GeneralNewsExtractor Versions Save
新闻网页正文通用抽取器 Beta 版.
v0.3.0
2 years ago0.2.6
3 years ago- 修复 extract_by_htag_and_title 在发现 H 标签中的文本与 title 标签的文本在最小公共子串长度小于4时被认为是标题的问题。
0.2.5
3 years ago- 如果标题中含有-|,且在较为靠前的地方,可能导致标题只提取了半截。需要判断-|左侧字符串的长度。如果小于4,那么返回整个标题字符串。
0.2.4
3 years ago- 预处理时,移除 footer 标签。
0.2.3
3 years ago0.2.2
3 years ago新闻列表页自动提取功能测试版已经上线,用法如下:
>>> from gne import ListPageExtractor
>>> html = '''经过渲染的网页 HTML 代码'''
>>> list_extractor = ListPageExtractor()
>>> result = list_extractor.extract(html,
feature='列表中任意元素的 XPath")
>>> print(result)
0.2.1
3 years ago0.1.9
3 years ago- 优化标题提取逻辑,根据@止水 和 @asyncins 的建议,通过对比 //title/text()中的文本与
标签中的文本,提取出标题。 - 增加
body_xpath参数,精确定义正文所在的位置,强力避免干扰。
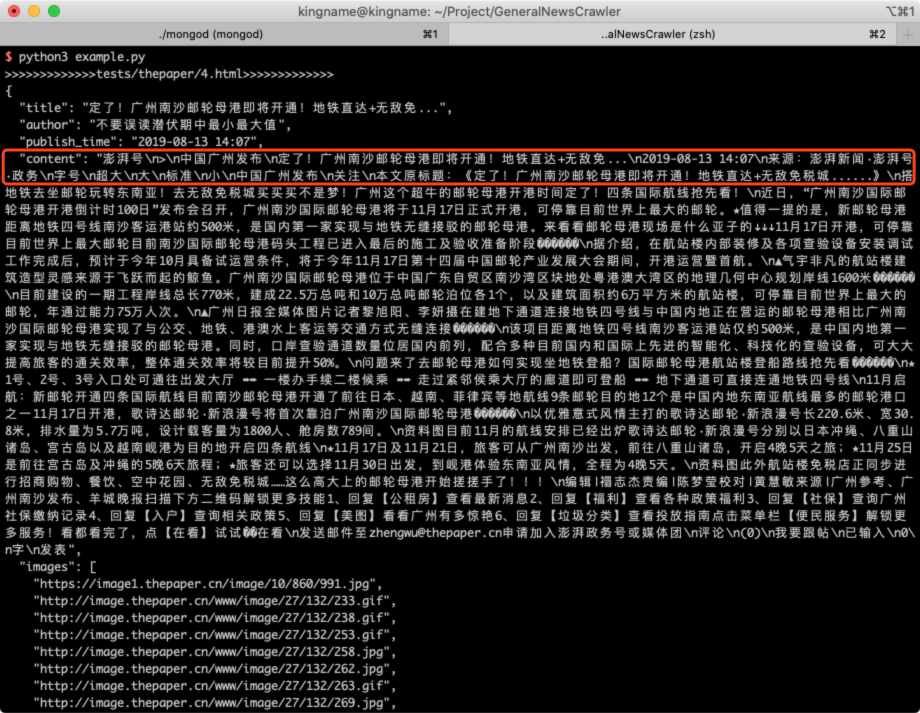
例如对于澎湃新闻,在不设置body_xpath参数时:
result = extractor.extract(html,
host='https://www.xxx.com',
noise_node_list=['//div[@class="comment-list"]',
'//*[@style="display:none"]',
'//div[@class="statement"]'
])
提取效果如下:
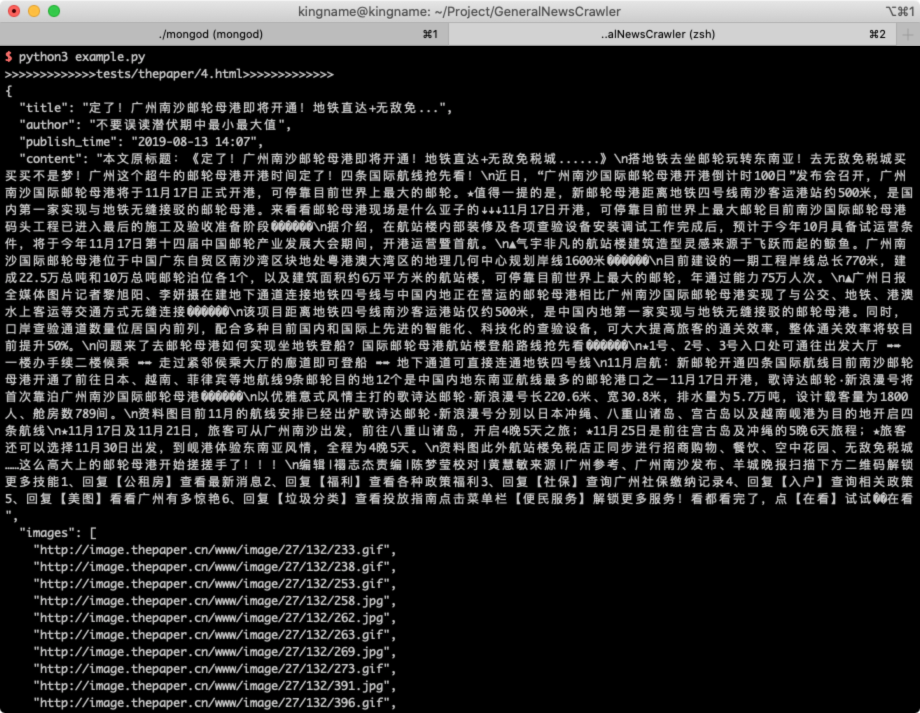
设置了body_xpath以后:
result = extractor.extract(html,
host='https://www.xxx.com',
body_xpath='//div[@class="news_txt"]', # 缩小正文提取范围
noise_node_list=['//div[@class="comment-list"]',
'//*[@style="display:none"]',
'//div[@class="statement"]'
])
结果如下:
0.18
4 years ago- 预处理逻辑可能会破坏原有 HTML 结构,导致用户自定义的 XPath 失效。因此需要再预处理之前提取 title、author 和 publish_time。