Dogen Versions Save
Reference implementation of the MASD Code Generator.
v1.0.32
1 year ago Baía Azul, Benguela, Angola. (C) 2022 Casal Sampaio.
Baía Azul, Benguela, Angola. (C) 2022 Casal Sampaio.
DRAFT: Release notes under construction
Introduction
As expected, going back into full time employment has had a measurable impact on our open source throughput. If to this one adds the rather noticeable PhD hangover — there were far too many celebratory events to recount — it is perhaps easier to understand why it took nearly four months to nail down the present release. That said, it was a productive effort when measured against its goals. Our primary goal was to finish the CI/CD work commenced the previous sprint. This we duly achieved, though you won't be surprised to find out it was far more involved than anticipated. So much so that the, ahem, final touches, have spilled over to the next sprint. Our secondary goal was to resume tidying up the LPS (Logical-Physical Space), but here too we soon bumped into a hurdle: Dogen's PlantUML output was not fit for purpose, so the goal quickly morphed into diagram improvement. Great strides were made in this new front but, as always, progress was hardly linear; to cut a very long story short, when we were half-way through the ask, we got lost on yet another architectural rabbit hole. A veritable Christmas Tale of a sprint it was, though we are not entirely sure on the moral of the story. Anyway, grab yourself that coffee and let's dive deep into the weeds.
User visible changes
This section covers stories that affect end users, with the video providing a quick demonstration of the new features, and the sections below describing them in more detail. Given the stories do not require that much of a demo, we discuss their implications in terms of the Domain Architecture.
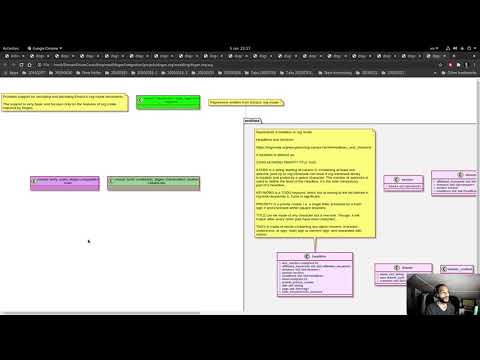 Video 1: Sprint 32 Demo.
Video 1: Sprint 32 Demo.
Remove Dia and JSON support
The major user facing story this sprint is the deprecation of two of our three codecs, Dia and JSON, and, somewhat more dramatically, the eradication of the entire notion of "codec" as it stood thus far. Such a drastic turn of events demands an in-depth explanation, so you'll have to bear with us. Lets start our journey with an historical overview.
It wasn't that long ago that "codecs" took the place of the better-known "injectors". Going further back in time, injectors themselves emerged from a refactor of the original "frontends", a legacy of the days when we viewed Dogen more like a traditional compiler. "Frontend" implies a unidirectional transformation and belongs to the compiler domain rather than MDE, so the move to injectors was undoubtedly a step in the right direction. Alas, as the release notes tried to explain then (section "Rename injection to codec"), we could not settle on this term because Dogen's injectors did not behave like "proper" MDE injectors, as defined in the MDE companion notes (p. 32):
In [Béz+03], Bézivin et al. outlines their motivation [for the creation of Technical Spaces (TS)]: ”The notion of TS allows us to deal more efficiently with the ever-increasing complexity of evolving technologies. There is no uniformly superior technology and each one has its strong and weak points.” The idea is then to engineer bridges between technical spaces, allowing the importing and exporting of artefacts across them. These bridges take the form of adaptors called ”projectors”, as Bézivin explains (emphasis ours):
The responsibility to build projectors lies in one space. The rationale to define them is quite simple: when one facility is available in another space and that building it in a given space is economically too costly, then the decision may be taken to build a projector in that given space. There are two kinds of projectors according to the direction: injectors and extractors. Very often we need a couple of injector/extractor [(sic.)] to solve a given problem. [Béz05a]
In other words, injectors are meant to be transforms responsible for projecting elements from one TS into another. Our "injectors" behaved like real injectors in some cases (e.g. Dia), but there were also extractors in the mix (e.g. PlantUML) and even "injector-extractors" too (e.g. JSON, org-mode). Calling this motley projector set "injectors" was a bit of a stretch, and maybe even contrary to the Domain Architecture clean up, given its responsibility for aligning Dogen source code and MDE vocabulary. After wrecking our brains for a fair bit, we decided "codec" sufficed as a stop-gap alternative:
A codec is a device or computer program that encodes or decodes a data stream or signal. Codec is a portmanteau [a blend of words in which parts of multiple words are combined into a new word] of coder/decoder. [Source: Wikipedia]
As this definition implies, the term belongs to the Audio/Video domain so its use never felt entirely satisfying; but, try as we might, we could not come up with a better of way of saying "injection and extraction" in one word, nor had anyone — to our knowledge — defined the appropriate portemanteau within MDE's canon. The alert reader won't fail to notice this is a classic case of a design smell, and so did we, though it was hard to pinpoint what hid behind the smell. Since development life is more than interminable discussions on terminology, and having more than exhausted the allocated resources for this matter, a line was drawn: "codec" was to remain in place until something better came along. So things stood at the start of the sprint, in this unresolved state.
Then, whilst dabbling on some apparently unrelated matters, the light bulb moment finally arrived; and when we fully grasped all its implications, the fallout was much bigger than just a component rename. To understand why it was so, it's important to remember that MASD theory set in stone the very notion of "injection from multiple sources" via the pervasive integration principle — the second of the methodology's six core values. I shan't bother you too much with the remaining five principles, but it is worth reading Principle 2 in full to contextualise our decision making. The PhD thesis (p. 61) states:
Principle 2: MASD adapts to users’ tools and workflows, not the converse. Adaptation is achieved via a strategy of pervasive integration.
MASD promotes tooling integration: developers preferred tools and workflows must be leveraged and integrated with rather than replaced or subverted. First and foremost, MASD’s integration efforts are directly aligned with its mission statement (cf. Section 5.2.2 [Mission Statement]) because integration infrastructure is understood to be a key source of SRPPs [Schematic and Repetitive Physical Patterns]. Secondly, integration efforts must be subservient to MASD’s narrow focus [Principle 1]; that is, MASD is designed with the specific purpose of being continually extended, but only across a fixed set of dimensions. For the purposes of integration, these dimensions are the projections in and out of MASD’s TS [Technical Spaces], as Figure 5.2 illustrates.
 Figure 1 [orginaly 5.2]: MASD Pervasive integration strategy.
Figure 1 [orginaly 5.2]: MASD Pervasive integration strategy.
Within these boundaries, MASD’s integration strategy is one of pervasive integration. MASD encourages mappings from any tools and to any programming languages used by developers — provided there is sufficient information publicly available to create and maintain those mappings, and sufficient interest from the developer community to make use of the functionality. Significantly, the onus of integration is placed on MASD rather than on the external tools, with the objective of imposing minimal changes to the tools themselves. To demonstrate how the approach is to be put in practice, MASD’s research includes both the integration of org-mode (cf. Chapter 7), as well as a survey on the integration strategies of special purpose code generators (Craveiro, 2021d [available here]); subsequent analysis generalised these findings so that MASD tooling can benefit from these integration strategies. Undertakings of a similar nature are expected as the tooling coverage progresses.
Whilst in theory this principle sounds great, and whilst we still agree wholeheartedly with it in spirit, there are a few practical problems with its current implementation. The first, which to be fair is already hinted at above, is that you need to have an interested community maintaining the injectors into MASD's TS. That is because, even with decent test coverage, it's very easy to break existing workflows when adding new functionality, and the continued maintenance of the tests is costly. Secondly, many of these formats evolve over time, so one needs to keep up-to-date with tooling to remain relevant. Thirdly, as we add formats we will inevitably pickup more and more external dependencies, resulting in a bulking up of Dogen's core only to satisfy some possibly peripheral use case. Finally, each injector adds a large cognitive load because, as we do changes, we now need to revisit all injectors and see how they map to each representation. Advanced mathematics is not required to see that the velocity of coding is an inverse function of the number of injectors; simple extrapolation shows a future where complexity goes through the roof and development slows down to a crawl. The obviousness of this conclusion does leave one wondering why it wasn't spotted earlier. Turns out we had looked into it but the analysis was naively hand-waved away during our PhD research by means of one key assumption: we posited the existence of a "native" format for modeling, whose scope would be a super-set of all functionality required by MASD. XMI was the main contender, and we even acquired Mastering XMI: Java Programming with the XMI Toolkit, XML and UML (OMG) for this purpose. In this light, mappings were seen as trivial-ish functions to well defined structural patterns, rather than an exploration of an open-ended space. Turns out this assumption was misplaced.
To make matters worse, the more we used org-mode in anger, the more we compared its plasticity to all other formats. Soon, a very important question emerged: what if org-mode is the native format for MASD? That is to say, given our experience with the myriad of input formats (including Dia, JSON, XMI and others), what if org-mode is the format which best embodies MASD's approach to Literate Modeling? Thus far, it certainly has proven to be the format with the lowest impedance mismatch to our conceptual model. And we could already see how the future would play out by looking at some of the stories in this release: there were obvious ways in which to simplify the org-mode representation (with the objective of improving PlantUML output), but these changes lacked an obvious mapping to other codecs such as Dia and JSON. They could of course be done, but in ways that would increase complexity across the board for other codecs. If to this you add resourcing constraints, then it makes sense to refocus the mission and choose a single format as the native MASD input format. Note that it does not mean we are abandoning Principle 2 altogether; one can envision separate repos for tools with mapping code that translates from a specific input format into org-mode, and these can even be loaded into the Dogen binary as shared objects via a plugin interface a-la Boost.DLL. In this framework, each format becomes the responsibility of a specific maintainer with its own plugin and set of tests — all of which exogenous to Dogen's core responsibilities — but still falling under the broader MASD umbrella. Most important of all, they can safely be ignored until such time concrete use cases arrive.
 Figure 2: After a decade and a half of continuous usage, Dia stands down - for now.
Figure 2: After a decade and a half of continuous usage, Dia stands down - for now.
Whilst the analysis required its fair share of white-boarding, the resulting action items did not; they were dealt with swiftly at the sprint's death. Post implementation, we could not help but notice its benefits are even broader than originally envisioned because a lot of the complexity in the codec model was related to supporting bits of functionality for disparate codecs. In addition, we trimmed down dependencies to libxml and zlib, and removed a lot of testing infrastructure — including the deletion of the infamous "frozen" repo described in Sprint 30. It was painful to see Dia going away, having used it for over a decade (Figure 2). Alas, one can ill afford to be sentimental with code bases, lest they rot and become an unmaintainable ball of mud. The dust has barely settled, but it already appears we are converging closer to the original vision of injection (Figure 3); next sprint we'll continue to work out the implications of this change, such as moving PlantUML output to regular code generation. If that is indeed doable, it'll be a major breakthrough in regularising the code base.
 Figure 3: The Dogen pipeline, circa Sprint 12.
Figure 3: The Dogen pipeline, circa Sprint 12.
Those still paying attention will not fail to see a symmetry between injectors and extractors. In other words, as we increase Dogen's coverage across TS — adding more and more languages, and more and more functionality in each language — we will suffer from a similar complexity explosion to what was described above for injection. However, several mitigating factors come to our rescue, or so we hope. First, whilst injectors are at the mercy of the tooling, which changes often, extractors depend on programming language specifications, idioms and libraries. These change too but not quite as often. The problem is worse for libraries, of course, as these do get released often, but not quite as bad for the programming language itself. Secondly, there is an expectation of backwards compatibility when programming languages change, meaning we can get away with being stale for longer; and for libraries, we should clearly state which versions we support. Existing versions will not bit-rot, though we may be a bit stale with regards to latest-and-greatest. I guess, as it was with injectors, time will tell how well these assumptions hold up.
Improve note placement in PlantUML for namespaces
A minor user facing change was the improvement on how we generate PlantUML notes for namespaces. In the past these were generated as follows:
namespace entities #F2F2F2 {
note top of variability
Houses all of the meta-modeling elements related to variability.
end note
The problem with this approach is that the notes end up floating above the namespace with an arrow, making it hard to read. A better approach is a floating note:
namespace entities #F2F2F2 {
note variability_1
Houses all of the meta-modeling elements related to variability.
end note
The note is now declared inside the namespace. To ensure the note has a unique name, we simply append the note count.
A second, somewhat related change is the removal of indentation on notes:
note as transforms_1
Top-level transforms for Dogen. These are the entry points to all
transformations.
end note
Sadly, though it makes PlantUML output a fair bit uglier, this change was needed because indentation spacing is included in the output of PlantUML. Notes now look better — i.e., un-indented — though of course the input PlantUML script did suffer. These are the trade-offs one must make.
Change PlantUML's layout engine
Strictly speaking, this change is not user facing per se — in other words, nothing will change for users, unless they follow the same approach as Dogen. However, as it has had a major impact in the readability of our PlantUML diagrams, we believe it's worth shouting about. Anyway, to cut a long story short: we played a bit with different layout engines this sprint, as part of our efforts in making PlantUML diagrams more readable. In the end we settled on ELK, the Eclipse Layout Kernel. If you are interested, we were greatly assisted in our endeavours by the PlantUML community:
- Alternative layout engines from graphviz #1110
- Class diagrams: how to make best use of space in large diagrams #1187
The change itself is fairly minor from a Dogen perspective, e.g. in CMake we added:
message(STATUS "Found PlantUML: ${PLANTUML_PROGRAM}")
set(WITH_PLANTUML "on")
set(PLANTUML_ENVIRONMENT PLANTUML_LIMIT_SIZE=65536 PLANTUML_SECURITY_PROFILE=UNSECURE)
set(PLANTUML_OPTIONS -Playout=elk -tsvg)
The operative part being -Playout=elk. Whilst it did not solve all of our woes, it certainly made diagrams a tad neater as Figure 4 attests.
 Figure 4: Codec model in PlantUML with the ELK layout.
Figure 4: Codec model in PlantUML with the ELK layout.
Note also that you need to install the ELK jar, as per instructions in the PlantUML site.
Development Matters
In this section we cover topics that are mainly of interest if you follow Dogen development, such as details on internal stories that consumed significant resources, important events, etc. As usual, for all the gory details of the work carried out this sprint, see the sprint log. As usual, for all the gory details of the work carried out this sprint, see the sprint log.
Milestones and Éphémérides
There were no particular events to celebrate.
Significant Internal Stories
This was yet another sprint focused on internal engineering work, completing the move to the new CI environment that was started in Sprint 31. This work can be split into three distinct epics: continuous builds, nightly builds and general improvements. Finally, we also spent a fair bit of time improving PlantUML diagrams.
CI Epic 1: Continuous Builds
The main task this sprint was to get the Reference Products up to speed in terms of Continuous builds. We also spent some time ironing out messaging coming out of CI.
 Figure 5: Continuous builds for the C++ Reference Product.
Figure 5: Continuous builds for the C++ Reference Product.
The key stories under this epic can be summarised as follows:
- Add continuous builds to C++ reference product: CI has been restored to the C++ reference product, via github workflows.
- Add continuous builds to C# reference product: CI has been restored to the C# reference product, via github workflows.
- Gitter notifications for builds are not showing up: some work was required to reinstate basic Gitter support for GitHub workflows. It the end it was worth it, especially because we can see everything from within Emacs!
-
Create a GitHub account for MASD BOT: closely related to the previous story, it was a bit annoying to have the GitHub account writing messages to gitter as oneself because you would not see these (presumably the idea being that you sent the message yourself, so you don't need to see it twice). Turns out its really easy to create a github account for a bot, just use your existent email address and add
+something, for example+masd-bot. With this we now see the messages as coming from the MASD bot.
CI Epic 2: Nightly Builds
This sprint was focused on bringing Nightly builds up-to-speed. The work was difficult due to the strange nature of our nightly builds. We basically do two types things with our nightlies:
- run valgrind on the existing CI, to check for any memory issues. In the future one can imagine adding fuzzing etc and other long running tasks that are not suitable for every commit.
- perform a "full generation" for all Dogen code, called internally "fullgen". This is a setup whereby we generate all facets across physical space, even though many of them are disabled for regular use. It serves as a way to validate that we generate good code. We also generate tests for these facets. Ideally we'd like to valgrind all of this code too.
At the start of this sprint we were in a bad state because all of the changes done to support CI in GitHub didn't work too well with our current setup. In addition, because nightlies took too long to run on Travis, we were running them on our own PC. Our first stab was to simply move nightlies into GitHub workflow. We soon found out that a naive approach would burst GitHub limits, generous as they are, because fullgen plus valgrind equal a long time running tests. Eventually we settled on the final approach of splitting fullgen from the plain nightly. This, plus the deprecation of vast swathes of the Dogen codebase meant that we could run fullgen.
 Figure 6: Nightly builds for Dogen.
Figure 6: Nightly builds for Dogen. fg stands for fullgen.
In terms of detail, the following stories were implemented to get to the bottom of this epic:
- Improve diffing output in tests: It was not particularly clear why some tests were failing on nightlies but passing on continuous builds. We spent some time making it clearer.
- Nightly builds are failing due to missing environment var: A ridiculously large amount of time was spent in understanding why the locations of the reference products were not showing up in nightly builds. In the end, we ended up changing the way reference products are managed altogether, making life easier for all types of builds. See this story under "General Improvements".
- Full generation support in tests is incorrect: Nightly builds require "full generation"; that is to say, generating all facets across physical space. However, there were inconsistencies on how this was done because our unit tests relied on "regular generation".
- Tests failing with filesystem errors: yet another fallout of the complicated way in which we used to do nightlies, with lots of copying and moving of files around. We somehow managed to end up in a complex race condition when recreating the product directories and initialising the test setup. The race condition was cleaned up and we are more careful now in how we recreate the test data directories.
- Add nightly builds to C++ reference product: We are finally building the C++ reference implementation once more.
- Investigate nightly issues: this was an hilarious problem: we were still running nightlies on our desktop PC, and after a Debian update they stopped appearing. Reason: for some reason sleep mode was set to a different default and the PC was now falling asleep after a certain time without use. However, the correct solution is to move to GitHub and not depend on local PCs so we merely deprecated local nightlies. It also saves on electricity bills, so it was a double win.
- Create a nightly github workflow: as per the previous story, all nightlies are now in GitHub! this is both for "plain" nightlies as well as "fullgen" builds, with full CDash integration.
- Run nightlies only when there are changes: we now only build nightlies if there was a commit in the previous 24 hours, which hopefully will make GitHub happier.
- Consider creating nightly branches: with the move to GitHub actions, it made sense to create a real branch that is persisted in GitHub rather than a temporary throw away one. This is because its very painful to investigate issues: one has to recreate the "fullgen" code first, then redo the build, etc. With the new approach, the branch for the current nightly is created and pushed into GitHub, and then the nightly runs off of it. This means that, if the nightly fails, one simply has to pull the branch and build it locally. Quality of life improved dramatically.
- Nightly builds are taking too long: unfortunately, we burst the GitHub limits when running fullgen builds under valgrind. This was a bit annoying because we really wanted to see if all of the generated code was introducing some memory issues, but alas it just takes too long. Anyways, as a result of this, and as alluded to in other stories, we split "plain" nightlies from "fullgen" nightlies, and used valgrind only on plain nightlies.
CI Epic 3: General Improvements
Some of the work did not fall under Continuous or Nightly builds, so we are detailing it here:
- Update boost to latest in vcpkg: Dogen is now using Boost v1.80. In addition, given how trivial it is to update dependencies, we shall now perform an update at the start of every new sprint.
- Remove deprecated uses of boost bind: Minor tidy-up to get rid of annoying warnings that resulted from using latest Boost.
- Remove uses of mock configuration factory: as part of the tidy-up around configuration, we rationalised some of the infrastructure to create configurations.
- Cannot access binaries from release notes: annoyingly it seems the binaries generated on each workflow are only visible to certain GitHub users. As a mitigation strategy, for now we are appending the packages directly to the release note. A more lasting solution is required, but it will be backlogged.
- Enable CodeQL: now that LGTM is no more, we started looking into its next iteration. First bits of support have been added via GitHub actions, but it seems more is required in order to visualise its output. Sadly, as this is not urgent, it will remain on the backlog.
- Code coverage in CDash has disappeared: as part of the CI work, we seemed to have lost code coverage. It is still not clear why this was happening, but after some other changes, the code coverage came back. Not ideal, clearly there is something stochastic somewhere on our CTest setup but, hey-ho, nothing we can do until the problem resurfaces.
- Make reference products git sub-modules: in the past we had a complicated set of scripts that downloaded the reference products, copied them to well-known locations and so on. It was... not ideal. As we had already mentioned in the previous release, it also meant we had to expose end users to our quirky directory structure because the CMake presets are used by all. With this release we had a moment of enlightenment: what if the reference products were moved to git submodules? We've had such success with vcpkg in the previous sprint that it seemed like a no-brainer. And indeed it was. We are now not exposing any of the complexities of our own personal choices in directory structures, and due to the magic of git, the specific version of the reference product is pinned on the commit and commited into git. This is a much better approach altogether.
 Figure 7: Reference products are now git sub-modules of Dogen.
Figure 7: Reference products are now git sub-modules of Dogen.
PlantUML Epic: Improvements to diagrams of Dogen models
Our hope was to resume the fabled PMM refactor this sprint. However, as we tried using the PlantUML diagrams in anger, it was painfully clear we couldn't see the class diagram for the classes, if you pardon the pun. To be fair, smaller models such as codec, identification and so on had diagrams that could be readily understood; but key diagrams such as those for the logical and text models are in an unusable state. So it was that, before we could get on with real coding, we had to make the diagrams at least "barely usable", to borrow Ambler's colourful expression [Ambler, Scott W (2007). “Agile Model driven development (AMDD)]". In the previous sprint we had already added a simple way to express relationships, like so:
** Taggable :element:
:PROPERTIES:
:custom_id: 8BBB51CE-C129-C3D4-BA7B-7F6CB7C07D64
:masd.codec.stereotypes: masd::object_template
:masd.codec.plantuml: Taggable <|.. comment
:END:
Any expression under masd.codec.plantuml is transported verbatim to the PlantUML diagram. We decided to annotate all Dogen models with such expressions to see how that would impact diagrams in terms of readability. Of course, the right thing would be to automate such relationships but, as per previous sprint's discussions, this is easier said than done: you'd move from a world of no relationships to a world of far too many relationships, making the diagram equally unusable. So hand-holding it was. This, plus the move to ELK as explained above allowed us to successfully update a large chunk of Dogen models:
-
dogen -
dogen.cli -
dogen.codec -
dogen.identification -
dogen.logical -
dogen.modeling -
dogen.orchestration -
dogen.org -
dogen.physical
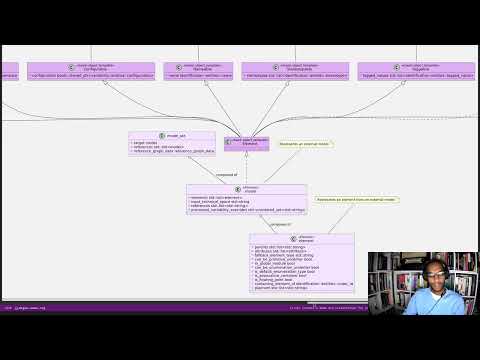
However, we hit a limitation with dogen.text. The model is just too unwieldy in its present form. Part of the problem stems from the fact that there are just no relations to add: templates are not related to anything. So, by default, PlantUML makes one long (and I do mean long) line. Here is a small fragment of the model:
 Figure 8: Partial representation of Dogen's text model in PlantUML.
Figure 8: Partial representation of Dogen's text model in PlantUML.
Tried as we might we could not get this model to work. Then we noticed something interesting: some parts of the model where classes are slightly smaller were being rendered in a more optimal way, as you can see in the picture above; smaller classes cluster around a circular area whereas very long classes are lined up horizontally. We took our findings to PlantUML:
We are still investigating what can be done from a PlantUML perspective, but it seems having very long stereotypes is confusing the layout engine. Reflecting on this, it seems this is also less readable for humans too. For example:
**** builtin header :element:
:PROPERTIES:
:custom_id: ED36860B-162A-BB54-7A4B-4B157F8F7846
:masd.wale.kvp.containing_namespace: text.transforms.hash
:masd.codec.stereotypes: masd::physical::archetype, dogen::builtin_header_configuration
:END:
Using stereotypes in this manner is a legacy from Dia, because that is what is expected of a UML diagram. However, since org-mode does not suffer from these constraints, it seemed logical to create different properties to convey different kinds of information. For instance, we could split out configurations into its own entry:
**** enum header :element:
:PROPERTIES:
:custom_id: F2245764-7133-55D4-84AB-A718C66777E0
:masd.wale.kvp.containing_namespace: text.transforms.hash
:masd.codec.stereotypes: masd::physical::archetype
:masd.codec.configurations: dogen::enumeration_header_configuration
:END:
And with this, the mapping into PlantUML is also simplified, since perhaps the configurations are not needed from a UML perspective. Figure 9 shows both of these approaches side by side:
 Figure 9: Removal of some stereotypes.
Figure 9: Removal of some stereotypes.
Next sprint we need to update all models with this approach and see if this improves diagram generation.
This epic was composed of a number of stories, as follows:
- Add PlantUML relationships to diagrams: manually adding each relationship to each model was a lengthy (and somewhat boring) operation, but improved the generated diagrams dramatically.
- Upgrade PlantUML to latest: it seems latest is always greatest with PlantUML, so we spent some time understanding how we can manually update it rather than depend on the slightly older version in Debian. We ended up settling on a massive hack, just drop the JAR in the same directory as the packaged version and then symlink it. Not great, but it works.
- Change namespaces note implementation in PlantUML: See user visible stories above.
- Consider using a different layout engine in PlantUML: See user visible stories above.
Video series of Dogen coding
We have been working on a long standing series of videos on the PMM refactor. However, as you probably guessed, they have had nothing to do with refactoring with the PMM so far, because the CI/CD work has dominated all our time for several months now. To make matters more confusing, we had recorded a series of videos on CI previously (MASD - Dogen Coding: Move to GitHub CI), but in an extremely optimistic step, we concluded that series because we thought the work that was left was fairly trivial — famous last words, hey. If that wasn't enough, our Debian PC has been upgraded to Pipewire which — whilst a possibly superior option to Pulse Audio — lacks a noise filter that we can work with.
To cut a long and somewhat depressing story short, our videos were in a big mess and we didn't quite know how to get out of it. So this sprint we decided to start from a clean slate:
- the existing series on PMM refactor was renamed to "MASD - Dogen Coding: Move to GitHub Actions". It seems best rather than append these 3 videos to the existing "MASD - Dogen Coding: Move to GitHub CI" playlist because it would probably make it even more confusing.
- we... well, completed it as is, even though it missed all of the work in the previous sprint. This is just so we can get it out of the way. I guess once noise-free sound is working again we could add an addendum and do a quick tour of our new CI/CD infrastructure, but given our present time constraints it is hard to tell when that will be.
Anyways, hopefully all of that makes some sense. Here are the videos we recorded so far.
 Video 2: Playlist for "MASD - Dogen Coding: Move to GitHub Actions".
Video 2: Playlist for "MASD - Dogen Coding: Move to GitHub Actions".
The table below shows the individual parts of the video series.
| Video | Description |
|---|---|
| Part 1 | In this video we start off with some boring tasks left over from the previous sprint. In particular, we need to get nightlies to go green before we can get on with real work. |
| Part 2 | This video continues the boring work of sorting out the issues with nightlies and continuous builds. We start by revising what had been done offline to address the problems with failing tests in the nightlies and then move on to remove the mock configuration builder that had been added recently. |
| Part 3 | With this video we finally address the remaining CI problems by adding GitHub Actions support for the C# Reference Product. |
Table 1: Video series for "MASD - Dogen Coding: Move to GitHub Actions".
With a bit of luck, regular video service will be resumed next sprint.
Resourcing
The resourcing picture is, shall we say, nuanced. On the plus side, utilisation is down significantly when compared to the previous sprint — we did take four months this time round instead of a couple of years, so that undoubtedly helped. On the less positive side, we still find ourselves well outside the expected bounds for this particular metric; given a sprint is circa 80 hours, one would expect to clock that much time in a month or two of side-coding. We are hoping next sprint will compress some of the insane variability we have experienced of late with regards to the cadence of our sprints.
 Figure 10: Cost of stories for sprint 32.
Figure 10: Cost of stories for sprint 32.
The per-story data forms an ever so slightly flatterer picture. Around 23% of the overall spend was allocated towards non-coding tasks such as writing the release notes (~12.5%), backlog refinement (~8%) and demo related activities. Worrying, it was up around 5% from the previous sprint, which was itself already an extremely high number historically. Given the resource constraints, it would be wise to compress time spent on management activities such as these to free up time for actual work, and buck the trend of these two or three sprints. However, the picture is not quite as clear cut as it may appear since release notes are becoming more and more a vehicle for reflection, both on the activities of the sprint (post mortem) but also taking on a more philosophical, and thus broader, remit. Given no further academic papers are anticipated, most of our literature reflections are now taking place via this medium. In this context, perhaps the high cost on the release notes is worth its price.
With regards t the meat of the sprint: engineering activities where bucketed into three main topics, with CI/CD taking around 30% of the total ask (22% for Nightlies and 10% for Continuous), roughly 30% taken on PlantUML work and the remaining 15% used in miscellaneous engineering activities — including a fair portion of analysis on the "native" format for MASD. This was certainly time well-spent, even though we would have preferred to conclude CI work quicker. All and all, it was a though but worthwhile sprint, which marks the end of the PhD era and heralds the start of the new "open source project on the side era".
Roadmap
With Sprint 32 we decided to decommission the Project Roadmap. It had served us well up to the end of the PhD as it was a useful, if albeit vague, forecasting device for what was to come up in the short to medium term. Now that we have finished commitments with firm dead lines we can rely on a pure agile approach and see where each sprint takes us. Besides, it is one less task to worry about when writing up the release notes. The road map started initially in Sprint 14, so it has been with us just shy of four years.
Binaries
Binaries for the present release are available in Table 2.
| Operative System | Binaries |
|---|---|
| Linux Debian/Ubuntu | dogen_1.0.32_amd64-applications.deb |
| Windows | DOGEN-1.0.32-Windows-AMD64.msi |
| Mac OSX | DOGEN-1.0.32-Darwin-x86_64.dmg |
Table 2: Binary packages for Dogen.
A few important notes:
- Linux: the Linux binaries are not stripped at present and so are larger than they should be. We have an outstanding story to address this issue, but sadly CMake does not make this a trivial undertaking.
- OSX and Windows: we are not testing the OSX and Windows builds (e.g. validating the packages install, the binaries run, etc.). If you find any problems with them, please report an issue.
- 64-bit: as before, all binaries are 64-bit. For all other architectures and/or operative systems, you will need to build Dogen from source. Source downloads are available in zip or tar.gz format.
- Assets on release note: these are just pictures and other items needed by the release note itself. We found that referring to links on the internet is not a particularly good idea as we now have lots of 404s for older releases. Therefore, from now on, the release notes will be self contained. Assets are otherwise not used.
Next Sprint
Now that we are finally out of the woods of CI/CD engineering work, expectations for the next sprint are running high. We may actually be able to devote most of the resourcing towards real coding. Having said that, we still need to mop things up with the PlantUML representation, which will probably not be the most exciting of tasks.
That's all for this release. Happy Modeling!
v1.0.31
1 year ago Graduation day for the PhD programme of Computer Science at the University of Hertfordshire, UK. (C) 2022 Shahinara Craveiro.
Graduation day for the PhD programme of Computer Science at the University of Hertfordshire, UK. (C) 2022 Shahinara Craveiro.
Introduction
After an hiatus of almost 22 months, we've finally managed to push another Dogen release out of the door. Proud of the effort as we are, it must be said it isn't exactly the most compelling of releases since the bulk of its stories are related to basic infrastructure. More specifically, the majority of resourcing had to be shifted towards getting Continuous Integration (CI) working again, in the wake of Travis CI's managerial changes. However, the true focus of the last few months lays outside the bounds of software engineering; our time was spent mainly on completing the PhD thesis, getting it past a myriad of red-tape processes and perhaps most significantly of all, on passing the final exam called the viva. And so we did. Given it has taken some eight years to complete the PhD programme, you'll forgive us for the break with the tradition in naming releases after Angolan places or events; regular service will resume with the next release, on this as well as on the engineering front <knocks on wood, nervously>. So grab a cupper, sit back, relax, and get ready for the release notes that mark the end of academic life in the Dogen project.
User visible changes
This section covers stories that affect end users, with the video providing a quick demonstration of the new features, and the sections below describing them in more detail. The demo spends some time reflecting on the PhD programme overall.
 Video 1: Sprint 31 Demo.
Video 1: Sprint 31 Demo.
Deprecate support for dumping tracing to a relational database
It wasn't that long ago Dogen was extended to dump tracing information into relational databases such as PostgreSQL and their ilk. In fact, v1.0.20's release notes announced this new feature with great fanfare, and we genuinely had high hopes for its future. You are of course forgiven if you fail to recall what the fuss was all about, so it is perhaps worthwhile doing a quick recap. Tracing - or probing as it was known then - was introduced in the long forgotten days of Dogen v1.0.05, the idea being that it would be useful to inspect model state as the transform graph went through its motions. Together with log files, this treasure trove of information enabled us to quickly understand where things went wrong, more often than not without necessitating a debugger. And it was indeed incredibly useful to begin with, but we soon got bored of manually inspecting trace files. You see, the trouble with these crazy critters is that they are rather plump blobs of JSON, thus making it difficult to understand "before" and "after" diffs for the state of a given model transform - even when allowing for json-diff and the like. To address the problem we doubled-down on our usage of JQ, but the more we did so, the clearer it became that JQ queries competed in the readability space with computer science classics like regular expressions and perl. A few choice data points should give a flavour of our troubles:
# JQ query to obtain file paths:
$ jq .models[0].physical.regions_by_logical_id[0][1].data.artefacts_by_archetype[][1].data.data.file_path
# JQ query to sort models by elements:
$ jq '.elements|=sort_by(.name.qualified)'
# JQ query for element names in generated model:
$ jq ."elements"[]."data"."__parent_0__"."name"."qualified"."dot"
It is of course deeply unfair to blame JQ for all our problems, since "meaningful" names such as __parent_0__ fall squarely within Dogen's sphere of influence. Moreover, as a tool JQ is extremely useful for what it is meant to do, as well as being incredibly fast at it. Nonetheless, we begun to accumulate more and more of these query fragments, glued them up with complex UNIX shell pipelines that dumped information from trace files into text files, and then dumped diffs of said information to other text files which where then... - well, you get the drift. These scripts were extremely brittle and mostly "one-off" solutions, but at least the direction of travel was obvious: what was needed was a way to build up a number of queries targeting the "before" and "after" state of any given transform, such that we could ask a series of canned questions like "has object x0 gone missing in transform t0?" or "did we update field f0 incorrectly in transform t0?", and so on. One can easily conceive that a large library of these queries would accumulate over time, allowing us to see at a glance what changed between transforms and, in so doing, make routine investigations several orders of magnitude faster. Thus far, thus logical. We then investigated PostgreSQL's JSON support and, at first blush, found it to be very comprehensive. Furthermore, given that Dogen always had basic support for ODB, it was "easy enough" to teach it to dump trace information into a relational database - which we did in the aforementioned release.
Alas, after the initial enthusiasm, we soon realised that expressing our desired questions as database queries was far more difficult than anticipated. Part of it is related to the complex graph that we have on our JSON documents, which could be helped by creating a more relational-database-friendly model; and part of it is the inexperience with PostgreSQL's JSON query extensions. Sadly, we do not have sufficient time address either question properly, given the required engineering effort. To make matters worse, even though it was not being used in anger, the maintenance of this code was become increasingly expensive due to two factors:
- its reliance on a beta version of ODB (v2.5), for which there are no DEBs readily available; instead, one is expected to build it from source using Build2, an extremely interesting but rather suis generis build tool; and
- its reliance on either a manual install of the ODB C++ libraries or a patched version of vcpkg with support for v2.5. As vcpkg undergoes constant change, this means that every time we update it, we then need to spend ages porting our code to the new world.
Now, one of the rules we've had for the longest time in Dogen is that, if something is not adding value (or worse, subtracting value) then it should be deprecated and removed until such time it can be proven to add value. As with any spare time project, time is extremely scarce, so we barely have enough of it to be confused with the real issues at hand - let alone speculative features that may provide a pay-off one day. So it was that, with great sadness, we removed all support for the relational backend on this release. Not all is lost though. We use MongoDB a fair bit at work, and got the hang of its query language. A much simpler alternative is to dump the JSON documents into MongoDB - a shell script would do, at least initially - and then write Mongo queries to process the data. This is an approach we shall explore next time we get stuck investigating an issue using trace dumps.
Add "verbatim" PlantUML extension
The quality of our diagrams degraded considerably since we moved away from Dia. This was to be expected; when we originally added PlantUML support in the previous release, it was as much a feasibility study as it was the implementation of a new feature. The understanding was that we'd have to spend a number of sprints slowly improving the new codec, until its diagrams where of a reasonable standard. However, this sprint made two things clear: a) just how much we rely on these diagrams to understand the system, meaning we need them back sooner rather than later; and b) just how much machinery is required to properly model relations in a rich way, as was done previously. Worse: it is not necessarily possible to merely record relations between entities in the input codec and then map those to a UML diagram. In Dia, we only modeled "significant relations" in order to better convey meaning. Lets make matters concrete by looking at a vocabulary type such as entities::name in model dogen::identification. It is used throughout the whole of Dogen, and any entity with a representation in the LPS (Logical-Physical Space) will use it. A blind approach of modeling each and every relation to a core type such as this would result in a mess of inter-crossing lines, removing any meaning from the resulting diagram.
After a great deal of pondering, we decided that the PlantUML output needs two kinds of data sources: automated, where the relationship is obvious and uncontroversial - e.g. the attributes that make up a class, inheritance, etc.; and manual, where the relationship requires hand-holding by a human. This is useful for example in the above case, where one would like to suppress relationships against a basic vocabulary type. The feature was implemented by means of adding a PlantUML verbatim attribute to models. It is called "verbatim" because we merely cut and paste the field's content into the PlantUML representation. By convention, these statements are placed straight after the entity they were added to. It is perhaps easier to understand this feature by means of an example. Say in the dogen.codec model one wishes to add a relationship between model and element. One could go about it as follows:
 Figure 1: Use of the verbatim PlantUML property in the
Figure 1: Use of the verbatim PlantUML property in the dogen.codec model.
As you can see, the property masd.codec.plantuml is extremely simple: it merely allows one to enter valid PlantUML statements, which are subsequently transported into the generated source code without modification, e.g.:
 Figure 2: PlantUML source code for
Figure 2: PlantUML source code for dogen.codec model.
For good measure, we can observe the final (graphical) output produced by PlantUML in Figure 3, with the two relations, and compare it with the old Dia representation (Figure 4). Its worth highlighting a couple of things here. Firstly - and somewhat confusingly - in addition to element, the example also captures a relationship with the object template Element. It was left on purpose as it too is a useful demonstration of this new feature. Note that it's still not entirely clear whether this is the correct UML syntax for modeling relationships with object templates - the last expert I consulted was not entirely pleased with this approach - but no matter. The salient point is not whether this specific representation is correct or incorrect, but that one can choose to use this or any other representation quite easily, as desired. Secondly and similarly, the aggregation between model_set, model and element is something that one would like to highlight in this model, and it is possible to do so trivially by means of this feature. Each of these classes is composed of a number of attributes which are not particularly interesting from a relationship perspective, and adding relations for all of those would greatly increase the amount of noise in the diagram.
 Figure 3: Graphical output produced by PlantUML from Dogen-generated sources.
Figure 3: Graphical output produced by PlantUML from Dogen-generated sources.
This feature is a great example of how often one needs to think of a problem from many different perspectives before arriving at a solution; and that, even though the problem may appear extremely complex at the start, sometimes all it takes is to view it from a completely different angle. All and all, the feature was implemented in just over two hours; we had originally envisioned lots of invasive changes at the lowers levels of Dogen just to propagate this information, and likely an entire sprint dedicated to it. To be fair, the jury is not out yet on whether this is really the correct approach. Firstly, because we now need to go through each and every model and compare the relations we had in Dia to those we see in PlantUML, and implement them if required. Secondly, we have no way of knowing if the PlantUML input is correct or not, short of writing a parser for their syntax - which we won't consider. This means the user will only find out about syntax errors after running PlantUML - and given it will be within generated code, it is entirely likely the error messages will be less than obvious as to what is causing the problem. Thirdly and somewhat related: the verbatim nature of this attribute entails bypassing the Dogen type system entirely, by design. This means that if this information is useful for purposes other than PlantUML generation - say for example for regular source code generation - we would have no access to it. Finally, the name masd.codec.plantuml is also questionable given the codec name is plantuml. Next release we will probably name it to masd.codec.plantuml.verbatim to better reflect its nature.
 Figure 4: Dia representation of the
Figure 4: Dia representation of the dogen.codec model.
A possibly better way of modeling this property is to add a non-verbatim attribute such as "significant relationship" or "user important relationship" or some such. Whatever its name, said attribute would model the notion of there being an important relationship between some types within the Dogen type system, and it could then be used by the PlantUML codec to output it in its syntax. However, before we get too carried away, its important to remember that we always take the simplest possible approach first and wait until use cases arrive, so all of this analysis has been farmed off to the backlog for some future use.
Video series on MDE and MASD
In general, we tend to place our YouTube videos under the Development Matters section of the release notes because these tend to be about coding within the narrow confines of Dogen. As with so many items within this release, an exception was made for one of the series because it is likely to be of interest to Dogen developers and users alike. The series in question is called "MASD: An introduction to Model Assisted Software Development", and it is composed of 10 parts as of this writing. Its main objective was to prepare us for the viva, so the long arc of the series builds up to why one would want to create a new methodology and ends with an explanation of what that methodology might be. However, as we were unsure as to whether we could use material directly from the thesis, and given our shortness of time to create new material specifically for the series, we opted for a high-level description of the methodology; in hindsight, we find it slightly unsatisfactory due to a lack of visuals so we are considering an additional 11th part which reviews a couple of key chapters from the thesis (5 and 6).
At any rate, the individual videos are listed on Table 1, with a short description. They are also available as a playlist, as per link below.
 Video 2: Playlist "MASD: An introduction to Model Assisted Software Development".
Video 2: Playlist "MASD: An introduction to Model Assisted Software Development".
| Video | Description |
|---|---|
| Part 1 | This lecture is the start of an overview of Model Driven Engineering (MDE), the approach that underlies MASD. |
| Part 2 | In this lecture we conclude our overview of MDE by discussing the challenges the discipline faces in terms of its foundations. |
| Part 3 | In this lecture we discuss the two fundamental concepts of MDE: Models and Transformations. |
| Part 4 | In this lecture we take a large detour to think about the philosophical implications of modeling. In the detour we discuss Russell, Whitehead, Wittgenstein and Meyers amongst others. |
| Part 5 | In this lecture we finish our excursion into the philosophy of modeling and discuss two core topics: Technical Spaces (TS) and Platforms. |
| Part 6 | In this video we take a detour and talk about research, and how our programme in particular was carried out - including all the bumps and bruises we faced along the way. |
| Part 7 | In this lecture we discuss Variability and Variability Management in the context of Model Driven Engineering (MDE). |
| Part 8 | In this lecture we start a presentation of the material of the thesis itself, covering state of the art in code generation, and the requirements for a new approach. |
| Part 9 | In this lecture we outline the MASD methodology: its philosophy, processes, actors and modeling language. We also discuss the domain architecture in more detail. |
| Part 10 | In this final lecture we discuss Dogen, introducing its architecture. |
Table 1: Video series for "MASD: An introduction to Model Assisted Software Development".
Development Matters
In this section we cover topics that are mainly of interest if you follow Dogen development, such as details on internal stories that consumed significant resources, important events, etc. As usual, for all the gory details of the work carried out this sprint, see the sprint log. As usual, for all the gory details of the work carried out this sprint, see the sprint log.
Milestones and Éphémérides
This sprint marks the end of the PhD programme that started in 2014.
 Figure 5: PhD thesis within the University of Hertfordshire archives.
Figure 5: PhD thesis within the University of Hertfordshire archives.
Significant Internal Stories
From an engineering perspective, this sprint had one goal which was to restore our CI environment. Other smaller stories were also carried out.
Move CI to GitHub actions
A great number of stories this sprint were connected with the epic of returning to a sane world of continuous integration; CI had been lost with the demise of the open source support in Travis CI. First and foremost, I'd like to give an insanely huge shout out to Travis CI for all the years of supporting open source projects, even when perhaps it did not make huge financial sense. Prior to this decision, we had relied on Travis CI quite a lot, and in general it just worked. To my knowledge, they were the first ones to introduce the simple YAML configuration for their IaC language, and it still supports features that we could not map to in our new approach (e.g. the infamous issue #399). So it was not without sadness that we lost Travis CI support and found ourselves needing to move on to a new, hopefully stable, home.
Whilst where at it, a second word of thanks goes out to AppVeyor who we have also used for the longest time, with very few complaints. For many years, AppVeyor have been great supporters of open source and free software, so a massive shout out goes to them as well. Sadly, we had to reconsider AppVeyor's use in the context of Travis CI's loss, and it seemed sensible to stick to a single approach for all operative systems if at all possible. Personally, this is a sad state of affairs because we are choosing to support one large monolithic corporation in detriment of two small but very committed vendors, but as always, the nuances of the decision making process are obliterated by the practicalities of limited resourcing with which to carry work out - and thus a small risk apetite for both the demise of yet another vendor as well as for the complexities that always arrive when dealing with a mix of suppliers.
And so our search begun. As we have support for GitHub, BitBucket and GitLab as Git clones, we considered these three providers. In the end, we settled on GitHub actions, mainly because of the wealth of example projects using C++. All things considered, the move was remarkably easy, though not without its challenges. At present we seem to have all Dogen builds across Linux, Windows and OSX working reliably - though, as always, much work still remains such as porting all of our reference products.
 Figure 6: GitHub actions for the Dogen project.
Figure 6: GitHub actions for the Dogen project.
Related Stories: "Move build to GitHub", "Can't see build info in github builds", "Update the test package scripts for the GitHub CI", "Remove deprecated travis and appveyor config files", "Create clang build using libc++", "Add packaging step to github actions", "Setup MSVC Windows build for debug and release", "Update build instructions in readme", "Update the test package scripts for the GitHub CI", "Comment out clang-cl windows build", "Setup the laptop for development", "Windows package is broken", "Rewrite CTest script to use github actions".
Improvements to vcpkg setup
As part of the move to GitHub actions, we decided to greatly simplify our builds. In the past we had relied on a massive hack: we built all our third party dependencies manually and placed them, as a zip, on DropBox. This worked, but updating these dependencies was a major pain and so done very infrequently. In particular, we often forgot the details on how exactly those builds had been done and where all of the libraries had been sourced. As part of the research on GitHub actions, it became apparent that the cool kids had moved en masse to using vcpkg within the CI itself , and employed a set of supporting actions to make this use case much easier than before (building on the fly, caching, and so on). This new setup is highly advantageous because it makes updating third party dependencies a mere git submodule update, like so:
$ cd vcpkg/
$ git pull origin master
remote: Enumerating objects: 18250, done.
remote: Counting objects: 100% (7805/7805), done.
remote: Compressing objects: 100% (129/129), done.
remote: Total 18250 (delta 7720), reused 7711 (delta 7676), pack-reused 10445
Receiving objects: 100% (18250/18250), 9.05 MiB | 3.07 MiB/s, done.
Resolving deltas: 100% (12995/12995), completed with 1774 local objects.
...
$ cmake --build --preset linux-clang-release --target rat
While we were there, we took this opportunity and simplified all dependencies; sadly this meant removing our use of ODB since v2.5 is not available on vcpkg (see above). The feature is still present on the code generator, but one wonders if it should be completely deprecated next release when we get to the C++ reference product. Boost.DI was also another victim of this clean up. At any rate, the new setup is a productivity improvement of several orders of magnitude, since in the past we had to have our own OSX and Windows Physicals/VM's to build the dependencies whereas now we rely solely on vcpkg. For an idea of just how painful things used to be, just have a peek at "Updating Boost Version" in v1.0.19
Related Stories: "Update vcpkg to latest", "Remove third-party dependencies outside vcpkg", "Update nightly builds to use new vcpkg setup".
Improvements to CTest and CMake scripts
Closely related to the work on vcpkg and GitHub actions was a number of fundamental changes to our CMake and CTest setup. First and foremost, we like to point out the move to use CMake Presets. This is a great little feature in CMake that enables packing all of the CMake configuration into a preset file, and removes the need for the good old build.* scripts that had littered the build directory. It also means that building from Emacs - as well as other editors and IDEs which support presets, of course - is now really easy. In the past we had to supply a number o environment variables and other such incantations to the build script in order to setup the required environment. With presets all of that is encapsulated into a self comntained CMakePresets.json file, making the build much simpler:
cmake --preset linux-clang-release
cmake --build --preset linux-clang-release
You can also list the available presets very easily:
$ cmake --list-presets
Available configure presets:
"linux-clang-debug" - Linux clang debug
"linux-clang-release" - Linux clang release
"linux-gcc-debug" - Linux gcc debug
"linux-gcc-release" - Linux gcc release
"windows-msvc-debug" - Windows x64 Debug
"windows-msvc-release" - Windows x64 Release
"windows-msvc-clang-cl-debug" - Windows x64 Debug
"windows-msvc-clang-cl-release" - Windows x64 Release
"macos-clang-debug" - Mac OSX Debug
"macos-clang-release" - Mac OSX Release
This ensures a high degree of regularity of Dogen builds if you wish to stick to the defaults, which is the case for almost all our use cases. The exception had been nightlies, but as we explain elsewhere, with this release we also managed to make those builds conform to the same overall approach.
The release also saw a general clean up of the CTest script, now called CTest.cmake, which supports both continuous as well as nighly builds with minimal complexity. Sadly, the integration of presets with CTest is not exactly perfect, so it took us a fair amount of time to work out how to best get these two to talk to each other.
Related Stories: "Rewrite CTest script to use github actions", "Assorted improvements to CMake files"
Smaller stories
In addition to the big ticket items, a number of smaller stories was also worked om.
- Fix broken org-mode tests: due to the ad-hoc nature of our org-mode parser, we keep finding weird and wonderful problems with code generation, mainly related to the introduction of spurious whitelines. This sprint we fixed yet another group of these issues. Going forward, the right solution is to remove org-mode support from within Dogen, since we can't find a third party library that is rock solid, and add instead an XMI-based codec. We can then extend Emacs to generate this XMI output. There are downsides to this approach - for example, the loss of support to non-Emacs based editors such as VI and VS Code.
- Generate doxygen docs and add to site: Every so often we update manually the Doxygen docs available on our site. This time we also added a badge linking back to the documentation. Once the main bulk of work is finished with GitHub actions, we need to consider adding an action to regenerate documentation.
- Update build instructions in README*: This sprint saw a raft of updates to our REAMDE file, mostly connected with the end of the tesis as well as all the build changes related to GitHub actions.
- Replace Dia IDs with UUIDs: Now that we have removed Dia models from within Dogen, it seemed appropriate to get rid of some of its vestiges such as Object IDs based on Dia object names. This is yet another small step towards making the org-mode models closer to their native representation. We also begun work on supporting proper capitalisation of org-mode headings ("Capitalise titles in models correctly"), but sadly this proved to be much more complex than expected and has since been returned to the product backlog for further analysis.
- Tests should take full generation into account: Since time immemorial, our nightly builds have been, welll, different, from regular CI builds. This is because we make use of a feature called "full generation". Full generation forces the instantiation of model elements across all facets of physical space regardless of the requested configuration within the user model. This is done so that we exercise generated code to the fullest, and also has the great benefit of valgrinding the generated tests, hopefully pointing out any leaks we may have missed. One major down side of this approach was the need to somehow "fake" the contents of the Dogen directory, to ensure the generated tests did not break. We did this via the "pristine" hack: we kept two checkouts of Dogen, and pointed the tests of the main build towards this printine directory, so that the code geneation tests did not fail. It was ugly but just about worked. That is, until we introduced CMake Presets. Then, it caused all sorts of very annoying issues. In this sprint, after the longest time of trying to extend the hack, we finally saw the obvious: the easiest way to address this issue is to extend the tests to also use full generation. This was very easy to implement and made the nightlies regular with respect to the continuous builds.
Video series of Dogen coding
This sprint we recorded a series of videos titled "MASD - Dogen Coding: Move to GitHub CI". It is somewhat more generic than the name implies, because it includes a lot of the side-tasks needed to make GitHub actions work such as removing third party dependencies, fixing CTest scripts, etc. The video series is available as a playlist, in the link below.
 Video 3: Playlist for "MASD - Dogen Coding: Move to GitHub CI".
Video 3: Playlist for "MASD - Dogen Coding: Move to GitHub CI".
The next table shows the individual parts of the video series.
| Video | Description |
|---|---|
| Part 1 | In this part we start by getting all unit tests to pass. |
| Part 2 | In this video we update our vcpkg fork with the required libraries, including ODB. However, we bump into problems getting Dogen to build with the new version of ODB. |
| Part 3 | In this video we decide to remove the relational model altogether as a way to simplify the building of Dogen. It is a bittersweet decision as it took us a long time to code the relational model, but in truth it never lived up to its original promise. |
| Part 4 | In this short video we remove all uses of Boost DI. Originally, we saw Boost DI as a solution for our dependency injection needs, which are mainly rooted in the registration of M2T (Model to Text) transforms. |
| Part 5 | In this video we update vcpkg to use latest and greatest and start to make use of the new standard machinery for CMake and vcpkg integration such as CMake presets. However, ninja misbehaves at the end. |
| Part 6 | In this part we get the core of the workflow to work, and iron out a lot of the kinks across all platforms. |
| Part 7 | In this video we review the work done so far, and continue adding support for nightly builds using the new CMake infrastructure. |
| Part 8 | This video concludes the series. In it, we sort out the few remaining problems with nightly builds, by making them behave more like the regular CI builds. |
Table 2: Video series for "MASD - Dogen Coding: Move to GitHub CI".
Resourcing
At almost two years elapsed time, this sprint was characterised mainly by its irregularity, and rendered metrics such as utilisation rate completely meaningless. It would of course be an unfair comment if we stopped at that, given how much was achieved on the PhD front; alas, lines of LaTex source count not towards the engineering of software systems. Focusing solely on the engineering front and looking at the sprint as a whole, it must be classified as very productive, since it was just over 85 hours long and broadly achieved its stated mission. It is always painful to spend this much effort just to get back to where we were in terms of CI/CD during the Travis CI golden era, but it is what it is. If anything, our modernised setup is a qualitative step up in terms of functionality when compared to the previous approach, so its not all doom and gloom.
 Figure 7: Cost of stories for sprint 31.
Figure 7: Cost of stories for sprint 31.
In total, we spent just over 57% working on the GitHub CI move. Of these - in fact, of the whole sprint - the most expensive story was rewriting CTest scripts, at almost 16% of total effort. We also spent a lot of time updating nightly builds to use new vcpkg setup and performing assorted improvements to CMake files (9.3% and 7.6% respectively). It was somewhat disappointing that we did not manage to touch the reference products, which are at present still CI-less. Somewhat surprisingly we still managed to spend 13.3% of the total resource ask doing real coding; some of it justified (for example, removing the database options was a requirement for the GitHub CI move because we wanted to drop ODB) and some of it more of a form of therapy given the boredom of working on IaC (Infrastructure as Code). We also clocked just over 11% on working in the MDE and MASD video series, which is more broadly classified as PhD work; since it has an application to the engineering side, it was booked against the engineering work rather than the PhD programme itself.
A final note on the whopping 18.3% consumed on agile-related work. In particular, we spent an uncharacteristically large amount of time refining our sprint and product backlogs: 10% versus the 7% of sprint 30 and the 3.5% of sprint 29. Of course, in the context of thee many months with very little coding, it does make sense that we spent a lot of time dreaming about coding, and that is what the backlogs there are for. At any rate, over 80% of the resourcing this sprint can be said to be aligned with the core mission of the sprint, so one would conclude it was well spent.
Roadmap
We've never been particularly sold on the usefulness of our roadmaps, to be fair, but perhaps for historical reasons we have grown attached to them. There is little to add from the previous sprint: the big ticket items stay unchanged, and given our day release from work for the PhD will cease soon, it is expected that our utilisation rate will start to slow down correspondingly. The roadmap remains the same, nonetheless.


Binaries
As part of the GitHub CI move, the production of binaries has changed considerably. In addition, we are not yet building binaries off of the tag workflow so these links are against the last commit of the sprint - presumably the resulting build would have been identical. For now, we have manually uploaded the binaries into the release assets.
| Operative System | Binaries |
|---|---|
| Linux Debian/Ubuntu | dogen_1.0.31_amd64-applications.deb |
| Windows | DOGEN-1.0.31-Windows-AMD64.msi |
| Mac OSX | DOGEN-1.0.31-Darwin-x86_64.dmg |
Table 3: Binary packages for Dogen.
A few important notes:
- the Linux binaries are not stripped at present and so are larger than they should be. We have an outstanding story to address this issue, but sadly CMake does not make this a trivial undertaking.
- as before, all binaries are 64-bit. For all other architectures and/or operative systems, you will need to build Dogen from source. Source downloads are available in zip or tar.gz format.
- a final note on the assets present on the release note. These are just pictures and other items needed by the release note itself. We found that referring to links on the internet is not a particularly good idea as we now have lots of 404s for older releases. Therefore, from now on, the release notes will be self contained. Assets are otherwise not used.
- we are not testing the OSX and Windows builds (e.g. validating the packages install, the binaries run, etc.). If you find any problems with them, please report an issue.
Next Sprint
The next sprint's mission will focus on mopping up GitHub CI - largely addressing the reference products, which were untouched this sprint. The remaining time will be allocated to the clean up of the physical model and meta-model, which we are very much looking forward to. It will be the first release with real coding in quite some time.
That's all for this release. Happy Modeling!
v1.0.30
3 years ago Municipal stadium in Moçamedes, Namibe, Angola. (C) 2020 Angop.
Municipal stadium in Moçamedes, Namibe, Angola. (C) 2020 Angop.
Introduction
Happy new year! The first release of the year is a bit of a bumper one: we finally managed to add support for org-mode, and transitioned all of Dogen to it. It was a mammoth effort, consuming the entirety of the holiday season, but it is refreshing to finally be able to add significant user facing features again. Alas, this is also a bit of a bitter-sweet release because we have more or less run out of coding time, and need to redirect our efforts towards writing the PhD thesis. On the plus side, the architecture is now up-to-date with the conceptual model, mostly, and the bits that aren't are fairly straightforward (famous last words). And this is nothing new; Dogen development has always oscillated between theory and practice. If you recall, a couple of years ago we had to take a nine-month coding break to learn about the theoretical underpinnings of MDE and then resumed coding on Sprint 8 for what turned out to be a 22-sprint-long marathon (pun intended), where we tried to apply all that was learned to the code base. Sprint 30 brings this long cycle to a close, and begins a new one; though, this time round, we are hoping for far swifter travels around the literature. But lets not get lost talking about the future, and focus instead on the release at hand. And what a release it was.
User visible changes
This section covers stories that affect end users, with the video providing a quick demonstration of the new features, and the sections below describing them in more detail.
Video 1: Sprint 30 Demo.
Org-mode support
A target that we've been chasing for the longest time is the ability to create models using org-mode. We use org-mode (and emacs) for pretty much everything in Dogen, such time keeping and task management - it's how we manage our product and sprint backlogs, for one - and we'll soon be using it to write academic papers too. It's just an amazing tool with a great tooling ecosystem, so it seemed only natural to try and see if we could make use of it for modeling too. Now, even though we are very comfortable with org-mode, this is not a decision to be taken lightly because we've been using Dia since Dogen's inception, over eight years ago.
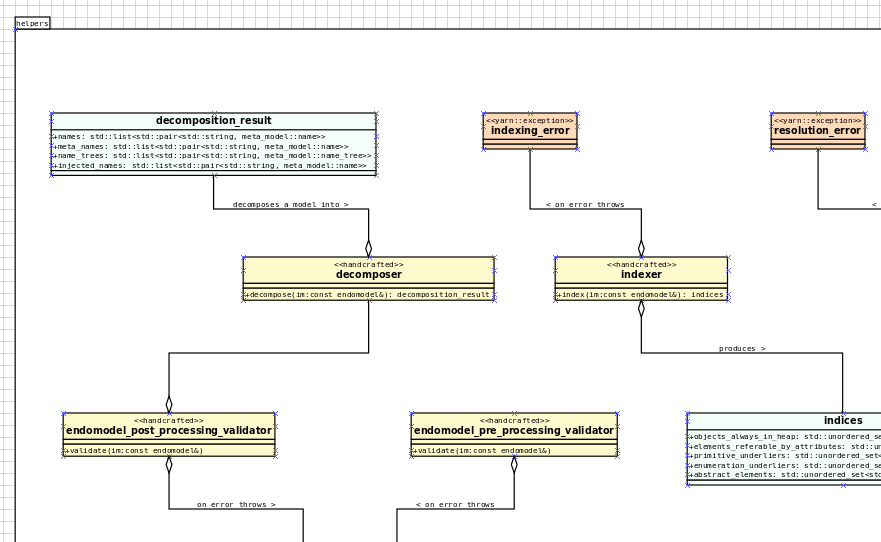 Figure 1: Dia diagram for a Dogen model with the introduction of colouring, Dogen v1.0.06
Figure 1: Dia diagram for a Dogen model with the introduction of colouring, Dogen v1.0.06
As much as we profoundly love Dia, the truth is we've had concerns about relying on it too much due to its somewhat sparse maintenance, with the last release happening some nine years ago. What's more pressing is that Dia relies on an old version of GTK, meaning it could get pulled from distributions at any time; we've already had a similar experience with Gnome Referencer, which wasn't at all pleasant. In addition, there are a number of "papercuts" that are mildly annoying, if livable, and which will probably not be addressed; we've curated a list of such issues, in the hope of one day fixing these problems upstream, but that day never came. The direction of travel for the maintenance is also not entirely aligned with our needs. For example, we recently saw the removal of python support in Dia - at least in the version which ships with Debian - a feature in which we relied upon heavily, and intended to do more so in the future. All of this to say that we've had a number of ongoing worries that motivated our decision to move away from Dia. However, I don't want to sound too negative here - and please don't take any of this as a criticism to Dia or its developers. Dia is an absolutely brilliant tool, and we have used it for over two decades; It is great at what it does, and we'll continue to use it for free modeling. Nonetheless, it has become increasingly clear that the directions of Dia and Dogen have started to diverge over the last few years, and we could not ignore that. I'd like to take this opportunity to give a huge thanks to all of those involved in Dia (past and present); they have certainly created an amazing tool that stood the test of time. Also, although we are moving away from Dia use in mainline Dogen, we will continue to support the Dia codec and we have tests to ensure that the current set of features will continue to work.
That's that for the rationale for moving away from Dia. But why org-mode? We came up with a nice laundry list of reasons:
- "Natural" Representation: org-mode documents are trees, with arbitrary nesting, which makes it a good candidate to represent the nesting of namespaces and classes. It's just a natural representation for structural information.
- Emacs tooling: within the org-mode document we have full access to Emacs features. For example, we have spell checkers, regular copy-and-pasting, etc. This greatly simplifies the management of models. Since we already use Emacs for everything else in the development process, this makes the process even more fluid.
- Universality: org-mode is fairly universal, with support in Visual Studio Code, Atom and even Vim (for more details, see Get started with Org mode without Emacs). None of these implementations are as good as Emacs, of course - not that we are biased, or anything - but they are sufficient to at least allow for basic model editing. And installing a simple plugin in your editor of choice is much easier than having to learn a whole new tool.
- "Plainer" plain-text: org-mode documents are regular text files, and thus easy to life-cycle in a similar fashion to code; for example, one can version control and diff these documents very easily. Now, we did have Dia's files in uncompressed XML, bringing some of these advantages, but due to the verbosity of XML it was very hard to see the wood for the trees. Lots of lines would change every time we touched a model element - and I literally mean "touch" - making it difficult to understand the nature of the change. Bisection for example was not helped by this.
- Models as documentation: Dogen aims to take the approach of "Literate Modeling" described in papers such as Literate Modelling - Capturing Business Knowledge with the UML. It was clear from the start that a tool like Dia would not be able to capture the wealth of information we intended to add to the models. Org-mode on the other hand is the ideal format to bring disparate types of information together (see Replacing Jupyter with Orgmode for an example of the sort of thing we have in mind).
- Integration with org-babel: Since models contain fragments of source code, org-mode's support for working with source code will come in handy. This will be really useful straight away on the handling of text templates, but even more so in the future when we add support for code merging.
Over the past few sprints we've been carrying out a fair bit of experimentation on the side, generating org-mode files from the existing Dia models; it was mostly an exercise in feasibility to see if we could encode all of the required information in a comprehensible manner within the org-mode document. These efforts convinced us that this was a sensible approach, so this sprint we focused on adding end-to-end support for org-mode. This entailed reading org-mode documents, and using them to generate the exact same code as we had from Dia. Unfortunately, though C++ support for org-mode exists, we could not find any suitable library for integration in Dogen. So we decided to write a simple parser for org-mode documents. This isn't a "generic parser" by any means, so if you throw invalid documents at it, do expect it to blow up unceremonially. Figure 2 shows the dogen.org model represented as a org-mode document.
 Figure 2:
Figure 2: dogen.org model in the org-mode representation.
We tried as much as possible to leverage native org-mode syntax, for example by using tags and property drawers to encode Dogen information. However, this is clearly a first pass and many of the decisions may not survive scrutiny. As always, we need to have a great deal of experience editing models to see what works and what does not, and it's likely we'll end up changing the markup in the future. Nonetheless, the guiding principle is to follow the "spirit" of org-mode, trying to make the documents look like "regular" org-mode documents as much as possible. One advantage of this approach is that the existing tooling for org-mode can then be used with Dogen models - for example, org-roam, org-ref, org-brain, org-tanglesync and many more. Sadly, one feature which we did not manage to achieve was the use of stitch-mode in the org-babel blocks. It appears there is some kind of incompatibility between org-mode and polymode; more investigation is required, such as for instance playing with the interestingly named poly-org. As Figure 3 demonstrates, the stitch templates are at present marked as fundamental, but users can activate stitch mode when editing the fragment.
 Figure 3: Stitch template in
Figure 3: Stitch template in dogen.text model.
In order to make our life easier, we implemented conversion support for org-mode:
$ head dogen.cli.dia
<?xml version="1.0" encoding="UTF-8"?>
<dia:diagram xmlns:dia="http://www.lysator.liu.se/~alla/dia/">
<dia:diagramdata>
<dia:attribute name="background">
<dia:color val="#ffffffff"/>
</dia:attribute>
<dia:attribute name="pagebreak">
<dia:color val="#000099ff"/>
</dia:attribute>
<dia:attribute name="paper">
$ dogen.cli convert --source dogen.cli.dia --destination dogen.cli.org
$ head dogen.cli.org
#+title: dogen.cli
#+options: <:nil c:nil todo:nil ^:nil d:nil date:nil author:nil
#+tags: { element(e) attribute(a) module(m) }
:PROPERTIES:
:masd.codec.dia.comment: true
:masd.codec.model_modules: dogen.cli
:masd.codec.input_technical_space: cpp
:masd.codec.reference: cpp.builtins
:masd.codec.reference: cpp.std
:masd.codec.reference: cpp.boost
This feature was mainly added for our benefit, but it may also be useful for any users that wish to update their models from Dia to org-mode. We made use of conversion to migrate all of the Dogen core models into org-mode, including the library models - though these required a bit of manual finessing to get them into the right shape. We also performed a number of modeling tasks in the sprint using the new format and the work proceeded as expected; see the below sections for links to a video series on this subject. However, one thing we did notice is that we missed the ability to visualise models as UML diagrams. And that gives us a nice segway into the second major story of this sprint.
Initial PlantUML support
Whilst the advantages of modeling using textual languages over graphical languages are patently obvious, the truth is the modeling process requires both views in order to progress smoothly. Maybe its just me but I get a lot of information about a system very quickly just by looking at a well-curated class diagram. It is especially so when one does not touch a sub-system for extended periods of time; it only takes a few minutes to observe and absorb the structure of the sub-system by looking carefully at its class diagram. In Dogen, we have relied on this since the beginning, particularly because we need to context-switch in-and-out so often. With the move to org-mode we suddenly found ourselves unable to do so, and it was quite disorienting. So we decided to carry out yet another little experiment: to add basic support for PlantUML. PlantUML is a textual notation that describes pretty much all types of UML diagrams, as well as a tool that converts files in that notation over to a graphical representation. The syntax is very simple and intuitive. Take for example one of the samples they supply:
@startuml
Class11 <|.. Class12
Class13 --> Class14
Class15 ..> Class16
Class17 ..|> Class18
Class19 <--* Class20
@enduml
This very simple and compact notation produces the rather wonderful UML class diagram:
 Figure 4: UML Class Diagram generated from PlantUML sample. Source: PlantUML site.
Figure 4: UML Class Diagram generated from PlantUML sample. Source: PlantUML site.
Given the notation is so straightforward, we decided to create a codec that outputs PlantUML documents, which can then be processed by their tool. To do so, simply convert the model:
$ dogen.cli convert --source dogen.cli.org --destination dogen.cli.plantuml
The listing below has a fragment of the output produced by Dogen; it contains the PlantUML representation of the dogen.org model from Figure 2.
@startuml
set namespaceSeparator ::
note as N1
Provides support for encoding and decoding Emacs's org-mode
documents.
The support is very basic and focuses only on the features
of org mode required by Dogen.
end note
namespace entities #F2F2F2 {
class section #F7E5FF {
+{field} blocks std::list<block>
}
class document #F7E5FF {
+{field} affiliated_keywords std::list<affiliated_keyword>
+{field} drawers std::list<drawer>
+{field} section section
+{field} headlines std::list<headline>
}
<snip>
You can process it with PlantUML, to produce SVG output (or PNG, etc):
$ plantuml dogen.org.plantuml -tsvg
The SVG output is particularly nice because you can zoom in and out as required. It is also rendered very quickly by the browser, as attested by Figure 5.
 Figure 5:
Figure 5: dogen.org SVG representation, produced by PlantUML.
While it was fairly straightforward to add basic PlantUML support, the diagrams are still quite far from the nice orderly representations we used to have with Dia. They are definitely an improvement on not having any visual representation at all, mind you, but of course given our OCD nature, we feel compeled to try to get them as close as possible to what we had before. In order to do so we will have to do some re-engineering of the codec model and bring in some of the information that lives in the logical model. In particular:
- generalisation parsing so that we can depict these relationships in the diagram; this is actually quite tricky because some of the information may live on profiles.
- some level of resolution: all intra-model types must be resolved in order to support associations.
These changes will have to remain on the work stack for the future. For now the diagrams are sufficient to get us going, as Figures 5 and 6 demonstrate. Finally, its also worthwhile pointing out that PlantUML has great integration with Emacs and with org-mode in particular, so in the future it is entirely possible we could "inject" a graphical representation of model elements into the model itself. Clearly, there are many possibilities to explore here, but for now these remain firmly archived in the "future directions" section of the product backlog.
 Figure 6: Fragment of the PlantUML representation of
Figure 6: Fragment of the PlantUML representation of dogen.profiles model.
Add support for reference directories
With this release we also managed to add another feature which we have been pining for: the ability to have models in multiple directories. In the past we automatically detected the library directory, and we also checked for models in the target directory; due to this it was not possible to have models in any other directory. With this release, a new command line parameter was added: --reference-directory.
$ dogen.cli generate --help
Dogen is a Model Driven Engineering tool that processes models encoded in supported codecs.
Dogen is created by the MASD project.
Displaying options specific to the generate command.
For global options, type --help.
Generation:
-t [ --target ] arg Model to generate code for, in any of the
supported formats.
-o [ --output-directory ] arg Output directory for the generated code.
Defaults to the current working directory.
-r [ --reference-directory ] arg One or more directories to check for
referenced models.
Users can supply directories containing their models and Dogen will check those directories when resolving references. This means you no longer need to keep all your models in a big jumble on the same directory, but should instead start to keep them together with the code they generate. We used this feature in Dogen to separate the old dogen.models directory, and created a number of modeling directories where all the content related to modeling for a given component will be placed. For example, see the dogen.org modeling directory:
$ ls -l
total 76
-rw-r--r-- 1 marco marco 3527 2021-01-02 12:37 CMakeLists.txt
-rw-r--r-- 1 marco marco 10360 2021-01-03 17:36 dogen.org.org
-rw-r--r-- 1 marco marco 3881 2021-01-03 13:53 dogen.org.plantuml
-rw-r--r-- 1 marco marco 60120 2021-01-03 13:54 dogen.org.svg
Development Matters
In this section we cover topics that are mainly of interest if you follow Dogen development, such as details on internal stories that consumed significant resources, important events, etc. As usual, for all the gory details of the work carried out this sprint, see the sprint log.
Milestones and Ephemerides
This sprint saw the 13,000th commit to Dogen.
 Figure 7: Commit number 13,000th was made to the Dogen GitHub repository.
Figure 7: Commit number 13,000th was made to the Dogen GitHub repository.
Significant Internal Stories
This sprint had two key goals, both of which were achieved: org-mode and PlantUML support. These were described in the user facing stories above. In this section we shall provide more details about how this work was organised, as well as other stories which were not user facing.
Org-mode work
The following stories were required to bring about org-mode support:
- Add support for reading org mode documents: creation of an org-mode parser, as well as a model to represent the types of this domain.
- Add org-mode codec for input: story to plug in the new org-mode parser into the codec framework, from an input perspective.
- Create a model to org transform: output side of the work; the addition of a transform which takes a Dogen model and generates an org-mode document.
- Add tags to org model: originally we tried to infer the element's meta-type by its position (e.g. package, "regular" element, attribute). However, it soon became obvious this was not possible and we ended up having to add org tags to perform this work. A story related to this one was also Assorted improvements to org model, where we sorted out a small number of papercuts with the org documents.
- Consider replacing properties drawer with tables: an attempt to use org-mode tables instead of property drawers to represent meta-data. We had to cancel the effort as we could not get it to work before the end of the sprint.
- Convert library models into org: we spent a fair bit of time in converting all of the JSON models we had on our library into org-mode. The automatic conversion worked fairly well, but it was missing some key bits which had to be added manually.
- Convert reference models into org: similarly to the library models, we had to convert all of Dogen's models into org-mode. This also includes the work for C++ and C# reference models. We managed to use the automatic conversion for all of these, after a fair bit of work on the conversion code.
- Create a "frozen" project: although we were moving away from Dia, we did not want the existing support to degrade. The Dia Dogen models are an exacting test in code generation, which add a lot of value. There has always been an assumption that these would be a significant part of the code generator testing suite, but what we did not anticipate is that we'd move away from using a "core" codec such as Dia. So in order not to lose all of the testing infrastructure we decided to create a "frozen" version of Dogen, which in truth is not completely frozen, but contains a faithful representation across all supported codecs of the Dogen models at that point in time. With Frozen we can guarantee that the JSON and Dia support will not be any worse for all the features used by Dogen at the time the snapshot was taken.
- Remove JSON and Dia models for Dogen: once Frozen was put in place, we decommissioned all of the existing Dia and JSON models within Dogen. This caused a number of breaks which had to be hunted down and fixed.
- Add org-to-org tests and Analysis on org mode round-tripping: we added a "special" type of round-tripping: the org-to-org conversion. This just means we can read an org-mode document and then regenerate it without introducing any differences. It may sound quite tautological, but it has its uses; for example, we can introduce new features to org documents by adding it to the output part of the transform chain and then regenerating all documents. This was useful several times this sprint. It will also be quite useful in the future, when we integrate with external tooling; we will be able to append data to user models without breaking any of the user content (hopefully).
-
Inject custom IDs into org documents: we tried not to have an identifier in org-mode documents for each element, but this caused problems when recreating the topology of the document. We had to use our org-to-org transform to inject
custom_id(the org-mode attribute used for this purpose), though some had to be injected manually.
Whitespace handling
Whilst it was introduced in the context of the org-mode, the changes to the handling of whitespace are a veritable epic in its own right. The problem was that in the past we wanted to preserve whitespace as supplied by the user in the original codec model; however, if we did this for org-mode documents, we would end up with very strange looking documents. So instead we decided to trim leading and trailing whitespace for all commentary. It took a while to get it to work such that the generated code had no differences, but this approach now means the org-mode documents look vaguely sensible, as does the generated code. The following stories were involved in adding this feature:
- Move documentation transform to codec model: for some reason we had decided to place the documentation trimming transform in the logical model. This made things a lot more complicated. In this sprint we moved it into the codec model, which greatly simplified the transform. Stitch templates are consuming whitespace: this was a bit of a wild-goose chase. We thought the templates were some how causing problems with the spacing, but in the end it was just to do with how we trim different assets. Some hackery was required to ensure text templates are correctly terminated with a new line.
- Remove leading and trailing new lines from comments: the bulk of the work where we trimmed all commentary.
-
Allow spaces in headlines for org mode documents: to make org-mode documents more readable, we decided to allow the use of spaces in headlines. These get translated to underscores as part of the processing. It is possible to disable this translation via the not-particularly-well-named key
masd.codec.preserve_original. This was mainly required for types such asunsigned intand the like.
PlantUML work
There were a couple of stories involved in adding this feature:
- Add PlantUML markup language support: the main story that added the new codec. We also added CMake targets to generate all models.
- Add comments to PlantUML diagrams: with this story we decided to add support for displaying comments in modeling elements. It is somewhat experimental, and its look and feel is not exactly ideal, but it does seem to add some value. More work on the cosmetics is required.
Smaller stories
A number of smaller stories was also worked on:
-
Merge dia codec model into main codec model: we finally got rid of the Dia "modelet" that we have been carrying around for a few sprints; all of its code has now been refactored and placed in the
dogen.codecmodel, as it should be. - Split orchestration tests by model and codec: our massive file containing all code generation tests was starting to cause problems, particularly with treemacs and lsp-mode in emacs. This story saw the monster file split into a number of small files, organised by codec and product.
- Add missing provenance details to codec models: whilst trobuleshooting an issue we noticed that the provenance details had not been populated correctly at the codec level. This story addresses this shortcoming and paves the way for GCC-style errors, which will allow users to be taken to the line in the org-document where the issue stems from.
Video series of Dogen coding
This sprint we recorded some videos on the implementation of the org-mode codec, and the subsequent use of these models. The individual videos are listed on Table 2, with a short description. They are also available as a playlist, as per link below.
 Video 2: Playlist "MASD - Dogen Coding: Org Codec".
Video 2: Playlist "MASD - Dogen Coding: Org Codec".
| Video | Description |
|---|---|
| Part 1 | In this part we provide context about the current task and start off by doing some preliminary work setting up the required infrastructure. |
| Part 2 | In this video we review the work done to process org mode documents, and start coding the codec transform. However, we bump into a number of problems. |
| Part 3 | In this video we review the work done to get the org codec to generate files, and analyse the problems we're having at present, likely related to errors processing profiles. |
| Part 4 | In this video we review the work done offline to implement the basic support for reading org-mode documents and start the work to write org mode documents using our org model. |
| Part 6 | In this part we review the round-trip work made to support org mode, and refactor the tags used in org models. We also add support for org custom IDs. |
| Part 7 | Addendum video where we demonstrate the use of the new org mode models in a more expansive manner. |
| Part 8 | In this second addendum we work on the org-to-org transform, solving a number of issues with whitespacing. |
| Part 9 | In this video we try to explore moving away from properties to represent meta-data and using tables instead, but we run into a number of difficulties and end up spending most time fixing bugs related to element provenance. |
Resourcing
As you can see from the lovely spread of colours in the pie chart below (Figure 8), our story-keeping this sprint was much healthier than usual; the biggest story took 24.3% which is also a great sign of health. Our utilisation rate was also the highest since records began, at 70%, and a marked improvement over the measly 35% we clocked last sprint. To be fair, that is mainly an artefact of the holiday season more than anything else, but who are we to complain - one is always happy when the numbers are going in the right direction, regardless of root cause. On the less positive front, we spent around 16.2% on activities that were not related to our core mission - a sizable increase from the 11% last time round, with the main culprit being the 4.5% spent on addressing Emacs issues (including some low-level elisp investigations). On the plus side, we did make a few nice changes to our Emacs setup, which will help with productivity, so its not just sunk costs. Predictably, the circa 84% dedicated to "real work" was dominated by org-mode stories (~54%), with PlantUML coming in at a distant second (7%). All and all, it was a model sprint - if you pardon the pun - from a resourcing perspective.
 Figure 8: Cost of stories for sprint 30.
Figure 8: Cost of stories for sprint 30.
Roadmap
The road map has been working like clockwork for the last few sprints, with us ticking stories off as if it was a mere list - clearly no longer the Oracle of Delphi it once was - and this sprint was no exception. Were we to be able to continue with the same release cadence, the next sprint would no doubt also tick off the next story on our list. Alas, we have ran out of coding time, so Sprint 31 will instead be very long running sprint, with very low utilisation rate. In addition, we won't bother creating sprints when the work is completely dedicated to writing; instead, regular service will resume once the writing comes to an end.


Binaries
You can download binaries from either Bintray or GitHub, as per Table 3. All binaries are 64-bit. For all other architectures and/or operative systems, you will need to build Dogen from source. Source downloads are available in zip or tar.gz format.
| Operative System | Format | BinTray | GitHub |
|---|---|---|---|
| Linux Debian/Ubuntu | Deb | dogen_1.0.30_amd64-applications.deb | dogen_1.0.30_amd64-applications.deb |
| Windows | MSI | DOGEN-1.0.30-Windows-AMD64.msi | DOGEN-1.0.30-Windows-AMD64.msi |
Table 3: Binary packages for Dogen.
Note 1: The Linux binaries are not stripped at present and so are larger than they should be. We have an outstanding story to address this issue, but sadly CMake does not make this a trivial undertaking.
Note 2: Due to issues with Travis CI, we did not manage to get OSX to build, so and we could not produce a final build for this sprint. The situation with Travis CI is rather uncertain at present so we may remove support for OSX builds altogether next sprint.
Next Sprint
The goals for the next sprint are:
- to implement path and dependencies via PMM.
That's all for this release. Happy Modeling!
v1.0.29
3 years ago Bar O Stop, Namibe. (C) 2010 Jo Sinfield
Bar O Stop, Namibe. (C) 2010 Jo Sinfield
Introduction
And so t'was that the 29th sprint of the 1.0 era finally came to a close; and what a bumper sprint it was. If you recall, on Sprint 28 we saw the light and embarked on a coding walkabout to do a "bridge refactor". The rough objective was to complete a number of half-baked refactors, and normalise the entire architecture around key domain concepts that have been absorbed from MDE (Model Driven Engineering) literature. Sprint 29 brings this large wandering to a close - well, at least as much as one can "close" these sort of never ending things - and leaves us on a great position to focus back on "real work". Lest you have forgotten, the "real work" had been to wrap things up with the PMM (Physical Meta-Model), but it had fallen by the wayside since the end of Sprint 27. When this work resumes, we can now reason about the architecture without having to imagine some idealised target state that would probably never arrive (at the rate we were progressing), making the effort a lot less onerous. Alas, this trivialises the sprint somewhat. The truth was that it took over 380 commits and 89 hours of intense effort to get us in this place, and it is difficult to put in words the insane amount of work that makes up this release. Nevertheless, one is compeled to give it a good old go, so settle in for the ride that was Sprint 29.
User visible changes
This section normally covers stories that affect end users, with the video providing a quick demonstration of the new features, and the sections below describing them in more detail. As there were no user facing features, the video discusses the work on internal features instead.
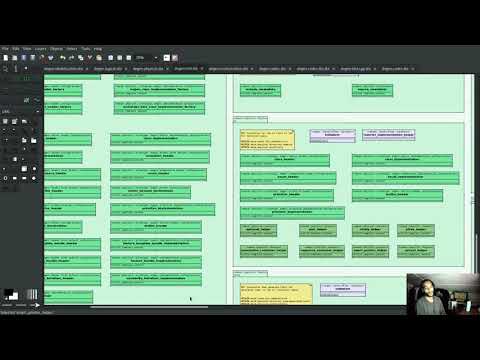 Video 1: Sprint 29 Demo.
Video 1: Sprint 29 Demo.
Development Matters
In this section we cover topics that are mainly of interest if you follow Dogen development, such as details on internal stories that consumed significant resources, important events, etc. As usual, for all the gory details of the work carried out this sprint, see the sprint log.
Significant Internal Stories
This sprint had two key goals, both of which were achieved:
- moving remaining "formattable" types to logical and physical models.
- Merge
textmodels.
By far, the bulk of the work went on the second of these two goals. In addition, a "stretch" goal appeared towards the end of the sprint, which was to tidy-up and merge the codec model. These goals were implemented by means of four core stories, which captured four different aspects of the work, and were then aided by a cast of smaller stories which, in truth, were more like sub-stories of these "conceptual epics". We shall cover the main stories in the next sections and slot in the smaller stories as required. Finally, there were a number of small "straggler stories" which we'll cover at the end.
Complete the formattables refactor
A very long running saga - nay, a veritable Brazilian soap opera of coding - finally came to an end this sprint with the conclusion of the "formattables" refactor. We shan't repeat ourselves explaining what this work entailed, given that previous release notes had already done so in excruciating detail, but its certainly worth perusing those writings to get an understanding of the pain involved. This sprint we merely had to tie up lose ends and handle the C# aspects of the formattables namespace. As before, all of these objects were moved to "suitable" locations within the LPS (Logical-Physical Space), though perhaps further rounds of modeling clean-ups are required to address the many shortcomings of the "lift-and-shift" approach taken. This was by design, mind you; it would have been very tricky, and extremely slow-going, if we had to do a proper domain analysis for each of these concepts and then determine the correct way of modeling them. Instead, we continued the approach laid out for the C++ model, which was to move these crazy critters to the logical or physical models with the least possible amount of extra work. To be fair, the end result was not completely offensive to our sense of taste, in most cases, but there were indeed instances that required closing one's eyes and "just get on with it", for we kept on being tempted to do things "properly". It takes a Buddhist-monk-like discipline to restrict oneself to a single "kind" of refactor at a time, but it is crucial to do so because otherwise one will be forever stuck in the "refactor loop", which we described in The Refactoring Quagmire all those moons ago.
It is also perhaps worth spending a few moments to reflect on the lessons taught by formattables. On one hand, it is a clear validation of the empirical approach. After all, though the modeling was completely wrong from a domain expertise standpoint, much of what was laid out within this namespace captured the essence of the task at hand. So, what was wrong about formattables? The key problem was that we believed that there were three representations necessary for code-generation:
- the external representation, which is now housed in the
codecmodel; - the "language agnostic" representation, which is now housed in the
logicmodel; - the "language-specific" representation, which was implemented by formattables (i.e.,
text.cppandtext.csharp).
What the empirical approach demonstrated was that there is no clear way to separate the second and third representations, try as we might, because there is just so much overlap between them. The road to the LPS had necessarily to go through formattables, because in theory it appeared so clear and logical that separate TSs (Technical Spaces) should have clean, TS-specific representations which were ready to be written to files. As Mencken stated:
Every complex problem has a solution which is simple, direct, plausible—and wrong.
In fact, It took a great deal of careful reading through the literature, together with a lot of experimentation, to realise that doing so is not at all practical. Thus, it does not seem that it was possible to have avoided making this design mistake. One could even say that this "mistake" is nothing but the empirical approach at play, because you are expected to conduct experiments and accumulate facts about your object of study, and then revise your hypothesis accordingly. The downside, of course, is that it takes a fair amount of time and effort to perform these "revisions" and it certainly feels as if there was "wasted time" which could have been saved if only we started off with the correct design in the first place. Alas, it is not clear how would one simply have the intuition for the correct design without the experimentation. In other words, the programmer's perennial condition.
Move helpers into text model and add them to the PMM
As described in the story above, it has become increasingly clear that the text model is nothing but a repository of M2T (Model to Text) transforms, spread out across TS's and exposed programatically into the PMM for code generation purposes. Therefore, the TS-specific models for C++ and C# no longer make any sense; what is instead required is a combined text model containing all of the text transforms, adequately namespaced, making use of common interfaces and instantiating all of the appropriate PMM entities. This "merging" work fell under the umbrella of the architectural clean up work planned for this sprint.
The first shot across the bow in the merging war concerned moving "helpers" from both C++ and C# models into the combined model. A bit of historical context is perhaps useful here. Helpers, in the M2T sense, have been a pet-peeve of ours for many many moons. Their role is to code-generate functionlets inside of the archetypes (e.g. the "real" M2T transforms). These helpers, via an awfully complicated binding logic which we shall not bore you with, bind to the type system and then end up acting as "mini-adapters" for specific purposes, such as allowing us to use third-party libraries within Dogen, cleaning up strings prior to dumping them in streams and so forth. A code sample should help in clarifying this notion. The below code fragment, taken from logical::entities::element, contains the output three different helper functions:
inline std::string tidy_up_string(std::string s) {
boost::replace_all(s, "\r\n", "<new_line>");
boost::replace_all(s, "\n", "<new_line>");
boost::replace_all(s, "\"", "<quote>");
boost::replace_all(s, "\\", "<backslash>");
return s;
}
namespace boost {
inline bool operator==(const boost::shared_ptr<dogen::variability::entities::configuration>& lhs,
const boost::shared_ptr<dogen::variability::entities::configuration>& rhs) {
return (!lhs && !rhs) ||(lhs && rhs && (*lhs == *rhs));
}
}
namespace boost {
inline std::ostream& operator<<(std::ostream& s, const boost::shared_ptr<dogen::variability::entities::configuration>& v) {
s << "{ " << "\"__type__\": " << "\"boost::shared_ptr\"" << ", "
<< "\"memory\": " << "\"" << static_cast<void*>(v.get()) << "\"" << ", ";
if (v)
s << "\"data\": " << *v;
else
s << "\"data\": ""\"<null>\"";
s << " }";
return s;
}
}
The main advantage of the "helper approach" is that one does not have to distribute any additional header files or libraries to compile the generated code, other than the third-party libraries themselves. Sadly, this is not sufficient to compensate for its downsides. This approach has never been particularly efficient or pretty - imagine hundreds of lines such as the above scattered around the code base - but, significantly, it isn't particularly scalable either, because one needs to modify the code generator accordingly for every new third party library, together with the associated (and rather complex) bindings. Our incursions through the literature provided a much cleaner way to address these requirements via hand-crafted PDMs (Platform Definition Models), which are coupled with third-party libraries and are responsible for providing any glue needed by generated code. However, since we've been knee-deep into a cascade of refactoring efforts, we could not bring ourselves to halt the present work once more and context-switch to yet another (possibly) long running refactoring effort. As a result, we decided to keep calm and carry on the burden of moving helpers around, until such time we could refactor them out of existence. The text model merging did present a chance to revisit this decision, but we thought best "to confuse one issue at a time" and decided to "just move" the helpers across to the text model. As it turned out, "just moving" them was no trivial matter. Our troubles begun as soon as we tried to untangle the "helpers" from the "assistant".
At this juncture, your design alarm bells are probably ringing very loudly, and so were ours. After all, a common adage amongst senior developers is that whenever you come up with entities named "assistant", "helper", "manager" and the like, they are giving you a clear and unambiguous indication that you have a slim understanding of the domain; worse, they'll soon devolve into a great big ball of mud, for no one can possibly divine their responsibilities. The blog posts on this matter are far too many to count - i.e., Jeff Atwood, Alan Green, and many Stack Overflow posts such as this one. However, after some investigation, it seemed there was indeed some method in our madness:
- the "helpers" where really PDMs in disguise, and those would be dealt with at some point in the future, so they could be ignored for now;
- the "assistant" had ultimately two distinct responsibilities: 1) to perform some TS-specific transformation of data elements from the logical model, which we now understood to fall under the logical model umbrella; 2) to perform some "formating assistance", providing common routines to a lot of M2T transforms. We implemented some of these refactors, but others were deemed to be outside of the scope of the present exercise, and were therefore added to the backlog.
This was the harbinger of things to come. Much more significantly, assistants and helpers where bound together in a cycle, meaning we could not move them incrementally to the text model as we originally envisioned. As we've elaborated many a times in these pages, cycles are never the bearers of good fortune, so we took upon ourselves breaking the cycle as part of this exercise. Fortunately this was not too difficult, as the parts of the assistant API used by the helpers were fairly self contained. The functionality was encapsulated into an ABC (Abstract Base Class), a decision that is not without controversy, but which suffices amply to address the problem at hand - all the more so given that helpers are to be removed in the not too distant future.
A third stumbling block was that, even though helpers are deprecated and their impact should be contained to legacy code, they still needed to be accessible via the PMM. Sadly, the existing helper code was making use of some of the same features which in the new world are addressed by the PMM, and so we had no choice but to extend the PMM with helper support. Though not ideal, this was done in a fairly painless manner, and it is hopefully self-contained enough that not much of the code base will start to rely on its presence. Once all of these obstacles were resolved, the bulk of the work was fairly repetitive: to move helpers in groups into the text model, tidying up each text template until it produced compilable code.
In the end, the following stories were required to bring the main story to a close:
- Improvements to template processing in logical model: minor fixes to how templates were being handled.
- Convert legacy helpers into new style helpers in C++: the bulk of the adaptation work in the C++ TS.
- Add C++ helpers to the PMM: Adding PMM infrastructure to deal with helpers. Here we are mainly concerned with C++, but to be fair much of the infrastructure is common to all TSs.
-
Remove unused wale keys in
text.cpp: minor tidy-up of templates and associated wale (mustache) keys. -
Merge
cpp_artefact_transform*wale templates : Removal of unnecessary wale (mustache) templates. - Add C# helpers to the PMM: Modifications to the PMM to cater for C#-specific concerns.
-
Move helpers to
textmodel: Remaining work in moving the helpers across to the combinedtextmodel.
Move text transforms in C++ and C# models into text model
Once we had helpers under our belt, we could turn our attention to the more pressing concerns of the M2T transforms. These presented a bigger problem due to scale: there are just far too many text transforms. This was a particularly annoying problem due to how editing in Dia works at present, with severe limitations on copying and pasting across diagrams. Alas, there was nothing for it but patience. Over a long period of time, we performed a similar exercise to that of the helpers and moved each text template into their resting location in the text model. The work was not what you'd call a creative exercise, but nonetheless an important one because the final layout of the text model now mirrors the contents of the PMM - precisely what we had intended from the beginning.
 Figure 1: Birds-eye view of the
Figure 1: Birds-eye view of the text model
Figure 1 shows a birds-eye view of the text model. On the top-leftmost corner, in orange, you can see the wale (mustache) templates. Next to it is the entities namespace, containing the definition of the LPS (in pink-ish). At the bottom of the picture, with the greener tones, you have the two major TS: C++ (on the bottom left) and C# (on the bottom right, clipped). Each TS shows some of the M2T transforms that composes them. All elements are exposed into the PMM via code-generation.
Clean up and merge codec models
The final "large" architectural problem we had to address was the current approach for the codec models. Long ago, we envisioned a proliferation of the number of codecs for Dogen, and so thought these should be dynamically injected to facilitate the use case. In our view, each codec would extend Dogen to process file types for specific uses, such as adding eCore support, as well as for other, non-UML-based representations. Whilst we still see a need for such an approach, it was originally done with little conceptual understanding of MDE and as such resulted in lots of suis generis terminology. In addition, we ended up with lots of little "modelets" with tiny bits of functionality, because each codec now shares most of its pipeline with the main codec model. Thus, the right approach was to merge all of these models into the codec model, and to move away from legacy terms such as hydrator, encoder and the like, favouring instead the typical MDE terminology of transforms and transform chains. This story covered the bulk of the work, including the merging of the codec.json and codec.org models, but sadly just as we were closing in in the codec.dia model we ran out of time. The work shall be completed early next sprint.
 Figure 2: Fragment of the
Figure 2: Fragment of the codec model after refactoring.
Other stories related to this work:
- Use MDE terminology in Dia model: the plain (non-codec) representation of Dia got an "MDE tidy-up, following the same pattern as all other models and using transforms rather than hydrators, etc.
Assorted smaller stories
A number of small stories was also worked on:
- Fix some problems with c++ visual studio: assorted improvements to Visual Studio project files; though these are still not ready for end users.
- Orchestration should have an initialiser: instead of copying and pasting the individual initialisers, create a top-level initialiser in orchestration and reuse it.
- Add namespaces to "dummy function": two classes with the same name in different namespaces resulted in the same "dummy" function, resulting in spurious OSX warnings. With this change, we generate the dummy function name from file path resulting in unique names in a component.
- Remove disabled files from project items: C# and C++ Visual Studio solutions contained files for disabled facets, due to the way enablement worked in C#. With the merge to the text model, this caused problems so we now honour disabled facets when generating project files.
- Remove JSON models from Dogen: Remove tests for JSON models within the Dogen product. JSON is still supported within the C++ reference implementation, but at least this way we do not need to regenerate the JSON models every time we change Dogen models which is quite often.
Video series of Dogen coding
This sprint we concluded the video series on the formattables refactor as well as a series on the text model refactor. These are available as playlists. The tables below present a summary of each part. Note that the previous videos for the formattables refactor are available on the release note for Sprint 28.
| Video | Description |
|---|---|
| Part 19 | In this video we get rid of most of the helper related properties in formattables and almost get rid of the formattables model itself, but fail to do so in the end due to some unexpected dependencies. |
| Part 20 | In this part we start to add the PMM infrastructure, beginning with the logical model representation of helpers. However, when we try to use it in anger, the world blows up. |
| Part 21 | In this video we try to generate the helpers implementation but find that there are some very significant errors in how helpers have been modeled. |
| Part 22 | In this episode we complete the transition of types helpers and do a few hash helpers. Apologies for the echo in the sound. |
| Part 23 | In this video we tackle the helpers in the C# Technical Space, as well as other assorted types. |
| Part 24 | In the final part in this series, we finally get rid of the formattables namespace. |
Table 1: Remaining videos on the playlist for the formattables refactor.
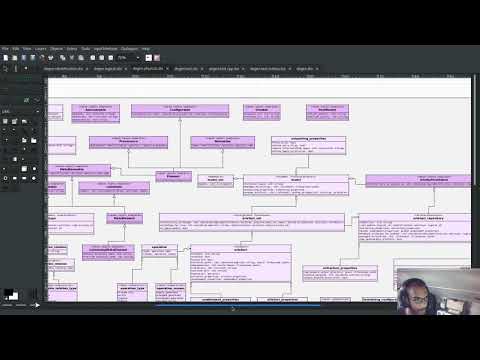 Video 2: Playlist "MASD - Dogen Coding: Formatables Refactor".
Video 2: Playlist "MASD - Dogen Coding: Formatables Refactor".
| Video | Description |
|---|---|
| Part 1 | In this part we introduce the task, and describe the overall approach. We also start to tackle the helpers. |
| Part 2 | In this part we tried to replace the C++ helper interface with the one from Text but we faced all sorts of fundamental issues and had to go back to the drawing board. |
| Part 3 | In this part we spend a lot of time copying and pasting code to adapt the helper M2T transforms to the new interface. We get close to the end of this task but don't quite complete it. |
| Part 4 | In this part we move across all backends and facets to the combined text model. |
| Part 5 | In this part we remove all of the helper parafernalia in text.cpp and text.csharp, bar the helpers themselves, and consolidate it all under the text model. We also move the first helper. |
| Part 6 | In this part we review the helper work we did offline and attempt to move to the new, non-TS-specific way of organising text transforms. |
| Part 7 | In this part we review a number of changes done offline and then deal with the C# assistant, moving it across to the text model. |
| Part 8 | In this part we mostly complete the work on merging the text model. Apologies in advance for this vide as it has a number of problems including bad sound quality as well as several stoppages, and finally, it terminates abruptly due to a machine crash. However we kept it for the record |
| Part 9 | This part is a recap due to the abrupt ending of the previous part, due to a machine crash (damn NVidia drivers for Linux!). |
Table 2: Individual videos on the playlist for the text model refactor.
 Video 3: Playlist "MASD - Dogen Coding: Formatables Refactor".
Video 3: Playlist "MASD - Dogen Coding: Formatables Refactor".
Resourcing
On one hand, the utilisation rate of 35% was not particularly brilliant this sprint, but by pretty much any other metric it has to be considered a model of resource consumption (if you pardon the MDE pun). Almost 89% of the total ask was used on stories directly related to the development process, and whilst the break down of stories was not exactly stellar, we still managed a good spread with the top 3 stories consuming 24.1%, 17.8% and 15.2% respectively. We tend to look closely at this because its a good indicator of the health of the analysis of a sprint, and its always a bad sign when one story dominates the majority of the ask. Nonetheless, when one looks at the story titles in more detail its still clear that there was a certain element of laziness in how the work was split and, as always, there is room for improvement in this department. The 11% on non-core tasks had the usual characteristics, with 5.7% allocated to the release notes, and a very cheap demo at 0.5%. One important note though is that this sprint consumed almost 90 hours in total rather than the more traditional 80, which means that looking at percentage numbers is somewhat misleading, particularly when comparing to a typical sprint. The major downside of this sprint was general tiredness, as usual, given the huge amount of the commitment. Sadly not much can be changed in this department, and ideally we wouldn't want to slow down in the next sprint though the Holidays may have a detrimental effect.
 Figure 3: Cost of stories for sprint 29.
Figure 3: Cost of stories for sprint 29.
Roadmap
The key alteration to the road map - other than the removal of the long standing "formattables refactor" - was the addition of the org-mode codec. We've spent far too many hours dealing with the inadequacies of Dia, and it is by now clear that we have much to gain by moving into Emacs for all our modeling needs (and thus, all our Dogen needs since everything else is already done inside Emacs). Therefore we've decided to take the hit and work on implementing org-mode support next sprint before we resume the PMM work. Other than that we are as we were, though on the plus side the road map does have a very realistic feel now given that we are actually completing targets on a sprint by sprint basis.


Binaries
You can download binaries from either Bintray or GitHub, as per Table 3. All binaries are 64-bit. For all other architectures and/or operative systems, you will need to build Dogen from source. Source downloads are available in zip or tar.gz format.
| Operative System | Format | BinTray | GitHub |
|---|---|---|---|
| Linux Debian/Ubuntu | Deb | dogen_1.0.29_amd64-applications.deb | dogen_1.0.29_amd64-applications.deb |
| OSX | DMG | DOGEN-1.0.29-Darwin-x86_64.dmg | DOGEN-1.0.29-Darwin-x86_64.dmg |
| Windows | MSI | DOGEN-1.0.29-Windows-AMD64.msi | DOGEN-1.0.29-Windows-AMD64.msi |
Table 3: Binary packages for Dogen.
Note 1: The OSX and Linux binaries are not stripped at present and so are larger than they should be. We have an outstanding story to address this issue, but sadly CMake does not make this a trivial undertaking.
Note 2: Due to issues with Travis CI, we had a number of failed OSX builds and we could not produce a final build for this sprint. However, given no user related functionality is provided, we left the link to the last successful build of Sprint 29. The situation with Travis CI is rather uncertain at present so we may remove support for OSX builds altogether next sprint.
Next Sprint
The goals for the next sprint are:
- to finish the codec tidy-up work.
- to implement org mode codec.
- to start implement path and dependencies via PMM.
That's all for this release. Happy Modeling!
v1.0.28
3 years ago Artesanal market, Praia das Miragens, Moçâmedes, Angola. (C) 2015 David Stanley.
Artesanal market, Praia das Miragens, Moçâmedes, Angola. (C) 2015 David Stanley.
Introduction
Welcome to yet another Dogen release. After a series of hard-fought and seemingly endless sprints, this sprint provided a welcome respite due to its more straightforward nature. Now, this may sound like a funny thing to say, given we had to take what could only be construed as one massive step sideways, instead of continuing down the track beaten by the previous n iterations; but the valuable lesson learnt is that, oftentimes, taking the theoretically longer route yields much faster progress than taking the theoretically shorter route. Of course, had we heeded van de Snepscheut, we would have known:
In theory, there is no difference between theory and practice. But, in practice, there is.
What really matters, and what we keep forgetting, is how things work in practice. As we mention many a times in these release notes, the highly rarefied, highly abstract meta-modeling work is not one for which we are cut out, particularly when dealing with very complex and long-running refactorings. Therefore, anything which can bring the abstraction level as close as possible to normal coding is bound to greatly increase productivity, even if it requires adding "temporary code". With this sprint we finally saw the light and designed an architectural bridge between the dark old world - largely hacked and hard-coded - and the bright and shiny new world - completely data driven and code-generated. What is now patently obvious, but wasn't thus far, is that bridging the gap will let us to move quicker because we don't have to carry so much conceptual baggage in our heads every time we are trying to change a single line of code.
Ah, but we are getting ahead of ourselves! This and much more shall be explained in the release notes, so please read on for some exciting news from the front lines of Dogen development.
User visible changes
This section normally covers stories that affect end users, with the video providing a quick demonstration of the new features, and the sections below describing them in more detail. As there were no user facing features, the video discusses the work on internal features instead.
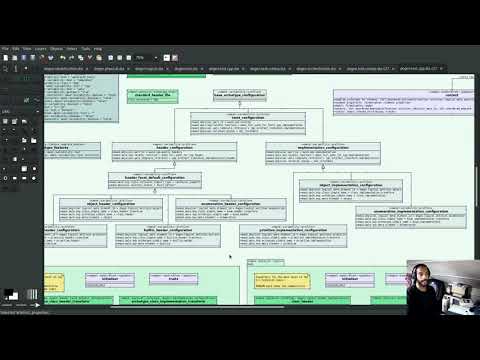 Video 1: Sprint 28 Demo.
Video 1: Sprint 28 Demo.
Development Matters
In this section we cover topics that are mainly of interest if you follow Dogen development, such as details on internal stories that consumed significant resources, important events, etc. As usual, for all the gory details of the work carried out this sprint, see the sprint log.
Significant Internal Stories
The main story this sprint was concerned with removing the infamous locator from the C++ and C# models. In addition to that, we also had a small number of stories, all gathered around the same theme. So we shall start with the locator story, but provide a bit of context around the overall effort.
Move C++ locator into physical model
As we explained at length in the previous sprint's release notes, our most pressing concern is finalising the conceptual model for the LPS (Logical-Physical Space). We have a pretty good grasp of what we think the end destination of the LPS will be, so all we are trying to do at present is to refactor the existing code to make use of those new entities and relationships, replacing all that has been hard-coded. Much of the problems that still remain stem from the "formattables subsystem", so it is perhaps worthwhile giving a quick primer of what formattables were, why they came to be and why we are getting rid of them. For this we need to travel in time, to close to the start of Dogen. In those long forgotten days, long before we had the benefit of knowing about MDE (Model Driven Engineering) and domain concepts such as M2M (Model-to-Model) and M2T (Model-to-Text) transforms, we "invented" our own terminology and approach to converting modeling elements into source code. The classes responsible for generating the code were called formatters because we saw them as a "formatting engine" that dumped state into a stream; from there, it logically followed that the things we were "formatting" should be called "formattables", well, because we could not think of a better name.
Crucially, we also assumed that the different technical spaces we were targeting had lots of incompatibilities that stopped us from sharing code between them, which meant that we ended up creating separate models for each of the supported technical spaces - i.e., C++ and C#, which we now call major technical spaces. Each of these ended up with its own formattables namespace. In this world view, there was the belief that we needed to transform models closer to their ultimate technical space representation before we could start generating code. But after doing so, we began to realise that the formattable types were almost identical to their logical and physical counterparts, with a small number of differences.
 Figure 1: Fragment of the formattables namespace, C++ Technical Space, circa sprint 23.
Figure 1: Fragment of the formattables namespace, C++ Technical Space, circa sprint 23.
What we since learned is that the logical and physical models must be able to represent all of the data required in order to generate source code. Where there are commonalities between technical spaces, we should exploit them, but where there are differences, well, they must still be represented within the logical and physical models; there simply is nowhere else to place them. In other words, there isn't a requirement to keep the logical and physical models technical space agnostic, as we long thought was needed; instead, we should aim for a single representation, but also not be afraid of multiple representations where they make more sense. With this began a very long-standing effort to move modeling elements across, one at a time, from formattables and the long forgotten fabric namespaces into their final resting place. The work got into motion circa sprint 18, and fabric was swiftly dealt with, but formattables proved more challenging. Finally, ten sprints later, this long running effort came unstuck when we tried to deal with the representation of paths (or "locations") in the new world because it wasn't merely just "moving types around"; the more the refactoring progressed, the more abstract it was becoming. For a flavour of just how abstract things are getting, have a read on Section "Add Relations Between Archetypes in the PMM" in sprint 26's release notes.
Ultimately, it became clear that we tried to bite more than we could chew. After all, in a completely data driven world, all of the assembly performed in order to generate a path is done by introspecting elements of the logical model, the physical meta-model (PMM) and the physical model (PM). This is extremely abstract work, where all that once were regular programming constructs have now been replaced by a data representation of some kind; and we had no way to validate any of these representations until we reached the final stage of assembling paths together, a sure recipe for failure. We struggled with this on the back-end of the last sprint and the start of this one, but then it suddenly dawned that we could perhaps move one step closer to the end destination without necessarily making the whole journey; going half-way or bridging the gap, if you will. The moment of enlightenment revealed by this sprint was to move the hard-coded concepts in formattables to the new world of transforms and logical/physical entities, without fully making them data-driven. Once we did that, we found we had something to validate against that was much more like-for-like, instead of the massive impedance mismatch we are dealing with at present.
So this sprint we moved the majority of types in formattables into their logical or physical locations. As the story title implies, the bulk of the work was connected to moving the locator class on both C# and C++ formattables. This class had a seemingly straightforward responsibility: to build relative and full paths in the physical domain. However, it was also closely intertwined with the old-world formatters and the generation of dependencies (such as the include directives). It was difficult to unpick all of these different strands that connected the locator to the old world, and encapsulate them all inside of a transform, making use only of data available in the physical meta model and physical model, but once we achieved that all was light.
There were lots of twists and turns, of course, and we did find some cases that do not fit terribly well the present design. For instance, we had assumed that there was a natural progression in terms of projections, i.e.:
- from an external representation;
- to the simplified internal representation in the codec model;
- to the projection into the logical model;
- to the projection into the physical model;
- to, ultimately, the projection into a technical space - i.e., code generation.
As it turns out, sometimes we need to peek into the logical model after the projection to the physical model has been performed, which is not quite so linear as we'd want. This may sound slightly confusing, given that the entire point of the LPS is to have a model that combines both the logical and physical dimensions. Indeed, it is so; but what we do not expect is to have to modify the logical dimension after it was constructed and projected into the physical domain. Sadly, this is the case when computing items that require lists of project items such build files. Problems such as this made it for a tricky journey, but we somehow managed to empty out the C++ formattables model to the last few remaining types - the helpers - which we will hopefully mop up next sprint. C# is not lagging far behind, but we decided to tackle them separately now.
Move stand-alone formattables to physical/logical models
Given that the locator story (above) became a bit of a mammoth - consuming 50% of the total ask - we thought we would separate any formattable types which were not directly related to locator into its own story. As it turns out there were still quite a few, but this story does not really add much to the narrative above given that the objectives were very much the same.
Create a video series on the formattables refactor
A lot of the work for the formattables refactor was captured in a series of coding videos. I guess you'd have to be a pretty ardent fan of Dogen to find these interesting, especially as it is an 18-part series, but if you are, you can finally binge. Mind you, the recording does not cover the entirety of the formattables work, for reasons we shall explain later; at around 15 hours long, it covers just about 30% of the overall time spent on these stories (~49 hours). Table 1 provides an exhaustive list of the videos, with a short description for each one; a link to the playlist itself is available below (c.f. Video 2).
Video 2: Playlist "MASD - Dogen Coding: Formatables Refactor".
With so much taped coding, we ended up penning a few reflections on the process. These are partially a rehashing of what we had already learned (c.f. Sprint 19, section "Recording of coding sessions"), but also contain some new insights. They can be summarised as follows:
- taped coding acts as a motivating factor, for some yet to be explained reason. It's not as if we have viewers or anything, but for some reason the neo-cortex seems to find it easier to get on with work if we think that we are recording. To be fair, we already experienced this with the MDE Papers, which had worked quite well in the past, though we lost the plot there a little bit of late.
- taped coding is great for thinking through a problem in terms of overall design. In fact, it's great if you try to explain the problem out loud in simple terms to a (largely imaginary) lay audience. You are forced to rethink the problem, and in many cases, it's easier to spot flaws with your reasoning as you start to describe it.
- taped coding is not ideal if you need to do "proper" programming, at least for me. This is because it's difficult to concentrate on coding if you are also describing what you are doing - or perhaps I just can't really multitask.
In general, we found that it's often good to do a video as we start a new task, describe the approach and get the task started; but as we get going, if we start to notice that progress is slow, we then tend to finish the video where we are and complete the task offline. The next video then recaps what was done, and begins a new task. Presumably this is not ideal for an audience that wants to experience the reality of development, but we haven't found a way to do this without degrading productivity to unacceptable levels.
| Video | Description |
|---|---|
| Part 1 | In this part we explain the rationale for the work and break it into small, self-contained stories. |
| Part 2 | In this part we read the project path properties from configuration. |
| Part 3 | In this part we attempt to tackle the locator directly, only to find out that there are other types which need to be cleaned up first before we can proceed. |
| Part 4 | In this part we finish the locator source code changes, only to find out that there are test failures. These then result in an investigation that takes us deep into the tracing subsystem. |
| Part 5 | In this part we finally manage to get the legacy locator to work off of the new meta-model properties, and all tests to go green. |
| Part 6 | Yet more work on formattables locator. |
| Part 7 | In this part we try to understand why the new transform is generating different paths from the old transform and fix a few of these cases. |
| Part 8 | In this part we continue investigating incorrect paths being produced by the new paths transform. |
| part 9 | In this part we finally replace the old way of computing the full path with the new (but still hacked) transform. |
| Part 10 | In this part we start to tackle the handling of inclusion directives. |
| Part 11 | In this video we try to implement the legacy dependencies transform, but bump into numerous problems. |
| Part 12 | More work in the inclusion dependencies transform. |
| Part 13 | In this part we finish copying across all functions from the types facet into the legacy inclusion dependencies transform. |
| Part 14 | In this part we start looking at the two remaining transforms in formatables. |
| Part 15 | In this video we first review the changes that were done offline to remove the C++ locator and then start to tackle the stand-alone formatable types in the C++ model. |
| Part 16 | In this part we start to tackle the streaming properties, only to find out it's not quite as trivial as we thought. |
| Part 17 | In this video we recap the work done on the streaming properties, and perform the refactor of the C++ standard. |
| Part 18 | In this video we tackle the C++ aspect properties. |
Table 1: Individual videos on the playlist for the formattables refactor.
Assorted smaller stories
Before we decided on the approach narrated above, we tried to continue to get the data-driven approach done. That resulted in a number of small stories that progressed the approach, but didn't get us very far:
- Directory names and postfixes are PMM properties: Work done to model directory names and file name postfixes correctly in the PMM. This was a very small clean-up effort, that sadly can only be validated when we start assembly paths properly within the PMM.
-
Move
enabledandoverwriteintoenablement_properties: another very small tidy-up effort that improved the modeling around enablement related properties. - Tracing of orchestration chains is incorrect : whilst trying to debug a problem, we noticed that the tracing information was incorrect. This is mainly related to chains being reported as transforms and transforms using incorrect names due to copy-and-pasting errors.
- Add full and relative path processing to PM: we progressed this ever-so-slightly but we bumped into many problems so we ended up postponing this story for the next sprint.
- Create a factory transform for parts and archetype kinds: as with the previous story, we gave up on this one.
- Analysis on a formatables refactor: this was the analysis story that revealed the inadequacies of the present attempt of diving straight into a data-driven approach from the existing formattables code.
Presentation for APA
We were invited by the Association of Angolan Programmers (Associação dos Programadores Angolanos) to do a presentation regarding research. It is somewhat tangential to Dogen, in that we do not get into a lot of details with the code itself but it may still be of interest. However, the presentation is in Portuguese. A special shout out and thanks goes to Filipe Mulonde (twitter: @filipe_mulonde) and Alexandre Juca (twitter: @alexjucadev) for inviting me, organising the event and for their work in APA in general.
 Video 3: Talk: "Pesquisa científica em Ciência da Computação" (Research in Computer Science).
Video 3: Talk: "Pesquisa científica em Ciência da Computação" (Research in Computer Science).
Resourcing
Sadly, we did not improve our lot this sprint with regards to proper resource attribution. We created one massive story, the locator work, at 50%, and a smattering of smaller stories which are not very representative of the effort. In reality we should have created a number of much smaller stories around the locator work, which is really more of an epic than a story. However, we only realised the magnitude of the task when we were already well into it. At that point, we did split out the other formattable story, at 10% of the ask, but it was a bit too little too late to make amends. At any rate, 61% of the sprint was taken with this formattables effort, and around 18% or so went on the data-driven effort; on the whole, we spent close to 81% on coding tasks, which is pretty decent, particularly if we take into account our "media" commitments. These had a total cost of 8.1%, with the lion's share (6.1%) going towards the presentation for APA. Release notes (5.5%) and backlog grooming (4.7%) were not particularly expensive, which is always good to hear. However, what was not particularly brilliant was our utilisation rate, dwindling to 35% with a total of 42 elapsed days for this sprint. This was largely a function of busy work and personal life. Still, it was a massive increase over the previous sprint's 20%, so we are at least going on the right direction.
 Figure 2: Cost of stories for sprint 28.
Figure 2: Cost of stories for sprint 28.
Roadmap
We actually made some changes to the roadmap this time round, instead of just forwarding all of the items by one sprint as we customarily do. It does see that we have five clear themes to work on at present so we made these into entries in the road map and assigned a sprint each. This is probably far too optimistic, but nonetheless the entire point of the roadmap is to give us a general direction of travel rather than oracular predictions on how long things will take - which we already know too well is a futile effort. What is not quite so cheerful is that the roadmap is already pointing out to March 2021 as the earliest, most optimistic date for completion, which is not reassuring.


Binaries
You can download binaries from either Bintray or GitHub, as per Table 1. All binaries are 64-bit. For all other architectures and/or operative systems, you will need to build Dogen from source. Source downloads are available in zip or tar.gz format.
| Operative System | Format | BinTray | GitHub |
|---|---|---|---|
| Linux Debian/Ubuntu | Deb | dogen_1.0.28_amd64-applications.deb | dogen_1.0.28_amd64-applications.deb |
| OSX | DMG | DOGEN-1.0.28-Darwin-x86_64.dmg | DOGEN-1.0.28-Darwin-x86_64.dmg |
| Windows | MSI | DOGEN-1.0.28-Windows-AMD64.msi | DOGEN-1.0.28-Windows-AMD64.msi |
Table 2: Binary packages for Dogen.
Note: The OSX and Linux binaries are not stripped at present and so are larger than they should be. We have an outstanding story to address this issue, but sadly CMake does not make this a trivial undertaking.
Next Sprint
The goals for the next sprint are:
- to finish formattables refactor;
- to start implement path and dependencies via PMM.
That's all for this release. Happy Modeling!
v1.0.27
3 years ago Abandoned freighter North of Namibe, Angola. (C) Alfred Weidinger, 2011
Abandoned freighter North of Namibe, Angola. (C) Alfred Weidinger, 2011
Introduction
We've been working on Dogen for long enough to know that there is no such thing as an easy sprint; still, after a long sequence of very challenging ones, we were certainly hoping for an easier ride this time round. Alas, not to be. Due to never ending changes in personal circumstances, both with work and private life, Sprint 27 ended up being an awfully long sprint, with a grand total of 70 elapsed days rather than the 30 or 40 customary ones. To make matters worse, not only was it a bit of a fragmented sprint in time - a bit stop-start, if we're honest - but it was also somewhat disjointed in terms of the work as well. One never ending story occupied the bulk of the work, though it did have lots of challenging variations; and the remainder - a smattering of smaller stories - were insufficient to make any significant headway towards the sprint goals. Ah, the joys of working on such a long, open-ended project, hey. And to round it all up nicely, we weren't able to do a single MDE Paper of the Week (PofW); there just weren't enough hours in the day, and these were the first ones to fall by the wayside. They will hopefully resume at the usual cadence next sprint.
The picture may sound gloomy, but do not fear. As we shall see in these release notes, we may have not achieved what we set out to achieve originally, but much else was achieved nevertheless - giving us more than sufficient grounds for our unwavering developer optimism. Omnia mutantur, nihil interit, as Ovid would say.
User visible changes
This section normally covers stories that affect end users, with the video providing a quick demonstration of the new features, and the sections below describing them in more detail. As there were no user facing features, the video discusses the work on internal features instead.
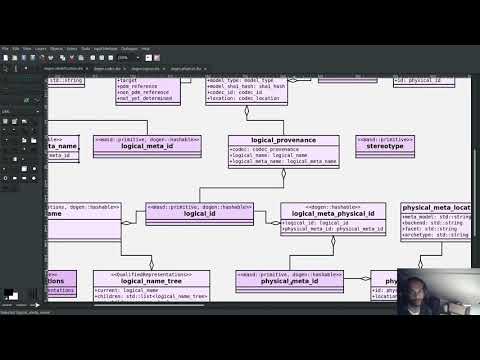 Video 1: Sprint 27 Demo.
Video 1: Sprint 27 Demo.
Development Matters
In this section we cover topics that are mainly of interest if you follow Dogen development, such as details on internal stories that consumed significant resources, important events, etc. As usual, for all the gory details of the work carried out this sprint, see the sprint log.
Significant Internal Stories
The story arc of the last few sprints has been centred around reducing the impedance mismatch between Dogen's source code and the conceptual model for the Logical-Physical Space (at times called the LPS). In turn, the LPS stemmed from the work we were doing in cleaning up the text models - in particular the C++ and C# backends; in other words, what we have been trying to achieve for some time now is to remove a large amount of hard-coding and just plain old bad modeling in those two models. For a throw back, see the section Towards a physical Model in the release notes of Sprint 23. At any rate, every time we try to address what appears to be a fairly straightforward issue, we soon realise it has big implications for the LPS, and then we end up going on yet another wild goose chase to try to find a solution that is in keeping with the conceptual model. Once its all resolved, we then go back to the task at hand and move forwards by a metre or so... until we find the next big issue. It has been this way for a while and sadly this sprint was no different. The main story that consumed just under 51% of the ask was the creation of a new model, the identification model, which was not directly aligned with the sprint goal. We then worked on a series of smaller stories that were indeed aligned with the goal, but which also required what appears to be a never ending series of mini-spikes. Lets have a quick look at all of these stories.
Create an identification model
The graph of relationships between the different models in Dogen has been a source of concern for a very long time, as this blog post attests. We are facing the typical engineering trade-offs: on one hand, we do not want cycles between models because that severely impairs testability and comprehension; on the other hand, we do not want a small number of "modelets", which have no well-defined responsibilities beyond simply existing to break up cycles. One such bone of contention has been the strange nature of the relationship between the logical and physical models. To be fair, this tangled relationship is largely a byproduct of the fundamental nature of the LPS, which posits that the logical-physical space is one combined entity. Predictably, these two models have a lot of references to each other:
- the
logicalmodel contains inside of it a model of thephysicalentities, which is use to code-generate these entities. - the
physicalmodel represents regions of the LPS for a given point in the logical axis of the LPS, and therefore needs to reference thelogicalmodel.
Until this sprint the problem had been resolved by duplicating types from both models. This was not an ideal approach but it did address both the problem of cycles as well as avoiding the existence of modelets. As we continued to move types around on our clean ups, we eventually realised that there are only a small number of types needed for these cross-model relationships to be modeled correctly; and as it turns out, pretty much all of these types seem to be related in one way or another to the "identification" of LPS entities. Now, this is not completely true - a few types are common but not really related to identification; but in the main, the notion holds sufficiently true. Therefore we decided to create a model with the surprising name of identification and put all the types in there. So far so good. This could have possibly been done with a simple set of renames, which would not take us too long. However, we were not content and decided to address a second long standing problem: avoid the use of "strings" everywhere for identification. If you've watched the Kevlin Henney classic presentation Seven Ineffective Coding Habits of Many Programmers, you should be aware that using strings and other such types all over the place is a sign of weak domain modeling. If you haven't, as with all Henney talks, I highly recommend it. At any rate, for the purposes of the present exercise, the Thomas Fagerbekk summary suffices:
4. We don't abstract enough.
Use your words, your classes, your abstractions. Don't do Strings, Lists and integers all over the place. [...] Instead, think about how you can communicate the meaning of the objects in the domain. Kevlin pulls up a wordcloud of the words used most frequently in a codebase (about 38-minute mark in the video): The most common words should tell you something about what the codebase is about. [...] A bad example shows List, Integer, String and such basic structures as the most common words. The better example has PrintingDevice, Paper, Picture. This makes the code less readable, because such generic variables can represent so many different things.
Now, if you have even a passing familiarity with Dogen's source code, you could not have helped but notice that we have a very large number of distinct IDs and meta-IDs all represented as strings. We've known for a long while that this is not ideal, not just because of Henney's points above, but also because we often end up using a string of "type" A as if it were a string of "type" B (e.g. using a logical meta-model ID when we are searching for a physical ID, say). These errors are painful to get to the bottom of. Wouldn't it be nice if the type system could detect them up front? Given these are all related to identification, we thought, might as well address this issue at the same time. And given Dogen already has built-in support for primitive types - that is, wrappers for trivial types such as string - it did seem that we were ready to finally make this change. Designing the new model was surprisingly quick; where the rubber met the road was on refactoring the code base to make use of the shiny new types.
Video 2: Part 1 of 3 of the series of videos on the Identification Refactor.
As you can imagine, and we now know first hand, modifying completely how "identification" works across a large code base is anything but a trivial exercise. There were many, many places where these types were used, sometimes incorrectly, and each of these places had its own subtleties. This change was one long exhausting exercise of modifying a few lines of code, dealing with a number of compilation errors and then dealing with many test failures. Then, rinse, repeat. Part of the not-exactly-fun-process was recorded on a series of videos, available on the playlist MASD - Dogen Coding: Identification Refactor:
- MASD - Dogen Coding: Identification Refactor - Part 1
- MASD - Dogen Coding: Identification Refactor - Part 2
- MASD - Dogen Coding: Identification Refactor - Part 3
These videos catch a tiny sliver of the very painful refactor, but they are more than sufficient to give a flavour of the over 42 hours of "joy" we went through. Having said that, in the end we did experience moments of non-sarcastic joy because the code base is now so much better for it. If nothing else, at least now a word cloud will not have std::string as its most common type - or so one would hope; the hypothesis was not put to the test, probably out of fear. At any rate, we felt this approach was such an improvement that we started to think of all the other types of patterns we have which share similarities with primitives; and how they could also benefit from a similar clean up. However, the reverie quickly ended; at this stage, these are but wishful dreams, a mere gathering of requirements for that one day where our copious free time will allow us to take on a side project of such magnitude. Once backlogged, the dreams quickly faded away and we were back to the task at hand.
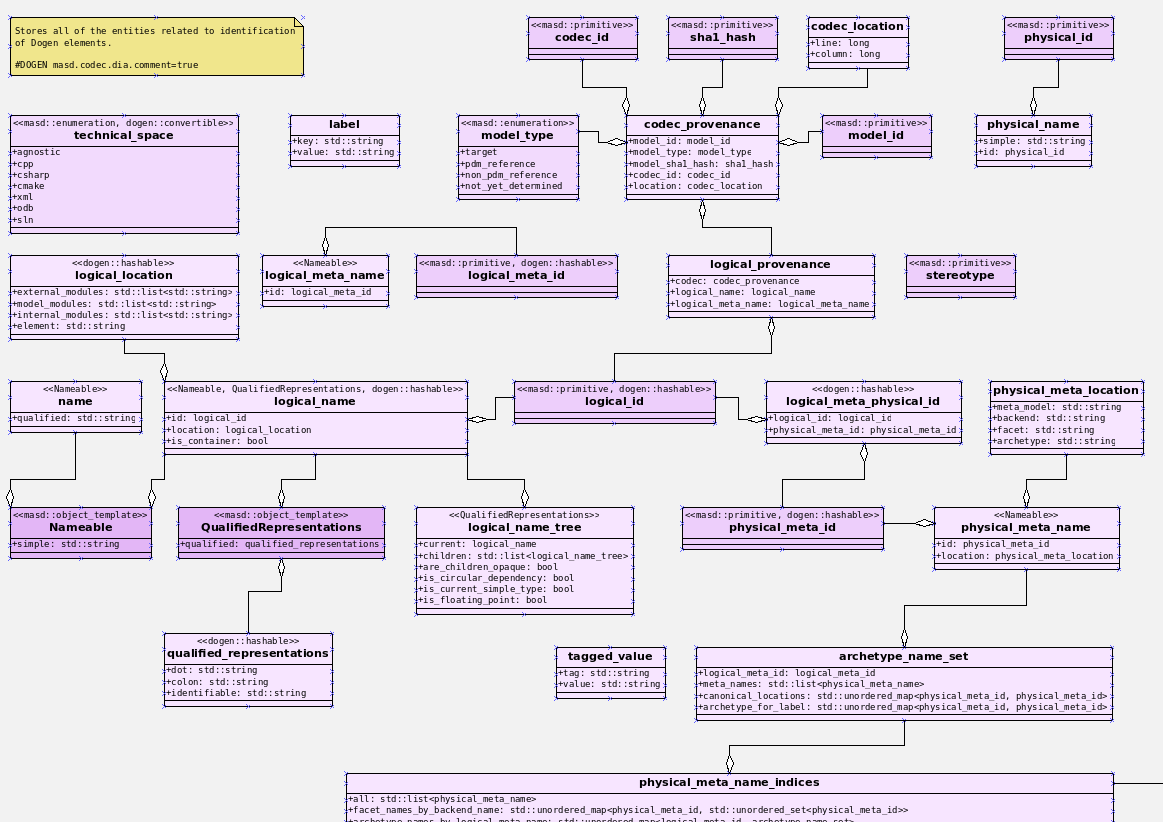 Figure 1: The Dogen Identification model.
Figure 1: The Dogen Identification model.
Rename injection to codec
A small but very helpful change - nay, instrumental change - on our never ending quest to clean up the conceptual model was the renaming of the injection models to codec. In order to understand its importance, we need to go back in time via our old favourite imagine of the Dogen pipeline:
Figure 2: The Dogen pipeline, circa Sprint 12.
Almost every box in this diagram has changed name, as our understanding of the domain evolved, though their functional roles remained fairly constant. This sprint it was the turn of the "injection" box. This happened because we begun to realise that there are several "forces" at play:
- the terms injection and extraction imply the notion that elements are to be projected with regards to a technical space; when into a technical space, then its an injection, and when out of a technical space, its an extraction.
- the process of performing the projection can be done by the same set of classes. That is, it's often convenient to declare an encoder and a decoder next to each other because the coding and decoding is functionally very similar.
- the generation of text from model elements is considered an extraction, as is the plain conversion of models of one type to another. However, given there is a very well understood set of terms regarding the transformation of model elements into text - e.g., model-to-text transforms - its not insightful to call this an extraction.
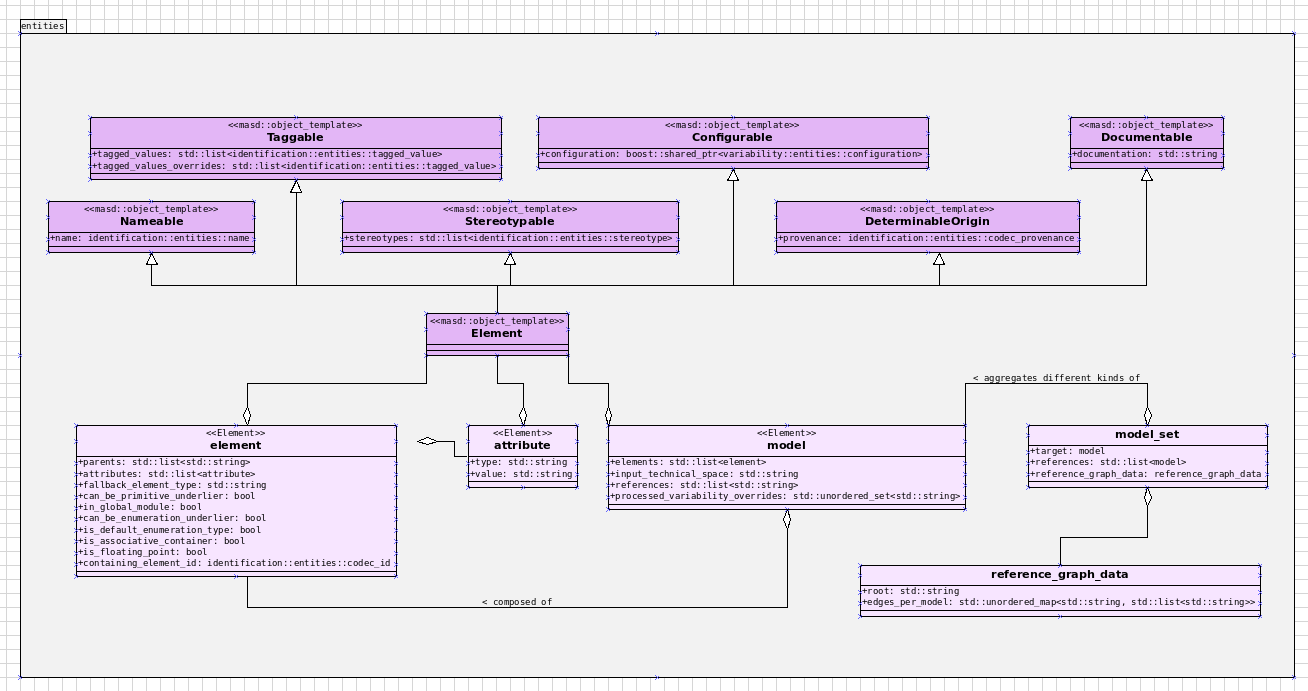 Figure 3: the Dogen Codec model.
Figure 3: the Dogen Codec model.
When we took all this factors into account, it became obvious we could not call these models "injection" or "injectors", because that is not all that they do. We debated calling them "inxtractors" given they were both injectors and extractors, but quickly realised we were entering the terminological domain of "modems" (i.e., "modulators" and "demodulators") and so we settled on calling them "codecs" because they encode and decode elements from the format of one technical space to the format of another. Once the light-bulb went off, all was light and the rename itself was fairly trivial.
Assorted conceptual model clean ups
A number of small stories worked on were directly or indirectly related to conceptual model clean ups - that is, the polishing of the code to make it coherent with our present understanding of the conceptual model. These were:
- Create a logical to physical projector: In the past we had transforms and adapters which had bits of the projection work. Now that we understand projections much better, it makes sense to have dedicated classes responsible for the projection.
-
Clean up the logical-physical model: A bit of a grab-bag story related to all sorts of miscellaneous clean up work done on the
textandphysicalmodels. Whilst the story itself wasn't huge (7% of the ask), it delivered immense amounts of clarity. As an example, instead of duplicating properties from both thelogicalandphysicalmodels in the text model, we now have modeled it very clearly as a representation of LPS, in a way that is completely transparent (c.f., Figure 4). We also finally renamed theartefact_setto a physicalregion, which is in keeping with the LPS, as well as the removal of a large number of duplicate types and properties in the physical model.
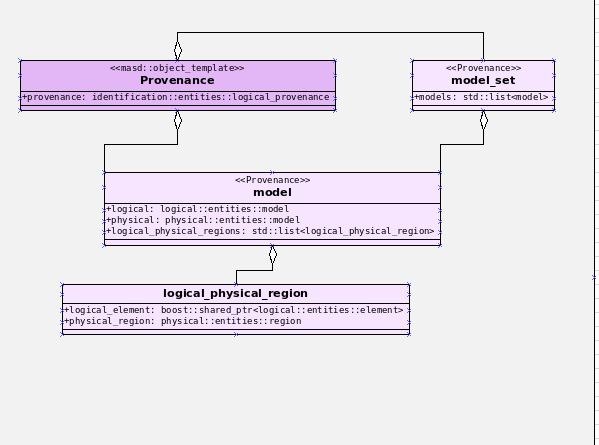 Figure 4: The refactored Dogen Text model.
Figure 4: The refactored Dogen Text model.
-
Empty path ID error in logs: yet another clean up story, this entailed understanding why we were producing so many weird and wonderful warnings in the log files related to empty paths. Turns out we had missed out some of the logic regarding the filtering out of reference models prior to generation - in particular the Platform Definition Models or PDMs - which resulted in us trying to look for paths where none exist. With this clean up we have a proper transform to filter out all artefacts and even whole regions of physical space which are not supposed to exist at the point at which we write files to the file-system (
remove_regions_transform). -
Add instances of physical meta-model elements: This story was a bit of a mind-bender in terms of the LPS. Thus far we have relied on the usual meta-model taxonomy as prescribed by the OMG. However, with this sprint we started to break with the nice clear cut hierarchical model because we noticed that there is in fact a layer in between the physical meta-model (PMM) and the physical model (PM). This layer comes to be because the PMM is configurable via the variability elements that Dogen supports. This variability means that the actual PMM a given model has could be completely different from another model. Now, of course, we only allow a very restricted form of configuration at this level, but nonetheless its large enough that it requires a large amount of supporting data structures. As we did not quite know what to call these data structures, we decided to go for the suitably incorrect postfix of
_properties. Henney would not have been proud, clearly.
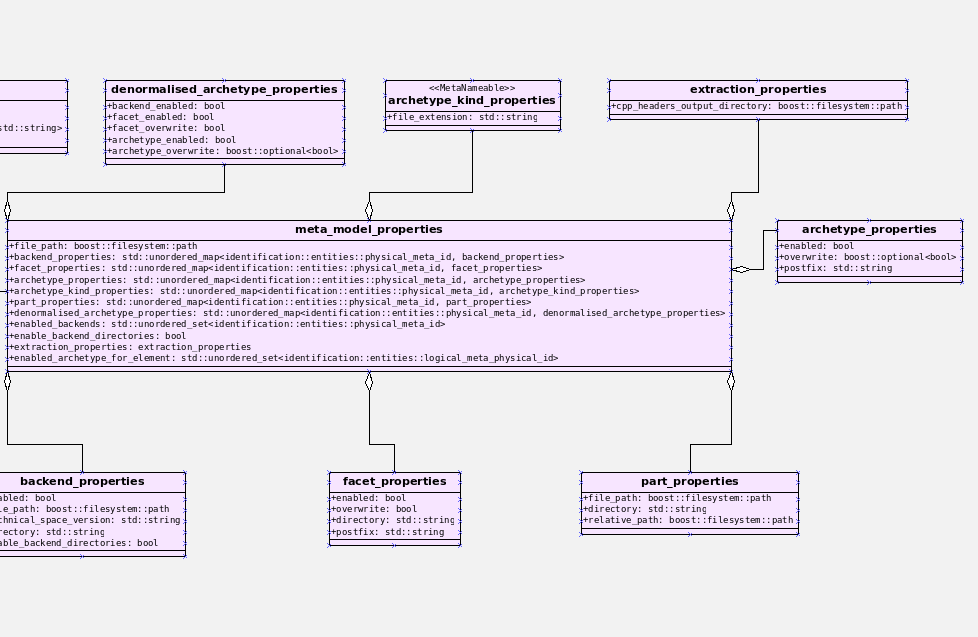 Figure 5: Dogen meta-model properties.
Figure 5: Dogen meta-model properties.
- Add dependencies to artefacts: work was started but not completed on adding dependencies to artefacts and archetypes, but we then ran into all of the clean ups mentioned above. It shall continue next sprint, where we will hopefully describe this story properly.
- Add full and relative path processing to PM: similarly to the previous story, this is a long standing story which is part of the clean up arc. Each sprint we tend to do a bit of progress on it, but sadly, it also generates a large amount of spikes, meaning we never tend to get very far. When we do complete it, we shall provide a complete description of this endeavour.
- Other minor stories: Stories comprising 0.1% to 0.3% of the ask were also completed, but were very minor. For example, we toyed with removing split project support, but in the end concluded this did not provide the bang we expected and, in the end, rolled back the changes.
Resourcing
As we've already mentioned, resourcing this sprint was completely dominated by one big ol' massive story: updating the entire code base to use the new identification model. Weighing in at 51%, it amply demonstrates our inability to break up large stories into small, digestible pieces. In reality, we probably should have had an epic encompassing around 3 or 4 stories, one for each chunk of the pipeline - e.g. injection, logical, physical, etc. As it was, we bundled all the work into one massive story, which is not ideal for the purposes of analysis. For example, the logical work was the largest of them all, but that is not visible through the lens of the data. OK, so the breaking down of stories was not exactly amazing, but on the plus side we did spend 82% of the total ask on "real engineering", as opposed to the other 18% allocated to "housekeeping". These were scattered over release notes (8.8%), backlog management (3%), demos (just under 1%) and addressing issues with nightlies, at a costly 5.3%. Finally, what was truly not ideal was our utilisation rate of 20% - the lowest since records begun in Sprint 20. Sadly, this particular metric is only a function of our desires to a small degree, and much more a function of the environment we operate in, so there is only so much we can do to optimise it. Overall, and given the constraints, one would have to conclude this was a pretty efficient sprint, though we do hope the utilisation rate can start to climb to number levels in the near future.
 Figure 6: Cost of stories for sprint 27.
Figure 6: Cost of stories for sprint 27.
Roadmap
Our oracular project plan suffered the traditional updates - that is, move everything forward by a sprint and pray next sprint delivers some action on the sprint goals. To be perfectly honest, there is a very clear pattern asserting itself, which is to say the clean up associated with the LPS is extremely difficult and utterly impossible to estimate. So the always dubious project plan has become of even less value. But since it also works as a roadmap, we'll keep nudging it along - just don't read too much (or anything, really) into those dates. We never did.


Binaries
You can download binaries from either Bintray or GitHub, as per Table 1. All binaries are 64-bit. For all other architectures and/or operative systems, you will need to build Dogen from source. Source downloads are available in zip or tar.gz format.
| Operative System | Format | BinTray | GitHub |
|---|---|---|---|
| Linux Debian/Ubuntu | Deb | dogen_1.0.27_amd64-applications.deb | dogen_1.0.27_amd64-applications.deb |
| OSX | DMG | DOGEN-1.0.27-Darwin-x86_64.dmg | DOGEN-1.0.27-Darwin-x86_64.dmg |
| Windows | MSI | DOGEN-1.0.27-Windows-AMD64.msi | DOGEN-1.0.27-Windows-AMD64.msi |
Table 1: Binary packages for Dogen.
Note: The OSX and Linux binaries are not stripped at present and so are larger than they should be. We have an outstanding story to address this issue, but sadly CMake does not make this a trivial undertaking.
Next Sprint
The goals for the next sprint are:
- to finish PMM generation;
- to implement locator and dependencies via PMM.
That's all for this release. Happy Modeling!
v1.0.26
3 years ago Bentiaba river, Namibe, Angola. (C) 2016 O Viajante.
Bentiaba river, Namibe, Angola. (C) 2016 O Viajante.
Introduction
Welcome to yet another Dogen sprint! This one was a bit of a Klingon Release, if we've ever seen one. Now, I know we did say Sprint 25 was a hard slog, but on hindsight 'twas but a mere walk in the park when compared to what was to come. Sprint 26 was at least twice as hard, lasted almost twice as long in terms of elapsed-time, had around 20% extra resourcing compared to what we usually allocate to a sprint and involved such a degree of abstract thinking - given our modest abilities - we often lost the plot altogether and had to go back to first principles. To add insult to injury, after such an intense a bout of coding, we still ended up miles off of the original sprint goal, which was clearly far too ambitious to begin with. For all of its hardships, the sprint did end on a high note when we finally had time to reflect on what was achieved; and the conceptual model does appear to be nearing its final shape - though, of course, you'd be forgiven for thinking you've heard that one before. Alas, some things never change.
But that's quite enough blabbering - let's look at how and where the action took place.
User visible changes
This section covers stories that affect end users, with the video providing a quick demonstration of the new features, and the sections below describing them in more detail. As there were only two small user facing features, the video also discusses the work on internal features.
 Video 1: Sprint 26 Demo.
Video 1: Sprint 26 Demo.
Archetype Factories and Transforms
The main story visible to end users this sprint is deeply connected to our physical model changes, so it requires a fair amount of background in order to make sense of it. Before we proceed, we must first go through the usual disclaimers, pointing out that whilst this is technically a user facing story - in that any user can make use of this feature - in practice, it's only meant for those working in Dogen's internals - i.e. generating the code generator. It's also worthwhile pointing out that Dogen uses a generative architecture, where we try to generate as much as possible of Dogen using Dogen; and that we want the generated portion to increase over time. With those two important bits of information in hand, let's now take a step back to see how it all fits together.
MASD's logical model contains a set of modeling elements that capture the essential characteristics of the things we want to code-generate. Most of these elements are familiar to programmers because our targets tend to be artefacts created by programmers; these are classes, methods, enumerations and the like, the bricks and mortar we typically associate with the coding activity. However, from a MASD perspective, the story does not end there - and hence why we used the term "things". Ultimately, any artefact that contributes to a software product can be modeled as a logical entity, provided it exhibits "commonalities" which can be abstracted in order to recreate it via code generation. The fact that we model programming constructs is seen as more of a "coincidence" than anything else; what we really care about is locating and extracting certain kinds of structural patterns on files. One way to think about this is that we see some files as higher-dimensional structures that embed lower dimensional structures, which contain enough information to enable us to recreate the higher-dimensional structure. Our quest is to find cases where this happens, and to add the lower dimensional structures to our logical model. It just so happens that those lower dimensional structures are often programming constructs.
 Figure 1: Archetypes representing M2T transforms in
Figure 1: Archetypes representing M2T transforms in text.cpp model, on Sprint 25.
MASD provides a separation between logical entities and their eventual physical representation as a file. The mapping between the logical domain and the physical domain is seen as a projection through these spaces; one logical element projects to zero, one or many physical elements. In the physical domain, files are abstracted into artefacts (the physical model or PM), and each artefact is an instance of an archetype (the physical meta model or PMM). These are related in very much the same way a class and an object are: the artefact is an instance of an archetype. Until recently, we had to tell Dogen about the available archetypes "by hand" (a rough approximation): each text template had some boilerplate to inject the details of the archetype into the framework. After a great deal of effort, Sprint 25 finally brought us to a point where this code was generated by Dogen in the spirit of the framework. This was achieved by treating archetypes themselves as logical concepts, and providing physical projections for these logical elements as we do for any other logical element. Which neatly brings us to the present.
Archetypes had a single projection that contained two distinct bits of functionality:
- Telling the system about themselves: the above mentioned registration of the archetype, which is used by a set of transforms to generate the PMM.
- Providing an M2T transform: each archetype takes an associated logical element and generates its representation as an artefact.
The more we thought about it, the more it seemed strange that these two very different concerns were bundled into the same archetype. After all, we don't mix say serialisation with type definition on the same archetype, and for good reason. After some deliberation, we concluded it was there only for historical reasons. So this sprint we decided to project logical representations of some physical meta-model elements - e.g., backend, facet, archetype - onto two distinct physical archetypes:
- Factory: responsible for creating the physical meta-model element for the purposes of the PMM.
- Transform: responsible for the M2T transform.
 Figure 2: Archetypes after the split in the present sprint.
Figure 2: Archetypes after the split in the present sprint.
It all seemed rather logical (if you pardon the pun), until one started to implement it. Trouble is, because we are knee-deep in the meta-land, many things end up in surprising places when one takes them to their logical consequences. Take archetypes for example. There is an archetype that represents the archetype factory itself, as there is an archetype that represents the archetype transform itself too, and there are permutations of the two as well - leading us to very interesting names such as archetype_class_header_factory_factory, archetype_class_header_transform_transform and the like. At first glance, these appear to be straight out of Spolsky's Factory Factory Factory parable - a threshold that, when reached, normally signals a need to halt and rethink the design. Which we did. However, in our defence, there is some method to the madness. Let's dissect the first name:
- the logical element this archetype maps to is
archetype; - the particular item it is interested in is a C++
class_header; - but its not just any old archetype class header, its the one specifically made for the
factoryof the archetype; - which, as it turns out, its also the factory which generates the
factoryof the archetype.
I guess every creator of a "framework" always comes up with justifications such as the above, and we'd be hard-pressed to explain why our case is different ("it is, honest guv!"). At any rate, we are quite happy with this change as its consistent with the conceptual model and made the code a lot cleaner. Hopefully it will still make sense when we have to maintain it in a few years time.
Add Support for CSV Values in Variability
The variability model is a very important component of Dogen that often just chugs along, with only the occasional sharing of the spotlight (Sprint 22). It saw some minor attention again this sprint, as we decided to add a new value type to the variability subsystem. Well, two value types to be precise, both on the theme of CSV:
-
comma_separated: allows meta-data values to be retrieved as a set of CSV values. These are just a container of strings. -
comma_separated_collection: allows meta-data values to be collections ofcomma_separatedvalues.
We probably should have used the name csv for these types, to be fair, given its a well known TLA. A clean up for future sprints, no doubt. At any rate, this new feature was implemented to allow us to process relation information in a more natural way, like for example:
#DOGEN masd.physical.constant_relation=dogen.physical.helpers.meta_name_factory,archetype:masd.cpp.types.class_header
#DOGEN masd.physical.variable_relation=self,archetype:masd.cpp.types.archetype_class_header_factory
For details on relations in the PMM, see the internal stories section.
Development Matters
In this section we cover topics that are mainly of interest if you follow Dogen development, such as details on internal stories that consumed significant resources, important events, etc. As usual, for all the gory details of the work carried out this sprint, see the sprint log.
Ephemerides
This sprint saw the 12,000th commit to Dogen. To our displeasure, it also saw the implementation of the new GitHub design, depicted in Figure 3.
 Figure 3: Dogen's GitHub repo at the 12,000th commit.
Figure 3: Dogen's GitHub repo at the 12,000th commit.
Milestones
No milestones where reached this sprint.
Significant Internal Stories
This sprint had the ambitious goal of replacing the hard-coded way in which we handle relationships in both the C++ and C# model with a PMM based approach. As it turns out, it was an extremely ambitious goal. There were two core stories that captured this work, each composed with a large number of small sub-stories; we grouped these into the two sections below.
Add Relations Between Archetypes in the PMM
It has been known for a long time that certain kinds of relationships exist at the archetype level, regardless of the state of the logical modeling element we are trying to generate. In other words, an archetype can require a fixed set of logical model elements, projected to a given archetype (e.g., say the type definition). For instance, when you implement an archetype, you may find it needs some specific "platform services" such as logging, iostreams, standard exceptions and so forth, which must be present regardless of the state of the logical model elements processed by the M2T transform. This is somewhat of a simplification because sometimes there is conditionality attached to these relations, but its a sufficient approximation of the truth for the present purposes. These we shall name constant relations, as they do not change with regards to the logical model element.
In addition, archetypes also have relations with other archetypes based on the specific contents of the logical model element they are trying to generate; for example, having an attribute may require including one or more headers for the logical model elements as given by the attribute's type - e.g., std::unordered_map<std::string, some_user_type> requires unordered_map and string from the std model, as well as some_user_type from the present model; or an archetype may require another archetype like, for example, a class implementation will always need the class header. In the first case we have an explicit relation, whereas in the latter case its an implicit relation, but both of these fall under the umbrella of variable relations because they vary depending on the data contained in the logical model element. They can only be known for sure when we are processing a specific model.
Up to now, we have modeled the projection of relations from the logical dimension into the physical dimension by allowing archetypes themselves to "manually" create dependencies. This meant that we pushed all of the problem to "run time", regardless of whether the relations are variable or constant; worse, it also means we've hard-coded the relations in a way that is completely transparent to the models - with "transparent" here having a bad connotation. Listing 1 provides an example of how these are declared. This approach is of course very much in keeping with Dogen's unspoken motto, shamelessly stolen elsewhere, of "first hard-code and get it to work in any way possible, as quickly as possible, then continuously refactor". Sadly, now has come the time for the second part of that motto, and that is what this story concerns itself with.
const auto io_arch(transforms::io::traits::class_header_archetype_qn());
const bool in_inheritance(o.is_parent() || o.is_child());
const bool io_enabled(builder.is_enabled(o.name(), io_arch));
const bool requires_io(io_enabled && in_inheritance);
const auto ios(inclusion_constants::std::iosfwd());
if (requires_io)
builder.add(ios);
using ser = transforms::serialization::traits;
const auto ser_fwd_arch(ser::class_forward_declarations_archetype_qn());
builder.add(o.name(), ser_fwd_arch);
const auto carch(traits::canonical_archetype());
builder.add(o.transparent_associations(), carch);
const auto fwd_arch(traits::class_forward_declarations_archetype_qn());
builder.add(o.opaque_associations(), fwd_arch);
const auto self_arch(class_header_transform::static_archetype().meta_name().qualified());
builder.add(o.parents(), self_arch);
using hash = transforms::hash::traits;
const auto hash_carch(hash::traits::canonical_archetype());
builder.add(o.associative_container_keys(), hash_carch);
Listing 1: Fragment of inclusion dependencies in the class_header_transform.
The reason why we do not want relations to be transparent is because the graph of physical dependencies contains a lot of valuable information; for example, it could tell us if the user has decided to instantiate an invalid configuration such as disabling the hash facet and then subsequently creating a std::unordered_map instance, which requires it. In addition, we always wondered if there really was a reason to have a completely separate handling of relations for C++ and C#, or whether it was possible to combine the two into a unified approach that took into account the gulf of differences between the languages (e.g., #include of files versus using of namespaces). So the purpose of this story was to try to bring relations into the PMM as first class citizens so that we could reason about them, and then to generate the physical specificities of each technical space from this abstraction. With this release we have done the first of these steps: we have introduced all of the machinery that declares relations as part of the archetype factory generation, as well as all the paraphernalia of logical transforms which process the meta-data in order to bring it into a usable form in the physical domain. It was a very large story in of itself, but there were also a large number of smaller stories that formed the overall picture. These can be briefly summarised as follows:
- Analysis on solving relationship problems: Much of the work in finding a taxonomy for the different relation types came from this story, as well as deciding on the overall approach for modeling them in the logical and physical models.
-
Create a TS agnostic representation of inclusion: Due to how we hard-coded relations, we needed to extract the requirements for the C++ Technical Space in a form that did not pull in too much C++-specific concepts. We've had the notion that some archetypes are "non-inclusive", that is to say, they generate files which we think cannot be part of any relation (e.g. inclusion of a
cppfile is not allowed). In this story we tried to generalise this notion. -
Use PMM to compute
meta_name_indices: As part of the PMM clean-up, we want to start using it as much as possible to generate all of the data structures that we are at present hard-coded. This story was one such clean-up, which consolidated a lot of dispersed infrastructure into the PMM. -
Add labels to archetypes: In the existing implementation we have the notion of "canonical archetypes". These exist so that when we have a logical model element and require the archetype that contains its type definition, we can "resolve" it to the appropriate archetype depending on the logical meta-type; e.g.
enum_header,class_header, and so forth. Labels were designed as generalisation of this mapping infrastructure, so that we can have arbitrary labels, including the somewhat more meaningfultype_definition. -
Analysis on archetype relations for stitch templates: Stitch templates are their own nest of wasps when it comes to relations. We incorrectly allowed templates to have their own "inclusion" system via the
<#@ masd.stitch.inclusion_dependency="x.hpp">directive. This seemed really clever at the time, but in light of this analysis, it clearly suffers from exactly the same issues as the regular M2T transforms did - we have no way of knowing what these templates are pulling in, whether those models are available and so forth. With this analysis story we found a generalised way to bring in relations from stitch templates into the fold. However, the implementation will be no easy feat. - Analysis on reducing the number of required wale keys: Whilst we were looking at stitch it seemed only logical that we also looked at our other templating engine, wale (really, a poor man's implementation of mustache, which we will hopefully replace at some point). It seems obvious that we have far too many keys being passed in to our wale templates, and that the required data is available in the PMM. This story pointed out which bits of information can already be supplied by the PMM. We need a follow up implementation story to address it.
- Analysis on implementing containment with configuration: this story provides a much easier way to handle enablement, as opposed to the pairs of transforms we have at present that handle first a "global configuration" and then a "local configuration". With the analysis in this story we could "flatten" these into a single configuration which could then be processed in one go. However, the implementation story for this analysis will probably have to remain in the backlog as its not exactly a pressing concern.
-
Merge kernel with physical meta-model: We originally had the notion of a "kernel", which grouped backends, facets and archetypes. However, we still don't really have a good use case for having more than one kernel. With this story we deprecated and removed the
kernelmeta-entity and flattened the PMM. We can always reintroduce it if a use case is found. -
Move templating aspects of archetype into a generator type: Due to the complexity of having relations for the archetype as well as relations for the templates, we factored out the templating aspects of the archetype into a new logical entity called
archetype_text_templating. This made the modeling a bit more clearer, as opposed to names such as "meta-relations" that had been tried before. This story was further complemented by "Rename archetype generator" where we changed the name to its present form. - Remove traits for archetypes: With the rise of the PMM, we no longer need to hard-code archetype names via the so-called "traits". We started removing some of these, but many of the pesky critters still remain.
-
Convert
wale_template_referenceto meta-data: Archetypes always had the ability to reference wale templates, as well as containing a stitch template. Due to some misguided need for consistency, we modeled both stitch template and the reference to a wale template as attributes. However, the net result was a huge amount of duplication, given that almost all archetypes use one of two wale templates. The problem should be fairly evident in Figure 1, even though it only shows a narrow window of thetext.cppmodel. With this story we moved this field to meta-data, meaning we can now use the profiling system to our advantage and therefore remove all duplication. Figure 2 depicts the new look. - Archetype kind and postfix as parts of a larger pattern: More analysis trying to understand how we can reconstruct file paths from the generalised elements we have in PMM. We tried to see if we can model these using the new labelling approach, with moderate success. The implementation story for this analysis is to follow, likely next sprint.
- Split physical relation properties: Trivial story to improve the modeling of relations on the physical domain. These now have its own top-level class.
{kind=link}
{kind=link}
All of these disparate stories molded the logical and physical models into containing the data needed to handle relations. After all of this work, we just about got to the point where we were trying to generate the relations themselves; and then we realised this task could not be completed until we resolved some key modeling errors of data types that really belonged in the physical domain but were unfortunately located elsewhere. So we downed our tools and started work on the next story.
Create an Archetype Repository in Physical Model
This story started with very good intentions but quickly became a dishevelled grab-bag of refactoring efforts. The main idea behind it was that we seem to have two distinct phases of processing of the physical model:
- the first phase happens during the logical to physical projection; at this point we need to perform a number of transforms to the physical model, but we are not quite yet ready to let go of the logical model as we still need the combined logical-physical space in order to perform the M2T transforms.
- the second phase happens once we have the stand alone physical model. This is fairly straightforward, dealing with any post-processing that may be required.
Our key concern here is with the first phase - and hopefully you can now see how this story relates to the previous one, given that we'd like to stick the processing of relations somewhere in there. Whilst it may be tempting to create an instance of the physical model for the first phase, we would then have to throw it away when we resume the guise of the logical-physical space in dogen.text. Besides, we did not really need a full blown physical model instance; all that is required is a set of artefacts to populate. And with this, the notion of the "artefact repository" was born. Whilst we were doing so, we also noticed something else that was rather interesting: the logical-physical space deals mainly with planes of the physical space that pertain to each individual modeling element (as covered by the story "Add hash map of artefacts in physical model"). We had originally incorrectly called these planes "manifolds", but subsequent reading seems to imply they are just 1D planes of a 2D space (see Manifolds: A Gentle Introduction). Once we understood that, we then refactored both the artefact repository as well as the physical model to be implemented in terms of these planes - which we have named artefact_set for now, though perhaps the name needs revisiting.
It took some doing to put the artefact repository and the plane approach in, but once it was indeed in, it made possible a great number of cleanups that we had been trying to do for many sprints. In the end, we were finally able to move all physical concepts that had been scattered around logical and text models - at one point we generated over 10 temporary non-buildable commits before squashing it into one monstrous commit. Though some further refactoring is no doubt required, at least now these types live in their final resting place in the physical model (Figure 4), together with a chain that populates the artefact repository. In the end, it was a rather rewarding change though it certainly did not seem so as we in the thick of doing it.
 Figure 4: Physical model after refactoring.
Figure 4: Physical model after refactoring.
MDE Paper of the Week (PofW)
This sprint we spent a bit more than usual reading MDE papers (6.1%), and read a total of 5 papers. It should have really been 6 but due to time constraints we missed one. As usual, we published a video on youtube with the review of each paper. The following papers were read:
- MDE PotW 10: Using Aspects to Model Product Line Variability: Groher, Iris, and Markus Voelter. "Using Aspects to Model Product Line Variability." SPLC (2). 2008. PDF
- MDE PotW 11: A flexible code generator for MOF based modeling languages: Bichler, Lutz. "A flexible code generator for MOF-based modeling languages." 2nd OOPSLA Workshop on Generative Techniques in the context of Model Driven Architecture. 2003. PDF
- MDE PotW 12: A Comparison of Generative Approaches: XVCL and GenVoca: Blair, James, and Don Batory. "A Comparison of Generative Approaches: XVCL and GenVoca." Technical report, The University of Texas at Austin, Department of Computer Sciences (2004). PDF
- MDE PotW 13: An evaluation of the Graphical Modeling Framework GMF: Seehusen, Fredrik, and Ketil Stølen. "An evaluation of the graphical modeling framework (gmf) based on the development of the coras tool." International Conference on Theory and Practice of Model Transformations. Springer, Berlin, Heidelberg, 2011. PDF
- MDE PotW 14: Features as transformations: A generative approach to software development: Vranić, Valentino, and Roman Táborský. "Features as transformations: A generative approach to software development." Computer Science and Information Systems 13.3 (2016): 759-778. PDF
Resourcing
As we alluded to in the introduction, this sprint had a whopping 95 hours worth of effort as opposed to the more traditional 80 hours - 18.7% more resourcing than usual. It also lasted for some 6 weeks rather than 4, meaning our utilisation rate was a measly 35%, our second worse since records begun on Sprint 20 (Figure 4). Partially this was due to work and life constraints, but partially it was also due to the need to have some time away from the rarefied environment of the logical-physical space, which is not exactly a friendly place to those who do not favour abstraction.
 Figure 5: Utilisation rate since Sprint 20.
Figure 5: Utilisation rate since Sprint 20.
If one ignores those glaring abnormalities, the sprint was otherwise fairly normal. Around 75% of the resourcing was concerned with stories that contributed directly to the sprint goal - not quite the 80% of the previous sprint but not too shabby a number either. As the colouration of Figure 6 attests, those 75% were spread out across a decent number of stories, meaning we didn't do so bad in capturing the work performed. On non-core matters, we spent around 6.1% on MDE papers - up from 5.2% last sprint - but giving us a good bang for the buck with 5 papers instead of the 4 we had last sprint. Its a bit painful to read papers after a long week of coding for both professional and personal projects, but its definitely worth our while. We also had around 2.2% of the ask wasted on spikes, mainly troubleshooting problems with the nightly build and with Emacs/clangd. Finally, we dedicated almost 16% to process related matters, including 8.4% on editing the release notes and 6.1% on backlog grooming. Overall, it was a solid effort from a resourcing perspective, with the exception of the utilisation rate. Hopefully, regular service will be resumed next sprint on that regard.
 Figure 6: Cost of stories for sprint 26.
Figure 6: Cost of stories for sprint 26.
Roadmap
Sadly, not much to be said for our road map. We did not make any progress with regards to closing the fabled generation meta-model clean-up given that we are yet to do a dent in the PMM relations. We probably should rename this milestone as well, given the generation model is long gone from the code-base. One for next sprint.


Binaries
You can download binaries from either Bintray or GitHub, as per Table 2. All binaries are 64-bit. For all other architectures and/or operative systems, you will need to build Dogen from source. Source downloads are available in zip or tar.gz format.
| Operative System | Format | BinTray | GitHub |
|---|---|---|---|
| Linux Debian/Ubuntu | Deb | dogen_1.0.26_amd64-applications.deb | dogen_1.0.26_amd64-applications.deb |
| OSX | DMG | DOGEN-1.0.26-Darwin-x86_64.dmg | DOGEN-1.0.26-Darwin-x86_64.dmg |
| Windows | MSI | DOGEN-1.0.26-Windows-AMD64.msi | DOGEN-1.0.26-Windows-AMD64.msi |
Table 1: Binary packages for Dogen.
Note: The OSX and Linux binaries are not stripped at present and so are larger than they should be. We have an outstanding story to address this issue, but sadly CMake does not make this a trivial undertaking.
Next Sprint
The goal for the next sprint is carried over from the previous sprint. Given the overambitious nature of the previous sprint's goal, this time we decided to go for a single objective:
- implement locator and dependencies via PMM.
That's all for this release. Happy Modeling!
v1.0.25
3 years ago River mouth of the Cunene River, Angola. (C) 2015 O Viajante.
River mouth of the Cunene River, Angola. (C) 2015 O Viajante.
Introduction
Another month, another Dogen sprint. And what a sprint it was! A veritable hard slog, in which we dragged ourselves through miles in the muddy terrain of the physical meta-model, one small step at a time. Our stiff upper lips were sternly tested, and never more so than at the very end of the sprint; we almost managed to connect the dots, plug in the shiny new code-generated physical model, and replace the existing hand-crafted code. Almost. It was very close, but, alas, the end-of-sprint bell rung just as we were applying the finishing touches, meaning that, after a marathon, we found ourselves a few yards short of the sprint goal. Nonetheless, it was by all accounts an extremely successful sprint. And, as part of the numerous activities around the physical meta-model, we somehow managed to also do some user facing fixes too, so there are goodies in pretty much any direction you choose to look at.
So, lets have a gander and see how it all went down.
User visible changes
This section covers stories that affect end users, with the video providing a quick demonstration of the new features, and the sections below describing them in more detail.
 Video 1: Sprint 25 Demo.
Video 1: Sprint 25 Demo.
Profiles do not support collection types
A long-ish standing bug in the variability subsystem has been the lack of support for collections in profiles. If you need to remind yourself what exactly profiles are, the release notes of sprint 16 contain a bit of context which may be helpful before you proceed. These notes can also be further supplemented by those of sprint 22 - though, to be fair, the latter describe rather more advanced uses of the feature. At any rate, profiles are used extensively throughout Dogen, and on the main, they have worked surprisingly well. But collections had escaped its remit thus far.
The problem with collections is perhaps best illustrated by means of an example. Prior to this release, if you looked at a random model in Dogen, you would likely find the following:
#DOGEN ignore_files_matching_regex=.*/test/.*
#DOGEN ignore_files_matching_regex=.*/tests/.*
...
This little incantation makes sure we don't delete hand-crafted test files. The meta-data key ignore_files_matching_regex is of type text_collection, and this feature is used by the remove_files_transform in the physical model to filter files before we decide to delete them. Of course, you will then say: "this smells like a hack to me! Why aren't the manual test files instances of model elements themselves?" And, of course, you'd be right to say so, for they should indeed be modeled; there is even a backlogged story with words to that effect, but we just haven't got round to it yet. Only so many hours in the day, and all that. But back to the case in point, it has been mildly painful to have to duplicate cases such as the above across models because of the lack of support for collections in variability's profiles. As we didn't have many of these, it was deemed a low priority ticket and we got on with life.
With the physical meta-model work, things took a turn for the worse; suddenly there were a whole lot of wale KVPs lying around all over the place:
#DOGEN masd.wale.kvp.class.simple_name=primitive_header_transform
#DOGEN masd.wale.kvp.archetype.simple_name=primitive_header
Here, the collection masd.wale.kvp is a KVP (e.g. key_value_pair in variability terms). If you multiply this by the 80-odd M2T transforms we have scattered over C++ and C#, the magnitude of the problem becomes apparent. So we had no option but get our hands dirty and fix the variability subsystem. Turns out the fix was not trivial at all, and required a lot of heavy lifting but by the end of it we addressed it for both cases of collections; it is now possible to add any element of the variability subsystem to a profile and it will work. However, its worthwhile considering what the semantics of the merging mean after this change. Up to now we only had to deal with scalars, so the approach for the merge was very simple:
- if an entry existed in the model element, it took priority - regardless of existing on a bindable profile or not;
- if an entry existed in the profile but not in the modeling element, we just used the profile entry.
Because these were scalars we could simply take one of the two, lhs or rhs. With collections, following this logic is not entirely ideal. This is because we really want the merge to, well, merge the two collections together rather than replacing values. For example, in the KVP use case, we define KVPs in a hierarchy of profiles and then possibly further overload them at the element level (Figure 1). Where the same key exists in both lhs and rhs, we can apply the existing logic for scalars and take one of the two, with the element having precedence. This is what we have chosen to implement this sprint.
 Figure 1: Profiles used to model the KVPs for M2T transforms.
Figure 1: Profiles used to model the KVPs for M2T transforms.
This very simple merging strategy has worked for all our use cases, but of course there is the potential of surprising behaviour; for example, you may think the model element will take priority over the profile, given that this is the behaviour for scalars. Surprising behaviour is never ideal, so in the future we may need to add some kind of knob to allow configuring the merge strategy. We'll cross that bridge when we have a use case.
Extend tracing to M2T transforms
Tracing is one of those parts of Dogen which we are never quite sure whether to consider it a "user facing" part of the application or not. It is available to end users, of course, but what they may want to do with it is not exactly clear, given it dumps internal information about Dogen's transforms. At any rate, thus far we have been considering it as part of the external interface and we shall continue to do so. If you need to remind yourself how to use the tracing subsystem, the release notes of the previous sprint had a quick refresher so its worth having a look at those.
To the topic in question then. With this release, the volume of tracing data has increased considerably. This is a side-effect of normalising "formatters" into regular M2T transforms. Since they are now just like any other transform, it therefore follows they're expected to also hook into the tracing subsystem; as a result, we now have 80-odd new transforms, producing large volumes of tracing data. Mind you, these new traces are very useful, because its now possible to very quickly see the state of the modeling element prior to text generation, as well as the text output coming out of each specific M2T transform. Nonetheless, the incrase in tracing data had consequences; we are now generating so many files that we found ourselves having to bump the transform counter from 3 digits to 5 digits, as this small snippet of the tree command for a tracing directory amply demonstrates:
...
│ │ │ ├── 00007-text.transforms.local_enablement_transform-dogen.cli-9eefc7d8-af4d-4e79-9c1f-488abee46095-input.json
│ │ │ ├── 00008-text.transforms.local_enablement_transform-dogen.cli-9eefc7d8-af4d-4e79-9c1f-488abee46095-output.json
│ │ │ ├── 00009-text.transforms.formatting_transform-dogen.cli-2c8723e1-c6f7-4d67-974c-94f561ac7313-input.json
│ │ │ ├── 00010-text.transforms.formatting_transform-dogen.cli-2c8723e1-c6f7-4d67-974c-94f561ac7313-output.json
│ │ │ ├── 00011-text.transforms.model_to_text_chain
│ │ │ │ ├── 00000-text.transforms.model_to_text_chain-dogen.cli-bdcefca5-4bbc-4a53-b622-e89d19192ed3-input.json
│ │ │ │ ├── 00001-text.cpp.model_to_text_cpp_chain
│ │ │ │ │ ├── 00000-text.cpp.transforms.types.namespace_header_transform-dogen.cli-0cc558f3-9399-43ae-8b22-3da0f4a489b3-input.json
│ │ │ │ │ ├── 00001-text.cpp.transforms.types.namespace_header_transform-dogen.cli-0cc558f3-9399-43ae-8b22-3da0f4a489b3-output.json
│ │ │ │ │ ├── 00002-text.cpp.transforms.io.class_implementation_transform-dogen.cli.conversion_configuration-8192a9ca-45bb-47e8-8ac3-a80bbca497f2-input.json
│ │ │ │ │ ├── 00003-text.cpp.transforms.io.class_implementation_transform-dogen.cli.conversion_configuration-8192a9ca-45bb-47e8-8ac3-a80bbca497f2-output.json
│ │ │ │ │ ├── 00004-text.cpp.transforms.io.class_header_transform-dogen.cli.conversion_configuration-b5ee3a60-bded-4a1a-8678-196fbe3d67ec-input.json
│ │ │ │ │ ├── 00005-text.cpp.transforms.io.class_header_transform-dogen.cli.conversion_configuration-b5ee3a60-bded-4a1a-8678-196fbe3d67ec-output.json
│ │ │ │ │ ├── 00006-text.cpp.transforms.types.class_forward_declarations_transform-dogen.cli.conversion_configuration-60cfdc22-5ada-4cff-99f4-5a2725a98161-input.json
│ │ │ │ │ ├── 00007-text.cpp.transforms.types.class_forward_declarations_transform-dogen.cli.conversion_configuration-60cfdc22-5ada-4cff-99f4-5a2725a98161-output.json
│ │ │ │ │ ├── 00008-text.cpp.transforms.types.class_implementation_transform-dogen.cli.conversion_configuration-d47900c5-faeb-49b7-8ae2-c3a0d5f32f9a-input.json
...
In fact, we started to generate so much tracing data that it became obvious we needed some simple way to filter it. Which is where the next story comes in.
Add "scoped tracing" via regexes
With this release we've added a new option to the tracing subsystem: tracing-filter-regex. It is described as follows in the help text:
Tracing:
...
--tracing-filter-regex arg One or more regular expressions for the
transform ID, used to filter the tracing
output.
The idea is that when we trace we tend to look for the output of specific transforms or groups of transforms, and so it may make sense to filter out the output to speed up generation. For example, to narrow tracing to the M2T chain, one could use:
--tracing-filter-regex ".*text.transforms.model_to_text_chain.*"
This would result in 5 tracing files being generated rather than the 550 odd for a for trace of the dogen.cli model.
Handling of container names is incorrect
The logical model has many model elements which can contain other modeling elements. The most obvious case is, of course, module, which maps to a UML package in the logical dimension and to namespace in the physical dimension for many technical spaces. However, there are others, such as modeline_group for decorations, as well as the new physical elements such as backend and facet. Turns out we had a bug in the mapping of these containers from the logical dimension to the physical dimension, probably for the longest time, and we didn't even notice it. Let's have a look at say transforms.hpp in dogen.orchestration/types/transforms/:
...
#ifndef DOGEN_ORCHESTRATION_TYPES_TRANSFORMS_TRANSFORMS_HPP
#define DOGEN_ORCHESTRATION_TYPES_TRANSFORMS_TRANSFORMS_HPP
#if defined(_MSC_VER) && (_MSC_VER >= 1200)
#pragma once
#endif
/**
* @brief Top-level transforms for Dogen. These are
* the entry points to all transformations.
*/
namespace dogen::orchestration {
...
As you can see, whilst the file is located in the right directory, and the header guard also makes the correct reference to the transforms namespace, the documentation is placed against dogen::orchestration rather than dogen::orchestration::transforms, as we intended. Since thus far this was mainly used for documentation purposes, the bug remained unnoticed. This sprint however saw the generation of containers for the physical meta-model (e..g backend and facet), meaning that the bug now resulted in very obvious compilation errors. We had to do some major surgery into how containers are processed in the logical model, but in the end, we got the desired result:
...
#ifndef DOGEN_ORCHESTRATION_TYPES_TRANSFORMS_TRANSFORMS_HPP
#define DOGEN_ORCHESTRATION_TYPES_TRANSFORMS_TRANSFORMS_HPP
#if defined(_MSC_VER) && (_MSC_VER >= 1200)
#pragma once
#endif
/**
* @brief Top-level transforms for Dogen. These are
* the entry points to all transformations.
*/
namespace dogen::orchestration::transforms {
...
It may appear to be a lot of pain for only a few characters worth of a change, but there is nonetheless something quite satisfying to the OCD amongst us.
Update stitch mode for emacs
Many moons ago we used to have a fairly usable emacs mode for stitch templates based on poly-mode. However, poly-mode moved on, as did emacs, but our stitch mode stayed still, so the code bit-rotted a fair bit and eventually stopped working altogether. With this sprint we took the time to update the code to comply with the latest poly-mode API. As it turns out, the changes were minimal so we probably should have done it before instead of struggling on with plain text template editing.
 Figure 2: Emacs with the refurbished stitch mode.
Figure 2: Emacs with the refurbished stitch mode.
We did run into one or two minor difficulties when creating the mode - narrated on #268: Creation of a poly-mode for a T4-like language, but overall it was really not too bad. In fact, the experience was so pleasant that we are now considering writing a quick mode for wale templates as well.
Create archetypes for all physical elements
As with many stories this sprint, this one is hard to pin down as "user facing" or "internal". We decided to go for user facing, given that users can make use of this functionality, though at present it does not make huge sense to do so. The long and short of it is that all formatters have now been updated to use the shiny new logical model elements that model the physical meta-model entities. This includes archetypes and facets. Figure 3 shows the current state of the text.cpp model.
Figure 3: M2T transforms in text.cpp model.
This means that, in theory, users could create their own backends by declaring instances of these meta-model elements - hence why it's deemed to be "user facing". In practice, we are still some ways until that'll work out of the box, and it will remain that way whilst we're bogged down in the never ending "generation refactor". Nevertheless, this change was certainly a key step on the long road to towards achieving our ultimate aims. For instance, it's now possible to create a new M2T transform by just adding a new model element with the right annotations and the generated code will take care of almost all the necessary hooks into the generation framework. The almost is due to running out of time, but hopefully these shortcomings will be addressed early next sprint.
Development Matters
In this section we cover topics that are mainly of interest if you follow Dogen development, such as details on internal stories that consumed significant resources, important events, etc. As usual, for all the gory details of the work carried out this sprint, see the sprint log.
Ephemerides
This sprint had the highest commit count of all Dogen sprints, by some margin; it had 41.6% more commits than the second highest sprint (Table 1).
| Sprint | Name | Timestamp | Number of commits |
|---|---|---|---|
| v1.0.25 | "Foz do Cunene" | 2020-05-31 21:48:14 | 449 |
| v1.0.21 | "Nossa Senhora do Rosário" | 2020-02-16 23:38:34 | 317 |
| v1.0.11 | "Moçamedes" | 2019-02-26 15:39:23 | 311 |
| v1.0.22 | "Cine Teatro Namibe" | 2020-03-16 08:47:10 | 307 |
| v1.0.16 | "São Pedro" | 2019-05-05 21:11:28 | 282 |
| v1.0.24 | "Imbondeiro no Iona" | 2020-05-03 19:20:17 | 276 |
Table 1: Top 6 sprints by commit count.
Interestingly, it was not particularly impressive from a diff stat perspective, when compared to some other mammoth sprints of the past:
v1.0.06..v1.0.07: 9646 files changed, 598792 insertions(+), 624000 deletions(-)
v1.0.09..v1.0.10: 7026 files changed, 418481 insertions(+), 448958 deletions(-)
v1.0.16..v1.0.17: 6682 files changed, 525036 insertions(+), 468646 deletions(-)
...
v1.0.24..v1.0.25: 701 files changed, 62257 insertions(+), 34251 deletions(-)
This is easily explained by the fact that we did a lot of changes to the same fixed number of files (the M2T transforms).
Milestones
No milestones where reached this sprint.
Significant Internal Stories
This sprint had a healthy story count (32), and a fairly decent distribution of effort. Still, two stories dominated the picture, and were the cause for most other stories, so we'll focus on those and refer to the smaller ones in their context.
Promote all formatters to archetypes
At 21.6% of the ask, promoting all formatters to M2T transforms was the key story this sprint. Impressive though it might be, this bulgy number does not paint even half of the picture, because, as we shall see, the implementation of this one story splintered into a never-ending number of smaller stories. But lets start at the beginning. To recap, the overall objective has been to make what we have called thus far "formatters" first class citizens in the modeling world; to make them look like regular transforms. More specifically, like Model-to-Text transforms, given that is precisely what they had been doing: to take model elements and convert them into a textual representation. So far so good.
Then, the troubles begin:
- as we've already mentioned at every opportunity, we have a lot of formatters; we intentionally kept the count down - i.e. we are not adding any new formatters until the architecture stabilises - but of course the ones we have are the "minimum viable number" needed in order for Dogen to generate itself (not quite, but close). And 80 is no small number.
- the formatters use stitch templates, which makes changing them a lot more complicated than changing code - remember that the formatter is a generator, and the stitch template is the generator for the generator. Its very easy to lose track of where we are in these many abstraction layers, and make a change in the wrong place.
- the stitch templates are now modeling elements, carried within Dia's XML. This means we need to unpack them from the model, edit them, and pack them back in the model. Clearly, we have reached the limitations of Dia, and of course, we have a good solution for this in the works, but for now it is what it is; not quick.
- unhelpfully, formatters tend to come in all shapes and sizes, and whilst there is commonality, there are also a lot of differences. Much of the work was finding real commonalities, abstracting them (perhaps into profiles) and regenerating.
In effect, this task was one gigantic, never ending rinse-and-repeat. We could not make too many changes in one go, lest we broke the world and then spent ages trying to figure out where, so we had to do a number of very small passes over the total formatter count until we reached the end result. Incidentally, that is why the commit count is so high.
As if all of this was not enough, matters were made even more challenging because, every so often, we'd try to do something "simple" - only to bump into some key limitation in the Dogen architecture. We then had to solve the limitation and resume work. This was the case for the following stories:
- Profiles do not support collection types: we started to simplify archetypes and then discovered this limitation. Story covered in detail in the user-facing stories section above.
- Extend tracing to M2T transforms: well, since M2T transforms are transforms, they should also trace. This took us on yet another lovely detour. Story covered in detail in the user-facing stories section above.
- Add "scoped tracing" via regexes: Suddenly tracing was taking far too long - the hundreds of new trace files could possibly have something to do with it, perhaps. So to make it responsive again, we added filtering. Story covered in detail in the user-facing stories section above.
- Analysis on templating and logical model: In the past we thought it would be really clever to expand wale templates from within stitch templates. It was not, as it turns out; we just coupled the two rather independent templating systems for no good reason. In addition, this made stitch much more complicated than it needs to be. In reality, what we really want is a simple interface where we can supply a set of KVPs plus a template as a string and obtain the result of the template instantiation. The analysis work pointed out a way out of this mess.
- Split wale out of stitch templates: After the analysis came the action. With this story we decoupled stitch from wale, and started the clean up. However, since we are still making use of stitch outside of the physical meta-model elements, we could not complete the tidy-up. It must wait until we remove the formatter helpers.
-
templatingshould not depend onphysical: A second story that fell out of the templating analysis; we had a few dependencies between the physical and templating models, purely because we wanted templates to generate artefacts. With this story we removed this dependency and took one more step towards making the templating subsystem independent of files and other models. - Move decoration transform into logical model: In the previous sprint we successfully moved the stitch and wale template expansions to the logical model workflow. However, the work was not complete because we were missing the decoration elements for the template. With this sprint, we relocated decoration handling into the logical model and completed the template expansion work.
- Resolve references to wale templates in logical model: Now that we can have an archetype pointing to a logical element representing a wale template, we need to also make sure the element is really there. Since we already had a resolver to do just that, we extended it to cater for these new meta-model elements.
- Update stitch mode for emacs: We had to edit a lot of stitch templates in order to reshape formatters, and it was very annoying to have to do that in plain text. A nice mode to show which parts of the file are template and which parts are real code made our life much easier. Story covered in detail in the user-facing stories section above.
- Ensure stitch templates result in valid JSON: converting some stitch templates into JSON was resulting in invalid JSON due to incorrect escaping. We had to quickly get our hands dirty in the JSON injector to ensure the escaping was done correctly.
All and all, this story was directly or indirectly responsible for the majority of the work this sprint, so as you can imagine, we were ecstatic to see the back of it.
Create a PMM chain in physical model
Alas, our troubles were not exactly at an end. The main reason why we were on the hole of the previous story was because we have been trying to create a representation of the physical-meta model (PMM); this is the overarching "arch" of the story, if you pardon me the pun. And once we managed to get those pesky M2T transforms out of the way, we then had to contend ourselves with this little crazy critter. Where the previous story was challenging mainly due to its boredom, this story provided challenges for a whole different reason: to generate an instance of a meta-model by code-generating it as you are changing the generator's generator is not exactly the easiest of things to follow.
The gist of what we were trying to achieve is very easy to explain, of course; since Dogen knows at compile time the geometry of physical space, and since that geometry is a function of the logical elements that represent the physical meta-model entities, it should therefore be possible to ask Dogen to create an instance of this model via code-generation. This is greatly advantageous, clearly, because it means you can simply add a new modeling element of a physical meta-type (say an archetype or a facet), rebuild Dogen and - lo-and-behold - the code generator is now ready to start generating instances of this meta-type.
As always, there was a wide gulf between theory and practice, and we spent the back end of the sprint desperately swimming across it. As with the previous story, we ended up having to address a number of other problems in order to get on with the task at hand. These were:
- Create a bootstrapping chain for context: Now that the physical meta-model is a real model, we need to generate it via transform chains rather than quick hacks as we had done in the past. Sadly, all the code around context generation was designed for the context to be created prior to the real transformations taking place. You must bear in mind that the physical meta-model is part of the transform context presented to almost all transforms as they execute; however, since the physical meta-model is also a model, we now have a "bootstrapping" stage that builds the first model which is needed for all other models to be created. With this change we cleaned up all the code around this bootstrapping phase, making it compliant with MDE.
- Handling of container names is incorrect: As soon as we started generating backends and facets we couldn't help but notice that they were placed in the wrong namespace, and so were all containers. A fix had to be done before we could proceed. Story covered in detail in the user-facing stories section above.
- Facet and backend files are in the wrong folder: a story related to the previous one; not only where the namespaces wrong but the files were also incorrect too. Fixing the previous problem addressed both issues.
-
Add template related attributes to physical elements: We first thought it would be a great idea to carry the stitch and wale templates all the way into the physical meta-model representation; we were half-way through the implementation when we realised that this story made no sense at all. This is because the stitch templates are only present when we are generating models for the archetypes (e.g.
text.cppandtext.csharp). On all other cases, we will have the physical meta-model (it is baked in into the binary, after all) but no way of obtaining the text of the templates. This was a classical case of trying to have too much symmetry. The story was then aborted. -
Fix
static_archetypemethod in archetypes: A number of fixes was done into the "static/virtual" pattern we use to return physical meta-model elements. This was mainly a tidy-up to ensure we useconstby reference consistently, instead of making spurious copies.
MDE Paper of the Week (PofW)
This sprint we spent around 5.2% of the total ask reading four MDE papers. As usual, we published a video on youtube with the review of each paper. The following papers were read:
- MDE PotW 05: An EMF like UML generator for C++: Jäger, Sven, et al. "An EMF-like UML generator for C++." 2016 4th International Conference on Model-Driven Engineering and Software Development (MODELSWARD). IEEE, 2016. PDF.
- MDE PotW 06: An Abstraction for Reusable MDD Components: Kulkarni, Vinay, and Sreedhar Reddy. "An abstraction for reusable MDD components: model-based generation of model-based code generators." Proceedings of the 7th international conference on Generative programming and component engineering. 2008. PDF.
- MDE PotW 07: Architecture Centric Model Driven Web Engineering: Escott, Eban, et al. "Architecture-centric model-driven web engineering." 2011 18th Asia-Pacific Software Engineering Conference. IEEE, 2011. PDF
- MDE PotW 08: A UML Profile for Feature Diagrams: Possompès, Thibaut, et al. "A UML Profile for Feature Diagrams: Initiating a Model Driven Engineering Approach for Software Product Lines." Journée Lignes de Produits. 2010. PDF.
All the papers provided interesting insights, and we need to transform these into actionable stories. The full set of reviews that we've done so far can be accessed via the playlist MASD - MDE Paper of the Week.
 Video 2: MDE PotW 05: An EMF like UML generator for C++.
Video 2: MDE PotW 05: An EMF like UML generator for C++.
Resourcing
As we've already mentioned, this sprint was particularly remarkable due to its high number of commits. Overall, we appear to be experiencing an upward trend on this department, as Figure 4 attests. Make of that what you will, of course, since more commits do not equal more work; perhaps we are getting better at committing early and committing often, as one should. More significantly, it was good to see the work spread out over a large number of stories rather than the bulkier ones we'd experienced for the last couple of sprints; and the stories that were indeed bulky - at 21.6% and 12% (described above) - were also coherent, rather than a hodgepodge of disparate tasks gather together under the same heading due to tiredness.
 Figure 4: Commit counts from sprints 13 to 25.
Figure 4: Commit counts from sprints 13 to 25.
We saw 79.9% of the total ask allocated to core work, which is always pleasing. Of the remaining 20%, just over 5% was allocated to MDE papers, and 13% went to process. The bulk of process was, again, release notes. At 7.3%, it seems we are still spending too much time on writing the release notes, but we don't seem to find a way to reduce this cost. It may be that its natural limit is around 6-7%; any less and perhaps we will start to lose the depth of coverage we're getting at present. Besides, we find it to be an important part of the agile process, because we have no other way to perform post-mortem analysis of sprints; and it is a much more rigorous form of self-inspection. Maybe we just need to pay its dues and move on.
The remaining non-core activities were as usual related to nursing nightly builds, a pleasant 0.9% of the ask, and also a 1% spent dealing with the fall out of a borked dist-upgrade on our main development box. On the plus side, after that was sorted, we managed to move to the development version of clang (v11), meaning clangd is even more responsive than usual.
All and all, it was a very good sprint from the resourcing front.
 Figure 5: Cost of stories for sprint 25.
Figure 5: Cost of stories for sprint 25.
Roadmap
Other than being moved forward by a month, our "oracular" road map suffered only one significant alteration from the previous sprint: we doubled the sprint sizes to close to a month, which seems wise given we have settled on that cadence for a few sprints now. According to the oracle, we have at least one more sprint to finish the generation refactor - though, if the current sprint is anything to go by, that may be a wildly optimistic assessment.
As you were, it seems.


Binaries
You can download binaries from either Bintray or GitHub, as per Table 2. All binaries are 64-bit. For all other architectures and/or operative systems, you will need to build Dogen from source. Source downloads are available in zip or tar.gz format.
| Operative System | Format | BinTray | GitHub |
|---|---|---|---|
| Linux Debian/Ubuntu | Deb | dogen_1.0.25_amd64-applications.deb | dogen_1.0.25_amd64-applications.deb |
| OSX | DMG | DOGEN-1.0.25-Darwin-x86_64.dmg | DOGEN-1.0.25-Darwin-x86_64.dmg |
| Windows | MSI | DOGEN-1.0.25-Windows-AMD64.msi | DOGEN-1.0.25-Windows-AMD64.msi |
Table 2: Binary packages for Dogen.
Note: The OSX and Linux binaries are not stripped at present and so are larger than they should be. We have an outstanding story to address this issue, but sadly CMake does not make this a trivial undertaking.
Next Sprint
The sprint goals for the next sprint are as follows:
- finish PMM generation.
- implement locator and dependencies via PMM.
- move physical elements and transforms from logical and text models to physical model.
That's all for this release. Happy Modeling!
v1.0.24
4 years ago A baobab tree in Iona national park, Namib, Angola. (C) 2011 Alfred Weidinger
A baobab tree in Iona national park, Namib, Angola. (C) 2011 Alfred Weidinger
Introduction
Welcome to the second release of Dogen under quarantine. As with most people, we have now converged to the new normal - or, at least, adjusted best one can to these sorts of world-changing circumstances. Development continued to proceed at a steady clip, if somewhat slower than the previous sprint's, and delivered a fair bit of internal changes. Most significantly, with this release we may have finally broken the back of the fabled generation model refactor - though, to be fair, we'll only know for sure next sprint. We've also used some of our copious free time to make key improvements to infrastructure, fixing a number of long-standing annoyances. So, grab yourself a hot ${beverage_of_choice} and get ready for yet another exciting Dogen sprint review!
User visible changes
This section covers stories that affect end users, with the video providing a quick demonstration of the new features, and the sections below describing them in more detail. As there have only been a small number of user facing changes, we've also used the video to discuss the internal work.
 Video 1: Sprint 24 Demo.
Video 1: Sprint 24 Demo.
Add model name to tracing dumps
Though mainly useful for Dogen developers, the tracing subsystem can be used by end users as well. As before, it can be enabled via the usual flags:
Tracing:
--tracing-enabled Generate metrics about executed transforms.
--tracing-level arg Level at which to trace.Valid values: detail,
summary. Defaults to summary.
--tracing-guids-enabled Use guids in tracing metrics, Not recommended
when making comparisons between runs.
--tracing-format arg Format to use for tracing metrics. Valid
values: plain, org-mode, graphviz. Defaults to
org-mode.
--tracing-backend arg Backend to use for tracing. Valid values:
file, relational.
--tracing-run-id arg Run ID to use to identify the tracing session.
With this release, we fixed a long standing annoyance with the file backend, which is to name the trace files according to the model the transform is operating on. This is best demonstrated by means of an example. Say we take an arbitrary file from a tracing dump of the injection subsystem. Previously, files were named like so:
000-injection.dia.decoding_transform-c040099b-858a-4a3d-af5b-df74f1c7f52c-input.json
...
This made it quite difficult to find out which model was being processed with this transform, particularly when there are large numbers of similarly named files. With this release we've added the model name to the tracing file name for the transform (e.g., dogen.logical):
000-injection.dia.decoding_transform-dogen.logical-c040099b-858a-4a3d-af5b-df74f1c7f52c-input.json
...
This makes locating the tracing files much easier, and we've already made extensive use of this feature whilst troubleshooting during development.
Primitives use compiler generated default constructors
Up to now our valgrind output had been so noisy that we weren't really paying too much attention to it. However, with this release we finally tidied it up - as we shall see later on in these release notes - and, would you believe it, obvious bugs started to get uncovered almost immediately. This particular one was detected with the help of two sharp-eyed individuals - Indranil and Ian - as well as valgrind. So, it turns out we were generating primitives that used the compiler provided default constructor even when the underlying type was a built-in type. Taking an example for the C++ reference model:
class bool_primitive final {
public:
bool_primitive() = default;
...
private:
bool value_;
This of course resulted in uninitialised member variables. With this release the generated code now creates a manual default constructor:
class bool_primitive final {
...
public:
bool_primitive();
...
Which does the appropriate initialisation (do forgive the static_cast, these will be cleaned up at some point in the future):
bool_primitive::bool_primitive()
: value_(static_cast<bool>(0)) { }
This fix illustrates the importance of static and dynamic analysis tools, forcing us to refresh the story on the missing LLVM/Clang tools. Sadly there aren't enough hours of the day to tackle all of these but we must get to them sooner rather than later.
Circular references with boost::shared_ptr
Another valgrind catch was the detection of a circular reference when using boost::shared_ptr. We did the classic school-boy error of having a data structure with a child pointing to its parent, and the parent pointing to the child. This is all fine and dandy but we did so using boost::shared_ptr for both pointers (in node.hpp):
boost::shared_ptr<dogen::logical::helpers::node> parent_;
...
std::list<boost::shared_ptr<dogen::logical::helpers::node> > children_;
In these cases, the literature advises one to use weak_ptr, so that's what we did:
boost::weak_ptr<dogen::logical::helpers::node> parent_;
...
std::list<boost::shared_ptr<dogen::logical::helpers::node> > children_;
With this the valgrind warning went away. Of course, the alert reader will point out that we probably should be using pointer containers for the children but I'm afraid that's one for another story.
Allow creating models with no decorations
While we're on the subject of brown-paper-bag bugs, another interesting one was fixed this sprint: our "sanity check model", which we use to make sure our packages produce a minimally usable Dogen binary, was causing Dogen to segfault (oh, the irony, the irony). This is, in truth, a veritable comedy of errors, so its worth recapping the series of events that led to its discovery. It all started with our test packaging script, who needs to know the version of the compiler for which the package was built, so that it can look for the binaries in the filesystem. Of course, this is less than ideal, but it is what it is and sadly we have other more pressing matters to look at so it will remain this way for some time.
The code in question is like so:
#
# Compiler
#
compiler="$1"
shift
if [[ "x${compiler}" = "x" ]]; then
compiler="gcc8";
echo "* Compiler: ${compiler} (default)"
...
elif [ "${compiler}" = "clang8" ]; then
echo "* Compiler: ${compiler}"
else
echo "* Unrecognised compiler: ${compiler}"
exit
fi
However, we forgot to update the script when we moved to clang-9. Now, normally this would have been picked up by travis as a red build, except we decided to return a non-error-error-code (see above). This meant that packages had not been tested for quite a while. To make matters interesting, we did introduce a bad bug over time; we changed the handling of default decorations. The problem is that all test models use the test profile, and the test profile contains decorations. The only model that did not contain any decorations was - you guessed it - the hello world model that is used in the package sanity tests. So once we fixed the package testing script we then had to fix the code that handles default decorations.
Development Matters
In this section we cover topics that are mainly of interest if you follow Dogen development, such as details on internal stories that consumed significant resources, important events, etc. As usual, for all the gory details of the work carried out this sprint, see the sprint log.
Ephemerides
The 11,111th commit was reached during this release.
 Figure 1: 11,111th commit in the Dogen git repository.
Figure 1: 11,111th commit in the Dogen git repository.
Milestones
The first set of completely green builds have been obtained for Dogen - both nightlies and continuous builds. This includes tests, dynamic analysis and code coverage.
 Figure 2: Builds for Dogen in CDash's dashboard.
Figure 2: Builds for Dogen in CDash's dashboard.
The first set of completely green nightly builds have been obtained for the C++ Reference Model. Work still remains on continuous builds for OSX and Windows, with 4 and 2 test failures respectively.
 Figure 3: Builds for C++ reference model in CDash's dashboard.
Figure 3: Builds for C++ reference model in CDash's dashboard.
Significant Internal Stories
There were several stories connected to the generation model refactor, which we have aggregated under one sundry umbrella to make our life easier. The remaining stories are all connected to infrastructure and the like.
Generation model refactor
We probably should start by admitting that we did not do a particularly brilliant job of sizing tasks this sprint. Instead, we ended up with a couple of gigantic, epic-like stories - XXXL? - rather than a number of small, focused and roughly equally sized stories that we prefer - L and X, in t-shirt sizes. Yet another great opportunity for improvement is clearly presenting itself here. To make things more understandable for this post-mortem, we decided to paper over the cracks and provide a slightly more granular view - rather than the coarse-grained way in which it was originally recorded on the sprint backlog.
The core of the work was divided as follows:
- Adding physical entities to the logical model: this story was continued from the previous sprint. The entities themselves had already been added to the logical model, so the work consisted mainly on creating the required transforms to ensure they had the right data by the time we hit the M2T (Model-to-Text) transforms.
-
Generating physical model entities from
m2tclasses: we finally go to the point where the top-level M2T transforms are generating the physical archetypes, which means the complete generation of the physical meta-model is not far now. The remaining physical meta-model entities (backend, facet, parts) are not quite as fiddly, hopefully. - Bootstrapping of physical entities: we continued the work on generation of physical entities via the logical model elements that represent them. This is very fiddly work because we are trying to bootstrap the existing templates - that is, generate code that resembles the existing generators - and therefore requires a great deal of concentration; its very easy to lose track of where we are and break everything, and we done so a few times this sprint, costing us a fair bit of time in tracking back the errors. There is hope that this work is almost complete though.
- Add T2T (Text-to-Text) transforms: As usual, a great deal of effort was spent on making sure that the code is consistent with the current understanding of the conceptual model. One aspect that had been rather illusive is the handling of templates; these are in effect not M2T transforms, because we've already discarded the model representation. With this sprint we arrived at T2T (Text-to-Text) transforms, which are a surprisingly good fit for both types of logic-less templates we have in Dogen (stitch and wale) but also have the potential to model cartridges such as ODB, XSD tool and many other types of code generators. More work on this remains next sprint, but the direction of travel is very promising.
-
Rename the
m2tmodel totext: following on from the previous entry, given that we now had two different types of transforms in this model (e.g., M2T and T2T) we could not longer call it them2tmodel, and thus decided to rename it to justtext. As it turns out, this is a much better fit for the conceptual model and prepares ourselves for the coming work on cartridges, which now have a very suitable location in which to be placed.
As you can probably gather from what is written on these topics in the sprint backlog, these few bullet points do little justice to the immense amount of mental effort that was spent on them. Sadly, we do not have the time - and I dare say, the inclination - to explain in the required detail how all of these issues contribute to the overall picture we are trying to form. Hopefully when the generation refactor is completed and all the fuzziness is taken away, a blog post can be produced summarising all of the moving parts in a concise narrative.
Code Coverage
Code coverage is important to us, for very much the same reason it is important to any software project: you want to make sure your unit tests are exercising as much of the code as possible. However, in addition to this, we also need to make sure the generated code is being adequately tested by the generated tests, both for Dogen as well as the Reference Implementation models. Historically, C++ has had good code coverage tools and services but they haven't been the most... user friendly, shall we say, pieces of software ever made. So, since Dogen's early days, I've been very eager to experiment the new wave of code coverage cloud services such as Coverals and Codecov and tools such as kcov to track code coverage. The experiment was long running but has now run its course, I am sorry to report, as we just faced too many problems for my liking. Now, in the interest of fairness, its not entirely clear if some of the problems we experienced are related to kcov rather than the cloud services; but other issues such as troubles with API keys and so forth were definitely related to the services themselves. Given we don't have the time to troubleshoot every problem, and we must be able to rely on the code coverage numbers to make important decisions, I had no option but to move back to good old CDash - a tool that had proven reliable in the past for this.
 Figure 4: Code coverage for Dogen, continuous builds, after moving back to CDash.
Figure 4: Code coverage for Dogen, continuous builds, after moving back to CDash.
I must confess that it was with a heavy heart that I even begun to contemplate moving away from kcov, as I quite like the tool; compared to the pain of setting up gcov or even llvm-cov, I think kcov is a work of art and a master of delightful user experience. Also, the maintainer is very friendly and responsive, as previous communications attest. Alas, as far as I could see, there was no easy way to connect the output of kcov with CDash, so back to the drawing board we went. I shan't bother you with graphic descriptions of the trials and tribulations of setting up gcov and llvm-cov - I presume any Linux C/C++ developer is far too battle-scarred to find any such tales interesting - but it suffices to say that, after a great deal of pain and many, many failed builds later we eventually managed to get gcov to produce the desired information.
 Figure 5: Code coverage for Dogen, nightly builds, after moving back to CDash.
Figure 5: Code coverage for Dogen, nightly builds, after moving back to CDash.
Figure 4 illustrates the progress of code coverage on Dogen's continuous builds over time, whereas Figure 5 looks at coverage in nightlies. As we explained previously, we have different uses for coverage depending on which build we use. Nightly builds run all generated tests, and as such they produce code coverage that takes into account the generated tests. This is useful, but its important not to confuse it with manually generated tests, which provide us with "real" coverage; that is, coverage that emerged as a result of "real" - i.e., domain - use of the types. We need both of these measurements in order to make sense of what areas are lacking. With CDash we now seem to have a reliable source of information for both of these measurements. As you can see from these charts, the coverage is not oscillating through time as it did previously when we used the coverage services (possibly due to kcov problems, but I personally doubt it). As an added bonus, we no longer have red builds due to "failed checks" in GitHub due to stochastic decreases in coverage, as we had far too many times in the past.
 Figure 6: Dogen nightly build duration over time.
Figure 6: Dogen nightly build duration over time.
A very important aspect when adding code coverage to already busy nightlies was the impact on build duration. We first started by trying to use clang and llvm-cov but we found that the nightlies started to take far too long to complete. This is possibly something to do with our settings - perhaps valgrind was not happy with the new coverage profiling parameters? - but given we didn't have a lot of time to experiment, we decided instead to move over to gcov and gcc debug builds. Figures 6 and 7 show the impact to the build time to both Dogen and the C++ Reference Model. These were deemed acceptable.
 Figure 7: C++ reference model build duration over time.
Figure 7: C++ reference model build duration over time.
Dynamic Analysis
As with code coverage, we've been making use of CDash to keep track of data produced by valgrind. However, we let the reports bit-rot somewhat, with lots of false positives clouding the view (or at least we hope they are false positives). With this release we took the time to update our suppression files, removing the majority of false positives. We then immediately located a couple of issues in the code, as explained above.
 Figure 8: Valgrind errors over time in CDash.
Figure 8: Valgrind errors over time in CDash.
I don't think we need any additional incentives to keep the board nice and clean as far as dynamic analysis is concerned. Figure 8 shows the current state of zero warnings, which is a joy to behold.
MDE Paper of the Week (PofW)
This sprint we started another experiment with YouTube and video recording: a sort of "self-journal club". For those not from a research background, many research labs organise a weekly (insert your frequency here, I guess) meeting where the participants discuss a scientific paper. The idea is that everyone reads the paper, but the chosen presenter will go through it in depth, and the audience can ask questions and so forth. Normally, this is a great forum to discuss papers that you are reading as part of your research and get some help to understand more difficult parts. Its also a place where you can see what everybody else is up to across your lab. At any rate, with the move back to gainful employment I no longer get the chance to participate in my lab's journal club. In addition, I found that many of the papers I had read over the years had lots of useful information that makes a lot more sense now than it did when i first read them. Thus, a re-read was required.
So I combined these two ideas and come up with the somewhat sad idea of a "self-journal club", the "MDE Paper of the Week (PofW)", where I read and discuss the papers of interest . These are available in YouTube, should you, for whatever unfathomable reason, find them interesting. Four papers have been read thus far:
- MDE PotW 01: Systems Variability Modeling: A Textual Model Mixing Class and Feature Concepts
- MDE PotW 02:A Code Generation Metamodel for ULF-Ware Generating Code for SDL
- MDE PotW 03: A Lightweight MDSD Process Applied in Small Projects
- MDE PotW 04: Un estudio comparativo de dos herramientas MDA: OptimalJ y ArcStyler
The last paper was more experimental than usual, what with it being in Spanish, but it worked better than we expected, so from now on we shall consider papers on other languages we can parse.
As with coding videos, the most significant advantage of this approach is motivational; I now find that I must re-read a paper a week even when I don't feel like it, purely because of the fact that I publish them online. Lets see how long the YouTube effect will last though...
Resourcing
Weighing in just short of 280 commits and with over 83 hours of work, this sprint was, by traditional measurements, a success. To be fair, we did return to the more regular duration of around four weeks rather than the three of the previous sprint, resulting in a utilisation rate of precisely 50% -a decrease of 16% from the previous sprint. On the other hand, this slower velocity seems far more sustainable than the break neck pace we attempted previously; our aim will continue to be around 50%, which effectively means part-time work.
 Figure 9: Cost of stories for sprint 24.
Figure 9: Cost of stories for sprint 24.
Where the waters become a bit murkier is when we break down the stories by "type". We spent around 56% of the overall ask on stories directly connected to the sprint goal, which may appear to be a bit low. The bulk of the remaining 44% were spent largely on process (24.5%), and infrastructure (11.5%) with a notable mention for the almost 6% spent moving code coverage into CDash. Another 6.6% was spent on reading MDE papers, which is of course time well spent from a strategic perspective but it does eat into the coding time. Of the 24.5% spent on process, a notable mention is the 11.3% spent editing the release notes. These are becoming a bit too expensive for our liking so next sprint we need to speed these along.
Roadmap
The roadmap remains more or less unchanged, other than the fact that it was projected forward by one sprint; much like Pinky and the Brain, our proximal goal remains the same: to finish the generation refactor. Its not entirely clear whether we're Pinky or the Brain, but we do feel that the problem is understood a bit better, so there is some faint hope that next sprint could bring it to a close.


Binaries
You can download binaries from either Bintray or GitHub, as per Table 1. All binaries are 64-bit. For all other architectures and/or operative systems, you will need to build Dogen from source. Source downloads are available in zip or tar.gz format.
| Operative System | Format | BinTray | GitHub |
|---|---|---|---|
| Linux Debian/Ubuntu | Deb | dogen_1.0.24_amd64-applications.deb | dogen_1.0.24_amd64-applications.deb |
| OSX | DMG | DOGEN-1.0.24-Darwin-x86_64.dmg | DOGEN-1.0.24-Darwin-x86_64.dmg |
| Windows | MSI | DOGEN-1.0.24-Windows-AMD64.msi | DOGEN-1.0.24-Windows-AMD64.msi |
Table 1: Binary packages for Dogen.
Note: The OSX and Linux binaries are not stripped at present and so are larger than they should be. We have an outstanding story to address this issue, but sadly CMake does not make this a trivial undertaking.
Next Sprint
The goal for the next sprint is to complete most of the work on the generation refactor. It is unlikely we shall finish it in its entirety as they are quite a few fiddly bits, but we shall aim to get most of it out of the way.
That's all for this release. Happy Modeling!
v1.0.23
4 years ago
Introduction
Welcome to the first release of Dogen under quarantine. I hope you have been able to stay home and stay safe, in what are very trying times for us all. This release is obviously unimportant in the grand scheme of things, but perhaps it can provide a momentary respite to those of us searching for something else to focus our attention on. The sprint itself was a rather positive one, if somewhat quiet on the user-facing front; of particular note is the fact that we have finally made major inroads on the fabled "generation" refactoring, which we shall cover at length. So get ready for some geeky MDE stories.
User Visible Changes
This section covers stories that affect end users, with the video providing a quick demonstration of the new features, and the sections below describing them in more detail. Since there were only a couple of minor user facing changes, we've used the video to chat about the internal work as well.
 Video 1: Sprint 23 Demo.
Video 1: Sprint 23 Demo.
Generate the MASD Palette
Whilst positive from an end-goal perspective, the growth of the logical model has had a big impact on the MASD palette, and we soon started to struggle to find colours for this zoo of new meta-model elements. Predictably, the more the model grew, the bigger the problem became and the direction of travel was more of the same. We don't have a lot of time for artistic reveries, so this sprint we felt enough's enough and took the first steps in automating the process. To our great astonishment, even something as deceptively simple as "finding decent colours" is a non-trivial question, for which there is published research. So we followed Voltaire's sound advice - le mieux est l'ennemi du bien and all that - and went for the simplest possible approach that could get us moving in the right direction.
 Figure 1: Fragment of the old MASD palette, with manually crafted colours.
Figure 1: Fragment of the old MASD palette, with manually crafted colours.
A trivial new script to generate colours was created. It is based on the above-linked Seaborn python library, as it appears to provide sets of palettes for these kinds of use cases. We are yet to master the technicalities of the library, but at this point we can at least generate groups of colours that are vaguely related. This is clearly only the beginning of the process, both in terms of joining the dots of the scripts (at present you need to manually copy the new palettes into the colouring script) but also as far as finding the right Seaborn palettes to use; as you can see from Figure 2, the new MASD palette has far too many similar colours, making it difficult to visually differentiate meta-model elements. More exploration of Seaborn - and colouring in general - is required.
 Figure 2: Fragment of the new MASD palette, with colours generated by a script.
Figure 2: Fragment of the new MASD palette, with colours generated by a script.
Add org-mode output to dumpspecs
The previous sprint saw the addition of a new command to the Dogen command line tool called dumpspecs:
$ ./dogen.cli --help | tail -n 7
Commands:
generate Generates source code from input models.
convert Converts a model from one codec to another.
dumpspecs Dumps all specs for Dogen.
For command specific options, type <command> --help.
At inception,dumpspecs only supported the plain reporting style, but it became obvious that it could also benefit from providing org-mode output. For this, a new command line option was added: --reporting-style.
$ ./dogen.cli dumpspecs --help
Dogen is a Model Driven Engineering tool that processes models encoded in supported codecs.
Dogen is created by the MASD project.
Displaying options specific to the dumpspecs command.
For global options, type --help.
Dumping specs:
--reporting-style arg Format to use for dumping specs. Valid values: plain,
org-mode. Defaults to org-mode.
The output can be saved to a file for visualisation and further processing:
$ ./dogen.cli dumpspecs --reporting-style org-mode > specs.org
The resulting file can be opened on any editor that supports org-mode, such as Emacs, Vim or Visual Studio Code. Figure 3 provides an example of visualising the output in Emacs.
 Figure 3: Using Emacs to visualise the output of
Figure 3: Using Emacs to visualise the output of dumpspecs in org-mode format.
Development Matters
This section cover topics that are mainly of interest if you follow Dogen development, such as details on internal stories that consumed significant resources, important events, etc. As usual, if you are interested on all the gory details of the work carried out this sprint, please see the sprint log.
Milestones
The 11,000th commit was made to the Dogen GitHub repository during this release.
 Figure 4: 11,000th commit for Dogen on GitHub.
Figure 4: 11,000th commit for Dogen on GitHub.
The Dogen build is now completely warning and error free, across all supported configurations - pleasing to the eye for the OCD'ers amongst us. Of course, now the valgrind defects on the nightly become even more visible, so we'll have to sort those out soon.
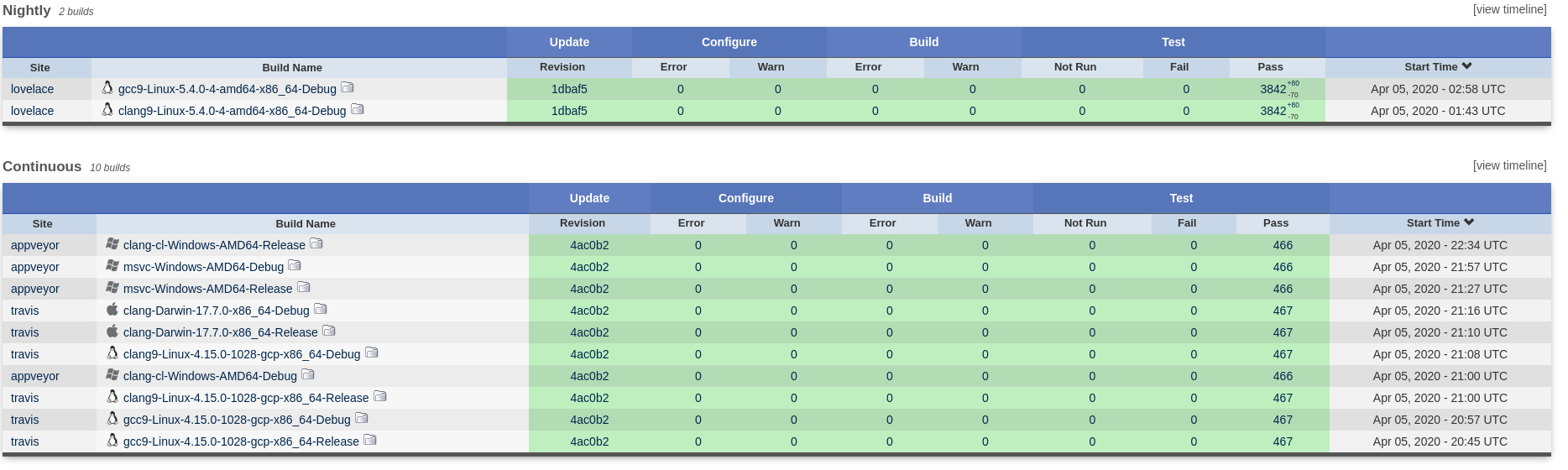 Figure 5: Dogen's CI is finally free of warnings.
Figure 5: Dogen's CI is finally free of warnings.
Significant Internal Stories
The sprint was dominated by smattering of small and medium-sized stories that, collectively, made up the "generation" refactor work. We've grouped the most significant of them into a handful of "themes", allowing us to cover the refactor in some detail. To be fair, it is difficult to provide all of the required context in order to fully understand the rationale for the work, but we tried our best.
Rename assets to the logical model
One change that was trivial with regards to resourcing but huge in conceptual terms was the rename of assets into the logical model. We'll talk more about the importance of this change in the next section - in the context of the logical-physical space - but here I just want to reflect a little on the historic evolution of this model, as depicted on Table 1.
| Release | Date | Name | Description | Problem |
|---|---|---|---|---|
| v0.0.20 | 16 Nov 2012 | sml |
The Simplified Modeling Language. | It was never really a "language". |
| v0.0.71 | 10 Aug 2015 | tack |
Random sewing term. | No one knew what it meant. |
| v0.0.72 | 21 Oct 2015 | yarn |
Slightly less random sewing term. | Term already used by a popular project; Dogen moves away from sewing terms. |
| v1.0.07 | 1 Jan 2018 | modeling |
Main point of the model. | Too generic a term; used everywhere in both Dogen and MDE. |
| v1.0.10 | 29 Oct 2018 | coding |
Name reflects entities better. | Model is not just about coding elements. |
| v1.0.18 | 2 Jun 2019 | assets |
Literature seems to imply this is a better name. | Name is somewhat vague; anything can be an asset. |
| v1.0.23 | 6 Apr 2020 | logical |
Rise of the logical-physical space and associated conceptual model. | None yet. |
Table 1: Historic evolution of the name of the model with the core Dogen entities.
What this cadence of name changes reveals is a desperate hunt to understand the role of this model in the domain. We are now hoping that it has reached its final resting place, but we'll only know for sure when we complete the write up of the MASD conceptual model.
Towards a physical Model
The processing pipeline for Dogen remains largely unchanged since its early days. Figure 6 is a diagram from sprint 12 describing the pipeline and associated models; other than new names, it is largely applicable to the code as it stands today. However, as we've already hinted, what has changed in quite dramatic fashion is our understanding of the conceptual role of these models. Over time, a picture of a sparse logical-physical space emerged; as elements travel through the pipeline, they are also traveling through this space, transformed by projections that are parameterised by variability, and ultimately materializing as fully-formed artefacts, ready to be written to the filesystem. Beneath those small name changes lies a leap in conceptual understanding of the domain, and posts such as the The Refactoring Quagmire give you a feel for just how long and windy the road to enlightenment has been.
Figure 6: Dogen's processing pipeline circa sprint 12.
For the last few sprints, we have been trying to get the code to behave according to this newly found knowledge. The previous sprint saw us transition the variability model to this brave new world, and this sprint we have turned our attention to the logical and physical models. Whilst the logical model work was just a trivial rename (narrated above), the physical model was a much bigger task than any thus far because all we had was an assortment of unrelated models, very far away from their desired state.
Our starting salvo was composed of three distinct lines of attack:
-
Refactor the
archetypesmodelet. The first moment of enlightenment was when we realised that the smallarchetypesmodel was nothing but a disguised meta-model of the physical dimension for the logical-physical space. In effect, it is a metaphysical model though such a name (and associated pun) would probably not be viewed well in academic circles, so we had to refrain from using it. Nonetheless, we took the existingarchetypesmodel and refactored it into the core of thephysicalmodel. Types such asarchetype_locationbecame the basis of the physical meta-model, populated with entities such asbackend,facetandkernel. -
Merge the
extractionmodel into thephysicalmodel. More surprisingly, we eventually realised that theextractionmodel was actually representing instances of the physical meta-model, and as such should be merged into it. It was rather difficult to wrap our heads around this concept; to do so, we had to let go of the idea thatartefactsare representations of files in memory, and instead started to view them as elements travelling in the logical-physical space towards their ultimate destination. After a great many whiteboard sessions, these ideas were eventually clarified and then much of the conceptual design fell into place. -
Move physical aspects in the
logicalmodel to thephysicalmodel. The last step of our three-pronged approach was to figure out that the proliferation of types with names such asartefact_properties,enablement_propertiesand the like was just a leakage of physical concepts into the logical model. This happened because we did not have a strong conceptual framework, and so never quite knew where to place things. As the physical model started to take shape with the two changes above, we finally resolved this long standing problem, and it suddenly became clear that most of the physical properties we had been associating with logical elements were more adequately modeled as part of the artefacts themselves. This then allows us to cleanly separate thelogicalandphysicalmodels, very much in keeping with the decoupling performed last sprint for thevariabilityandphysicalmodels (the latter known then asarchetypes, of course). The sprint saw us modeling the required types correctly in thephysicalmodel, but the entire tidy-up will be long in completing as the code in question is very fiddly.
 Figure 7: Entities in the
Figure 7: Entities in the physical model.
Once all of these changes were in, we ended up with a physical model with a more coherent look and feel, as Figure 7 atestares. However, we were not quite done. We then turned our attention to one of the biggest challenges within the physical model. For reasons that have been lost in the mists of time, very early on in Dogen's life we decided that all names within a location had to be qualified. This is best illustrated by means of an example. Take the archetype masd.cpp.types.class_header, responsible for creating header files for classes. Its physical location was previously as follows:
- kernel:
masd - backend:
masd.cpp - facet:
masd.cpp.types - archetype:
masd.cpp.types.class_header
This was a remarkably bad idea, with all sorts of consequences and none of them good - not least of which complicating things significantly when trying to come up with a unified approach to file paths processing. So we had to very carefully change the code to use simple names as it should have done in the first place, i.e.:
- kernel:
masd - backend:
cpp - facet:
types - archetype:
class_header
Because so much of the code base depended on the fully qualified name - think formatter registrations, binding of logical model elements, etc - it was an uphill battle to get it to comply with this change. In fact, it was by far the most expensive story of the entire sprint. Fortunately we have tests that give us some modicum of confidence that we have not broken the world when making such fundamental changes, but nonetheless it was grueling work.
Rename the generation Models to m2t
It has long been understood that "formatters" are nothing but model-to-text (M2T) transforms, as per standard MDE terminology. With this sprint, we finally had the time to rename the generation models to their rightful name:
-
generationbecamem2t -
generation.cppbecamem2t.cpp -
generation.csharpbecamem2t.csharp
In addition, as per the previous story, the new role of the m2t model is now to perform the expansion of the logical model into the physical dimension of the logical-physical space. With this sprint we begun this exercise, but sadly only scratched the surface as we ran out of time. Nonetheless, the direction of travel seems clear, and much of the code that is at present duplicated between m2t.cpp and m2t.csharp should find its new home within m2t, in a generalised form that makes use of the shiny new physical meta-model.
Rename the meta-model Namespace to entities
One of the terms that can become very confusing very fast is meta-model. When you are thick in the domain of MDE, pretty much everything you touch is a meta-something, so much so that calling things "meta-models" should be done sparingly and only when it can provide some form of enlightenment to the reader. So it was that we decided to deprecate the widely used namespace meta-model in favour of the much blander entities.
Resourcing
With an astonishing utilisation rate of 66%, this sprint was extremely efficient. Perhaps a tad too efficient, even; next sprint we may need to lower the utilisation rate back closer to 50%, in order to ensure we get adequate rest. We've also managed to focus 80% of the total ask on stories directly related to the sprint mission. Of these, the flattening of the physical names completely dominated the work (over 25%), followed by a smattering of smaller stories. Outside of the sprint's mission, we spent a bit over 17% on process, with 10% on release notes and demo - still a tad high, but manageable - and the rest on maintaining the sprint and product backlog. The small crumbs were spent on "vanity" infrastructure projects: adding support for clang 10 (1%) - which brought noticeable benefits because clangd, as always, has improved in leaps and bounds - and sorting out some rather annoying warnings on Windows' clang-cl (1.3%).
 Figure 8: Cost of stories for sprint 22.
Figure 8: Cost of stories for sprint 22.
Roadmap
We've updated the roadmap with the big themes we envision as being key to the release of Dogen v2. As always, it must be taken with a huge grain of salt, but still there is something very satisfying about seeing the light at the end of the tunnel.


Binaries
You can download binaries from either Bintray or GitHub, as per Table 2. All binaries are 64-bit. For all other architectures and/or operative systems, you will need to build Dogen from source. Source downloads are available in zip or tar.gz format.
| Operative System | Format | BinTray | GitHub |
|---|---|---|---|
| Linux Debian/Ubuntu | Deb | dogen_1.0.23_amd64-applications.deb | dogen_1.0.23_amd64-applications.deb |
| OSX | DMG | DOGEN-1.0.23-Darwin-x86_64.dmg | DOGEN-1.0.23-Darwin-x86_64.dmg |
| Windows | MSI | DOGEN-1.0.23-Windows-AMD64.msi | DOGEN-1.0.23-Windows-AMD64.msi |
Table 2: Binary packages for Dogen.
Note: The OSX and Linux binaries are not stripped at present and so are larger than they should be. We have an outstanding story to address this issue, but sadly CMake does not make this a trivial undertaking.
Next Sprint
We shall continue work on the "generation" refactor - a name that is now not quite as apt given all the model renaming. We are hopeful - but not too hopeful - of completing this work next sprint. Famous last words.
That's all for this release. Happy Modeling!