Apache Druid Versions Save
Apache Druid: a high performance real-time analytics database.
druid-29.0.1
1 month agoDruid 29.0.1
Apache Druid 29.0.1 is a patch release that fixes some issues in the Druid 29.0.0 release.
Bug fixes
- Added type verification for INSERT and REPLACE to validate that strings and string arrays aren't mixed #15920
- Concurrent replace now allows pending Peon segments to be upgraded using the Supervisor #15995
- Changed the
targetDataSourceattribute to return a string containing the name of the datasource. This reverts the breaking change introduced in Druid 29.0.0 for INSERT and REPLACE MSQ queries #16004 #16031 - Decreased the size of the distribution Docker image #15968
- Fixed an issue with SQL-based ingestion where string inputs, such as from CSV, TSV, or string-value fields in JSON, are ingested as null values when they are typed as LONG or BIGINT #15999
- Fixed an issue where a web console-generated Kafka supervisor spec has
flattenSpecin the wrong location #15946 - Fixed an issue with filters on expression virtual column indexes incorrectly considering values null in some cases for expressions which translate null values into not null values #15959
- Fixed an issue where the data loader crashes if the incoming data can't be parsed #15983
- Improved DOUBLE type detection in the web console #15998
- Web console-generated queries now only set the context parameter
arrayIngestModetoarraywhen you explicitly opt in to use arrays #15927 - The web console now displays the results of an MSQ query that writes to an external destination through the
EXTERNfunction #15969
Incompatible changes
Changes to targetDataSource in EXPLAIN queries
Druid 29.0.1 includes a breaking change that restores the behavior for targetDataSource to its 28.0.0 and earlier state, different from Druid 29.0.0 and only 29.0.0. In 29.0.0, targetDataSource returns a JSON object that includes the datasource name. In all other versions, targetDataSource returns a string containing the name of the datasource.
If you're upgrading from any version other than 29.0.0, there is no change in behavior.
If you are upgrading from 29.0.0, this is an incompatible change.
Dependency updates
- Updated PostgreSQL JDBC Driver version to 42.7.2 #15931
Credits
@abhishekagarwal87 @adarshsanjeev @AmatyaAvadhanula @clintropolis @cryptoe @dependabot[bot] @ektravel @gargvishesh @gianm @kgyrtkirk @LakshSingla @somu-imply @techdocsmith @vogievetsky
druid-29.0.0
2 months agodruid-28.0.1
4 months agoDescription
Apache Druid 28.0.1 is a patch release that fixes some issues in the 28.0.0 release. See the complete set of changes for additional details.
# Notable Bug fixes
- https://github.com/apache/druid/pull/15405 To make the start-druid script more robust
- https://github.com/apache/druid/pull/15402 Fixes the query caching bug for groupBy queries with multiple post-aggregation metrics
-
https://github.com/apache/druid/pull/15430 Fixes the failure of tasks during an upgrade due to the addition of new task action
RetrieveSegmentsToReplaceActionwhich would not be available on the overlord at the time of rolling upgrade - https://github.com/apache/druid/pull/15500 Bug fix with NullFilter which is commonly utilised with the newly default SQL compatible mode.
# Credits
Thanks to everyone who contributed to this release!
@cryptoe @gianm @kgyrtkirk @LakshSingla @vogievetsky
druid-28.0.0
5 months agodruid-27.0.0
9 months agoApache Druid 27.0.0 contains over 316 new features, bug fixes, performance enhancements, documentation improvements, and additional test coverage from 50 contributors.
See the complete set of changes for additional details, including bug fixes.
Review the upgrade notes and incompatible changes before you upgrade to Druid 27.0.0.
# Highlights
# New Explore view in the web console (experimental)
The Explore view is a simple, stateless, SQL backed, data exploration view to the web console. It lets users explore data in Druid with point-and-click interaction and visualizations (instead of writing SQL and looking at a table). This can provide faster time-to-value for a user new to Druid and can allow a Druid veteran to quickly chart some data that they care about.
The Explore view is accessible from the More (...) menu in the header:
# Query from deep storage (experimental)
Druid now supports querying segments that are stored only in deep storage. When you query from deep storage, you can query larger data available for queries without necessarily having to scale your Historical processes to accommodate more data. To take advantage of the potential storage savings, make sure you configure your load rules to not load all your segments onto Historical processes.
Note that at least one segment of a datasource must be loaded onto a Historical process so that the Broker can plan the query. It can be any segment though.
For more information, see the following:
# Schema auto-discovery and array column types
Type-aware schema auto-discovery is now generally available. Druid can determine the schema for the data you ingest rather than you having to manually define the schema.
As part of the type-aware schema discovery improvements, array column types are now generally available. Druid can determine the column types for your schema and assign them to these array column types when you ingest data using type-aware schema auto-discovery with the auto column type.
For more information about this feature, see the following:
- Type-aware schema discovery.
- 26.0.0 release notes for Schema auto-discovery.
- 26.0.0 release notes for array column types.
# Smart segment loading
The Coordinator is now much more stable and user-friendly. In the new smartSegmentLoading mode, it dynamically computes values for several configs which maximize performance.
The Coordinator can now prioritize load of more recent segments and segments that are completely unavailable over load of segments that already have some replicas loaded in the cluster. It can also re-evaluate decisions taken in previous runs and cancel operations that are not needed anymore. Moreoever, move operations started by segment balancing do not compete with the load of unavailable segments thus reducing the reaction time for changes in the cluster and speeding up segment assignment decisions.
Additionally, leadership changes have less impact now, and the Coordinator doesn't get stuck even if re-election happens while a Coordinator run is in progress.
Lastly, the cost balancer strategy performs much better now and is capable of moving more segments in a single Coordinator run. These improvements were made by borrowing ideas from the cachingCost strategy. We recommend using cost instead of cachingCost since cachingCost is now deprecated.
For more information, see the following:
- Upgrade note for config changes related to smart segment loading
- New coordinator metrics
- Smart segment loading documentation
# New query filters
Druid now supports the following filters:
- Equality: Use in place of the selector filter. It never matches null values.
- Null: Match null values. Use in place of the selector filter.
- Range: Filter on ranges of dimension values. Use in place of the bound filter. It never matches null values
Note that Druid's SQL planner uses these new filters in place of their older counterparts by default whenever druid.generic.useDefaultValueForNull=false or if sqlUseBoundAndSelectors is set to false on the SQL query context.
You can use these filters for filtering equality and ranges on ARRAY columns instead of only strings with the previous selector and bound filters.
For more information, see Query filters.
# Guardrail for subquery results
Users can now add a guardrail to prevent subquery’s results from exceeding the set number of bytes by setting druid.server.http.maxSubqueryRows in the Broker's config or maxSubqueryRows in the query context. This guardrail is recommended over row-based limiting.
This feature is experimental for now and defaults back to row-based limiting in case it fails to get the accurate size of the results consumed by the query.
# Added a new OSHI system monitor
Added a new OSHI system monitor (OshiSysMonitor) to replace SysMonitor. The new monitor has a wider support for different machine architectures including ARM instances. We recommend switching to the new monitor. SysMonitor is now deprecated and will be removed in future releases.
# Java 17 support
Druid now fully supports Java 17.
# Hadoop 2 deprecated
Support for Hadoop 2 is now deprecated. It will be removed in a future release.
For more information, see the upgrade notes.
# Additional features and improvements
# SQL-based ingestion
# Improved query planning behavior
Druid now fails query planning if a CLUSTERED BY column contains descending order. Previously, queries would successfully plan if any CLUSTERED BY columns contained descending order.
The MSQ fault, InsertCannotOrderByDescending, is deprecated. An INSERT or REPLACE query containing a CLUSTERED BY expression cannot be in descending order. Druid's segment generation code only supports ascending order. Instead of the fault, Druid now throws a query ValidationException.
# Improved segment sizes
The default clusterStatisticsMergeMode is now SEQUENTIAL, which provide more accurate segment sizes.
# Other SQL-based ingestion improvements
- The same aggregator can now have two output names #14367
- Enabled using functions as inputs for
indexandlengthparameters #14480 - Improved parse exceptions #14398
# Ingestion
# Ingestion improvements
- If the Overlord fails to insert a task into the metadata because of a payload that exceeds the
max_allowed_packetlimit, the response now returns400 Bad request. This prevents anindex_paralleltask from retrying the insertion of a bad sub-task indefinitely and causes it to fail immediately. #14271 - A negative streaming ingestion lag is no longer emitted as a result of stale offsets. #14292
- Removed double synchronization on simple map operations in Kubernetes task runner. #14435
- Kubernetes overlord extension now cleans up the job if the task pod fails to come up in time. #14425
# MSQ task engine querying
In addition to the new query from deep storage feature, SELECT queries using the MSQ task engine have been improved.
# Support for querying lookup and inline data directly
You can now query lookup tables directly, such as SELECT * FROM lookup.xyz, when using the MSQ task engine.
# Truncated query results
SELECT queries executed using MSQ generate only a subset of the results in the query reports. To fetch the complete result set, run the query using the native engine.
# New context parameter for query results
Added a query context parameter MultiStageQueryContext to determine whether the result of an MSQ SELECT query is limited.
# Query results directory
Druid now supports a query-results directory in durable storage to store query results after the task finishes. The auto cleaner does not remove this directory unless the task ID is not known to the Overlord.
# Querying
# New function for regular expression replacement
The new function REGEXP_REPLACE allows you to replace all instances of a pattern with a replacement string.
# HLL and Theta sketch estimates
You can now use HLL_SKETCH_ESTIMATE and THETA_SKETCH_ESTIMATE as expressions. These estimates work on sketch columns and have the same behavior as postAggs.
# EARLIEST_BY and LATEST_BY signatures
Updated EARLIEST_BY and LATEST_BY function signatures as follows:
- Changed
EARLIEST(expr, timeColumn)toEARLIEST_BY(expr, timeColumn) - Changed
LATEST(expr, timeColumn)toLATEST_BY(expr, timeColumn)
# INFORMATION_SCHEMA.ROUTINES TABLE
Use the new INFORMATION_SCHEMA.ROUTINES to programmatically get information about the functions that Druid SQL supports.
For more information, such as the available columns, see ROUTINES table.
# New Broker configuration for SQL schema migrations
You can now better control how Druid reacts to schema changes between segments. This can make querying more resilient when newer segments introduce different types, such as if a column previously contained LONG values and newer segments contain STRING.
Use the new Broker configuration, druid.sql.planner.metadataColumnTypeMergePolicy to control how column types are computed for the SQL table schema when faced with differences between segments.
Set it to one of the following:
-
leastRestrictive: the schema only updates once all segments are reindexed to the new type. -
latestInterval: the SQL schema gets updated as soon as the first job with the new schema publishes segments in the latest time interval of the data.
leastRestrictive can have better query time behavior and eliminates some query time errors that can occur when using latestInterval.
# EXPLAIN PLAN improvements
The EXPLAIN PLAN result includes a new column ATTRIBUTES that describes the attributes of a query.
For more information, see SQL translation
# Metrics and monitoring
# Monitor for Overlord and Coordinator service health
Added a new monitor ServiceStatusMonitor to monitor the service health of the Overlord and Coordinator.
# New Broker metrics
The following metrics are now available for Brokers:
| Metric | Description | Dimensions |
|---|---|---|
segment/metadatacache/refresh/count |
Number of segments to refresh in broker segment metadata cache. Emitted once per refresh per datasource. | dataSource |
segment/metadatacache/refresh/time |
Time taken to refresh segments in broker segment metadata cache. Emitted once per refresh per datasource. | dataSource |
# New Coordinator metrics
| Metric | Description | Dimensions | Normal value |
|---|---|---|---|
segment/loadQueue/assigned |
Number of segments assigned for load or drop to the load queue of a server. | dataSource,server |
Varies |
segment/loadQueue/success |
Number of segment assignments that completed successfully. | dataSource, server |
Varies |
segment/loadQueue/cancelled |
Number of segment assignments that were canceled before completion. | dataSource,server |
0 |
segment/loadQueue/failed |
Number of segment assignments that failed to complete. | dataSource, server |
0 |
# New metrics for task completion updates
| Metric | Description | Normal value |
|---|---|---|
task/status/queue/count |
Monitors the number of queued items | Varies |
task/status/updated/count |
Monitors the number of processed items | Varies |
# Added groupId to Overlord task metrics
Added groupId to task metrics emitted by the Overlord. This is helpful for grouping metrics like task/run/time by a single task group, such as a single compaction task or a single MSQ query.
# New metrics for monitoring sync status of HttpServerInventoryView
TBD for name change
| Metric | Description | Dimensions | Normal value |
|---|---|---|---|
serverview/sync/healthy |
Sync status of the Coordinator/Broker with a segment-loading server such as a Historical or Peon. Emitted by the Coordinator and Brokers only when HTTP-based server view is enabled. This metric can be used in conjunction with serverview/sync/unstableTime to debug slow startup of the Coordinator. |
server, tier |
1 for fully synced servers, 0 otherwise |
serverview/sync/unstableTime |
Time in milliseconds for which the Coordinator/Broker has been failing to sync with a segment-loading server. Emitted by the Coordinator and Brokers only when HTTP-based server view is enabled. | server, tier |
Not emitted for synced servers. |
# Cluster management
# New property for task completion updates
The new property druid.indexer.queue.taskCompleteHandlerNumThreads controls the number of threads used by the Overlord TaskQueue to handle task completion updates received from the workers.
For the related metrics, see new metrics for task completion updates.
# Enabled empty tiered replicants for load rules
Druid now allows empty tiered replicants in load rules. Use this feature along with query from deep storage to increase the amount of data you can query without needing to scale your Historical processes.
# Stabilized initialization of HttpServerInventoryView
The initialization of HttpServerInventoryView maintained by Brokers and Coordinator is now resilient to Historicals and Peons crashing. The crashed servers are marked as stopped and not waited upon during the initialization.
New metrics are available to monitor the sync status of HttpServerInventoryView with different servers.
# Web console
# Console now uses the new statements API for all MSQ interaction
The console uses the new async statements API for all sql-msq-task engine queries.
While this has relatively few impacts on the UX of the query view, you are invited to peek under the hood and check out the new network requests being sent as working examples of the new API.
You can now specify durableStorage as the result destination for SELECT queries (when durable storage is configured):
![Choose to write the results for SELECT queries to durable storage]
After running a SELECT query that wrote its results to durableStorage, download the full, unlimited result set directly from the Broker:
# Added UI around data source with zero replica segments
This release of Druid supports having datasources with segments that are not replicated on any Historicals. These datasources appear in the console like so:
# Added a dialog for viewing and setting the dynamic compaction config
There's now a dialog for managing your dynamic compaction config:
# Other web console improvements
- Replaced the Ingestion view with two views: Supervisors and Tasks. #14395
- Added a new virtual column
replication_factorto thesys.segmentstable. This returns the total number of replicants of the segment across all tiers. The column is set to -1 if the information is not available. #14403 - Added stateful filter URLs for all views. #14395
# Extensions
# Improved segment metadata for Kafka emitter extension
The Kafka emitter extension has been improved. You can now publish events related to segments and their metadata to Kafka. You can set the new properties such as in the following example:
druid.emitter.kafka.event.types=["metrics", "alerts", "segment_metadata"]
druid.emitter.kafka.segmentMetadata.topic=foo
# Contributor extensions
# Apache® Iceberg integration
You can now ingest data stored in Iceberg and query that data directly by querying from deep storage. Support for Iceberg is available through the new community extension.
For more information, see Iceberg extension.
# Dependency updates
The following dependencies have had their versions bumped:
- Apache DataSketches has been upgraded to 4.1.0. Additionally, the datasketches-memory component has been upgraded to version 2.2.0. #14430
- Hadoop has been upgraded to version 3.3.6. #14489
- Avro has been upgraded to version 1.11.1. #14440
# Developer notes
Introduced a new unified exception, DruidException, for surfacing errors. It is partially compatible with the old way of reporting error messages. Response codes remain the same, all fields that previously existed on the response will continue to exist and be populated, including errorMessage. Some error messages have changed to be more consumable by humans and some cases have the message restructured. There should be no impact to the response codes.
org.apache.druid.common.exception.DruidException is deprecated in favor of the more comprehensive org.apache.druid.error.DruidException.
org.apache.druid.metadata.EntryExistsException is deprecated and will be removed in a future release.
# Upgrade notes and incompatible changes
# Upgrade notes
# Hadoop 2 deprecated
Many of the important dependent libraries that Druid uses no longer support Hadoop 2. In order for Druid to stay current and have pathways to mitigate security vulnerabilities, the community has decided to deprecate support for Hadoop 2.x releases starting this release. Starting with Druid 28.x, Hadoop 3.x is the only supported Hadoop version.
Consider migrating to SQL-based ingestion or native ingestion if you are using Hadoop 2.x for ingestion today. If migrating to Druid ingestion is not possible, plan to upgrade your Hadoop infrastructure before upgrading to the next Druid release.
Please note that druid 27 is not compatible with Hadoop 2. You have to upgrade your Hadoop cluster to 3.x before upgrading to 27.0.0. Or you can build a hadoop 2 compatible distribution by explicitly selecting Hadoop 2 profile from druid 27 source artifact.
# Worker input bytes for SQL-based ingestion
The maximum input bytes for each worker for SQL-based ingestion is now 512 MiB (previously 10 GiB).
# Parameter execution changes for Kafka
When using the built-in FileConfigProvider for Kafka, interpolations are now intercepted by the JsonConfigurator instead of being passed down to the Kafka provider. This breaks existing deployments.
For more information, see KIP-297.
# GroupBy v1 deprecated
GroupBy queries using the v1 legacy engine has been deprecated. It will be removed in future releases. Use v2 instead. Note that v2 has been the default GroupBy engine.
For more information, see GroupBy queries.
# Push-based real-time ingestion deprecated
Support for push-based real-time ingestion has been deprecated. It will be removed in future releases.
# cachingCost segment balancing strategy deprecated
The cachingCost strategy has been deprecated and will be removed in future releases. Use an alternate segment balancing strategy instead, such as cost.
# Segment loading config changes
The following segment related configs are now deprecated and will be removed in future releases:
-
maxSegmentsInNodeLoadingQueue -
maxSegmentsToMove -
replicationThrottleLimit -
useRoundRobinSegmentAssignment -
replicantLifetime -
maxNonPrimaryReplicantsToLoad -
decommissioningMaxPercentOfMaxSegmentsToMove
Use smartSegmentLoading mode instead, which calculates values for these variables automatically.
Additionally, the defaults for the following Coordinator dynamic configs have changed:
-
maxsegmentsInNodeLoadingQueue: 500, previously 100 -
maxSegmentsToMove: 100, previously 5 -
replicationThrottleLimit: 500, previously 10
These new defaults can improve performance for most use cases.
# SysMonitor support deprecated
Switch to OshiSysMonitor as SysMonitor is now deprecated and will be removed in future releases.
# Incompatible changes
# Removed property for setting max bytes for dimension lookup cache
druid.processing.columnCache.sizeBytes has been removed since it provided limited utility after a number of internal changes. Leaving this config is harmless, but it does nothing.
# Removed Coordinator dynamic configs
The following Coordinator dynamic configs have been removed:
-
emitBalancingStats: Stats for errors encountered while balancing will always be emitted. Other debugging stats will not be emitted but can be logged by setting the appropriatedebugDimensions. -
useBatchedSegmentSamplerandpercentOfSegmentsToConsiderPerMove: Batched segment sampling is now the standard and will always be on.
Use the new smart segment loading mode instead.
# Credits
Thanks to everyone who contributed to this release! @317brian @a2l007 @abhishek-chouhan @abhishekagarwal87 @abhishekrb19 @adarshsanjeev @AlexanderSaydakov @amaechler @AmatyaAvadhanula @asdf2014 @churromorales @clintropolis @cryptoe @demo-kratia @ektravel @findingrish @georgew5656 @gianm @hardikbajaj @harinirajendran @imply-cheddar @jakubmatyszewski @janjwerner-confluent @jgoz @jon-wei @kfaraz @knorth55 @LakshSingla @maytasm @nlippis @panhongan @paul-rogers @petermarshallio @pjain1 @PramodSSImmaneni @pranavbhole @robo220 @rohangarg @sergioferragut @skytin1004 @somu-imply @suneet-s @techdocsmith @tejaswini-imply @TSFenwick @vogievetsky @vtlim @writer-jill @YongGang @zachjsh
druid-26.0.0
11 months agoApache Druid 26.0.0 contains over 390 new features, bug fixes, performance enhancements, documentation improvements, and additional test coverage from 65 contributors.
See the complete set of changes for additional details.
Review the upgrade notes and incompatible changes before you upgrade to Druid 26.0.0.
# Highlights
# Auto type column schema (experimental)
A new "auto" type column schema and indexer has been added to native ingestion as the next logical iteration of the nested column functionality. This automatic type column indexer that produces the most appropriate column for the given inputs, producing either STRING, ARRAY<STRING>, LONG, ARRAY<LONG>, DOUBLE, ARRAY<DOUBLE>, or COMPLEX<json> columns, all sharing a common 'nested' format.
All columns produced by 'auto' have indexes to aid in fast filtering (unlike classic LONG and DOUBLE columns) and use cardinality based thresholds to attempt to only utilize these indexes when it is likely to actually speed up the query (unlike classic STRING columns).
COMPLEX<json> columns produced by this 'auto' indexer store arrays of simple scalar types differently than their 'json' (v4) counterparts, storing them as ARRAY typed columns. This means that the JSON_VALUE function can now extract entire arrays, for example JSON_VALUE(nested, '$.array' RETURNING BIGINT ARRAY). There is no change with how arrays of complex objects are stored at this time.
This improvement also adds a completely new functionality to Druid, ARRAY typed columns, which unlike classic multi-value STRING columns behave with ARRAY semantics. These columns can currently only be created via the 'auto' type indexer when all values are an arrays with the same type of elements.
An array data type is a data type that allows you to store multiple values in a single column of a database table. Arrays are typically used to store sets of related data that can be easily accessed and manipulated as a group.
This release adds support for storing arrays of primitive values such as ARRAY<STRING>, ARRAY<LONG>, and ARRAY<DOUBLE> as specialized nested columns instead of breaking them into separate element columns.
These changes affect two additional new features available in 26.0: schema auto-discovery and unnest.
# Schema auto-discovery (experimental)
We’re adding schema-auto discovery with type inference to Druid. With this feature, the data type of each incoming field is detected when schema is available. For incoming data which may contain added, dropped, or changed fields, you can choose to reject the nonconforming data (“the database is always correct - rejecting bad data!”), or you can let schema auto-discovery alter the datasource to match the incoming data (“the data is always right - change the database!”).
Schema auto-discovery is recommend for new use-cases and ingestions. For existing use-cases be careful switching to schema auto-discovery because Druid will ingest array-like values (e.g. ["tag1", "tag2]) as ARRAY<STRING> type columns instead of multi-value (MV) strings, this could cause issues in downstream apps replying on MV behavior. Hold off switching until an official migration path is available.
To use this feature, set spec.dataSchema.dimensionsSpec.useSchemaDiscovery to true in your task or supervisor spec or, if using the data loader in the console, uncheck the Explicitly define schema toggle on the Configure schema step. Druid can infer the entire schema or some of it if you explicitly list dimensions in your dimensions list.
Schema auto-discovery is available for native batch and streaming ingestion.
# UNNEST arrays (experimental)
Part of what’s cool about UNNEST is how it allows a wider range of operations that weren’t possible on Array data types. You can unnest arrays with either the UNNEST function (SQL) or the unnest datasource (native).
Unnest converts nested arrays or tables into individual rows. The UNNEST function is particularly useful when working with complex data types that contain nested arrays, such as JSON.
For example, suppose you have a table called "orders" with a column called "items" that contains an array of products for each order. You can use unnest to extract the individual products ("each_item") like in the following SQL example:
SELECT order_id, each_item FROM orders, UNNEST(items) as unnested(each_item)
This produces a result set with one row for each item in each order, with columns for the order ID and the individual item
Note the comma after the left table/datasource (orders in the example). It is required.
#13268 #13943 #13934 #13922 #13892 #13576 #13554 #13085
# Sort-merge join and hash shuffle join for MSQ
We can now perform shuffle joins by setting by setting the context parameter sqlJoinAlgorithm to sortMerge for the sort-merge algorithm or omitting it to perform broadcast joins (default).
Multi-stage queries can use a sort-merge join algorithm. With this algorithm, each pairwise join is planned into its own stage with two inputs. This approach is generally less performant but more scalable, than broadcast.
Set the context parameter sqlJoinAlgorithm to sortMerge to use this method.
Broadcast hash joins are similar to how native join queries are executed.
# Storage improvements on dictionary compression
Switching to using frontcoding dictionary compression (experimental) can save up to 30% with little to no impact to query performance.
This release further improves the frontCoded type of stringEncodingStrategy on indexSpec with a new segment format version, which typically has faster read speeds and reduced segment size. This improvement is backwards incompatible with Druid 25.0. Added a new formatVersion option, which defaults to the the current version 0. Set formatVersion to 1 to start using the new version.
Additionally, overall storage size, particularly with using larger buckets, has been improved.
# Additional features and improvements
# MSQ task engine
# Array-valued parameters for SQL queries
Added support for array-valued parameters for SQL queries using. You can now reuse the same SQL for every ingestion, only passing in a different set of input files as query parameters.
# EXTEND clause for the EXTERN functions
You can now use an EXTEND clause to provide a list of column definitions for your source data in standard SQL format.
The web console now defaults to using the EXTEND clause syntax for all queries auto-generated in the web console. This means that SQL-based ingestion statements generated by the web console in Druid 26 (such as from the SQL based data loader) will not work in earlier versions of Druid.
# MSQ fault tolerance
Added the ability for MSQ controller task to retry worker task in case of failures. To enable, pass faultTolerance:true in the query context.
-
Connections to S3 for fault tolerance and durable shuffle storage are now more resilient. #13741
-
Improved S3 connector #13960
- Added retries and max fetch size.
- Implemented S3utils for interacting with APIs.
# Use tombstones when running REPLACE operations
REPLACE for SQL-based ingestion now generates tombstones instead of marking segments as unused.
If you downgrade Druid, you can only downgrade to a version that also supports tombstones.
# Better ingestion splits
The MSQ task engine now considers file size when determining splits. Previously, file size was ignored; all files were treated as equal weight when determining splits.
Also applies to native batch.
# Enabled composed storage for Supersorter intermediate data
Druid now supports composable storage for intermediate data. This allows the data to be stored on multiple storage systems through local disk and durable storage. Behavior is enabled when the runtime config druid.indexer.task.tmpStorageBytesPerTask is set and the query context parameter durableShuffleStorage is set to true.
# Other MSQ improvements
- Added a check to prevent the collector from downsampling the same bucket indefinitely. #13663
- Druid now supports composable storage for SuperSorter intermediate data. This allows the data to be stored on multiple storage systems through fallbacks. #13368
- When MSQ throws a
NOT_ENOUGH_MEMORY_FAULTerror, the error message now suggests a JVMXmxsetting to provide. #13846 - Add a new fault "QueryRuntimeError" to MSQ engine to capture native query errors. #13926
-
maxResultsSizehas been removed from the S3OutputConfig and a defaultchunkSizeof 100MiB is now present. This change primarily affects users who wish to use durable storage for MSQ jobs.
# Ingestion
# Indexing on multiple disks
You can now use multiple disks for indexing tasks. In the runtime properties for the MiddleManager/Indexer, use the following property to set the disks and directories:
-
druid.worker.baseTaskDirs=[\"PATH1\",\"PATH2\",...]
# Improved default fetch settings for Kinesis
Updated the following fetch settings for the Kinesis indexing service:
-
fetchThreads: Twice the number of processors available to the task. -
fetchDelayMillis: 0 (no delay between fetches). -
recordsPerFetch: 100 MB or an estimated 5% of available heap, whichever is smaller, divided byfetchThreads. -
recordBufferSize: 100 MB or an estimated 10% of available heap, whichever is smaller. -
maxRecordsPerPoll: 100 for regular records, 1 for aggregated records.
# Added fields in the sampler API response
The response from /druid/indexer/v1/sampler now includes the following:
-
logicalDimension: list of the most restrictive typed dimension schemas -
physicalDimension: list of dimension schemas actually used to sample the data -
logicalSegmentSchema: full resulting segment schema for the set of rows sampled
# Multi-dimensional range partitioning for Hadoop-based ingestion
Hadoop-based ingestion now supports multi-dimensional range partitioning. #13303
# Other ingestion improvements
- Improved performance when ingesting JSON data. #13545
- Added
contextmap toHadoopIngestionSpec. You can set thecontextmap directly inHadoopIngestionSpecusing the command line (non-task) version or in thecontextmap forHadoopIndexTaskwhich is then automatically added toHadoopIngestionSpec. #13624
# Querying
Many of the querying improvements for Druid 26.0 are discussed in the highlights section. This section describes additional improvements to querying in Druid.
# New post aggregators for Tuple sketches
You can now do the following operations with Tuple sketches using post aggregators:
- Get the sketch output as Base64 String.
- Provide a constant Tuple sketch in a post aggregation step that can be used in set operations.
- Estimate the sum of summary/metrics objects associated with Tuple sketches.
# Support for SQL functions on Tuple sketches
Added SQL functions for creating and operating on Tuple sketches.
# Improved nested column performance
Improve nested column performance by adding cardinality based thresholds for range and predicate indexes to choose to skip using bitmap indexes. #13977
# Improved logs for query errors
Logs for query errors now include more information about the exception that occurred, such as error code and class.
# Improve performance of SQL operators NVL and COALESCE
SQL operators NVL and COALESCE with 2 arguments now plan to a native NVL expression, which supports the vector engine. Multi-argument COALESCE still plans into a case_searched, which is not vectorized.
# Improved performance for composite key joins
Composite key joins are now faster.
# Other querying improvements
- Improved exception logging of queries during planning. Previously, a class of
QueryExceptionwould throw away the causes making it hard to determine what failed in the SQL planner. #13609
- Added function equivalent to Math.pow to support square, cube, square root. #13704
- Enabled merge-style operations that combine multiple streams. This means that query operators are now pausable. #13694
- Various improvements to improve query performance and logic. #13902
# Metrics
# New server view metrics
The following metrics are now available for Brokers:
| Metrics | Description | Normal value |
|---|---|---|
init/serverview/time |
Time taken to initialize the broker server view. Useful to detect if brokers are taking too long to start. | Depends on the number of segments. |
init/metadatacache/time |
Time taken to initialize the broker segment metadata cache. Useful to detect if brokers are taking too long to start | Depends on the number of segments. |
The following metric is now available for Coordinators:
| Metrics | Description | Normal value |
|---|---|---|
init/serverview/time |
Time taken to initialize the coordinator server view. | Depends on the number of segments |
# Additional metadata for native ingestion metrics
You can now add additional metadata to the ingestion metrics emitted from the Druid cluster. Users can pass a map of metadata in the ingestion spec context parameters. These get added to the ingestion metrics. You can then tag these metrics with other metadata besides the existing tags like taskId. For more information, see General native ingestion metrics.
# Peon monitor override when using MiddleManager-less ingestion
You can now override druid.monitoring.monitors if you don't want to inherit monitors from the Overlord. Use the following property: druid.indexer.runner.peonMonitors.
# Cluster management
# Enabled round-robin segment assignment and batch segment allocation by default
Round-robin segment assignment greatly speeds up Coordinator run times and is hugely beneficial to all clusters. Batch segment allocation works extremely well when you have multiple concurrent real-time tasks for a single supervisor.
# Improved client change counter in HTTP Server View
The client change counter is now more efficient and resets in fewer situations.
# Enabled configuration of ZooKeeper connection retries
You can now override the default ZooKeeper connection retry count. In situations where the underlying k8s node loses network connectivity or is no longer able to talk to ZooKeeper, configuring a fast fail can trigger pod restarts which can then reassign the pod to a healthy k8s node.
# Improve memory usage on Historicals
Reduced segment heap footprint.
# MiddleManager-less extension
# Better sidecar support
The following property has been added to improve support for sidecars:
-
druid.indexer.runner.primaryContainerName=OVERLORD_CONTAINER_NAME: Set this to the name of your Druid container, such asdruid-overlord. The default setting is the first container in thepodSpeclist.
Use this property when Druid is not the first container, such as when you're using Istio and the istio-proxy sidecar gets injected as the first container.
# Other improvements for MiddleManager-less extension
- The
druid-kubernetes-overlord-extensionscan now be loaded in any Druid service. #13872 - You can now add files to the common configuration directory when deploying on Kubernetes. #13795
- You can now specify a Kubernetes pod spec per task type. #13896
- You can now override
druid.monitoring.monitors. If you don't want to inherit monitors from the Overlord, you can override the monitors with the following config:druid.indexer.runner.peonMonitors.#14028 - Added live reports for
KubernetesTaskRunner. #13986
# Compaction
# Added a new API for compaction configuration history
Added API endpoint CoordinatorCompactionConfigsResource#getCompactionConfigHistory to return the history of changes to automatic compaction configuration history. If the datasource does not exist or it has no compaction history, an empty list is returned
# Security
# Support for the HTTP Strict-Transport-Security response header
Added support for the HTTP Strict-Transport-Security response header.
Druid does not include this header by default. You must enable it in runtime properties by setting druid.server.http.enableHSTS to true.
# Add JWT authenticator support for validating ID Tokens #13242
Expands the OIDC based auth in Druid by adding a JWT Authenticator that validates ID Tokens associated with a request. The existing pac4j authenticator works for authenticating web users while accessing the console, whereas this authenticator is for validating Druid API requests made by Direct clients. Services already supporting OIDC can attach their ID tokens to the Druid requests under the Authorization request header.
# Allow custom scope when using pac4j
Updated OpenID Connect extension configuration with scope information.
Applications use druid.auth.pac4j.oidc.scope during authentication to authorize access to a user's details.
# Web console
# Kafka metadata is included by default when loading Kafka streams with the data loader
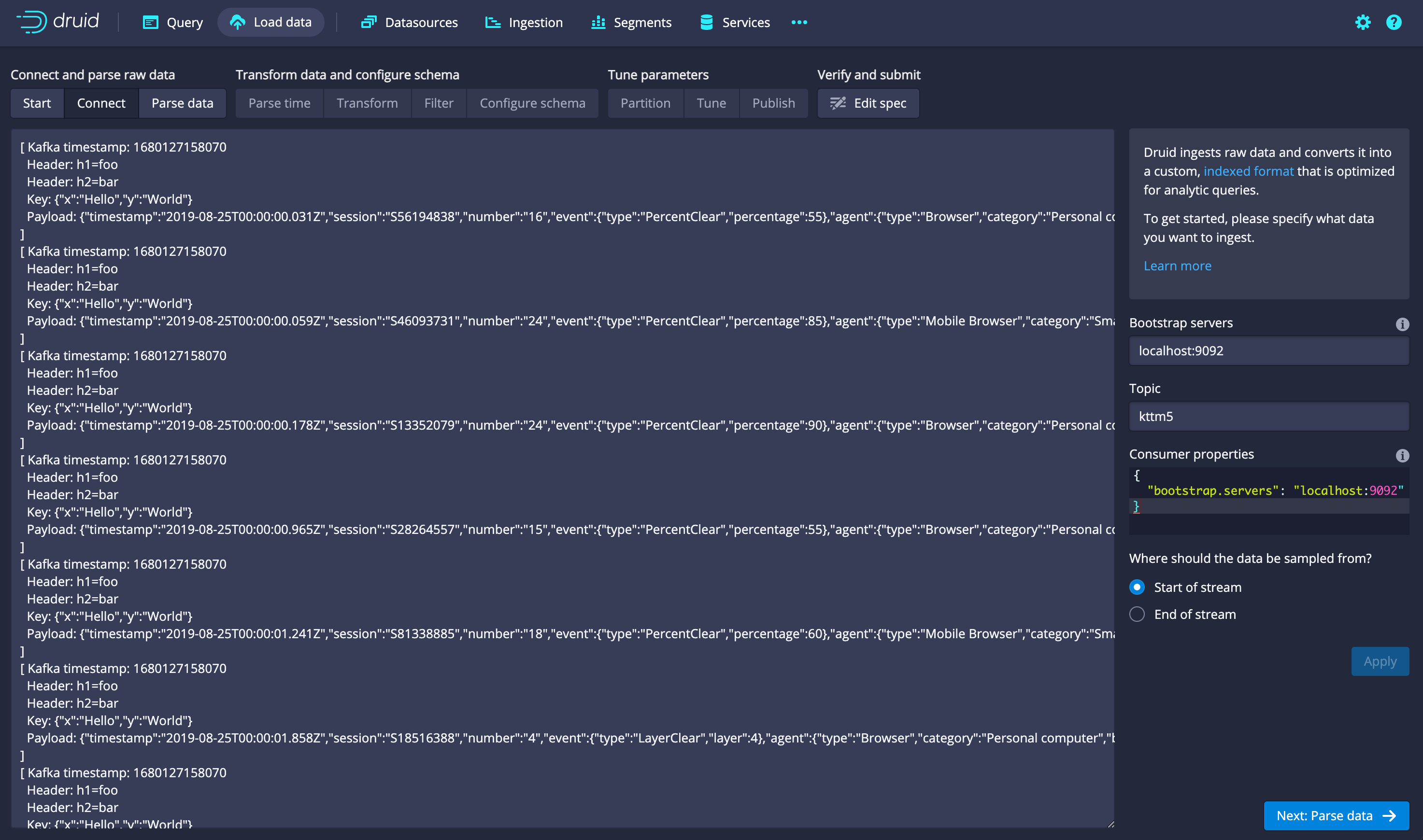
The streaming data loader in the console added support for the Kafka input format, which gives you access to the Kafka metadata fields like the key and the Kafka timestamp. This is used by default when you choose a Kafka stream as the data source.

# Overlord dynamic config
Added a form with JSON fallback to the Overlord dynamic config dialog.
https://github.com/apache/druid/pull/13993

# Other web console improvements:
- Added view to see compaction history. #13861
- Added segment writing progress indicator. #13929
- Added icons for SQL
NULLdatatype. https://github.com/apache/druid/pull/13786 - Improved error reporting. https://github.com/apache/druid/pull/13636
- Improved the look of Group by totals in the Services view. https://github.com/apache/druid/pull/13631
- Improved the autocompletion when typing queries. https://github.com/apache/druid/pull/13830
- Improved cell rendering to show
"". https://github.com/apache/druid/pull/13786 - Changed views to only be enabled if they work. https://github.com/apache/druid/pull/13786
# Docs
# SQL tutorial using Jupyter notebook
Added a new tutorial to our collection of Jupyter Notebook-based Druid tutorials. This interactive tutorial introduces you to the unique aspects of Druid SQL with the primary focus on the SELECT statement. For more information, see Learn the basics of Druid SQL.
# Python Druid API
Added a Python API for use in Jupyter notebooks.
# Updated Docker Compose
This release includes several improvements to the docker-compose.yml file that Druid tutorials reference:
- Added configuration to bind Postgres instance on the default port ("5432") to the
docker-compose.ymlfile. - Updated Broker, Historical, MiddleManager, and Router instances to use Druid 24.0.1 on the
docker-compose.ymlfile. - Removed trailing space on the
docker-compose.ymlfile.
# Bug fixes
Druid 26.0.0 contains 80 bug fixes, the complete list is available here.
# Dependency updates
The following dependencies have had their versions bumped:
- Apache Kafka to version 3.4.0 #13802
- Apache Zookeeper to version 3.5.10 #13715
- Joda-Time to version 2.12.4 #13999
- Kubernetes Java Client to 6.4.1 #14028
The full list is available here.
# Upgrade notes and incompatible changes
# Upgrade notes
# Real-time tasks
Optimized query performance by lowering the default maxRowsInMemory for real-time ingestion, which might lower overall ingestion throughput #13939
# Incompatible changes
# Firehose ingestion removed
The firehose/parser specification used by legacy Druid streaming formats is removed. Firehose ingestion was deprecated in version 0.17, and support for this ingestion was removed in version 24.0.
# Information schema now uses numeric column types
The Druid system table (INFORMATION_SCHEMA) now uses SQL types instead of Druid types for columns. This change makes the INFORMATION_SCHEMA table behave more like standard SQL. You may need to update your queries in the following scenarios in order to avoid unexpected results if you depend either of the following:
- Numeric fields being treated as strings.
- Column numbering starting at 0. Column numbering is now 1-based.
# frontCoded segment format change
The frontCoded type of stringEncodingStrategy on indexSpec with a new segment format version, which typically has faster read speeds and reduced segment size. This improvement is backwards incompatible with Druid 25.0.
For more information, see the frontCoded string encoding strategy highlight.
# Developer notes
# Null value coercion moved out of expression processing engine
Null values input to and created by the Druid native expression processing engine no longer coerce null to the type appropriate 'default' value if druid.generic.useDefaultValueForNull=true. This should not impact existing behavior since this has been shifted onto the consumer and internally operators will still use default values in this mode. However, there may be subtle behavior changes around the handling of null values. Direct callers can get default values by using the new valueOrDefault() method of ExprEval, instead of value().
# Simplified dependencies
druid-core, extendedset, and druid-hll modules have been consolidated into druid-processing to simplify dependencies. Any extensions referencing these should be updated to use druid-processing instead. Existing extension binaries should continue to function normally when used with newer versions of Druid.
This change does not impact end users. It does impact anyone who develops extensions for Druid.
# Credits
Thanks to everyone who contributed to this release!
@317brian @a2l007 @abhagraw @abhishekagarwal87 @abhishekrb19 @adarshsanjeev @AdheipSingh @amaechler @AmatyaAvadhanula @anshu-makkar @ApoorvGuptaAi @asdf2014 @benkrug @capistrant @churromorales @clintropolis @cryptoe @dependabot[bot] @dongjoon-hyun @drudi-at-coffee @ektravel @EylonLevy @findingrish @frankgrimes97 @g1y @georgew5656 @gianm @hqx871 @imply-cheddar @imply-elliott @isandeep41 @jaegwonseo @jasonk000 @jgoz @jwitko @kaijianding @kfaraz @LakshSingla @maytasm @nlippis @p- @paul-rogers @pen4 @raboof @rohangarg @sairamdevarashetty @sergioferragut @somu-imply @soullkk @suneet-s @SurajKadam7 @techdocsmith @tejasparbat @tejaswini-imply @tijoparacka @TSFenwick @varachit @vogievetsky @vtlim @winminsoe @writer-jill @xvrl @yurmix @zachjsh @zemin-piao
druid-25.0.0
1 year agoApache Druid 25.0.0 contains over 300 new features, bug fixes, performance enhancements, documentation improvements, and additional test coverage from 51 contributors.
See the complete set of changes for additional details.
# Highlights
# MSQ task engine now production ready
The multi-stage query (MSQ) task engine used for SQL-based ingestion is now production ready. Use it for any supported workloads. For more information, see the following pages:
# Simplified Druid deployments
The new start-druid script greatly simplifies deploying any combination of Druid services on a single-server. It comes pre-packaged with the required configs and can be used to launch a fully functional Druid cluster simply by invoking ./start-druid. For experienced Druids, it also gives complete control over the runtime properties and JVM arguments to have a cluster that exactly fits your needs.
The start-druid script deprecates the existing profiles such as start-micro-quickstart and start-nano-quickstart. These profiles may be removed in future releases. For more information, see Single server deployment.
# String dictionary compression (experimental)
Added support for front coded string dictionaries for smaller string columns, leading to reduced segment sizes with only minor performance penalties for most Druid queries.
This can be enabled by setting IndexSpec.stringDictionaryEncoding to {"type":"frontCoded", "bucketSize": 4} , where bucketSize is any power of 2 less than or equal to 128. Setting this property instructs indexing tasks to write segments using compressed dictionaries of the specified bucket size.
Any segment written using string dictionary compression is not readable by older versions of Druid.
For more information, see Front coding.
https://github.com/apache/druid/pull/12277
# Kubernetes-native tasks
Druid can now use Kubernetes to launch and manage tasks, eliminating the need for middle managers.
To use this feature, enable the druid-kubernetes-overlord-extensions in the extensions load list for your Overlord process.
https://github.com/apache/druid/pull/13156
# Hadoop-3 compatible binary
Druid now comes packaged as a dedicated binary for Hadoop-3 users, which contains Hadoop-3 compatible jars. If you do not use Hadoop-3 with your Druid cluster, you may continue using the classic binary.
# Multi-stage query (MSQ) task engine
# MSQ enabled for Docker
MSQ task query engine is now enabled for Docker by default.
https://github.com/apache/druid/pull/13069
# Query history
Multi-stage queries no longer show up in the Query history dialog. They are still available in the Recent query tasks panel.
# Limit on CLUSTERED BY columns
When using the MSQ task engine to ingest data, the number of columns that can be passed in the CLUSTERED BY clause is now limited to 1500.
https://github.com/apache/druid/pull/13352
# Support for string dictionary compression
The MSQ task engine supports the front-coding of String dictionaries for better compression. This can be enabled for INSERT or REPLACE statements by setting indexSpec to a valid json string in the query context.
https://github.com/apache/druid/pull/13275
# Sketch merging mode
Workers can now gather key statistics, used to generate partition boundaries, either sequentially or in parallel. Set clusterStatisticsMergeMode to PARALLEL, SEQUENTIAL or AUTO in the query context to use the corresponding sketch merging mode. For more information, see Sketch merging mode.
https://github.com/apache/druid/pull/13205
# Performance and operational improvements
- Error messages: For disallowed MSQ warnings of certain types, the warning is now surfaced as the error. https://github.com/apache/druid/pull/13198
- Secrets: For tasks containing SQL with sensitive keys, Druid now masks the keys while logging with the help regular expressions. https://github.com/apache/druid/pull/13231
- Downsampling accuracy: MSQ task engine now uses the number of bytes instead of number of keys when downsampling data. https://github.com/apache/druid/pull/12998
- Memory usage: When determining partition boundaries, the heap footprint of internal sketches used by MSQ is now capped at 10% of available memory or 300 MB, whichever is lower. Previously, the cap was strictly 300 MB. https://github.com/apache/druid/pull/13274
-
Task reports: Added fields
pendingTasksandrunningTasksto the worker report. See Query task status information for related web console changes. https://github.com/apache/druid/pull/13263
# Querying
# Async reads for JDBC
Prevented JDBC timeouts on long queries by returning empty batches when a batch fetch takes too long. Uses an async model to run the result fetch concurrently with JDBC requests.
https://github.com/apache/druid/pull/13196
# Improved algorithm to check values of an IN filter
To accommodate large value sets arising from large IN filters or from joins pushed down as IN filters, Druid now uses a sorted merge algorithm for merging the set and dictionary for larger values.
https://github.com/apache/druid/pull/13133
# Enhanced query context security
Added the following configuration properties that refine the query context security model controlled by druid.auth.authorizeQueryContextParams:
-
druid.auth.unsecuredContextKeys: A JSON list of query context keys that do not require a security check. -
druid.auth.securedContextKeys: A JSON list of query context keys that do require a security check.
If both are set, unsecuredContextKeys acts as exceptions to securedContextKeys.
https://github.com/apache/druid/pull/13071
# HTTP response headers
The HTTP response for a SQL query now correctly sets response headers, same as a native query.
https://github.com/apache/druid/pull/13052
# Metrics
# New metrics
The following metrics have been newly added. For more details, see the complete list of Druid metrics.
# Batched segment allocation
These metrics pertain to batched segment allocation.
| Metric | Description | Dimensions |
|---|---|---|
task/action/batch/runTime |
Milliseconds taken to execute a batch of task actions. Currently only being emitted for batched segmentAllocate actions |
dataSource, taskActionType=segmentAllocate |
task/action/batch/queueTime |
Milliseconds spent by a batch of task actions in queue. Currently only being emitted for batched segmentAllocate actions |
dataSource, taskActionType=segmentAllocate |
task/action/batch/size |
Number of task actions in a batch that was executed during the emission period. Currently only being emitted for batched segmentAllocate actions |
dataSource, taskActionType=segmentAllocate |
task/action/batch/attempts |
Number of execution attempts for a single batch of task actions. Currently only being emitted for batched segmentAllocate actions |
dataSource, taskActionType=segmentAllocate |
task/action/success/count |
Number of task actions that were executed successfully during the emission period. Currently only being emitted for batched segmentAllocate actions |
dataSource, taskId, taskType, taskActionType=segmentAllocate |
task/action/failed/count |
Number of task actions that failed during the emission period. Currently only being emitted for batched segmentAllocate actions |
dataSource, taskId, taskType, taskActionType=segmentAllocate |
# Streaming ingestion
| Metric | Description | Dimensions |
|---|---|---|
ingest/kafka/partitionLag |
Partition-wise lag between the offsets consumed by the Kafka indexing tasks and latest offsets in Kafka brokers. Minimum emission period for this metric is a minute. | dataSource, stream, partition |
ingest/kinesis/partitionLag/time |
Partition-wise lag time in milliseconds between the current message sequence number consumed by the Kinesis indexing tasks and latest sequence number in Kinesis. Minimum emission period for this metric is a minute. | dataSource, stream, partition |
ingest/pause/time |
Milliseconds spent by a task in a paused state without ingesting. | dataSource, taskId, taskType |
ingest/handoff/time |
Total time taken in milliseconds for handing off a given set of published segments. | dataSource, taskId, taskType |
https://github.com/apache/druid/pull/13238 https://github.com/apache/druid/pull/13331 https://github.com/apache/druid/pull/13313
# Other improvements
- New dimension
taskActionTypewhich may take values such assegmentAllocate,segmentTransactionalInsert, etc. This dimension is reported fortask/action/run/timeand the new batched segment allocation metrics. https://github.com/apache/druid/pull/13333 - Metric
namespace/cache/heapSizeInBytesfor global cached lookups now accounts for theStringobject overhead of 40 bytes. https://github.com/apache/druid/pull/13219 -
jvm/gc/cpuhas been fixed to report nanoseconds instead of milliseconds. https://github.com/apache/druid/pull/13383
# Nested columns
# Nested columns performance improvement
Improved NestedDataColumnSerializer to no longer explicitly write null values to the field writers for the missing values of every row. Instead, passing the row counter is moved to the field writers so that they can backfill null values in bulk.
https://github.com/apache/druid/pull/13101
# Support for more formats
Druid nested columns and the associated JSON transform functions now support Avro, ORC, and Parquet.
https://github.com/apache/druid/pull/13325 https://github.com/apache/druid/pull/13375
# Refactored a datasource before unnest
When data requires "flattening" during processing, the operator now takes in an array and then flattens the array into N (N=number of elements in the array) rows where each row has one of the values from the array.
https://github.com/apache/druid/pull/13085
# Ingestion
# Improved filtering for cloud objects
You can now stop at arbitrary subfolders using glob syntax in the ioConfig.inputSource.filter field for native batch ingestion from cloud storage, such as S3.
https://github.com/apache/druid/pull/13027
# Async task client for streaming ingestion
You can now enable asynchronous communication between the stream supervisor and indexing tasks by setting chatAsync to true in the tuningConfig. The async task client uses its own internal thread pool and thus ignrores the chatThreads property.
https://github.com/apache/druid/pull/13354
# Improved handling of JSON data with streaming ingestion
You can now better control how Druid reads JSON data for streaming ingestion by setting the following fields in the input format specification:
-
assumedNewlineDelimitedto parse lines of JSON independently. -
useJsonNodeReaderto retain valid JSON events when parsing multi-line JSON events when a parsing exception occurs.
The web console has been updated to include these options.
https://github.com/apache/druid/pull/13089
# Ingesting from an idle Kafka stream
When a Kafka stream becomes inactive, the supervisor ingesting from it can be configured to stop creating new indexing tasks. The supervisor automatically resumes creation of new indexing tasks once the stream becomes active again. Set the property dataSchema.ioConfig.idleConfig.enabled to true in the respective supervisor spec or set druid.supervisor.idleConfig.enabled on the overlord to enable this behaviour. Please see the following for details:
https://github.com/apache/druid/pull/13144
# Kafka Consumer improvement
You can now configure the Kafka Consumer's custom deserializer after its instantiation.
https://github.com/apache/druid/pull/13097
# Kafka supervisor logging
Kafka supervisor logs are now less noisy. The supervisors now log events at the DEBUG level instead of INFO.
https://github.com/apache/druid/pull/13392
# Fixed Overlord leader election
Fixed a problem where Overlord leader election failed due to lock reacquisition issues. Druid now fails these tasks and clears all locks so that the Overlord leader election isn't blocked.
https://github.com/apache/druid/pull/13172
# Support for inline protobuf descriptor
Added a new inline type protoBytesDecoder that allows a user to pass inline the contents of a Protobuf descriptor file, encoded as a Base64 string.
https://github.com/apache/druid/pull/13192
# Duplicate notices
For streaming ingestion, notices that are the same as one already in queue won't be enqueued. This will help reduce notice queue size.
https://github.com/apache/druid/pull/13334
# Sampling from stream input now respects the configured timeout
Fixed a problem where sampling from a stream input, such as Kafka or Kinesis, failed to respect the configured timeout when the stream had no records available. You can now set the maximum amount of time in which the entry iterator will return results.
https://github.com/apache/druid/pull/13296
# Streaming tasks resume on Overlord switch
Fixed a problem where streaming ingestion tasks continued to run until their duration elapsed after the Overlord leader had issued a pause to the tasks. Now, when the Overlord switch occurs right after it has issued a pause to the task, the task remains in a paused state even after the Overlord re-election.
https://github.com/apache/druid/pull/13223
# Fixed Parquet list conversion
Fixed an issue with Parquet list conversion, where lists of complex objects could unexpectedly be wrapped in an extra object, appearing as [{"element":<actual_list_element>},{"element":<another_one>}...] instead of the direct list. This changes the behavior of the parquet reader for lists of structured objects to be consistent with other parquet logical list conversions. The data is now fetched directly, more closely matching its expected structure.
https://github.com/apache/druid/pull/13294
# Introduced a tree type to flattenSpec
Introduced a tree type to flattenSpec. In the event that a simple hierarchical lookup is required, the tree type allows for faster JSON parsing than jq and path parsing types.
https://github.com/apache/druid/pull/12177
# Operations
# Compaction
Compaction behavior has changed to improve the amount of time it takes and disk space it takes:
- When segments need to be fetched, download them one at a time and delete them when Druid is done with them. This still takes time but minimizes the required disk space.
- Don't fetch segments on the main compact task when they aren't needed. If the user provides a full
granularitySpec,dimensionsSpec, andmetricsSpec, Druid skips fetching segments.
For more information, see the documentation on Compaction and Automatic compaction.
https://github.com/apache/druid/pull/13280
# Idle configs for the Supervisor
You can now set the Supervisor to idle, which is useful in cases where freeing up slots so that autoscaling can be more effective.
To configure the idle behavior, use the following properties:
| Property | Description | Default |
|---|---|---|
druid.supervisor.idleConfig.enabled |
(Cluster wide) If true, supervisor can become idle if there is no data on input stream/topic for some time. |
false |
druid.supervisor.idleConfig.inactiveAfterMillis |
(Cluster wide) Supervisor is marked as idle if all existing data has been read from input topic and no new data has been published for inactiveAfterMillis milliseconds. |
600_000 |
inactiveAfterMillis |
(Individual Supervisor) Supervisor is marked as idle if all existing data has been read from input topic and no new data has been published for inactiveAfterMillis milliseconds. |
no (default == 600_000) |
https://github.com/apache/druid/pull/13311
# Improved supervisor termination
Fixed issues with delayed supervisor termination during certain transient states.
https://github.com/apache/druid/pull/13072
# Backoff for HttpPostEmitter
The HttpPostEmitter option now has a backoff. This means that there should be less noise in the logs and lower CPU usage if you use this option for logging.
https://github.com/apache/druid/pull/12102
# DumpSegment tool for nested columns
The DumpSegment tool can now be used on nested columns with the --dump nested option.
For more information, see dump-segment tool.
https://github.com/apache/druid/pull/13356
# Segment loading and balancing
# Batched segment allocation
Segment allocation on the Overlord can take some time to finish, which can cause ingestion lag while a task waits for segments to be allocated. Performing segment allocation in batches can help improve performance.
There are two new properties that affect how Druid performs segment allocation:
| Property | Description | Default |
|---|---|---|
druid.indexer.tasklock.batchSegmentAllocation |
If set to true, Druid performs segment allocate actions in batches to improve throughput and reduce the average task/action/run/time. See batching segmentAllocate actions for details. |
false |
druid.indexer.tasklock.batchAllocationWaitTime |
Number of milliseconds after Druid adds the first segment allocate action to a batch, until it executes the batch. Allows the batch to add more requests and improve the average segment allocation run time. This configuration takes effect only if batchSegmentAllocation is enabled. |
500 |
In addition to these properties, there are new metrics to track batch segment allocation. For more information, see New metrics for segment allocation.
For more information, see the following:
https://github.com/apache/druid/pull/13369 https://github.com/apache/druid/pull/13503
# Improved cachingCost balancer strategy
The cachingCost balancer strategy now behaves more similarly to cost strategy. When computing the cost of moving a segment to a server, the following calculations are performed:
- Subtract the self cost of a segment if it is being served by the target server
- Subtract the cost of segments that are marked to be dropped
https://github.com/apache/druid/pull/13321
# Faster segment assignment
You can now use a round-robin segment strategy to speed up initial segment assignments. Set useRoundRobinSegmentAssigment to true in the Coordinator dynamic config to enable this feature.
https://github.com/apache/druid/pull/13367
# Default to batch sampling for balancing segments
Batch sampling is now the default method for sampling segments during balancing as it performs significantly better than the alternative when there is a large number of used segments in the cluster.
As part of this change, the following have been deprecated and will be removed in future releases:
- coordinator dynamic config
useBatchedSegmentSampler - coordinator dynamic config
percentOfSegmentsToConsiderPerMove - old non-batch method of sampling segments
# Remove unused property
The unused coordinator property druid.coordinator.loadqueuepeon.repeatDelay has been removed. Use only druid.coordinator.loadqueuepeon.http.repeatDelay to configure repeat delay for the HTTP-based segment loading queue.
https://github.com/apache/druid/pull/13391
# Avoid segment over-replication
Improved the process of checking server inventory to prevent over-replication of segments during segment balancing.
https://github.com/apache/druid/pull/13114
# Provided service specific log4j overrides in containerized deployments
Provided an option to override log4j configs setup at the service level directories so that it works with Druid-operator based deployments.
https://github.com/apache/druid/pull/13020
# Various Docker improvements
- Updated Docker to run with JRE 11 by default.
- Updated Docker to use
gcr.io/distroless/java11-debian11image as base by default. - Enabled Docker buildkit cache to speed up building.
- Downloaded
bash-staticto the Docker image so that scripts that require bash can be executed. - Bumped builder image from
3.8.4-jdk-11-slimto3.8.6-jdk-11-slim. - Switched busybox from
amd64/busybox:1.30.0-glibctobusybox:1.35.0-glibc. - Added support to build arm64-based image.
https://github.com/apache/druid/pull/13059
# Enabled cleaner JSON for various input sources and formats
Added JsonInclude to various properties, to avoid population of default values in serialized JSON.
https://github.com/apache/druid/pull/13064
# Improved direct memory check on startup
Improved direct memory check on startup by providing better support for Java 9+ in RuntimeInfo, and clearer log messages where validation fails.
https://github.com/apache/druid/pull/13207
# Improved the run time of the MarkAsUnusedOvershadowedSegments duty
Improved the run time of the MarkAsUnusedOvershadowedSegments duty by iterating over all overshadowed segments and marking segments as unused in batches.
https://github.com/apache/druid/pull/13287
# Web console
# Delete an interval
You can now pick an interval to delete from a dropdown in the kill task dialog.
https://github.com/apache/druid/pull/13431
# Removed the old query view
The old query view is removed. Use the new query view with tabs. For more information, see Web console.
https://github.com/apache/druid/pull/13169
# Filter column values in query results
The web console now allows you to add to existing filters for a selected column.
https://github.com/apache/druid/pull/13169
# Support for Kafka lookups in the web-console
Added support for Kafka-based lookups rendering and input in the web console.
https://github.com/apache/druid/pull/13098
# Query task status information
The web console now exposes a textual indication about running and pending tasks when a query is stuck due to lack of task slots.
https://github.com/apache/druid/pull/13291
# Extensions
# Extension optimization
Optimized the compareTo function in CompressedBigDecimal.
https://github.com/apache/druid/pull/13086
# CompressedBigDecimal cleanup and extension
Removed unnecessary generic type from CompressedBigDecimal, added support for number input types, added support for reading aggregator input types directly (uningested data), and fixed scaling bug in buffer aggregator.
https://github.com/apache/druid/pull/13048
# Support for Kubernetes discovery
Added POD_NAME and POD_NAMESPACE env variables to all Kubernetes Deployments and StatefulSets.
Helm deployment is now compatible with druid-kubernetes-extension.
https://github.com/apache/druid/pull/13262
# Docs
# Jupyter Notebook tutorials
We released our first Jupyter Notebook-based tutorial to learn the basics of the Druid API. Download the notebook and follow along with the tutorial to learn how to get basic cluster information, ingest data, and query data. For more information, see Jupyter Notebook tutorials.
https://github.com/apache/druid/pull/13342
https://github.com/apache/druid/pull/13345
# Dependency updates
# Updated Kafka version
Updated the Apache Kafka core dependency to version 3.3.1.
https://github.com/apache/druid/pull/13176
# Docker improvements
Updated dependencies for the Druid image for Docker, including JRE 11. Docker BuildKit cache is enabled to speed up building.
https://github.com/apache/druid/pull/13059
# Upgrading to 25.0.0
Consider the following changes and updates when upgrading from Druid 24.0.x to 25.0.0. If you're updating from an earlier version, see the release notes of the relevant intermediate versions.
# Default HTTP-based segment discovery and task management
The default segment discovery method now uses HTTP instead of ZooKeeper.
This update changes the defaults for the following properties:
| Property | New default | Previous default |
|---|---|---|
druid.serverview.type for segment management |
http | batch |
druid.coordinator.loadqueuepeon.type for segment management |
http | curator |
druid.indexer.runner.type for the Overlord |
httpRemote | local |
To use ZooKeeper instead of HTTP, change the values for the properties back to the previous defaults. ZooKeeper-based implementations for these properties are deprecated and will be removed in a subsequent release.
https://github.com/apache/druid/pull/13092
# Finalizing HLL and quantiles sketch aggregates
The aggregation functions for HLL and quantiles sketches returned sketches or numbers when they are finalized depending on where they were in the native query plan.
Druid no longer finalizes aggregators in the following two cases:
- aggregators appear in the outer level of a query
- aggregators are used as input to an expression or finalizing-field-access post-aggregator
This change aligns the behavior of HLL and quantiles sketches with theta sketches.
To restore old behaviour, you can set sqlFinalizeOuterSketches=true in the query context.
https://github.com/apache/druid/pull/13247
# Kill tasks mark segments as unused only if specified
When you issue a kill task, Druid marks the underlying segments as unused only if explicitly specified. For more information, see the API reference
https://github.com/apache/druid/pull/13104
# Incompatible changes
# Upgrade curator to 5.3.0
Apache Curator upgraded to the latest version, 5.3.0. This version drops support for ZooKeeper 3.4 but Druid has already officially dropped support in 0.22. In 5.3.0, Curator has removed support for Exhibitor so all related configurations and tests have been removed.
https://github.com/apache/druid/pull/12939
# Fixed Parquet list conversion
The behavior of the parquet reader for lists of structured objects has been changed to be consistent with other parquet logical list conversions. The data is now fetched directly, more closely matching its expected structure. See parquet list conversion for more details.
https://github.com/apache/druid/pull/13294
# Credits
Thanks to everyone who contributed to this release!
@317brian @599166320 @a2l007 @abhagraw @abhishekagarwal87 @adarshsanjeev @adelcast @AlexanderSaydakov @amaechler @AmatyaAvadhanula @ApoorvGuptaAi @arvindanugula @asdf2014 @churromorales @clintropolis @cloventt @cristian-popa @cryptoe @dampcake @dependabot[bot] @didip @ektravel @eshengit @findingrish @FrankChen021 @gianm @hnakamor @hosswald @imply-cheddar @jasonk000 @jon-wei @Junge-401 @kfaraz @LakshSingla @mcbrewster @paul-rogers @petermarshallio @rash67 @rohangarg @sachidananda007 @santosh-d3vpl3x @senthilkv @somu-imply @techdocsmith @tejaswini-imply @vogievetsky @vtlim @wcc526 @writer-jill @xvrl @zachjsh
druid-24.0.2
1 year agoApache Druid 24.0.2 is a bug fix release that fixes some issues in the 24.0.1 release. See the complete set of changes for additional details.
# Bug fixes
https://github.com/apache/druid/pull/13138 to fix dependency errors while launching a Hadoop task.
# Credits
@kfaraz @LakshSingla
druid-24.0.1
1 year agoApache Druid 24.0.1 is a bug fix release that fixes some issues in the 24.0 release. See the complete set of changes for additional details.
# Notable Bug fixes
https://github.com/apache/druid/pull/13214 to fix SQL planning when using the JSON_VALUE function. https://github.com/apache/druid/pull/13297 to fix values that match a range filter on nested columns. https://github.com/apache/druid/pull/13077 to fix detection of nested objects while generating an MSQ SQL in the web-console. https://github.com/apache/druid/pull/13172 to correctly handle overlord leader election even when tasks cannot be reacquired. https://github.com/apache/druid/pull/13259 to fix memory leaks from SQL statement objects. https://github.com/apache/druid/pull/13273 to fix overlord API failures by de-duplicating task entries in memory. https://github.com/apache/druid/pull/13049 to fix a race condition while processing query context. https://github.com/apache/druid/pull/13151 to fix assertion error in SQL planning.
# Credits
Thanks to everyone who contributed to this release!
@abhishekagarwal87 @AmatyaAvadhanula @clintropolis @gianm @kfaraz @LakshSingla @paul-rogers @vogievetsky
# Known issues
- Hadoop ingestion does not work with custom extension config due to injection errors (fixed in https://github.com/apache/druid/pull/13138)
druid-24.0.0
1 year agoApache Druid 24.0.0 contains over 300 new features, bug fixes, performance enhancements, documentation improvements, and additional test coverage from 67 contributors. See the complete set of changes for additional details.
# Major version bump
Starting with this release, we have dropped the leading 0 from the release version and promoted all other digits one place to the left. Druid is now at major version 24, a jump up from the prior 0.23.0 release. In terms of backward-compatibility or breaking changes, this release is not significantly different than other previous major releases such as 0.23.0 or 0.22.0. We are continuing with the same policy as we have used in prior releases: minimizing the number of changes that require special attention when upgrading, and calling out any that do exist in the release notes. For this release, please refer to the Upgrading to 24.0.0 section for a list of backward-incompatible changes in this release.
# New Features
# Multi-stage query task engine
SQL-based ingestion for Apache Druid uses a distributed multi-stage query architecture, which includes a query engine called the multi-stage query task engine (MSQ task engine). The MSQ task engine extends Druid's query capabilities, so you can write queries that reference external data as well as perform ingestion with SQL INSERT and REPLACE. Essentially, you can perform SQL-based ingestion instead of using JSON ingestion specs that Druid's native ingestion uses. In addition to the easy-to-use syntax, the SQL interface lets you perform transformations that involve multiple shuffles of data.
SQL-based ingestion using the multi-stage query task engine is recommended for batch ingestion starting in Druid 24.0.0. Native batch and Hadoop-based ingestion continue to be supported as well. We recommend you review the known issues and test the feature in a staging environment before rolling out in production. Using the multi-stage query task engine with plain SELECT statements (not INSERT ... SELECT or REPLACE ... SELECT) is experimental.
If you're upgrading from an earlier version of Druid or you're using Docker, you'll need to add the druid-multi-stage-query extension to druid.extensions.loadlist in your common.runtime.properties file.
For more information, refer to the Overview documentation for SQL-based ingestion.
#12524 #12386 #12523 #12589
# Nested columns
Druid now supports directly storing nested data structures in a newly added COMPLEX<json> column type. COMPLEX<json> columns store a copy of the structured data in JSON format as well as specialized internal columns and indexes for nested literal values—STRING, LONG, and DOUBLE types. An optimized virtual column allows Druid to read and filter these values at speeds consistent with standard Druid LONG, DOUBLE, and STRING columns.
Newly added Druid SQL, native JSON functions, and virtual column allow you to extract, transform, and create COMPLEX<json> values in at query time. You can also use the JSON functions in INSERT and REPLACE statements in SQL-based ingestion, or in a transformSpec in native ingestion as an alternative to using a flattenSpec object to "flatten" nested data for ingestion.
See SQL JSON functions, native JSON functions, Nested columns, virtual columns, and the feature summary for more detail.
#12753 #12714 #12753 #12920
# Updated Java support
Java 11 is fully supported is no longer experimental. Java 17 support is improved.
#12839
# Query engine updates
# Updated column indexes and query processing of filters
Reworked column indexes to be extraordinarily flexible, which will eventually allow us to model a wide range of index types. Added machinery to build the filters that use the updated indexes, while also allowing for other column implementations to implement the built-in index types to provide adapters to make use indexing in the current set filters that Druid provides.
#12388
# Time filter operator
You can now use the Druid SQL operator TIME_IN_INTERVAL to filter query results based on time. Prefer TIME_IN_INTERVAL over the SQL BETWEEN operator to filter on time. For more information, see Date and time functions.
#12662
# Null values and the "in" filter
If a values array contains null, the "in" filter matches null values. This differs from the SQL IN filter, which does not match null values.
For more information, see Query filters and SQL data types. #12863
# Virtual columns in search queries
Previously, a search query could only search on dimensions that existed in the data source. Search queries now support virtual columns as a parameter in the query.
#12720
# Optimize simple MIN / MAX SQL queries on __time
Simple queries like select max(__time) from ds now run as a timeBoundary queries to take advantage of the time dimension sorting in a segment. You can set a feature flag to enable this feature.
#12472 #12491
# String aggregation results
The first/last string aggregator now only compares based on values. Previously, the first/last string aggregator’s values were compared based on the _time column first and then on values.
If you have existing queries and want to continue using both the _time column and values, update your queries to use ORDER BY MAX(timeCol).
#12773
# Reduced allocations due to Jackson serialization
Introduced and implemented new helper functions in JacksonUtils to enable reuse of
SerializerProvider objects.
Additionally, disabled backwards compatibility for map-based rows in the GroupByQueryToolChest by default, which eliminates the need to copy the heavyweight ObjectMapper. Introduced a configuration option to allow administrators to explicitly enable backwards compatibility.
#12468
# Updated IPAddress Java library
Added a new IPAddress Java library dependency to handle IP addresses. The library includes IPv6 support. Additionally, migrated IPv4 functions to use the new library.
#11634
# Query performance improvements
Optimized SQL operations and functions as follows:
- Vectorized numeric latest aggregators (#12439)
- Optimized
isEmpty()andequals()on RangeSets (#12477) - Optimized reuse of Yielder objects (#12475)
- Operations on numeric columns with indexes are now faster (#12830)
- Optimized GroupBy by reducing allocations. Reduced allocations by reusing entry and key holders (#12474)
- Added a vectorized version of string last aggregator (#12493)
- Added Direct UTF-8 access for IN filters (#12517)
- Enabled virtual columns to cache their outputs in case Druid calls them multiple times on the same underlying row (#12577)
- Druid now rewrites a join as a filter when possible in IN joins (#12225)
- Added automatic sizing for GroupBy dictionaries (#12763)
- Druid now distributes JDBC connections more evenly amongst brokers (#12817)
# Streaming ingestion
# Kafka consumers
Previously, consumers that were registered and used for ingestion persisted until Kafka deleted them. They were only used to make sure that an entire topic was consumed. There are no longer consumer groups that linger.
#12842
# Kinesis ingestion
You can now perform Kinesis ingestion even if there are empty shards. Previously, all shards had to have at least one record.
#12792
# Batch ingestion
# Batch ingestion from S3
You can now ingest data from endpoints that are different from your default S3 endpoint and signing region. For more information, see S3 config. #11798
# Improvements to ingestion in general
This release includes the following improvements for ingestion in general.
# Increased robustness for task management
Added setNumProcessorsPerTask to prevent various automatically-sized thread pools from becoming unreasonably large. It isn't ideal for each task to size its pools as if it is the only process on the entire machine. On large machines, this solves a common cause of OutOfMemoryError due to "unable to create native thread".
#12592
# Avatica JDBC driver
The JDBC driver now follows the JDBC standard and uses two kinds of statements, Statement and PreparedStatement.
#12709
# Eight hour granularity
Druid now accepts the EIGHT_HOUR granularity. You can segment incoming data to EIGHT_HOUR buckets as well as group query results by eight hour granularity.
#12717
# Ingestion general
# Updated Avro extension
The previous Avro extension leaked objects from the parser. If these objects leaked into your ingestion, you had objects being stored as a string column with the value as the .toString(). This string column will remain after you upgrade but will return Map.toString() instead of GenericRecord.toString. If you relied on the previous behavior, you can use the Avro extension from an earlier release.
#12828
# Sampler API
The sampler API has additional limits: maxBytesInMemory and maxClientResponseBytes. These options augment the existing options numRows and timeoutMs. maxBytesInMemory can be used to control the memory usage on the Overlord while sampling. maxClientResponseBytes can be used by clients to specify the maximum size of response they would prefer to handle.
#12947
# SQL
# Column order
The DruidSchema and SegmentMetadataQuery properties now preserve column order instead of ordering columns alphabetically. This means that query order better matches ingestion order.
#12754
# Converting JOINs to filter
You can improve performance by pushing JOINs partially or fully to the base table as a filter at runtime by setting the enableRewriteJoinToFilter context parameter to true for a query.
Druid now pushes down join filters in case the query computing join references any columns from the right side.
#12749 #12868
# Add is_active to sys.segments
Added is_active as shorthand for (is_published = 1 AND is_overshadowed = 0) OR is_realtime = 1). This represents "all the segments that should be queryable, whether or not they actually are right now".
#11550
# useNativeQueryExplain now defaults to true
The useNativeQueryExplain property now defaults to true. This means that EXPLAIN PLAN FOR returns the explain plan as a JSON representation of equivalent native query(s) by default. For more information, see Broker Generated Query Configuration Supplementation.
#12936
# Running queries with inline data using druid query engine
Some queries that do not refer to any table, such as select 1, are now always translated to a native Druid query with InlineDataSource before execution. If translation is not possible, for queries such as SELECT (1, 2), then an error occurs. In earlier versions, this query would still run.
#12897
# Coordinator/Overlord
# You can configure the Coordinator to kill segments in the future
You can now set druid.coordinator.kill.durationToRetain to a negative period to configure the Druid cluster to kill segments whose interval_end is a date in the future. For example, PT-24H would allow segments to be killed if their interval_end date was 24 hours or less into the future at the time that the kill task is generated by the system.
A cluster operator can also disregard the druid.coordinator.kill.durationToRetain entirely by setting a new configuration, druid.coordinator.kill.ignoreDurationToRetain=true. This ignores interval_end date when looking for segments to kill, and can instead kill any segment marked unused. This new configuration is turned off by default, and a cluster operator should fully understand and accept the risks before enabling it.
# Improved Overlord stability
Reduced contention between the management thread and the reception of status updates from the cluster. This improves the stability of Overlord and all tasks in a cluster when there are large (1000+) task counts.
#12099
# Improved Coordinator segment logging
Updated Coordinator load rule logging to include current replication levels. Added missing segment ID and tier information from some of the log messages.
#12511
# Optimized overlord GET tasks memory usage
Addressed the significant memory overhead caused by the web-console indirectly calling the Overlord’s GET tasks API. This could cause unresponsiveness or Overlord failure when the ingestion tab was opened multiple times.
#12404
# Reduced time to create intervals
In order to optimize segment cost computation time by reducing time taken for interval creation, store segment interval instead of creating it each time from primitives and reduce memory overhead of storing intervals by interning them. The set of intervals for segments is low in cardinality.
#12670
# Brokers/Overlord
Brokers now have a default of 25MB maximum queued per query. Previously, there was no default limit. Depending on your use case, you may need to increase the value, especially if you have large result sets or large amounts of intermediate data. To adjust the maximum memory available, use the druid.broker.http.maxQueuedBytes property.
For more information, see Configuration reference.
# Web console
Prepare to have your Web Console experience elevated! - @vogievetsky
# New query view (WorkbenchView) with tabs and long running query support

You can use the new query view to execute multi-stage, task based, queries with the /druid/v2/sql/task and /druid/indexer/v1/task/* APIs as well as native and sql-native queries just like the old Query view. A key point of the sql-msq-task based queries is that they may run for a long time. This inspired / necessitated many UX changes including, but not limited to the following:
# Tabs
You can now have many queries stored and running at the same time, significantly improving the query view UX.

You can open several tabs, duplicate them, and copy them as text to paste into any console and reopen there.
# Progress reports (counter reports)
Queries run with the multi-stage query task engine have detailed progress reports shown in the summary progress bar and the in detail execution table that provides summaries of the counters for every step.

# Error and warning reports
Queries run with the multi-stage query task engine present user friendly warnings and errors should anything go wrong. The new query view has components to visualize these with their full detail including a stack-trace.

# Recent query tasks panel
Queries run with the multi-stage query task engine are tasks. This makes it possible to show queries that are executing currently and that have executed in the recent past.

For any query in the Recent query tasks panel you can view the execution details for it and you can also attach it as a new tab and continue iterating on the query. It is also possible to download the "query detail archive", a JSON file containing all the important details for a given query to use for troubleshooting.
# Connect external data flow
Connect external data flow lets you use the sampler to sample your source data to, determine its schema and generate a fully formed SQL query that you can edit to fit your use case before you launch your ingestion job. This point-and-click flow will save you much typing.

# Preview button
The Preview button appears when you type in an INSERT or REPLACE SQL query. Click the button to remove the INSERT or REPLACE clause and execute your query as an "inline" query with a limi). This gives you a sense of the shape of your data after Druid applies all your transformations from your SQL query.
# Results table
The query results table has been improved in style and function. It now shows you type icons for the column types and supports the ability to manipulate nested columns with ease.
# Helper queries
The Web Console now has some UI affordances for notebook and CTE users. You can reference helper queries, collapsable elements that hold a query, from the main query just like they were defined with a WITH statement. When you are composing a complicated query, it is helpful to break it down into multiple queries to preview the parts individually.
# Additional Web Console tools
More tools are available from the ... menu:
- Explain query - show the query plan for sql-native and multi-stage query task engine queries.
- Convert ingestion spec to SQL - Helps you migrate your native batch and Hadoop based specs to the SQL-based format.
- Open query detail archive - lets you open a query detail archive downloaded earlier.
- Load demo queries - lets you load a set of pre-made queries to play around with multi-stage query task engine functionality.
# New SQL-based data loader
The data loader exists as a GUI wizard to help users craft a JSON ingestion spec using point and click and quick previews. The SQL data loader is the SQL-based ingestion analog of that.
Like the native based data loader, the SQL-based data loader stores all the state in the SQL query itself. You can opt to manipulate the query directly at any stage. See (#12919) for more information about how the data loader differs from the Connect external data workflow.
# Other changes and improvements
- The query view has so much new functionality that it has moved to the far left as the first view available in the header.
- You can now click on a datasource or segment to see a preview of the data within.
- The task table now explicitly shows if a task has been canceled in a different color than a failed task.
- The user experience when you view a JSON payload in the Druid console has been improved. There’s now syntax highlighting and a search.
- The Druid console can now use the column order returned by a scan query to determine the column order for reindexing data.
- The way errors are displayed in the Druid console has been improved. Errors no longer appear as a single long line.
See (#12919) for more details and other improvements
# Metrics
# Sysmonitor stats for Peons
Sysmonitor stats, like memory or swap, are no longer reported since Peons always run on the same host as MiddleManagerse. This means that duplicate stats will no longer be reported.
#12802
# Prometheus
You can now include the host and service as labels for Prometheus by setting the following properties to true:
-
druid.emitter.prometheus.addHostAsLabel -
druid.emitter.prometheus.addServiceAsLabel
#12769
# Rows per segment
(Experimental) You can now see the average number of rows in a segment and the distribution of segments in predefined buckets with the following metrics: segment/rowCount/avg and segment/rowCount/range/count.
Enable the metrics with the following property: org.apache.druid.server.metrics.SegmentStatsMonitor
#12730
# New sqlQuery/planningTimeMs metric
There’s a new sqlQuery/planningTimeMs metric for SQL queries that computes the time it takes to build a native query from a SQL query.
#12923
# StatsD metrics reporter
The StatsD metrics reporter extension now includes the following metrics:
- coordinator/time
- coordinator/global/time
- tier/required/capacity
- tier/total/capacity
- tier/replication/factor
- tier/historical/count
- compact/task/count
- compactTask/maxSlot/count
- compactTask/availableSlot/count
- segment/waitCompact/bytes
- segment/waitCompact/count
- interval/waitCompact/count
- segment/skipCompact/bytes
- segment/skipCompact/count
- interval/skipCompact/count
- segment/compacted/bytes
- segment/compacted/count
- interval/compacted/count #12762
# New worker level task metrics
Added a new monitor, WorkerTaskCountStatsMonitor, that allows each middle manage worker to report metrics for successful / failed tasks, and task slot usage.
#12446
# Improvements to the JvmMonitor
The JvmMonitor can now handle more generation and collector scenarios. The monitor is more robust and works properly for ZGC on both Java 11 and 15.
#12469
# Garbage collection
Garbage collection metrics now use MXBeans.
#12481
# Metric for task duration in the pending queue
Introduced the metric task/pending/time to measure how long a task stays in the pending queue.
#12492
# Emit metrics object for Scan, Timeseries, and GroupBy queries during cursor creation
Adds vectorized metric for scan, timeseries and groupby queries.
#12484
# Emit state of replace and append for native batch tasks
Druid now emits metrics so you can monitor and assess the use of different types of batch ingestion, in particular replace and tombstone creation.
#12488 #12840
# KafkaEmitter emits queryType
The KafkaEmitter now properly emits the queryType property for native queries.
#12915
# Security
You can now hide properties that are sensitive in the API response from /status/properties, such as S3 access keys. Use the druid.server.hiddenProperties property in common.runtime.properties to specify the properties (case insensitive) you want to hide.
#12950
# Other changes
- You can now configure the retention period for request logs stored on disk with the
druid.request.logging.durationToRetainproperty. Set the retention period to be longer thanP1D(#12559) - You can now specify liveness and readiness probe delays for the historical StatefulSet in your values.yaml file. The default is 60 seconds (#12805)
- Improved exception message for native binary operators (#12335)
- Improved error messages when URI points to a file that doesn't exist (#12490)
- Improved build performance of modules (#12486)
- Improved lookups made using the druid-kafka-extraction-namespace extension to handle records that have been deleted from a kafka topic (#12819)
- Updated core Apache Kafka dependencies to 3.2.0 (#12538)
- Updated ORC to 1.7.5 (#12667)
- Updated Jetty to 9.4.41.v20210516 (#12629)
- Added
Zstandardcompression library toCompressionStrategy(#12408) - Updated the default gzip buffer size to 8 KB to for improved performance (#12579)
- Updated the default
inputSegmentSizeBytesin Compaction configuration to 100,000,000,000,000 (~100TB)
# Bug fixes
Druid 24.0 contains over 68 bug fixes. You can find the complete list here
# Upgrading to 24.0
# Permissions for multi-stage query engine
To read external data using the multi-stage query task engine, you must have READ permissions for the EXTERNAL resource type. Users without the correct permission encounter a 403 error when trying to run SQL queries that include EXTERN.
The way you assign the permission depends on your authorizer. For example, with [basic security]((/docs/development/extensions-core/druid-basic-security.md) in Druid, add the EXTERNAL READ permission by sending a POST request to the roles API.
The example adds permissions for users with the admin role using a basic authorizer named MyBasicMetadataAuthorizer. The following permissions are granted:
- DATASOURCE READ
- DATASOURCE WRITE
- CONFIG READ
- CONFIG WRITE
- STATE READ
- STATE WRITE
- EXTERNAL READ
curl --location --request POST 'http://localhost:8081/druid-ext/basic-security/authorization/db/MyBasicMetadataAuthorizer/roles/admin/permissions' \
--header 'Content-Type: application/json' \
--data-raw '[
{
"resource": {
"name": ".*",
"type": "DATASOURCE"
},
"action": "READ"
},
{
"resource": {
"name": ".*",
"type": "DATASOURCE"
},
"action": "WRITE"
},
{
"resource": {
"name": ".*",
"type": "CONFIG"
},
"action": "READ"
},
{
"resource": {
"name": ".*",
"type": "CONFIG"
},
"action": "WRITE"
},
{
"resource": {
"name": ".*",
"type": "STATE"
},
"action": "READ"
},
{
"resource": {
"name": ".*",
"type": "STATE"
},
"action": "WRITE"
},
{
"resource": {
"name": "EXTERNAL",
"type": "EXTERNAL"
},
"action": "READ"
}
]'
# Behavior for unused segments
Druid automatically retains any segments marked as unused. Previously, Druid permanently deleted unused segments from metadata store and deep storage after their duration to retain passed. This behavior was reverted from 0.23.0.
#12693
# Default for druid.processing.fifo
The default for druid.processing.fifo is now true. This means that tasks of equal priority are treated in a FIFO manner. For most use cases, this change can improve performance on heavily loaded clusters.
#12571
# Update to JDBC statement closure
In previous releases, Druid automatically closed the JDBC Statement when the ResultSet was closed. Druid closed the ResultSet on EOF. Druid closed the statement on any exception. This behavior is, however, non-standard. In this release, Druid's JDBC driver follows the JDBC standards more closely: The ResultSet closes automatically on EOF, but does not close the Statement or PreparedStatement. Your code must close these statements, perhaps by using a try-with-resources block. The PreparedStatement can now be used multiple times with different parameters. (Previously this was not true since closing the ResultSet closed the PreparedStatement.) If any call to a Statement or PreparedStatement raises an error, the client code must still explicitly close the statement. According to the JDBC standards, statements are not closed automatically on errors. This allows you to obtain information about a failed statement before closing it. If you have code that depended on the old behavior, you may have to change your code to add the required close statement.
#12709
# Known issues
# Credits
@2bethere @317brian @a2l007 @abhagraw @abhishekagarwal87 @abhishekrb19 @adarshsanjeev @aggarwalakshay @AmatyaAvadhanula @BartMiki @capistrant @chenrui333 @churromorales @clintropolis @cloventt @CodingParsley @cryptoe @dampcake @dependabot[bot] @dherg @didip @dongjoon-hyun @ektravel @EsoragotoSpirit @exherb @FrankChen021 @gianm @hellmarbecker @hwball @iandr413 @imply-cheddar @jarnoux @jasonk000 @jihoonson @jon-wei @kfaraz @LakshSingla @liujianhuanzz @liuxiaohui1221 @lmsurpre @loquisgon @machine424 @maytasm @MC-JY @Mihaylov93 @nishantmonu51 @paul-rogers @petermarshallio @pjfanning @rockc2020 @rohangarg @somu-imply @suneet-s @superivaj @techdocsmith @tejaswini-imply @TSFenwick @vimil-saju @vogievetsky @vtlim @williamhyun @wiquan @writer-jill @xvrl @yuanlihan @zachjsh @zemin-piao