Distil Whisper Save
Distilled variant of Whisper for speech recognition. 6x faster, 50% smaller, within 1% word error rate.
Distil-Whisper
[Paper] [Models] [Colab] [Training Code]
Distil-Whisper is a distilled version of Whisper that is 6 times faster, 49% smaller, and performs within 1% word error rate (WER) on out-of-distribution evaluation sets:
| Model | Params / M | Rel. Latency ↑ | Short-Form WER ↓ | Long-Form WER ↓ |
|---|---|---|---|---|
| large-v3 | 1550 | 1.0 | 8.4 | 11.0 |
| distil-large-v3 | 756 | 6.3 | 9.7 | 10.8 |
| distil-large-v2 | 756 | 5.8 | 10.1 | 11.6 |
| distil-medium.en | 394 | 6.8 | 11.1 | 12.4 |
| distil-small.en | 166 | 5.6 | 12.1 | 12.8 |
For most applications, we recommend the latest distil-large-v3 checkpoint, since it is the most performant distilled checkpoint and compatible across all Whisper libraries. The only exception is resource-constrained applications with very little memory, such as on-device or mobile applications, where the distil-small.en is a great choice, since it is only 166M parameters and performs within 4% WER of Whisper large-v3.
Note: Distil-Whisper is currently only available for English speech recognition. We are working with the community to distill Whisper on other languages. If you are interested in distilling Whisper in your language, check out the provided training code. We will soon update the repository with multilingual checkpoints when ready!
1. Usage
Distil-Whisper is supported in Hugging Face 🤗 Transformers from version 4.35 onwards. To run the model, first install the latest version of the Transformers library. For this example, we'll also install 🤗 Datasets to load a toy audio dataset from the Hugging Face Hub:
pip install --upgrade pip
pip install --upgrade transformers accelerate datasets[audio]
Short-Form Transcription
Short-form transcription is the process of transcribing audio samples that are less than 30-seconds long, which is the maximum receptive field of the Whisper models. This means the entire audio clip can be processed in one go without the need for chunking.
First, we load Distil-Whisper via the convenient AutoModelForSpeechSeq2Seq and AutoProcessor classes.
We load the model in float16 precision and make sure that loading time takes as little time as possible by passing low_cpu_mem_usage=True.
In addition, we want to make sure that the model is loaded in safetensors format by passing use_safetensors=True:
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "distil-whisper/distil-large-v3"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
The model and processor can then be passed to the pipeline.
Note that if you would like to have more control over the generation process, you can directly make use of model + processor API as shown below.
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
max_new_tokens=128,
torch_dtype=torch_dtype,
device=device,
)
Next, we load an example short-form audio from the LibriSpeech corpus:
from datasets import load_dataset
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
sample = dataset[0]["audio"]
Finally, we can call the pipeline to transcribe the audio:
result = pipe(sample)
print(result["text"])
To transcribe a local audio file, simply pass the path to your audio file when you call the pipeline:
result = pipe("audio.mp3")
print(result["text"])
For more information on how to customize the automatic speech recognition pipeline, please refer to the ASR pipeline docs. We also provide an end-to-end Google Colab that benchmarks Whisper against Distil-Whisper.
For more control over the generation parameters, use the model + processor API directly:
Ad-hoc generation arguments can be passed to model.generate, including num_beams for beam-search, return_timestamps
for segment-level timestamps, and prompt_ids for prompting. See the docstrings
for more details.
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor
from datasets import Audio, load_dataset
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "distil-whisper/distil-large-v3"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
dataset = dataset.cast_column("audio", Audio(processor.feature_extractor.sampling_rate))
sample = dataset[0]["audio"]
input_features = processor(
sample["array"], sampling_rate=sample["sampling_rate"], return_tensors="pt"
).input_features
input_features = input_features.to(device, dtype=torch_dtype)
gen_kwargs = {
"max_new_tokens": 128,
"num_beams": 1,
"return_timestamps": False,
}
pred_ids = model.generate(input_features, **gen_kwargs)
pred_text = processor.batch_decode(pred_ids, skip_special_tokens=True, decode_with_timestamps=gen_kwargs["return_timestamps"])
print(pred_text)
Sequential Long-Form
The latest distil-large-v3 checkpoint is specifically designed to be compatible with OpenAI's sequential long-form transcription algorithm. This algorithm uses a sliding window for buffered inference of long audio files (> 30-seconds), and returns more accurate transcriptions compared to the chunked long-form algorithm.
The sequential long-form algorithm should be used in either of the following scenarios:
- Transcription accuracy is the most important factor, and latency is less of a consideration
- You are transcribing batches of long audio files, in which case the latency of sequential is comparable to chunked, while being up to 0.5% WER more accurate
If you are transcribing single long audio files and latency is the most important factor, you should use the chunked algorithm described below. For a detailed explanation of the different algorithms, refer to Sections 5 of the Distil-Whisper paper.
We start by loading the model and processor as before:
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "distil-whisper/distil-large-v3"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
The model and processor can then be passed to the pipeline.
Note that if you would like to have more control over the generation process, you can directly make use of model.generate(...) API as shown below.
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
max_new_tokens=128,
torch_dtype=torch_dtype,
device=device,
)
Next, we load a long-form audio sample. Here, we use an example of concatenated samples from the LibriSpeech corpus:
from datasets import load_dataset
dataset = load_dataset("distil-whisper/librispeech_long", "clean", split="validation")
sample = dataset[0]["audio"]
Finally, we can call the pipeline to transcribe the audio:
result = pipe(sample)
print(result["text"])
To transcribe a local audio file, simply pass the path to your audio file when you call the pipeline:
result = pipe("audio.mp3")
print(result["text"])
For more control over the generation parameters, use the model + processor API directly:
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor
from datasets import Audio, load_dataset
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "distil-whisper/distil-large-v3"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
dataset = dataset.cast_column("audio", Audio(processor.feature_extractor.sampling_rate))
sample = dataset[0]["audio"]
inputs = processor(
sample["array"],
sampling_rate=sample["sampling_rate"],
return_tensors="pt",
truncation=False,
padding="longest",
return_attention_mask=True,
)
inputs = inputs.to(device, dtype=torch_dtype)
gen_kwargs = {
"max_new_tokens": 448,
"num_beams": 1,
"condition_on_prev_tokens": False,
"compression_ratio_threshold": 1.35, # zlib compression ratio threshold (in token space)
"temperature": (0.0, 0.2, 0.4, 0.6, 0.8, 1.0),
"logprob_threshold": -1.0,
"no_speech_threshold": 0.6,
"return_timestamps": True,
}
pred_ids = model.generate(**inputs, **gen_kwargs)
pred_text = processor.batch_decode(pred_ids, skip_special_tokens=True, decode_with_timestamps=False)
print(pred_text)
Chunked Long-Form
distil-large-v3 remains compatible with the Transformers chunked long-form algorithm. This algorithm should be used when a single large audio file is being transcribed and the fastest possible inference is required. In such circumstances, the chunked algorithm is up to 9x faster than OpenAI's sequential long-form implementation (see Table 7 of the Distil-Whisper paper).
We can load the model and processor as before:
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "distil-whisper/distil-large-v3"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
To enable chunking, pass the chunk_length_s parameter to the pipeline. For distil-large-v3, a chunk length of 25-seconds
is optimal. To activate batching, pass the argument batch_size:
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
max_new_tokens=128,
chunk_length_s=25,
batch_size=16,
torch_dtype=torch_dtype,
device=device,
)
The argument max_new_tokens controls the maximum number of generated tokens per-chunk. In the typical speech setting,
we have no more than 3 words spoken per-second. Therefore, for a 30-second input, we have at most 90 words (approx 128 tokens).
We set the maximum number of generated tokens per-chunk to 128 to truncate any possible hallucinations that occur at the
end of the segment. These tokens get removed at the chunk borders using the long-form chunking transcription algorithm,
so it is more efficient to truncate them directly during generation to avoid redundant generation steps in the decoder.
Now, let's load a long-form audio sample. Here, we use an example of concatenated samples from the LibriSpeech corpus:
from datasets import load_dataset
dataset = load_dataset("distil-whisper/librispeech_long", "clean", split="validation")
sample = dataset[0]["audio"]
Finally, we can call the pipeline to transcribe the audio:
result = pipe(sample)
print(result["text"])
For more information on how to customize the automatic speech recognition pipeline, please refer to the ASR pipeline docs.
Speculative Decoding
Distil-Whisper can be used as an assistant model to Whisper for speculative decoding. Speculative decoding mathematically ensures the exact same outputs as Whisper are obtained while being 2 times faster. This makes it the perfect drop-in replacement for existing Whisper pipelines, since the same outputs are guaranteed.
For speculative decoding, we need to load both the teacher: openai/whisper-large-v3.
As well as the assistant (a.k.a student) distil-whisper/distil-large-v3.
Let's start by loading the teacher model and processor. We do this in much the same way we loaded the Distil-Whisper model in the previous examples:
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor
import torch
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "openai/whisper-large-v3"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
Now let's load the assistant. Since Distil-Whisper shares exactly same encoder as the teacher model, we only need to load the 2-layer decoder as a "Decoder-only" model:
from transformers import AutoModelForCausalLM
assistant_model_id = "distil-whisper/distil-large-v2"
assistant_model = AutoModelForCausalLM.from_pretrained(
assistant_model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
assistant_model.to(device)
The assistant model shares the same processor as the teacher, so there's no need to load a student processor.
We can now pass the assistant model to the pipeline to be used for speculative decoding. We pass it as a generate_kwarg
with the key "assistant_model"
so that speculative decoding is enabled:
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
max_new_tokens=128,
generate_kwargs={"assistant_model": assistant_model},
torch_dtype=torch_dtype,
device=device,
)
As before, we can pass any sample to the pipeline to be transcribed:
from datasets import load_dataset
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
sample = dataset[0]["audio"]
result = pipe(sample)
print(result["text"])
Note: speculative decoding should be on average 2x faster than using "only" Whisper large-v2 at a mere 8% increase in VRAM memory usage while mathematically ensuring the same results. This makes it the perfect replacement for Whisper large-v2 in existing speech recognition pipelines.
For more details on speculative decoding, refer to the following resources:
- Speculative decoding for 2x faster Whisper inference blog post by Sanchit Gandhi
- Assisted Generation: a new direction toward low-latency text generation blog post by Joao Gante
- Fast Inference from Transformers via Speculative Decoding paper by Leviathan et. al.
Additional Speed & Memory Improvements
You can apply additional speed and memory improvements to Distil-Whisper which we cover in the following.
Flash Attention
We recommend using Flash Attention 2 if your GPU allows for it. To do so, you first need to install Flash Attention:
pip install flash-attn --no-build-isolation
You can then pass use_flash_attention_2=True to from_pretrained to enable Flash Attention 2:
- model = AutoModelForSpeechSeq2Seq.from_pretrained(model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True)
+ model = AutoModelForSpeechSeq2Seq.from_pretrained(model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True, use_flash_attention_2=True)
Torch Scale-Product-Attention (SDPA)
If your GPU does not support Flash Attention, we recommend making use of BetterTransformers. To do so, you first need to install optimum:
pip install --upgrade optimum
And then convert your model to a "BetterTransformer" model before using it:
model = AutoModelForSpeechSeq2Seq.from_pretrained(model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True)
+ model = model.to_bettertransformer()
Exporting to Other Libraries
Distil-Whisper has support in the following libraries with the original "sequential" long-form transcription algorithm. Click the links in the table to see the relevant code-snippets for each:
| Library | distil-small.en | distil-medium.en | distil-large-v2 |
|---|---|---|---|
| OpenAI Whisper | link | link | link |
| Whisper cpp | link | link | link |
| Transformers js | link | link | link |
| Candle (Rust) | link | link | link |
Updates will be posted here with the integration of the "chunked" long-form transcription algorithm into the respective libraries.
For the 🤗 Transformers code-examples, refer to the sections Short-Form and Long-Form Transcription.
2. Why use Distil-Whisper? ⁉️
Distil-Whisper is designed to be a drop-in replacement for Whisper on English speech recognition. Here are 5 reasons for making the switch to Distil-Whisper:
- Faster inference: 6 times faster inference speed, while performing to within 1% WER of Whisper on out-of-distribution audio:
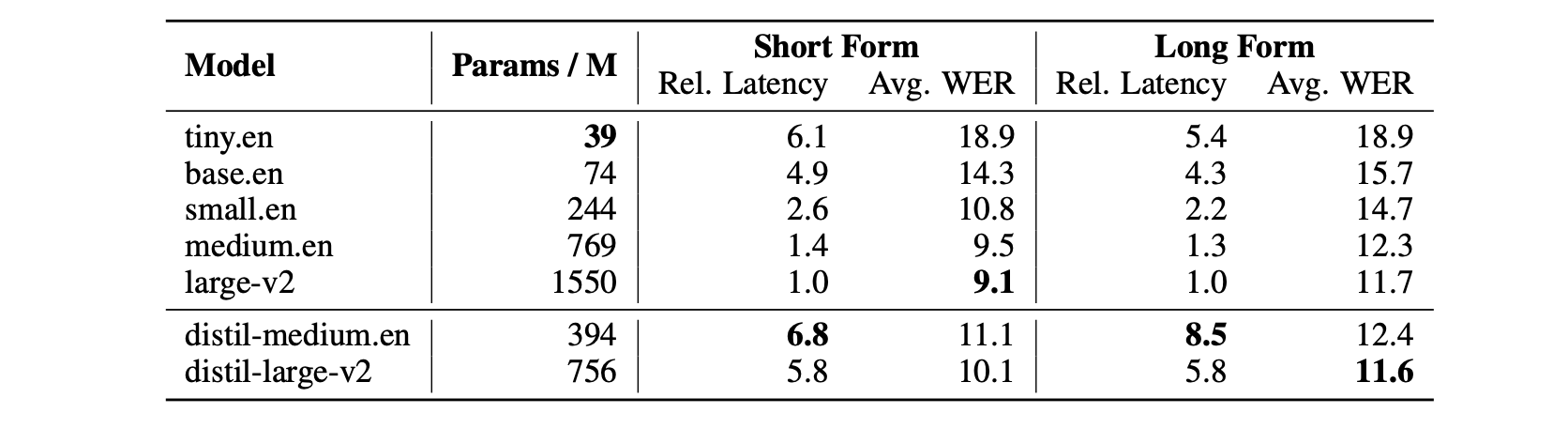
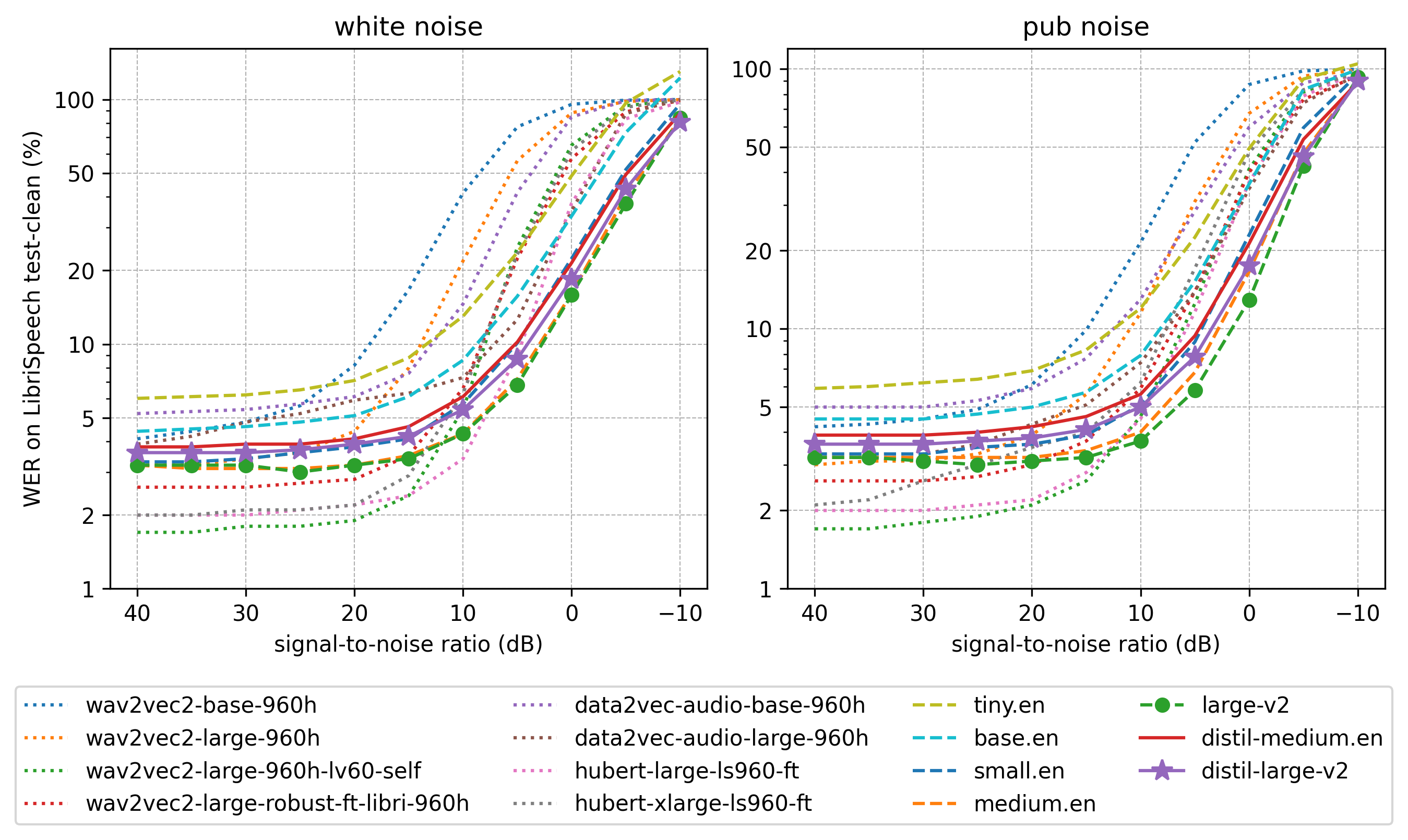
- Robustness to noise: demonstrated by strong WER performance at low signal-to-noise ratios:
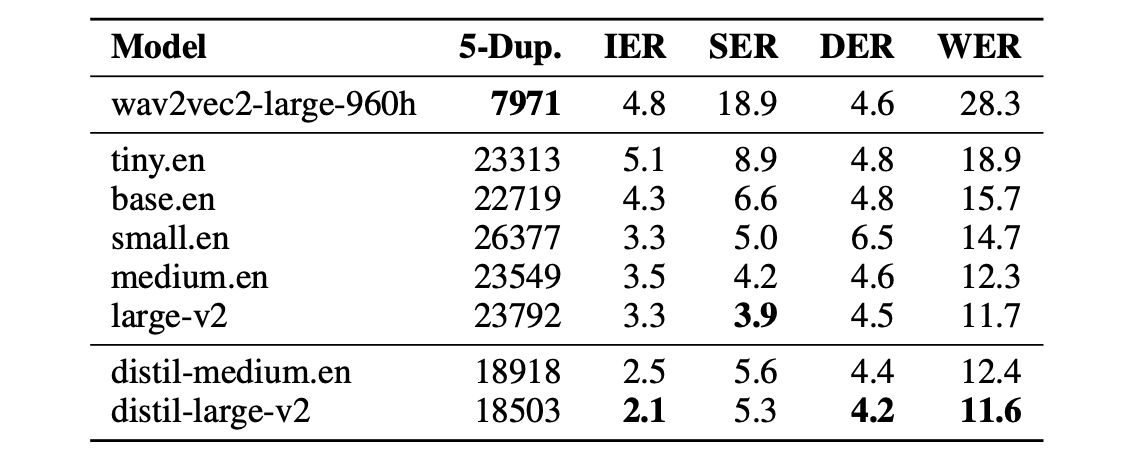
- Robustness to hallucinations: quantified by 1.3 times fewer repeated 5-gram word duplicates (5-Dup.) and 2.1% lower insertion error rate (IER) than Whisper:
- Designed for speculative decoding: Distil-Whisper can be used as an assistant model to Whisper, giving 2 times faster inference speed while mathematically ensuring the same outputs as the Whisper model.
- Permissive license: Distil-Whisper is MIT licensed, meaning it can be used for commercial applications.
3. Approach ✍️
To distill Whisper, we copy the entire encoder module and freeze it during training. We copy only two decoder layers, which are initialised from the first and last decoder layers from Whisper. All other decoder layers from Whisper are discarded:
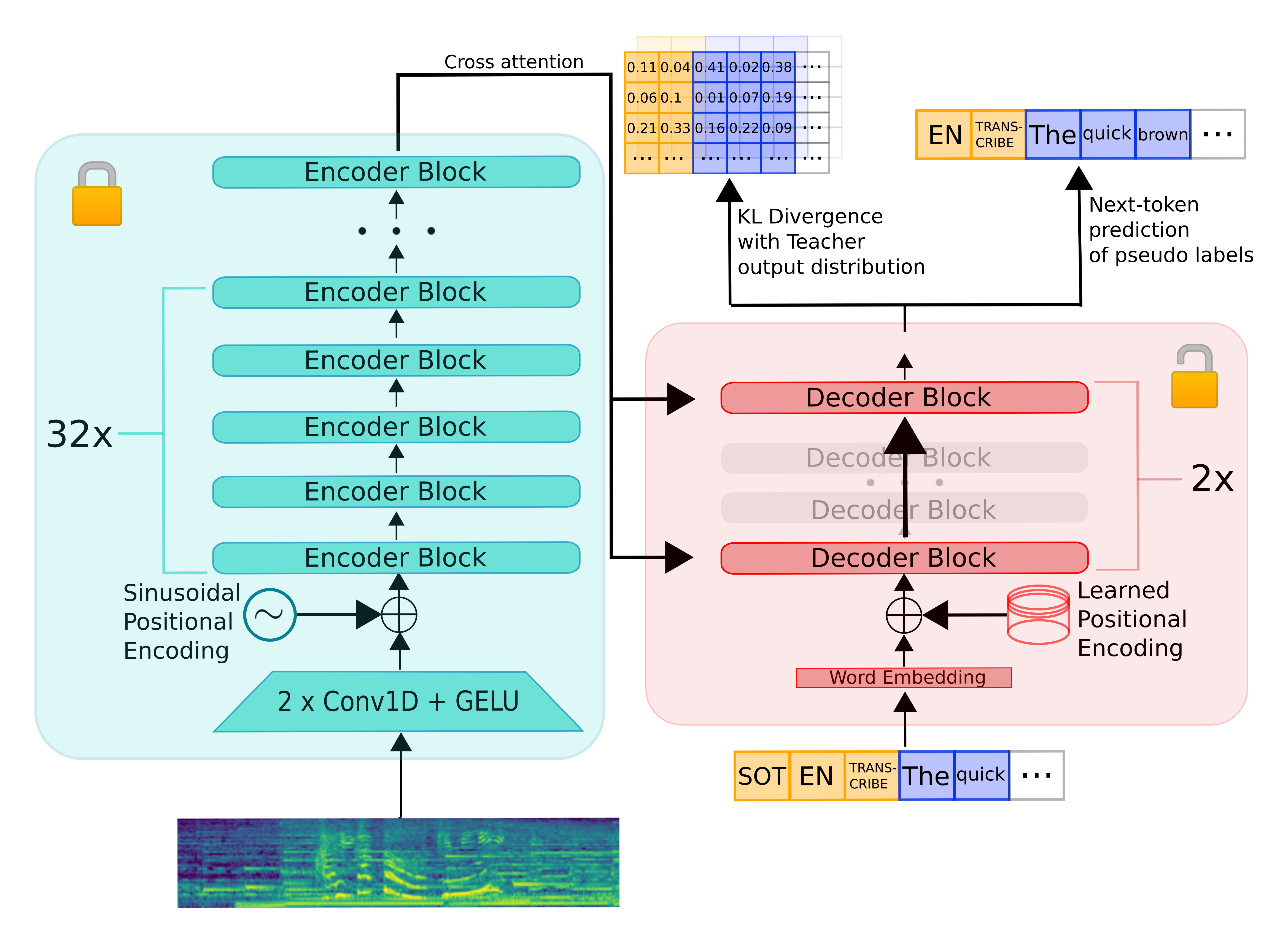
Distil-Whisper is trained on a knowledge distillation objective. Specifically, it is trained to minimise the KL divergence between the distilled model and the Whisper model, as well as the cross-entropy loss on pseudo-labelled audio data.
We train Distil-Whisper on a total of 22k hours of pseudo-labelled audio data, spanning 10 domains with over 18k speakers:
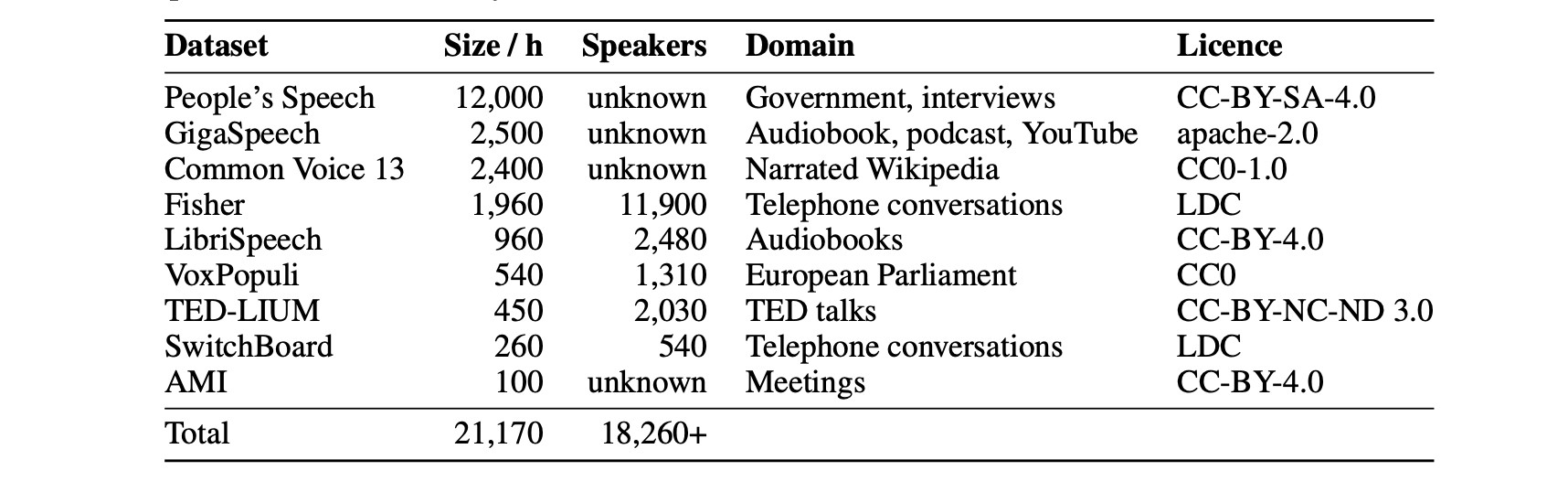
This diverse audio dataset is paramount to ensuring robustness of Distil-Whisper to different datasets and domains.
In addition, we use a WER filter to discard pseudo-labels where Whisper mis-transcribes or hallucinates. This greatly improves WER performance of the downstream distilled model.
For full details on the distillation set-up and evaluation results, refer to the Distil-Whisper paper.
4. Training Code
Training code to reproduce Distil-Whisper can be found in the directory training. This code has been adapted be general enough to distill Whisper for multilingual speech recognition, facilitating anyone in the community to distill Whisper on their choice of language.
5. Acknowledgements
- OpenAI for the Whisper model and original codebase
- Hugging Face 🤗 Transformers for the model integration
- Google's TPU Research Cloud (TRC) program for Cloud TPU v4s
6. Citation
If you use this model, please consider citing the Distil-Whisper paper:
@misc{gandhi2023distilwhisper,
title={Distil-Whisper: Robust Knowledge Distillation via Large-Scale Pseudo Labelling},
author={Sanchit Gandhi and Patrick von Platen and Alexander M. Rush},
year={2023},
eprint={2311.00430},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
And also the Whisper paper:
@misc{radford2022robust,
title={Robust Speech Recognition via Large-Scale Weak Supervision},
author={Alec Radford and Jong Wook Kim and Tao Xu and Greg Brockman and Christine McLeavey and Ilya Sutskever},
year={2022},
eprint={2212.04356},
archivePrefix={arXiv},
primaryClass={eess.AS}
}
