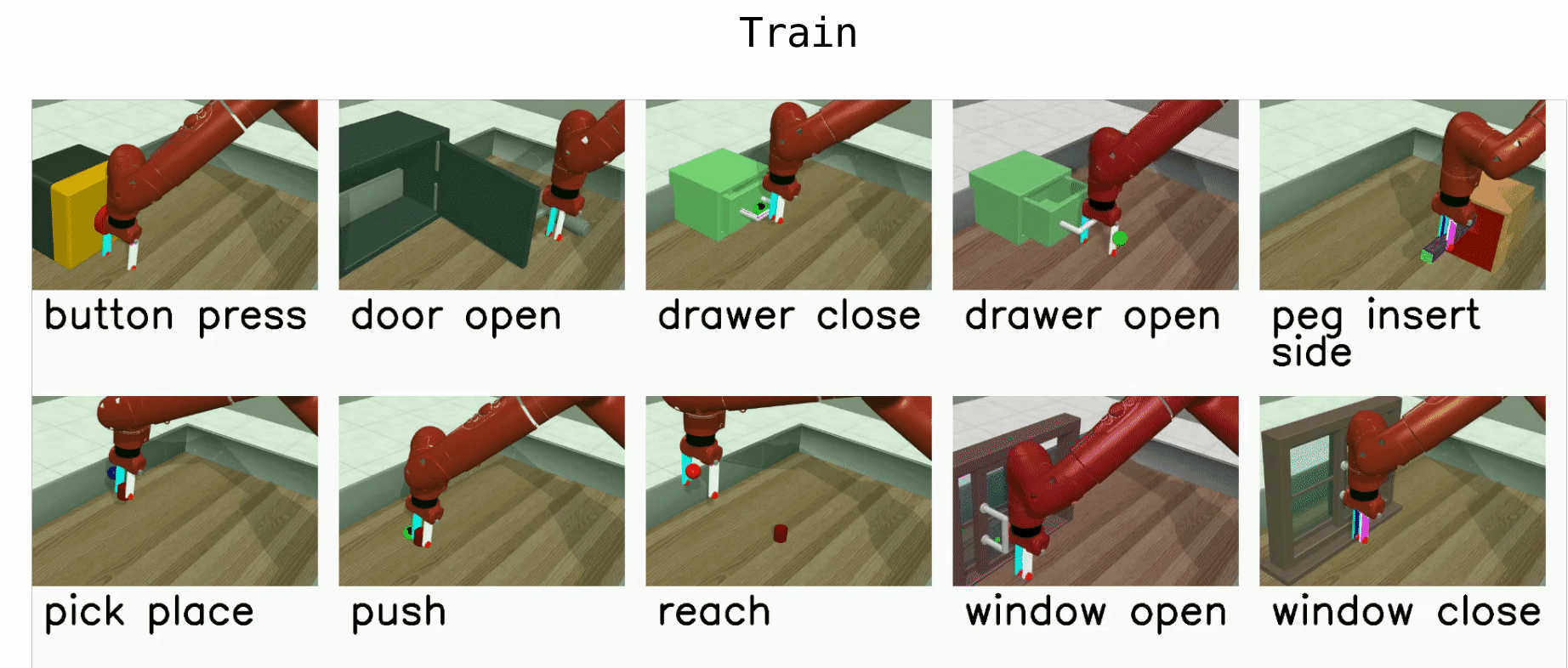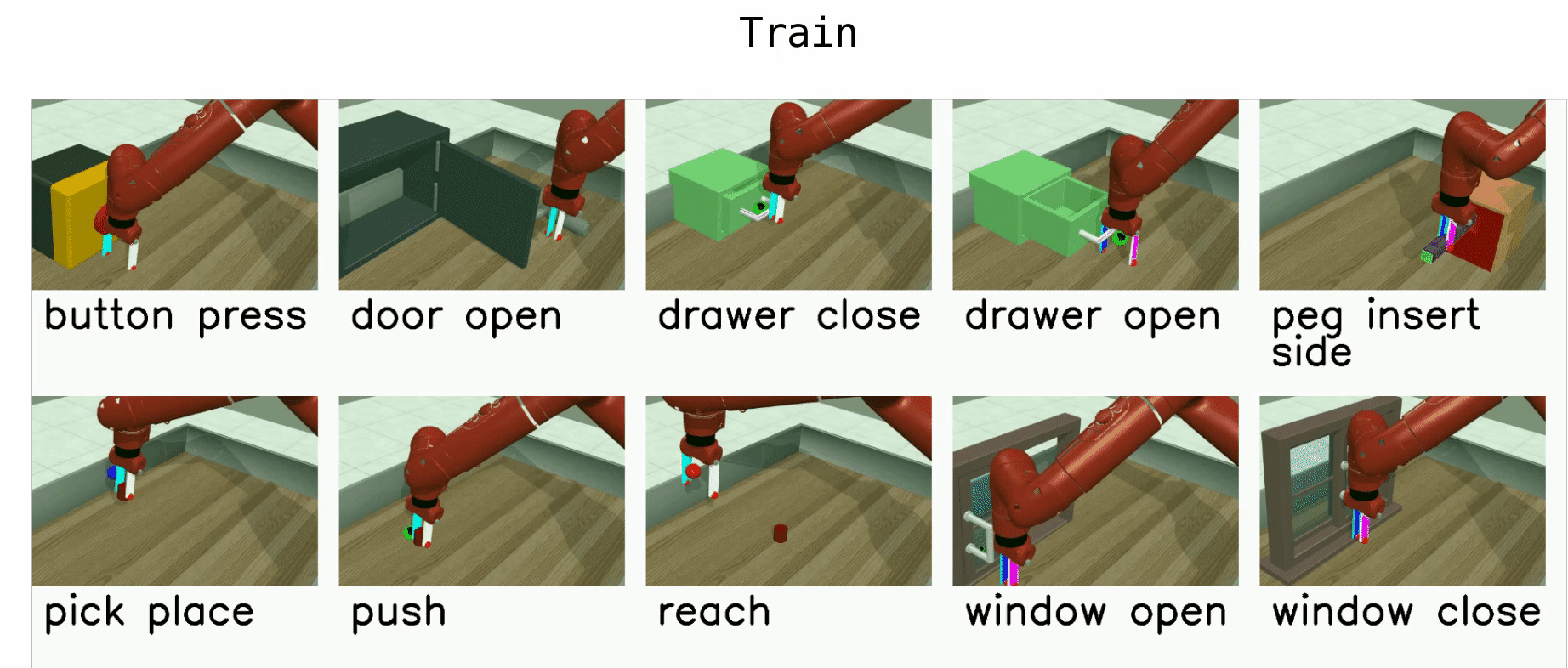
Meta-World is an open-source simulated benchmark for meta-reinforcement learning and multi-task learning consisting of 50 distinct robotic manipulation tasks. We aim to provide task distributions that are sufficiently broad to evaluate meta-RL algorithms' generalization ability to new behaviors.
For more background information, please refer to our website and the accompanying conference publication, which provides baseline results for 8 state-of-the-art meta- and multi-task RL algorithms.
Table of Contents
- Installation
- Using the benchmark
- Citing Meta-World
- Accompanying Baselines
- Become a Contributor
- Acknowledgements
Join the Community
Metaworld is now maintained by the Farama Foundation! You can interact with our community and the new developers in our Discord server
Maintenance Status
The current roadmap for Meta-World can be found here
Installation
To install everything, run:
pip install git+https://github.com/Farama-Foundation/Metaworld.git@master#egg=metaworld
Alternatively, you can clone the repository and install an editable version locally:
git clone https://github.com/Farama-Foundation/Metaworld.git
cd Metaworld
pip install -e .
For users attempting to reproduce results found in the Meta-World paper please use this command:
pip install git+https://github.com/Farama-Foundation/Metaworld.git@04be337a12305e393c0caf0cbf5ec7755c7c8feb
Using the benchmark
Here is a list of benchmark environments for meta-RL (ML*) and multi-task-RL (MT*):
- ML1 is a meta-RL benchmark environment which tests few-shot adaptation to goal variation within single task. You can choose to test variation within any of 50 tasks for this benchmark.
- ML10 is a meta-RL benchmark which tests few-shot adaptation to new tasks. It comprises 10 meta-train tasks, and 3 test tasks.
- ML45 is a meta-RL benchmark which tests few-shot adaptation to new tasks. It comprises 45 meta-train tasks and 5 test tasks.
- MT10, MT1, and MT50 are multi-task-RL benchmark environments for learning a multi-task policy that perform 10, 1, and 50 training tasks respectively. MT1 is similar to ML1 because you can choose to test variation within any of 50 tasks for this benchmark. In the original Meta-World experiments, we augment MT10 and MT50 environment observations with a one-hot vector which identifies the task. We don't enforce how users utilize task one-hot vectors, however one solution would be to use a Gym wrapper such as this one
Basics
We provide a Benchmark API, that allows constructing environments following the gymnasium.Env interface.
To use a Benchmark, first construct it (this samples the tasks allowed for one run of an algorithm on the benchmark).
Then, construct at least one instance of each environment listed in benchmark.train_classes and benchmark.test_classes.
For each of those environments, a task must be assigned to it using
env.set_task(task) from benchmark.train_tasks and benchmark.test_tasks,
respectively.
Tasks can only be assigned to environments which have a key in
benchmark.train_classes or benchmark.test_classes matching task.env_name.
Please see the sections Running ML1, MT1 and Running ML10, ML45, MT10, MT50
for more details.
You may wish to only access individual environments used in the Metaworld benchmark for your research. See the Accessing Single Goal Environments for more details.
Seeding a Benchmark Instance
For the purposes of reproducibility, it may be important to you to seed your benchmark instance. For example, for the ML1 benchmark environment with the 'pick-place-v2' environment, you can do so in the following way:
import metaworld
SEED = 0 # some seed number here
benchmark = metaworld.ML1('pick-place-v2', seed=SEED)
Running ML1 or MT1
import metaworld
import random
print(metaworld.ML1.ENV_NAMES) # Check out the available environments
ml1 = metaworld.ML1('pick-place-v2') # Construct the benchmark, sampling tasks
env = ml1.train_classes['pick-place-v2']() # Create an environment with task `pick_place`
task = random.choice(ml1.train_tasks)
env.set_task(task) # Set task
obs = env.reset() # Reset environment
a = env.action_space.sample() # Sample an action
obs, reward, done, info = env.step(a) # Step the environment with the sampled random action
MT1 can be run the same way except that it does not contain any test_tasks
Running a benchmark
Create an environment with train tasks (ML10, MT10, ML45, or MT50):
import metaworld
import random
ml10 = metaworld.ML10() # Construct the benchmark, sampling tasks
training_envs = []
for name, env_cls in ml10.train_classes.items():
env = env_cls()
task = random.choice([task for task in ml10.train_tasks
if task.env_name == name])
env.set_task(task)
training_envs.append(env)
for env in training_envs:
obs = env.reset() # Reset environment
a = env.action_space.sample() # Sample an action
obs, reward, done, info = env.step(a) # Step the environment with the sampled random action
Create an environment with test tasks (this only works for ML10 and ML45, since MT10 and MT50 don't have a separate set of test tasks):
import metaworld
import random
ml10 = metaworld.ML10() # Construct the benchmark, sampling tasks
testing_envs = []
for name, env_cls in ml10.test_classes.items():
env = env_cls()
task = random.choice([task for task in ml10.test_tasks
if task.env_name == name])
env.set_task(task)
testing_envs.append(env)
for env in testing_envs:
obs = env.reset() # Reset environment
a = env.action_space.sample() # Sample an action
obs, reward, done, info = env.step(a) # Step the environment with the sampled random action
Accessing Single Goal Environments
You may wish to only access individual environments used in the Meta-World benchmark for your research. We provide constructors for creating environments where the goal has been hidden (by zeroing out the goal in the observation) and environments where the goal is observable. They are called GoalHidden and GoalObservable environments respectively.
You can access them in the following way:
from metaworld.envs import (ALL_V2_ENVIRONMENTS_GOAL_OBSERVABLE,
ALL_V2_ENVIRONMENTS_GOAL_HIDDEN)
# these are ordered dicts where the key : value
# is env_name : env_constructor
import numpy as np
door_open_goal_observable_cls = ALL_V2_ENVIRONMENTS_GOAL_OBSERVABLE["door-open-v2-goal-observable"]
door_open_goal_hidden_cls = ALL_V2_ENVIRONMENTS_GOAL_HIDDEN["door-open-v2-goal-hidden"]
env = door_open_goal_hidden_cls()
env.reset() # Reset environment
a = env.action_space.sample() # Sample an action
obs, reward, done, info = env.step(a) # Step the environment with the sampled random action
assert (obs[-3:] == np.zeros(3)).all() # goal will be zeroed out because env is HiddenGoal
# You can choose to initialize the random seed of the environment.
# The state of your rng will remain unaffected after the environment is constructed.
env1 = door_open_goal_observable_cls(seed=5)
env2 = door_open_goal_observable_cls(seed=5)
env1.reset() # Reset environment
env2.reset()
a1 = env1.action_space.sample() # Sample an action
a2 = env2.action_space.sample()
next_obs1, _, _, _ = env1.step(a1) # Step the environment with the sampled random action
next_obs2, _, _, _ = env2.step(a2)
assert (next_obs1[-3:] == next_obs2[-3:]).all() # 2 envs initialized with the same seed will have the same goal
assert not (next_obs2[-3:] == np.zeros(3)).all() # The env's are goal observable, meaning the goal is not zero'd out
env3 = door_open_goal_observable_cls(seed=10) # Construct an environment with a different seed
env1.reset() # Reset environment
env3.reset()
a1 = env1.action_space.sample() # Sample an action
a3 = env3.action_space.sample()
next_obs1, _, _, _ = env1.step(a1) # Step the environment with the sampled random action
next_obs3, _, _, _ = env3.step(a3)
assert not (next_obs1[-3:] == next_obs3[-3:]).all() # 2 envs initialized with different seeds will have different goals
assert not (next_obs1[-3:] == np.zeros(3)).all() # The env's are goal observable, meaning the goal is not zero'd out
Citing Meta-World
If you use Meta-World for academic research, please kindly cite our CoRL 2019 paper the using following BibTeX entry.
@inproceedings{yu2019meta,
title={Meta-World: A Benchmark and Evaluation for Multi-Task and Meta Reinforcement Learning},
author={Tianhe Yu and Deirdre Quillen and Zhanpeng He and Ryan Julian and Karol Hausman and Chelsea Finn and Sergey Levine},
booktitle={Conference on Robot Learning (CoRL)},
year={2019}
eprint={1910.10897},
archivePrefix={arXiv},
primaryClass={cs.LG}
url={https://arxiv.org/abs/1910.10897}
}
Accompanying Baselines
If you're looking for implementations of the baselines algorithms used in the Meta-World conference publication, please look at our sister directory, Garage.
Note that these aren't the exact same baselines that were used in the original conference publication, however they are true to the original baselines.
Become a Contributor
We welcome all contributions to Meta-World. Please refer to the contributor's guide for how to prepare your contributions.
Acknowledgements
Meta-World is a work by Tianhe Yu (Stanford University), Deirdre Quillen (UC Berkeley), Zhanpeng He (Columbia University), Ryan Julian (University of Southern California), Karol Hausman (Google AI), Chelsea Finn (Stanford University) and Sergey Levine (UC Berkeley).
The code for Meta-World was originally based on multiworld, which is developed by Vitchyr H. Pong, Murtaza Dalal, Ashvin Nair, Shikhar Bahl, Steven Lin, Soroush Nasiriany, Kristian Hartikainen and Coline Devin. The Meta-World authors are grateful for their efforts on providing such a great framework as a foundation of our work. We also would like to thank Russell Mendonca for his work on reward functions for some of the environments.

{kind=link}
{kind=link}
{kind=link}
{kind=link}