Evalplus Versions Save
EvalPlus for rigourous evaluation of LLM-synthesized code
v0.2.2
1 month agoMain updates
- New CLI:
evalplus.sanitizeto post-process LLM generated code as much as possible - New CLI:
evalplus.syncheckto check the Python compilability of LLM generated code
PyPI: https://pypi.org/project/evalplus/0.2.2/ Docker Hub: https://hub.docker.com/layers/ganler/evalplus/v0.2.2/images/sha256-b9b2055b8380a8cdddd71b4355c56c13fe37d930cd46d0815e140b7dbe045dd2
v0.2.1
1 month agoMain updates
- HumanEval+ and MBPP+ datasets are on the hub now:
- HumanEval+ is ported to original HumanEval format. Release files have a new home now:
- You can use EvalPlus through bigcode-evaluation-harness now
- Docker image now uses Python 3.10 since some model might generate Python code using latest syntax, leading to false positive using older Python
- Sanitizer is now merged into the pacakge
- Several improvements and bug fixes to the sanitizer
- Test suite reduction now moved to
tools - Fixes the
CACHE_DIRnonexistance issue - Simplified the format of
eval_results.jsonfor readability - Use
EVALPLUS_TIMEOUT_PER_TASKenv var to set the maximum testing time for each task - Timeout per test is set to 0.5s by default
- Fixes argument validity for
inputgen.py
Dataset maintainence
-
HumanEval/32: fixes the oracle
Supported codegen models
- Now EvalPlus leaderboard lists 82 models
- WizardCoders
- Stable Code
- OpenCodeInterpreter
- antropic API
- mistral API
- CodeLlama instruct
- Phi-2
- Solar
- Dophin
- OpenChat
- CodeMillenials
- Speechless
- xdan-l1-chat
- etc.
PyPI: https://pypi.org/project/evalplus/0.2.1/ Docker Hub: https://hub.docker.com/layers/ganler/evalplus/v0.2.1/images/sha256-2bb315e40ea502b4f47ebf1f93561ef88280d251bdc6f394578c63d90e1825d7
v0.2.0
5 months ago🔥 Announcing MBPP+
MBPP is a dataset curated by Google. Its full set includes around 1000 crowd-sourced Python programming problems. However, certain amount of problems can be noisy (e.g., prompts make no sense or tests are broken). Consequently, a subset (~427 problems) of the data has been hand-verified by original author -- MBPP-sanitized.
MBPP+ improves MBPP based on its sanitized version (MBPP-sanitized):
- We further hand-verify the problems to trim ill-formed problems to keep 399 problems
- We also fix the problems whose implementation is wrong (more details can be found here)
- We perform test augmentation to improve the number of tests by 35x (on avg from 3.1 to 108.5)
- We mantain the scripting compatibility against HumanEval+ where one simply needs to toggle the switch by
--dataset mbppforevalplus.evaluate,codegen/generate.py,tools/checker.pyas well astools/sanitize.py - Initial leaderboard is made available on https://evalplus.github.io/leaderboard.html and we will keep updating
A typical workflow to use MBPP+:
# Step 1: Generate MBPP solutions
from evalplus.data import get_mbpp_plus, write_jsonl
def GEN_SOLUTION(prompt: str) -> str:
# LLM produce the whole solution based on prompt
samples = [
dict(task_id=task_id, solution=GEN_SOLUTION(problem["prompt"]))
for task_id, problem in get_mbpp_plus().items()
]
write_jsonl("samples.jsonl", samples)
# May perform some post-processing to sanitize LLM produced code
# e.g., https://github.com/evalplus/evalplus/blob/master/tools/sanitize.py
# Step 2: Evaluation on MBPP+
docker run -v $(pwd):/app ganler/evalplus:latest --dataset mbpp --samples samples.jsonl
# STDOUT will display the scores for "base" (with MBPP tests) and "base + plus" (with additional MBPP+ tests)
🔥 HumanEval+ Maintainance
- Leaderboard updates (now 41 models!): https://evalplus.github.io/leaderboard.html
- DeepSeek Coder series
- Phind-CodeLlama
- Mistral and Zephyr series
- Smaller StarCoders
- HumanEval+ now upgrades to
v0.1.9fromv0.1.6- Test-case fixes: 0, 3, 9, 148
- Prompt fixes: 114
- Contract fixes: 1, 2, 99, 35, 28, 32, 160
PyPI: https://pypi.org/project/evalplus/0.2.0/ Docker Hub: https://hub.docker.com/layers/ganler/evalplus/v0.2.0/images/sha256-6f1b9bd13930abfb651a99d4c6a55273271f73e5b44c12dcd959a00828782dd6
v0.1.7
8 months ago- EvalPlus leader board: https://evalplus.github.io/leaderboard.html
- Evaluated CodeLlama, CodeT5+ and WizardCoder
- Fixed contract (HumanEval+): 116, 126, 006
- Removed extreme inputs (HumanEval+): 32
- Established
HUMANEVAL_OVERRIDE_PATHwhich allows to override the original dataset with customized dataset
PyPI: https://pypi.org/project/evalplus/0.1.7/ Docker Hub: https://hub.docker.com/layers/ganler/evalplus/v0.1.7/images/sha256-69fe87df89b8c1545ff7e3b20232ac6c4841b43c20f22f4a276ba03f1b0d79ae
v0.1.6
10 months ago- Supporting configurable timeouts $T=\max(T_{base}, T_{gt}\times k)$, where:
- $T_{base}$ is the minimal timeout (configurable by
--min-time-limit; default to 0.2s); - $T_{gt}$ is the runtime of the ground-truth solutions (achieved via profiling);
- $k$ is a configurable factor
--gt-time-limit-factor(default to 4);
- $T_{base}$ is the minimal timeout (configurable by
- Using a more conservative timeout setting to mitigate test-beds with weak performance ($T_{base}: 0.05s \to 0.2s$ and $k: 2\to 4$).
-
HumanEval+dataset bug fixes:- Medium contract fixesL P129 (#4), P148 (self-identified)
- Minor contract fixes: P75 (#4), P53 (#8), P0 (self-identified), P3 (self-identified), P9 (self-identified)
- Minor GT fixes: P140 (#3)
PyPI: https://pypi.org/project/evalplus/0.1.6/ Docker Hub: https://hub.docker.com/layers/ganler/evalplus/v0.1.6/images/sha256-5913b95172962ad61e01a5d5cf63b60e1140dd547f5acc40370af892275e777c
v0.1.5
11 months ago🚀 HumanEval+[mini] -- 47x smaller while equivalently effective as HumanEval+
- Add
--minitoevalplus.evaluate ...you can use a minimal and best-quality set of extra tests to accelerate evaluation! -
HumanEval+[mini](avg 16.5 tests) is smaller thanHumanEval+(avg 774.8 tests) by 47x. - This is achieved via test-suite reduction -- we run a set covering algorithm to preserve the same coverage (coverage analysis), mutant-killings (mutation analysis) and sample-killings (pass-fail status of each sample-test pair).
PyPI: https://pypi.org/project/evalplus/0.1.5/ Docker Hub: https://hub.docker.com/layers/ganler/evalplus/v0.1.5/images/sha256-01ef3275ab02776e94edd4a436a3cd33babfaaf7a81e7ae44f895c2794f4c104
v0.1.4
1 year ago-
Performance:
- Lazy loading of the cache of evaluation results
- Use
ProcessPoolExecutoroverThreadPoolExecutor - Caching groudtruth outputs
-
Observability:
- Concurrent logger when a task gets stuck for 10s
-
New models:
- CodeGen2 (infill)
- StarCoder (infill)
-
Fixes:
- Deterministic hashing of input problem
PyPI: https://pypi.org/project/evalplus/0.1.4/ Docker Hub: https://hub.docker.com/layers/ganler/evalplus/v0.1.4/images/sha256-a0ea8279c71afa9418808326412b1e5cd11f44b3b59470477ecf4ba999d4b73a
v0.1.3
1 year ago- Fixes evaluation when input sample format is
.jsonl
PyPI: https://pypi.org/project/evalplus/0.1.3/ Docker Hub: https://hub.docker.com/layers/ganler/evalplus/v0.1.3/images/sha256-fd13ab6ee2aa313eb160fc29debe8c761804cb6af7309280b4e200b6549bd75a
v0.1.2
1 year ago- Fix the bug induced by using
--base-only - Build docker image locally instead of simply doing a
pip install
PyPI: https://pypi.org/project/evalplus/0.1.2/ Docker Hub: https://hub.docker.com/layers/ganler/evalplus/v0.1.2/images/sha256-747ae02f0bfbd300c0205298113006203d984373e6ab6b8fb3048626f41dbe08
v0.1.1
1 year agoIn this version, efforts are mainly made to sanitize and standardize code in evalplus. Most importantly, evalplus strictly follows the dataset usage style of HumanEval. As a result, users can use evalplus in this way:
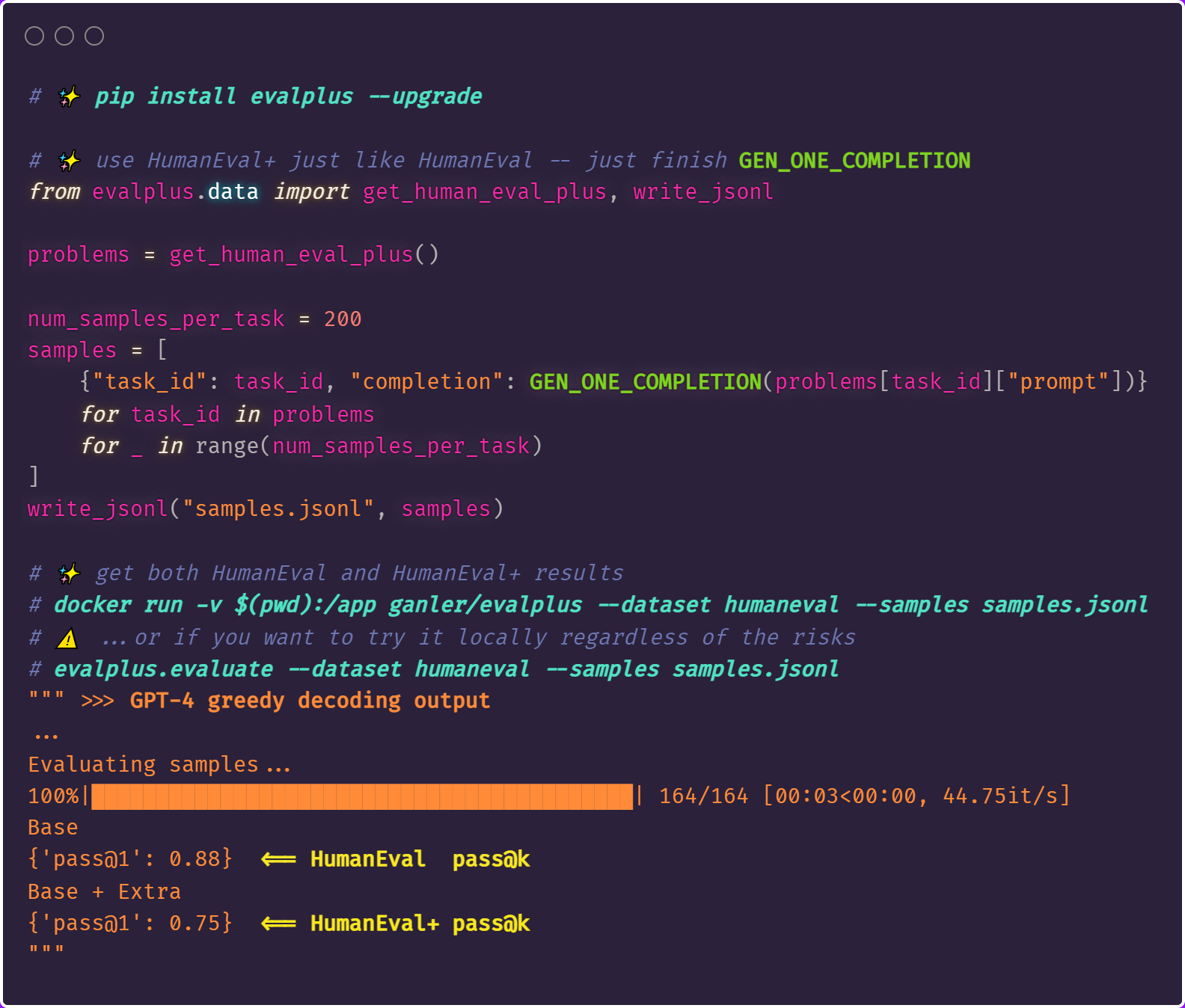
For more details, the main changes are (tracked in #1):
- Package build and pypi setup
- (HumanEval Compatibility) Support sample files as
.jsonl - (HumanEval Compatibility)
get_human_eval_plus()returns adictinstead oflist - (HumanEval Compatibility) Use HumanEval task ID splitter
"/"over"_" - Optimize the evaluation parallelism scheme to the sample-level granularity (original: task level)
- Optimize IPC via shared memory
- Remove groundtruth solutions to avoid data leakage
- Use docker the sandboxing mechanism
- Support Codegen2 in generation
- Split dependency into multiple categories
PyPI: https://pypi.org/project/evalplus/0.1.1/ Docker Hub: https://hub.docker.com/layers/ganler/evalplus/v0.1.1/images/sha256-4993a0dc0ec13d6fe88eb39f94dd0a927e1f26864543c8c13e2e8c5d5c347af0