ImageSetCleaner Save
Semi-supervised tool for cleaning image dataset , using deep learning.
Semi-supervised detection of wrong labels in labeled data set

Usage
This algorithm is well suited to validate labelled images obtained with web scrapping, untrusted sources or colloborativly generated labels.
How does it work
This approach separate our image directory between two classes, inliers, and outliers, by describing the images with the bottlenecks values generated by the end of the convolution phase of a pre-trained CNN, like 'inception-v3' or a MobileNets, for faster computation. ( see: Here )
These values are then fed to a clustering algorithm to get a prediction. To increase performance, some values of random images are precomputed, and added during the fit of our classifier.
Basic Usage
Just run the ImageSetCleaner.py and pass the location of the directory you want to detect like so :
python image_set_cleaner.py --image_dir=./foo/LocationLabelDir/
You will then see a GUI pop up where you will be able to fine tune the detection and delete/move the selected outliers.
Installation
$ pip install -r requirements.txt
Options
-
--image_dir: Path to the image directory you want to examine
-
--clustering_method: Choose your method of clustering, between : kmeans, birch, gaussian_mixture, agglomerative_clustering
-
--processing: You have the choice between 3 operations to handle the predictions of the clustering algorithm : - gui (default) : Will pop a gui that will let you delete the detected images directly - delete : Will simply delete the detected outliers - move : Will move the detected outliers to specified path given in --relocation_dir
-
--relocation_dir: Path where you want the detected images to be moved, when the processing option move is selected
-
--architecture: The name of the pretrained architecture you want to use. I will advice to use a mobilenet, instead of inception-v3, unless you have a lot of image of one label, to prevent the effect of the curse of dimensionality:
['inception_v3', 'mobilenet_1.0_224', 'mobilenet_1.0_192', 'mobilenet_1.0_160', 'mobilenet_1.0_128','mobilenet_0.75_224', 'mobilenet_0.75_192', 'mobilenet_0.75_160', 'mobilenet_0.75_128', 'mobilenet_0.50_224', 'mobilenet_0.50_192', 'mobilenet_0.50_160', 'mobilenet_0.50_128', 'mobilenet_0.25_224', 'mobilenet_0.25_192', 'mobilenet_0.25_160', 'mobilenet_0.25_128']
The mobilenets follow the pattern : mobilenet_
-
--model_dir: Path where you want the weights and description to be downloaded, or if already done
-
--pollution_dir: Path where the precomputed of random images are located.
-
--pollution_percent: The percentage of bolltenecks that will be used for the prediction of the clustering algorithm in addition to the values computed on your images.
Creating your own noisy bottlenecks
You can create your own pollution values, that are more specefic to your problem by running the script Create_noise_bottlenecks.py. See further explanations, and option inside the file.
python create_noise_bottlenecks.py --image_dir=./foo/LocationLabelDir/ --architecture=all
Some result
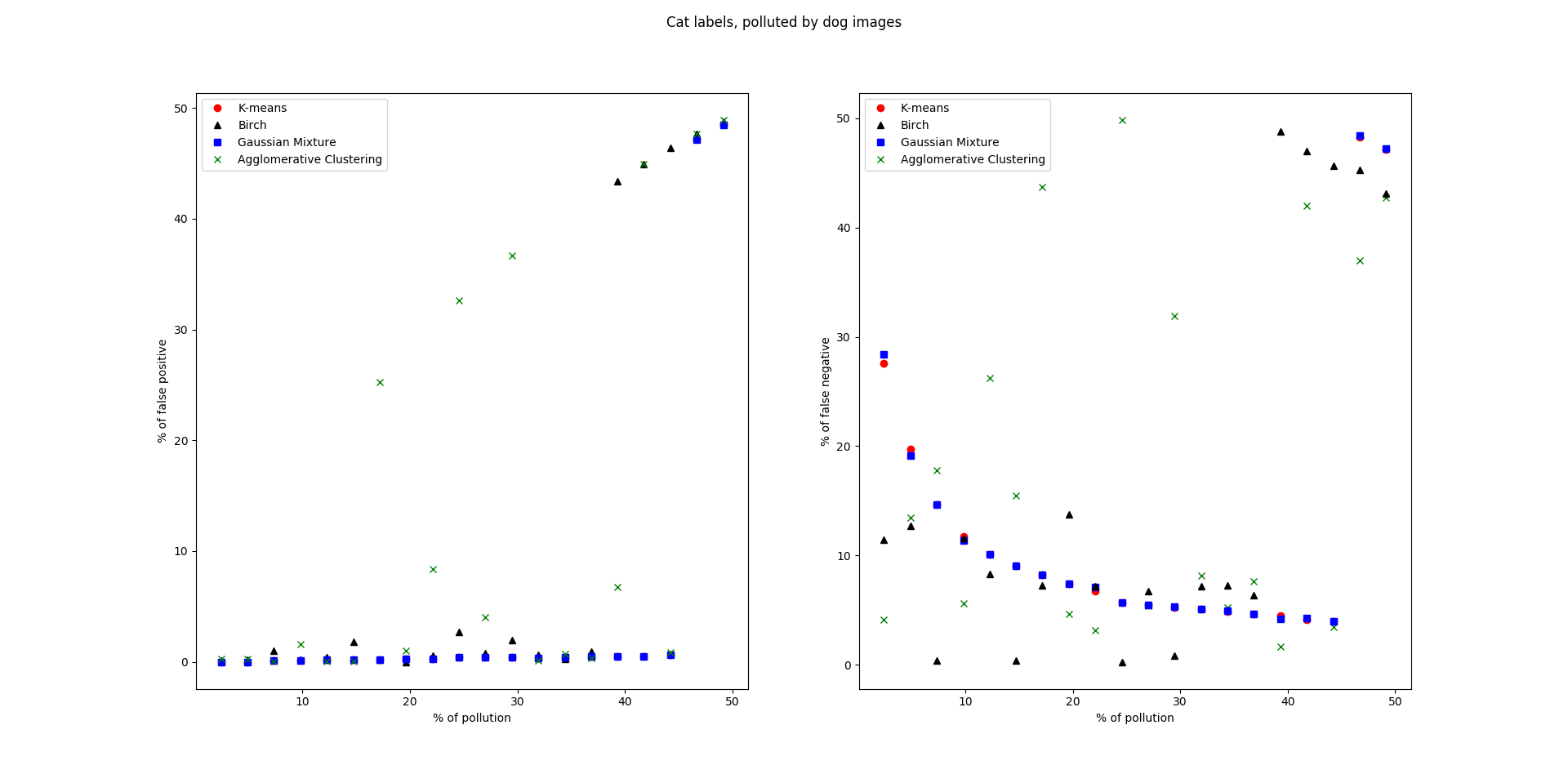
These graphs are generated using a set of cat images (inliers), and a percentage gradualy increasing of dog images.
As expected this method works realy great, for images or labels that our pretrained CNN has seen. So if you have a need specific, or checking a constant data stream, with known outcome of images, I encourage you to use a custom CNN and adapt the code, and/or use the create_noise_bottlenecks script, for better performance.
Furthermore from these graphs the breaking point of our estimator can be estimated at between 40-45 % of noise. This is due to the process of normalizing the predictions, and choosing as inliers the smallest cluster.


In these two graphs, the method as been tested, on a likely data mining source, google image. It achieves a detection of up to 90 % of wrong labels, while minimizing false positives to under 10 % of our set. This can bring your data set, from unsalvageable or too expensive to correct or gather, to something that could be use for training despite residual noise ( see : Here )
Visualisation
Here is a visualisation of this problem after different iso map transformations to validate the process, by looking at the separability of our two clusters and get an intuition of the effect of added pollution images, for better performance.

What could be improved
As of right now, the unsupurvised algorithms used are still limited as they are only clustering data, instead of true semi-supervised, and also reuse information from the user that deleted/moved wrong labels with the GUI.
