Mmlspark Versions Save
Simple and Distributed Machine Learning
v0.11.1
1 year agoSynapseML v0.11.1
Bug Fixes 🐞
- set default values for aadToken & url for internal Synapse (#1918)
- ONNX model shape inference cannot handle batch with shape [-1] (#1906)
- forgot to add getPValue to python side (#1909)
- generate random dir for each test (#1908)
- add back diagnosticsInfo for MVAD (#1892)
- DML run get timeout if big dataset has more feature columns (Workaround Synapse Spark optimizer issue) (#1903)
- fix date parsing in FaceSuite test (#1896)
- fix Build pipeline (#1904)
- Retry OnnxHub call to improve test reliability (#1889)
- Normalize line-endings (#1883)
- Remove case matching for erased generic type (#1880)
- fix bug #1869, DML .setFitIntercept should be set to true (#1876)
- Remove extraneous "Foo" type from Py codegen (#1867)
- Allow variable size in ONNX inputs (#1851)
- Abstain from CodeQL for markdown-only changes (#1865)
- fix style
- update OpenAIEmbedding internalServiceType
Build 🏭
- bump peter-evans/create-or-update-comment from 2 to 3 (#1907)
- bump ossf/scorecard-action from 2.1.2 to 2.1.3 (#1898)
- bump amannn/action-semantic-pull-request from 5.1.0 to 5.2.0 (#1878)
- bump @sideway/formula from 3.0.0 to 3.0.1 in /website (#1874)
- bump webpack from 5.75.0 to 5.76.1 in /website (#1870)
Documentation 📘
- Fix installation instruction in the webpage for the build.sbt file (#1921)
- note discrete treatment data type (#1905)
- add custom chatbot creation to form demo (#1888)
- add overview page for simple DNN and fix some typos (#1879)
- Fix a typo in installation docs
- fix link issue in CONTRIBUTING.md (#1864)
- fix a few issues in cognitive service demo (#1861)
Features 🌈
- add streaming API for MVAD (#1893)
- [DistributionBalanceMeasure] Add implementation + unit tests for custom reference distribution (#1885)
- Add ChatGPT through the
OpenAIChatCompletiontransformer (#1887) - support new api version of form recognizer (#1882)
- Add a new function to DMLModel, getPValue (#1863)
- update default internal endpoint for cog services (#1859)
Maintenance 🔧
- bump to v0.11.1 (#1933)
- Adding telemetry for the dataset metadata. This one is specially for … (#1917)
- fix r tests (#1927)
- fix build issues (#1916)
- disable test until Synapse is fixed (#1915)
- add .bloop to .gitignore (#1897)
- clean up old/missed search indexes in SearchWriterSuite (#1901)
- Add utility to clean azure search indexes
- update website docs to point to correct developer API docs (#1877)
- Update pipeline.yaml for Azure Pipelines (#1866)
- make sure nightly build has new commit
Changes:
- 866261c212441a92c4c5dfa14d0f16ce71be510f chore: bump to v0.11.1 (#1933)
- 3c097027eeba8896724d979ae50d50f432934ef6 chore: Adding telemetry for the dataset metadata. This one is specially for … (#1917)
- 0d0d10c7cdedca17bc7cb85d039c5c42ae954721 feat: add streaming API for MVAD (#1893)
- 1b71c1dadef393ce8173144230e1165a1fc651e4 chore: fix r tests (#1927)
- 0df97ad230e6ce7f2f90132b1117d1e39d0f1cb7 chore: fix build issues (#1916)
- 78695fb03b56e4eb8b179cccd91dd655fefda2f8 Update Regression - Vowpal Wabbit vs. LightGBM vs. Linear Regressor.ipynb (#1922)
- 87d5bc5391e5c4a2b04ae86ebf987a2c5c8dc10d docs: Fix installation instruction in the webpage for the build.sbt file (#1921)
- 8320b2baa84e5963ea5539b3d8aafd8fcebb2ec3 fix: set default values for aadToken & url for internal Synapse (#1918)
- 4912ae49c51fe7c335b4ad634d3496e03b0c23f7 chore: disable test until Synapse is fixed (#1915)
- 469445b7880b336c605fdb5f6bec570989134d27 fix: ONNX model shape inference cannot handle batch with shape [-1] (#1906)
See More
- 3fa001e129c914b7f315a015434a4bb4462d8836 build: bump peter-evans/create-or-update-comment from 2 to 3 (#1907)
- f51327e236d09483247b64ee99c7de40c5f245c0 Update LightGBM version to 3.3.5 (#1910)
- b1e584ecd7e2b600043e218856bf5e5b3110a888 fix: forgot to add getPValue to python side (#1909)
- a09a6f775e3a21875eace9c6c710d88a533a014c docs: note discrete treatment data type (#1905)
- 0fa3f2a6647a16053b970f7e2e240bee9fc5436a fix: generate random dir for each test (#1908)
- 736c3172dea00c7116989959dd37bb8bb68e8d0a fix: add back diagnosticsInfo for MVAD (#1892)
- 13afff6ba89ec7951fd9d47739214ef6e4e57d52 fix: DML run get timeout if big dataset has more feature columns (Workaround Synapse Spark optimizer issue) (#1903)
- 7546e7fe9f4c14f396f3e99806df4b4e783105d7 build: bump ossf/scorecard-action from 2.1.2 to 2.1.3 (#1898)
- f227f02496c51f500a5d82bbe7ee1a9a8e2e9acb fix: fix date parsing in FaceSuite test (#1896)
- 0f02626eec3a23b5e5d21b880589b95f0045bb39 fix: fix Build pipeline (#1904)
- ce9fe41031e790b694a63056decb4642dfe249b9 chore: add .bloop to .gitignore (#1897)
- 7ffa970f56b31794b59765cd5f4fe4fdd82db483 chore: clean up old/missed search indexes in SearchWriterSuite (#1901)
- 9a6cf0358a45d16ff20d458ffc6dcdcb88ccf5d9 chore: Add utility to clean azure search indexes
- 52919ce40042ad19a9ca6834d49776d6c88ff595 fix: Retry OnnxHub call to improve test reliability (#1889)
- 979c62911f1d79fe19e337855a8bd0cf57a77390 feat: [DistributionBalanceMeasure] Add implementation + unit tests for custom reference distribution (#1885)
- 412620a88ceac095cd34f8a73ad90df5b3da6f82 docs: add custom chatbot creation to form demo (#1888)
- 9f634a62070d52775ef9df86afd7d04d4f6e9c7f feat: Add ChatGPT through the
OpenAIChatCompletiontransformer (#1887) - 76570894b4108ab6e5d44ce8f790ee49485636b6 fix: Normalize line-endings (#1883)
- c1567920acc05d54dab96c8c30c55dc89eb2225a feat: support new api version of form recognizer (#1882)
- ed842a5f84e101862df5d85c7d9de1eacf763b85 docs: add overview page for simple DNN and fix some typos (#1879)
- 87e1c78611345d048bac3337cfa849f0dca7eb77 fix: Remove case matching for erased generic type (#1880)
- cd72bc921ebbb4e624142e5245d6241f0e382bc3 build: bump amannn/action-semantic-pull-request from 5.1.0 to 5.2.0 (#1878)
- 564d04756a514d69ed43edd338f17e84e605a8a1 fix: fix bug #1869, DML .setFitIntercept should be set to true (#1876)
- 392dbbf3583037d46f7b03e5cdf59323b5bead42 chore: update website docs to point to correct developer API docs (#1877)
- 129abdebb384457fe07d48c591f96278b517c255 build: bump @sideway/formula from 3.0.0 to 3.0.1 in /website (#1874)
- 4d1c560d57bd25786516124924a7eb2bdaecd5a6 build: bump webpack from 5.75.0 to 5.76.1 in /website (#1870)
- 62c79d84d9999a618a596a03bab12dfad05114ce docs: Fix a typo in installation docs
- 1f63dab87586607f774d6240718a6b59f1b8546f feat: Add a new function to DMLModel, getPValue (#1863)
- 83f8260df14b15cd3260e087706aee494a1824e2 fix: Remove extraneous "Foo" type from Py codegen (#1867)
- a5bec4577b305d19131e439a80bdaba8d46b1110 fix: Allow variable size in ONNX inputs (#1851)
- 23c9b0ac7f49e2eb6c537b57490fd485b5b0e029 chore: Update pipeline.yaml for Azure Pipelines (#1866)
- dedcbdac6ba10c9782106f04900e35678821e957 docs: fix link issue in CONTRIBUTING.md (#1864)
- a7f31d552cc3d42896455d4f84810306928836d2 fix: Abstain from CodeQL for markdown-only changes (#1865)
- a5f38b1732c089330457dd3d303f0608cf466a8f Update DoubleMLEstimator test CI verification (#1862)
- a44f917d211acc1593632a710cd476e93419ea82 fix: fix style
- cc931aff41fb733473e49a533e91862f65b4e428 fix: update OpenAIEmbedding internalServiceType
- 424d586e2782593da988d3d917ca81d3ab1465bc feat: update default internal endpoint for cog services (#1859)
- e4a0e2c381fd4b0638a47981e874046f74ae6f74 docs: fix a few issues in cognitive service demo (#1861)
- 8a216cedea99f40d71a88ef9e8f3b0f6ea815abf chore: make sure nightly build has new commit
This list of changes was auto generated.
v0.11.0
1 year ago
Building production ready distributed machine learning pipelines can be a challenge for even the most seasoned researcher or engineer. We are excited to announce the release of SynapseML v0.11.0 (Previously MMLSpark), an open-source library that aims to simplify the creation of massively scalable machine learning pipelines. SynapseML unifies several existing ML Frameworks and new MSFT algorithms in a single, scalable API that’s usable across Python, R, Scala, Java, .NET, C#, and F#.
Highlights
 |
||
|---|---|---|
| ChatGPT and GPT-4 at Scale | Simple Deep Learning | LightGBM v2 |
| Intelligent chat and embeddings. Simplified Prompting APIs. | Train custom image and text classifiers with ease | Higher performance, >10x lower memory footprint, same API |
| View Notebook | Learn More | Try an example |
 |
||
|---|---|---|
| ONNX Model Hub | Causal Learning | Vowpal Wabbit v2 |
| Embed >150 state of the art deep networks into your pipelines | Discover and measure causal treatment effects | New second generation integration |
| Learn More | View Docs | Explore Samples |
New Features
General ✨
- R Support is no longer Beta! (#1586)
- Support for Spark 3.2.3
Open AI 🤖
- Add OpenAI Prompt Template support (#1843)
- Add Azure OpenAI embedding support (#1832)
- Add Azure Active Directory authentication for OpenAI (#1829)
- Add Null-value handling for OpenAI models (#1854)
Deep Learning 🕸
- Remove CNTK functionality and replace with ONNX (#1593)
- Add the
DeepTextClassifiera simple API for fine tuning a wide array of Hugging Face 🤗 text transformers using PyTorch Lightning (#1591) - Add the
DeepVisionClassifiera simple API for deep transfer learning and fine-tuning of a variety of vision backbones (#1518)
Azure Cognitive Services for Big Data 🧠
- Add
SpeakerEmotionInferencetransformer to generate emotion annotation tags for emotive reading inSpeechToText(#1691) - Add new AnalyzeText API (#1760)
- Support Azure Active Directory (AAD) authentication for the cognitive services (#1778, #1797)
- Move different cognitive services into sub packages (#1746)
- Add audiobook generation example (#1852)
- Add a notebook for advanced cognitive service usage (#1825)
- Upgrade MVAD to v1.1 (#1788)
- Remove MVAD's dependence on hardwired credentials and azure SDKs (#1629)
- Add word-level timing to
SpeechToTextSDKandConversationTranscription(#1801) - Add the
descriptionExcludesparameter to AnalyzeImage (#1590)
Causal Learning 📈
- Add the causal
DoubleMLEstimatorfor learning causal treatment effects from data (#1715) - Add a DoubleMLEstimator document and sample notebook (#1730)
- Fix DML regression bug, should remove both treatment and outcome columns as feature columns (#1820)
- Add TreatmentCol type checking (#1816)
- Update test to validate ATE value should be positive (#1821)
- Fix issue with missing causal test coverage (#1799)
LightGBM 🌳
- Add LightGBM streaming execution mode for more reliable performance with orders of magnitude less memory. (#1580)
- Add maxNumClasses param to LightGBMClassifier for multi-class (#1841)
- Added the
passThroughArgsfeature which allows users to set low level LGBM parameters before they are wrapped in SparkML (#1749)
Vowpal Wabbit 🐇
- Vowpal Wabbit v2 (#1579):
- Support Vowpal Wabbit input format using VowpalWabbitGeneric model
- Support additional algorithms & label types (multi-class, cost sensitive one against all): sample notebook
- Progressive validation (aka 1-step ahead) using VowaplWabbitGenericProgressive
- New Contextual Bandit Offline Policy Evaluation Notebook
- Data parallel training independent of cluster size
Additional Updates
Bug Fixes 🐞
- Support grayscale images in
toNDArray(#1592) - Adjust learning rate in VW example notebook (#1853)
- Correct copy/paste error in acr cleanup (#1838)
- Fix synapse test config, and isolation forest notebook (#1833)
- Add spark config to fix ArrayStoreException (#1757)
- Fix breeze NoSuchMethodError (#1807)
- Fix
modelVersionparam in TextAnalytics (#1756) - Make logging infrastructure consistent and add logging checks (#1755)
- Fix website sidebars and vulnerabilities in packages (#1753)
- Remove Vowpal Wabbit exclusion, add Interpretability exclusion (#1708)
- Update isolation forest notebook (#1696)
- Remove error on invalid columns in DropColumns (#1695)
- Fix PyArrow failure in deeplearning test (#1689)
- Fix linked service setters on cog service base class (#1685)
- KernelSHAP throws error when the key type in the ZipMap output is LongType (#1656)
- Fix flaky translate tests (#1643)
- Fix speechToTextSuite serialization Fuzzing failure (#1626)
- Fix translator endpoint and update all endpoints for gov regions (#1623)
- Finder runtime issues (#1598)
- Clean up cluster if Databricks tests pass (#1599)
- Fix deep-learning test flakiness (#1600)
- Update
DotnetTestBaseassembly version (#1601) - Fix flaky forms test (#1584)
- Fix namespace import for Experimental (#1780)
Build 🏭
- Automate cleanup of Azure Container Registry images (#1787, #1751, #1735, #1814)
- Add bot to remove stale issues (#1602)
- Return values from TaskKeys (#1775)
- Remove unnecessary SbtPlugin settings (#1771)
- Simplify E2E test pipeline with a test matrix
- Add welcome message to new PRs/Issues (#1573, #1583)
- Add workflow to label new and reopened issues (#1571)
- Add a secret scanner (#1724)
- Add workflow to open GitHub issues after a comment (#1676)
- Add workflow to remove awaiting-response issue label on comment (#1674)
- Publish test jars so downstream projects can depend on test configurations and utilities
- Making build secrets optional and cached to remove 1 min latency on sbt commands (#1726)
- Add nightly build to catch flakes early (#1774)
- Automatically delete accumulated models in build (#1758, #1729, #1759)
- Add Dependabot for updating GitHub actions (#1608)
- Update build pipeline to ubuntu 20.04 (#1624)
Documentation 📘
- Add a hyperparameter tuning sample with HyperOpt (#1828)
- Add docs for new LightGBM
executionModeparameter (#1779) - Add additional ONNX docs for model hub and slicing (#1781)
- Improve OpenAI notebook (#1596)
- Add dotnet installation & examples (#1567, #1570)
- Update deep vision docs (#1752)
- Add custom search engine creation video to website (#1581)
- Replace Boston housing dataset with California housing dataset (#1856)
- Improve overview section in README
- Fix typo in old versions of Interpretability - Explanation Dashboard.md (#1846)
- Add versioned docs (#1858, #1566)
- Fix Synapse installation instructions for Spark 3.2 (#1815)
- Update required spark and python version on website doc (#1812)
- Fix latex rendering issue in Data Balance Analysis (#1796)
- Fix Acrolinx issues (#1792, #1793, #1808, #1794)
- Pin binder to latest released version
- Improve python env creation instructions in developer readme (#1693)
- Remove unused docs and fix links
- Improve example notebooks
- fix command to launch Jupyter notebook (#1649)
- Add documentation for MLFlow logging and loading (#1641)
- Update spark version in Readme
- Fix .NET logo on website (#1604)
- Update v0.10.0 installation guidance (#1578)
Maintenance 🔧
- Bump spark to 3.2.3 (#1744)
- Update Scalatest and Scalactic dependencies (#1706)
- Keep GitHub actions up to date (#1839, #1766, #1737, #1680, #1688, #1777, #1773, #1770, #1786, #1610, #1611, #1612)
- Keep website up to date (#1826, #1809, #1785, #1719, #1709, #1609, #1740)
- Update container registry and service principal connections
- Maintain Synapse tests (#1835, #1823, #1810, #1803, #1658)
- Fix codecov.yaml
- Fix conda env creation flakiness in build (#1748)
- Bump SynapseML Version (#1857, #1738, #1628)
- Improve code style (#1736, #1716, #1790)
- Pin az and python versions in build (#1705)
- Fix ado issue linker configurations (#1704)
- Add
synapse-internalto platform detector function (#1651) - Update OpenAI service to official deployment (#1619)
- Pin binder version (#1607)
Deprecations and Removals 🗑️
- Deprecate old TextAnalytics APIs (#1627)
- Remove old TextAnalytics APIs (#1622)
- Remove deprecated LIME APIs (#1620)
- Deprecate CNTK classes and ModelDownloader (#1712)
- Delete CNTK and related utils (#1743)
- Move ImageFeaturizer to
onnxnamespace (#1711)
Testing 💚
- Add Additional E2E testing infrastructure (#1727, #1769)
- Improve ONNX test reliability (#1713)
- Stabilize flaky tests (#1576, #1842)
- Remove Synapse E2E test exclusions (#1757, #1699, #1798, #1698, #1837)
- Add automated tests for getters and setters and improve test coverage (#1631)
Contributor Spotlight
We are excited to highlight the contributions of the following SynapseML contributors:
 |
 |
 |
|---|---|---|
| Scott Votaw | Serena Ruan | Haizhou (Dylan) Wang |
| Scott Votaw is a Principal Engineer on the SynapseML team has solved some of SynapseML’s toughest challenges in record time. In this release, Scott contributed both the new LightGBM streaming execution mode, and fully replaced our deep learning stack with the ONNX Runtime. These efforts were massive lifts including huge changes to the LightGBM native libraries and complex dependency management jujitsu respectively. Scott brings his love for the craft to every project he works on so keep your eyes peeled for more amazing feats of engineering from him in future releases. | Serena is a Software Engineer II on the SynapseML team and operates on a separate plane of existence than the rest of us mere mortals. Following up on prior major contributions like .NET support, form recognition, translation, and creating the SynapseML Website, Serena contributed the Simple Deep Learning package for this release. This package makes it easy to train modern deep text and vision networks from Hugging Face and torchvision on Spark clusters. Serena seeks only the most difficult engineering challenges and her contributions have laid the groundwork for many more deep-learning based algorithms in SynapseML. | Haizhou (Dylan) is a Senior Software engineer in the CSX Data team and a first-time contributor to the SynapseML library. Dylan contributed the new SynapseML causal learning package for the v0.11 release. This package helps users discover the effectiveness of things like medical treatments or economic policies even without controlled experiments. With his elegant contributions, Dylan has laid the foundation for more causal collaborations with the EconML library. |
 |
 |
 |
| Markus Cozowicz | Brendan Walsh | Jessica Wang |
| Markus is a Principal Applied Scientist who (just!) joined the SynapseML team. Despite only recently coming on board officially, Markus has long been a prolific contributor to the library and built the Vowpal Wabbit and Isolation Forest integrations. In this release, Markus contributed the second generation of the Vowpal Wabbit integration, improving its generality and applicability. He also expanded the OpenAI integration to support embeddings and simplified prompt templating. Our team is incredibly lucky to have such a consistent and thoughtful collaborator. | Brendan is a Senior Engineer on the SynapseML team who recently joined after a long tenure on the Cognitive Services team where he developed their containerized cognitive service effort and co-authored the SynapseML publication on large-scale microservices. Brendan used this expertise to onboard Emotion Detection for text to speech models. He then went on to use this new emotive reading capability to create and donate thousands of audiobooks to the open source. You can learn more about Brendan’s awesome technical philanthropy efforts at https://aka.ms/audiobook. | Jessica is Software Engineer who recently joined the SynapseML team. Already, Jessica has grown into the role of the SynapseML benevolent “doc”tator. This release Jessica has worked hard to ensure that the SynapseML notebooks work across a wide variety of Spark platforms and are easy and simple to get started with. This work requires knowledge of the entire library’s surface area, and we are thankful Jessica has worked so hard to learn this breadth of content. If you have been following notebook examples from https://aka.ms/spark you have Jessica to thank! |
 |
 |
 |
| Kyle Rush | Avrilia Floratou | Jason Wang |
| Kyle is a Senior Software Engineer on the SynapseML team with a penchant for architecture and a streak of taking on big responsibility behind the scenes. Kyle has been instrumental in expanding our testing infrastructure to new platforms so that the lights stay on even as the number of contributions increases. This often requires nontrivial code and delicate cross-team collaboration, and Kyle has both the engineering might and the charismatic finesse to make sure these systems can be spun up successfully. | Avrilia is Principal Scientist Manager in the Grey Systems Lab, first-time SynapseML contributor, and a delightful collaborator. This release, Avrilia contributed the first prototype of the simplified OpenAI prompting transformer. This contribution makes it easy to ask ChatGPT and other LLMs questions about large datasets and to create new LLM-derived columns in databases. You can learn more about her work through the OpenAI Docs and prompting demo | Jason Wang is a Principal Software Engineering on the CSX Data team and has a long history of not only contributing huge features to SynapseML, but actively maintaining his contributions. This release, Jason’s work on the ONNX model hub protocol enables quick access to over >150 pretrained deep networks from the Java and Scala ecosystems. Jason has also been instrumental in fixing the most difficult and arduous bugs, some even stemming from the core Spark runtime. Finally, we deeply appreciate Jason’s leadership in the community: he consistently encourages and helps others contribute, and his impact extends far beyond his own personal contributions. |
Acknowledgements
We would like to acknowledge the developers and contributors, both internal and external, who helped create this version of SynapseML
Eric Dettinger, Markus Weimer, Serena Ruan @serena-ruan, Scott Votaw @svotaw, Haizhou (Dylan) Wang @dylanw-oss, Puneet Pruthi @ppruthi, Markus Cozowicz @eisber, Brendan Walsh @BrendanWalsh, Jessica Wang @JessicaXYWang, Kyle Rush @k-rush, Avrilia Floratou, Jason Wang @memoryz, Mark Niehaus @niehaus59, Keerthi Yanda @KeerthiYandaOS, Ilya Matiach @imatiach-msft, Kashyap Patel @ms-kashyap, Martha Laguna @martthalch @marthalc, Sarah Shy @sarahshy, @ocworld, @adityakode, @nightscape, Alexandra Savelieva @alsavelv, Tom Finley, Jeff Zheng, James Verbus @jverbus, Chris Hoder, Misha Desai, Nellie Gustafsson, Eren Orbey, Beverly Kodhek, Louise Han @jr-MS, Raj Rikhy, Marcos Campos, Mike Estee, Brice Chung, Justyna Lucznik, Kim Manis, Mitrabhanu Mohanty, Bogdan Crivet, Anand Raman, William T. Freeman, Akshaya Annavajhala (AK), Guolin Ke, Spark.NET Team, ONNX Team, Azure Global, Vowpal Wabbit Team, LightGBM Team, MSFT Garage Team, MSR Outreach Team, Speech SDK Team, MLflow Team
Learn More





Changes:
- 7b23764a93e73eab9c8903cb5f37e2438caedce0 docs: make v0.11.0 docs (#1858)
- 795bbecf5d1c803c549e78a0a940f5d7ef607127 docs: Add audiobook generation example (#1852)
- 8f9e970dd5df96db28a64b45687bf7e17adb8dd8 chore: bump version to 0.11.0 (#1857)
- 09648a32308f055d0cecf63eda2f82a2d2914d4c docs: replace Boston housing dataset with California housing dataset (#1856)
- 2b2419f1458634208b7127c557dc98717ce0b455 fix: OpenAI completion & prompting null handling (#1854)
- 66f30e30dfbcb8295ab29fe27b6e2501e87d5ac8 fix: adjust learning rate in VW example notebook (#1853)
- d64563f8efcb55a855d48ddea066ee361722ba5a chore: Upgrading ONNX version to fix assembly bug (#1849)
- a64b6e09e9c7e96f62ae8fd9a72663f66474d1a9 chore: fix mcr connection
- d23dd46e87cf0688c46c1ebedae1a4a7048186a2 chore: update build service principal
- 6876d53a95d71dc5c1fe66650d3f7b72b839fca1 chore: Update the build pipeline
See More
- c1aa5a542e26d84912cf93b8780d62d8952cad01 docs: Fix type in old version of Interpretability - Explanation Dashboard.md (#1846)
- 48f9c4c46e2a80d81639bcfcb1fb374e038e4de0 feat: OpenAI Prompt Template support (#1843)
- fbbb4336d12fe1d3124295aa3c42f16d522d133e chore: fix form recognition tests (#1842)
- b90425c41cbff7451c1bece19b59b254660c5b7b build: bump amannn/action-semantic-pull-request from 5.0.2 to 5.1.0 (#1839)
- 31c4ea34bea59d8456d29f2791117ee3ef1a5627 fix: correct copy/paste error in acr cleanup (#1838)
- c99796f955692f041a707e729216be05eeae9e02 feat: add maxNumClasses param to LightGBMClassifier for multi-class (#1841)
- eb0bbe335ffdb00e58dd89947f0542e9a602ba31 fix: modify synapse test config, modify isolation forest notebook for testing (#1833)
- 8af5112d33f5de24f97f5d8f59fd9d403e412bd6 docs: remove hyperOpt exclusion - mlflow on synapse (#1837)
- d66796d7c743d63e9e0b2bd1b45874f448b61aff build: bump http-cache-semantics from 4.1.0 to 4.1.1 in /website (#1826)
- 7038e1da31f9ef48f119a7805110ea190155f97c feat: add Azure OpenAI embedding support (#1832)
- 6c6d89b54a595718a149e8accc9de3b311fadb22 chore: turn off failing synapse tests (#1835)
- eb355817285564bd062eb6deab9755146ba00157 docs: add hyperopt sample (#1828)
- 2262a9bf5d3db651f9d87cd2a3849e1154d600ad feat: add aad auth for openAI (#1829)
- a7e20ce39d479a680da5811f6fa04975e0b407c0 docs: Add a notebook for advanced cognitive service usage (#1825)
- 3eed94c205629764119ec1ba04b93f426c201cd8 test: Update test to validate ATE value should be positive with the test data (#1821)
- 8aa4ae17dc9e6e45fa53047f9827edc5beb2b8ac chore: re-enable E2E tests for Synapse-Extension (#1823)
- 1dcb5881235994c42ad88aafdfffebeb9ae29ea4 docs: update spark3.2 installation on Synapse (#1815)
- e36643f1a71e39b0c6bfe6c53935b857453dcd61 fix: Fix DML regression bug, should remove both treatment and outcome columns as feature columns (#1820)
- 4ef8e30167a304ecd2a58dbf4a443d91e062d8ad fix: Add spark config to fix ArrayStoreException in Synapse - Add back HyperparameterTuning nbs to test pipeline (#1757)
- eb403728f9162565fd3ec124012ed671b92447e0 fix: Add TreatmentCol Type check at the very beginning (#1816)
- af0a218bcc9b03d9b677ba7b6978a09fc64ba46b docs: update required spark and python version on website doc (#1812)
- e0c5364df052e6e896e01e5a3e971876771a7170 build: bump ua-parser-js from 0.7.31 to 0.7.33 in /website (#1809)
- e212f5df2f3c1da89409f3214a4d5c82dc1f135f chore: add retry to commands (#1814)
- bd1e0a61f3fc0dc109702e613d21eadd04c56565 fix: breeze NoSuchMethodError (#1807)
- 13ff3467fd0778761463ed3ebfa652e07dc5ad1c chore: Disable synapse-extension tests, add params to pipeline (#1810)
- 4c8d2e972f1bfb33efc6aced2b8a9a542de119ec doc: apply diffs from website/docs to website/versioned_docs (#1808)
- 7d8d6fd634bee190520853ebf69f6e62b5ac15b7 replicating the unit test data (#1806)
- fb47138d7e881ecb654d5d039893e63bb13abce9 docs: DoubleMLEstimator document and sample notebook (#1730)
- 8ba77e4eea742c4728a662ba68a660db6c974054 build: Return values from TaskKeys (#1775)
- 94ed68512d41434af28f26097dbe2ebef5c1643c chore: disable Interpretability tests (#1803)
- 54e7ac6143fc25ed2300e85fddb4e3ce21922e84 feat: add setting for getting word level timing information from SpeechToText (#1801)
- d8d523c6ba603d62744b06608265bb5bfbdad8df feat: annual Vowpal Wabbit improvements (#1579)
- 01e31dc69102694cbd05be1757c69b20efc13651 test: fix issue with missing causal tests (#1799)
- 9d92349ac6805321838eee0a9e6ca8407cdbf16f test: remove interpretability exclusion (#1798)
- d308dc4497abba715f245f4e1c3cb130968d26d2 refactor: enhancement to aad token (#1797)
- 333dedbdc8342ed2e73df29821c5a8912f3e58fd feat: upgrade MVAD to v1.1 (#1788)
- 54a749638c3383fc0609bed86af088d5d960223a chore: fix typo in chron build def
- c653ed77a13d7d99238c52ceb6aa4c4a6290ea3a docs: Clean latex - Data Balance Analysis (#1796)
- 76e7b73954cc1dc0da9e6c7022a42ed8a873329a chore: linx fixes for README and features (#1794)
- fc3a7a6a1485b2b3229a76648c2836d6c4fe4f53 chore: Re-enable e2e tests, add cron schedule to build definition (#1774)
- a95fad403184ae4fa4b886c28b2ea072b4344373 docs: Add docs for LightGBM execution mode (#1779)
- 44bcbf1fdcf5be829a46688ddc7e9cba06f98f13 improve documentation - bug, typo, correctness (#1791)
- 77da4b40822a5e40afdbe5a6956666ffc9a0068f chore: acrolinx fixes for reference, mlflow and getting_started in 0.10.2 (#1793)
- 8cc6a16a0e30cf6d8e58cb64f209c738931b9adf docs: mollify acrolinx (#1792)
- 974e36aaad0714a3e9ca83caa6a1130fb51f249a docs: Added more up-to-date ONNX docs (#1781)
- dc57deaf43010c91a181abe42776d43426f2e0cc feat: add aad authentication support for cognitive services (#1778)
- dd1563fc3004143c120de3b58d77d4f66338b8a2 build: bump json5 from 2.2.1 to 2.2.3 in /website (#1785)
- 3d8c84d7ffbe246a1e7651f75c0347b07fc5becd chore: fix style (#1790)
- 53788bd94cf0cc4badaaa91651b02221d297cf69 fix: small tweaks to clean_acr (#1787)
- 851efdc98de7c61480912c14bf192ad222c41b97 build: bump actions/upload-artifact from 3.1.1 to 3.1.2 (#1786)
- 9978c3b760b88839f0d5f574c159d7ed96323994 build: bump ossf/scorecard-action from 2.1.1 to 2.1.2 (#1777)
- 421e3fe3c09f7871db80f588654ef587d47adcea Fix: fix annamespace import for Experimental (#1780)
- 8dc4a582bb3e3f9c477583e850b76ddd4254973d build: bump ossf/scorecard-action from 2.1.0 to 2.1.1 (#1773)
- 61435147a64a52680152b3e55275a139a8b6b787 build: Remove unnecessary SbtPlugin settings (#1771)
- de21adaa9408df0ec566711f6ccd9fb1bc3ac903 chore: disable synapse-internal tests
- d0a9f20df0f753c93ad459cd401197165b64be96 feat: Causal DoubleMLEstimator (#8) (#1715)
- 7ab63a14ac1a9f14174b16b1be88ea99a94b5db4 fix: Update synapse-extension test environment, enable cleanup of old arti… (#1769)
- be02bf78b4ab3b789f6cc773cf71653acc8e0933 build: bump ossf/scorecard-action from 2.0.6 to 2.1.0 (#1770)
- 0bf4772ec35b0cd9b91d7da0c97d2fb1ad193cd1 build: bump actions/upload-artifact from 3.1.0 to 3.1.1 (#1766)
- bb6e37b956c62378b13cebeed0b63b2916e4a98c Update codeql.yml (#1765)
- 8a30fd482b9f564ff96277d712f1ec856a1c00cc Create codacy.yml
- d9810b157d68f22bda50b4dbfd271514e49a812a Create codeql.yml
- 630a442c1fcf7556e3514fd91dd8bf6d88a502ab Create scorecards.yml
- 7785cb5e15fe17b51d3610d95f045de5e0a72d26 feat: add new AnalyzeText API (#1760)
- cf14041be1e17e030af18fa1eb2afc96623e3e65 chore: delete old models before tests rather than after (#1759)
- 9e32a99b40151136d4af0c2bbb1ffba8865f45a1 fix: fix failing SpeakerEmotionInferenceSuite
- 4a2595461fb1d68609ec74ce4f7d33e58095452e fix: delete too many anomaly models (#1758)
- adad80d4454dd4fab4aacc93fa34e2aefb5ff75b chore: remove cntk and downloader tests from build
- 046689d9666c334aa0e11a603882afc62c8d1775 chore: fix codecov.yaml
- 3a3be327d0022d3181ac22ea90c9b6b2b5beae92 feat: Add LightGBM streaming execution mode (#1580)
- b205cc47b0e43ddcd1a947246bd568fbbe897630 fix: fix modelVersion param in TextAnalytics (#1756)
- b797d6c2ec9cea652ba01fcc03ca91baed413b76 fix: make logging infrastructure consistent and add logging checks (#1755)
- 557470bcec78acba3adcd9524337be628446311a fix: fix website sidebars and vulnerabilities in packages (#1753)
- 9c98609a23bb82f4bfeb2bcabf0b7c9840061691 docs: update deepvision docs on website (#1752)
- 629da631a263e46fbccd98d2026c73291087a46b refactor: move different cognitive services into sub packages (#1746)
- 37f2e90dd948419a7b31ec1bcbafb079f7fdb9ea chore: fix clean acr (#1751)
- c6cc0a88a14fbbce6296200d1d0b258cd4220c5f fix: Add docs for passThroughArgs (#1749)
- b6ef511ab10ca8101d7637cbd912b0efdabfb9fa docs: Pinning binder to latest released version
- 2a89e13870b136ffcfa5262956878bcfe8c6e578 feat: Delete CNTKand related utils (#1743)
- 98add7a4b2c260660d4b92dabd9d5a8ee4bd67d4 chore: fix conda env creation (#1748)
- 558f5d887302cb9b2af48d3a373002bba292eeb9 chore: bump spark to 3.2.3 (#1744)
- 70843d5c13d995742c277ae13b015b85c348e0a8 chore: bump docusaurus (#1740)
- 2d06b94683282770f126176e2a7ab9be1dd5db80 build: bump loader-utils from 2.0.3 to 2.0.4 in /website (#1719)
- aa69541cd290301eedcd7f0e386498d22ea99b0d docs: removing beta tag from R
This list of changes was auto generated.
v0.10.2
1 year agov0.10.2
Bug Fixes 🐞
- remove Vowpal Wabbit exclusion, add Interpretability exclusion (#1708)
- remove synapse E2E testing exclusion - cyber ml (#1699)
- update isolation forest notebook (#1696)
- don't throw on invalid columns in DropColumns (#1695)
- fix pyarrow failure in deeplearning test (#1689)
- fix linked service on cog service base (#1685)
- fix Uplift Modelling style
- KernelSHAP throws error when the key type in the ZipMap output is LongType (#1656)
- fix flaky translate tests (#1643)
- update ubuntu to 20.04 in pipeline (#1624)
Build 🏭
- bump actions/checkout from 2 to 3 (#1737)
- bump loader-utils from 2.0.2 to 2.0.3 in /website (#1709)
- bump amannn/action-semantic-pull-request from 5.0.1 to 5.0.2 (#1688)
- bump amannn/action-semantic-pull-request from 4 to 5.0.1 (#1680)
Documentation 📘
- update developer readme instruction on python env creation (#1693)
- fix multiple typos and update error hintings in ai-samples-timeseries notebook (#1663)
- improve error msg to make it clearer for users and fix typos (#1662)
- simplify data downloading and add mlflow to uplift modelling (#1659)
- move magic command forward since it restarts interpreter
- remove unused docs and fix links
- improve example notebooks
- add aisample uplift modelling (#1640)
- fix command to launch jupyter notebook (#1649)
- add mlflow in ai samples time series forecasting (#1645)
- add mlflow logging and loading (#1641)
- update spark version in Readme
- improve readme overview
- add aisample on text classification (#1617)
Features 🌈
- add simple deep learning text classifier (#1591)
- Add SpeakerEmotionInference transformer for generating SSML t… (#1691)
- Deprecate CNTK objects (#1712)
- Remove CNTK functionality and replace with ONNX (#1593)
- R test generation (#1586)
Maintenance 🔧
- bump version to 0.10.2 (#1738)
- fix style (#1736)
- automate clean-acr with github action workflow (#1735)
- autodelete old models (#1729)
- Making secrets optional and cached (#1726)
- add secret scanning infrastructure (#1724)
- Move new ImageFeaturizer to onnx namespace (#1711)
- ScalaStyle fixes (#1716)
- update scalatest and scalactic (#1706)
- remove synapse test exclusions (#1698)
- pin az and python versions (#1705)
- fix ado integration (#1704)
- remove notebooks (#1703)
- fix reopen comment action
- fix reopen on comment workflow
- fix typo in issue reopen yaml
- re open github issues after a comment (#1676)
- clean up github workflows and add issue label remover (#1674)
- turn off failing synapse tests temporarily (#1658)
- added
synapse-internalto platform detector function (#1651) - publish test jars
- improve test coverage (#1631)
- Remove MVAD's dependence on hardwired credentials and azure SDKs (#1629)
- clean up TextAnalytics cog service APIs (#1622)
Testing 💚
Acknowledgements
We would like to acknowledge the developers and contributors, both internal and external who helped create this version of SynapseML.\n
Changes:
- cd1d2ea65ffcd0f89bf1fee231c430560508bcce chore: bump version to 0.10.2 (#1738)
- fd78889112b8d48927ddac1b660f62400bb1ba12 build: bump actions/checkout from 2 to 3 (#1737)
- c806ba79d17afa6edf53c9ea55e563f6842a6825 chore: fix style (#1736)
- e6b5a90352b7456333df92dc9f7755b6cb8f300b feat: add simple deep learning text classifier (#1591)
- 1de2d558996fed8ff12a312a52d53c39c3322fcb chore: automate clean-acr with github action workflow (#1735)
- 952d1bd3e0a4b7755d8aa3d069ff90ff626c7b17 clarify date comparisons when deleting old models/groups (#1733)
- 6ea02bd81ef09647119f4c36583f3a523dd7c795 chore: autodelete old models (#1729)
- 8b02e1d31751eef8b01b87ee590f1b3169e6371a chore: Making secrets optional and cached (#1726)
- c62c6ad441c18d98354099dbd39448d4b0734c58 test: Additional E2E testing infrastructure (#1727)
- aeb2ff7ecde6180fc546e2596d8121c71be49505 feat: Add SpeakerEmotionInference transformer for generating SSML t… (#1691)
See More
- 0b96cc5bd5b26b677f2bd1ff7371c631c3984ee4 chore: add secret scanning infrastructure (#1724)
- 2a7a67ba373d3dd69c7ac4cd2f4118d1980eac06 feat: Deprecate CNTK objects (#1712)
- e38e3ad30c6bb10cbafa4351974aea8c2b8ebf37 chore: Move new ImageFeaturizer to onnx namespace (#1711)
- 0ff6802377328cb8875f7c60305da77074fa1771 test: Improve ONNXtests reliability (#1713)
- fe4c5d27a8d35aa90c5a70383b028de652247d48 chore: ScalaStyle fixes (#1716)
- 050b541e8b74c09d63abfdb2ad05d7582bd06f29 build: bump loader-utils from 2.0.2 to 2.0.3 in /website (#1709)
- f2e88fdea7c1010118913eecf0457b5daf881d25 feat: Remove CNTK functionality and replace with ONNX (#1593)
- abdfe19e79ca0533c168366aca96b8082a44a8db fix: remove Vowpal Wabbit exclusion, add Interpretability exclusion (#1708)
- 6a1f994812234ba861bcae0c96fb11f185eec261 chore: update scalatest and scalactic (#1706)
- 144674fdb9537e6dbad2817dee95d8c26eaf3fa5 chore: remove synapse test exclusions (#1698)
- 32c654b83781c6e028fdd23be47e083d1decb8e7 chore: pin az and python versions (#1705)
- c8fba2831d34338b5c82079a77b77963ceab32b6 chore: fix ado integration (#1704)
- 92d409574376a1570ab49cc82a60c7efbc9fd1de chore: remove notebooks (#1703)
- a9537809d877be4c2eec83b9a55c46a942026d41 fix: remove synapse E2E testing exclusion - cyber ml (#1699)
- b257c70562b312e03ca8fb566d71582601725800 fix: update isolation forest notebook (#1696)
- 9120b056920b54647b75c2c640a8e9e87c919969 using predictionCol for isolation forest (#1686) [ #1060 ]
- 448f6b7ca81d0e806e06410a5035bd5edff2ad6e Remove trident.mlflow APIs. (#1687)
- f4af33f719844d419083e6204bb58ee14b6de133 fix: don't throw on invalid columns in DropColumns (#1695)
- c531bbbfc93ccee3a3cc167060411941d3635e1b docs: update developer readme instruction on python env creation (#1693)
- 467e651dd814213bbfe4c13e5bc1b6dac7fd86ee build: bump amannn/action-semantic-pull-request from 5.0.1 to 5.0.2 (#1688)
- 302831ffd8cec84f0e24de6eef4c193d3ed0966a fix: fix pyarrow failure in deeplearning test (#1689)
- e857511e21e471829048650955823ecfe8e1e89d fix: fix linked service on cog service base (#1685)
- f29318a274610dda543ee1422bdbd74cdb6a752a build: bump amannn/action-semantic-pull-request from 4 to 5.0.1 (#1680)
- 50ac0c8aa7149637396700b8ccf16a422eb732ed Update reopen-issue-on-comment.yml
- c9278b5c1c2225c6b0f48bcd21996a1a584cd1f9 chore: fix reopen comment action
- b3a9ba9ca84e7af257664f81858301c9af03fc61 chore: fix reopen on comment workflow
- 9fe273b8665d9c70b5f0375a9b8e603d65143874 chore: fix typo in issue reopen yaml
- a7c50de2e905b55d64be9fdc413f012fdaecfb27 chore: re open github issues after a comment (#1676)
- 8914750ac804fe9072b327e4cecfc6c382cd52f2 chore: clean up github workflows and add issue label remover (#1674)
- 965231a98c7bc32151dc93f6c1a399c4b6ba4c76 docs: fix multiple typos and update error hintings in ai-samples-timeseries notebook (#1663)
- 4fa7249966386fdc86edb99ea1ea665ef1643c94 docs: improve error msg to make it clearer for users and fix typos (#1662)
- dd9e5d24a570f5735c2e048b35d0fb06aa887000 fix: fix Uplift Modelling style
- 5a52aef842eaeb36796fc4fc825e9198c371229f docs: simplify data downloading and add mlflow to uplift modelling (#1659)
- 95f451ab3f1b13d635c69b797f153610c2902ea4 chore: turn off failing synapse tests temporarily (#1658)
- 76d73826de969c36a3e71f884bf0dd7258beb7f0 fix: KernelSHAP throws error when the key type in the ZipMap output is LongType (#1656)
- e703ad4605e387e711de4e0ee3d9919d57e46674 chore: added
synapse-internalto platform detector function (#1651) - ca358e369a20fdbbfc43339cb0fb09d481cfe16a docs: move magic command forward since it restarts interpreter
- 3a160b395dae8d7d3af528b4d6180dc4d7737dd6 docs: remove unused docs and fix links
- d5a499720a4cd7a536ac755fbe1af2f355a27bc1 docs: improve example notebooks
- a7d097a7057d4363a5de4d1b9173867df60522b2 chore: publish test jars
- b7c8cf10b7b70fd90f45fe0e81a4bf7d8b58b4eb docs: add aisample uplift modelling (#1640)
- c8750ce83a6884ddb7503c361c53c6d67fab86e8 docs: fix command to launch jupyter notebook (#1649)
- 8d552746951ab4190e82dda1d4f04699fc46c69f docs: add mlflow in ai samples time series forecasting (#1645)
- d751a52b7e61d460bac15b01d5f2680274cbde77 fix: fix flaky translate tests (#1643)
- 59a922b4c7aa73f4a1f540b9f17ecc8f46c55a86 docs: add mlflow logging and loading (#1641)
- 4115d4f0f2ea5210b9eafd777ff7dc6f4567a7fb Create .acrolinx-config.edn
- 64fecca3f51ec6df6753edde0fba23ab87127a3e docs: update spark version in Readme
- 32037ecf357917d4270d7a2e7deec7074be91c4b docs: improve readme overview
- 289bd974275a7df6c0dfc79fb9a20156a14c3c7e remove extra packages installation in pythontests (#1633)
- 4878686cf58696bc276f810912f7a8667a2bcff0 feat: R test generation (#1586)
- 1381db524e9a48ba2d0463d7c1bfb8b057c9fc61 chore: improve test coverage (#1631)
- e700fd146a3c19aefac442b5f91f2b27600da938 chore: Remove MVAD's dependence on hardwired credentials and azure SDKs (#1629)
- d5ee8e747aeb0edc42a9c1e6b448503717bb1b1c fix: update ubuntu to 20.04 in pipeline (#1624)
- dbbe6814c6f82793f549cf798bce16a06b4abcc6 chore: clean up TextAnalytics cog service APIs (#1622)
- d98ac02c989492307e924f286cd5a7f3be767241 docs: add aisample on text classification (#1617)
This list of changes was auto generated.
v0.10.1
1 year agoSynapseML v0.10.1
Bug Fixes 🐞
- fix speechToTextSuite serializationFuzzing failure (#1626)
- fix translator endpoint and update all endpoints for gov regions (#1623)
- binder runtime issues (#1598)
- clean up cluster if databricks tests pass (#1599)
- fix deep-learning test flakiness (#1600)
- update dotnetTestBase assembly version (#1601)
- fix flaky forms test (#1584)
Build 🏭
- bump EnricoMi/publish-unit-test-result-action from 1 to 2 (#1609)
- bump actions/setup-node from 2 to 3 (#1610)
- bump actions/setup-python from 2.3.2 to 4.2.0 (#1611)
- bump actions/setup-java from 2 to 3 (#1612)
- simplify e2e test pipeline with test matrix
Documentation 📘
- add aisample notebooks into community folder (#1606)
- add aisample time series forecasting (#1614)
- fix .NET logo on website (#1604)
- improve OpenAI notebook (#1596)
- pin mybinder to v0.10.0 to avoid thrashing
- add demo into videos on website (#1581)
- update installation guidance of v0.10.0 (#1578)
- add more .net samples (#1570)
- add dotnet installation & example doc (#1567)
- Update issue template
Features 🌈
- add stale bot for issues (#1602)
- Support grayscale images in
toNDArray(#1592) - Add the
descriptionExcludesparameter to AnalyzeImage (#1590) - Added the
DeepVisionClassifiera simple API for deep transfer learning and fine-tuning of a variety of vision backbones (#1518)
Maintenance 🔧
- bump to v0.10.1 (#1628)
- deprecate old Text analytics APIs to prepare for refactoring (#1627)
- remove deprecated lime APIs (#1620)
- update openai service to the official deployment, and disable test due to outage (#1619)
- Auto update GitHub actions with dependabot (#1608)
- hotfix binder badge
- pin binder version for users (#1607)
- Bump spark to 3.2.2
- bump spark version
- Format welcome message with emojis (#1583)
- Add welcome message to new PRs/Issues (#1573)
- Add GH workflow to label new/reopened issues (#1571)
- update website (#1566)
Testing 💚
- stabilize unit tests (#1576)
Acknowledgements
We would like to acknowledge the developers and contributors, both internal and external who helped create this version of SynapseML.\n
Changes:
- 0f54bc65e720ac89f1d4c04502bc2cb5c6310db7 chore: bump to v0.10.1 (#1628)
- 3d0f3f466afde7f69d91cdf27a97e629ac6dad91 chore: deprecate old Text analytics APIs to prepare for refactor (#1627)
- 2052e13b82f6ccc94848359f8070f24d5f06de6c chore: remove deprecated lime APIs (#1620)
- 09213b010e658833148026d242268e2eb0482b17 fix: fix speechToTextSuite serializationFuzzing failure (#1626)
- 9f78bf0074ebf3668fb7e1d5d18a681ec236f988 fix: fix translator endpoint and update all endpoints for gov regions (#1623)
- 7e90d190bd3f96869fe176c4eefe2bc417fe34fe docs: add aisample notebooks into community folder (#1606)
- ac40e5af5d2a7bd1f6c0a25b12b2e07e6ff92c2e chore: update openai service to official, and disable test due to outage (#1619)
- f54f7f68a4cb6596af5975d4caa20ea0ead798b2 docs: add aisample time series forecasting (#1614)
- 7b4b0e1c066e1ec7c3bff719e12b991d8193a25e build: bump EnricoMi/publish-unit-test-result-action from 1 to 2 (#1609)
- 43b0d1714954b1d160d1e0a11c64a52226d6825a build: bump actions/setup-node from 2 to 3 (#1610)
See More
- c48a07a97493269799571c0df8a06654c414c247 build: bump actions/setup-python from 2.3.2 to 4.2.0 (#1611)
- b1a331c3c61fd89c147e2b0be65b9b23056eba9b build: bump actions/setup-java from 2 to 3 (#1612)
- 78e40cb37cab655d6d94b4df8690d1302154d019 chore: Auto update github actions with dependabot (#1608)
- 69d2d202439187f862bee59cac93b99e19ce0a4d chore: hotfix binder badge
- 93d7ccf7a782d89ac157d6e1c87ea3f55d11b886 chore: pin binder version for users (#1607)
- c7a61ecd57f9962590be3a075f586578a7fa3e13 fix: binder runtime issues (#1598)
- c960c06b8534e6b0013f4b2107d262fd4be62472 docs: fix .NET logo on website (#1604)
- 28a35b43ea7685e2e70ffc84c1bd39c6f7866176 fix: clean up cluster if databricks tests pass (#1599)
- 5a28740881a7298d783ed922b7746b7fc3d7c77b fix: fix deep-learning test flakiness (#1600)
- adf1a61d19a4493a39b063dc2abddc16a8b1bbe6 fix: update dotnetTestBase assembly version (#1601)
- c659b330342cdde38340b2c488d4b9bc8b2df58b feat: add stale bot for issues (#1602)
- 05a420257c25167c300a9a7c6e13f5674e4fba9a docs: improve OpenAI notebook (#1596)
- e019756ae7534cc1cdf81a8b24f8224b92855bdc feat: Support gray scale images in
toNDArray(#1592) - 51beaa0e462d5f7edc5f32242e0a7b8cc91b3ab5 feat: Add the
descriptionExcludesparameter to AnalyzeImage (#1590) - b9ac22a544a1398cd77e00dd10f0796f729eaf4c docs: pin mybinder to v0.10.0 to avoid thrashing
- 1808a0f452ffab9ee24063b1e6c16ef5ed06f95d chore: Bump spark to 3.2.2
- 8e7d4533e7f2c54da35438eb6561e47ee9269197 build: simplify e2e test pipeline with test matrix
- 8e34c7ba56687c2d92f601c5bbf1475cbad68584 chore: bump spark version
- 44c8ed5239dd7b7f43295865ff5b0caa87d40ab6 feat: Added the
DeepVisionClassifiera simple API for deep transfer learning and fine-tuning of a variety of vision backbones (#1518) - e4f0883740b970430cbbb5781431206b788caa49 fix: fix flaky forms test (#1584)
- 7da5f49d3161c2a2809f3dce5d117d9ec7903eb5 chore: Format welcome message with emojis (#1583)
- 0e6bb3557aff7314fd791bd40d8dccaaed7c5093 Serena/update issue template (#1582)
- a6a271860889dcc0b81bb8c5915bc35f31b866f3 docs: add demo into videos on website (#1581)
- 7c34fc4332443bff1d4e0f8c7a696f1c94d71977 test: stabilize unit tests (#1576)
- 49f3a58f9853421f832b6c50bf459d92af075459 chore: Add welcome message to new PRs/Issues (#1573)
- 4868e8bfed15da4d40cad1a910a272bc43bafc92 Add back LightGBM library initialization in booster (#1575)
- d427b8842a56a88dbbe1d533a4df083c41adb07f docs: update installation guidance of v0.10.0 (#1578)
- 55a60c9c017278881de70aa92bf516cf0e5fa552 docs: add more .net samples (#1570)
- 39fe2d8b987e0bee0823320d456d87da48b7a45d chore: Add GH workflow to label new/reopened issues (#1571)
- 0febe3cb5df1838bb5daaa138fbc74ee904a69ff docs: add dotnet installation & example doc (#1567)
- db95a1046584c158a3819325c2229d6501b48330 chore: update website (#1566)
This list of changes was auto generated.
v0.10.0
1 year ago
Building production ready distributed machine learning pipelines can be a challenge for even the most seasoned researcher or engineer. We are excited to announce the release of SynapseML v0.10.0 (Previously MMLSpark), an open-source library that aims to simplify the creation of massively scalable machine learning pipelines. SynapseML unifies several existing ML Frameworks and new MSFT algorithms in a single, scalable API that’s usable across Python, R, Scala, Java, .NET, C#, and F#.
Highlights
 |
|||
|---|---|---|---|
| OpenAI Language Models | .NET, C#, and F# Support | Full MLFlow Support | Live Demos in Browser |
| Embed 175-billion parameter models into your databases with ease | Use or train any SynapseML model from .NET | Quick and easy MLOps, model management, and autologging | Explore the SynapseML library with zero setup |
| Learn More | Getting Started Guide | Explore the Docs | Run in Browser |
New Features
General ✨
- SynapseML now supports .NET, C#, F#, and other .NET ecosystem languages in addition to Scala, Python, and R. Please see our Setup Guide and LightGBM from .NET example for more details. (#1539, #1156, #1443)
- SynapseML is now usable from your browser with zero setup using Binder. Quickly explore our demos in Binder. (#1487, #1493)
Azure Cognitive Services for Big Data 🧠
- Added OpenAI GPT-3 Sentence Completion Transformer. Use this feature to embed 175-billion parameter language models into distributed pipelines and databases to solve a variety of general purpose NLP tasks across natural language and code. (#1495, #1541)
- Added an example of Sentence Completion with GPT-3 (#1564)
- Added support for Form Recognizer V3.0 (#1269)
- Improved MVAD usability with async training and better data validation (#1477)
- Upgraded the univariate anomaly detection version to v1.1-preview (#1440)
- Added a multivariate anomaly detection sample notebook (#1365)
- Added a Text to Speech example to cognitive service overview (#1350)
- Added opinion mining to TextSentiment Models (#1449)
- Fixed Azure Maps schemas (#1553)
- Removed modelID param validators in FormRecognizerV3 (#1551)
- Fixed form recognizer and form ontology learner issues (#1506)
- Fixed
setServiceNamepython method in OpenAI (#1498) - Fixed error in Text Analytics Analyze schema
- Improved error handling for MVAD (#1448, #1391)
- Removed unused concurrency parameter for MVAD (#1383)
- Improved robustness of flood risk notebook by adding polling (#1427)
Responsible AI at Scale 😇
- Added partial dependence plots (PDP) to allow for understanding how independent variables affect a model's prediction (#1426)
- Updated ICE/PDP documentation with PDP-based feature importance and additional examples (#1441, #1352)
- Added a notebook for ICE and PDP feature explainers (#1318)
- Updated data balance documentation to better describe how it can be used to ensure model fairness (#1540)
MLFlow 🔃
- Added documentation for MLFlow autologging (#1508)
- Added documentation on the SynapseML-MLFlow integration (#1428)
LightGBM on Spark 🌳
- Added the ability to pass in generic argument strings to LightGBM enabling many complex parameterizations (#1444)
- Added seed parameters to LightGBM (#1387)
- Added a method to get LightGBM native model string directly (#1515)
- Fixed issue with validation data creation during
useSingleDatasetmode (#1527) - Fixed multiclass training with initial scores (#1526)
- Fixed saving LightGBM model iterations with early stopping (#1497)
- Fixed issue where chunk size parameter was incorrectly specified during data copy (#1490)
- Fixed issue where when empty partition is chosen as the main worker in
singleDatasetMode(#1458) - Fixed bug with data repartitioning in
LightGBMRanker(#1368) - Fixed outdated docs for
useSingleDatasetMode(#1562) - Refactored LightGBM class structure to improve logging and debugging (#1557)
Vowpal Wabbit 🐇
- Fixed issues with the
saveNativeModelfor the VWRegressionModel #1364 (#1366) - Fixed issues with building quadratic interaction terms (#1460)
Isolation Forests 🌲
Additional Updates
Maintenance 🔧
- Removed unused debugging code (#1546)
- Remove Synapse test exclusion for Explanation Dashboard notebook (#1531)
- Made python style checks verbose (#1532)
- Fixed library checking while installing library on Databricks cluster (#1488)
- Upgraded and fix Dockerfiles (#1472)
- Added Developer Docker Image build to pipeline (#1480)
- Fixed ADO area path in Issue Linker (#1464)
- Fix master version badge display
- Improved Databricks error reporting
- Updated azure cli to stop build errors
- Fixed SSL handshake flakiness
- Added
itsdangerousas a dependency to ADB tests (#1412) - Turned on debug for pr to work item workflow
- Pointed pr linker to official implementation
- Changed GitHub action trigger from pull_request_target to pull_request (#1413)
- Fixed issue where Unit Tests were not executing (#1409)
- Added Azure DevOps PR linker (#1394)
- Updated GH PAT name (#1389)
- Re-enable Synapse E2E Tests (#1517)
- Updated SynapseE2E Tests to Spark 3.2 (#1362)
- Fix ADO issue/pr linking (#1463)
- Cleaned up extra MVAD models and improved network resiliency (#1457)
- Updated azure blob client version (#1563)
- Fixed docker security vulnerability (#1561)
- Streamlined scalastyle hook (#1530)
- Updated CODEOWNERS (#1523)
- Updated OpenAI resource info (#1525)
- Fixed semantic PR checking (#1503)
- Updated docker images to remain compliant (#1500)
- Added component governance explicitly to build so timeout variable works (#1489)
- Fixed path for notebook test files in gitignore (#1485)
- Increased component governance timeout (#1482)
- Added conda caching to build
- Stopped build from failing after 1 hour
- Fixed flaking MVAD test
- Refactored build pipeline definitions
- Split Synapse tests into multiple test (#1377)
- Moved from ADO Pipelines to GitHub Workflows (#1406)
Website Improvements 💻
- Fixed MathJax expressions rendering (#1343)
- Fixed google analytics gtags (#1434)
- Corrected placement of BingSiteAuth.xml config (#1445, #1439)
- Fixed website security and upgrade docusaurus (#1545)
- Moveed Geospatial Services to its own folder (#1345)
- Bumped minimist from 1.2.5 to 1.2.6 in /website (#1455)
- Bumped node-forge from 1.2.1 to 1.3.0 in /website (#1451)
- Bumped prismjs from 1.25.0 to 1.27.0 in /website (#1430)
- Bumped follow-redirects from 1.14.7 to 1.14.8 in /website (#1402)
- Bumped nanoid from 3.1.23 to 3.2.0 in /website (#1355)
- Bumped shelljs from 0.8.4 to 0.8.5 in /website (#1347)
- Bumped follow-redirects from 1.14.1 to 1.14.7 in /website (#1348)
- Bumped cross-fetch from 3.1.4 to 3.1.5 in /website (#1496)
- Bumped async from 2.6.3 to 2.6.4 in /website (#1481)
- Pinned onnxmltools to a specific version (#1524)
Bug Fixes 🐞
- Fixed twitter sentiment detection notebook (#1544)
- Fixed issue with
DataConversionserialization (#1505) - Fixed typos in
TestBase(#1501) - Fixed issue in
GridSpacepython API (#1470) - Fixed reflective class loading in IntelliJ (#1456)
- Removed verbose
ComputeModelStatisticsoutput and convertscoredLabelsColto DoubleType (#1361) - Fixed flaking in geospatial notebooks
Code Style 🎶
- Improved style checks using pre-commit (#1538, #1528, #1535)
- Formatted code and notebooks with Black style checker (#1522, #1520)
Documentation 📘
- Tabularized badges for readability (#1486)
- Added a PR template (#1418)
- Improved installation readme (#1369, #1422)
- Added a Security readme (#1511)
- Updated the Azure Synapse readme (#1372)
- Remove reference to custom maven resolver
- Added pointer to docs on synapse pool configuration
- Fixed typos in readme (#1516)
Contributor Spotlight
We are excited to highlight the contributions of the following SynapseML contributors:
|
 |
 |
|---|---|---|
| Serena Ruan | Ric Serradas | Puneet Pruthi |
| Serena is a Software Engineer II on the Synapse team in Beijing and a force of nature. In this release, Serena has continued her prolific contribution steak by adding language support for .NET, C#, and F# and integrating SynapseML with MLFlow. Additionally, Serena has contributed several features to the MLFlow and Spark.NET open-source communities so that these systems can work better for every user. These contributions are just some of the many amazing things Serena has accomplished during this release, and her devotion and craft are pivotal to the ecosystem. | Ric is a Senior Engineering Manager on the OneNote team with a shining personality and drive to collaborate. In just a few weeks Ric hit the ground running by setting up an automated link between GitHub and Azure DevOps, building the first working version of SynapseE2E tests, and re-writing our entire build in GH Actions. Furthermore, Ric worked tirelessly through nights and weekends to land his contributions. | Puneet is a Senior Engineer on the SynapseML team with a knack for engineering systems and dockerization. Puneet's contributions to the library include architecting the new binder integration, driving our Synapse E2E tests to completion, and improving SynapseML’ s infrastructure around community engagement. Puneet is constantly thinking of ways to improve the community and we value his effort. |
 |
 |
 |
| Mark Niehaus | Keerthi Yanda | Yagna Oruganti |
| Mark is a Senior Software Engineer on the SynapseML team with a deep knowledge of the .NET ecosystem and infrastructure development. In this release, Mark architected SynapseML’ s .NET binding blob publishing strategy, drove the OpenAI GPT-3 bindings to completion, and wrote a detailed GPT-3 walkthrough. Mark completed these projects while supporting the Time Series Insights service, speaking to his ability to keep multiple plates spinning at a time. | Keerthi is a Software Engineer II on the SynapseML team. Despite joining Microsoft just a few months ago, Keerthi has quickly learned the SynapseML ropes to take command of our integration with the Azure Synapse platform. Huge kudos to her for braving long build times, and daunting error messages to make sure SynapseML works out of the box on Synapse Analytics clusters. | Yagna is a Senior Data and Applied Scientist on the Industry AI team with a talent for building solutions that integrate many community tools to solve customer challenges. Yagna's first contribution to SynapseML was a masterpiece of a demo showing how to use Isolation Forests, MLFlow, Tabular SHAP, and the interpret-ml explanation dashboard in a single anomaly detection example. |
Acknowledgements
We would like to acknowledge the developers and contributors, both internal and external, who helped create this version of SynapseML
Serena Ruan @serena-ruan, Eric Dettinger, Scott Votaw @svotaw, Puneet Pruthi @ppruthi, Ric Serradas @riserrad, Mark Niehaus @niehaus59, Kyle Rush @k-rush, Keerthi Yanda @KeerthiYandaOS, Yagna Oruganti @YagnaDeepika, Jason Wang @memoryz, Ilya Matiach @imatiach-msft, Yazeed Alaudah @yalaudah, Elena Zherdeva @ezherdeva, Kashyap Patel @ms-kashyap, Martha Laguna @martthalch @marthalc, Alex Li @liyzcj, Maria Guirguis @maguir, Alexandra Savelieva @alsavelv, @netang, Sudhindra Kovalam @SudhindraKovalam, Markus Cozowicz @eisber, Tom Finley, Markus Weimer, Jeff Zheng, James Verbus @jverbus, Chris Hoder, Misha Desai, Nellie Gustafsson, Eren Orbey, Beverly Kodhek, Louise Han @jr-MS, Justyna Lucznik, Kim Manis, Mitrabhanu Mohanty, Bogdan Crivat, Anand Raman, William T. Freeman, James Montemagno, Luis Quintanilla, Dennis Kennedy, Ryan Hurey, Jarno Ensio, Brian Mouncer, Steve Suh @suhsteve, Akshaya Annavajhala (AK), Guolin Ke, Tara Grumm, Niharika Dutta @Niharikadutta, Andrew Fogarty, Juanyong Duan, Weichen Xu @WeichenXu123, Spark.NET Team, ONNX Team, Azure Global, Vowpal Wabbit Team, LightGBM Team, MSFT Garage Team, MSR Outreach Team, Speech SDK Team, MLflow Team
Learn More
 |
 |
 |
|---|---|---|
| Visit our website for the latest docs, demos, and examples | Read more about SynapseML's GA release in the Microsoft Research Blog | Learn more about our .NET bindings and code generation system. |
 |
 |
 |
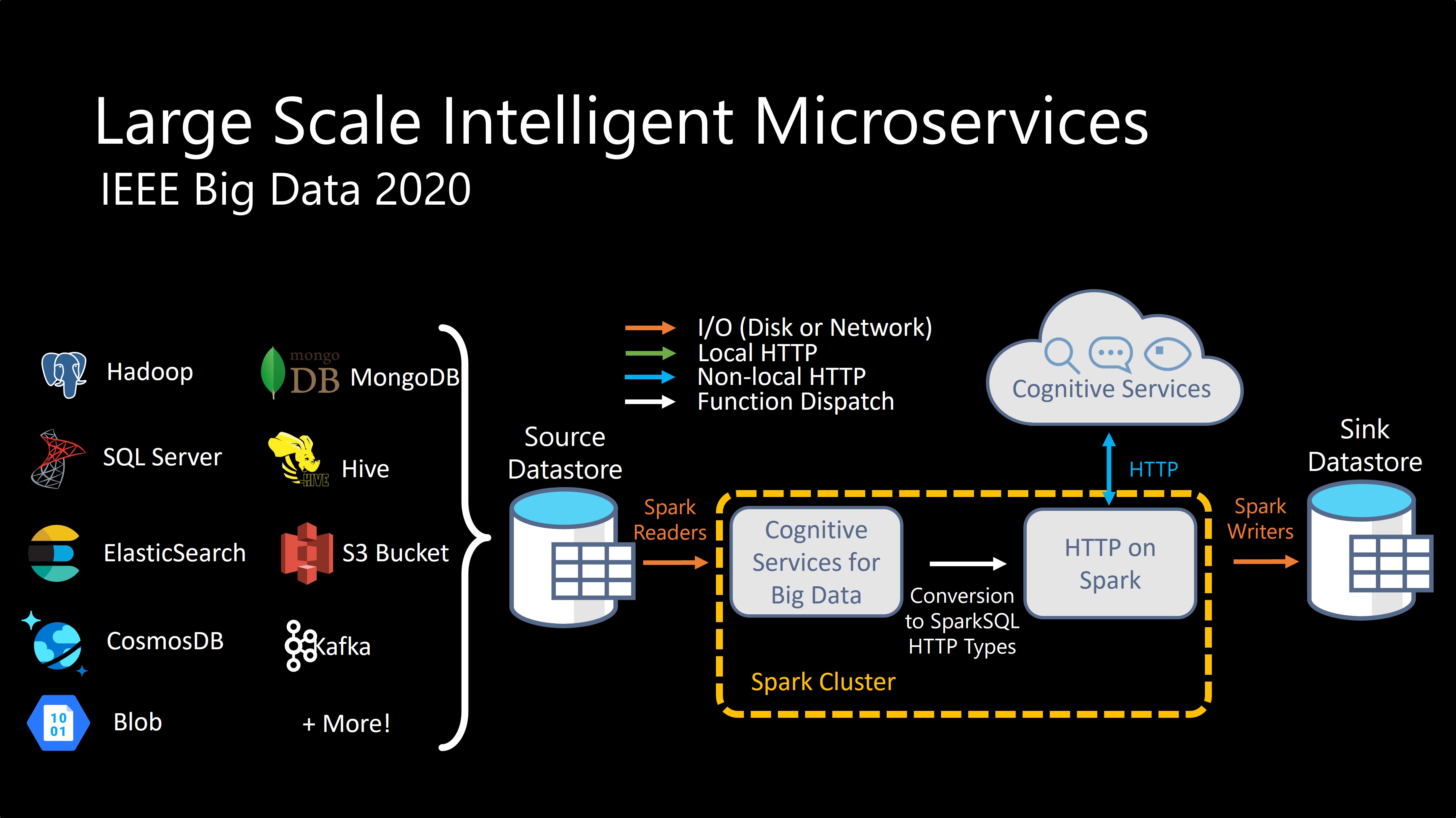
| Watch a demonstration of SynapseML to create a multilingual search engine. | Read our Paper from IEEE Big Data '21 | Explore our integration with the Azure OpenAI Service |
mmlspark-v0.7
1 year agoNew functionality:
- New transforms:
EnsembleByKey,CacherTimer; see the documentation.
Updates:
-
Miniconda version 4.3.21, including Python 3.6.
-
CNTK version 2.1, using Maven Central.
-
Use OpenCV from the OpenPnP project from Maven Central.
Improvements:
-
Spark's
binaryFilesfunction had a regression in version 2.1 from version 2.0 which would lead to performance issues; work around that for now. Data frame operations after a use ofBinaryFileReader(eg, reading images) are significantly faster with this. -
The Spark installation is now patched with
hadoop-azureandazure-storage. -
Includes additional bug fixes and improvements.
mmlspark-v0.8
1 year agoNew functionality:
-
We are now uploading MMLSpark as a
Azure/mmlsparkspark package. Use--packages Azure:mmlspark:0.8with the Spark command-line tools. -
Add a bi-directional LSTM medical entity extractor to the
ModelDownloader, and new jupyter notebook for medical entity extraction using NLTK, PubMed Word embeddings, and the Bi-LSTM. -
Add
ImageSetAugmenterfor easy dataset augmentation within image processing pipelines.
Improvements:
-
Optimize the performance of
CNTKModel. It now broadcasts a loaded model to workers and shares model weights between partitions on the same worker. Minibatch padding (an internal workaround of a CNTK bug) is now no longer used, eliminating excess computations when there is a mismatch between the partition size and minibatch size. -
Bugfix: CNTKModel can work with models with unnamed outputs.
Docker image improvements:
-
Environment variables are now part of the docker image (in addition to being set in bash).
-
New docker images:
-
microsoft/mmlspark:latest: plain image, as always, -
microsoft/mmlspark:gpu: GPU variant based on annvidia/cudaimage. -
microsoft/mmlspark:plusandmicrosoft/mmlspark:plus-gpu: these images contain additional packages for internal use; they will probably be based on an older Conda version too in future releases.
-
Updates:
-
The Conda environment now includes NLTK.
-
Updated Java and SBT versions.
mmlspark-v0.9
1 year agoNew functionality:
-
Refactor
ImageReaderandBinaryFileReaderto support streaming images, including a Python API. Also improved performance of the readers. Check the 302 notebook for usage example. -
Add
ClassBalancerestimator for improving classification performance on highly imbalanced datasets. -
Create an infrastructure for automated fuzzing, serialization, and python wrapper tests.
-
Added a
DropColumnspipeline stage.
New notebooks:
- 305: A Flowers sample notebook demonstrating deep transfer learning
with
ImageFeaturizer.
Updates:
- Our main build is now based on Spark 2.2.
Improvements:
-
Enable streaming through the
EnsembleByKeytransformer. -
ImageReader, HDFS issue, etc.
mmlspark-v0.10
1 year agoNew functionality:
-
We now provide initial support for training on a GPU VM, and an ARM template to deploy an HDI Cluster with an associated GPU machine. See
docs/gpu-setup.mdfor instructions on setting this up. -
New auto-generated R wrappers for estimators and transformers. To import them into R, you can use devtools to import from the uploaded zip file. Tests and sample notebooks to come.
-
A new
RenameColumntransformer for renaming columns within a pipeline.
New notebooks:
-
Notebook 104: An experiment to demonstrate regression models to predict automobile prices. This notebook demonstrates the use of
Pipelinestages,CleanMissingData, andComputePerInstanceStatistics. -
Notebook 105: Demonstrates
DataConversionto make some columns Categorical. -
There us a 401 notebook in
notebooks/gpuwhich demonstrates CNTK training when using a GPU VM. (It is not shown with the rest of the notebooks yet.)
Updates:
- Updated to use CNTK 2.2. Note that this version of CNTK depends on libpng12 and libjasper1 -- which are included in our docker images. (This should get resolved in the upcoming CNTK 2.3 release.)
Improvements:
-
Local builds will always use a "0.0" version instead of a version based on the git repository. This should simplify the build process for developers and avoid hard-to-resolve update issues.
-
The
TextPreprocessortransformer can be used to find and replace all key value pairs in an input map. -
Fixed a regression in the image reader where zip files with images no longer displayed the full path to the image inside a zip file.
-
Additional minor bug and stability fixes.
mmlspark-v0.11
1 year agoNew functionality:
-
TuneHyperparameters: parallel distributed randomized grid search for SparkML and TrainClassifier/TrainRegressor parameters. Sample notebook and python wrappers will be added in the near future.
-
Added
PowerBIWriterfor writing and streaming data frames to PowerBI. -
Expanded image reading and writing capabilities, including using images with Spark Structured Streaming. Images can be read from and written to paths specified in a dataframe.
-
New functionality for convenient plotting in Python.
-
UDF transformer and additional UDFs.
-
Expanded pipeline support for arbitrary user code and libraries such as NLTK through UDFTransformer.
-
Refactored fuzzing system and added test coverage.
-
GPU training supports multiple VMs.
Updates:
-
Updated to Conda 4.3.31, which comes with Python 3.6.3.
-
Also updated SBT and JVM.
Improvements:
- Additional bugfixes, stability, and notebook improvements.