Beneath Save Abandoned
Beneath is a serverless real-time data platform ⚡️
![]()
Beneath is a serverless real-time data platform. Our goal is to create one end-to-end platform for data workers that combines data storage, processing, and visualization with data quality management and governance.

![]()
Beneath is a work in progress and your input makes a big difference! If you like it, star the project to show your support or reach out and tell us what you think.
🧠 Philosophy
The holy grail of data work is putting data science into production. It's glorious to build live dashboards that aggregate multiple data sources, send real-time alerts based on a machine learning model, or offer customer-specific analytics in your frontend.
But building a modern data management stack is a full-time job, and a lot can go wrong. If you were starting a project from scratch today, you might set up Postgres, BigQuery, Kafka, Airflow, DBT and Metabase just to cover the basics. Later, you would need more tools to do data quality management, data cataloging, data versioning, data lineage, permissions management, change data capture, stream processing, and so on.
Beneath is a new way of building data apps. It takes an end-to-end approach that combines data storage, processing, and visualization with data quality management and governance in one serverless platform. The idea is to provide one opinionated layer of abstraction, i.e. one SDK and UI, which under the hood builds on modern data technologies.
Beneath is inspired by services like Netlify and Vercel that make it remarkable easy for developers to build and run web apps. In that same spirit, we want to give data scientists and engineers the fastest developer experience for building data products.
🚀 Status
We started with the data storage and governance layers. You can use the Beneath Beta today to store, explore, query, stream, monitor and share data. It offers several interfaces, including a Python client, a CLI, websockets, and a web UI. The beta is stable for non-critical use cases. If you try out the beta and have any feedback to share, we'd love to hear it!
Next up, we're tackling the data processing and data visualization layers, which will bring expanded opportunity for data governance and data quality management (see the roadmap at the end of this README for progress).
🎬 Tour
The snippet below presents a whirlwind tour of the Python API:
# Create a new table
table = await client.create_table("examples/demo/foo", schema="""
type Foo @schema {
foo: String! @key
bar: Timestamp
}
""")
# Write batch or real-time data
await table.write(data)
# Load into a dataframe
df = await beneath.load_full(table)
# Replay and subscribe to changes
await beneath.consume(table, callback, subscription_path="...")
# Analyze with SQL
data = await beneath.query_warehouse(f"SELECT count(*) FROM `{table}`")
# Lookup by key, range or prefix
data = await table.query_index(filter={"foo": {"_prefix": "bar"}})
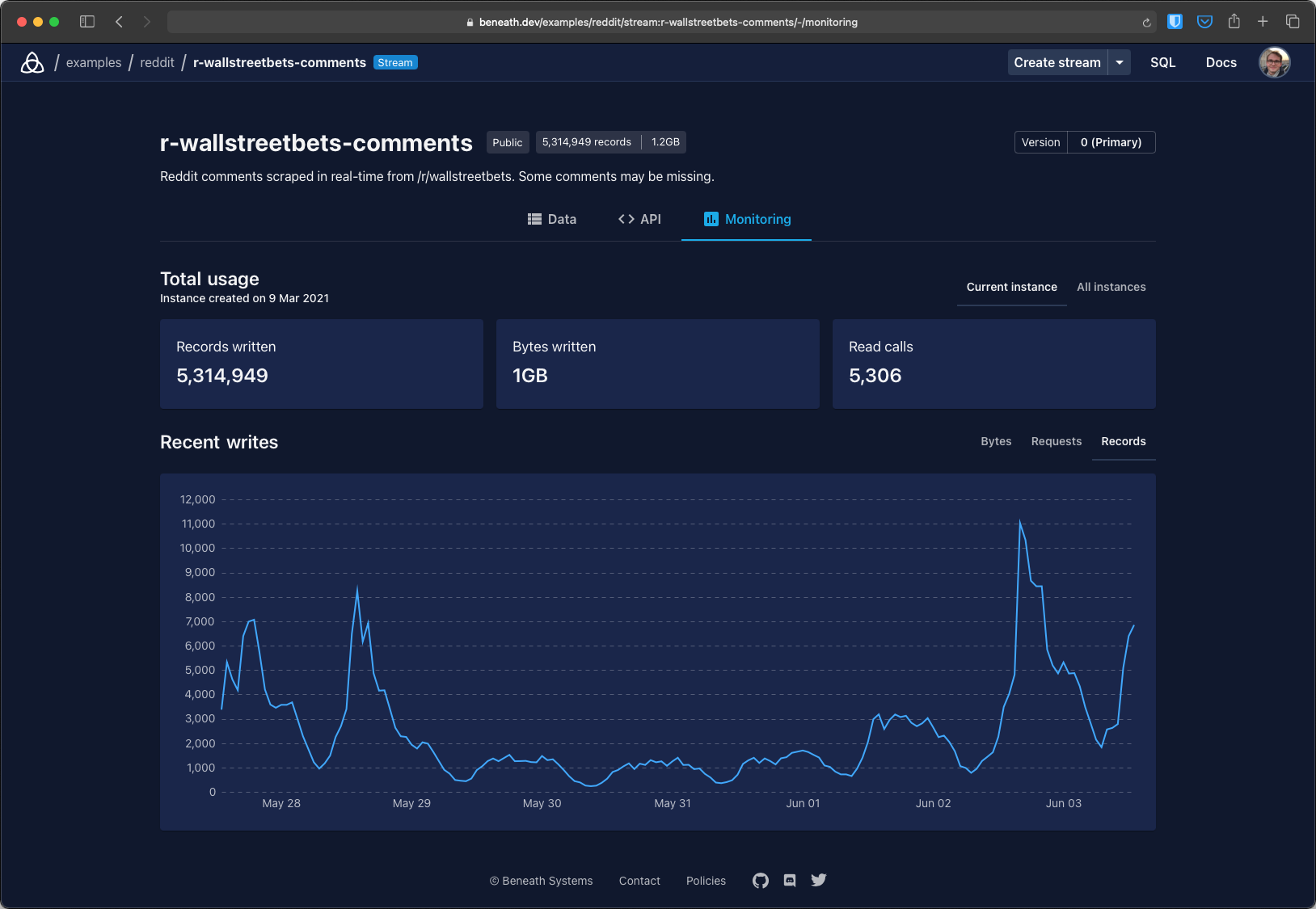
The image below shows a screenshot from the Beneath console. Check out the home page for a demo video.
🐣 Get started
The best way to try Beneath is with a free beta account. Sign up here. When you have created an account, you can:
- Install and authenticate the Beneath SDK
- Browse public projects and integrate using Python, JavaScript, Websockets and more
- Create a private or public project and start writing data
We're working on bundling a self-hosted version that you can run locally. If you're interested in self-hosting, let us know!
👋 Community and Support
- Chat in our Discord
- Email us at [email protected]
- Book a casual 20-minute meeting
🎓 Documentation
- Homepage: https://about.beneath.dev
- Documentation and tutorials: https://about.beneath.dev/docs
- Python client reference: https://python.docs.beneath.dev
- JavaScript client reference: https://js.docs.beneath.dev
- React client reference: https://react.docs.beneath.dev
📦 Features and roadmap
-
Data storage
- Log streaming for replay and subscribe
- Replication to key-value store for fast indexed lookups
- Replication to data warehouse for OLAP queries (SQL)
- Schema management and enforcement
- Data versioning
- Schema evolution and migrations
- Secondary indexes
- Strongly consistent operations for OLTP
- Geo-replicated storage
-
Data processing
- Scheduled/triggered SQL queries
- Compute sandbox for batch and streaming pipelines
- Git-integration for continuous deployments
- DAG view of tables and pipelines for data lineage
- Data app catalog (one-click parameterized deployments)
-
Data visualization and exploration
- Vega-based charts
- Dashboards composed from charts and tables
- Alerting layer
- Python notebooks (Jupyter)
-
Data governance
- Web console and CLI for creating and browsing resources
- Usage dashboards for tables, services, users and organizations
- Usage quota management
- Granular permissions management
- Service accounts with custom permissions and quotas
- API secrets (tokens) that can be issued/revoked
- Data search and discovery
- Audit logs as meta-tables
-
Data quality management
- Field validation rules, checked on write
- Alert triggers
- Data distribution tests
- Machine learning model re-training and monitoring
-
Integrations
- gRPC, REST and websockets APIs
- Command-line interface (CLI)
- Python client
- JS and React client
- PostgreSQL wire-protocol compatibility
- GraphQL API for data
- Row restricted access tokens for identity-centered apps
- Self-hosted Beneath on Kubernetes with federation
🍿 How it works
Check out the Concepts section of the docs for an overview of how Beneath works.
The contributing/ directory in this repository contains a deeper technical walkthrough of the software architecture.
🛒 License
This repository contains the full source code for Beneath. Beneath's core is source available, licensed under the Business Source License, which converts to the Apache 2.0 license after four years. All the client libraries (in the clients/ directory) and examples (in the examples/ directory) are open-source, licensed under the MIT license.
