Autogluon Versions Save
AutoGluon: Fast and Accurate ML in 3 Lines of Code
v1.1.0
2 weeks agoVersion 1.1.0
We're happy to announce the AutoGluon 1.1 release.
AutoGluon 1.1 contains major improvements to the TimeSeries module, achieving a 60% win-rate vs AutoGluon 1.0 through the addition of Chronos, a pretrained model for time series forecasting, along with numerous other enhancements. The other modules have also been enhanced through new features such as Conv-LORA support and improved performance for large tabular datasets between 5 - 30 GB in size. For a full breakdown of AutoGluon 1.1 features, please refer to the feature spotlights and the itemized enhancements below.
Join the community:
Get the latest updates:

This release supports Python versions 3.8, 3.9, 3.10, and 3.11. Loading models trained on older versions of AutoGluon is not supported. Please re-train models using AutoGluon 1.1.
This release contains 125 commits from 20 contributors!
Full Contributor List (ordered by # of commits):
@shchur @prateekdesai04 @Innixma @canerturkmen @zhiqiangdon @tonyhoo @AnirudhDagar @Harry-zzh @suzhoum @FANGAreNotGnu @nimasteryang @lostella @dassaswat @afmkt @npepin-hub @mglowacki100 @ddelange @LennartPurucker @taoyang1122 @gradientsky
Special thanks to @ddelange for their continued assistance with Python 3.11 support and Ray version upgrades!
Spotlight
AutoGluon Achieves Top Placements in ML Competitions!
AutoGluon has experienced wide-spread adoption on Kaggle since the AutoGluon 1.0 release. AutoGluon has been used in over 130 Kaggle notebooks and mentioned in over 100 discussion threads in the past 90 days! Most excitingly, AutoGluon has already been used to achieve top ranking placements in multiple competitions with thousands of competitors since the start of 2024:
| Placement | Competition | Author | Date | AutoGluon Details | Notes |
|---|---|---|---|---|---|
| :3rd_place_medal: Rank 3/2303 (Top 0.1%) | Steel Plate Defect Prediction | Samvel Kocharyan | 2024/03/31 | v1.0, Tabular | Kaggle Playground Series S4E3 |
| :2nd_place_medal: Rank 2/93 (Top 2%) | Prediction Interval Competition I: Birth Weight | Oleksandr Shchur | 2024/03/21 | v1.0, Tabular | |
| :2nd_place_medal: Rank 2/1542 (Top 0.1%) | WiDS Datathon 2024 Challenge #1 | lazy_panda | 2024/03/01 | v1.0, Tabular | |
| :2nd_place_medal: Rank 2/3746 (Top 0.1%) | Multi-Class Prediction of Obesity Risk | Kirderf | 2024/02/29 | v1.0, Tabular | Kaggle Playground Series S4E2 |
| :2nd_place_medal: Rank 2/3777 (Top 0.1%) | Binary Classification with a Bank Churn Dataset | lukaszl | 2024/01/31 | v1.0, Tabular | Kaggle Playground Series S4E1 |
| Rank 4/1718 (Top 0.2%) | Multi-Class Prediction of Cirrhosis Outcomes | Kirderf | 2024/01/01 | v1.0, Tabular | Kaggle Playground Series S3E26 |
We are thrilled that the data science community is leveraging AutoGluon as their go-to method to quickly and effectively achieve top-ranking ML solutions! For an up-to-date list of competition solutions using AutoGluon refer to our AWESOME.md, and don't hesitate to let us know if you use AutoGluon in a competition!
Chronos, a pretrained model for time series forecasting
AutoGluon-TimeSeries now features Chronos, a family of forecasting models pretrained on large collections of open-source time series datasets that can generate accurate zero-shot predictions for new unseen data. Check out the new tutorial to learn how to use Chronos through the familiar TimeSeriesPredictor API.
General
- Refactor project README & project Tagline @Innixma (#3861, #4066)
- Add AWESOME.md competition results and other doc improvements. @Innixma (#4023)
- Pandas version upgrade. @shchur @Innixma (#4079, #4089)
- PyTorch, CUDA, Lightning version upgrades. @prateekdesai04 @canerturkmen @zhiqiangdon (#3982, #3984, #3991, #4006)
- Ray version upgrade. @ddelange @tonyhoo (#3774, #3956)
- Scikit-learn version upgrade. @prateekdesai04 (#3872, #3881, #3947)
- Various dependency upgrades. @Innixma @tonyhoo (#4024, #4083)
TimeSeries
Highlights
AutoGluon 1.1 comes with numerous new features and improvements to the time series module. These include highly requested functionality such as feature importance, support for categorical covariates, ability to visualize forecasts, and enhancements to logging. The new release also comes with considerable improvements to forecast accuracy, achieving 60% win rate and 3% average error reduction compared to the previous AutoGluon version. These improvements are mostly attributed to the addition of Chronos, improved preprocessing logic, and native handling of missing values.
New Features
- Add Chronos pretrained forecasting model (tutorial). @canerturkmen @shchur @lostella (#3978, #4013, #4052, #4055, #4056, #4061, #4092, #4098)
- Measure the importance of features & covariates on the forecast accuracy with
TimeSeriesPredictor.feature_importance(). @canerturkmen (#4033, #4087) - Native missing values support (no imputation required). @shchur (#3995, #4068, #4091)
- Add support for categorical covariates. @shchur (#3874, #4037)
- Improve inference speed by persisting models in memory with
TimeSeriesPredictor.persist(). @canerturkmen (#4005) - Visualize forecasts with
TimeSeriesPredictor.plot(). @shchur (#3889) - Add
RMSLEevaluation metric. @canerturkmen (#3938) - Enable logging to file. @canerturkmen (#3877)
- Add option to keep lightning logs after training with
keep_lightning_logshyperparameter. @shchur (#3937)
Fixes and Improvements
- Automatically preprocess real-valued covariates @shchur (#4042, #4069)
- Add option to skip model selection when only one model is trained. @shchur (#4002)
- Ensure all metrics handle missing values in target @shchur (#3966)
- Fix bug when loading a GPU trained model on a CPU machine @shchur (#3979)
- Fix inconsistent random seed. @canerturkmen @shchur (#3934, #4099)
- Fix crash when calling .info after load. @afmkt (#3900)
- Fix leaderboard crash when no models trained. @shchur (#3849)
- Add prototype TabRepo simulation artifact generation. @shchur (#3829)
- Fix refit_full bug. @shchur (#3820)
- Documentation improvements, hide deprecated methods. @shchur (#3764, #4054, #4098)
- Minor fixes. @canerturkmen, @shchur, @AnirudhDagar (#4009, #4040, #4041, #4051, #4070, #4094)
AutoMM
Highlights
AutoMM 1.1 introduces the innovative Conv-LoRA, a parameter-efficient fine-tuning (PEFT) method stemming from our latest paper presented at ICLR 2024, titled "Convolution Meets LoRA: Parameter Efficient Finetuning for Segment Anything Model". Conv-LoRA is designed for fine-tuning the Segment Anything Model, exhibiting superior performance compared to previous PEFT approaches, such as LoRA and visual prompt tuning, across various semantic segmentation tasks in diverse domains including natural images, agriculture, remote sensing, and healthcare. Check out our Conv-LoRA example.
New Features
- Added Conv-LoRA, a new parameter efficient fine-tuning method. @Harry-zzh @zhiqiangdon (#3933, #3999, #4007, #4022, #4025)
- Added support for new column type: 'image_base64_str'. @Harry-zzh @zhiqiangdon (#3867)
- Added support for loading pre-trained weights in FT-Transformer. @taoyang1122 @zhiqiangdon (#3859)
Fixes and Improvements
- Fixed bugs in semantic segmentation. @Harry-zzh (#3801, #3812)
- Fixed crashes when using F1 metric. @suzhoum (#3822)
- Fixed bugs in PEFT methods. @Harry-zzh (#3840)
- Accelerated object detection training by ~30% for the high_quality and best_quality presets. @FANGAreNotGnu (#3970)
- Depreciated Grounding-DINO @FANGAreNotGnu (#3974)
- Fixed lightning upgrade issues @zhiqiangdon (#3991)
- Fixed using f1, f1_macro, f1_micro for binary classification in knowledge distillation. @nimasteryang (#3837)
- Removed MyMuPDF from installation due to the license issue. Users need to install it by themselves to do document classification. @zhiqiangdon (#4093)
Tabular
Highlights
AutoGluon-Tabular 1.1 primarily focuses on bug fixes and stability improvements. In particular, we have greatly improved the runtime performance for large datasets between 5 - 30 GB in size through the usage of subsampling for decision threshold calibration and the weighted ensemble fitting to 1 million rows, maintaining the same quality while being far faster to execute. We also adjusted the default weighted ensemble iterations from 100 to 25, which will speedup all weighted ensemble fit times by 4x. We heavily refactored the fit_pseudolabel logic, and it should now achieve noticeably stronger results.
Fixes and Improvements
- Fix return value in
predictor.fit_weighted_ensemble(refit_full=True). @Innixma (#1956) - Enhance performance on large datasets through subsampling. @Innixma (#3977)
- Fix refit_full crash when out of memory. @Innixma (#3977)
- Refactor and enhance
.fit_pseudolabellogic. @Innixma (#3930) - Fix crash in memory check during HPO for LightGBM, CatBoost, and XGBoost. @Innixma (#3931)
- Fix dynamic stacking on windows. @Innixma (#3893)
- LightGBM version upgrade. @mglowacki100, @Innixma (#3427)
- Fix memory-safe sub-fits being skipped if Ray is not initialized. @LennartPurucker (#3868)
- Logging improvements. @AnirudhDagar (#3873)
- Hide deprecated methods. @Innixma (#3795)
- Documentation improvements. @Innixma @AnirudhDagar (#2024, #3975, #3976, #3996)
Docs and CI
- Add auto benchmarking report generation. @prateekdesai04 (#4038, #4039)
- Fix tabular tests for Windows. @tonyhoo (#4036)
- Fix hanging tabular unit tests. @prateekdesai04 (#4031)
- Fix CI evaluation. @suzhoum (#4019)
- Add package version comparison between CI runs @prateekdesai04 (#3962, #3968, #3972)
- Update conf.py to reflect current year. @dassaswat (#3932)
- Avoid redundant unit test runs. @prateekdesai04 (#3942)
- Fix colab notebook links @prateekdesai04 (#3926)
New Contributors
- @npepin-hub made their first contribution in https://github.com/autogluon/autogluon/pull/3898
- @afmkt made their first contribution in https://github.com/autogluon/autogluon/pull/3900
- @dassaswat made their first contribution in https://github.com/autogluon/autogluon/pull/3932
- @nimasteryang made their first contribution in https://github.com/autogluon/autogluon/pull/3837
- @zkalson made their first contribution in https://github.com/autogluon/autogluon/pull/4096
v1.0.0
5 months agoVersion 1.0.0
Today is finally the day... AutoGluon 1.0 has arrived!! After over four years of development and 2061 commits from 111 contributors, we are excited to share with you the culmination of our efforts to create and democratize the most powerful, easy to use, and feature rich automated machine learning system in the world.
AutoGluon 1.0 comes with transformative enhancements to predictive quality resulting from the combination of multiple novel ensembling innovations, spotlighted below. Besides performance enhancements, many other improvements have been made that are detailed in the individual module sections.
This release supports Python versions 3.8, 3.9, 3.10, and 3.11. Loading models trained on older versions of AutoGluon is not supported. Please re-train models using AutoGluon 1.0.
This release contains 223 commits from 17 contributors!
Full Contributor List (ordered by # of commits):
@shchur, @zhiqiangdon, @Innixma, @prateekdesai04, @FANGAreNotGnu, @yinweisu, @taoyang1122, @LennartPurucker, @Harry-zzh, @AnirudhDagar, @jaheba, @gradientsky, @melopeo, @ddelange, @tonyhoo, @canerturkmen, @suzhoum
Join the community:
Get the latest updates:
Spotlight
Tabular Performance Enhancements
AutoGluon 1.0 features major enhancements to predictive quality, establishing a new state-of-the-art in Tabular modeling. To the best of our knowledge, AutoGluon 1.0 marks the largest leap forward in the state-of-the-art for tabular data since the original AutoGluon paper from March 2020. The enhancements come primarily from two features: Dynamic stacking to mitigate stacked overfitting, and a new learned model hyperparameters portfolio via Zeroshot-HPO, obtained from the newly released TabRepo ensemble simulation library. Together, they lead to a 75% win-rate compared to AutoGluon 0.8 with faster inference speed, lower disk usage, and higher stability.
AutoML Benchmark Results
OpenML released the official 2023 AutoML Benchmark results on November 16th, 2023. Their results show AutoGluon 0.8 as the state-of-the-art in AutoML systems across a wide variety of tasks: "Overall, in terms of model performance, AutoGluon consistently has the highest average rank in our benchmark." We now showcase that AutoGluon 1.0 achieves far superior results even to AutoGluon 0.8!
Below is a comparison on the OpenML AutoML Benchmark across 1040 tasks. LightGBM, XGBoost, and CatBoost results were obtained via AutoGluon, and other methods are from the official AutoML Benchmark 2023 results. AutoGluon 1.0 has a 95%+ win-rate against traditional tabular models, including a 99% win-rate vs LightGBM and a 100% win-rate vs XGBoost. AutoGluon 1.0 has between an 82% and 94% win-rate against other AutoML systems. For all methods, AutoGluon is able to achieve >10% average loss improvement (Ex: Going from 90% accuracy to 91% accuracy is a 10% loss improvement). AutoGluon 1.0 achieves first place in 63% of tasks, with lightautoml having the second most at 12% (AutoGluon 0.8 previously took first place 48% of the time). AutoGluon 1.0 even achieves a 7.4% average loss improvement over AutoGluon 0.8!
| Method | AG Winrate | AG Loss Improvement | Rescaled Loss | Rank | Champion |
|---|---|---|---|---|---|
| AutoGluon 1.0 (Best, 4h8c) | - | - | 0.04 | 1.95 | 63% |
| lightautoml (2023, 4h8c) | 84% | 12.0% | 0.2 | 4.78 | 12% |
| H2OAutoML (2023, 4h8c) | 94% | 10.8% | 0.17 | 4.98 | 1% |
| FLAML (2023, 4h8c) | 86% | 16.7% | 0.23 | 5.29 | 5% |
| MLJAR (2023, 4h8c) | 82% | 23.0% | 0.33 | 5.53 | 6% |
| autosklearn (2023, 4h8c) | 91% | 12.5% | 0.22 | 6.07 | 4% |
| GAMA (2023, 4h8c) | 86% | 15.4% | 0.28 | 6.13 | 5% |
| CatBoost (2023, 4h8c) | 95% | 18.2% | 0.28 | 6.89 | 3% |
| TPOT (2023, 4h8c) | 91% | 23.1% | 0.4 | 8.15 | 1% |
| LightGBM (2023, 4h8c) | 99% | 23.6% | 0.4 | 8.95 | 0% |
| XGBoost (2023, 4h8c) | 100% | 24.1% | 0.43 | 9.5 | 0% |
| RandomForest (2023, 4h8c) | 97% | 25.1% | 0.53 | 9.78 | 1% |
Not only is AutoGluon more accurate in 1.0, it is also more stable thanks to our new usage of Ray subprocesses during low-memory training, resulting in 0 task failures on the AutoML Benchmark.
AutoGluon 1.0 is capable of achieving the fastest inference throughput of any AutoML system while still obtaining state-of-the-art results. By specifying the infer_limit fit argument, users can trade off between accuracy and inference speed to meet their needs.
As seen in the below plot, AutoGluon 1.0 sets the Pareto Frontier for quality and inference throughput, achieving Pareto Dominance compared to all other AutoML systems. AutoGluon 1.0 High achieves superior performance to AutoGluon 0.8 Best with 8x faster inference and 8x less disk usage!
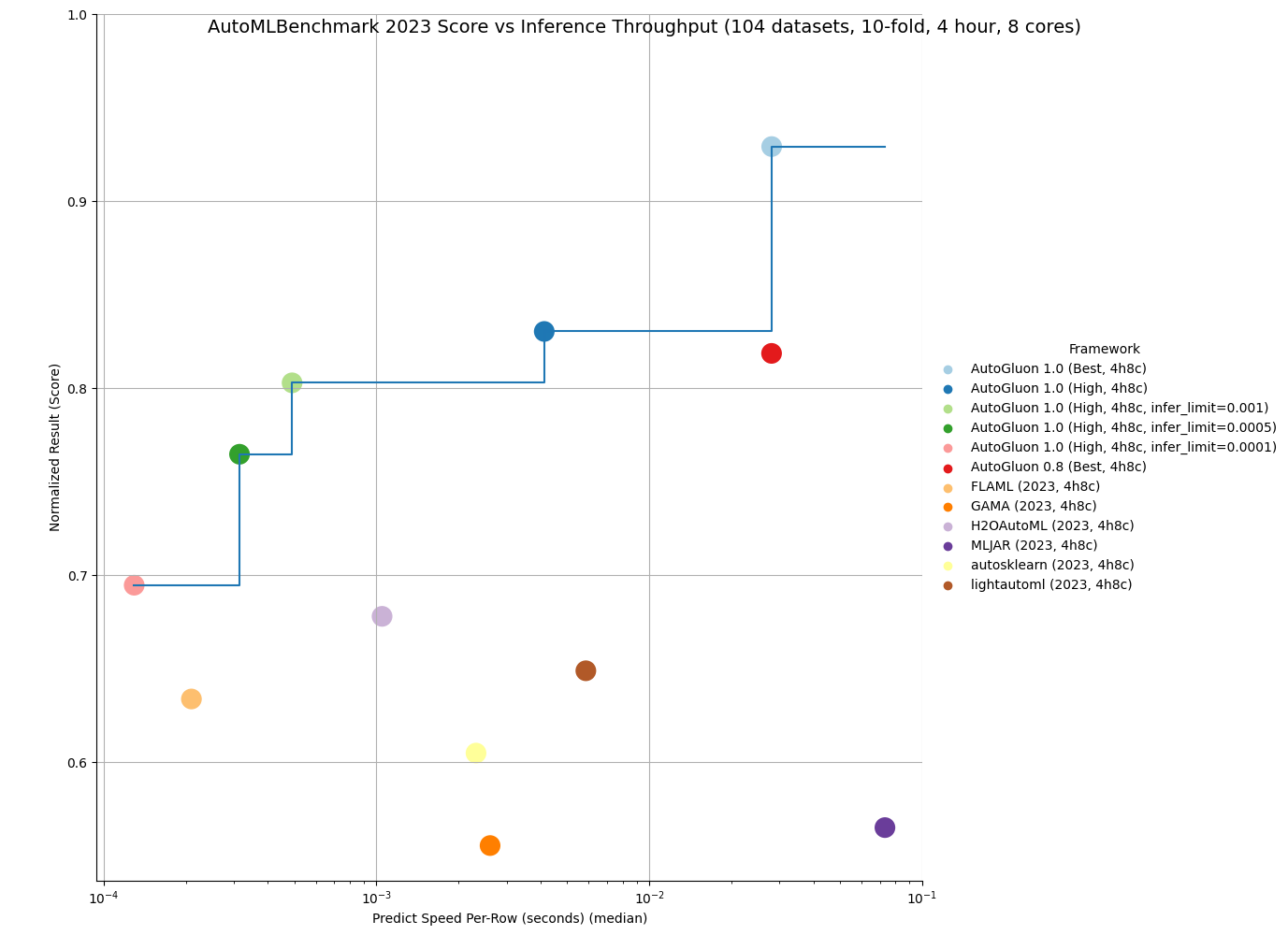
You can get more details on the results here.
We are excited to see what our users can accomplish with AutoGluon 1.0's enhanced performance. As always, we will continue to improve AutoGluon in future releases to push the boundaries of AutoML forward for all.
AutoGluon Multimodal (AutoMM) Highlights in One Figure

AutoMM Uniqueness
AutoGluon Multimodal (AutoMM) distinguishes itself from other open-source AutoML toolboxes like AutosSklearn, LightAutoML, H2OAutoML, FLAML, MLJAR, TPOT and GAMA, which mainly focus on tabular data for classification or regression. AutoMM is designed for fine-tuning foundation models across multiple modalities—image, text, tabular, and document, either individually or combined. It offers extensive capabilities for tasks like classification, regression, object detection, named entity recognition, semantic matching, and image segmentation. In contrast, other AutoML systems generally have limited support for image or text, typically using a few pretrained models like EfficientNet or hand-crafted rules like bag-of-words as feature extractors. AutoMM provides a uniquely comprehensive and versatile approach to AutoML, being the only AutoML system to support flexible multimodality and support for a wide range of tasks. A comparative table detailing support for various data modalities, tasks, and model types is provided below.
| Data | Task | Model | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| image | text | tabular | document | any combination | classification | regression | object detection | semantic matching | named entity recognition | image segmentation | traditional models | deep learning models | foundation models | |
| LightAutoML | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||
| H2OAutoML | ✓ | ✓ | ✓ | ✓ | ||||||||||
| FLAML | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||
| MLJAR | ✓ | ✓ | ✓ | ✓ | ||||||||||
| AutoSklearn | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||
| GAMA | ✓ | ✓ | ✓ | ✓ | ||||||||||
| TPOT | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||
| AutoMM | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
Special Thanks
We would like to conclude this spotlight by thanking Pieter Gijsbers, Sébastien Poirier, Erin LeDell, Joaquin Vanschoren, and the rest of the AutoML Benchmark authors for their key role in providing a shared and extensive benchmark to monitor the progress of the AutoML field. Their support has been invaluable to the AutoGluon project's continued growth.
We would also like to thank Frank Hutter, who continues to be a leader within the AutoML field, for organizing the AutoML Conference in 2022 and 2023 to bring the community together to share ideas and align on a compelling vision.
Finally, we would like to thank Alex Smola and Mu Li for championing open source software at Amazon to make this project possible.
Additional Special Thanks
- Special thanks to @LennartPurucker for leading development of dynamic stacking
- Special thanks to @geoalgo for co-authoring TabRepo to enable Zeroshot-HPO
- Special thanks to @ddelange for helping to add Python 3.11 support
- Special thanks to @mglowacki100 for providing numerous feedback and suggestions
- Special thanks to @Harry-zzh for contributing the new semantic segmentation problem type
General
Highlights
- Python 3.11 Support @ddelange @yinweisu (#3190)
Other Enhancements
- Added system info logging utility @Innixma (#3718)
Dependency Updates
- Upgraded torch to
>=2.0,<2.2@zhiqiangdon @yinweisu @shchur (#3404, #3587, #3588) - Upgraded numpy to
>=1.21,<1.29@prateekdesai04 (#3709) - Upgraded Pandas to
>=2.0,<2.2@yinweisu @tonyhoo @shchur (#3498) - Upgraded scikit-learn to
>=1.3,<1.5@yinweisu @tonyhoo @shchur (#3498) - Upgraded Pillow to
>=10.0.1,<11@jaheba (#3688) - Upgraded scipy to
>=1.5.4,<1.13@prateekdesai04 (#3709) - Upgraded LightGBM to
>=3.3,<4.2@mglowacki100 @prateekdesai04 @Innixma (#3427, #3709, #3733) - Upgraded XGBoost to
>=1.6,<2.1@Innixma (#3768) - Various minor dependency updates @jaheba (#3689)
Tabular
Highlights
AutoGluon 1.0 features major enhancements to predictive quality, establishing a new state-of-the-art in Tabular modeling. Refer to the spotlight section above for more details!
New Features
- Added
dynamic_stackingpredictor fit argument to mitigate stacked overfitting @LennartPurucker @Innixma (#3616) - Added zeroshot-HPO learned portfolio as new hyperparameters for
best_qualityandhigh_qualitypresets. @Innixma @geoalgo (#3750) - Added experimental scikit-learn API compatible wrappers to TabularPredictor. You can access them via
from autogluon.tabular.experimental import TabularClassifier, TabularRegressor. @Innixma (#3769) - Added
predictor.model_failures()@Innixma (#3421) - Added enhanced FT-Transformer @taoyang1122 @Innixma (#3621, #3644, #3692)
- Added
predictor.simulation_artifact()to support integration with TabRepo @Innixma (#3555)
Performance Improvements
- Enhanced FastAI model quality on regression via output clipping @LennartPurucker @Innixma (#3597)
- Added Skip-connection Weighted Ensemble @LennartPurucker (#3598)
- Fix memory leaks by using ray processes for sequential fitting @LennartPurucker (#3614)
- Added dynamic parallel folds support to better utilize compute in low memory scenarios @yinweisu @Innixma (#3511)
- Fixed linear model crashes during HPO and added search space for linear models @Innixma (#3571, #3720)
Other Enhancements
- Multi-layer stacking now produces deterministic results @LennartPurucker (#3573)
- Various model dependency updates @mglowacki100 (#3373)
- Various code cleanup and logging improvements @Innixma (#3408, #3570, #3652, #3734)
Bug Fixes / Code and Doc Improvements
- Fixed incorrect model memory usage calculation @Innixma (#3591)
- Fixed
infer_limitbeing used incorrectly when bagging @Innixma (#3467) - Fixed rare edge-case FastAI model crash @Innixma (#3416)
- Various minor bug fixes @Innixma (#3418, #3480)
AutoMM
AutoGluon Multimodal (AutoMM) is designed to simplify the fine-tuning of foundation models for downstream applications with just three lines of code. It seamlessly integrates with popular model zoos such as HuggingFace Transformers, TIMM, and MMDetection, providing support for a diverse range of data modalities, including image, text, tabular, and document data, whether used individually or in combination.
New Features
- Semantic Segmentation
- Introducing the new problem type
semantic_segmentation, for fine-tuning Segment Anything Model (SAM) with three lines of code. @Harry-zzh @zhiqiangdon (#3645, #3677, #3697, #3711, #3722, #3728) - Added comprehensive benchmarks from diverse domains, including natural images, agriculture, remote sensing, and healthcare.
- Utilizing parameter-efficient finetuning (PEFT) LoRA, showcasing consistent superior performance over alternatives (VPT, adaptor, BitFit, SAM-adaptor, and LST) in the extensive benchmarks.
- Added one semantic segmentation tutorial @zhiqiangdon (#3716).
- Using SAM-ViT Huge by default (GPU memory > 25GB required).
- Introducing the new problem type
- Few Shot Classification
- Added the new
few_shot_classificationproblem type for training few shot classifiers on images or texts. @zhiqiangdon (#3662, #3681, #3695) - Leveraging image/text foundation models to extract features and train SVM classifiers.
- Added one few shot classification tutorial. @zhiqiangdon (#3662)
- Added the new
- Supported torch.compile for faster training (experimental and torch >=2.2 required) @zhiqiangdon (#3520).
Performance Improvements
- Improved default image backbones, achieving a 100% win-rate on the image benchmark. @taoyang1122 (#3738)
- Replaced MLPs with FT-Transformer as the default tabular backbones, resulting in a 67% win-rate on the text+tabular benchmark. @taoyang1122 (#3732)
- Using both the improved default image backbones and FT-Transformer achieves a 62% win-rate on the text+tabular+image benchmark. @taoyang1122 (#3732, #3738)
Stability Enhancements
- Enabled rigorous multi-GPU CI testing. @prateekdesai04 (#3566)
- Fixed multi-GPU issues. @FANGAreNotGnu (#3617 #3665 #3684 #3691, #3639, #3618)
Enhanced Usability
- Supported custom evaluation metrics, which allows defining custom metric object and passing it to the
eval_metricargument @taoyang1122 (#3548) - Supported multi-GPU training in notebooks (experimental) @zhiqiangdon (#3484)
- Improved logging with system info @zhiqiangdon (#3735)
Improved Scalability
- The introduction of the new learner class design facilitates easier support for new tasks and data modalities within AutoMM, enhancing overall scalability. @zhiqiangdon (#3650, #3685, #3735)
Other Enhancements
- Added the option
hf_text.use_fastfor customizing fast tokenizer usage inhf_textmodels. @zhiqiangdon (#3379) - Added fallback evaluation/validation metric, supporting
f1_macrof1_micro, andf1_weighted. @FANGAreNotGnu (#3696) - Supported multi-GPU inference with the DDP strategy. @zhiqiangdon (#3445, #3451)
- Upgraded torch to 2.0. @zhiqiangdon (#3404)
- Upgraded lightning to 2.0 @zhiqiangdon (#3419)
- Upgraded torchmetrics to 1.0 @zhiqiangdon (#3422)
Code Improvements
- Refactored AutoMM with the learner class for improved design. @zhiqiangdon (#3650, #3685, #3735)
- Refactored FT-Transformer. @taoyang1122 (#3621, #3700)
- Refactored the visualizers of object detection, semantic segmentation, and NER. @zhiqiangdon (#3716)
- Other code refactor/clean-up: @zhiqiangdon @FANGAreNotGnu (#3383 #3399 #3434 #3667 #3684 #3695)
Bug Fixes/Doc Improvements
- Fixed HPO for focal loss. @suzhoum (#3739)
- Fixed one ONNX export issue. @AnirudhDagar (#3725)
- Improved AutoMM introduction for clarity. @zhiqiangdon (#3388 #3726)
- Improved AutoMM API doc. @zhiqiangdon @AnirudhDagar (#3772 #3777)
- Other bug fixes @zhiqiangdon @FANGAreNotGnu @taoyang1122 @tonyhoo @rsj123 @AnirudhDagar (#3384, #3424, #3526, #3593, #3615, #3638, #3674, #3693, #3702, #3690, #3729, #3736, #3474, #3456, #3590, #3660)
- Other doc improvements @zhiqiangdon @FANGAreNotGnu @taoyang1122 (#3397, #3461, #3579, #3670, #3699, #3710, #3716, #3737, #3744, #3745, #3680)
TimeSeries
Highlights
AutoGluon 1.0 features numerous usability and performance improvements to the TimeSeries module. These include automatic handling of missing data and irregular time series, new forecasting metrics (including custom metric support), advanced time series cross-validation options, and new forecasting models. AutoGluon produces state-of-the-art results in forecast accuracy, achieving 70%+ win rate compared to other popular forecasting frameworks.
New features
- Support for custom forecasting metrics @shchur (#3760, #3602)
- New forecasting metrics
WAPE,RMSSE,SQL+ improved documentation for metrics @melopeo @shchur (#3747, #3632, #3510, #3490) - Improved robustness:
TimeSeriesPredictorcan now handle data with all pandas frequencies, irregular timestamps, or missing values represented byNaN@shchur (#3563, #3454) - New models: intermittent demand forecasting models based on conformal prediction (
ADIDA,CrostonClassic,CrostonOptimized,CrostonSBA,IMAPA);WaveNetandNPTSfrom GluonTS; new baseline models (Average,SeasonalAverage,Zero) @canerturkmen @shchur (#3706, #3742, #3606, #3459) - Advanced cross-validation options: avoid retraining the models for each validation window with
refit_every_n_windowsor adjust the step size between validation windows withval_step_sizearguments toTimeSeriesPredictor.fit@shchur (#3704, #3537)
Enhancements
- Enable Ray Tune for deep-learning forecasting models @canerturkmen (#3705)
- Support passing multiple evaluation metrics to
TimeSeriesPredictor.evaluate@shchur (#3646) - Static features can now be passed directly to
TimeSeriesDataFrame.from_pathandTimeSeriesDataFrame.from_data_frameconstructors @shchur (#3635)
Performance improvements
- Much more accurate forecasts at low time limits thanks to new presets and updated logic for splitting the training time across models @shchur (#3749, #3657, #3741)
- Faster training and prediction + lower memory usage for
DirectTabularandRecursiveTabularmodels (#3740, #3620, #3559) - Enable early stopping and improve inference speed for GluonTS models @shchur (#3575)
- Reduce import time for
autogluon.timeseriesby moving import statements inside model classes (#3514)
Bug Fixes / Code and Doc Improvements
- Improve log messages @shchur (#3721)
- Add reference to the publication on AutoGluon-TimeSeries to README @shchur (#3482)
- Align API of
TimeSeriesPredictorwithTabularPredictor, remove deprecated methods @shchur (#3714, #3655, #3396) - General bug fixes and improvements @shchur(#3758, #3756, #3755, #3754, #3746, #3743, #3727, #3698, #3654, #3653, #3648, #3628, #3588, #3560, #3558, #3536, #3533, #3523, #3522, #3476, #3463)
EDA
The EDA module will be released at a later time, as it requires additional development effort before it is ready for 1.0.
We will make an announcement when EDA is ready for release. For now, please continue to use "autogluon.eda==0.8.2".
Deprecations
General
-
autogluon.core.spaceshas been deprecated. Please useautogluon.common.spacesinstead @Innixma (#3701)
Tabular
Tabular will log warnings if using the deprecated methods. Deprecated methods are planned to be removed in AutoGluon 1.2 @Innixma (#3701)
-
autogluon.tabular.TabularPredictor-
predictor.get_model_names()->predictor.model_names() -
predictor.get_model_names_persisted()->predictor.model_names(persisted=True) -
predictor.compile_models()->predictor.compile() -
predictor.persist_models()->predictor.persist() -
predictor.unpersist_models()->predictor.unpersist() -
predictor.get_model_best()->predictor.model_best -
predictor.get_pred_from_proba()->predictor.predict_from_proba() -
predictor.get_oof_pred_proba()->predictor.predict_proba_oof() -
predictor.get_oof_pred()->predictor.predict_oof() -
predictor.get_model_full_dict()->predictor.model_refit_map() -
predictor.get_size_disk()->predictor.disk_usage() -
predictor.get_size_disk_per_file()->predictor.disk_usage_per_file() -
predictor.leaderboard()silentargument deprecated, replaced bydisplay, defaults to False- Same for
predictor.evaluate()andpredictor.evaluate_predictions()
- Same for
-
AutoMM
- Deprecated the
FewShotSVMPredictorin favor of the newfew_shot_classificationproblem type @zhiqiangdon (#3699) - Deprecated the
AutoMMPredictorin favor ofMultiModalPredictor@zhiqiangdon (#3650) -
autogluon.multimodal.MultiModalPredictor- Deprecated the
configargument in the fit API. @zhiqiangdon (#3679) - Deprecated the
init_scratchandpipelinearguments in the init API @zhiqiangdon (#3668)
- Deprecated the
TimeSeries
-
autogluon.timeseries.TimeSeriesPredictor- Deprecated argument
TimeSeriesPredictor(ignore_time_index: bool). Now, if the data contains irregular timestamps, either convert it to regular frequency withdata = data.convert_frequency(freq)or provide frequency when creating the predictor asTimeSeriesPredictor(freq=freq). -
predictor.evaluate()now returns a dictionary (previously returned a float) -
predictor.score()->predictor.evaluate() -
predictor.get_model_names()->predictor.model_names() -
predictor.get_model_best()->predictor.model_best - Metric
"mean_wQuantileLoss"has been renamed to"WQL" -
predictor.leaderboard()silentargument deprecated, replaced bydisplay, defaults to False - When setting
hyperparametersto a string inpredictor.fit(), supported values are now"default","light"and"very_light"
- Deprecated argument
-
autogluon.timeseries.TimeSeriesDataFrame-
df.to_regular_index()->df.convert_frequency() - Deprecated method
df.get_reindexed_view(). Please see deprecation notes forignore_time_indexunderTimeSeriesPredictorabove for information on how to deal with irregular timestamps
-
- Models
- All models based on MXNet (
DeepARMXNet,MQCNNMXNet,MQRNNMXNet,SimpleFeedForwardMXNet,TemporalFusionTransformerMXNet,TransformerMXNet) have been removed - Statistical models from Statmodels (
ARIMA,Theta,ETS) have been replaced by their counterparts from StatsForecast (#3513). Note that these models now have different hyperparameter names. -
DirectTabularis now implemented usingmlforecastbackend (same asRecursiveTabular), most hyperparameter names for the model have changed.
- All models based on MXNet (
-
autogluon.timeseries.TimeSeriesEvaluatorhas been deprecated. Please use metrics available inautogluon.timeseries.metricsinstead. -
autogluon.timeseries.splitter.MultiWindowSplitterandautogluon.timeseries.splitter.LastWindowSplitterhave been deprecated. Please usenum_val_windowsandval_step_sizearguments toTimeSeriesPredictor.fitinstead (alternatively, useautogluon.timeseries.splitter.ExpandingWindowSplitter).
Papers
AutoGluon-TimeSeries: AutoML for Probabilistic Time Series Forecasting
We have published a paper on AutoGluon-TimeSeries at AutoML Conference 2023 (Paper Link, YouTube Video). In the paper, we benchmarked AutoGluon and popular open-source forecasting frameworks (including DeepAR, TFT, AutoARIMA, AutoETS, AutoPyTorch). AutoGluon produces SOTA results in point and probabilistic forecasting, and even achieves 65% win rate against the best-in-hindsight combination of models.
TabRepo: A Large Scale Repository of Tabular Model Evaluations and its AutoML Applications
We have published a paper on Tabular Zeroshot-HPO ensembling simulation to arXiv (Paper Link, GitHub). This paper is key to achieving the performance improvements seen in AutoGluon 1.0, and we plan to continue to develop the code-base to support future enhancements.
XTab: Cross-table Pretraining for Tabular Transformers
We have published a paper on tabular Transformer pre-training at ICML 2023 (Paper Link, GitHub). In the paper we demonstrate state-of-the-art performance for tabular deep learning models, including being able to match the performance of XGBoost and LightGBM models. While the pre-trained transformer is not yet incorporated into AutoGluon, we plan to integrate it in a future release.
Learning Multimodal Data Augmentation in Feature Space
Our paper on learning multimodal data augmentation was accepted at ICLR 2023 (Paper Link, GitHub). This paper introduces a plug-and-play module to learn multimodal data augmentation in feature space, with no constraints on the identities of the modalities or the relationship between modalities. We show that it can (1) improve the performance of multimodal deep learning architectures, (2) apply to combinations of modalities that have not been previously considered, and (3) achieve state-of-the-art results on a wide range of applications comprised of image, text, and tabular data. This work is not yet incorporated into AutoGluon, but we plan to integrate it in a future release.
Data Augmentation for Object Detection via Controllable Diffusion Models
Our paper on generative object detection data augmentation has been accepted at WACV 2024 (Paper and GitHub link will be available soon). This paper proposes a data augmentation pipeline based on controllable diffusion models and CLIP, with visual prior generation to guide the generation and post-filtering by category-calibrated CLIP scores to control its quality. We demonstrate that the performance improves across various tasks and settings when using our augmentation pipeline with different detectors. Although diffusion models are currently not integrated into AutoGluon, we plan to incorporate the data augmentation techniques in a future release.
Adapting Image Foundation Models for Video Understanding
We have published a paper on how to efficiently adapt image foundation models for video understanding at ICLR 2023 (Paper Link, GitHub). This paper introduces spatial adaptation, temporal adaptation and joint adaptation to gradually equip a frozen image model with spatiotemporal reasoning capability. The proposed method achieves competitive or even better performance than traditional full finetuning while largely saving the training cost of large foundation models.
v0.8.2
10 months agoVersion 0.8.2
v0.8.2 is a hot-fix release to pin pydantic version to avoid crashing during HPO
As always, only load previously trained models using the same version of AutoGluon that they were originally trained on. Loading models trained in different versions of AutoGluon is not supported.
See the full commit change-log here: https://github.com/autogluon/autogluon/compare/0.8.1...0.8.2
This version supports Python versions 3.8, 3.9, and 3.10.
Changes
- codespell: action, config + some typos fixed @yarikoptic @yinweisu (#3323)
- Unpin sentencepiece @zhiqiangdon (#3368)
- Pin pydantic @yinweisu (3370)
v0.8.1
10 months agoVersion 0.8.1
v0.8.1 is a bug fix release.
As always, only load previously trained models using the same version of AutoGluon that they were originally trained on. Loading models trained in different versions of AutoGluon is not supported.
See the full commit change-log here: https://github.com/autogluon/autogluon/compare/0.8.0...0.8.1
This version supports Python versions 3.8, 3.9, and 3.10.
Changes
Documentation improvements
- Update google analytics property @gidler (#3330)
- Add Discord Link @Innixma (#3332)
- Add community section to website front page @Innixma (#3333)
- Update Windows Conda install instructions @gidler (#3346)
- Add some missing Colab buttons in tutorials @gidler (#3359)
Bug Fixes / General Improvements
- Move PyMuPDF to optional @Innixma @zhiqiangdon (#3331)
- Remove TIMM in core setup @Innixma (#3334)
- Update persist_models max_memory 0.1 -> 0.4 @Innixma (#3338)
- Lint modules @yinweisu (#3337, #3339, #3344, #3347)
- Remove fairscale @zhiqiangdon (#3342)
- Fix refit crash @Innixma (#3348)
- Fix
DirectTabularmodel failing for some metrics; hide warnings produced byAutoARIMA@shchur (#3350) - Pin dependencies @yinweisu (#3358)
- Reduce per gpu batch size for AutoMM high_quality_hpo to avoid out of memory error for some corner cases @zhiqiangdon (#3360)
- Fix HPO crash by setting reuse_actor to False @yinweisu (#3361)
v0.8.0
10 months agoVersion 0.8.0
We're happy to announce the AutoGluon 0.8 release.
NEW: 
Note: Loading models trained in different versions of AutoGluon is not supported.
This release contains 196 commits from 20 contributors!
See the full commit change-log here: https://github.com/autogluon/autogluon/compare/0.7.0...0.8.0
Special thanks to @geoalgo for the joint work in generating the experimental tabular Zeroshot-HPO portfolio this release!
Full Contributor List (ordered by # of commits):
@shchur, @Innixma, @yinweisu, @gradientsky, @FANGAreNotGnu, @zhiqiangdon, @gidler, @liangfu, @tonyhoo, @cheungdaven, @cnpgs, @giswqs, @suzhoum, @yongxinw, @isunli, @jjaeyeon, @xiaochenbin9527, @yzhliu, @jsharpna, @sxjscience
AutoGluon 0.8 supports Python versions 3.8, 3.9, and 3.10.
Changes
Highlights
- AutoGluon TimeSeries introduced several major improvements, including new models, upgraded presets that lead to better forecast accuracy, and optimizations that speed up training & inference.
- AutoGluon Tabular now supports calibrating the decision threshold in binary classification (API), leading to massive improvements in metrics such as
f1andbalanced_accuracy. It is not uncommon to seef1scores improve from0.70to0.73as an example. We strongly encourage all users who are using these metrics to try out the new decision threshold calibration logic. - AutoGluon MultiModal introduces two new features: 1) PDF document classification, and 2) Open Vocabulary Object Detection.
- AutoGluon MultiModal upgraded the presets for object detection, now offering
medium_quality,high_quality, andbest_qualityoptions. The empirical results demonstrate significant ~20% relative improvements in the mAP (mean Average Precision) metric, using the same preset. - AutoGluon Tabular has added an experimental Zeroshot HPO config which performs well on small datasets <10000 rows when at least an hour of training time is provided (~60% win-rate vs
best_quality). To try it out, specifypresets="experimental_zeroshot_hpo_hybrid"when callingfit(). - AutoGluon EDA added support for Anomaly Detection and Partial Dependence Plots.
- AutoGluon Tabular has added experimental support for TabPFN, a pre-trained tabular transformer model. Try it out via
pip install autogluon.tabular[all,tabpfn](hyperparameter key is "TABPFN")! You can also try it out via specifyingpresets="experimental_extreme_quality".
General
- General doc improvements @tonyhoo @Innixma @yinweisu @gidler @cnpgs @isunli @giswqs (#2940, #2953, #2963, #3007, #3027, #3059, #3068, #3083, #3128, #3129, #3130, #3147, #3174, #3187, #3256, #3258, #3280, #3306, #3307, #3311, #3313)
- General code fixes and improvements @yinweisu @Innixma (#2921, #3078, #3113, #3140, #3206)
- CI improvements @yinweisu @gidler @yzhliu @liangfu @gradientsky (#2965, #3008, #3013, #3020, #3046, #3053, #3108, #3135, #3159, #3283, #3185)
- New AutoGluon Webpage @gidler @shchur (#2924)
- Support sample_weight in RMSE @jjaeyeon (#3052)
- Move AG search space to common @yinweisu (#3192)
- Deprecation utils @yinweisu (#3206, #3209)
- Update namespace packages for PEP420 compatibility @gradientsky (#3228)
Multimodal
AutoGluon MultiModal (also known as AutoMM) introduces two new features: 1) PDF document classification, and 2) Open Vocabulary Object Detection. Additionally, we have upgraded the presets for object detection, now offering medium_quality, high_quality, and best_quality options. The empirical results demonstrate significant ~20% relative improvements in the mAP (mean Average Precision) metric, using the same preset.
New Features
- PDF Document Classification. See tutorial @cheungdaven (#2864, #3043)
- Open Vocabulary Object Detection. See tutorial @FANGAreNotGnu (#3164)
Performance Improvements
- Upgrade the detection engine from mmdet 2.x to mmdet 3.x, and upgrade our presets @FANGAreNotGnu (#3262)
-
medium_quality: yolo-s -> yolox-l -
high_quality: yolox-l -> DINO-Res50 -
best_quality: yolox-x -> DINO-Swin_l
-
- Speedup fusion model training with deepspeed strategy. @liangfu (#2932)
- Enable detection backbone freezing to boost finetuning speed and save GPU usage @FANGAreNotGnu (#3220)
Other Enhancements
- Support passing data path to the fit() API @zhiqiangdon (#3006)
- Upgrade TIMM to the latest v0.9.* @zhiqiangdon (#3282)
- Support xywh output for object detection @FANGAreNotGnu (#2948)
- Fusion model inference acceleration with TensorRT @liangfu (#2836, #2987)
- Support customizing advanced image data augmentation. Users can pass a list of torchvision transform objects as image augmentation. @zhiqiangdon (#3022)
- Add yoloxm and yoloxtiny @FangAreNotGnu (#3038)
- Add MultiImageMix Dataset for Object Detection @FangAreNotGnu (#3094)
- Support loading specific checkpoints. Users can load the intermediate checkpoints other than model.ckpt and last.ckpt. @zhiqiangdon (#3244)
- Add some predictor properties for model statistics @zhiqiangdon (#3289)
-
trainable_parametersreturns the number of trainable parameters. -
total_parametersreturns the number of total parameters. -
model_sizereturns the model size measured by megabytes.
-
Bug Fixes / Code and Doc Improvements
- General bug fixes and improvements @zhiqiangdon @liangfu @cheungdaven @xiaochenbin9527 @Innixma @FANGAreNotGnu @gradientsky @yinweisu @yongxinw (#2939, #2989, #2983, #2998, #3001, #3004, #3006, #3025, #3026, #3048, #3055, #3064, #3070, #3081, #3090, #3103, #3106, #3119, #3155, #3158, #3167, #3180, #3188, #3222, #3261, #3266, #3277, #3279, #3261, #3267)
- General doc improvements @suzhoum (#3295, #3300)
- Remove clip from fusion models @liangfu (#2946)
- Refactor inferring problem type and output shape @zhiqiangdon (#3227)
- Log GPU info including GPU total memory, free memory, GPU card name, and CUDA version during training @zhiqaingdon (#3291)
Tabular
New Features
- Added
calibrate_decision_threshold(tutorial), which allows to optimize a given metric's decision threshold for predictions to strongly enhance the metric score. @Innixma (#3298) - We've added an experimental Zeroshot HPO config, which performs well on small datasets <10000 rows when at least an hour of training time is provided. To try it out, specify
presets="experimental_zeroshot_hpo_hybrid"when callingfit()@Innixma @geoalgo (#3312) - The TabPFN model is now supported as an experimental model. TabPFN is a viable model option when inference speed is not a concern, and the number of rows of training data is less than 10,000. Try it out via
pip install autogluon.tabular[all,tabpfn]! @Innixma (#3270) - Backend support for distributed training, which will be available with the next Cloud module release. @yinweisu (#3054, #3110, #3115, #3131, #3142, #3179, #3216)
Performance Improvements
- Accelerate boolean preprocessing @Innixma (#2944)
Other Enhancements
- Add quantile regression support for CatBoost @shchur (#3165)
- Implement quantile regression for LGBModel @shchur (#3168)
- Log to file support @yinweisu (#3232)
- Add support for
included_model_types@yinweisu (#3239) - Add enable_categorical=True support to XGBoost @Innixma (#3286)
Bug Fixes / Code and Doc Improvements
- Cross-OS loading of a fit TabularPredictor should now work properly @yinweisu @Innixma
- General bug fixes and improvements @Innixma @cnpgs @shchur @yinweisu @gradientsky (#2865, #2936, #2990, #3045, #3060, #3069, #3148, #3182, #3199, #3226, #3257, #3259, #3268, #3269, #3287, #3288, #3285, #3293, #3294, #3302)
- Move interpretable logic to InterpretableTabularPredictor @Innixma (#2981)
- Enhance drop_duplicates, enable by default @Innixma (#3010)
- Refactor params_aux & memory checks @Innixma (#3033)
- Raise regression
pred_proba@Innixma (#3240)
TimeSeries
In v0.8 we introduce several major improvements to the Time Series module, including new models, upgraded presets that lead to better forecast accuracy, and optimizations that speed up training & inference.
Highlights
- New models:
PatchTSTandDLinearfrom GluonTS, andRecursiveTabularbased on integration with themlforecastlibrary @shchur (#3177, #3184, #3230) - Improved accuracy and reduced overall training time thanks to updated presets @shchur (#3281, #3120)
- 3-6x faster training and inference for
AutoARIMA,AutoETS,Theta,DirectTabular,WeightedEnsemblemodels @shchur (#3062, #3214, #3252)
New Features
- Dramatically faster repeated calls to
predict(),leaderboard()andevaluate()thanks to prediction caching @shchur (#3237) - Reduce overfitting by using multiple validation windows with the
num_val_windowsargument tofit()@shchur (#3080) - Exclude certain models from presets with the
excluded_model_typesargument tofit()@shchur (#3231) - New method
refit_full()that refits models on combined train and validation data @shchur (#3157) - Train multiple configurations of the same model by providing lists in the
hyperparametersargument @shchur (#3183) - Time limit set by
time_limitis now respected by all models @shchur (#3214)
Enhancements
- Improvements to the
DirectTabularmodel (previously calledAutoGluonTabular): faster featurization, trained as a quantile regression model ifeval_metricis set to"mean_wQuantileLoss"@shchur (#2973, #3211) - Use correct seasonal period when computing the MASE metric @shchur (#2970)
- Check the AutoGluon version when loading
TimeSeriesPredictorfrom disk @shchur (#3233)
Minor Improvements / Documentation / Bug Fixes
- Update documentation and tutorials @shchur (#2960, #2964, #3296, #3297)
- General bug fixes and improvements @shchur (#2977, #3058, #3066, #3160, #3193, #3202, #3236, #3255, #3275, #3290)
Exploratory Data Analysis (EDA) tools
In 0.8 we introduce a few new tools to help with data exploration and feature engineering:
- Anomaly Detection @gradientsky (#3124, #3137) - helps to identify unusual patterns or behaviors in data that deviate significantly from the norm. It's best used when finding outliers, rare events, or suspicious activities that could indicate fraud, defects, or system failures. Check the Anomaly Detection Tutorial to explore the functionality.
- Partial Dependence Plots @gradientsky (#3071, #3079) - visualize the relationship between a feature and the model's output for each individual instance in the dataset. Two-way variant can visualize potential interactions between any two features. Please see this tutorial for more detail: Using Interaction Charts To Learn Information About the Data
Bug Fixes / Code and Doc Improvements
- Switch regression analysis in
quick_fitto use residuals plot @gradientsky (#3039) - Added
explain_rowsmethod toautogluon.eda.auto- Kernel SHAP visualization @gradientsky (#3014) - General improvements and fixes @gradientsky (#2991, #3056, #3102, #3107, #3138)
v0.7.0
1 year agoVersion 0.7.0
We're happy to announce the AutoGluon 0.7 release. This release contains a new experimental module autogluon.eda for exploratory
data analysis. AutoGluon 0.7 offers conda-forge support, enhancements to Tabular, MultiModal, and Time Series
modules, and many quality of life improvements and fixes.
As always, only load previously trained models using the same version of AutoGluon that they were originally trained on. Loading models trained in different versions of AutoGluon is not supported.
This release contains 170 commits from 19 contributors!
See the full commit change-log here: https://github.com/autogluon/autogluon/compare/v0.6.2...v0.7.0
Special thanks to @MountPOTATO who is a first time contributor to AutoGluon this release!
Full Contributor List (ordered by # of commits):
@Innixma, @zhiqiangdon, @yinweisu, @gradientsky, @shchur, @sxjscience, @FANGAreNotGnu, @yongxinw, @cheungdaven, @liangfu, @tonyhoo, @bryanyzhu, @suzhoum, @canerturkmen, @giswqs, @gidler, @yzhliu, @Linuxdex and @MountPOTATO
AutoGluon 0.7 supports Python versions 3.8, 3.9, and 3.10. Python 3.7 is no longer supported as of this release.
Changes
NEW: AutoGluon available on conda-forge
As of AutoGluon 0.7 release, AutoGluon is now available on conda-forge (#612)!
Kudos to the following individuals for making this happen:
- @giswqs for leading the entire effort and being a 1-man army driving this forward.
- @h-vetinari for providing excellent advice for working with conda-forge and some truly exceptional feedback.
- @arturdaraujo, @PertuyF, @ngam and @priyanga24 for their encouragement, suggestions, and feedback.
- The conda-forge team for their prompt and effective reviews of our (many) PRs.
- @gradientsky for testing M1 support during the early stages.
- @sxjscience, @zhiqiangdon, @canerturkmen, @shchur, and @Innixma for helping upgrade our downstream dependency versions to be compatible with conda.
- Everyone else who has supported this process either directly or indirectly.
NEW: autogluon.eda (Exploratory Data Analysis)
We are happy to announce AutoGluon Exploratory Data Analysis (EDA) toolkit. Starting with v0.7, AutoGluon now can analyze and visualize different aspects of data and models. We invite you to explore the following tutorials: Quick Fit, Dataset Overview, Target Variable Analysis, Covariate Shift Analysis. Other materials can be found in EDA Section of the website.
General
- Added Python 3.10 support. @Innixma (#2721)
- Dropped Python 3.7 support. @Innixma (#2722)
- Removed
daskanddistributeddependencies. @Innixma (#2691) - Removed
autogluon.textandautogluon.visionmodules. We recommend usingautogluon.multimodalfor text and vision tasks going forward.
AutoMM
AutoGluon MultiModal (a.k.a AutoMM) supports three new features: 1) document classification; 2) named entity recognition for Chinese language; 3) few shot learning with SVM
Meanwhile, we removed autogluon.text and autogluon.vision as these features are supported in autogluon.multimodal
New features
- Document Classification
- Add scanned document classification (experimental).
- Customers can train models for scanned document classification in a few lines of codes
- See tutorials
- Contributors and commits: @cheungdaven (#2765, #2826, #2833, #2928)
- NER for Chinese Language
- Support Chinese named entity recognition
- See tutorials
- Contributors and commits: @cheungdaven (#2676, #2709)
- Few Shot Learning with SVM
- Improved few shot learning by adding SVM support
- See tutorials
- Contributors and commits: @yongxinw (#2850)
Other Enhancements
- Add new loss function
FocalLoss. @yongxinw (#2860) - Add matcher realtime inference support. @zhiqiangdon (#2613)
- Add matcher HPO. @zhiqiangdon (#2619)
- Add YOLOX models (small, large, and x-large) and update presets for object detection. @FANGAreNotGnu (#2644, #2867, #2927, #2933)
- Add AutoMM presets @zhiqiangdon. (#2620, #2749, #2839)
- Add model dump for models from HuggingFace, timm and mmdet. @suzhoum @FANGAreNotGnu @liangfu (#2682, #2700, #2737, #2840)
- Bug fix / refactor for NER. @cheungdaven (#2659, #2696, #2759, #2773)
- MultiModalPredictor import time reduction. @sxjscience (#2718)
Bug Fixes / Code and Doc Improvements
- NER example with visualization. @sxjscience (#2698)
- Bug fixes / Code and Doc Improvements. @sxjscience @tonyhoo @giswqs (#2708, #2714, #2739, #2782, #2787, #2857, #2818, #2858, #2859, #2891, #2918, #2940, #2906, #2907)
- Support of Label-Studio file export in AutoMM and added examples. @MountPOTATO (#2615)
- Added example of few-shot memory bank model with feature extraction based on Tip-adapter. @Linuxdex (#2822)
Deprecations
-
autogluon.visionnamespace is deprecated. @bryanyzhu (#2790, #2819, #2832) -
autogluon.textnamespace is deprecated. @sxjscience @Innixma (#2695, #2847)
Tabular
- TabularPredictor’s inference speed has been heavily optimized, with an average 250% speedup for real-time inference. This means that TabularPredictor can satisfy <10 ms end-to-end latency on many datasets when using
infer_limit, and thehigh_qualitypreset can satisfy <100 ms end-to-end latency on many datasets by default. - TabularPredictor’s
"multimodal"hyperparameter preset now leverages the full capabilities of MultiModalPredictor, resulting in stronger performance on datasets containing a mix of tabular, image, and text features.
Performance Improvements
- Upgraded versions of all dependency packages to use the latest releases. @Innixma (#2823, #2829, #2834, #2887, #2915)
- Accelerated ensemble inference speed by 150% by removing TorchThreadManager context switching. @liangfu (#2472)
- Accelerated FastAI neural network inference speed by 100x+ and training speed by 10x on datasets with many features. @Innixma (#2909)
- (From 0.6.1) Avoid unnecessary DataFrame copies to accelerate feature preprocessing by 25%. @liangfu (#2532)
- (From 0.6.1) Refactor
NN_TORCHmodel to be dataset iterable, leading to a 100% inference speedup. @liangfu (#2395) - MultiModalPredictor is now used as a member of the ensemble when
TabularPredictor.fitis passedhyperparameters="multimodal". @Innixma (#2890)
API Enhancements
- Added
predict_multiandpredict_proba_multimethods toTabularPredictorto efficiently get predictions from multiple models. @Innixma (#2727) - Allow label column to not be present in
leaderboardcalls when scoring is disabled. @Innixma (#2912)
Deprecations
- Added a deprecation warning when calling
predict_probawithproblem_type="regression". This will raise an exception in a future release. @Innixma (#2684)
Bug Fixes / Doc Improvements
- Fixed incorrect time_limit estimation in
NN_TORCHmodel. @Innixma (#2909) - Fixed error when fitting with only text features. @Innixma (#2705)
- Fixed error when
calibrate=True, use_bag_holdout=TrueinTabularPredictor.fit. @Innixma (#2715) - Fixed error when tuning
n_estimatorswith RandomForest / ExtraTrees models. @Innixma (#2735) - Fixed missing onnxruntime dependency on Linux/MacOS when installing optional dependency
skl2onnx. @liangfu (#2923) - Fixed edge-case RandomForest error on Windows. @yinweisu (#2851)
- Added improved logging for
refit_full. @Innixma (#2913) - Added
compile_modelsto the deployment tutorial. @liangfu (#2717) - Various internal code refactoring. @Innixma (#2744, #2887)
- Various doc and logging improvements. @Innixma (#2668)
autogluon.timeseries
New features
-
TimeSeriesPredictornow supports past covariates (a.k.a.dynamic features or related time series which is not known for time steps to be predicted). @shchur (#2665, #2680) - New models from StatsForecast got introduced in
TimeSeriesPredictorfor various presets (medium_quality,high_qualityandbest_quality). @shchur (#2758) - Support missing value imputation for TimeSeriesDataFrame which allows users to customize filling logics for missing values and fill gaps in an irregular sampled times series. @shchur (#2781)
- Improve quantile forecasting performance of the AutoGluon-Tabular forecaster using the empirical noise distribution. @shchur (#2740)
Bug Fixes / Doc Improvements
- Bug fixes and code improvements. @shchur @canerturkmen (#2703, #2712, #2713, #2769, #2771, #2816, #2817, #2875, #2877, #2919)
- Doc improvements. @shchur @gidler (#2772, #2783, #2800)
v0.6.2
1 year agoVersion 0.6.2
v0.6.2 is a security and bug fix release.
As always, only load previously trained models using the same version of AutoGluon that they were originally trained on. Loading models trained in different versions of AutoGluon is not supported.
See the full commit change-log here: https://github.com/autogluon/autogluon/compare/v0.6.1...v0.6.2
Special thanks to @daikikatsuragawa and @yzhliu who were first time contributors to AutoGluon this release!
This version supports Python versions 3.7 to 3.9. 0.6.x are the last releases that will support Python 3.7.
Changes
Documentation improvements
- Ray usage FAQ (#2559) - @yinweisu
- Fix missing Predictor API doc (#2573) - @gidler
- 2023 Roadmap Update (#2590) - @Innixma
- Image classifiction tutorial update for bytearray (#2598) - @suzhoum
- Fix broken tutorial index links (#2617) - @shchur
- Improve timeseries quickstart tutorial (#2653) - @shchur
Bug Fixes / Security
- [multimodal] Refactoring and bug fixes(#2554, #2541, #2477, #2569, #2578, #2613, #2620, #2630, #2633, #2635, #2647, #2645, #2652, #2659) - @zhiqiangdon, @yongxinw, @FANGAreNotGnu, @sxjscience, @Innixma
- [multimodal] Support of named entity recognition (#2556) - @cheungdaven
- [multimodal] bytearray support for image modality (#2495) - @suzhoum
- [multimodal] Support HPO for matcher (#2619) - @zhiqiangdon
- [multimodal] Support Onnx export for timm image model (#2564) - @liangfu
- [tabular] Refactoring and bug fixes (#2387, #2595,#2599, #2589, #2628, #2376, #2642, #2646, #2650, #2657) - @Innixma, @liangfu, @yzhliu, @daikikatsuragawa, @yinweisu
- [tabular] Fix ensemble folding (#2582) - @yinweisu
- [tabular] Convert ColumnTransformer in tabular NN from sklearn to onnx (#2503) - @liangfu
- [tabular] Throw error on non-finite values in label column ($2509) - @gidler
- [timeseries] Refactoring and bug fixes (#2584, #2594, #2605, #2606) - @shchur
- [timeseries] Speed up data preparation for local models (#2587) - @shchur
- [timeseries] Spped up prediction for GluonTS models (#2593) - @shchur
- [timeseries] Speed up the train/val splitter (#2586) - @shchur [timeseries] Speed up TimeSeriesEnsembleSelection.fit (#2602) - @shchur
- [security] Update torch (#2588) - @gradientsky
v0.6.1
1 year agoVersion 0.6.1
v0.6.1 is a security fix / bug fix release.
As always, only load previously trained models using the same version of AutoGluon that they were originally trained on. Loading models trained in different versions of AutoGluon is not supported.
See the full commit change-log here: https://github.com/autogluon/autogluon/compare/v0.6.0...v0.6.1
Special thanks to @lvwerra who is first time contributors to AutoGluon this release!
This version supports Python versions 3.7 to 3.9. 0.6.x are the last releases that will support Python 3.7.
Changes
Documentation improvements
- Fix object detection tutorial layout (#2450) - @bryanyzhu
- Add multimodal cheatsheet (#2467) - @sxjscience
- Refactoring detection inference quickstart and bug fix on fit->predict - @yongxinw, @zhiqiangdon, @Innixma, @BingzhaoZhu, @tonyhoo
- Use Pothole Dataset in Tutorial for AutoMM Detection (#2468) - @FANGAreNotGnu
- add time series cheat sheet, add time series to doc titles (#2478) - @canerturkmen
- Update all repo references to autogluon/autogluon (#2463) - @gidler
- fix typo in object detection tutorial CI (#2516) - @tonyhoo
Bug Fixes / Security
- bump evaluate to 0.3.0 (#2433) - @lvwerra
- Add finetune/eval tests for AutoMM detection (#2441) - @FANGAreNotGnu
- Adding Joint IA3_LoRA as efficient finetuning strategy (#2451) - @Raldir
- Fix AutoMM warnings about object detection (#2458) - @zhiqiangdon
- [Tabular] Speed up feature transform in tabular NN model (#2442) - @liangfu
- fix matcher cpu inference bug (#2461) - @sxjscience
- [timeseries] Silence GluonTS JSON warning (#2454) - @shchur
- [timeseries] Fix pandas groupby bug + GluonTS index bug (#2420) - @shchur
- Simplified infer speed throughput calculation (#2465) - @Innixma
- [Tabular] make tabular nn dataset iterable (#2395) - @liangfu
- Remove old images and dataset download scripts (#2471) - @Innixma
- Support image bytearray in AutoMM (#2490) - @suzhoum
- [NER] add an NER visualizer (#2500) - @cheungdaven
- [Cloud] Lazy load TextPredcitor and ImagePredictor which will be deprecated (#2517) - @tonyhoo
- Use detectron2 visualizer and update quickstart (#2502) - @yongxinw, @zhiqiangdon, @Innixma, @BingzhaoZhu, @tonyhoo
- fix df preprocessor properties (#2512) - @zhiqiangdon
- [timeseries] Fix info and fit_summary for TimeSeriesPredictor (#2510) - @shchur
- [timeseries] Pass known_covariates to component models of the WeightedEnsemble - @shchur
- [timeseries] Gracefully handle inconsistencies in static_features provided by user - @shchur
- [security] update Pillow to >=9.3.0 (#2519) - @gradientsky
- [CI] upgrade codeql v1 to v2 as v1 will be deprecated (#2528) - @tonyhoo
- Upgrade scikit-learn-intelex version (#2466) - @Innixma
- Save AutoGluonTabular model to the correct folder (#2530) - @shchur
- support predicting with model fitted on v0.5.1 (#2531) - @liangfu
- [timeseries] Implement input validation for TimeSeriesPredictor and improve debug messages - @shchur
- [timeseries] Ensure that timestamps are sorted when creating a TimeSeriesDataFrame - @shchur
- Add tests for preprocessing mutation (#2540) - @Innixma
- Fix timezone datetime edgecase (#2538) - @Innixma, @gradientsky
- Mmdet Fix Image Identifier (#2492) - @FANGAreNotGnu
- [timeseries] Warn if provided data has a frequency that is not supported - @shchur
- Train and inference with different image data types (#2535) - @suzhoum
- Remove pycocotools (#2548) - @bryanyzhu
- avoid copying identical dataframes (#2532) - @liangfu
- Fix AutoMM Tokenizer (#2550) - @FANGAreNotGnu
- [Tabular] Resource Allocation Fix (#2536) - @yinweisu
- imodels version cap (#2557) - @yinweisu
- Fix int32/int64 difference between windows and other platforms; fix mutation issue (#2558) - @gradientsky
v0.5.3
1 year agoVersion 0.5.3
v0.5.3 is a security hotfix release.
This release is non-breaking when upgrading from v0.5.0. As always, only load previously trained models using the same version of AutoGluon that they were originally trained on. Loading models trained in different versions of AutoGluon is not supported.
See the full commit change-log here: https://github.com/awslabs/autogluon/compare/v0.5.2...v0.5.3
This version supports Python versions 3.7 to 3.9.
v0.6.0
1 year agoVersion 0.6.0
We're happy to announce the AutoGluon 0.6 release. 0.6 contains major enhancements to Tabular, Multimodal, and Time Series modules, along with many quality of life improvements and fixes.
As always, only load previously trained models using the same version of AutoGluon that they were originally trained on. Loading models trained in different versions of AutoGluon is not supported.
This release contains 263 commits from 25 contributors!
See the full commit change-log here: https://github.com/awslabs/autogluon/compare/v0.5.2...v0.6.0
Special thanks to @cheungdaven, @suzhoum, @BingzhaoZhu, @liangfu, @Harry-zzh, @gidler, @yongxinw, @martinschaef, @giswqs, @Jalagarto, @geoalgo, @lujiaying and @leloykun who were first time contributors to AutoGluon this release!
Full Contributor List (ordered by # of commits):
@shchur, @yinweisu, @zhiqiangdon, @Innixma, @FANGAreNotGnu, @canerturkmen, @sxjscience, @gradientsky, @cheungdaven, @bryanyzhu, @suzhoum, @BingzhaoZhu, @yongxinw, @tonyhoo, @liangfu, @Harry-zzh, @Raldir, @gidler, @martinschaef, @giswqs, @Jalagarto, @geoalgo, @lujiaying, @leloykun, @yiqings
This version supports Python versions 3.7 to 3.9. This is the last release that will support Python 3.7.
Changes
AutoMM
AutoGluon Multimodal (a.k.a AutoMM) supports three new features: 1) object detection, 2) named entity recognition, and 3) multimodal matching. In addition, the HPO backend of AutoGluon Multimodal has been upgraded to ray 2.0. It also supports fine-tuning billion-scale FLAN-T5-XL model on a single AWS g4.2x-large instance with improved parameter-efficient finetuning. Starting from 0.6, we recommend using autogluon.multimodal rather than autogluon.text or autogluon.vision and added deprecation warnings.
New features
-
Object Detection
- Add new problem_type
"object_detection". - Customers can run inference with pretrained object detection models and train their own model with three lines of code.
- Integrate with open-mmlab/mmdetection, which supports classic detection architectures like Faster RCNN, and more efficient and performant architectures like YOLOV3 and VFNet.
- See tutorials and examples for more detail.
- Contributors and commits: @FANGAreNotGnu, @bryanyzhu, @zhiqiangdon, @yongxinw, @sxjscience, @Harry-zzh (#2025, #2061, #2131, #2181, #2196, #2215, #2244, #2265, #2290, #2311, #2312, #2337, #2349, #2353, #2360, #2362, #2365, #2380, #2381, #2391, #2393, #2400, #2419, #2421, #2063, #2104, #2411)
- Add new problem_type
-
Named Entity Recognition
- Add new problem_type
"ner". - Customers can train models to extract named entities with three lines of code.
- The implementation supports any backbones in huggingface/transformer, including the recently FLAN-T5 series released by Google.
- See tutorials for more detail.
- Contributors and commits: @cheungdaven (#2183, #2232, #2220, #2282, #2295, #2301, #2337, #2346, #2361, #2372, #2394, #2412)
- Add new problem_type
-
Multimodal Matching
- Add new problem_type
"text_similarity","image_similarity","image_text_similarity". - Users can now extract semantic embeddings with pretrained models for text-text, image-image, and text-image matching problems.
- Moreover, users can further finetune these models with relevance data.
- The semantic text embedding model can also be combined with BM25 to form a hybrid indexing solution.
- Internally, AutoGluon Multimodal implements a twin-tower architecture that is flexible in the choice of backbones for each tower. It supports image backbones in TIMM, text backbones in huggingface/transformers, and also the CLIP backbone.
- See tutorials for more detail.
- Contributors and commits: @zhiqiangdon @FANGAreNotGnu @cheungdaven @suzhoum @sxjscience @bryanyzhu (#1975, #1994, #2142, #2179, #2186, #2217, #2235, #2284, #2297, #2313, #2326, #2337, #2347, #2357, #2358, #2362, #2363, #2375, #2378, #2404, #2416, #2407, #2417)
- Add new problem_type
-
Miscellaneous minor fixes. @cheungdaven @FANGAreNotGnu @geoalgo @zhiqiangdon (#2402, #2409, #2026, #2401, #2418)
Other Enhancements
- Fix the FT-Transformer implementation and support Fastformer. @BingzhaoZhu @yiqings (#1958, #2194, #2251, #2344, #2379, #2386)
- Support finetuning billion-scale FLAN-T5-XL in a single AWS g4.2x-large instance via improved parameter-efficient finetuning. See tutorial. @Raldir @sxjscience (#2032, #2108, #2285, #2336, #2352)
- Upgrade multimodal HPO to use ray 2.0 and also add new tutorial. @yinweisu @suzhoum @bryanyzhu (#2206, #2341)
- Further improvement on model distillation. Add example and tutorial. @FANGAreNotGnu @sxjscience (#1983, #2064, #2397)
- Revise the default presets of AutoMM for image classification problems. @bryanyzhu (#2351)
- Support backend=“automm” in autogluon.vision. @bryanyzhu (#2316)
- Add deprecated warning to autogluon.vision and autogluon.text and point the usage to autogluon.multimodal. @bryanyzhu @sxjscience (#2268, #2315)
- Examples about Kaggle: Feedback Prize prediction competition. We created a solution with AutoGluon Multimodal that obtained 152/1557 in the public leaderboard and 170/1557 in the private leaderboard, which is among the top 12% participants. The solution is public days before the DDL of the competition and obtained more than 3000 views. @suzhoum @MountPOTATO (#2129, #2168, #2333)
- Improve native inference speed. @zhiqiangdon (#2051, #2157, #2161, #2171)
- Other improvements, security/bug fixes. @zhiqiangdon @sxjscience @FANGAreNotGnu, @yinweisu @Innixma @tonyhoo @martinschaef @giswqs @tonyhoo (#1980, #1987, #1989, #2003, #2080, #2018, #2039, #2058, #2101, #2102, #2125, #2135, #2136, #2140, #2141, #2152, #2164, #2166, #2192, #2219, #2250, #2257, #2280, #2308, #2315, #2317, #2321, #2356, #2388, #2392, #2413, #2414, #2417, #2426, #2028, #2382, #2415, #2193, #2213, #2230)
- CI improvements. @yinweisu (#1965, #1966, #1972, #1991, #2002, #2029, #2137, #2151, #2156, #2163, #2191, #2214, #2369, #2113, #2118)
Experimental Features
- Support 11B-scale model finetuning with DeepSpeed. @Raldir (#2032)
- Enable few-shot learning with 11B-scale model. @Raldir (#2197)
- ONNX export example of hf_text model. @FANGAreNotGnu (#2149)
Tabular
New features
-
New experimental model
FT_TRANSFORMER. @bingzhaozhu, @innixma (#2085, #2379, #2389, #2410)- You can access it via specifying the
FT_TRANSFORMERkey in thehyperparametersdictionary or viapresets="experimental_best_quality". - It is recommended to use GPU to train this model, but CPU training is also supported.
- If given enough training time, this model generally improves the ensemble quality.
- You can access it via specifying the
-
New experimental model compilation support via
predictor.compile_models(). @liangfu, @innixma (#2225, #2260, #2300)- Currently only Random Forest and Extra Trees have compilation support.
- You will need to install extra dependencies for this to work:
pip install autogluon.tabular[all,skl2onnx]. - Compiling models dramatically speeds up inference time (~10x) when processing small batches of samples (<10000).
- Note that a known bug exists in the current implementation: Refitting models after compilation will fail
and cause a crash. To avoid this, ensure that
.compile_modelsis called only at the very end.
-
Added
predictor.clone(...)method to allow perfectly cloning a predictor object to a new directory. This is useful to preserve the state of a predictor prior to altering it (such as prior to calling.save_space,.distill,.compile_models, or.refit_full. @innixma (#2071) -
Added simplified
num_gpusandnum_cpusarguments topredictor.fitto control total resources. @yinweisu, @innixma (#2263) -
Improved stability and effectiveness of HPO functionality via various refactors regarding our usage of ray. @yinweisu, @innixma (#1974, #1990, #2094, #2121, #2133, #2195, #2253, #2263, #2330)
-
Upgraded dependency versions: XGBoost 1.7, CatBoost 1.1, Scikit-learn 1.1, Pandas 1.5, Scipy 1.9, Numpy 1.23. @innixma (#2373)
-
Added python version compatibility check when loading a fitted TabularPredictor. Will now error if python versions are incompatible. @innixma (#2054)
-
Added
fit_weighted_ensembleargument topredictor.fit. This allows the user to disable the weighted ensemble. @innixma (#2145) -
Added cascade ensemble foundation logic. @innixma (#1929)
Other Enhancements
- Improved logging clarity when using
infer_limit. @innixma (#2014) - Significantly improved HPO search space of XGBoost. @innixma (#2123)
- Fixed HPO crashing when tuning Random Forest, Extra Trees, or KNN. @innixma (#2070)
- Optimized roc_auc metric scoring speed by 7x. @innixma (#2318, #2331)
- Fixed bug with AutoMM Tabular model crashing if not trained last. @innixma (#2309)
- Refactored
Scorerclasses to be easier to use, plus added comprehensive unit tests for all metrics. @innixma (#2242) - Sped up TextSpecial feature generation during preprocessing by 20% @gidler (#2095)
- imodels integration improvements @Jalagarto (#2062)
- Fix crash when calling feature importance in quantile_regression. @leloykun (#1977)
- Add FAQ section for missing value imputation. @innixma (#2076)
- Various minor fixes and cleanup @innixma, @yinweisu, @gradientsky, @gidler (#1997, #2031, #2124, #2144, #2178, #2340, #2342, #2345, #2374, #2339, #2348, #2403, #1981, #1982, #2234, #2233, #2243, #2269, #2288, #2307, #2367, #2019)
Time Series
New features
-
TimeSeriesPredictornow supports static features (a.k.a. time series metadata, static covariates) and ** time-varying covariates** (a.k.a. dynamic features or related time series). @shchur @canerturkmen (#1986, #2238, #2276, #2287) - AutoGluon-TimeSeries now uses PyTorch by default (for
DeepARandSimpleFeedForward), removing the dependency on MXNet. @canerturkmen (#2074, #2205, #2279) - New models!
AutoGluonTabularrelies on XGBoost, LightGBM and CatBoost under the hood via theautogluon.tabularmodule.NaiveandSeasonalNaiveforecasters are simple methods that provide strong baselines with no increase in training time.TemporalFusionTransformerMXNetbrings the TFT transformer architecture to AutoGluon. @shchur (#2106, #2188, #2258, #2266) - Up to 20x faster parallel and memory-efficient training for statistical (local) forecasting models like
ETS,ARIMAandTheta, as well asWeightedEnsemble. @shchur @canerturkmen (#2001, #2033, #2040, #2067, #2072, #2073, #2180, #2293, #2305) - Up to 3x faster training for GluonTS models with data caching. GPU training enabled by default on PyTorch models. @shchur (#2323)
- More accurate validation for time series models with multi-window backtesting. @shchur (#2013, #2038)
-
TimeSeriesPredictornow handles irregularly sampled time series withignore_index. @canerturkmen, @shchur (#1993, #2322) - Improved and extended presets for more accurate forecasting. @shchur (#2304)
- 15x faster and more robust forecast evaluation with updates to
TimeSeriesEvaluator@shchur (#2147, #2150) - Enabled Ray Tune backend for hyperparameter optimization of time series models. @shchur (#2167, #2203)
More tutorials and examples
Improved documentation and new tutorials:
- Updated Quickstart tutorial
- New! In-depth tutorial
- New! Overview of available models and hyperparameters
- Updated API documentation
@shchur (#2120, #2127, #2146, #2174, #2187, #2354)
Miscellaneous
@shchur
- Deprecate passing quantile_levels to TimeSeriesPredictor.predict (#2277)
- Use static features in GluonTS forecasting models (#2238)
- Make sure that time series splitter doesn't trim training series shorter than prediction_length + 1 (#2099)
- Fix hyperparameter overloading in HPO for time series models (#2189)
- Clean up the TimeSeriesDataFrame public API (#2105)
- Fix item order in GluonTS models predictions (#2092)
- Implement hash_ts_dataframe_items (#2060)
- Speed up TimeSeriesDataFrame.slice_by_timestep (#2020)
- Speed up RandomForestQuantileRegressor and ExtraTreesQuantileRegressor (#2204)
- Various backend enhancements / refactoring / cleanup (#2314, #2294, #2292, #2278, #1985, #2398)
@canerturkmen
- Increase the number of samples used by DeepAR at prediction time (#2291)
- revise timeseries presets to minimum context length of 10 (#2065)
- Fix timeseries daily frequency inferred period (#2100)
- Various backend enhancements / refactoring / cleanup (#2286, #2302, #2240, #2093, #2098, #2044, #2385, #2355, #2405)