Jlumbroso Comma Save
Python CSV, and delimiter-spaced files, for humans!
Comma: A Python CSV Library for Humans
![]()
![]()

This library tries to make manipulating CSV files a great experience.
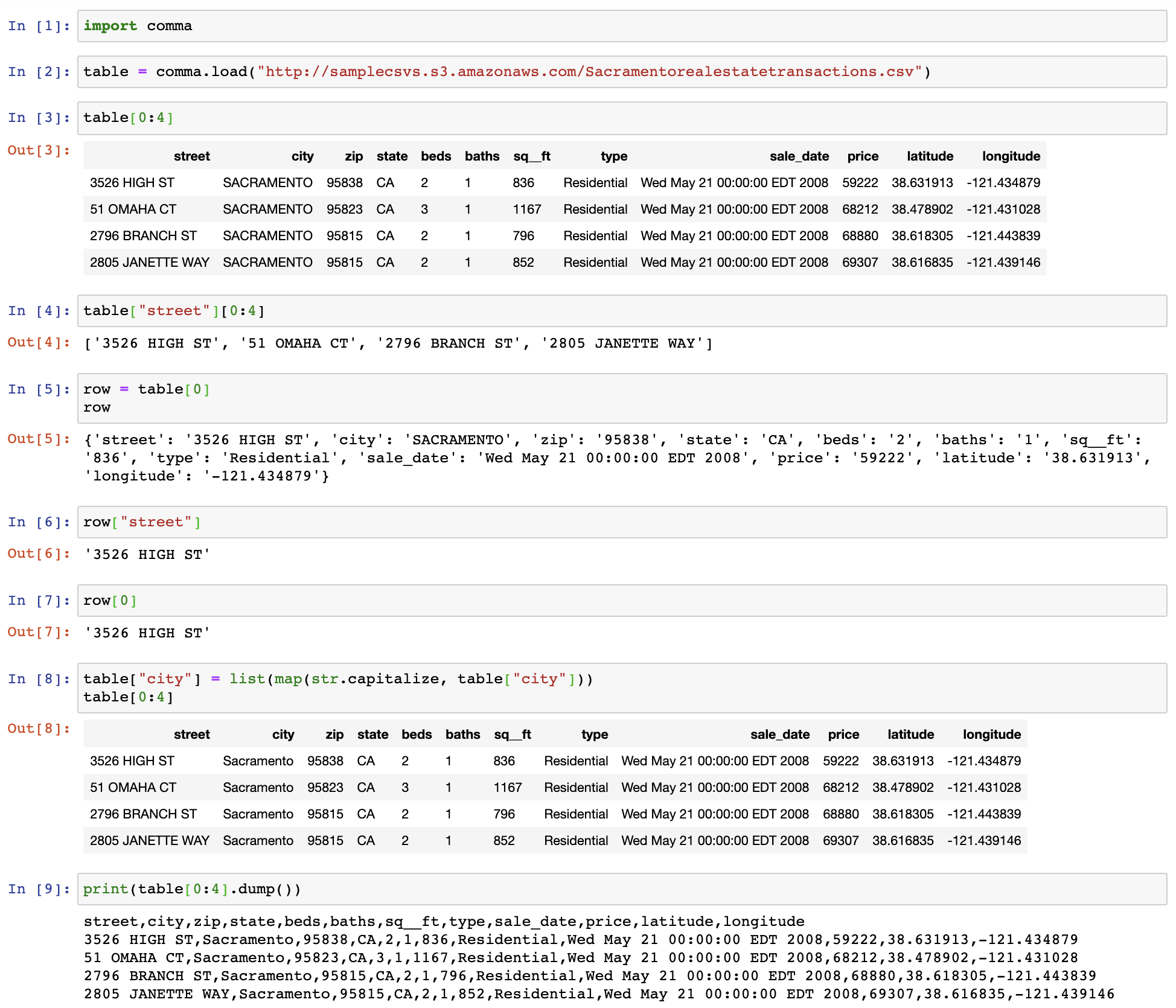
Features
Here are some of the features that comma supports:
- Robust autodetection of CSV parameters
(thanks to
clevercsv) and encoding (thanks tochardet). - Single-line usage,
comma.load(...), no syntax to remember or parameters to tweak. - Simple, Pythonic interface to access/modify the rows using standard
listanddictoperations, i.e.row[0]androw["street"]are equivalent. - Column slices using the header name, i.e.
table["street"]. - In-place editing of the dataset, including multiple lines.
- Opening files directly from an URL.
Installation
If you use pip:
pip install 'comma[autodetect,net]'
or if you use pipenv:
pipenv install 'comma[autodetect,net]'
Why?
Although Python, fortuitously, is
"batteries included",
on occasion, some of the libraries end up being designed with APIs
that don't map well to what turns out to be the most common usage
patterns. This is what happened with the various urllib libraries,
incredibly powerful, but limiting users by its complexity---it was
not straightforward, for instance, to use cookies: One of several
problems that requests by
@ken-reitz addressed. Indeed,
requests abstracts power beneath simplicity, smart defaults, and
discoverability.
For the CSV format, we are confronted with a similar situation. While both the JSON and YAML formats have packages that provide, one-command means to load content from files in those respective formats to a nested Python object, for the CSV format, the standard library has you use an iterator to access the data. Many details require significant syntax change (for instance the difference between having lists or dictionaries depends on the class that is used to read the file).
Since then, we also have several excellent libraries that, by providing great auto-detection (of dialect, file format, encoding, etc.) allow for hiding many details from the end user.
All this to say, comma will try to do exactly what you want
when you do:
import comma
data = comma.load("file.csv")
data[0]["field"] = "changed value"
comma.dump(data, filename="file_modified.csv")
Alternatives
Python is fortunate to have a lot of very good libraries to read/write CSV and tabular files in general. (Some of these were discovered through the excellent Awesome Python list.)
-
clevercsv: An exceptional library by @GjjvdBurg, builds on statistical and empirical to provide powerful and reliable CSV dialect detection. However, it strives to be a drop-in replacement for the original Pythoncsvmodule, and as such does not improve on the complex syntax. This library is the culmination of serious peer-reviewed research, andcommauses it internally to improve auto-detection. -
csvkit: This is a set of command-line tools (rather than a module/package) written in Python, to make it easier to manipulate CSV files. One of the highlights is a tool calledcsvpy <file.csv>to open a Python shell with the CSV data loaded into a Python object calledreader, to quickly run some Python logic on the data. While it is technically possible to usecsvkit's internals in a project, this is not documented. -
pandas: An advanced data science package for Python, this certainly provides a powerful CSV (and more generally, table file) reader and parser. The API of the table object is very powerful, but you need to take the time to learn how to use it. This library is perhaps not ideal for file manipulations. -
pyexcel: This library provides access to Excel and other tabular formats, including CSV, and various data sources (stream, database, file, ...). It emphasizes one common format-agnostic API, that instead has the user choose the data format (list, matrix, dictionary, ...). -
tablib: This library was originally written by Kenneth Reitz, the creator who broughtrequests,pipenvand many other goodies to Python---and then included in the Jazzband collective. The focus of this library is on interoperating between many different file formats (such as XLS, CSV, JSON, YAML, DF, etc., ..., even LaTeXbooktabs!). It seems to have a very high adoption rate because it is a dependency for many Jazzband libraries. The API is class-based rather than method-based. A companion library,prettytablefocuses on pretty printing tabular data (including from a CSV file). -
tabulator: This library provides a single interface to manipulate extremely large tabular data---and useful for files so large that they need to be streamed line-by-line; the library supports a broad array of formats including reading data directly from Google Spreadsheets. However this power means that reading a CSV file requires several operations.
Although not specifically restricted to Python, the AwesomeCSV resource is also interesting.
Miscellaneous
Although not specifically a Python library, nor designed to read/write CSV
files (but instead to compare them), daff
is a really cool project: It provides a diff of tabular data with cell-level
awareness.
Another unrelated project is Grist, a spreadsheet PaaS, which among other useful features, allows the use of Python within formulas.
Acknowledgements
Thanks to @zbanks for the name of the package!
Thanks to @rfreling,
@adamfinkelstein for discussing ideas
before I got started on this. Thanks to @GjjvdBurg
and collaborators for awesome, awesome contribution to text processing science
and our Python community with clevercsv.
License
This project is licensed under the LGPLv3 license, with the understanding that importing a Python modular is similar in spirit to dynamically linking against it.
-
You can use the library
commain any project, for any purpose, as long as you provide some acknowledgement to this original project for use of the library. -
If you make improvements to
comma, you are required to make those changes publicly available.
