Deepstory Save
Deepstory turns a text/generated text into a video where the character is animated to speak your story using his/her voice.
Deepstory
Deepstory is an artwork that incorporates Natural Language Generation(NLG) w/GPT-2, Text-to-Speech(TTS) w/Deep Convolutional TTS, speech to animation w/Speech driven animation and image animation w/First Order Motion Model into a media application.
To put it simply, it turns a text/generated text into a video where the character is animated to speak your story using his/her voice.
You can convert image into a video like this:

It provides a comfortable web interface and backend written with flask to create your own story.
It supports transformers model, and pytorch-dctts models
Live Demo
Colab (flask-ngrok): https://colab.research.google.com/drive/1HYCPUmFw5rN8kvZdwzFpfBlaUMWPNHas?usp=sharing
Video (In case you need instructions): https://blog.thetobysiu.com/video/
Updates
- Redesign interface, especially the whole GPT2 interface
- GPT2 now support text loading from original data, so that it can continue to generate a story based on the book
- Figure out the token limits in GPT2 and only infer to the nearest 1024 - predict length tokens
- GPT2 support interactive mode that generates several batches of sentences and provides an interface to add those sentence
- Sentence speaker mapping system, not replacing all speaker by default anymore
- text normalization is now in the synthesizing stage so that punctuations are preserved and can be referenced to have a variable duration in synthesized audio
- Audio synthesizing are now all in temp folder, synthesized audios are trimmed so that it's animated video is more accurate(sda mode trained data are short also)
- Combined audio now have variable silences according to punctuation
- Basically, rewrite the web interface and lots of codes...
Colab version will be available soon!
Interface
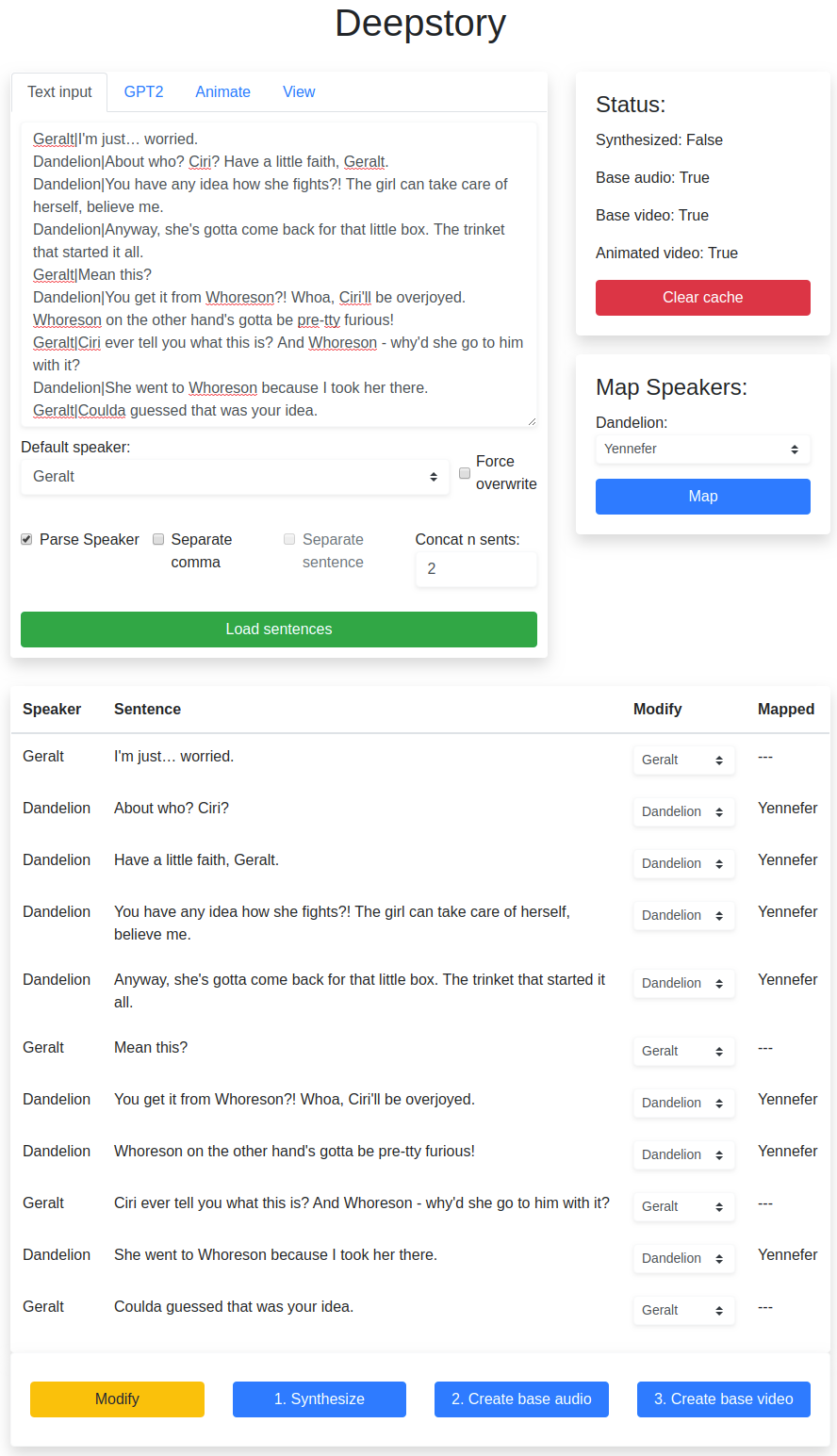
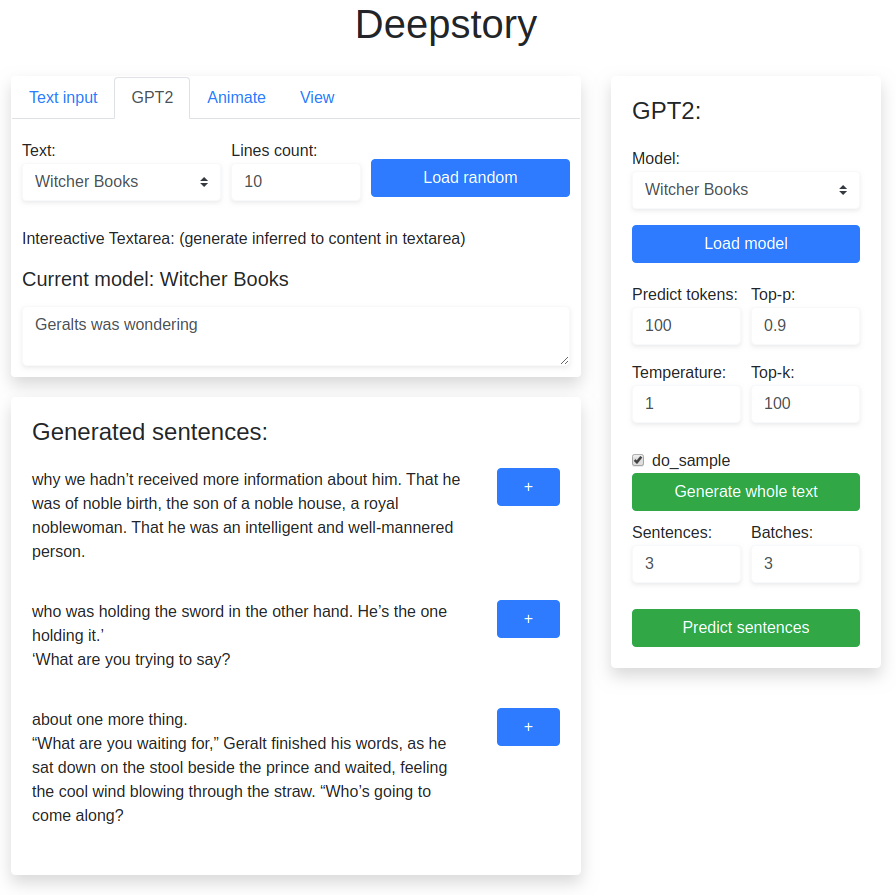
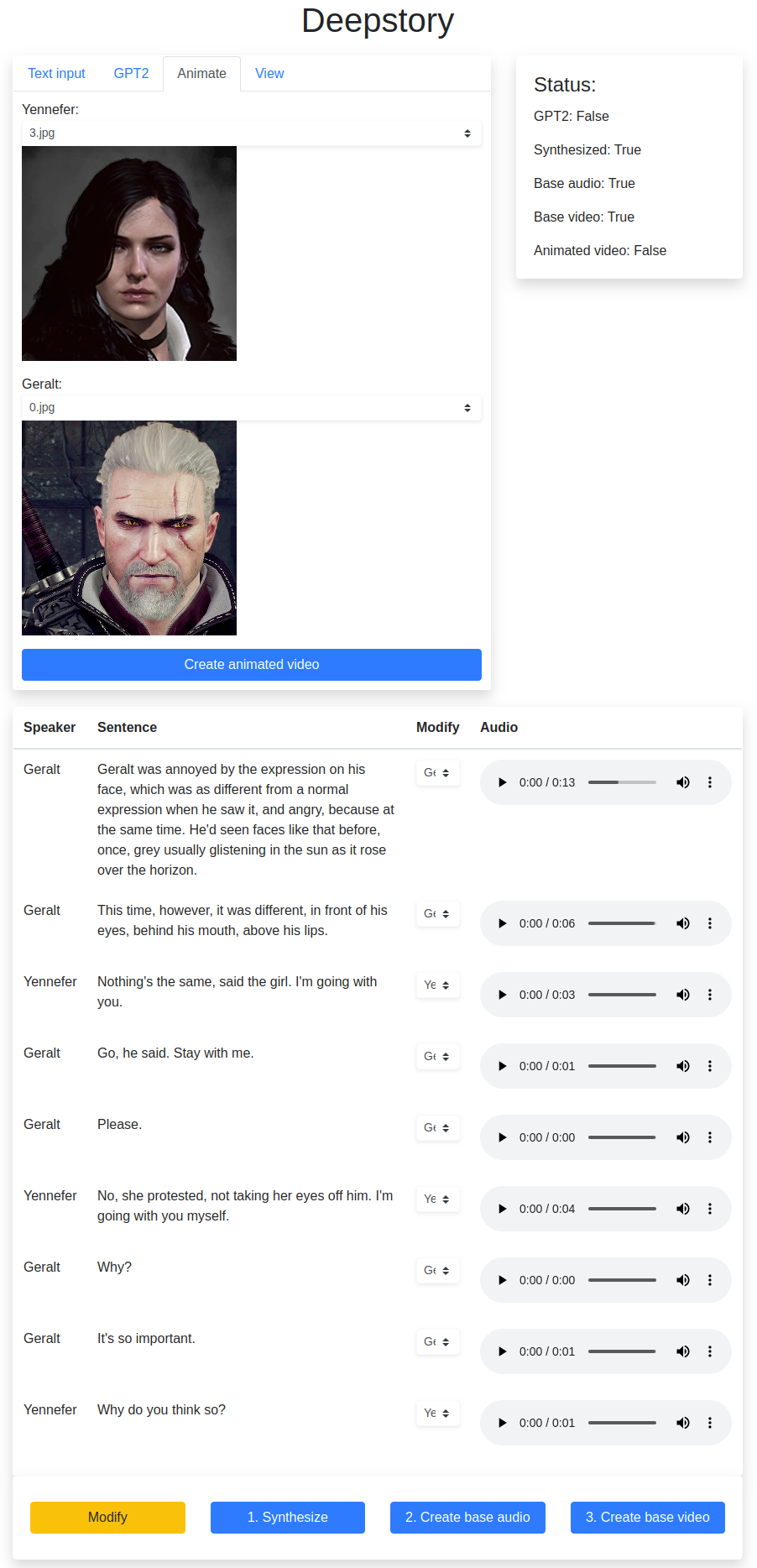
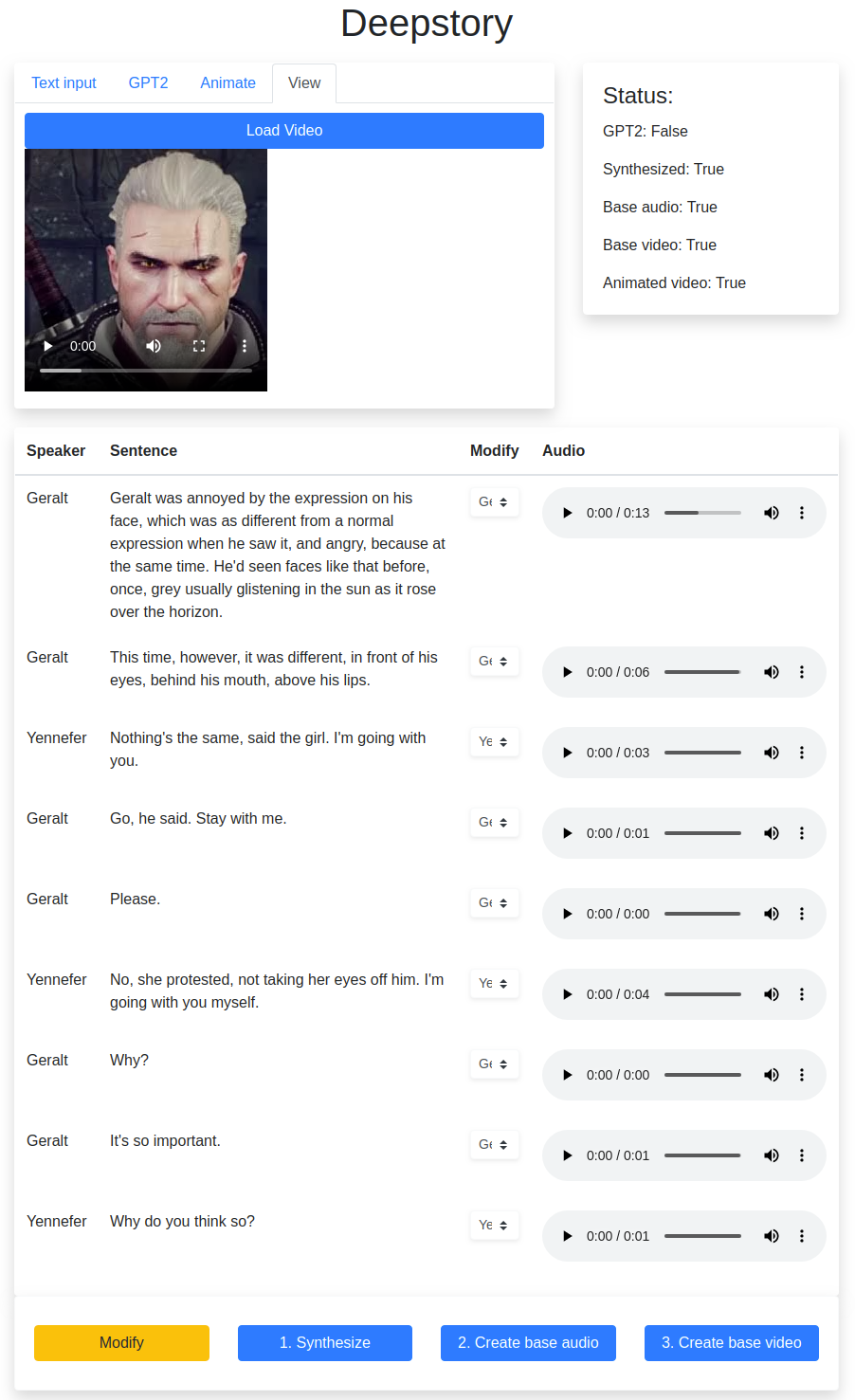
Folder structure
Deepstory
├── animator.py
├── app.py
├── data
│ ├── dctts
│ │ ├── Geralt
│ │ │ ├── ssrn.pth
│ │ │ └── t2m.pth
│ │ ├── LJ
│ │ │ ├── ssrn.pth
│ │ │ └── t2m.pth
│ │ └── Yennefer
│ │ ├── ssrn.pth
│ │ └── t2m.pth
│ ├── fom
│ │ ├── vox-256.yaml
│ │ ├── vox-adv-256.yaml
│ │ ├── vox-adv-cpk.pth.tar
│ │ └── vox-cpk.pth.tar
│ ├── gpt2
│ │ ├── Waiting for Godot
│ │ │ ├── config.json
│ │ │ ├── default.txt
│ │ │ ├── merges.txt
│ │ │ ├── pytorch_model.bin
│ │ │ ├── special_tokens_map.json
│ │ │ ├── text.txt
│ │ │ ├── tokenizer_config.json
│ │ │ └── vocab.json
│ │ └── Witcher Books
│ │ ├── config.json
│ │ ├── default.txt
│ │ ├── merges.txt
│ │ ├── pytorch_model.bin
│ │ ├── special_tokens_map.json
│ │ ├── text.txt
│ │ ├── tokenizer_config.json
│ │ └── vocab.json
│ ├── images
│ │ ├── Geralt
│ │ │ ├── 0.jpg
│ │ │ └── fx.jpg
│ │ └── Yennefer
│ │ ├── 0.jpg
│ │ ├── 1.jpg
│ │ ├── 2.jpg
│ │ ├── 3.jpg
│ │ ├── 4.jpg
│ │ └── 5.jpg
│ └── sda
│ ├── grid.dat
│ └── image.bmp
├── deepstory.py
├── generate.py
├── modules
│ ├── dctts
│ │ ├── audio.py
│ │ ├── hparams.py
│ │ ├── __init__.py
│ │ ├── layers.py
│ │ ├── ssrn.py
│ │ └── text2mel.py
│ ├── fom
│ │ ├── animate.py
│ │ ├── dense_motion.py
│ │ ├── generator.py
│ │ ├── __init__.py
│ │ ├── keypoint_detector.py
│ │ ├── sync_batchnorm
│ │ │ ├── batchnorm.py
│ │ │ ├── comm.py
│ │ │ ├── __init__.py
│ │ │ └── replicate.py
│ │ └── util.py
│ └── sda
│ ├── encoder_audio.py
│ ├── encoder_image.py
│ ├── img_generator.py
│ ├── __init__.py
│ ├── rnn_audio.py
│ ├── sda.py
│ └── utils.py
├── README.md
├── requirements.txt
├── static
│ ├── bootstrap
│ │ ├── css
│ │ │ └── bootstrap.min.css
│ │ └── js
│ │ └── bootstrap.min.js
│ ├── css
│ │ └── styles.css
│ └── js
│ └── jquery.min.js
├── templates
│ ├── animate.html
│ ├── deepstory.js
│ ├── gen_sentences.html
│ ├── gpt2.html
│ ├── index.html
│ ├── map.html
│ ├── models.html
│ ├── sentences.html
│ ├── status.html
│ └── video.html
├── test.py
├── text.txt
├── util.py
└── voice.py
Complete project download
They are available at the google drive version of this project. All the models(including Geralt, Yennefer) are included.
You have to download the spacy english model first.
make sure you have ffmpeg installed in your computer, and ffmpeg-python installed.
https://drive.google.com/drive/folders/1AxORLF-QFd2wSORzMOKlvCQSFhdZSODJ?usp=sharing
To simplify things, a google colab version will be released soon...
Requirements
It is required to have an nvidia GPU with at least 4GB of VRAM to run this project
Credits
https://github.com/tugstugi/pytorch-dc-tts
https://github.com/DinoMan/speech-driven-animation
https://github.com/AliaksandrSiarohin/first-order-model
https://github.com/huggingface/transformers
Notes
The whole project uses PyTorch, while tensorflow is listed in requirements.txt, it was used for transformers to convert a model trained from gpt-2-simple to a Pytorch model.
Only the files inside modules folder are slightly modified from the original. The remaining files are all written by me, except some parts that are referenced.
Bugs
There's still some memory issues if you synthesize sentences within a session over and over, but it takes at least 10 times to cause memory overflow.
Training models
There are other repos of tools that I created to preprocess the files. They can be found in my profile.
