Agriculture KnowledgeGraph Data Save
对知识库Wikidata的爬虫以及数据处理脚本 将三元组关系对齐到语料库的脚本 获取知识图谱数据的脚本
2020.07.29
由于工作原因,本项目不再维护,烦请谅解
说明
本项目为一些用于获取知识图谱中三元组关系的python脚本。包括爬取Wikidata数据的爬虫、爬取复旦知识工场数据的爬虫(由于知识工场限制爬取,这部分暂时不好用)、提取所有中文维基页面的脚本以及将Wikidata三元组数据对齐到中文维基页面语句的脚本。
运行环境
python3、 Scrapy、neo4j(仅对齐时需要)、MongoDB(标注关系数据集时需要)
注意:下面所有爬虫执行命令scrapy crawl XXX 请在各个模块的根目录执行,否则可能由于路径问题找不到文件导致程序报错
Model&taggingDemo&toolkit训练集标注工具(update 2018.04.07)
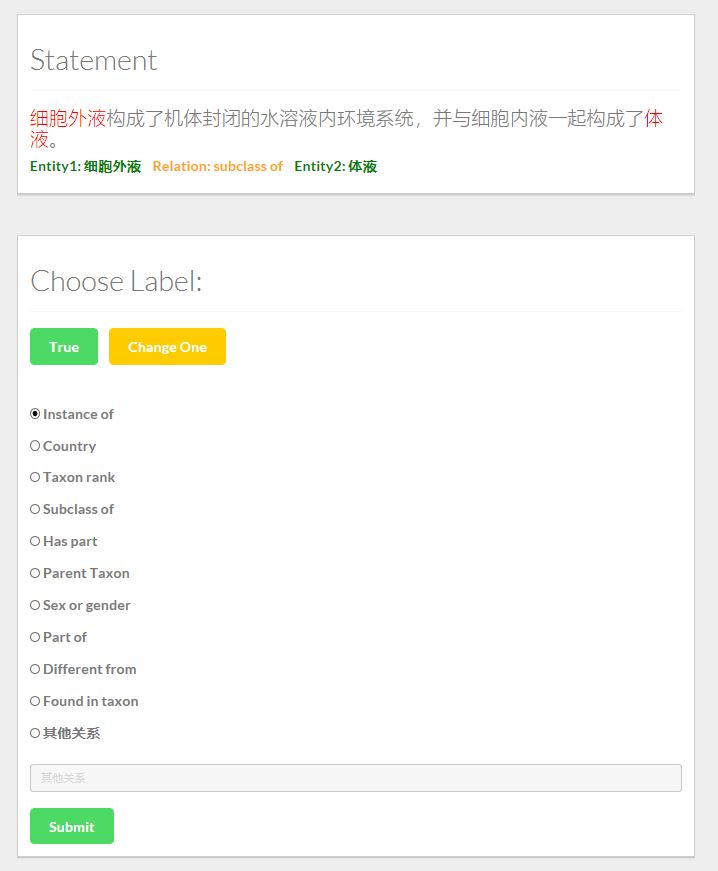
用于标注训练集的工具,如果Statement的标签是对的,点击True按钮;否则选择一个关系,或者输入其它关系。若当前句子无法判断,则点击Change One按钮换一条数据。
说明: Statement是/TrainDataBaseOnWiki/finalData中train_data.txt中的数据,我们将它转化成json,导入到mongoDB中。标注好的数据同样存在MongoDB中另一个Collection中。关于Mongo的使用方法可以参考官方tutorial,或者利用这篇文章简单了解一下MongoDB 。
我们在MongoDB中使用两个Collections,一个是train_data,即未经人工标注的数据;另一个是test_data,即人工标注好的数据。

使用方法
启动neo4j,mongodb之后,进入taggingdemo目录,启动django服务,进入127.0.0.1:8000/tagging即可使用
wikidataCrawler
用来爬取wikidata上定义的所有关系
wikidata中的所有关系都汇总在该网页上(链接) ,wikidataCrawler将该网页下的汇总的所有关系及其对应的中文名称爬取下来,存储为json格式
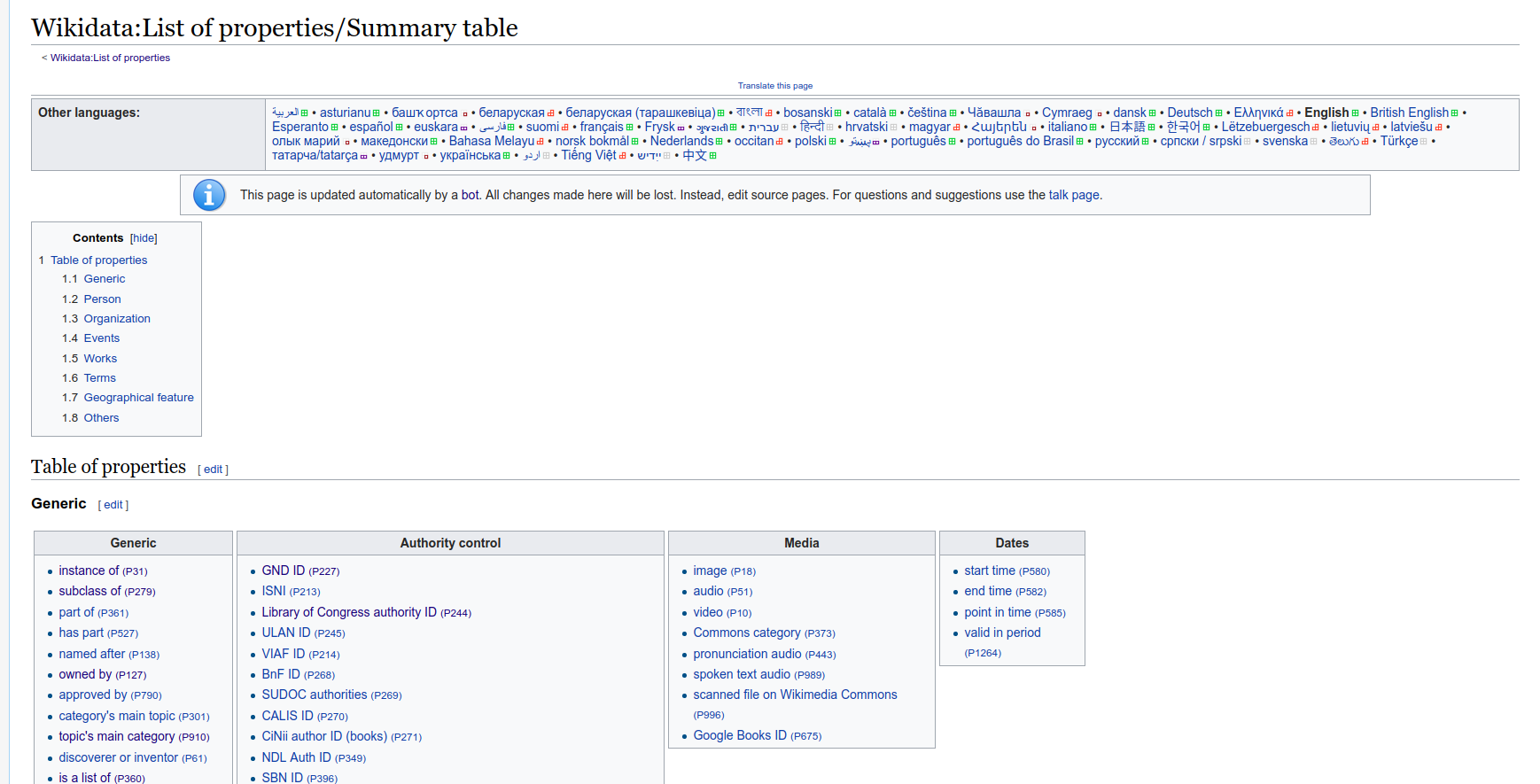
使用方法
进入到wikidataCrawler目录下,运行scrapy crawl relation即可爬取wikidata中定义的所有关系。可以得到relation.json和chrmention.json。
-
relation.json内容: 关系的id,关系所属的大类,关系所属子类,对应的链接,关系的英文表示 -
chrmention.json内容: 关系的id,关系的中文表示(对于不包含中文表示的数据暂时不做处理)。
将relation.json和chrmention.json的数据进行合并,运行mergeChrmentionToRelation.ipynb即可,得到的结果存储在result.json中,匹配失败的存在fail.json 中
wikientities
用来爬取实体,返回json格式
进入到wikientities目录下,运行scrapy crawl entity。可以得到 entity.json。
entity.json 是以predict_labels.txt中的实体为搜索词,在wikidata上搜索返回的json内容。
entity.json中还包括搜索词(即实体)以及实体所属的类别(和predict_labels.txt中一样)也加入json中存储。
由于我目前想做一个农业领域的知识图谱,因此predict_label.txt中很多词都是关于农业的,若想爬取其他实体,则自己修改predict_label.txt中的数据即可。
wikidataRelation说明
用来爬取实体和实体间的关系三元组,返回三元组
Wikidata是一个开放的全领域的知识库,其中包含大量的实体以及实体间的关系。下图是一个wikidata的实体页面
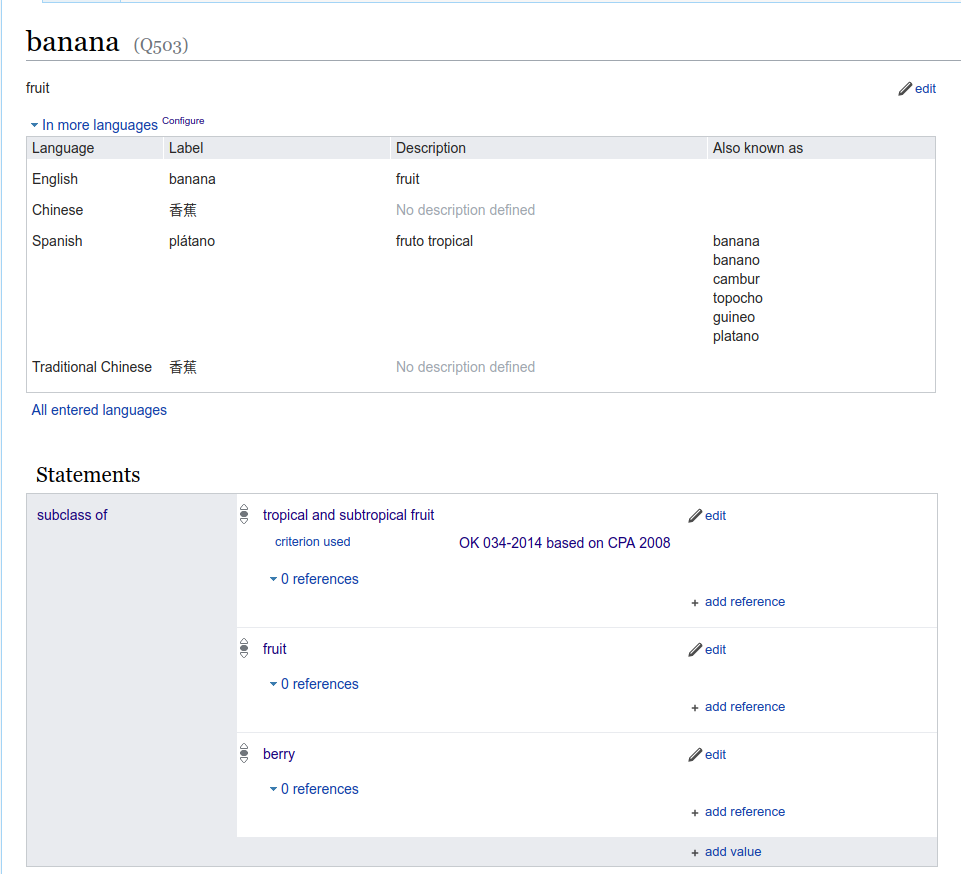
从图中可以看到wikidata实体页面包含实体的描述和与该实体相关联的其它实体及对应的关系。
wikidataRelation爬取得到的是实体和实体间的三元关系,例如合成橡胶和石油之间存在material used的关系,因此可以得到如下json格式的三元组:
{"entity1": "合成橡胶", "relation": "material used", "entity2": "石油"}
使用方法
首先运行preProcess.py,得到readytoCrawl.json。然后进入到wikidataRelation目录下,运行scrapy crawl entityRelation。可以得到entityRelation.json 。
entityRelation.json是利用entity.json中的所有实体为基础,获取与这些实体相关的其他实体和关系。
wikidataProcessing
用来处理得到的三元组关系(entityRelation.json)
将得到的entityRelation.json 处理成csv,并且存入neo4j数据库。该文件夹下的两个文件hudong_pedia.csv 和hudong_pedia2.csv 是爬取互动百科相关页面得到的,对应的就是wikientities目录下的predict_label.txt中的实体。运行relationDataProcessing.py 可以得到new_node.csv (即从wikidata实体页面中爬取得到的实体不包含在predict_label.txt中的部分)、wikidata_relation.csv(predict_label.txt中实体之间的关系)以及wikidata_relation2.csv(predict_label.txt中实体和新发现实体间的关系),将该目录下所有csv导入到neo4j中,具体操作参见Agriculture_KnowledgeGraph 中的项目部署部分。
CN_DBpediaCrawler
CN_DBpedia限制访问,需要向复旦大学知识工场申请API,否则只能限制每分钟爬取次数,这里的爬虫还有些问题,暂时不能使用。
wikiextractor
wikiextractor是用来获取维基百科语料的工具,维基百科有wiki dump可以直接下载:下载链接 ,下载好之后,利用wikiextractor工具进行处理,可以剔除掉一些无用的信息,直接得到维基百科语料库。wikiextractor工具链接 ,下载并安装后,将wiki dump放在wikiextractor目录下,执行命令
bzcat zhwiki-latest-pages-articles.xml.bz2 | python WikiExtractor.py -b 500K -o extracted -
可以得到处理好的维基百科语料,在目录extractor下。
由于得到的语料既有简体也有繁体,所以要进行繁简体转换。将本项目wikiextractor\extracted目录下的三个python文件复制到你处理好的维基百科语料的目录(extractor)下,运行convLan.py便可以将繁体转化为简体。
TrainDataBaseOnWiki
用于将从wikidata知识库中获取的三元组关系对齐到中文维基的语料库上
首先必须将wikidataProcessing目录下的csv导入到neo4j中,才能成功运行。运行extractTrainingData.py后,可以得到train_data.txt ,其内容包含:
entity1pos entity1 entity2pos entity2 setence relation
(注:该文件夹下的parallelTrainingData.py是后来加的,用来得到NA关系的数据,可以参考这个代码来并行得到train_data.txt)
从维基预料中对齐得到的训练集里面有很多属性关系(中文),甚至还有些关系为空值,把这部分过滤掉,得到filter_train_data_all.txt
python filterRelation.py
有些python文件因为文件名变动可能会报错,修改文件名即可
得到train_data.txt后,使用dataScrubbing.py处理得到的数据(参考,由于文件名变动一些代码可能运行不了),包括:
-
错误处理(not necessary)如果数据中有错误,利用该模块处理错误部分句子有换行,把换行去掉第一次产生的数据train_data.txt,由于之前程序在切割字符串时出了问题,因此relation这一列不对,这里重新处理一下 -
选择农业相关的数据从指定的train_data.txt中挑选出与农业有关的数据,
运行
python dataScrubbing.py handleError
执行错误管理模块
运行
python dataScrubbing.py selectAgriculturalData filename
执行数据选择模块
wikidataAnalyse
wikidataAnalyse: 得到staticResult.txt,统计各种关系的分布情况
extractEntityAttribute: 获取实体属性得到attributes.csv
getCorpus(弃用): 获得互动百科语料hudongBaikeCorpus.txt
hudongpediaCrawler
包含中国各个城市的各种气候,以及爬取所有气候的互动百科页面
Labels:(命名实体的分类)
| Label | NE Tags | Example |
|---|---|---|
| 0 | Invalid(不合法) | “色调”,“文化”,“景观”,“条件”,“A”,“234年”(不是具体的实体,或一些脏数据) |
| 1 | Person(人物,职位) | “袁隆平”,“习近平”,“皇帝” |
| 2 | Location(地点,区域) | “福建省”,“三明市”,“大明湖” |
| 3 | Organization(机构,会议) | “华东师范大学”,“上海市农业委员会” |
| 4 | Political economy(政治经济名词) | “惠农补贴”,“基本建设投资” |
| 5 | Animal(动物学名词,包括畜牧类,爬行类,鸟类,鱼类,等) | “绵羊”,“淡水鱼”,“麻雀” |
| 6 | Plant(植物学名词,包括水果,蔬菜,谷物,草药,菌类,植物器官,其他植物) | “苹果”,“小麦”,“生菜” |
| 7 | Chemicals(化学名词,包括肥料,农药,杀菌剂,其它化学品,术语等) | “氮”,“氮肥”,“硝酸盐”,“吸湿剂” |
| 8 | Climate(气候,季节) | “夏天”,“干旱” |
| 9 | Food items(动植物产品) | “奶酪”,“牛奶”,“羊毛”,“面粉” |
| 10 | Diseases(动植物疾病) | “褐腐病”,“晚疫病” |
| 11 | Natural Disaster(自然灾害) | “地震”,“洪水”,“饥荒” |
| 12 | Nutrients(营养素,包括脂肪,矿物质,维生素,碳水化合物等) | “维生素A”,"钙" |
| 13 | Biochemistry(生物学名词,包括基因相关,人体部位,组织器官,细胞,细菌,术语) | “染色体”,“血红蛋白”,“肾脏”,“大肠杆菌” |
| 14 | Agricultural implements(农机具,一般指机械或物理设施) | “收割机”,“渔网” |
| 15 | Technology(农业相关术语,技术和措施) | “延后栽培",“卫生防疫”,“扦插” |
| 16 | other(除上面类别之外的其它名词实体,可以与农业无关但必须是实体) | “加速度",“cpu”,“计算机”,“爱鸟周”,“人民币”,“《本草纲目》”,“花岗岩” |
