PaddleOCR Save
Awesome multilingual OCR toolkits based on PaddlePaddle (practical ultra lightweight OCR system, support 80+ languages recognition, provide data annotation and synthesis tools, support training and deployment among server, mobile, embedded and IoT devices)
English | 简体中文 | हिन्दी | 日本語 | 한국인 | Pу́сский язы́к

![]()

![]()
![]()



简介
PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力开发者训练出更好的模型,并应用落地。


📣 近期更新
- 🔥PaddleOCR 算法模型挑战赛 火热开启!报名时间1/15-3/31,30万元奖金池!快来一展身手吧😎!
- 🔨2023.11 发布 PP-ChatOCRv2: 一个SDK,覆盖20+高频应用场景,支持5种文本图像智能分析能力和部署,包括通用场景关键信息抽取(快递单、营业执照和机动车行驶证等)、复杂文档场景关键信息抽取(解决生僻字、特殊标点、多页pdf、表格等难点问题)、通用OCR、文档场景专用OCR、通用表格识别。针对垂类业务场景,也支持模型训练、微调和Prompt优化。
-
🔥2023.8.7 发布 PaddleOCR release/2.7
- 发布PP-OCRv4,提供mobile和server两种模型
- 发布PP-ChatOCR ,使用融合PP-OCR模型和文心大模型的通用场景关键信息抽取全新方案
- 🔨2022.11 新增实现4种前沿算法:文本检测 DRRG, 文本识别 RFL, 文本超分Text Telescope,公式识别CAN
- 2022.10 优化JS版PP-OCRv3模型:模型大小仅4.3M,预测速度提升8倍,配套web demo开箱即用
- 💥 直播回放:PaddleOCR研发团队详解PP-StructureV2优化策略。微信扫描下方二维码,关注公众号并填写问卷后进入官方交流群,获取直播回放链接与20G重磅OCR学习大礼包(内含PDF转Word应用程序、10种垂类模型、《动手学OCR》电子书等)
-
🔥2022.8.24 发布 PaddleOCR release/2.6
- 发布PP-StructureV2,系统功能性能全面升级,适配中文场景,新增支持版面复原,支持一行命令完成PDF转Word;
- 版面分析模型优化:模型存储减少95%,速度提升11倍,平均CPU耗时仅需41ms;
- 表格识别模型优化:设计3大优化策略,预测耗时不变情况下,模型精度提升6%;
- 关键信息抽取模型优化:设计视觉无关模型结构,语义实体识别精度提升2.8%,关系抽取精度提升9.1%。
- 🔥2022.8 发布 OCR场景应用集合:包含数码管、液晶屏、车牌、高精度SVTR模型、手写体识别等9个垂类模型,覆盖通用,制造、金融、交通行业的主要OCR垂类应用。
🌟 特性
支持多种OCR相关前沿算法,在此基础上打造产业级特色模型PP-OCR、PP-Structure和PP-ChatOCRv2,并打通数据生产、模型训练、压缩、预测部署全流程。
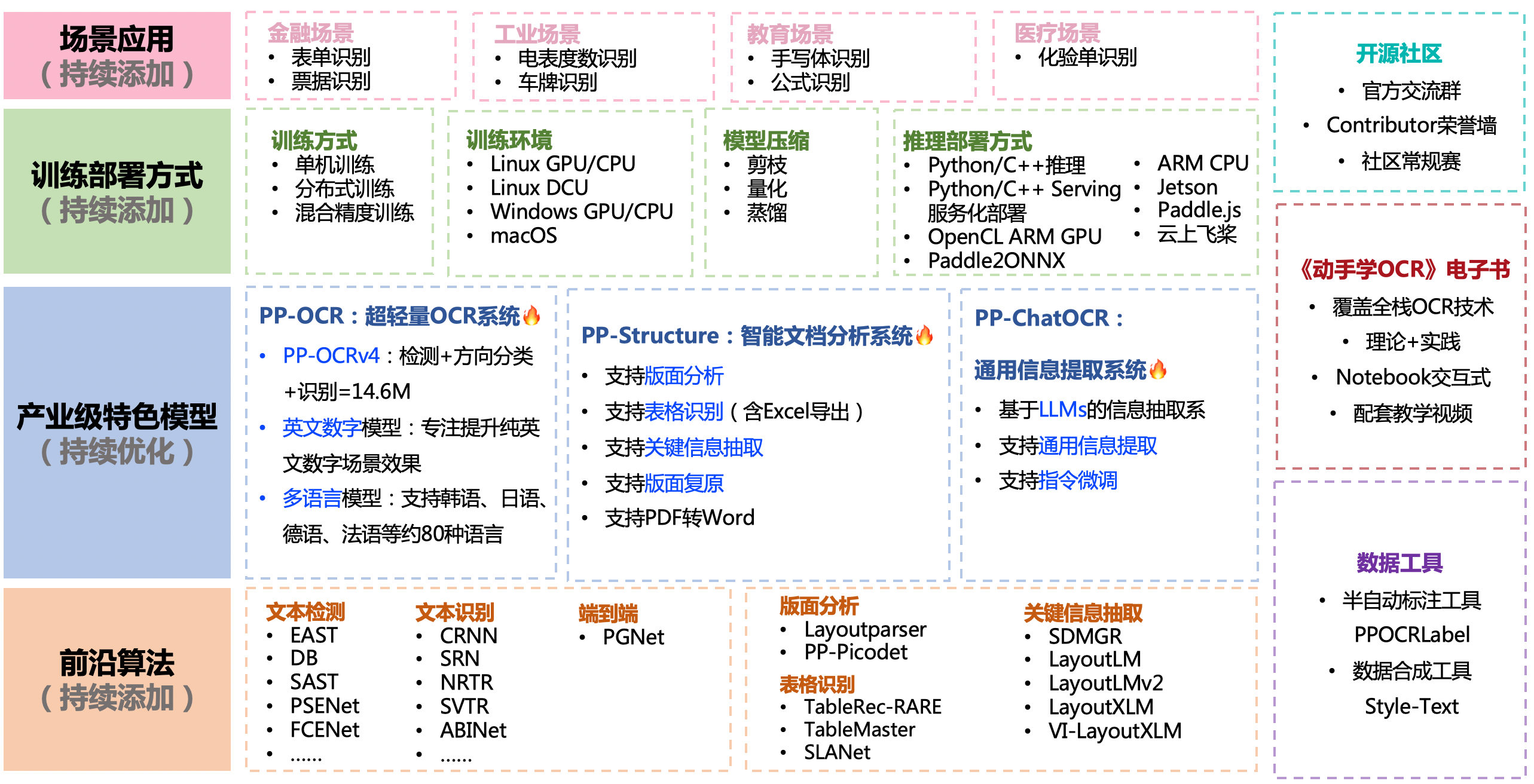
上述内容的使用方法建议从文档教程中的快速开始体验
⚡ 快速开始
-
在线免费体验:
- PP-OCRv4 在线体验地址:https://aistudio.baidu.com/application/detail/7658
- PP-ChatOCRv2 在线体验地址:https://aistudio.baidu.com/application/detail/10368
-
一行命令快速使用:快速开始(中英文/多语言/文档分析)
-
移动端demo体验:安装包DEMO下载地址(基于EasyEdge和Paddle-Lite, 支持iOS和Android系统)
📖 技术交流合作
-
飞桨AI套件(PaddleX)提供了飞桨模型训压推一站式全流程高效率开发平台,其使命是助力AI技术快速落地,愿景是使人人成为AI Developer!
- PaddleX 目前覆盖图像分类、目标检测、图像分割、3D、OCR和时序预测等领域方向,已内置了36种基础单模型,例如RT-DETR、PP-YOLOE、PP-HGNet、PP-LCNet、PP-LiteSeg等;集成了12种实用的产业方案,例如PP-OCRv4、PP-ChatOCR、PP-ShiTu、PP-TS、车载路面垃圾检测、野生动物违禁制品识别等。
- PaddleX 提供了“工具箱”和“开发者”两种AI开发模式。工具箱模式可以无代码调优关键超参,开发者模式可以低代码进行单模型训压推和多模型串联推理,同时支持云端和本地端。
- PaddleX 还支持联创开发,利润分成!目前 PaddleX 正在快速迭代,欢迎广大的个人开发者和企业开发者参与进来,共创繁荣的 AI 技术生态!
-
PaddleX官网地址:https://aistudio.baidu.com/intro/paddlex
-
PaddleX官方交流频道:https://aistudio.baidu.com/community/channel/610
📚《动手学OCR》电子书
🚀 开源共建
- 👫 加入社区:感谢大家长久以来对 PaddleOCR 的支持和关注,与广大开发者共同构建一个专业、和谐、相互帮助的开源社区是 PaddleOCR 的目标。我们非常欢迎各位开发者参与到飞桨社区的开源建设中,加入开源、共建飞桨。为感谢社区开发者在 PaddleOCR release2.7 中做出的代码贡献,我们将为贡献者制作与邮寄开源贡献证书,烦请填写问卷提供必要的邮寄信息。
-
🤩 社区活动:飞桨开源社区长期运营与发布各类丰富的活动与开发任务,在 PaddleOCR 社区,你可以关注以下社区活动,并选择自己感兴趣的内容参与开源共建:
- 🎁 飞桨套件快乐开源常规赛 | 传送门:OCR 社区常规赛升级版,以建设更好用的 OCR 套件为目标,包括但不限于学术前沿模型训练与推理、打磨优化 OCR 工具与应用项目开发等,任何有利于社区意见流动和问题解决的行为都热切希望大家的参与。让我们共同成长为飞桨套件的重要 Contributor 🎉🎉🎉。
- 💡 新需求征集 | 传送门:你在日常研究和实践深度学习过程中,有哪些你期望的 feature 亟待实现?请按照格式描述你想实现的 feature 和你提出的初步实现思路,我们会定期沟通与讨论这些需求,并将其纳入未来的版本规划中。
- 💬 PP-SIG 技术研讨会 | 传送门:PP-SIG 是飞桨社区开发者由于相同的兴趣汇聚在一起形成的虚拟组织,通过定期召开技术研讨会的方式,分享行业前沿动态、探讨社区需求与技术开发细节、发起社区联合贡献任务。PaddleOCR 希望可以通过 AI 的力量助力任何一位有梦想的开发者实现自己的想法,享受创造价值带来的愉悦。
- 📑 项目合作:如果你有企业中明确的 OCR 垂类应用需求,我们推荐你使用训压推一站式全流程高效率开发平台 PaddleX,助力 AI 技术快速落地。PaddleX 还支持联创开发,利润分成!欢迎广大的个人开发者和企业开发者参与进来,共创繁荣的 AI 技术生态!
🛠️ PP-OCR系列模型列表(更新中)
| 模型简介 | 模型名称 | 推荐场景 | 检测模型 | 方向分类器 | 识别模型 |
|---|---|---|---|---|---|
| 中英文超轻量PP-OCRv4模型(15.8M) | ch_PP-OCRv4_xx | 移动端&服务器端 | 推理模型 / 训练模型 | 推理模型 / 训练模型 | 推理模型 / 训练模型 |
| 中英文超轻量PP-OCRv3模型(16.2M) | ch_PP-OCRv3_xx | 移动端&服务器端 | 推理模型 / 训练模型 | 推理模型 / 训练模型 | 推理模型 / 训练模型 |
| 英文超轻量PP-OCRv3模型(13.4M) | en_PP-OCRv3_xx | 移动端&服务器端 | 推理模型 / 训练模型 | 推理模型 / 训练模型 | 推理模型 / 训练模型 |
- 超轻量OCR系列更多模型下载(包括多语言),可以参考PP-OCR系列模型下载,文档分析相关模型参考PP-Structure系列模型下载
PaddleOCR场景应用模型
| 行业 | 类别 | 亮点 | 文档说明 | 模型下载 |
|---|---|---|---|---|
| 制造 | 数码管识别 | 数码管数据合成、漏识别调优 | 光功率计数码管字符识别 | 下载链接 |
| 金融 | 通用表单识别 | 多模态通用表单结构化提取 | 多模态表单识别 | 下载链接 |
| 交通 | 车牌识别 | 多角度图像处理、轻量模型、端侧部署 | 轻量级车牌识别 | 下载链接 |
- 更多制造、金融、交通行业的主要OCR垂类应用模型(如电表、液晶屏、高精度SVTR模型等),可参考场景应用模型下载
📖 文档教程
- 运行环境准备
- PP-OCR文本检测识别🔥
- PP-Structure文档分析🔥
- 前沿算法与模型🚀
- 场景应用
- 数据标注与合成
- 数据集
- 代码组织结构
- 效果展示
- 《动手学OCR》电子书📚
- 开源社区
- FAQ
- 参考文献
- 许可证书
👀 效果展示 more
PP-OCRv3 中文模型



PP-OCRv3 英文模型


PP-OCRv3 多语言模型


PP-Structure 文档分析
- 版面分析+表格识别

- SER(语义实体识别)


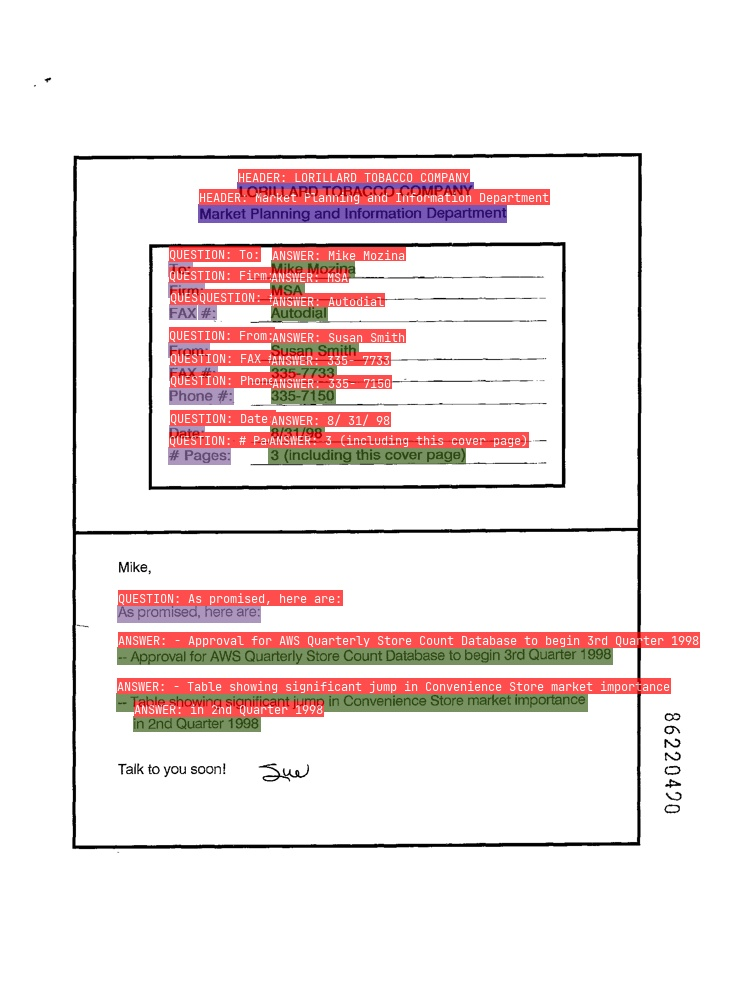
- RE(关系提取)



许可证书
本项目的发布受Apache 2.0 license许可认证。
