Cloud Based Sql Engine Using Spark Save
Cloud-based SQL engine using SPARK where data is accessible as JDBC/ODBC data source via Spark ThriftServer.
Spark As CLoudBased SQL Engine
This project shows how to use SPARK as Cloud-based SQL Engine and expose your big-data as a JDBC/ODBC data source via the Spark thrift server.
1. Central Idea
Traditional relational Database engines like SQL had scalability problems and so evolved couple of SQL-on-Hadoop frameworks like Hive, Cloudier Impala, Presto etc. These frameworks are essentially cloud-based solutions and they all come with their own advantages and limitations. This project will demo how SparkSQL comes across as one more SQL-on-Hadoop framework.
2. Architecture
Following picture illustrates how ApacheSpark can be used as SQL-on-Hadoop framework to serve your big-data as a JDBC/ODBC data source via the Spark thrift server.:
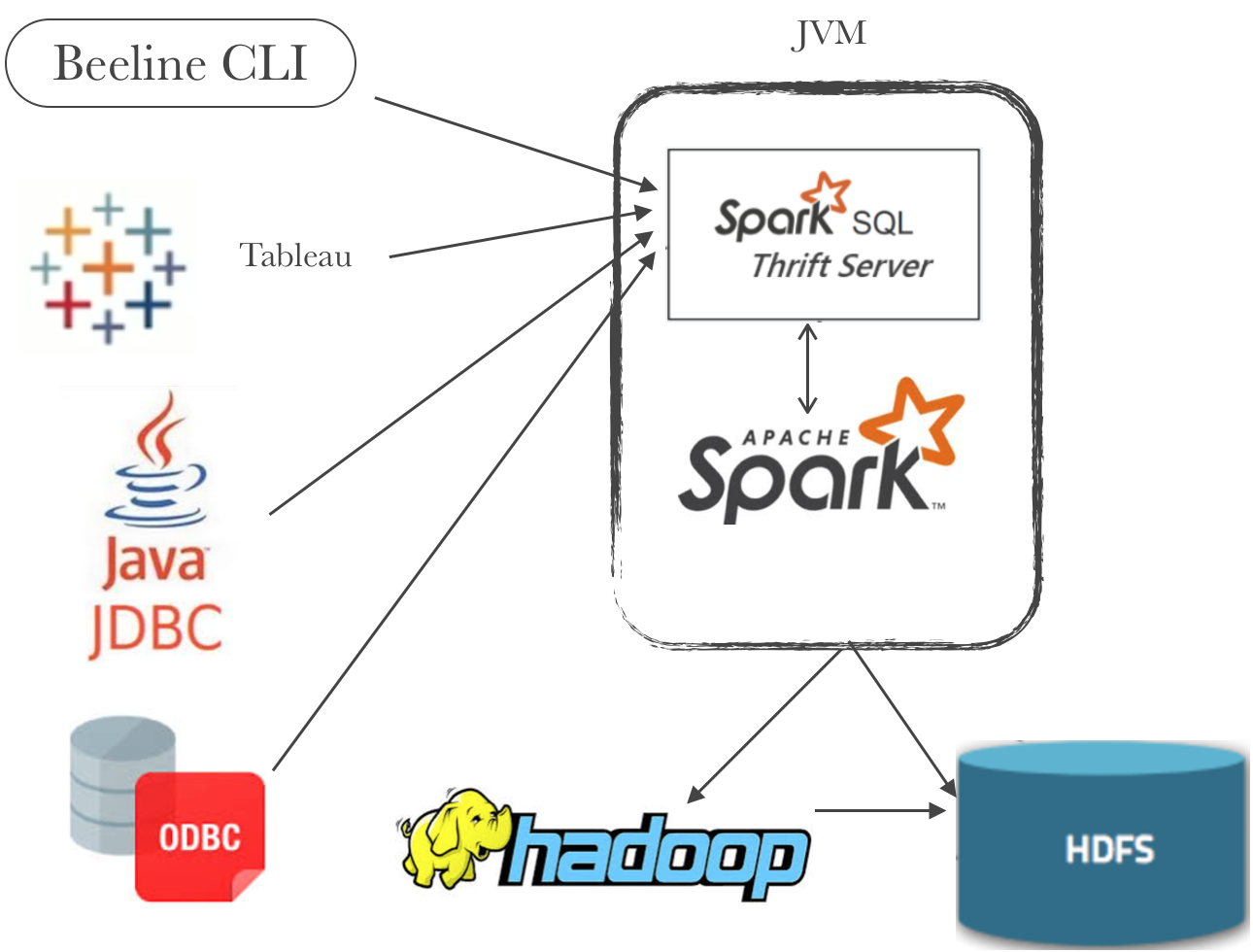
- Data from multiple sources can be pushed into Spark and then exposed as SQLtable
- These tables are then made accessible as a JDBC/ODBC data source via the Spark thrift server.
- Multiple clients like
Beeline CLI,JDBC,ODBCorBI tools like Tableauconnect to Spark thrift server. - Once the connection is established, ThriftServer will contact
SparkSQL engine to access Hive or Spark temp tables and run the sql queries on ApacheSpark framework. - Spark Thrift basically works similar to HiveServer2 thrift where HiveServer2 submits the sql queries as Hive MapReduce job vs Spark thrift server will use Spark SQL engine which underline uses full spark capabilities.
To know more about this topic, please refer to my blog here where I briefed the concept in detail.
3. Structure of the project:
- data: Contains input json used in MainApp to register sample data with SparkSql.
- src/main/java/MainApp.scala: Spark 2.1 implementation where it starts SparkSession and registers data from input.json with SparkSQL. (To keep the spark-session alive, there's a continuous while-loop in there).
- src/test/java/TestThriftClient.java: Java class to demo how to connect to thrift server as JDBC source and query the registered data
4. How to run this project?
This project does demo 2 things:
- 4.1. How to register data with SparkSql
- 4.2. How to query registered data via Spark ThriftServer - using Beeline and JDBC
4.1 How to register data with SparkSql
- Download this project.
- Build it:
mvn clean installand - Run MainApp:
spark-submit --class MainApp cloud-based-sql-engine-using-spark.jar. Tht's it! - It'll register some sample data in
recordstable with SparkSQL.
4.2 How to query registered data via Spark Thrift Server using Beeline and JDBC?
For this, first connect to Spark ThriftServer. Once the connection is established, just like HiveServer2, access Hive or Spark temp tables to run the sql queries on ApacheSpark framework. I'll show 2 ways to do this:
- Beeline: Perhaps, the simplest is to use beeline command-line tool provided in Spark's bin folder.
`$> beeline`
Beeline version 2.1.1-amzn-0 by Apache Hive
// Connect to spark thrift server..
`beeline> !connect jdbc:hive2://localhost:10000`
Connecting to jdbc:hive2://localhost:10000
Enter username for jdbc:hive2://localhost:10000:
Enter password for jdbc:hive2://localhost:10000:
// run your sql queries and access data..
`jdbc:hive2://localhost:10000> show tables;,`
-
Java JDBC: Please refer to this project's test folder where I've shared a java example
TestThriftClient.javato demo the same.
5. Requirements
- Spark 2.1.0, Java 1.8 and Scala 2.11
6. References:
- Complete guide and references to this project are briefed in my blog here.
