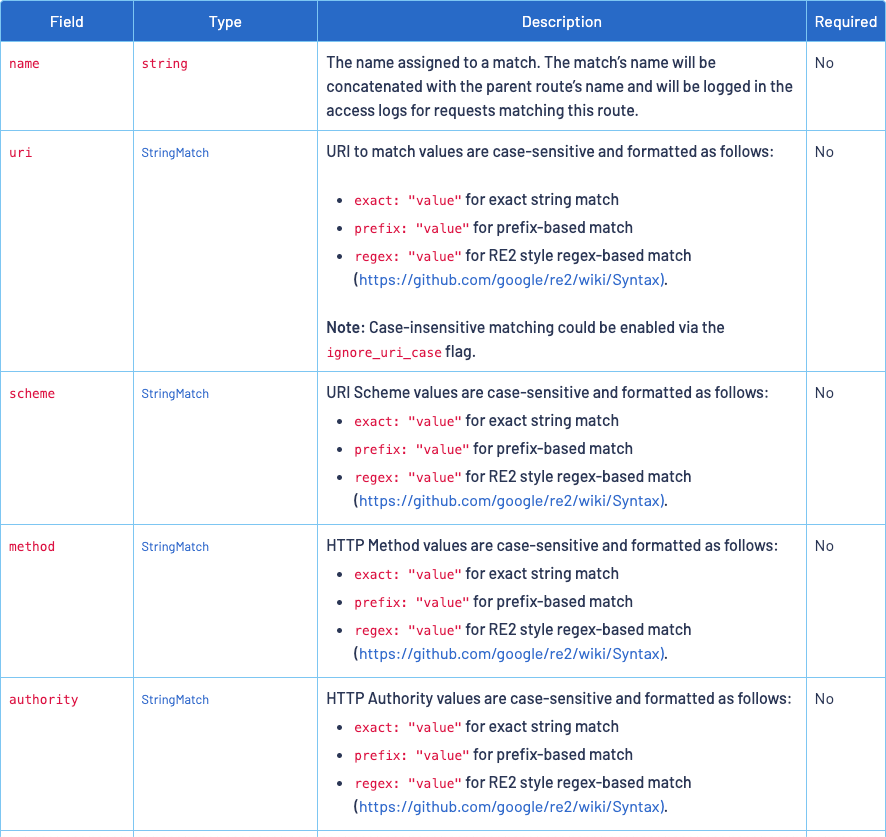
K8s Combat Save
☸️适用于研发人员的 k8s 实战项目🐳

背景
最近这这段时间更新了一些 k8s 相关的博客和视频,也收到了一些反馈;大概分为这几类:
- 公司已经经历过服务化改造了,但还未接触过云原生。
- 公司部分应用进行了云原生改造,但大部分工作是由基础架构和运维部门推动的,自己只是作为开发并不了解其中的细节,甚至 k8s 也接触不到。
- 还处于比较传统的以虚拟机部署的传统运维为主。
其中以第二种占大多数,虽然公司进行了云原生改造,但似乎和纯业务研发同学来说没有太大关系,自己工作也没有什么变化。
恰好我之前正好从业务研发的角度转换到了基础架构部门,两个角色我都接触过,也帮助过一些业务研发了解公司的云原生架构;
为此所以我想系统性的带大家以研发的角度对 k8s 进行实践。
因为 k8s 部分功能其实是偏运维的,对研发来说优先级并不太高; 所以我不太会涉及一些 k8s 运维的知识点,比如安装、组件等模块;主要以我们日常开发会使用到的组件为主。

入门
进阶
运维你的应用
- 应用探针
- 滚动更新与回滚
- 优雅采集日志
- 应用可观测性
- 指标可视化
部署应用到 k8s
首先从第一章【部署应用到 k8s】开始,我会用 Go 写一个简单的 Web 应用,然后打包为一个 Docker 镜像,之后部署到 k8s 中,并完成其中的接口调用。
编写应用
func main() {
http.HandleFunc("/ping", func(w http.ResponseWriter, r *http.Request) {
log.Println("ping")
fmt.Fprint(w, "pong")
})
http.ListenAndServe(":8081", nil)
}
应用非常简单就是提供了一个 ping 接口,然后返回了一个 pong.
Dockerfile
# 第一阶段:编译 Go 程序
FROM golang:1.19 AS dependencies
ENV GOPROXY=https://goproxy.cn,direct
WORKDIR /go/src/app
COPY go.mod .
#COPY ../../go.sum .
RUN --mount=type=ssh go mod download
# 第二阶段:构建可执行文件
FROM golang:1.19 AS builder
WORKDIR /go/src/app
COPY . .
#COPY --from=dependencies /go/pkg /go/pkg
RUN go build
# 第三阶段:部署
FROM debian:stable-slim
RUN apt-get update && apt-get install -y curl
COPY --from=builder /go/src/app/k8s-combat /go/bin/k8s-combat
ENV PATH="/go/bin:${PATH}"
# 启动 Go 程序
CMD ["k8s-combat"]
之后编写了一个 dockerfile 用于构建 docker 镜像。
docker:
@echo "Docker Build..."
docker build . -t crossoverjie/k8s-combat:v1 && docker image push crossoverjie/k8s-combat:v1
使用 make docker 会在本地构建镜像并上传到 dockerhub
编写 deployment
下一步便是整个过程中最重要的环节了,也是唯一和 k8s 打交道的地方,那就是编写 deployment。
在之前的视频[《一分钟了解 k8s》](【一分钟带你了解 k8s】 https://www.bilibili.com/video/BV1Cm4y1n7yG/?share_source=copy_web&vd_source=358858ab808efe832b0dda9dbc4701da)
中讲过常见的组件:
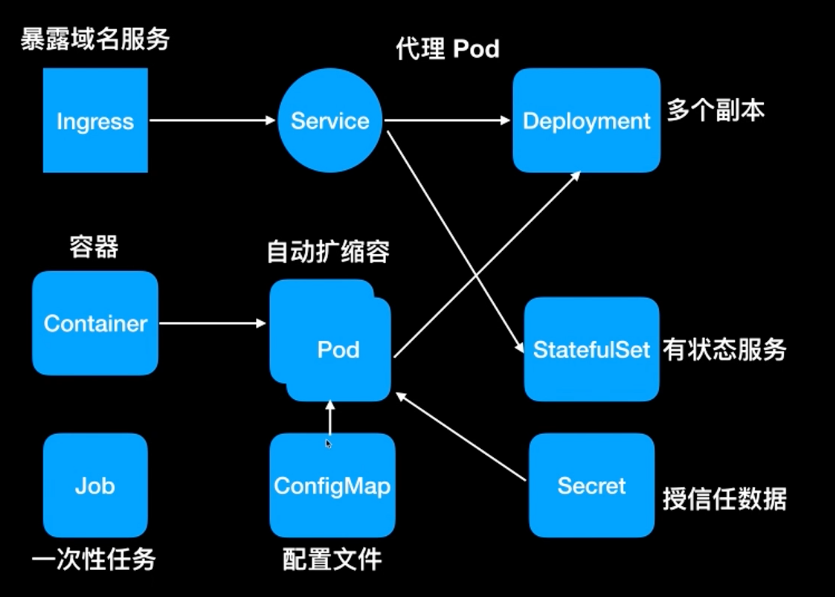
其中我们最常见的就是 deployment,通常用于部署无状态应用;现在还不太需要了解其他的组件,先看看 deployment 如何编写:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: k8s-combat
name: k8s-combat
spec:
replicas: 1
selector:
matchLabels:
app: k8s-combat
template:
metadata:
labels:
app: k8s-combat
spec:
containers:
- name: k8s-combat
image: crossoverjie/k8s-combat:v1
imagePullPolicy: Always
resources:
limits:
cpu: "1"
memory: 300Mi
requests:
cpu: "0.1"
memory: 30Mi
开头两行的 apiVersion 和 kind 可以暂时不要关注,就理解为 deployment 的固定写法即可。
metadata:顾名思义就是定义元数据的地方,告诉 Pod 我们这个 deployment 叫什么名字,这里定义为:k8s-combat
中间的:
metadata:
labels:
app: k8s-combat
也很容易理解,就是给这个 deployment 打上标签,通常是将这个标签和其他的组件进行关联使用才有意义,不然就只是一个标签而已。
标签是键值对的格式,key, value 都可以自定义。
而这里的 app: k8s-combat 便是和下面的 spec 下的 selector 选择器匹配,表明都使用 app: k8s-combat 进行关联。
而 template 中所定义的标签也是为了让选择器和 template 中的定义的 Pod 进行关联。
Pod 是 k8s 中相同功能容器的分组,一个 Pod 可以绑定多个容器,这里就只有我们应用容器一个了;后续在讲到 istio 和日志采集时便可以看到其他的容器。
template 中定义的内容就很容易理解了,指定了我们的容器拉取地址,以及所占用的资源(cpu/ memory)。
replicas: 1:表示只部署一个副本,也就是只有一个节点的意思。
部署应用
之后我们使用命令:
kubectl apply -f deployment/deployment.yaml
生产环境中往往会使用云厂商所提供的 k8s 环境,我们本地可以使用 https://minikube.sigs.k8s.io/docs/start/ minikube 来模拟。
就会应用这个 deployment 同时将容器部署到 k8s 中,之后使用:
kubectl get pod
在后台 k8s 会根据我们填写的资源选择一个合适的节点,将当前这个 Pod 部署过去。
就会列出我们刚才部署的 Pod:
❯ kubectl get pod
NAME READY STATUS RESTARTS AGE
k8s-combat-57f794c59b-7k58n 1/1 Running 0 17h
我们使用命令:
kubectl exec -it k8s-combat-57f794c59b-7k58n bash
就会进入我们的容器,这个和使用 docker 类似。
之后执行 curl 命令便可以访问我们的接口了:
root@k8s-combat-57f794c59b-7k58n:/# curl http://127.0.0.1:8081/ping
pong
root@k8s-combat-57f794c59b-7k58n:/#
这时候我们再开一个终端执行:
❯ kubectl logs -f k8s-combat-57f794c59b-7k58n
2023/09/03 09:28:07 ping
便可以打印容器中的日志,当然前提是应用的日志是写入到了标准输出中。
跨服务调用
在做传统业务开发的时候,当我们的服务提供方有多个实例时,往往我们需要将对方的服务列表保存在本地,然后采用一定的算法进行调用;当服务提供方的列表变化时还得及时通知调用方。
student:
url:
- 192.168.1.1:8081
- 192.168.1.2:8081
这样自然是对双方都带来不少的负担,所以后续推出的服务调用框架都会想办法解决这个问题。
以 spring cloud 为例:
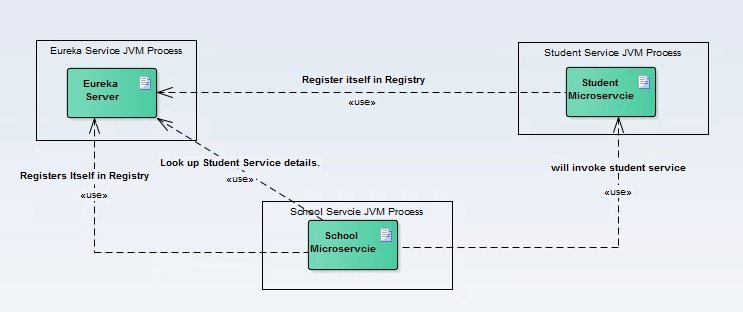
服务提供方会向一个服务注册中心注册自己的服务(名称、IP等信息),客户端每次调用的时候会向服务注册中心获取一个节点信息,然后发起调用。
但当我们切换到 k8s 后,这些基础设施都交给了 k8s 处理了,所以 k8s 自然得有一个组件来解决服务注册和调用的问题。
也就是我们今天重点介绍的 service。
service
在介绍 service 之前我先调整了源码:
func main() {
http.HandleFunc("/ping", func(w http.ResponseWriter, r *http.Request) {
name, _ := os.Hostname()
log.Printf("%s ping", name)
fmt.Fprint(w, "pong")
})
http.HandleFunc("/service", func(w http.ResponseWriter, r *http.Request) {
resp, err := http.Get("http://k8s-combat-service:8081/ping")
if err != nil {
log.Println(err)
fmt.Fprint(w, err)
return
}
fmt.Fprint(w, resp.Status)
})
http.ListenAndServe(":8081", nil)
}
新增了一个 /service 的接口,这个接口会通过 service 的方式调用服务提供者的服务,然后重新打包。
make docker
同时也新增了一个 deployment-service.yaml:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: k8s-combat-service # 通过标签选择关联
name: k8s-combat-service
spec:
replicas: 1
selector:
matchLabels:
app: k8s-combat-service
template:
metadata:
labels:
app: k8s-combat-service
spec:
containers:
- name: k8s-combat-service
image: crossoverjie/k8s-combat:v1
imagePullPolicy: Always
resources:
limits:
cpu: "1"
memory: 100Mi
requests:
cpu: "0.1"
memory: 10Mi
---
apiVersion: v1
kind: Service
metadata:
name: k8s-combat-service
spec:
selector:
app: k8s-combat-service # 通过标签选择关联
type: ClusterIP
ports:
- port: 8081 # 本 Service 的端口
targetPort: 8081 # 容器端口
name: app
使用相同的镜像部署一个新的 deployment,名称为 k8s-combat-service,重点是新增了一个kind: Service 的对象。
这个就是用于声明 service 的组件,在这个组件中也是使用 selector 标签和 deployment 进行了关联。
也就是说这个 service 用于服务于名称等于 k8s-combat-service 的 deployment。
下面的两个端口也很好理解,一个是代理的端口, 另一个是 service 自身提供出去的端口。
至于 type: ClusterIP 是用于声明不同类型的 service,除此之外的类型还有:
-
NodePort -
LoadBalancer -
ExternalName等类型,默认是ClusterIP,现在不用纠结这几种类型的作用,后续我们在讲到Ingress的时候会具体介绍。
负载测试
我们先分别将这两个 deployment 部署好:
k apply -f deployment/deployment.yaml
k apply -f deployment/deployment-service.yaml
❯ k get pod
NAME READY STATUS RESTARTS AGE
k8s-combat-7867bfb596-67p5m 1/1 Running 0 3h22m
k8s-combat-service-5b77f59bf7-zpqwt 1/1 Running 0 3h22m
由于我新增了一个 /service 的接口,用于在 k8s-combat 中通过 service 调用 k8s-combat-service 的接口。
resp, err := http.Get("http://k8s-combat-service:8081/ping")
其中 k8s-combat-service 服务的域名就是他的服务名称。
如果是跨 namespace 调用时,需要指定一个完整名称,在后续的章节会演示。
我们整个的调用流程如下:
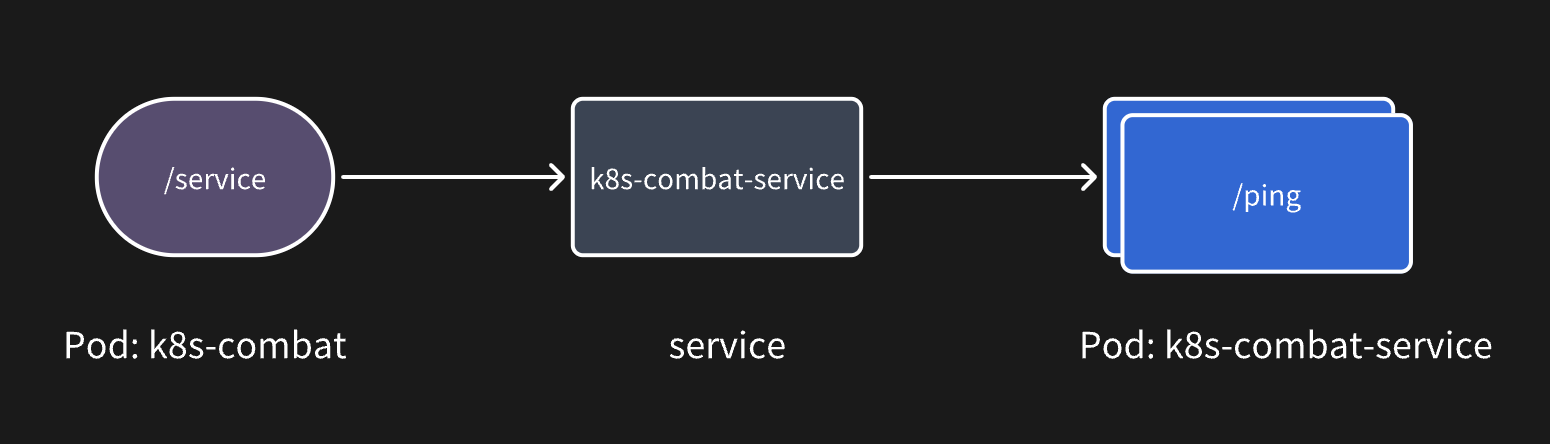
相信大家也看得出来相对于 spring cloud 这类微服务框架提供的客户端负载方式,service 是一种服务端负载,有点类似于 Nginx 的反向代理。
为了更直观的验证这个流程,此时我将 k8s-combat-service 的副本数增加到 2:
spec:
replicas: 2
只需要再次执行:
❯ k apply -f deployment/deployment-service.yaml
deployment.apps/k8s-combat-service configured
service/k8s-combat-service unchanged

不管我们对
deployment的做了什么变更,都只需要apply这个yaml文件即可, k8s 会自动将当前的deployment调整为我们预期的状态(比如这里的副本数量增加为 2);这也就是k8s中常说的声明式 API。
可以看到此时 k8s-combat-service 的副本数已经变为两个了。
如果我们此时查看这个 service 的描述时:
❯ k describe svc k8s-combat-service |grep Endpoints
Endpoints: 192.168.130.133:8081,192.168.130.29:8081
会发现它已经代理了这两个 Pod 的 IP。
 此时我进入了
此时我进入了 k8s-combat-7867bfb596-67p5m 的容器:
k exec -it k8s-combat-7867bfb596-67p5m bash
curl http://127.0.0.1:8081/service
并执行两次 /service 接口,发现请求会轮训进入 k8s-combat-service 的代理的 IP 中。
由于 k8s service 是基于 TCP/UDP 的四层负载,所以在 http1.1 中是可以做到请求级的负载均衡,但如果是类似于 gRPC 这类长链接就无法做到请求级的负载均衡。
换句话说 service 只支持连接级别的负载。
如果要支持 gRPC,就得使用 Istio 这类服务网格,相关内容会在后续章节详解。
总的来说 k8s service 提供了简易的服务注册发现和负载均衡功能,当我们只提供 http 服务时是完全够用的。
集群外部访问
前两章中我们将应用部署到了 k8s 中,同时不同的服务之间也可以通过 service 进行调用,现在还有一个步骤就是将我们的应用暴露到公网,并提供域名的访问。
这一步类似于我们以前配置 Nginx 和绑定域名,提供这个能力的服务在 k8s 中成为 Ingress。
通过这个描述其实也能看出 Ingress 是偏运维的工作,但也不妨碍我们作为研发去了解这部分的内容;了解整个系统是如何运转的也是研发应该掌握的技能。
安装 Ingress 控制器
在正式使用 Ingress 之前需要给 k8s 安装一个 Ingress 控制器,我们这里安装官方提供的 Ingress-nginx 控制器。
当然还有社区或者企业提供的各种控制器:

有两种安装方式: helm 或者是直接 apply 一个资源文件。
关于 helm 我们会在后面的章节单独讲解。
这里就直接使用资源文件安装即可,我已经上传到 GitHub 可以在这里访问: https://github.com/crossoverJie/k8s-combat/blob/main/deployment/ingress-nginx.yaml
其实这个文件也是直接从官方提供的复制过来的,也可以直接使用这个路径进行安装:
kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.8.2/deploy/static/provider/cloud/deploy.yaml
yaml 文件的内容是一样的。
不过要注意安装之后可能容器状态一直处于 Pending 状态,查看容器的事件时会发现镜像拉取失败。
k describe pod ingress-nginx-controller-7cdfb9988c-lbcst -n ingress-nginx
describe 是一个用于查看 k8s 对象详细信息的命令。
在刚才那份 yaml 文件中可以看到有几个镜像需要拉取,我们可以先在本地手动拉取镜像:

docker pull registry.k8s.io/ingress-nginx/controller:v1.8.2
如果依然无法拉取,可以尝试配置几个国内镜像源镜像拉取:
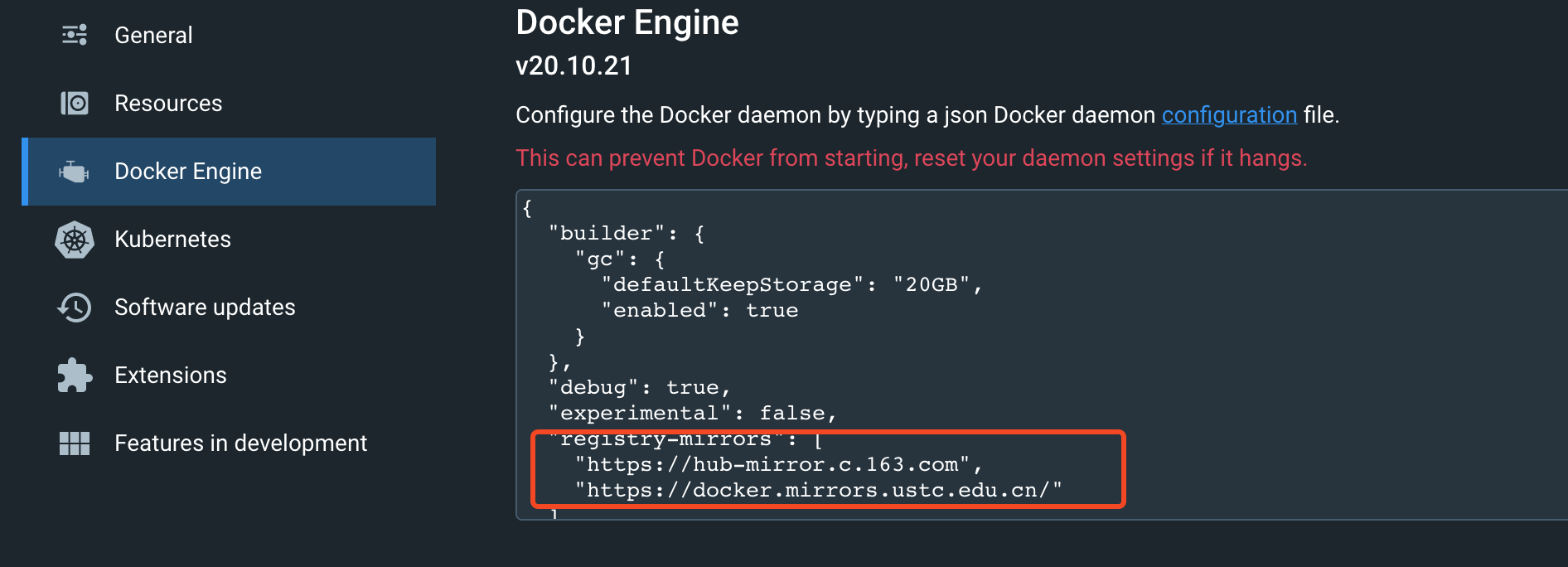
我这里使用的 docker-desktop 自带的 k8s,推荐读者朋友也使用这个工具。
创建 Ingress
使用刚才的 yaml 安装成功之后会在 ingress-nginx 命名空间下创建一个 Pod,通过 get 命令查看状态为 Running 即为安装成功。
$ k get pod -n ingress-nginx
NAME READY STATUS RESTARTS AGE
ingress-nginx-controller-7cdf 1/1 Running 2 (35h ago) 3d
Namespace 也是 k8s 内置的一个对象,可以简单理解为对资源进行分组管理,我们通常可以使用它来区分各个不同的环境,比如 dev/test/prod 等,不同命名空间下的资源不会互相干扰,且相互独立。
之后便可以创建 Ingress 资源了:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: k8s-combat-ingress
spec:
ingressClassName: nginx
rules:
- host: www.service1.io
http:
paths:
- backend:
service:
name: k8s-combat-service
port:
number: 8081
path: /
pathType: Prefix
- host: www.service2.io
http:
paths:
- backend:
service:
name: k8s-combat-service-2
port:
number: 8081
path: /
pathType: Prefix
看这个内容也很容易理解,创建了一个 Ingress 的对象,其中的重点就是这里的规则是如何定义的。
在 k8s 中今后还会接触到各种不同的 Kind
这里的 ingressClassName: nginx 也是在刚开始安装的控制器里定义的名字,由这个资源定义。
apiVersion: networking.k8s.io/v1
kind: IngressClass
metadata:
labels:
app.kubernetes.io/component: controller
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
app.kubernetes.io/version: 1.8.2
name: nginx
咱们这个规则很简单,就是将两个不同的域名路由到两个不同的 service。
这里为了方便测试又创建了一个
k8s-combat-service-2的 service,和k8s-combat-service是一样的,只是改了个名字而已。
测试
也是为了方便测试,我在应用镜像中新增了一个接口,用于返回当前 Pod 的 hostname。
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
name, _ := os.Hostname()
fmt.Fprint(w, name)
})
由于我实际并没有 www.service1.io/www.service2.io 这两个域名,所以只能在本地配置 host 进行模拟。
10.0.0.37 www.service1.io
10.0.0.37 www.service2.io
我测试所使用的 k8s 部署在我家里一台限制的 Mac 上,所以这里的 IP 它的地址。
当我们反复请求两次这个接口,会拿到两个不同的 hostname,也就是将我们的请求轮训负载到了这两个 service 所代理的两个 Pod 中。
❯ curl http://www.service1.io/
k8s-combat-service-79c5579587-b6nlj%
❯ curl http://www.service1.io/
k8s-combat-service-79c5579587-bk7nw%
❯ curl http://www.service2.io/
k8s-combat-service-2-7bbf56b4d9-dkj9b%
❯ curl http://www.service2.io/
k8s-combat-service-2-7bbf56b4d9-t5l4g
我们也可以直接使用 describe 查看我们的 ingress 定义以及路由规则:

$ k describe ingress k8s-combat-ingress
Name: k8s-combat-ingress
Labels: <none>
Namespace: default
Address: localhost
Ingress Class: nginx
Default backend: <default>
Rules:
Host Path Backends
---- ---- --------
www.service1.io
/ k8s-combat-service:8081 (10.1.0.65:8081,10.1.0.67:8081)
www.service2.io
/ k8s-combat-service-2:8081 (10.1.0.63:8081,10.1.0.64:8081)
Annotations: <none>
Events: <none>
如果我们手动新增一个域名解析:
10.0.0.37 www.service3.io
❯ curl http://www.service3.io/
<html>
<head><title>404 Not Found</title></head>
<body>
<center><h1>404 Not Found</h1></center>
<hr><center>nginx</center>
</body>
</html>
会直接 404,这是因为没有找到这个域名的规则。
访问原理
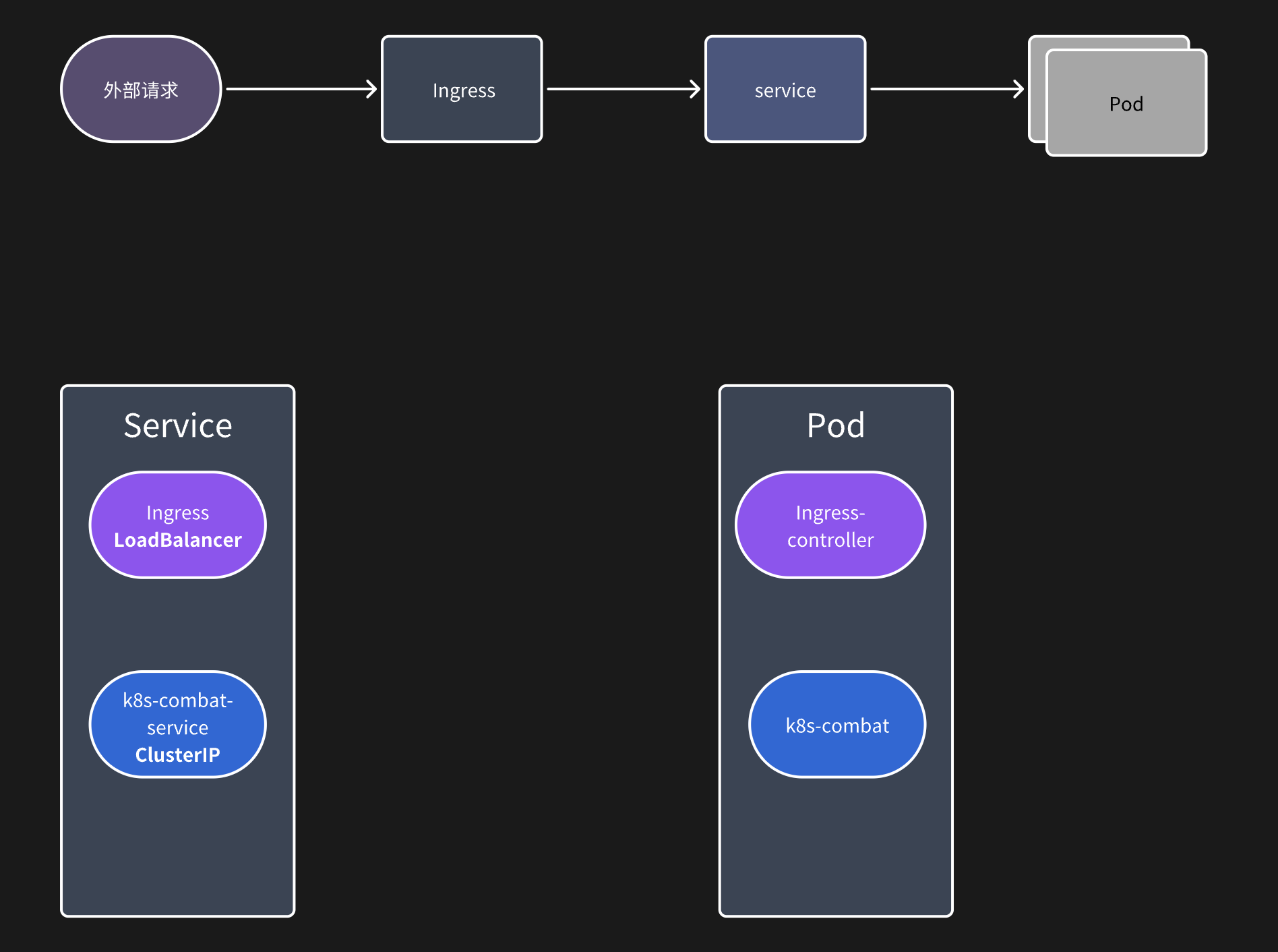 整个的请求路径如上图所示,其实我们的 Ingress 本质上也是一个 service(所以它也可以启动多个副本来进行负载),只是他的类型是
整个的请求路径如上图所示,其实我们的 Ingress 本质上也是一个 service(所以它也可以启动多个副本来进行负载),只是他的类型是 LoadBalancer,通常这种类型的 service 会由云厂商绑定一个外部 IP,这样就可以通过这个外部 IP 访问 Ingress 了。
而我们应用的 service 是 ClusterIP,只能在应用内部访问

通过 service 的信息也可以看到,我们 ingress 的 service 绑定的外部 IP 是 localhost(本地的原因)
总结
Ingress 通常是充当网关的作用,后续我们在使用 Istio 时,也可以使用 Istio 所提供的控制器来替换掉 Ingress-nginx,可以更方便的管理内外网流量。
本文的所有源码在这里可以访问: https://github.com/crossoverJie/k8s-combat
如何使用配置
在前面三节中已经讲到如何将我们的应用部署到 k8s 集群并提供对外访问的能力,x现在可以满足基本的应用开发需求了。
现在我们需要更进一步,使用 k8s 提供的一些其他对象来标准化我的应用开发。
首先就是 ConfigMap,从它的名字也可以看出这是用于管理配置的对象。
ConfigMap
不管我们之前是做 Java、Go 还是 Python 开发都会使用到配置文件,而 ConfigMap 的作用可以将我们原本写在配置文件里的内容转存到 k8s 中,然后和我们的 Container 进行绑定。
存储到环境变量
绑定的第一种方式就是将配置直接写入到环境变量,这里我先定义一个 ConfigMap:
apiVersion: v1
kind: ConfigMap
metadata:
name: k8s-combat-configmap
data:
PG_URL: "postgres://postgres:postgres@localhost:5432/postgres?sslmode=disable"
重点是 data 部分,存储的是一个 KV 结构的数据,这里存储的是一个数据库连接。
需要注意,KV 的大小不能超过 1MB
接着可以在容器定义中绑定这个 ConfigMap 的所有 KV 到容器的环境变量:
# Define all the ConfigMap's data as container environment variables
envFrom:
- configMapRef:
name: k8s-combat-configmap
我将 ConfigMap 的定义也放在了同一个 deployment 中,直接 apply:
❯ k apply -f deployment/deployment.yaml
deployment.apps/k8s-combat created
configmap/k8s-combat-configmap created
此时 ConfigMap 也会被创建,我们可以使用
❯ k get configmap
NAME DATA AGE
k8s-combat-configmap 1 3m17s
❯ k describe configmap k8s-combat-configmap
Data
====
PG_URL:
----
postgres://postgres:postgres@localhost:5432/postgres?sslmode=disable
拿到刚才声明的配置信息。
同时我在代码中也读取了这个环境变量:
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
name, _ := os.Hostname()
url := os.Getenv("PG_URL")
fmt.Fprint(w, fmt.Sprintf("%s-%s", name, url))
})
访问这个接口便能拿到这个环境变量:
root@k8s-combat-7b987bb496-pqt9s:/# curl http://127.0.0.1:8081
k8s-combat-7b987bb496-pqt9s-postgres://postgres:postgres@localhost:5432/postgres?sslmode=disable
root@k8s-combat-7b987bb496-pqt9s:/# echo $PG_URL
postgres://postgres:postgres@localhost:5432/postgres?sslmode=disable
存储到文件
有些时候我们也需要将这些配置存储到一个文件中,比如在 Java 中可以使用 spring 读取,Go 也可以使用 configor 这些第三方库来读取,所有配置都在一个文件中也更方便维护。
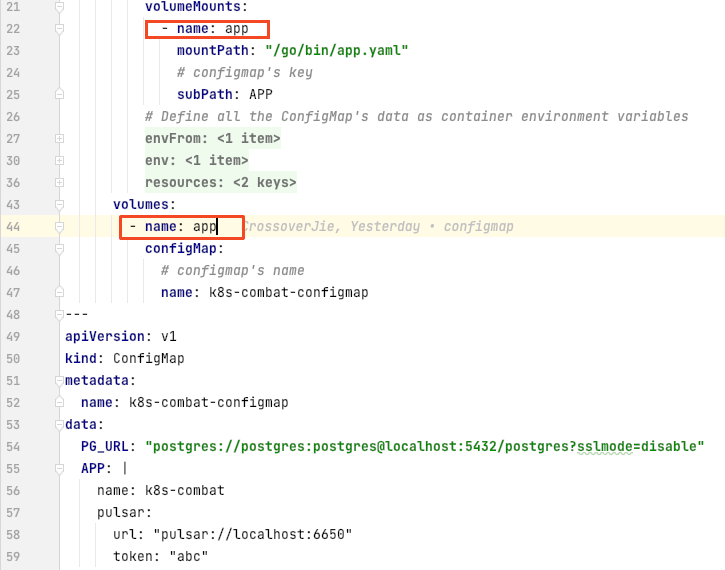 在
在 ConfigMap 中新增了一个 key:APP 存放了一个 yaml 格式的数据,然后在容器中使用 volumes 和 volumeMounts 将数据挂载到容器中的指定路径/go/bin/app.yaml
apply 之后我们可以在容器中查看这个文件是否存在:
root@k8s-combat-7b987bb496-pqt9s:/# cat /go/bin/app.yaml
name: k8s-combat
pulsar:
url: "pulsar://localhost:6650"
token: "abc"
配置已经成功挂载到了这个路径,我们便可以在代码中读取这些数据。
Secret
可以看到 ConfigMap 中是明文存储数据的;
k describe configmap k8s-combat-configmap
可以直接查看。
对一些敏感数据就不够用了,这时我们可以使用 Secret:
apiVersion: v1
kind: Secret
metadata:
name: k8s-combat-secret
type: Opaque
data:
PWD: YWJjCg==
---
env:
- name: PG_PWD
valueFrom:
secretKeyRef:
name: k8s-combat-secret
key: PWD
这里我新增了一个 Secret 用于存储密码,并在 container 中也将这个 key 写入到环境变量中。
❯ echo 'abc' | base64
YWJjCg==
Secret 中的数据需要使用 base64 进行编码,所以我这里存储的是 abc.
apply 之后我们再查看这个 Secret 是不能直接查看原始数据的。
❯ k describe secret k8s-combat-secret
Name: k8s-combat-secret
Type: Opaque
Data
====
PWD: 4 bytes
Secret 相比 ConfigMap 多了一个 Type 选项。
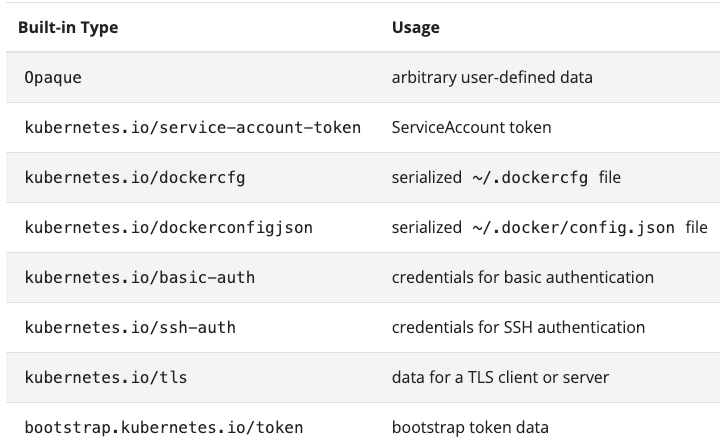
我们现阶段在应用中用的最多的就是这里的 Opaque,其他的暂时还用不上。
总结
在实际开发过程中研发人员基本上是不会直接接触 ConfigMap,一般会给开发者在管理台提供维护配置的页面进行 CRUD。
由于 ConfigMap 依赖于 k8s 与我们应用的语言无关,所以一些高级特性,比如实时更新就无法实现,每次修改后都得重启应用才能生效。
类似于 Java 中常见的配置中心:Apollo,Nacos 使用上会有不小的区别,但这些是应用语言强绑定的,如果业务对这些配置中心特性有强烈需求的话也是可以使用的。
但如果团队本身就是多语言研发,想要降低运维复杂度 ConfigMap 还是不二的选择。
Istio 入门
终于进入大家都比较感兴趣的服务网格系列了,在前面已经讲解了:
- 如何部署应用到
kubernetes - 服务之间如何调用
- 如何通过域名访问我们的服务
- 如何使用
kubernetes自带的配置ConfigMap
基本上已经够我们开发一般规模的 web 应用了;但在企业中往往有着复杂的应用调用关系,应用与应用之间的请求也需要进行管理。 比如常见的限流、降级、trace、监控、负载均衡等功能。
在我们使用 kubernetes 之前往往都是由微服务框架来解决这些问题,比如 Dubbo、SpringCloud 都有对应的功能。
但当我们上了 kubernetes 之后这些事情就应该交给一个专门的云原生组件来解决,也就是本次会讲到的 Istio,它是目前使用最为广泛的服务网格解决方案。
 官方对于 Istio 的解释比较简洁,落到具体的功能点也就是刚才提到的:
官方对于 Istio 的解释比较简洁,落到具体的功能点也就是刚才提到的:
- 限流降级
- 路由转发、负载均衡
- 入口网关、
TLS安全认证 - 灰度发布等
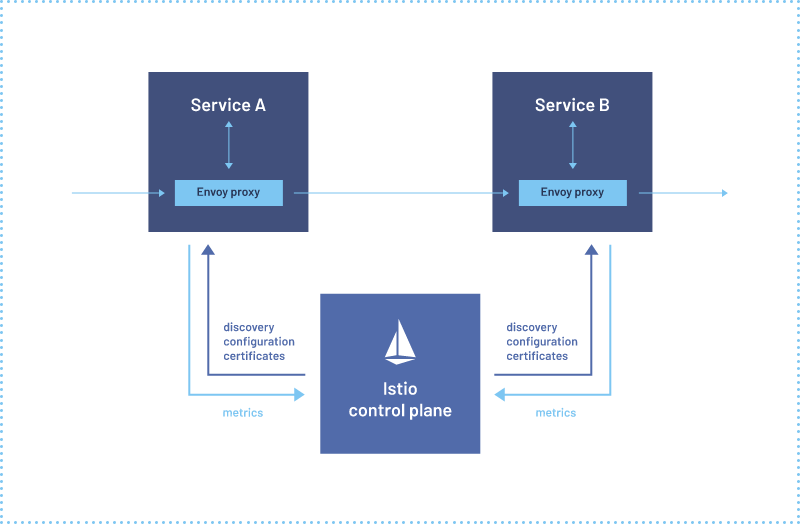
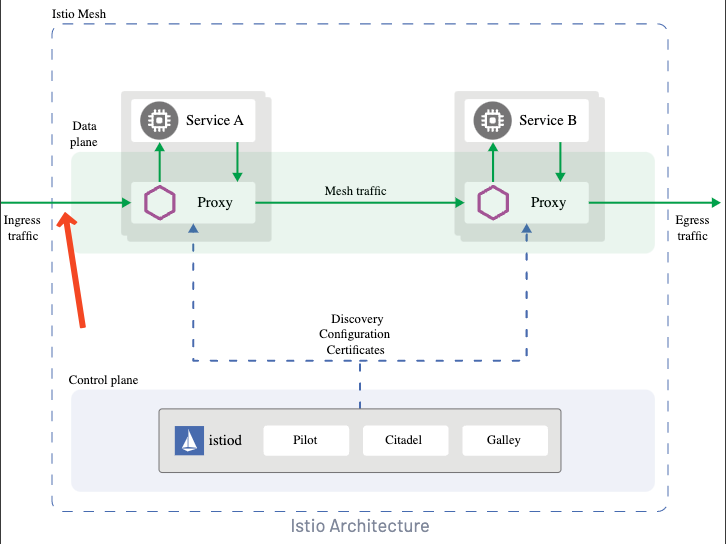
再结合官方的架构图可知:Istio 分为控制面 control plane 和数据面 data plane。
控制面可以理解为 Istio 自身的管理功能:
- 比如服务注册发现
- 管理配置数据面所需要的网络规则等
而数据面可以简单的把他理解为由 Envoy 代理的我们的业务应用,我们应用中所有的流量进出都会经过 Envoy 代理。
所以它可以实现负载均衡、熔断保护、认证授权等功能。
安装
首先安装 Istio 命令行工具
这里的前提是有一个 kubernetes 运行环境
Linux 使用:
curl -L https://istio.io/downloadIstio | sh -
Mac 可以使用 brew:
brew install istioctl
其他环境可以下载 Istio 后配置环境变量:
export PATH=$PWD/bin:$PATH
之后我们可以使用 install 命令安装控制面。
这里默认使用的是
kubectl所配置的kubernetes集群
istioctl install --set profile=demo -y
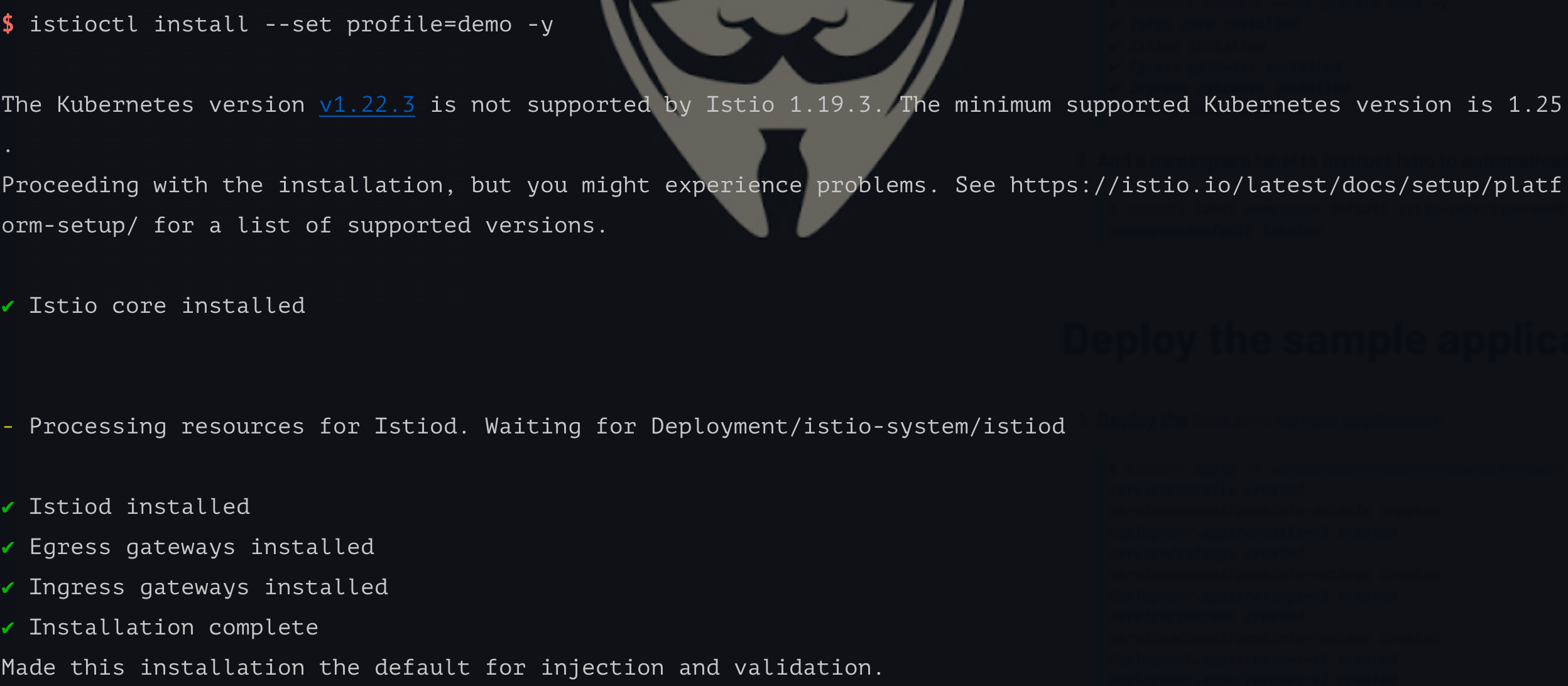 这个的
这个的 profile 还有以下不同的值,为了演示我们使用 demo 即可。
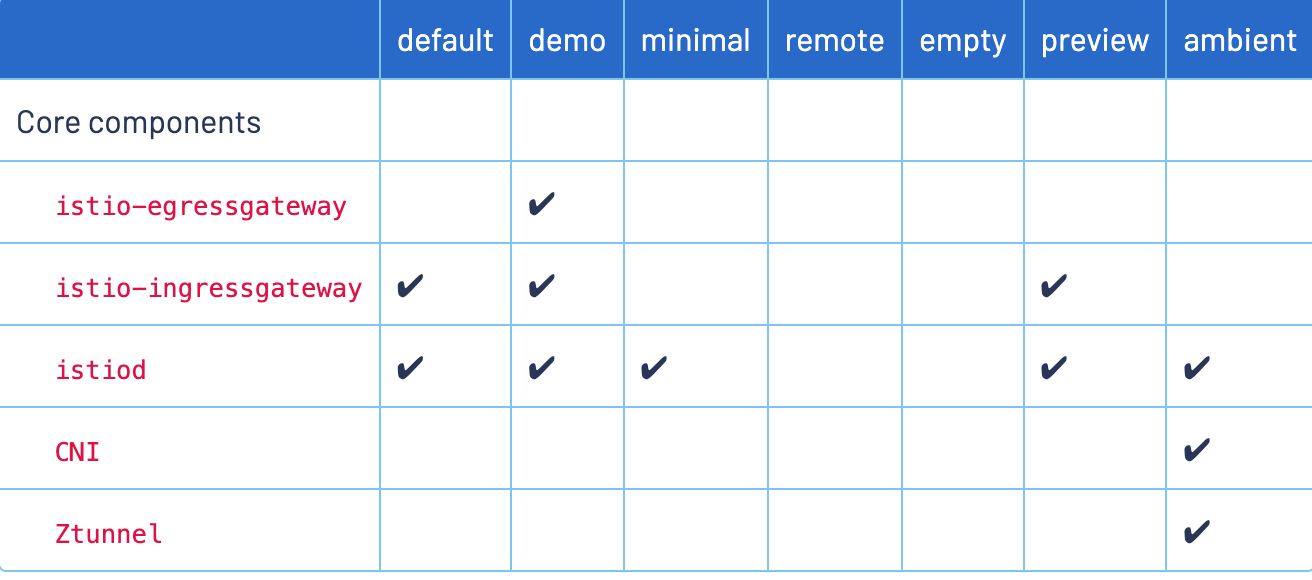
使用
# 开启 default 命名空间自动注入
$ k label namespace default istio-injection=enabled
$ k describe ns default
Name: default
Labels: istio-injection=enabled
kubernetes.io/metadata.name=default
Annotations: <none>
Status: Active
No resource quota.
No LimitRange resource.
之后我们为 namespace 打上 label,使得 Istio 控制面知道哪个 namespace 下的 Pod 会自动注入 sidecar。
这里我们为 default 这个命名空间打开自动注入 sidecar,然后在这里部署我们之前使用到的 deployment-istio.yaml
$ k apply -f deployment/deployment-istio.yaml
$ k get pod
NAME READY STATUS RESTARTS
k8s-combat-service-5bfd78856f-8zjjf 2/2 Running 0
k8s-combat-service-5bfd78856f-mblqd 2/2 Running 0
k8s-combat-service-5bfd78856f-wlc8z 2/2 Running 0
此时会看到每个Pod 有两个 container(其中一个就是 istio-proxy sidecar),也就是之前做 gRPC 负载均衡测试时的代码。
 还是进行负载均衡测试,效果是一样的,说明
还是进行负载均衡测试,效果是一样的,说明 Istio 起作用了。
此时我们再观察 sidecar 的日志时,会看到刚才我们所发出和接受到的流量:
$ k logs -f k8s-combat-service-5bfd78856f-wlc8z -c istio-proxy
[2023-10-31T14:52:14.279Z] "POST /helloworld.Greeter/SayHello HTTP/2" 200 - via_upstream - "-" 12 61 14 9 "-" "grpc-go/1.58.3" "6d293d32-af96-9f87-a8e4-6665632f7236" "k8s-combat-service:50051" "172.17.0.9:50051" inbound|50051|| 127.0.0.6:42051 172.17.0.9:50051 172.17.0.9:40804 outbound_.50051_._.k8s-combat-service.default.svc.cluster.local default
[2023-10-31T14:52:14.246Z] "POST /helloworld.Greeter/SayHello HTTP/2" 200 - via_upstream - "-" 12 61 58 39 "-" "grpc-go/1.58.3" "6d293d32-af96-9f87-a8e4-6665632f7236" "k8s-combat-service:50051" "172.17.0.9:50051" outbound|50051||k8s-combat-service.default.svc.cluster.local 172.17.0.9:40804 10.101.204.13:50051 172.17.0.9:54012 - default
[2023-10-31T14:52:15.659Z] "POST /helloworld.Greeter/SayHello HTTP/2" 200 - via_upstream - "-" 12 61 35 34 "-" "grpc-go/1.58.3" "ed8ab4f2-384d-98da-81b7-d4466eaf0207" "k8s-combat-service:50051" "172.17.0.10:50051" outbound|50051||k8s-combat-service.default.svc.cluster.local 172.17.0.9:39800 10.101.204.13:50051 172.17.0.9:54012 - default
[2023-10-31T14:52:16.524Z] "POST /helloworld.Greeter/SayHello HTTP/2" 200 - via_upstream - "-" 12 61 28 26 "-" "grpc-go/1.58.3" "67a22028-dfb3-92ca-aa23-573660b30dd4" "k8s-combat-service:50051" "172.17.0.8:50051" outbound|50051||k8s-combat-service.default.svc.cluster.local 172.17.0.9:44580 10.101.204.13:50051 172.17.0.9:54012 - default
[2023-10-31T14:52:16.680Z] "POST /helloworld.Greeter/SayHello HTTP/2" 200 - via_upstream - "-" 12 61 2 2 "-" "grpc-go/1.58.3" "b4761d9f-7e4c-9f2c-b06f-64a028faa5bc" "k8s-combat-service:50051" "172.17.0.10:50051" outbound|50051||k8s-combat-service.default.svc.cluster.local 172.17.0.9:39800 10.101.204.13:50051 172.17.0.9:54012 - default
总结
本期的内容比较简单,主要和安装配置相关,下一期更新如何配置内部服务调用的超时、限流等功能。
其实目前大部分操作都是偏运维的,即便是后续的超时配置等功能都只是编写 yaml 资源。
但在生产使用时,我们会给开发者提供一个管理台的可视化页面,可供他们自己灵活配置这些原本需要在 yaml 中配置的功能。
 其实各大云平台厂商都有提供类似的能力,比如阿里云的 EDAS 等。
其实各大云平台厂商都有提供类似的能力,比如阿里云的 EDAS 等。
配置Mesh
在上一篇 k8s-服务网格实战-入门Istio中分享了如何安装部署 Istio,同时可以利用 Istio 实现 gRPC 的负载均衡。
今天我们更进一步,深入了解使用 Istio 的功能。
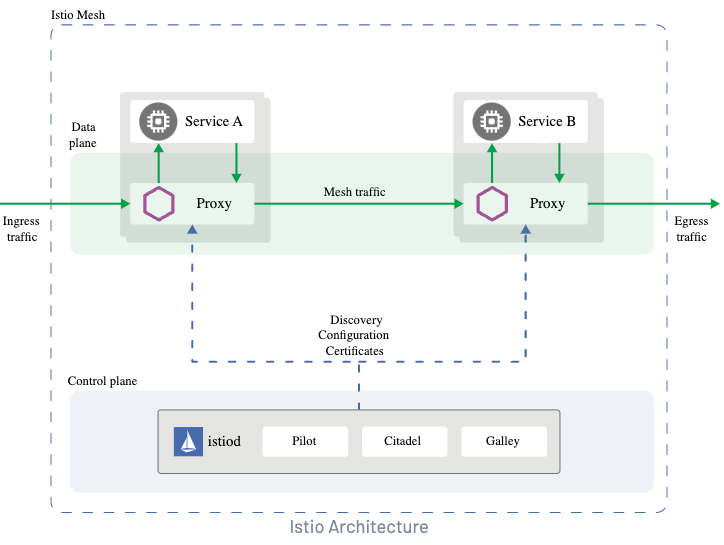 从 Istio 的流量模型中可以看出:Istio 支持管理集群的出入口请求(gateway),同时也支持管理集群内的 mesh 流量,也就是集群内服务之间的请求。
从 Istio 的流量模型中可以看出:Istio 支持管理集群的出入口请求(gateway),同时也支持管理集群内的 mesh 流量,也就是集群内服务之间的请求。
本次先讲解集群内部的请求,配合实现以下两个功能:
- 灰度发布(对指定的请求分别路由到不同的 service 中)
- 配置 service 的请求权重
灰度发布
在开始之前会部署两个 deployment 和一个 service,同时这两个 deployment 所关联的 Pod 分别对应了两个不同的 label,由于在灰度的时候进行分组。
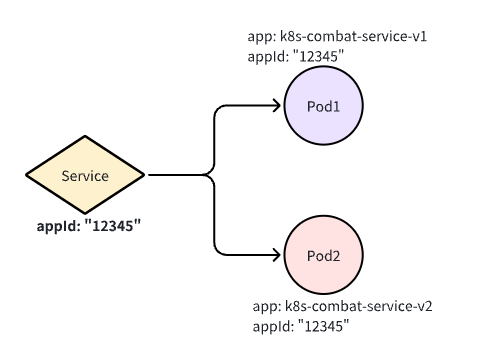
使用这个 yaml 会部署所需要的 deployment 和 service。
kubectl apply -f https://raw.githubusercontent.com/crossoverJie/k8s-combat/main/deployment/istio-mesh.yaml
首先设想下什么情况下我们需要灰度发布,一般是某个重大功能的测试,只对部分进入内测的用户开放入口。
假设我们做的是一个 App,我们可以对拿到了内测包用户的所有请求头中加入一个版本号。
比如 version=200 表示新版本,version=100 表示老版本。
同时在服务端会将这个版本号打印出来,用于区分请求是否进入了预期的 Pod。
// Client
version := r.URL.Query().Get("version")
name := "world"
ctx, cancel := context.WithTimeout(context.Background(), time.Second)
md := metadata.New(map[string]string{
"version": version,
})
ctx = metadata.NewOutgoingContext(ctx, md)
defer cancel()
g, err := c.SayHello(ctx, &pb.HelloRequest{Name: name})
// Server
func (s *server) SayHello(ctx context.Context, in *pb.HelloRequest) (*pb.HelloReply, error) {
md, ok := metadata.FromIncomingContext(ctx)
var version string
if ok {
version = md.Get("version")[0]
} log.Printf("Received: %v, version: %s", in.GetName(), version)
name, _ := os.Hostname()
return &pb.HelloReply{Message: fmt.Sprintf("hostname:%s, in:%s, version:%s", name, in.Name, version)}, nil
}
对 service 分组
进行灰度测试时往往需要新增部署一个灰度服务,这里我们称为 v2(也就是上图中的 Pod2)。
同时需要将 v1 和 v2 分组:
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: k8s-combat-service-ds
spec:
host: k8s-combat-service-istio-mesh
subsets:
- name: v1
labels:
app: k8s-combat-service-v1
- name: v2
labels:
app: k8s-combat-service-v2
这里我们使用 Istio 的 DestinationRule 定义 subset,也就是将我们的 service 下的 Pod 分为 v1/v2。
使用 标签
app进行分组
注意这里的 host: k8s-combat-service-istio-mesh 通常配置的是 service 名称。
apiVersion: v1
kind: Service
metadata:
name: k8s-combat-service-istio-mesh
spec:
selector:
appId: "12345"
type: ClusterIP
ports:
- port: 8081
targetPort: 8081
name: app
- name: grpc
port: 50051
targetPort: 50051
也就是这里 service 的名称,同时也支持配置为 host: k8s-combat-service-istio-mesh.default.svc.cluster.local,如果使用的简写Istio 会根据当前指定的 namespace 进行解析。
Istio 更推荐使用全限定名替代我们这里的简写,从而避免误操作。
当然我们也可以在 DestinationRule 中配置负载均衡的策略,这里我们先略过:
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: k8s-combat-service-ds
spec:
host: k8s-combat-service-istio-mesh
trafficPolicy:
loadBalancer:
simple: ROUND_ROBIN

这样我们就定义好了两个分组:
- v1:app: k8s-combat-service-v1
- v2:app: k8s-combat-service-v2
之后就可以配置路由规则将流量分别指定到两个不同的组中,这里我们使用 VirtualService 进行配置。
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: k8s-combat-service-vs
spec:
gateways:
- mesh
hosts:
- k8s-combat-service-istio-mesh # match this host
http:
- name: v1
match:
- headers:
version:
exact: '100'
route:
- destination:
host: k8s-combat-service-istio-mesh
subset: v1
- name: v2
match:
- headers:
version:
exact: '200'
route:
- destination:
host: k8s-combat-service-istio-mesh
subset: v2
- name: default
route:
- destination:
host: k8s-combat-service-istio-mesh
subset: v1
这个规则很简单,会检测 http 协议的 header 中的 version 字段值,如果为 100 这路由到 subset=v1 这个分组的 Pod 中,同理为 200 时则路由到 subset=v2 这个分组的 Pod 中。
当没有匹配到 header 时则进入默认的 subset:v1
gRPC也是基于 http 协议,它的metadata也就对应了http协议中的header。
header=100
Greeting: hostname:k8s-combat-service-v1-5b998dc8c8-hkb72, in:world, version:100istio-proxy@k8s-combat-service-v1-5b998dc8c8-hkb72:/$ curl "http://127.0.0.1:8081/grpc_client?name=k8s-combat-service-istio-mesh&version=100"
Greeting: hostname:k8s-combat-service-v1-5b998dc8c8-hkb72, in:world, version:100istio-proxy@k8s-combat-service-v1-5b998dc8c8-hkb72:/$ curl "http://127.0.0.1:8081/grpc_client?name=k8s-combat-service-istio-mesh&version=100"
Greeting: hostname:k8s-combat-service-v1-5b998dc8c8-hkb72, in:world, version:100istio-proxy@k8s-combat-service-v1-5b998dc8c8-hkb72:/$ curl "http://127.0.0.1:8081/grpc_client?name=k8s-combat-service-istio-mesh&version=100"
Greeting: hostname:k8s-combat-service-v1-5b998dc8c8-hkb72, in:world, version:100istio-proxy@k8s-combat-service-v1-5b998dc8c8-hkb72:/$ curl "http://127.0.0.1:8081/grpc_client?name=k8s-combat-service-istio-mesh&version=100"
header=200
Greeting: hostname:k8s-combat-service-v2-5db566fb76-xj7j6, in:world, version:200istio-proxy@k8s-combat-service-v1-5b998dc8c8-hkb72:/$ curl "http://127.0.0.1:8081/grpc_client?name=k8s-combat-service-istio-mesh&version=200"
Greeting: hostname:k8s-combat-service-v2-5db566fb76-xj7j6, in:world, version:200istio-proxy@k8s-combat-service-v1-5b998dc8c8-hkb72:/$ curl "http://127.0.0.1:8081/grpc_client?name=k8s-combat-service-istio-mesh&version=200"
Greeting: hostname:k8s-combat-service-v2-5db566fb76-xj7j6, in:world, version:200istio-proxy@k8s-combat-service-v1-5b998dc8c8-hkb72:/$ curl "http://127.0.0.1:8081/grpc_client?name=k8s-combat-service-istio-mesh&version=200"
Greeting: hostname:k8s-combat-service-v2-5db566fb76-xj7j6, in:world, version:200istio-proxy@k8s-combat-service-v1-5b998dc8c8-hkb72:/$ curl "http://127.0.0.1:8081/grpc_client?name=k8s-combat-service-istio-mesh&version=200"
Greeting: hostname:k8s-combat-service-v2-5db566fb76-xj7j6, in:world, version:200istio-proxy@k8s-combat-service-v1-5b998dc8c8-hkb72:/$ curl "http://127.0.0.1:8081/grpc_client?name=k8s-combat-service-istio-mesh&version=200"
Greeting: hostname:k8s-combat-service-v2-5db566fb76-xj7j6, in:world, version:200istio-proxy@k8s-combat-service-v1-5b998dc8c8-hkb72:/$ curl "http://127.0.0.1:8081/grpc_client?name=k8s-combat-service-istio-mesh&version=200"
Greeting: hostname:k8s-combat-service-v2-5db566fb76-xj7j6, in:world, version:200istio-proxy@k8s-combat-service-v1-5b998dc8c8-hkb72:/$ curl "http://127.0.0.1:8081/grpc_client?name=k8s-combat-service-istio-mesh&version=200"
根据以上的上面的测试请求来看,只要我们请求头里带上指定的 version 就会被路由到指定的 Pod 中。
利用这个特性我们就可以在灰度验证的时候单独发一个灰度版本的 Deployment,同时配合客户端指定版本就可以实现灰度功能了。
配置权重
同样基于 VirtualService 我们还可以对不同的 subset 分组进行权重配置。
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: k8s-combat-service-vs
spec:
gateways:
- mesh
hosts:
- k8s-combat-service-istio-mesh # match this host
http:
- match:
- uri:
exact: /helloworld.Greeter/SayHello
route:
- destination:
host: k8s-combat-service-istio-mesh
subset: v1
weight: 10
- destination:
host: k8s-combat-service-istio-mesh
subset: v2
weight: 90
timeout: 5000ms
这里演示的是针对 SayHello 接口进行权重配置(当然还有多种匹配规则),90% 的流量会进入 v2 这个 subset,也就是在 k8s-combat-service-istio-mesh service 下的 app: k8s-combat-service-v2 Pod。
Greeting: hostname:k8s-combat-service-v2-5db566fb76-xj7j6, in:world, version:200istio-proxy@k8s-combat-service-v1-5b998dc8c8-hkb72:/$ curl "http://127.0.0.1:8081/grpc_client?name=k8s-combat-service-istio-mesh&version=200"
Greeting: hostname:k8s-combat-service-v2-5db566fb76-xj7j6, in:world, version:200istio-proxy@k8s-combat-service-v1-5b998dc8c8-hkb72:/$ curl "http://127.0.0.1:8081/grpc_client?name=k8s-combat-service-istio-mesh&version=200"
Greeting: hostname:k8s-combat-service-v2-5db566fb76-xj7j6, in:world, version:200istio-proxy@k8s-combat-service-v1-5b998dc8c8-hkb72:/$ curl "http://127.0.0.1:8081/grpc_client?name=k8s-combat-service-istio-mesh&version=200"
Greeting: hostname:k8s-combat-service-v2-5db566fb76-xj7j6, in:world, version:200istio-proxy@k8s-combat-service-v1-5b998dc8c8-hkb72:/$ curl "http://127.0.0.1:8081/grpc_client?name=k8s-combat-service-istio-mesh&version=200"
Greeting: hostname:k8s-combat-service-v2-5db566fb76-xj7j6, in:world, version:200istio-proxy@k8s-combat-service-v1-5b998dc8c8-hkb72:/$ curl "http://127.0.0.1:8081/grpc_client?name=k8s-combat-service-istio-mesh&version=200"
Greeting: hostname:k8s-combat-service-v2-5db566fb76-xj7j6, in:world, version:200istio-proxy@k8s-combat-service-v1-5b998dc8c8-hkb72:/$ curl "http://127.0.0.1:8081/grpc_client?name=k8s-combat-service-istio-mesh&version=200"
Greeting: hostname:k8s-combat-service-**v1**-5b998dc8c8-hkb72, in:world, version:200istio-proxy@k8s-combat-service-v1-5b998dc8c8-hkb72:/$ curl "http://127.0.0.1:8081/grpc_client?name=k8s-combat-service-istio-mesh&version=200"
Greeting: hostname:k8s-combat-service-v2-5db566fb76-xj7j6, in:world, version:200istio-proxy@k8s-combat-service-v1-5b998dc8c8-hkb72:/$
经过测试会发现大部分的请求都会按照我们的预期进入 v2 这个分组。
当然除之外之外我们还可以:
- 超时时间
- 故障注入
- 重试
具体的配置可以参考 Istio 官方文档:
 当然在一些云平台也提供了可视化的页面,可以更直观的使用。
当然在一些云平台也提供了可视化的页面,可以更直观的使用。
以上是 阿里云的截图
配置网关
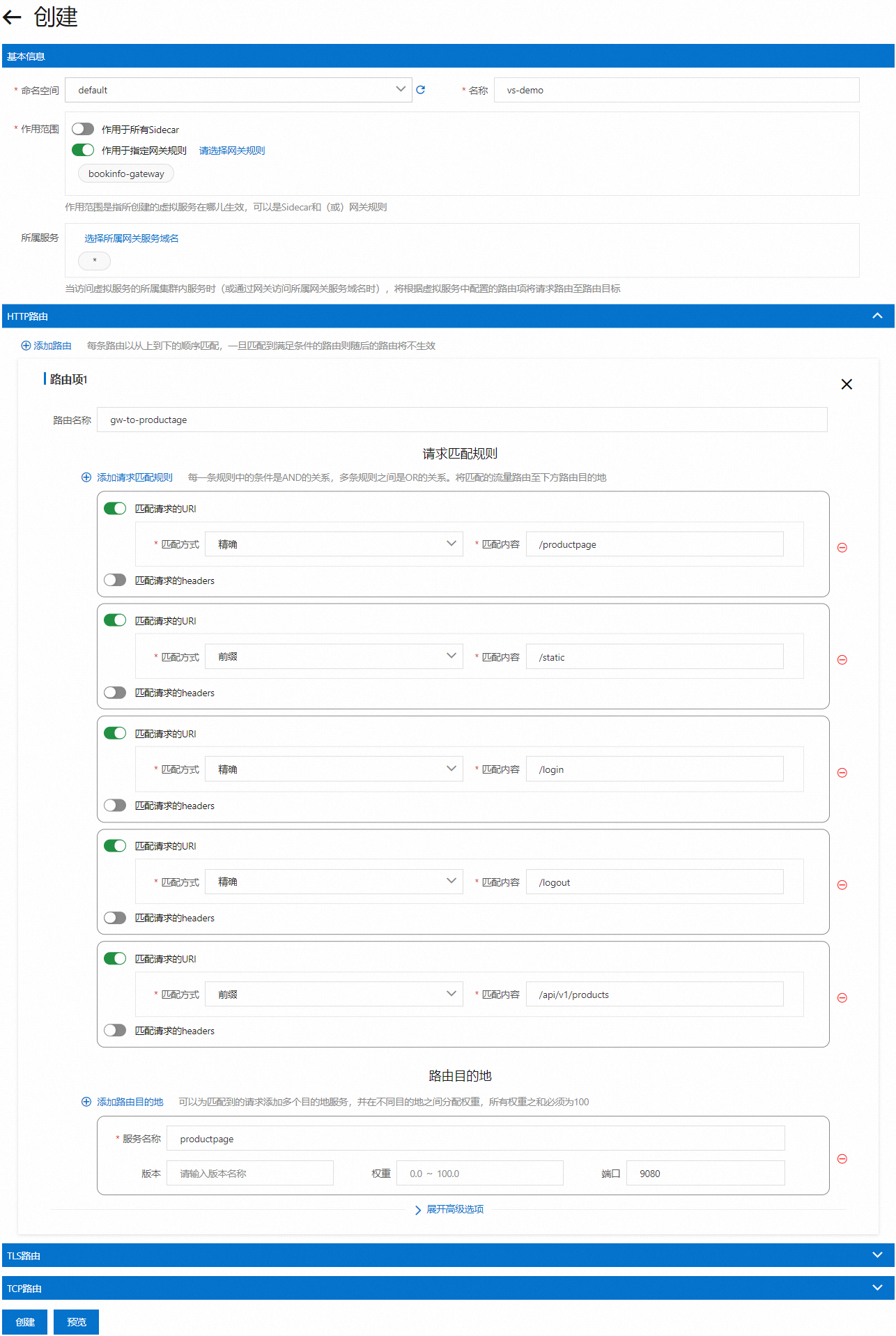
但他们的管理的资源都偏 kubernetes,一般是由运维或者是 DevOps 来配置,不方便开发使用,所以还需要一个介于云厂商和开发者之间的管理发布平台,可以由开发者以项目维度管理维护这些功能。
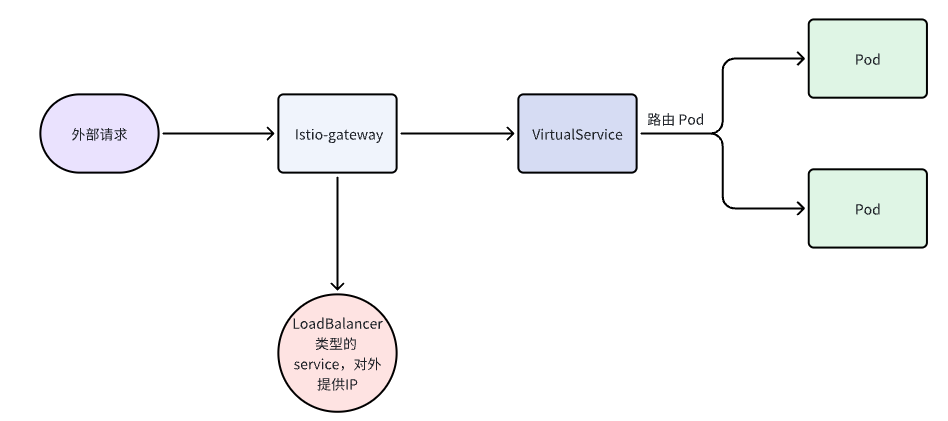
在上一期 k8s-服务网格实战-配置 Mesh 中讲解了如何配置集群内的 Mesh 请求,Istio 同样也可以处理集群外部流量,也就是我们常见的网关。
其实和之前讲到的k8s入门到实战-使用Ingress Ingress 作用类似,都是将内部服务暴露出去的方法。
只是使用 Istio-gateway 会更加灵活。
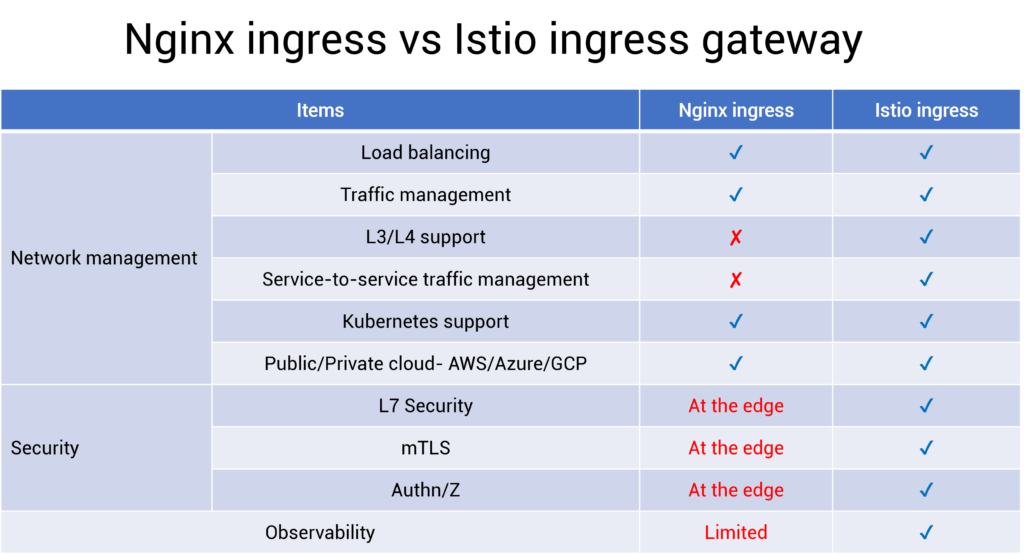
这里有一张功能对比图,可以明显的看出 Istio-gateway 支持的功能会更多,如果是一个中大型企业并且已经用上 Istio 后还是更推荐是有 Istio-gateway,使用同一个控制面就可以管理内外网流量。
创建 Gateway
开始之前首先是创建一个 Istio-Gateway 的资源:
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
name: istio-ingress-gateway
namespace: default
spec:
servers:
- port:
number: 80
name: http
protocol: HTTP
hosts:
- 'www.service1.io'
selector:
app: istio-ingressgateway #与现有的 gateway 关联
istio: ingressgateway
其中的 selector 选择器中匹配的 label 与我们安装 Istio 时候自带的 gateway 关联即可。
# 查看 gateway 的 label
k get pod -n istio-system
NAME READY STATUS
istio-ingressgateway-649f75b6b9-klljw 1/1 Running
k describe pod istio-ingressgateway-649f75b6b9-klljw -n istio-system |grep Labels
Labels: app=istio-ingressgateway
这个
Gateway在我们第一次安装Istio的时候就会安装这个组件。
这个配置的含义是网关会代理通过 www.service1.io 这个域名访问的所有请求。
之后需要使用刚才的 gateway 与我们的服务的 service 进行绑定,这时就需要使用到 VirtualService:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: k8s-combat-istio-http-vs
spec:
gateways:
- istio-ingress-gateway # 绑定刚才创建的 gateway 名称
hosts:
- www.service1.io
http:
- name: default
route:
- destination:
host: k8s-combat-service-istio-mesh #service 名称
port:
number: 8081
subset: v1
这个和我们之前讲到的 Mesh 内部流量时所使用到的 VirtualService 配置是一样的。
这里的含义也是通过 www.service1.io 以及 istio-ingress-gateway 网关的流量会进入这个虚拟服务,但所有的请求都会进入 subset: v1 这个分组。
这个的分组信息在上一节可以查询到:
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: k8s-combat-service-ds
spec:
host: k8s-combat-service-istio-mesh
subsets:
- name: v1
labels:
app: k8s-combat-service-v1
- name: v2
labels:
app: k8s-combat-service-v2
之后我们访问这个域名即可拿到响应,同时我们打开 k8s-combat-service-istio-mesh service 的 Pod 查看日志,会发现所有的请求都进入了 v1, 如果不需要这个限制条件,将 subset: v1 删除即可。
curl http://www.service1.io/ping
本地需要配置下 host:
127.0.0.1 www.service1.io
还有一点,我们需要拿到 gateway 的外部IP,才能将 IP 和刚才的域名www.service1.io 进行绑定(host,或者是域名管理台)。
如果使用的是 docker-desktop 自带的 kubernetes 集群时候直接使用 127.0.0.1 即可,默认就会绑定上。
如果使用的是 minikube 安装的,那需要使用 minikube tunnel 手动为 service 为LoadBalancer 类型的绑定一个本地 IP,具体可以参考文档:
https://minikube.sigs.k8s.io/docs/tasks/loadbalancer
如果是生产环境使用,云服务厂商会自动绑定一个外网 IP。
原理
这个的访问请求的流程和之前讲到的 kubernetes Ingress 流程是类似的,只是 gateway 是通过 VirtualService 来路由的 service,同时在这个 VirtualService 中可以自定义许多的路由规则。
总结
服务网格 Istio 基本上讲完了,后续还有关于 Telemetry 相关的 trace、log、metrics 会在运维章节更新,也会和 Istio 有所关联。
感兴趣的朋友可以持续关注。
应用探针
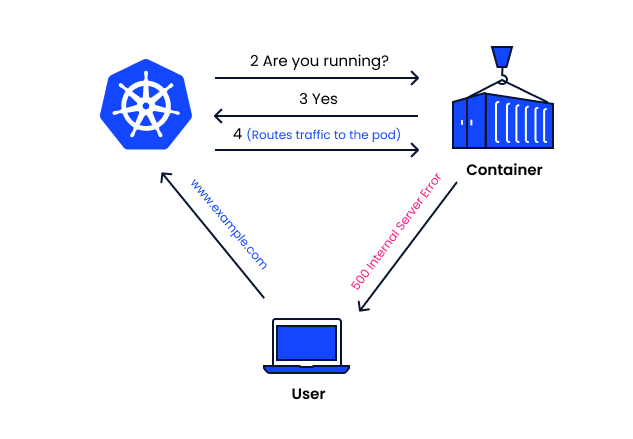
今天进入 kubernetes 的运维部分(并不是运维 kubernetes,而是运维应用),其实日常我们大部分使用 kubernetes 的功能就是以往运维的工作,现在云原生将运维和研发关系变得更紧密了。
今天主要讲解 Probe 探针相关的功能,探针最实用的功能就是可以控制应用优雅上线。
就绪探针
举个例子,当我们的 service 关联了多个 Pod 的时候,其中一个 Pod 正在重启但还没达到可以对外提供服务的状态,这时候如果有流量进入。
那这个请求肯定就会出现异常,从而导致问题,所以我们需要一个和 kubernetes 沟通的渠道,告诉它什么时候可以将流量放进来。
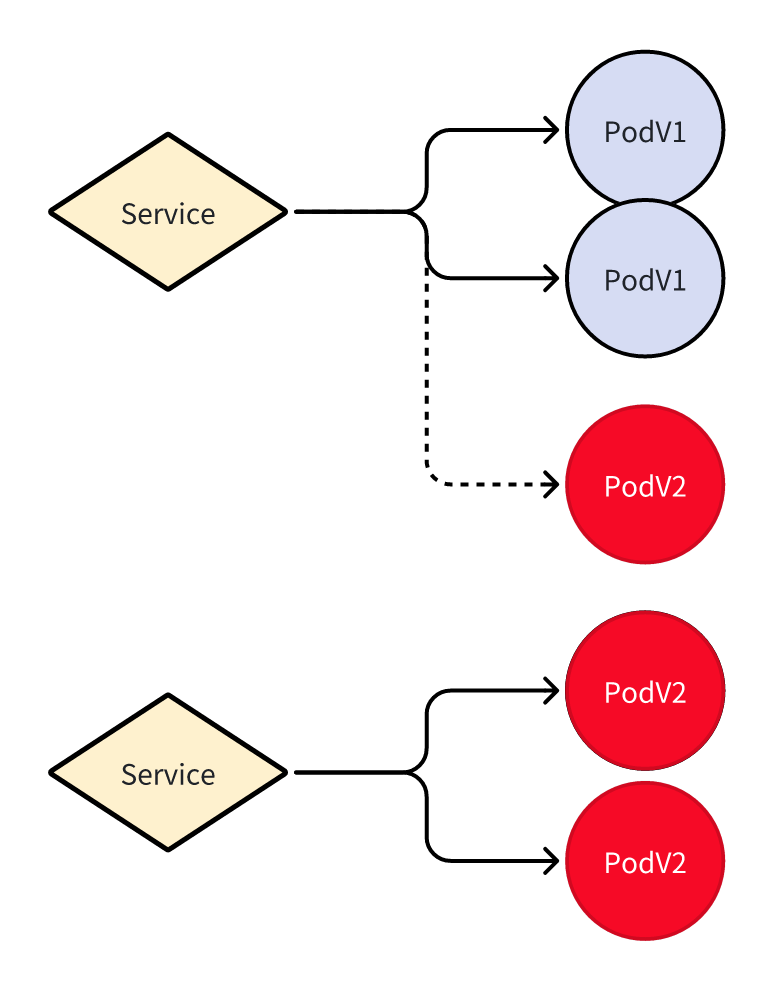
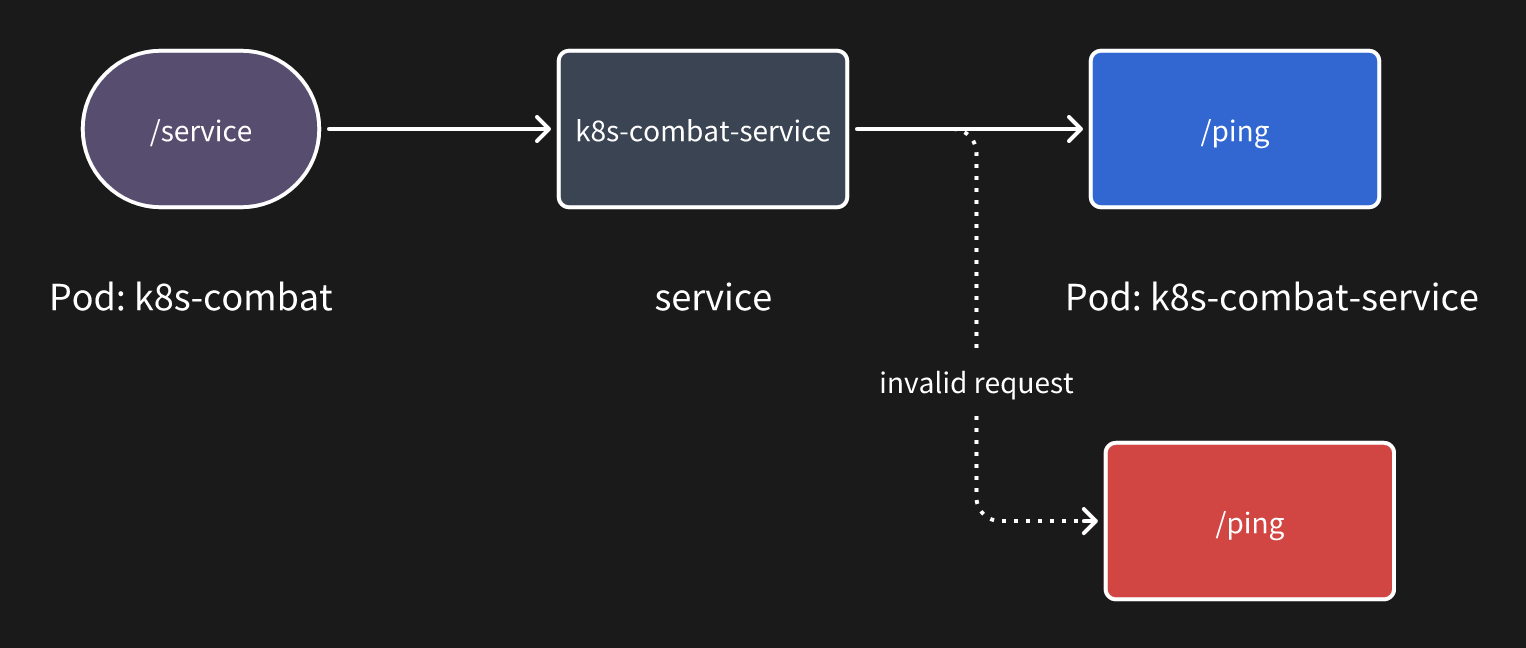 比如如图所示的情况,红色
比如如图所示的情况,红色 Pod 在未就绪的时候就不会有流量。
使用就绪探针就可以达到类似的效果:
livenessProbe:
failureThreshold: 3
httpGet:
path: /ping
port: 8081
scheme: HTTP
periodSeconds: 3
successThreshold: 1
timeoutSeconds: 1
这个配置也很直接:
- 配置一个 HTTP 的 ping 接口
- 每三秒检测一次
- 失败 3 次则认为检测失败
- 成功一次就认为检测成功
但没有配置就绪探针时,一旦 Pod 的
Endpoint加入到 service 中(Pod 进入Running状态),请求就有可能被转发过来,所以配置就绪探针是非常有必要的。
启动探针
而启动探针往往是和就绪探针搭配干活的,如果我们一个 Pod 启动时间过长,比如超过上面配置的失败检测次数,此时 Pod 就会被 kubernetes 重启,这样可能会进入无限重启的循环。
所以启动探针可以先检测一次是否已经启动,直到启动成功后才会做后续的检测。
startupProbe:
failureThreshold: 30
httpGet:
path: /ping
port: 8081
scheme: HTTP
periodSeconds: 5
successThreshold: 1
timeoutSeconds: 1
我这里两个检测接口是同一个,具体得根据自己是实际业务进行配置; 比如应用端口启动之后并不代表业务已经就绪了,可能某些基础数据还没加载到内存中,这个时候就需要自己写其他的接口来配置就绪探针了。

所有关于探针相关的日志都可以在 Pod 的事件中查看,比如如果一个应用在启动的过程中频繁重启,那就可以看看是不是某个探针检测失败了。
存活探针
存活探针往往是用于保证应用高可用的,虽然 kubernetes 可以在 Pod 退出后自动重启,比如 Pod OOM;但应用假死他是检测不出来的。
为了保证这种情况下 Pod 也能被自动重启,就可以配合存活探针使用:
livenessProbe:
failureThreshold: 3
httpGet:
path: /ping
port: 8081
scheme: HTTP
periodSeconds: 3
successThreshold: 1
timeoutSeconds: 1
一旦接口响应失败,kubernetes 就会尝试重启。
总结
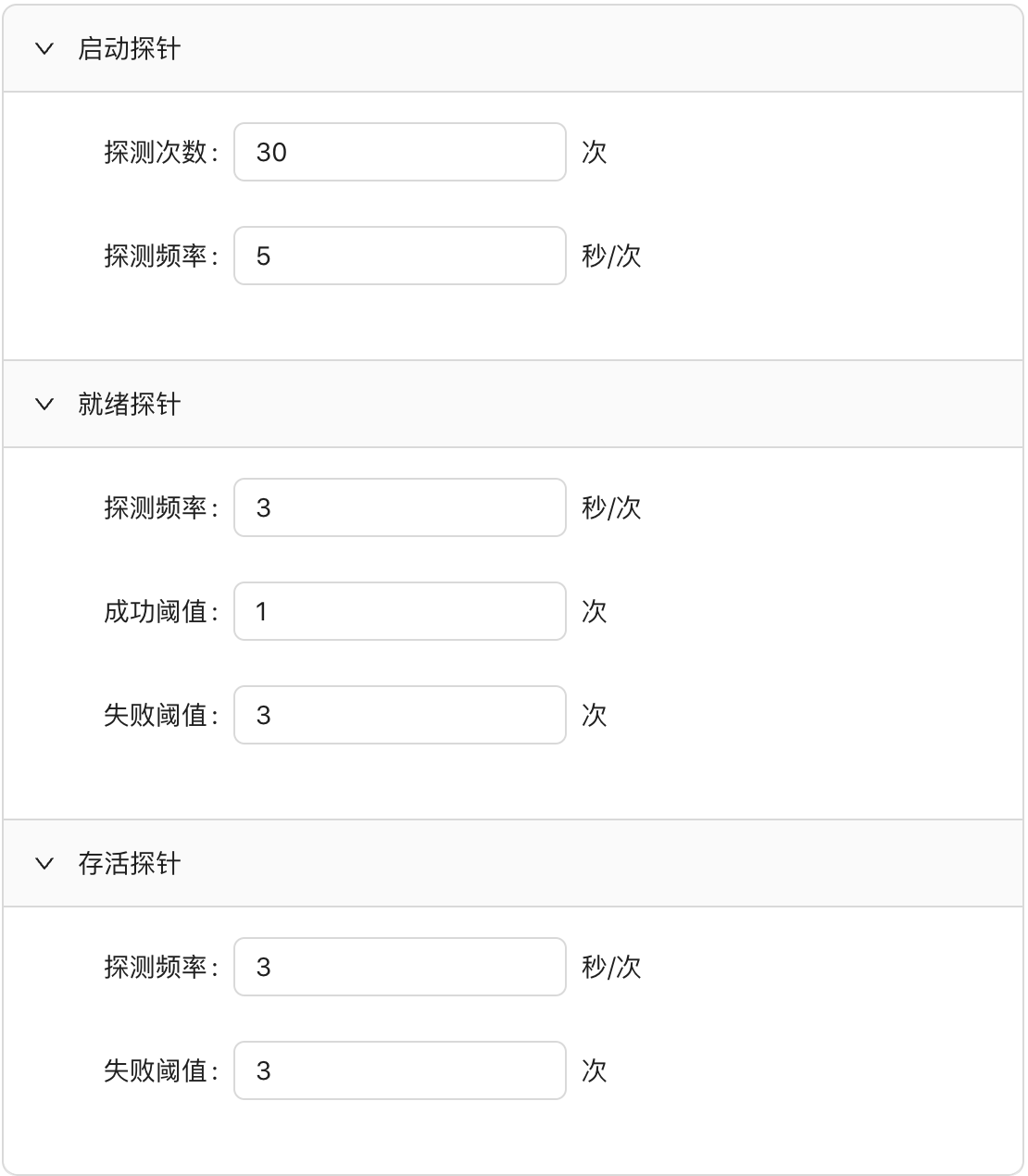
以上探针配置最好是可以在研效平台可视化配置,这样维护起来也比较简单。
探针是维护应用健康的必要手段,强烈推荐大家都进行配置。
滚动更新与回滚
当我们在生产环境发布应用时,必须要考虑到当前系统还有用户正在使用的情况,所以尽量需要做到不停机发版。
所以在发布过程中理论上之前的 v1 版本依然存在,必须得等待 v2 版本启动成功后再删除历史的 v1 版本。
如果 v2 版本启动失败 v1 版本不会做任何操作,依然能对外提供服务。
滚动更新
这是我们预期中的发布流程,要在 kubernetes 使用该功能也非常简单,只需要在 spec 下配置相关策略即可:
spec:
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
这个配置的含义是:
- 使用滚动更新,当然还有 Recreate 用于删除旧版本的 Pod,我们基本不会用这个策略。
-
maxSurge:滚动更新过程中可以最多超过预期 Pod 数量的百分比,当然也可以填整数。 -
maxUnavailable:滚动更新过程中最大不可用 Pod 数量超过预期的百分比。
这样一旦我们更新了 Pod 的镜像时,kubernetes 就会先创建一个新版本的 Pod 等待他启动成功后再逐步更新剩下的 Pod。

优雅停机
滚动升级过程中不可避免的又会碰到一个优雅停机的问题,毕竟是需要停掉老的 Pod。
这时我们需要注意两种情况:
- 停机过程中,已经进入 Pod 的请求需要执行完毕才能退出。
- 停机之后不能再有请求路由到已经停机的 Pod
第一个问题如果我们使用的是 Go,可以使用一个钩子来监听 kubernetes 发出的退出信号:
quit := make(chan os.Signal)
signal.Notify(quit, syscall.SIGHUP, syscall.SIGINT, syscall.SIGTERM, syscall.SIGQUIT, syscall.SIGPIPE)
go func() {
<-quit
log.Printf("quit signal received, exit \n")
os.Exit(0)
}()
在这里执行对应的资源释放。
如果使用的是 spring boot 也有对应的配置:
server:
shutdown: "graceful"
spring:
lifecycle:
timeout-per-shutdown-phase: "20s"
当应用收到退出信号后,spring boot 将不会再接收新的请求,并等待现有的请求处理完毕。
但 kubernetes 也不会无限等待应用将 Pod 将任务执行完毕,我们可以在 Pod 中配置
terminationGracePeriodSeconds: 30
来定义需要等待多长时间,这里是超过 30s 之后就会强行 kill Pod。
具体值大家可以根据实际情况配置
spec:
containers:
- name: example-container
image: example-image
lifecycle:
preStop:
exec:
command: ["sh", "-c", "sleep 10"]
同时我们也可以配置 preStop 做一个 sleep 来确保 kubernetes 将准备删除的 Pod 在 Iptable 中已经更新了之后再删除 Pod。
这样可以避免第二种情况:已经删除的 Pod 依然还有请求路由过来。
具体可以参考 spring boot 文档:
https://docs.spring.io/spring-boot/docs/2.4.4/reference/htmlsingle/#cloud-deployment-kubernetes-container-lifecycle
回滚
回滚其实也可以看作是升级的一种,只是升级到了历史版本,在 kubernetes 中回滚应用非常简单。
# 回滚到上一个版本
k rollout undo deployment/abc
# 回滚到指定版本
k rollout undo daemonset/abc --to-revision=3
同时 kubernetes 也能保证是滚动回滚的。
优雅重启
在之前的 如何优雅重启 kubernetes 的 Pod 那篇文章中写过,如果想要优雅重启 Pod 也可以使用 rollout 命令,它也也可以保证是滚动重启。
k rollout restart deployment/nginx
使用 kubernetes 的滚动更新确实要比我们以往的传统运维简单许多,就几个命令的事情之前得写一些复杂的运维脚本才能实现。
