ArchiveBox Versions Save
🗃 Open source self-hosted web archiving. Takes URLs/browser history/bookmarks/Pocket/Pinboard/etc., saves HTML, JS, PDFs, media, and more...
v0.4.17
3 years ago- Fix bugs with parsing long URLs as paths
- html-encoded URLs
- new generic HTML parser
- new
--initand--overwriteflags onadd - improve stdout and hints
- fix Pull title button
- other small bugfixes
v0.4.16
3 years agoA minor bugfix release for the Readability archive method to avoid timing out killing the whole archiving process.
v0.4.15
3 years ago- fix a bug where invalid URLs where attempted to be parsed an imported, causing the whole archive process to crash
- add support for scheduled archiving in docker
docker run -v $PWD:/data archivebox schedule --foreground --every=day --depth=1 'https://getpocket.com/users/USERNAME/feed/all'
# docker-compose.yml
version: '3.7'
services:
archivebox:
image: nikisweeting/archivebox:latest
command: schedule --foreground --every=day --depth=1 'https://getpocket.com/users/USERNAME/feed/all'
environment:
- USE_COLOR=True
- SHOW_PROGRESS=False
volumes:
- ./data:/data
v0.4.14
3 years agoAdd support for the Readability article text extractor, it runs on the SingleFile, Wget, and DOM dump output by default, but if none of those are available it will download the article from scratch to do text extraction. This release also officially adds Docker support for ARM architectures, including the Raspberry Pi. The image size was also shrunk from 1.5GB to 452MB by making sure unnecessary build tools are uninstalled after the package build process.

v0.4.13
3 years agov0.4.12
3 years agoThis is a minor bugfix release with some Dockerfile improvements to qualify for the official docker image library.
v0.4.11
3 years agoWe add a major new archive method in this release: SingleFile. On bare metal it requires installing Node and Chrome/Chromium, but it works out-of-the-box in the Docker version.
This finally allows ArchiveBox to pass all of the acid tests except one, and the archive for Github and many other sites are nicer than Wget was able to do on its own.



v0.4.9
3 years ago

🌅 v0.4 is officially released. This is a long-awaited 3rd-pass review over every corner of the archivebox UX. It adresses many of the fundamental shortcomings around index consistency by using a new SQLite database, with automatic migrations provided by django. It also smooths many of the rough edges, adds a new admin Web UI, a rich new CLI, closes 40+ github tickets, and is the first official release available on PyPI.
-
https://pypi.org/project/archivebox/
pip install archivebox -
https://hub.docker.com/r/nikisweeting/archivebox
docker run -v $PWD:/data nikisweeting/archivebox - https://archivebox.readthedocs.io/en/latest/
- https://github.com/pirate/ArchiveBox/releases/tag/v0.4.9
Enjoy!
🎉 Big thanks to everyone who helped! Especially the Monadical team @cdvv7788 @apkallum @afreydev and also @drpfenderson who helped us track down the last few index importing bugs! 🎉
The docs still have some work left to finish updating, but the CLI help text is all up-to-date (when in doubt, just pass --help).
Let us know if you find any rough edges here: https://github.com/pirate/ArchiveBox/issues/new/choose
pip install archivebox
cd path/to/your/archive/folder
archivebox init # this doubles as the migrate command, it will safely upgrade existing index files automatically
archviebox add 'https://example.com'
archviebox add 'https://getpocket.com/users/USERNAME/feed/all' --depth=1
archivebox status
archivebox server
archivebox help
Or if you prefer docker, the CLI works exactly the same archivebox [subcommand] [...args]:
docker run -v $PWD:/data nikisweeting/archivebox init
docker run -v $PWD:/data nikisweeting/archivebox add 'https://example.com'
docker run -v $PWD:/data -p 8000 nikisweeting/archivebox server
version: '3.7'
services:
archivebox:
image: nikisweeting/archivebox:latest
command: server 0.0.0.0:8000
stdin_open: true
tty: true
ports:
- 8000:8000
environment:
- USE_COLOR=True
volumes:
- ./data:/data
Screenshots

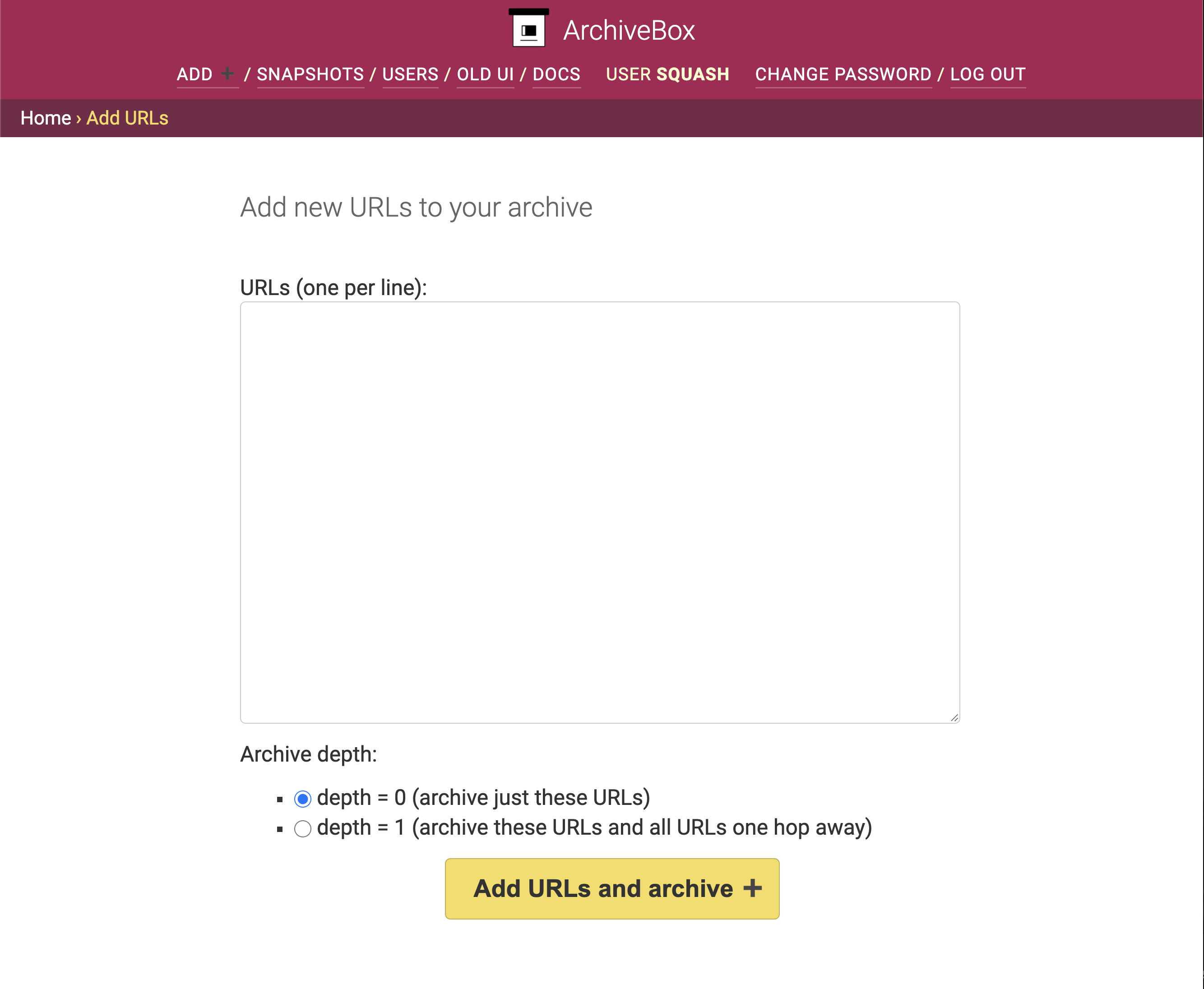
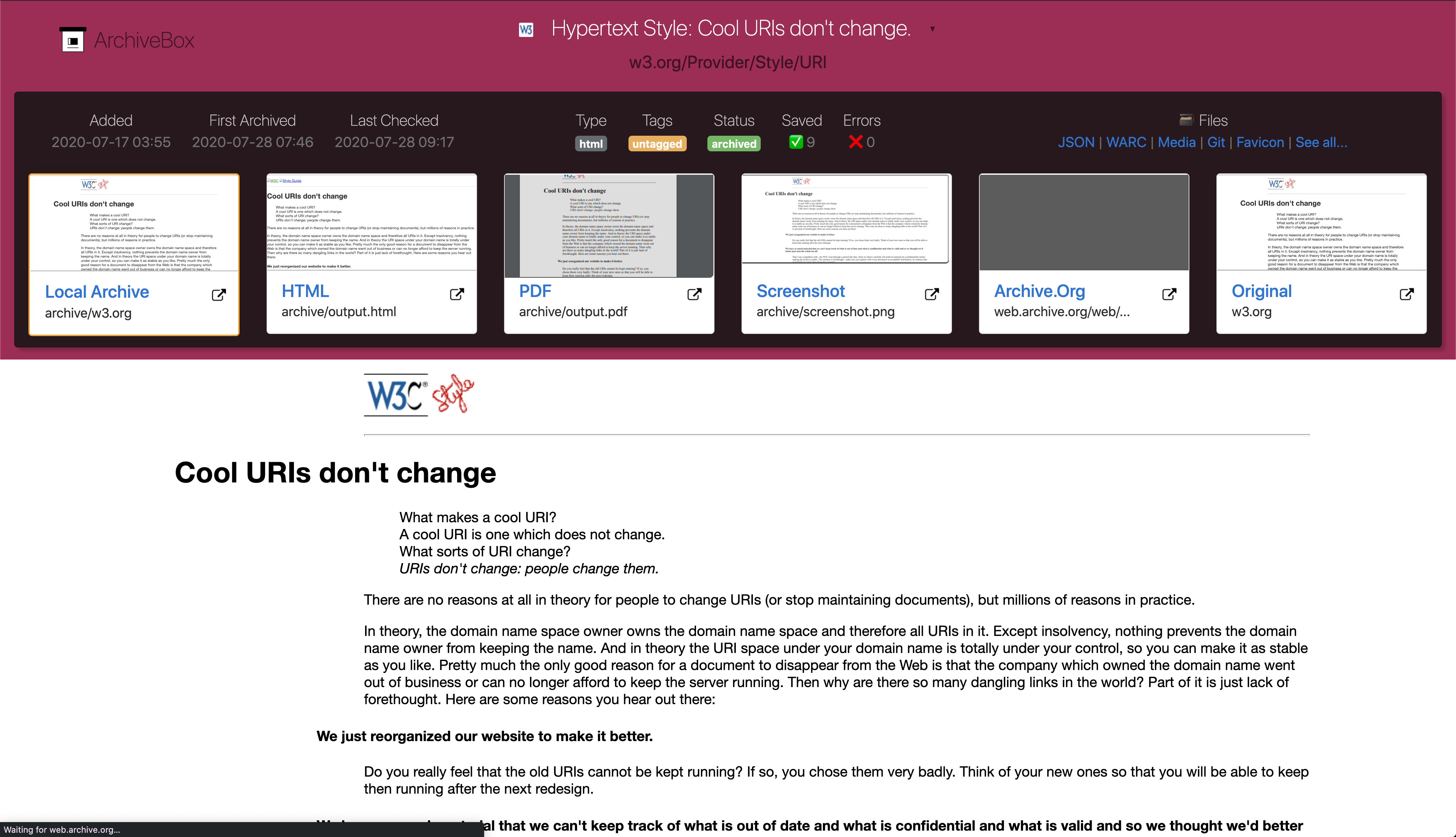

New Features
A bunch of big changes:
-
pip install archiveboxis now available - full transition to Django Sqlite DB with migrations (making upgrades between versions much safer now)
- maintains an intuitive and helpful CLI that's backwards-compatible with all previous archivebox data versions
- uses argparse instead of hand-written CLI system: see
archivebox/cli/archivebox.py - new subcommands-based CLI for
archivebox(see below) - new Web UI with pagination, better search, filtering, permissions, and more
- 30+ assorted bugfixes, new features, and tickets closed
For more info, see: https://github.com/pirate/ArchiveBox/wiki/Roadmap
Released in this version:
Install Methods:
- ✅
pip/pipenv install archivebox [--dev] - ✅
docker run nikisweeting/archivebox/docker-compose up - ❌
apt/brew/pkg/yum/nix/etc install archivebox(maybe later)
Command Line Interface:
- ✅
archivebox - ✅
archivebox version - ✅
archivebox help - ✅
archivebox init - ✅
archivebox status - ✅
archivebox add - ✅
archivebox remove - ✅
archivebox update - ✅
archivebox list - ✅
archivebox schedule - ✅
archivebox config - ✅
archivebox server - ✅
archivebox shell - ✅
archivebox manage - ❌
archivebox oneshot - ❌
archivebox export - ❌
archivebox proxy
Web UI:
- ✅
/Main index - ✅
/addPage to add new links to the archive (but needs improvement) - ✅
/archive/<timestamp>/Snapshot details page - ✅
/archive/<timestamp>/<url>live wget archive of page - ✅
/archive/<timestamp>/<extractor>get a specific extractor output for a given snapshot - ✅
/archive/<url>shortcut to view most recent snapshot of given url - ✅
/archive/<url_hash>shortcut to view most recent snapshot of given url - ✅
/adminAdmin interface to view and edit archive data - ✅
/old.htmlBackwards-compatible static HTML index for the previous version
Python API:
- ✅
from archivebox.main import add, remove, info, config, etc... - ✅
from archivebox.core.models import Snapshot, User, etc... - ✅
from archivebox.extractors import media, wget, screenshot, etc... - ✅
from archivebox.index import json, sql, html, etc... - ✅
from archivebox.parsers import pinboard_rss, pocket_html, generic_json, etc...
(Red ❌ features are still unfinished and will be released in later versions)
v0.2.4
5 years ago- better archive corruption guards (check structure invariants on every parse & save)
- remove title prefetching in favor of new FETCH_TITLE archive method
- slightly improved CLI output for parsing and remote url downloading
- re-save index after archiving completes to update titles and urls
- remove redundant derivable data from link json schema
- markdown link parsing support
- faster link parsing and better symbol handling using a new compiled URL_REGEX
v0.2.3
5 years ago- fixed issues with parsing titles including trailing tags
- fixed issues with titles defaulting to URLs instead of attempting to fetch
- fixed issue where bookmark timestamps from RSS would be ignored and current ts used instead
- fixed issue where ONLY_NEW would overwrite existing links in archive with only new ones
- fixed lots of issues with URL parsing by using
urllib.parseinstead of hand-written lambdas - ignore robots.txt when using wget (ssshhh don't tell anyone 😁)
- fix RSS parser bailing out when there's whitespace around XML tags
- fix issue with browser history export trying to run ls on wrong directory