JRC1995 Chatbot Save
Hybrid Conversational Bot based on both neural retrieval and neural generative mechanism with TTS.
Conversational-AI
Hybrid Conversational Bot based on both neural retrieval and neural generative mechanism with TTS.
See Project Report here. Note, however, that the report refers to an older version of the project which was much slower, which didn't use FAISS or TTS.
Credits:
- The TTS Folder is based on an earlier version of Mozilla TTS. I prepared the text2speech.py file which acts as an interface to the rest of the project.
- The encoder_client file in Sentence_Encoder is taken from Poly-AI. I modified it slightly to run it with Tensorflow 2. We also use their pre-trained models.
- DialoGPT (inside Generator) config files and vocab are taken from the DialoGPT repository. We also use their pre-trained models.
- The data here in Classifier is from MIDAS_dialog_act repository
- The corpus here is taken from Chatterbot_Corpus library
- Mobashir Sadat prepared and processed the Chatterbot Corpus and created the diagrams.
- Faiss, Huggingface's Transformers, and Tensorflow Hub are important components of the project. We use pre-trained models of Universal Sentence Encoder QA through Tensorflow Hub.
- Utils/functions.py and Utils/functions_old.py utilize a code from here: https://gist.github.com/nealrs/96342d8231b75cf4bb82 for contraction expansion.
Disclaimer:
Both the Generative and Retrieval Module runs on Reddit data which can be offensive or toxic.
Project Overview:
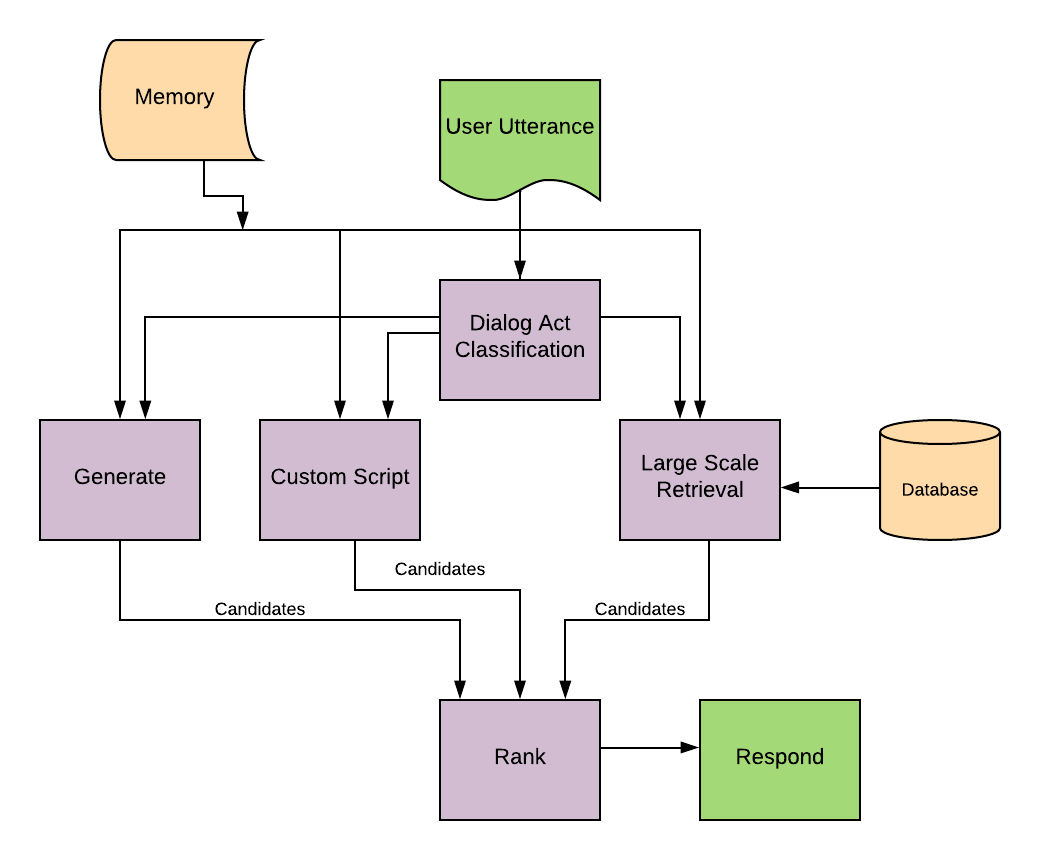
How conversation looks like:
(Most of them are retrieved from Reddit Database) (See the project report for generative examples)
Say Something: Hello, how are you?
Thinking......
Bot: I am doing well.
Say Something: What is your name?
Thinking......
Bot: My name is Ray Solomonon
Say Something: Do you like movies? If so, what kind?
Thinking......
Bot: I love a good demon possession movie. I love a good social thriller. I love science fiction. Really, I'm a big fan of all sorts of movies in general. But my favourites are movies like A Clockwork Orange, Moon, The Conjuring, Paranormal Activity 3 (specifically 3 because I think they did some really interesting/new things for the genre as a whole), etc.
Say Something: Are you sentient?
Thinking......
Bot: Probably no. What about you? Are YOU conscious or you just a P-Zombie?
Say Something: Tell me a Joke.
Thinking......
Bot: This girl said she knew me from the vegetarian restaurant....... But I've never met herbivore!
Say Something: What can you tell me about Quantum Field Theory?
Thinking......
Bot: Quantum field theory put simply is relativistic quantum mechanics where you can create and destroy particles. It's not "*the*" quantum field theory; there are lots of quantum field theories. For example, quantum electrodynamics describes electromagnetic interactions.
Say Something: Do you know anything about Sellar's myth of the given?
Thinking......
Bot: An important clarificatory note: the pairing of this question with this passage seems to imply that Sellars is suggesting that the Myth of the Given isn't really a myth. But he's actually doing the opposite: he's suggesting that his myth (we might call it the Myth of Genius Jones), which is supposed to *supplant* the Myth of the Given, is not really a myth. So I guess there are really two questions implicit in this post:
(1) Is the Myth of the Given really just a myth?
(2) Is the Myth of Genius Jones, which is supposed to provide an alternative to the Myth of the Given, really just a myth?
Sellars's view is that the answer to (1) is "yes" and that the answer to (2) is "no" (though, of course, he doesn't mean to endorse the Myth of Genius Jones taken *too* literally, i.e. he doesn't think the theory of thoughts was literally devised by one guy all at once).
Since you ask for thoughts, I'll add that my own view is that Sellars is right on both of these questions. The Myth of the Given is a Myth, and the story of Genius Jones is likely an apt metaphor for how we came to be aware of our own internal episodes.
Say Something: I am quite tired today; I didn’t know that the project deadline was so soon. I had a sleepless night working on the project.
Thinking......
Bot: Honestly i'm pretty irresponsible when it comes to projects. I always try to finish them the last second which is really bad. I have a set sleep time that i refuse to mess up. So i'm going to try and finish work before it's due so i don't start having panic attacks.
As for you just talk to your teacher. They've probably been in the same shoes as you: they'll understand.
Say Something: Did you know I accidentally deleted major portions of the project and had to reconstruct it again? Version control is important huh. Who knew?
Thinking......
Bot: Reminds me of the time I was working on a web development project in uni, the night before due date I kinda blew up the php code, and couldn't figure out what I broke.
Remember kids, source control is important!
Say Something: Just my luck, I have three project presentations in the same day.
Thinking......
Bot: Make sure you plan out studying this week and create a schedule for yourself. However, don't forget to keep sleep in the schedule!
Trust me, I was in college for 4.5 years and the one thing I learned was that all-nighters are *not* what you need. I failed calc the first time because I made so many stupid mistakes on the final that I would have at least been able to *think* about had I studied just a little less and slept just a little more. You need to find the right balance.
Say Something: By the way, can you tell me about Language Models?
Thinking......
Bot: On 1B dataset, [Exploring the Limits of Language Modeling](https://arxiv.org/abs/1602.02410) has 30 (23.7 with ensembles)
Say Something: Please tell me more about them.
Thinking......
Bot: Learn about **GRAPHENE**
https://www.youtube.com/watch?v=Mcg9_ML2mXY&t=2s
it will be the solution. it is the solution.
Video:

Requirements:
Here's my exported miniconda environment: https://github.com/JRC1995/Chatbot/blob/master/chatbot.yml
Also do:
apt-get install ffmpeg libavcodec-extra
Original Directory
This shows how the directory should be set up. It shows all the files and folders unfiltered along with all the big model weights that were not uploaded to the repository:
├── Classifier
│ ├── data
│ │ ├── dev.txt
│ │ ├── inference.txt
│ │ ├── process_data.py
│ │ ├── processed_data.pkl
│ │ └── train.txt
│ ├── DataLoader
│ │ └── bucket_and_batch.py
│ ├── model
│ │ ├── dialog_acts.py
│ │ └── __init__.py
│ ├── Model_Backup
│ │ └── model.pt
│ └── train_and_test
│ └── train.py
├── evaluate.py
├── Generator
│ ├── DialoGPT
│ │ ├── Configs
│ │ │ ├── config.json
│ │ │ ├── merges.txt
│ │ │ └── vocab.json
│ │ └── Parameters
│ │ ├── medium_ft.pkl
│ │ └── small_reverse.pkl
│ ├── Experimental Codes
│ │ ├── test_advanced_experimental_2.py
│ │ └── test_advanced_experimental.py
│ ├── generator.py
│ └── __init__.py
├── __init__.py
├── interact_generator_only.py
├── interact.py
├── interact_retrieval_only.py
├── interact_verbose.py
├── Readme.txt
├── ReRanker
│ └── rerank.py
├── Retriever
│ ├── Data
│ │ ├── advicea.csv
│ │ ├── adviceq.csv
│ │ ├── askphilosophya.csv
│ │ ├── askphilosophyq.csv
│ │ ├── askreddita.csv
│ │ ├── askredditq.csv
│ │ ├── asksciencea.csv
│ │ ├── askscienceq.csv
│ │ ├── casuala.csv
│ │ ├── casualq.csv
│ │ ├── eli5a.csv
│ │ ├── eli5q.csv
│ │ ├── mla.csv
│ │ ├── mlq.csv
│ │ └── SQL-format
│ ├── Database
│ │ └── reddit.db
│ ├── Faiss_index
│ │ ├── large.index
│ │ └── thread_idx.pkl
│ ├── faiss_it.py
│ ├── fill_data.py
│ └── Retrieve.py
├── Scripted
│ ├── Chatterbot_Corpus
│ │ ├── ai.yml
│ │ ├── botprofile.yml
│ │ ├── computers.yml
│ │ ├── conversations.yml
│ │ ├── emotion.yml
│ │ ├── food.yml
│ │ ├── gossip.yml
│ │ ├── greetings.yml
│ │ ├── health.yml
│ │ ├── history.yml
│ │ ├── humor.yml
│ │ ├── literature.yml
│ │ ├── money.yml
│ │ ├── movies.yml
│ │ ├── politics.yml
│ │ ├── psychology.yml
│ │ ├── science.yml
│ │ ├── sports.yml
│ │ └── trivia.yml
│ ├── Processed_Scripts
│ │ ├── Bot_Profile.pkl
│ │ ├── Chatterbot.pkl
│ │ ├── embedded_bot_queries.pkl
│ │ ├── embedded_chatterbot_queries.pkl
│ │ ├── intent_query_script.pkl
│ │ └── intent_response_script.pkl
│ ├── Random_Reddit_Data
│ │ ├── jokesq.csv
│ │ ├── nostupidq.csv
│ │ ├── showerthoughtsq.csv
│ │ ├── tilq.csv
│ │ └── writingpromptsa.csv
│ ├── setup.py
│ └── Subscripts
│ ├── fill_bot_profile.py
│ ├── fill_chatterbot.py
│ ├── intent_query_script.py
│ ├── intent_response_script.py
│ └── process_pkl.py
├── Sentence_Encoder
│ ├── Embeddings
│ │ ├── ConvRT
│ │ │ ├── assets
│ │ │ ├── saved_model.pb
│ │ │ ├── tfhub_module.pb
│ │ │ └── variables
│ │ │ ├── variables.data-00000-of-00002
│ │ │ ├── variables.data-00001-of-00002
│ │ │ └── variables.index
│ │ └── USE_QA
│ │ ├── assets
│ │ ├── saved_model.pb
│ │ └── variables
│ │ ├── variables.data-00000-of-00001
│ │ └── variables.index
│ ├── encoder_client.py
│ ├── meta_query_encoder_fast.py
│ ├── meta_query_encoder.py
│ ├── meta_response_encoder_fast.py
│ └── meta_response_encoder.py
├── TTS
│ ├── best_model_config.json
│ ├── config.json
│ ├── config_kusal.json
│ ├── dataset_analysis
│ │ ├── AnalyzeDataset.ipynb
│ │ ├── analyze.py
│ │ └── README.md
│ ├── datasets
│ │ ├── __init__.py
│ │ ├── Kusal.py
│ │ ├── LJSpeechCached.py
│ │ ├── LJSpeech.py
│ │ └── TWEB.py
│ ├── debug_config.py
│ ├── extract_feats.py
│ ├── hard-sentences.txt
│ ├── images
│ │ ├── example_model_output.png
│ │ └── model.png
│ ├── layers
│ │ ├── attention.py
│ │ ├── custom_layers.py
│ │ ├── __init__.py
│ │ ├── losses.py
│ │ └── tacotron.py
│ ├── LICENSE.txt
│ ├── models
│ │ ├── __init__.py
│ │ └── tacotron.py
│ ├── notebooks
│ │ ├── Benchmark.ipynb
│ │ ├── ReadArticle.ipynb
│ │ ├── synthesis.py
│ │ └── TacotronPlayGround.ipynb
│ ├── README.md
│ ├── requirements.txt
│ ├── server
│ │ ├── conf.json
│ │ ├── README.md
│ │ ├── server.py
│ │ ├── synthesizer.py
│ │ └── templates
│ │ └── index.html
│ ├── setup.py
│ ├── synthesis.py
│ ├── tests
│ │ ├── generic_utils_text.py
│ │ ├── __init__.py
│ │ ├── layers_tests.py
│ │ ├── loader_tests.py
│ │ ├── tacotron_tests.py
│ │ └── test_config.json
│ ├── text2speech.py
│ ├── ThisBranch.txt
│ ├── train.py
│ ├── TTS.egg-info
│ │ ├── dependency_links.txt
│ │ ├── PKG-INFO
│ │ ├── requires.txt
│ │ ├── SOURCES.txt
│ │ └── top_level.txt
│ ├── tts_model
│ │ ├── best_model.pth.tar
│ │ └── config.json
│ ├── utils
│ │ ├── audio_lws.py
│ │ ├── audio.py
│ │ ├── data.py
│ │ ├── generic_utils.py
│ │ ├── __init__.py
│ │ ├── text
│ │ │ ├── cleaners.py
│ │ │ ├── cmudict.py
│ │ │ ├── __init__.py
│ │ │ ├── numbers.py
│ │ │ └── symbols.py
│ │ └── visual.py
│ └── version.py
└── Utils
├── functions_old.py
├── functions.py
└── __init__.py
Project Setup
Component # 0: Sentence Encoder Module
The sentence encoder is one of the most fundamental components of the project. It uses a concatenation of Multi-context ConveRT and Universal Sentence Encoder QA to encode utterances. The encoded utterances are used for almost all the other modules - for retrieval, for classification, for ranking etc. For this module to work you need to download and store the model in the appropriate directory inside Sentence_Encoder. Refer to the directory tree for the extact location. Specifically, the content inside tensorflow-hub pretrained ConveRT model should go within Sentence_Encoder/Embeddings/ConvRT directory, and Universal Sentence Encoder Multilingual QA should go within Sentence_Encoder/Embeddings/USE_QA. The sentence encoder uses different components for encoding user utterances than that for encoding response candidates. It also can take context into account. See project report for details.
Component # 1: Scripted Module
Run setup.py inside the scripted folder to process all the necessary documents for this module. This module mostly prepares "query-responses" pair mappings. Given an utterance, the model finds the best matching query (by measuring cosine similarity or dot product of their encodings) and returns its corresponding responses.
Here you can write your "intent to response" maps. You can create any kind of new 'intent' (say '<fetch_water>') and you can then write the list of candidate responses for that intent. Instead of writing natural language responses you can also type in "command codes" (say <get_water>) and later upon detecting the command codes you can make the AI take any related action you want. Here you can write "intent to query" maps. For example:
'<fetch_water>':['bring me some water','I want some water']
That is here you map intents to potential queries and utterances related to that intent. You don't need to be exhaustive - the intent will be detected based on soft embedding based semantic-similarity search not through hard pattern matching.
You also need to keep downloaded Reddit data in Scripted/Random_Reddit_Data/ directory.
For this, I used Google Big Query to query out data from different subreddits and prepared different CSVs. I prepared jokesq.csv from r/Jokes, showerthoughsq.csv from r/Showerthoughts, tilq.csv from r/todayilearned, and nostupidq.csv from r/NoStupidQuestion. Each of these csv should have a 'title' field (denotes thread title), and jokesq.csv should also have the 'self-text' field (denotes the original post of a thread). Each of these CSVs are prepared from reddit submissions\posts (not comments). In addition to all these, I also prepared writingpromptsa.csv from r/WritingPrompts but for this the necessary fields are 'body' (denotes the comment text), 'parent_id' (denotes id of the immediate parent -comment or thread), and 'link_id' (denotes id of the thread in which the comment is made). These fields are essentially table attributes when you are using sql on Google Query. For more about downloading Reddit Data from Google Big Query see:
https://pushshift.io/using-bigquery-with-reddit-data/
https://www.reddit.com/r/bigquery/comments/3cej2b/17_billion_reddit_comments_loaded_on_bigquery/
You can also use this: https://files.pushshift.io/reddit/ (download comments and submissions from whichever year) and prepare the corresponding csv files from them.
In my case, I downloaded data from last few years (the latest year being 2018) and I also used 'scores' (denotes upvotes) as filter (I only kept highly upvoted ones). The threshold of score depends on the subreddits (popular subreddits can have frequent comments and posts with thousands of upvotes, in less popular ones getting 5 upvotes can be a big deal).
How are these data used? Depending on the user utterances, certain 'command codes' may be activated by the scripted module and depending on the command codes the retrieved response may come from a certain csv file from here.
For example, if you say "I want to hear a joke", the scripted module may return "<JOKE>" as an answer. "<JOKE>" will then be identified as not a natural language response but a "command code" which is mapped with some special action. In this case, the special action is randomly retrieving a row from jokesq.csv and responding with the concatenation of the title and self-text in that row.
Component # 2: Retrieval Module
Retrieval Module is similar to the scripted module. It also deals with query-responses mappings and retrieving based on cosine-similarity or dot-product between the encodings of preset queries and user utterances. The difference is that it operates solely on large scale organic data (precisely, it's Reddit data again). To prepare this module we have to again prepare a lot of csv files from different subreddits. Specifically you need to have these files:
'Retriever/Data/adviceq.csv' (from r/Advice),
'Retriever/Data/askphilosophyq.csv' (from r/askphilosophy),
'Retriever/Data/askredditq.csv' (from r/AskReddit),
'Retriever/Data/mlq.csv' (from r/MachineLearning),
'Retriever/Data/casualq.csv' (from r/CasualConversation),
'Retriever/Data/eli5q.csv' (from r/explainlikeimfive),
'Retriever/Data/askscienceq.csv' (from r/AskScience),
'Retriever/Data/advicea.csv' (from r/Advice),
'Retriever/Data/askphilosophya.csv' (from r/askphilosophy),
'Retriever/Data/askreddita.csv' (from r/AskReddit),
'Retriever/Data/mla.csv' (from r/MachineLearning),
'Retriever/Data/casuala.csv' (from r/CasualConversation),
'Retriever/Data/eli5a.csv' (from r/explainlikeimfive),
'Retriever/Data/asksciencea.csv' (from r/AskScience)
The files ending with 'q' refers to queries (utterances to respond to) and files ending with 'a' refers to candidate responses (answers). Each file ending with 'q' have data from reddit threads (submissions/posts) whereas each file ending with 'a' have data from reddit comments. I treat top level comments as candidate responses whereas thread titles act as the query utterance.
The CSV files ending with q require the following fields:
title, id
The CSV files ending with 'a' require the following fields:
body, id, parent_id, link_id
The order is not important. You can prepare the csv data by any means. You can use google big query or other sources mentioned in the scripted module section.
You can also use different CSV files. Just change the filepaths_q and filepaths_a list here accordingly.
After the csv files are setup execute the following steps in the following order:
- Run fill_data.py (to prepare a Sqlite database with queires and candidate responses along with their encodings)
- Run faiss_it.py (prepare faiss indexing and related stuff for fast retrieval)
WARNING: fill_data.py may take a long time (because of encoding a lot of texts). And there may also be some kind of memory leakage which makes the memory keep on accumulating leading to termination. I have not looked too deep into how to exactly fix it. An ugly workaround would be to do the processing in steps (like, run for one subreddit CSV(corresponding q and a files), terminate after completing, and then run again for another subreddit).
Component # 3: Dialog-Act Classifier Module
This module attempts to classify the dialog act of a given utterance. The available dialog act classes are:
['nonsense', 'dev_command', 'open_question_factual', 'appreciation', 'other_answers', 'statement', \
'respond_to_apology', 'pos_answer', 'closing', 'comment', 'neg_answer', 'yes_no_question', 'command', \
'hold', 'NULL', 'back-channeling', 'abandon', 'opening', 'other', 'complaint', 'opinion', 'apology', \
'thanking', 'open_question_opinion']
See here for more details on the classes. Depending on the class different actions are taken in interact.py or interact_(x).py.
To prepare this module you don't have to do anything as the pre-trained model is already available here.
If this file was not available you would have to do the following steps:
Component # 4: Generative Module
The generative module is based on DialoGPT. See:
https://github.com/microsoft/DialoGPT https://arxiv.org/abs/1911.00536
I created a custom decoder based on Nucleus Sampling. Essentially I am creating multiple sample responses in a batch using Nucleus Sampling. I was experimenting with other approaches (diverse beam decoding with nucleus sampling and such - but weren't able to get as diverse of responses - the experimental codes are available here).
To setup this module you only need to download the pre-trained files.
You need to make sure that these files are available in these directories:
├── Generator
│ ├── DialoGPT
│ │ └── Parameters
│ │ ├── medium_ft.pkl
│ │ └── small_reverse.pkl
medium_ft.pkl can be downloaded from here.
small_reverse.pkl can be downloaded from here.
Component # 5: Ranker Module
All these above modules together usally end up generating multiple candidate responses. Often scripted responses, retrieved responses, and generated responses together form the list of candidate responses. But we have to select one. This module is responsible for ranking and scoring each candidate response. This module is based on two methods - cosine similarity based on query and response encodings from Universal Sentence QA and a reverse generator using the principle of maximum mutual information. It uses a weighted average of the scores from the two methods. See the project report for more details.
You don't need to do anything to prepare this module.
Component # 6: TTS Module
This module is based on an older repository of Mozilla TTS. I also tried a newer version with Tacotron-2, but the practical results was worse on a lot of segments. WaveRNN made the voice much better but there were still issues with skipping or skimming through some portions of the text segments. Furthermore, WaveRNN makes this very slow. To prepare this module, download this pre-trained model (Tacotron-iter-120K in here). Then keep them here:
├── TTS
│ ├── tts_model
│ │ ├── best_model.pth.tar
│ │ └── config.json
Component # 7: Controller Module
interact.py and co. (interact_retrieval_only.py, interact_generator_only.py etc.) acts as the controller module. This file interfaces, co-ordinates, and handle the communication among all the different modules. You do not need to do anything further with these files.
Running the Project
If everything is set up, you are ready to run the project. To run the normal project as normal use:
python interact.py
To run the project with TTS voice disabled use (should work for other interact_(x).py files):
python interact.py --no-voice
To run the project in verbose mode (which shows where the responses are coming from - from reddit? from dialoGPT? from script? and the classified dialog acts), use:
python interact_verbose.py
To run the project without generator:
python interact_retrieval_only.py
To run the project allowing only the generator to generate candidate responses:
python interact_generator_only.py
