Ecce Save
ML Prediction of Bible Topics and Passages (Python / React)
Exploratory Core Concept Extraction (Ecce)
![]()


Introduction
ecce = "behold" (Latin)
Deuteronomy 5:24 (ESV)
And you said, ‘Behold, the Lord our God has shown us his glory and greatness, and owe have heard his voice out of the midst of the fire. This day we have seen God speak with man, and man still live.
For thousands of years, people have studied the Bible from countless perspectives with diverse approaches towards various goals. As a Christian myself, I have read, discussed, and learned from it both in personal study and through others. With the plethora of related documents in the form of commentaries, topical indexes, dictionaries, and cross-references, the Bible has been scoured from cover to cover throughout the ages.
The application of this project is two-fold. The first objective is to create a visual exploration of the topics from the Bible. If time permits, this would be accomplished using an interactive website that gives users a way to see related passages that were only previously linked in a manual fashion. Second, the trained network will be used to predicting both related topics and Scripture references from arbitrary text (similar in form to Bible verses).
Overview
This project is the intersection and analysis of three data sources: English Standard Version (ESV Bible translation), Nave's Topical Index, and Treasury of Scripture Knowledge (TSK, cross-references). The actual data processing and entire flow of the project can be found in the rendered notebook. Additional interactive exploratory data analysis can be found in several React components from the web app. The primary interaction in the web app flows through two models. The topic model combines ESV verse text with a filtered list of Nave's topics (at least 30 verses per topic). The cluster model combines ESV verse text with the cross-references from TSK such that groups of passages can be predicted.

In addition, I presented this project in my final semester for an M.S. in Data Science. The slides I used to present can be found in the repository:

Data Sources
English Standard Version. Text from English Standard Version (2001) is employed using JSON from honza/bibles. All copyrights remain with Crossway.1 Passages longer than three verses are truncated in the interface and link directly to BibleGateway.
Nave's Topical Index. Topics were extracted from text files assembled by the folks behind JustVerses.com from the original, public domain PDF. Although three levels of data are available (topics, categories, and sub-topics), the primary focus was the top-level topics with a total of ~4,200 topics that intersected with verses available from the ESV.
Treasury of Scripture Knowledge. Cross-references were also extracted from text files downloaded from JustVerses.com from the original, public domain data. These verses were associated with the ESV text by validating the references from just over 63,500 cross-reference clusters.
Topic Model

Cluster (Passage) Model
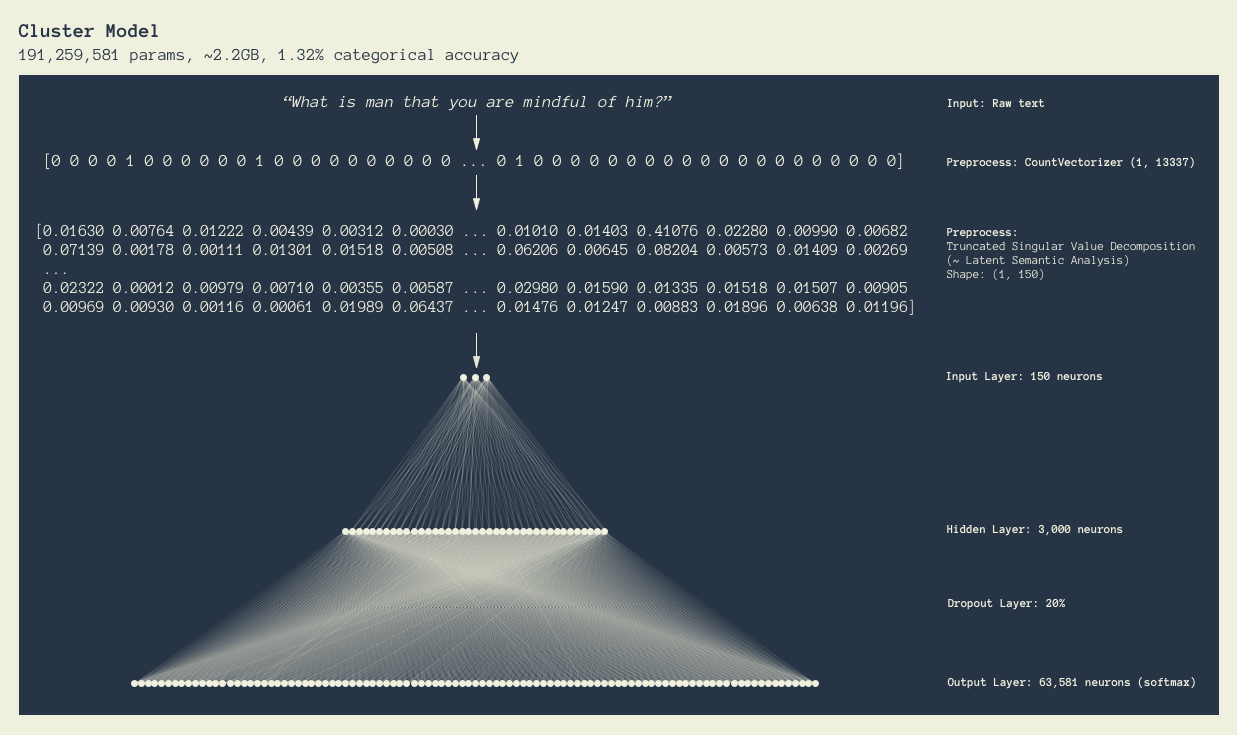
Results
Both of the highest performing models ended up being extremely large fully-connected neural networks although multiple types of recurrent architectures were explored (LSTMs and GRUs) with word embeddings from GloVe. The topic model came in at 435MB with 36,315,622 parameters with an input size of 13,337 and an output of 853 topics. The cluster model was 2.3GB with 191,259,581 parameters with an input size of 150 (truncated SVD of encoded word vocabulary) and an output of 63,581 clusters of cross-references.
Topic Model
Using data from Nave's Topical Index (about ~4,200 without filtering), all of the following model revisions were trained on 21,106 verses, validated on 3,725 verses, and evaluated on 6,208 verses.
| Name | Categorical Accuracy | Notes |
|---|---|---|
| lstm-base | 2.95% | sequence of words, no word embeddings, ~4200 possible topics |
| lstm-b4cab4 | 5.72% | tuned and tweaked, reduce to ~850 topics, word embeddings from glove.42B.300d (includes 92.55% of ESV words) |
| svd-bow-cb8915 | 6.91% | switch to truncated SVD with bag-of-words |
| svd-bow-52a075 | 6.62% | additional experiments, exclude top two topics |
| svd-bow-88bf90 | 8.21% | make SVD 200 components (102% of last model size) |
| svd-bow-ced288 | 7.06% | make SVD 150 components (200 was too big for initial production machine) |
| nave-4576e8 | 13.61% | properly filter topics and remove SVD due to smaller model size, use vocabulary count vectorizer as direct input |
Cluster Model
The cluster model was trained on cross-references from the Treasury of Scripture Knowledge . All of the following model revisions were trained on 20,837 verses, validated on 2,678 verses, and evaluated on 6,129 verses (70%-10%-20% split).
| Name | Categorical Accuracy | Notes |
|---|---|---|
| tsk-cluster-87b509 | 0.25% | initial fully-connected model |
| tsk-cluster-f13345 | 0.33% | add dropout layers and tweak architecture |
| tsk-cluster-1d7203 | 1.05% | fix verses to have multiple uuids |
| tsk-cluster-26869f | 1.14% | add hidden layer and overfit with 10 patience epochs |
| tsk-cluster-4e1698 | 1.16% | make SVD 200 components (doubled model size) |
| tsk-cluster-47f717 | 1.24% | make SVD 150 components (200 was too big for production) |
| tsk-cluster-8a1db9 | 1.32% | change epoch patience to 2 instead of 3 |
Usage
If you're interested in running the project or extending the existing work, you'll need to do the following setup the first time.
# Download sources
./download.sh
# Install Python version and setup dependencies
pyenv install 3.6.8
pyenv virtualenv 3.6.8 $(cat .python-version)
pip install -r requirements.txt
# Download spaCy model
python -m spacy download en
With this setup complete, some of the primary ways you'd want to interact the code are provided by the command line utility that includes documentation for each command.
❯ python -m ecce -h
usage: __main__.py [-h]
{nave-export,topic-export,train-nave,train-tsk,predict-nave,predict-tsk}
...
positional arguments:
{nave-export,topic-export,train-nave,train-tsk,predict-nave,predict-tsk}
nave-export Export processed data from Nave's Topical Index
topic-export Preprocess topics and export with ESV text
train-nave Train an neural network model on Nave data
train-tsk Train cluster model on TSK data
predict-nave (REPL) Predict topics based on text
predict-tsk (REPL) Predict TSK clusters based on text
optional arguments:
-h, --help show this help message and exit
Additional Information
Ecce: ML Prediction of Bible Topics and Passages
Copyright (C) 2019 Christian Di Lorenzo
This program is free software: you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation, either version 3 of the License, or (at your option) any later version.
This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.
You should have received a copy of the GNU General Public License along with this program. If not, see https://www.gnu.org/licenses/.
1 If you believe that the use of ESV text is in violation of copyrights, please send me a direct message with your reasoning so that I can remain above board. My current understanding is that using the 2001 version is not prohibitive in the manner I am using it assuming the entire application is open, noncommercial, and not exposing entire books of the Bible.
