Ayakashi Save
:zap: Ayakashi.io - The next generation web scraping framework
![]()
![]()


![]()
The next generation web scraping framework
The web has changed. Gone are the days that raw html parsing scripts were the proper tool for the job.
Javascript and single page applications are now the norm.
Demand for data scraping and automation is higher than ever,
from business needs to data science and machine learning.
Our tools need to evolve.
Ayakashi helps you build scraping and automation systems that are
- easy to build
- simple or sophisticated
- highly performant
- maintainable and built for change
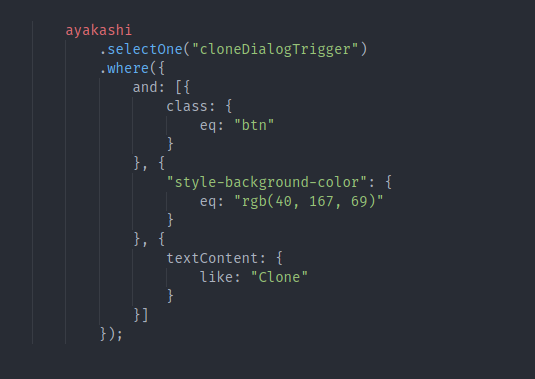
Powerful querying and data models
Ayakashi's way of finding things in the page and using them is done with props
and domQL.
Directly inspired by the relational database world (and SQL), domQL makes
DOM access easy and readable no matter how obscure the page's structure is.
Props are the way to package domQL expressions as re-usable structures which
can then be passed around to actions or to be used as models for data
extraction.
High level builtin actions
Ready made actions so you can focus on what matters.
Easily handle infinite scrolling, single page navigation, events
and more.
Plus, you can always build your own actions,
either from scratch or by composing other actions.
Preload code on pages
Need to include a bunch of code, a library you made
or a 3rd party module
and make it available on a page?
Preloaders have you covered.
Control how you save your data
Automatically save your extracted data
to all major SQL engines, JSON and CSV.
Need something more exotic or the ability to control exactly how the data is persisted?
Package and plug your custom logic as a script.
Manage the flow with pipelines
Scraping the data is only one part of the deal.
How about something like this:
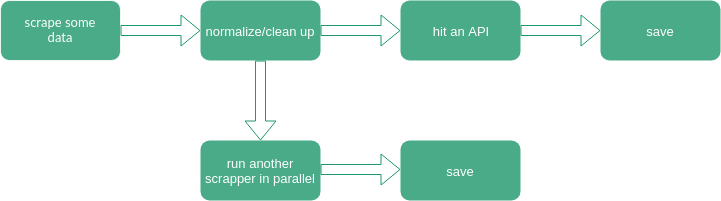
Need it to also be clean, readable and performant?
If so, pipelines can help.
Utilize all your cores
Ayakashi can utilize available cores as needed. Especially useful for projects that need to run multiple operations in parallel.
Extend it as you like
All APIs used to build the builtin functionality are properly exposed.
All core entities are composable and extensible.
Use the language of the web
Many argue about javascript and its quirkiness as a language but the truth is:
If you want to scrape the web, you should speak its language.
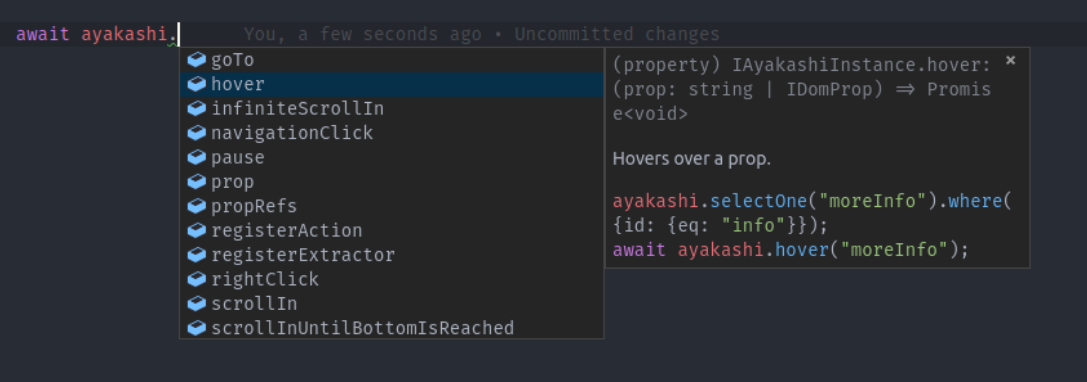
Great editor support
Ayakashi comes bundled with a fully documented public API that you can explore
directly in your editor.
Autocomplete any method, check signatures and examples or follow links to more documentation.
Sounds cool?
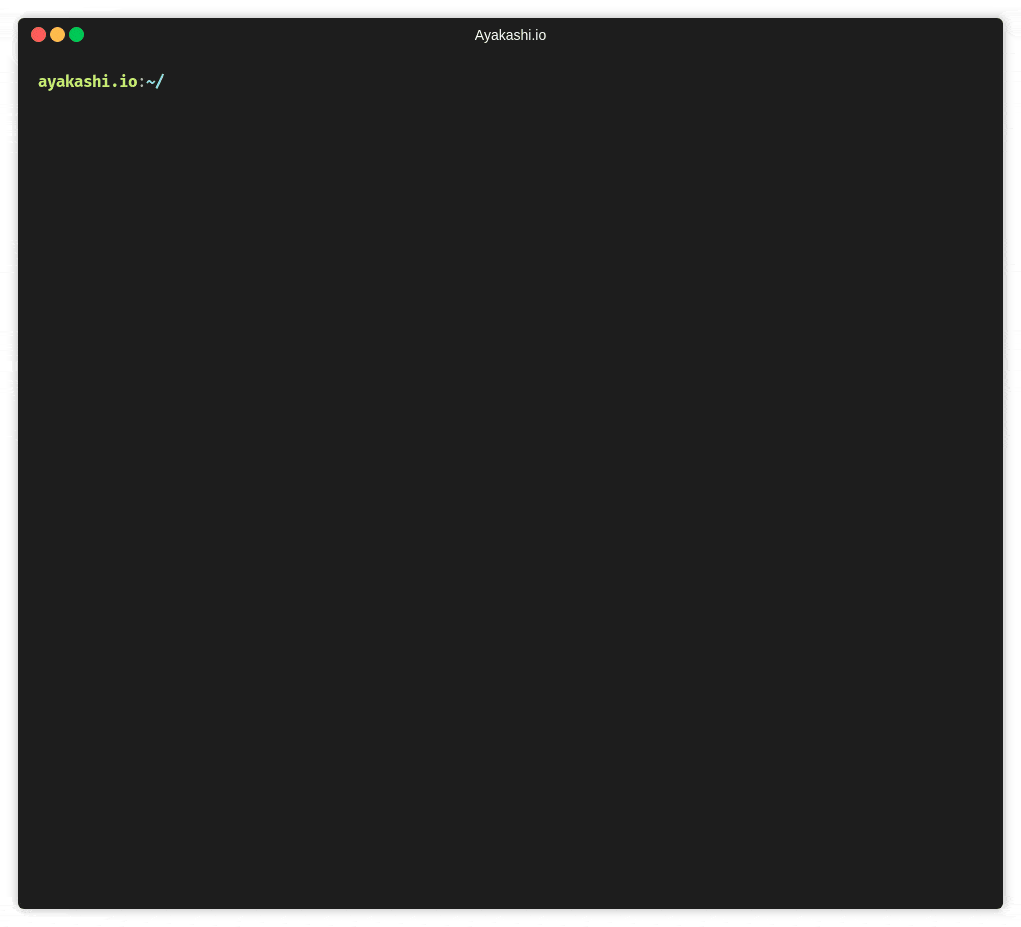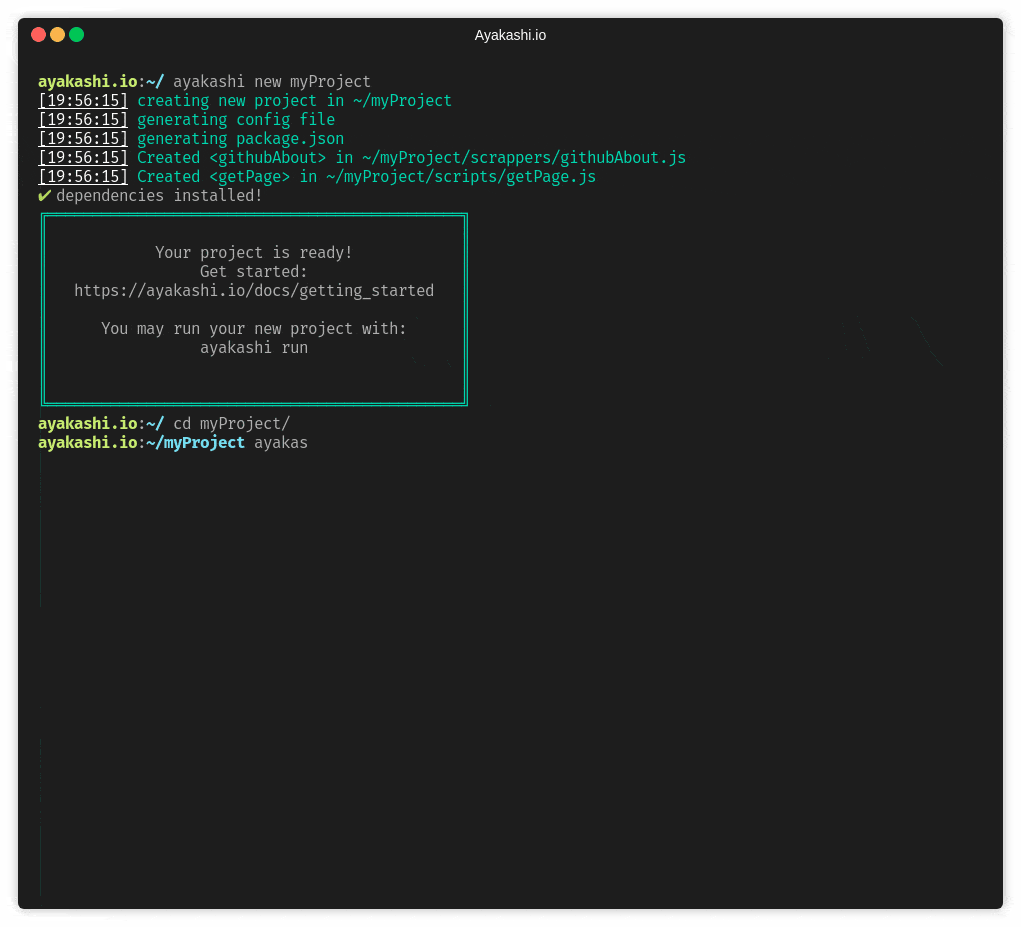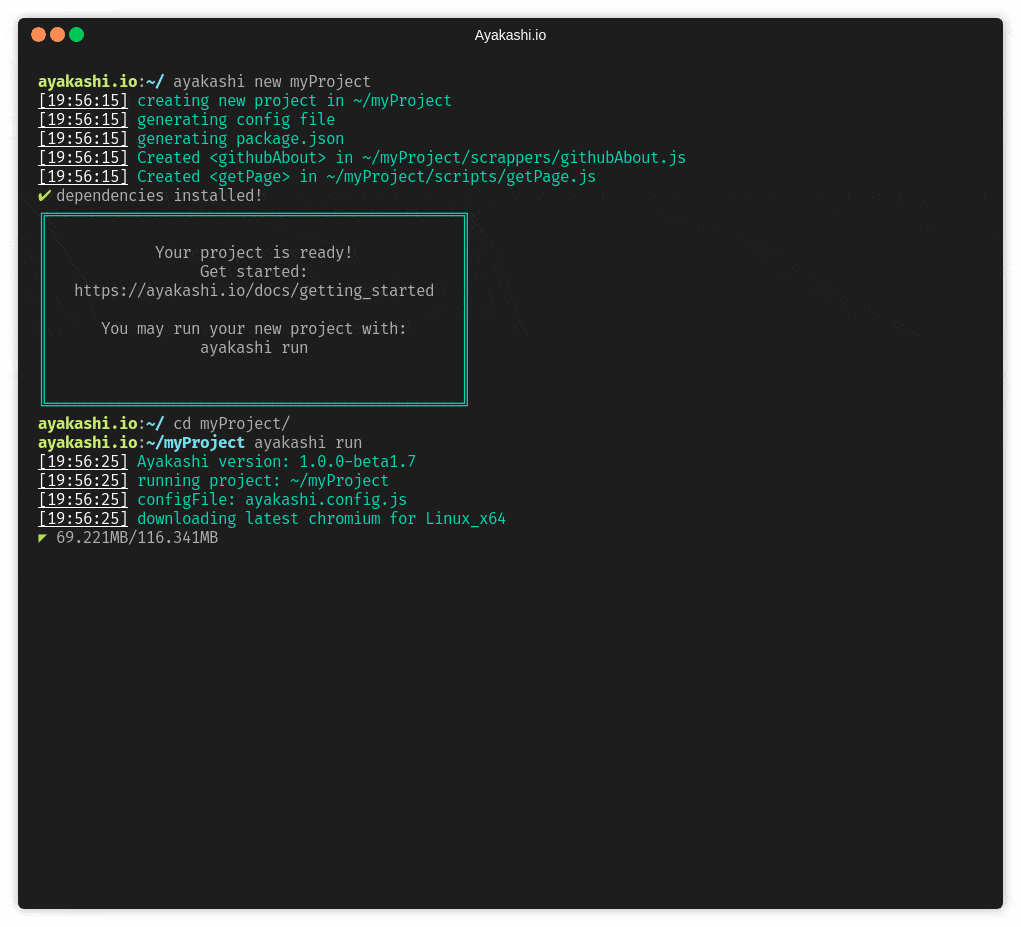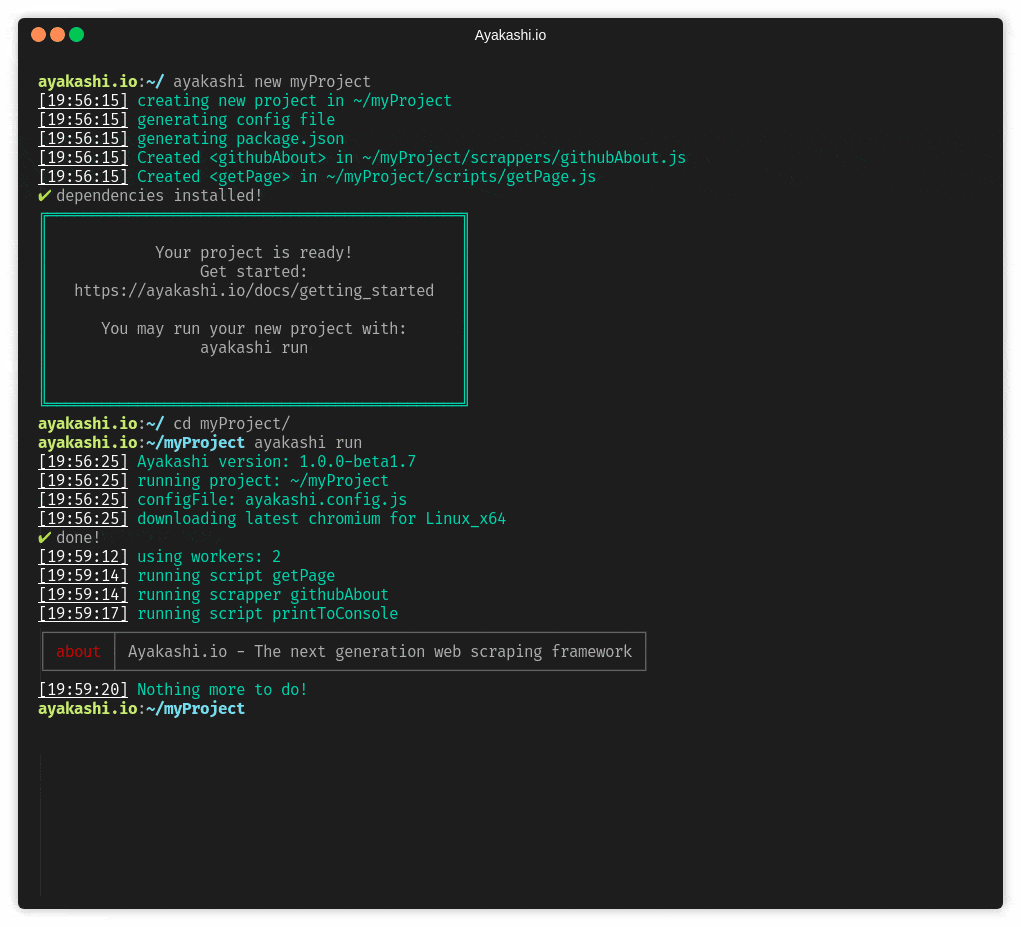
Just head over to the getting started guide!
